
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Many statistical software packages provide hypothesis tests for the independence or association between the rows and columns of a contingency table. However, insufficient guidance is available about the accuracy and domains-of-validity of some tests that are based on assumptions or approximations. This paper assesses the accuracy of the p-values for three tests of small
tables using Monte Carlo simulations and quantile regression. Results for the Fisher-Freeman-Halton exact tests indicate the p-value accuracy depends on the number of possible unique nominal probabilities. Results for the Pearson chi-square test indicate the p-value accuracy depends on the number of possible unique nominal probabilities and the expected cell counts. Results for the Goodman-Kruskal gamma test indicate the p-value accuracy depends on the number of possible unique ordinal probabilities, the expected cell counts, and the total cell counts. Empirical models for the accuracy of these tests and recommended domain-of-validity criteria are provided.
Public Interest Statement
Many scientific, technical, and socio-economic fields use contingency tables to evaluate the observed relationships between two or more factors. Statistical tests are widely used to determine whether or not the factors are independent (i.e. no relationship), and whether or not any association between the factors is statistically significant. The results of these tests may affect public policy and legal decisions (e.g. energy, environmental, health, and safety). However, these tests may be based on assumptions and approximations that can affect the accuracy of the test results. Existing guidelines for the use of these tests are often imprecise, inconsistent, subjective, or non-existent. This paper attempts to objectively estimate the accuracy of three exemplar tests and proposes test domain-of-validity criteria based on the estimated accuracy of the tests, which can assist decision-making. The methods developed in this paper can also be applied to other statistical tests and critical test threshold levels.
1. Introduction
Many statistical software packages provide hypothesis tests for the independence (e.g. Pearson chi-square) or association (e.g. Goodman-Kruskal gamma) between the rows and columns of a contingency table. These tests are often based on assumptions or approximations that may limit their domain-of-validity or accuracy. However, it is unclear from the existing literature and statistical software packages what these limitations are.
This paper assesses the domains-of-validity and accuracy of the Fisher-Freeman-Halton exact (Fisher, Citation1934; Freeman & Halton, Citation1951; Mehta & Patel, Citation1986), the Pearson chi-square (Fleiss, Citation1981), and the Goodman and Kruskal gamma (Brown & Benedetti, Citation1977; Goodman & Kruskal, Citation1979) test p-values for contingency tables up to and
versus indices based on the table dimensions and the row and column margin totals. These three tests were evaluated because they are well known and implemented in several statistical software packages, and the results of which are commonly reported and interpreted by a wide audience. The Fisher–Freeman–Halton test was also included because it is based on the exact reference distribution instead of an approximation.
1.1. Background
1.1.1. R ✕ C contingency tables
Two-dimensional contingency tables list the frequencies of two discrete data variable value combinations. Given row and column variables with
and
discrete values, let
represent the number of times the row variable is equal to the
’th discrete value and column variable is equal to the
’th discrete value. The result is a table with
rows and
columns. The
’th row and
’th column margin totals are denoted by
and
respectively, where a dot in the subscript denotes summation. The overall total is denoted by
. The expected cell count is
.
There are several different tests for the statistical significance of a table. The appropriateness and accuracy of these tests depends on the type of data, sampling method, sample size, and the null hypothesis (
) to be tested. The null hypothesis for the Fisher-Freeman-Halton exact and Pearson chi-square tests is the row and column variables are independent or have equal underlying probabilities. The null hypothesis for the Goodman and Kruskal’s gamma test is no association between the row and column variables. Many of these tests are supported by statistical software packages, such as SAS (Citation2013), SPSS (Citation2009), R (R Core Team, Citation2017; Ekstrøm, Citation2020), and MATLAB (MathWorks, Citation2016; Cardillo, Citation2007a).
1.1.2. Problem statement
We have observed that the Goodman-Kruskal gamma test results for association for some contingency tables appear to be inconsistent with the Pearson chi-square or exact test results for independence (or equal underlying probabilities). For example, consider the contingency table in . The results of three hypothesis tests for this
table are listed in . The p-values for the Fisher-Freeman-Halton exact and Pearson chi-square tests are much greater than 0.05, but the p-value for the Goodman-Kruskal gamma test is much less than 0.05.Footnote1 Therefore, these results indicate that there is a statistically significant association between the treatment and outcome even though the null hypothesis for independence or equal underlying probabilities cannot be rejected.Footnote2
Table 1. Example contingency table
Table 2. Hypothesis test results for
Existing test guidelines were not sufficient in understanding these apparent inconsistencies (e.g. ). Some recommended criteria for the Pearson chi-square test are that all should be greater than 5, 10, or even 20. Cochran [Cochran, Citation1952, p. 328], however, commented that the “numbers 10 and 5 appear to have been arbitrarily chosen”. The SPSS CROSSTAB Pearson chi-square test results for the Example in included a footnote “3 cells (50.0%) have expected count less than 5. The minimum expected count is 1.32”. The R chisq.text function presents a warning message for the same table that the “Chi-squared approximation may be incorrect”. However, Cochran indicates in [Cochran, Citation1954, p. 418] that there are a number of special cases where the
approximation may be adequate if some
. There is a large body of work that discusses guidelines for using the Pearson chi-square test. Tate and Hyer cited a wide range of opinions in [Tate and Hyer, Citation1973, p. 836] regarding these guidelines, which are summarized . Koehler and Larntz observed that “for the null hypothesis of symmetry, the chi-squared approximation for the Pearson statistic is quite adequate at the .05 and .01 nominal levels for expected frequencies as low as .25 when
,
,
” [Koehler and Larntz, Citation1980, p. 343].Footnote3
Table 3. Example Pearson Chi-Square test recommendations summarized by Tate and Hyer (Tate and Hyer, Citation1973, p. 836)
The guidelines for the Goodman-Kruskal gamma test are almost non-existent. Ott et al. indicates, “Although no specific requirement for sample size is generally given, we should never use this test when ” [Ott et al., Citation1992, p. 399]. The accuracy of some of these tests for special cases were previously investigated using Monte Carlo methods in (Craddock & Flood, Citation1970; Göktaş & İşçi, Citation2011), however clear recommendations regarding the domain-of-validity of the tests were not given.
Therefore, the objective of this study was to assess the domain-of-validity and accuracy of the Fisher–Freeman–Halton, Pearson chi-square, and Goodman-Kruskal gamma tests in order to determine generally applicable guidelines for their use. It was not our objective to evaluate other tests or adjustments, such as the mid p-value (Agresti, Citation2002) or Ehwerhemuepha (Ehwerhemuepha et al., Citation2019), which may be more suitable for a given statistical problem.
1.2. Paper organization
The remainder of this paper is organized into five sections. The methods used to are described in Section 2. The results are described in Section 3. Limitations of this analysis are described in Section 4. Recommendations and conclusions are in Sections 5 and 6.
This paper is also accompanied by seven appendices and other supplementary material that are available online. A detailed description of the Monte Carlo simulation method and example results are in Appendix A. Supporting algorithms are described in Appendix B. Empirical envelope model search results are summarized in Appendix C. Supporting methods and results are in Appendix D. Example recommended accuracy criteria calculations are in Appendix E. MATLAB run scripts and functions to reproduce the results herein are described in Appendix F. R run scripts and functions to reproduce the example domain-of-validity and accuracy criteria results herein are described in Appendix G.
2. Methods
The evaluation of the hypothesis test domain-of-validity and accuracy was accomplished in two main steps. First, the 5th percentile p-values for each of the hypothesis tests were estimated for all combinations of tables within a simulation domain using Monte Carlo simulations (e.g. [Kroese and Chan, Citation2014, Chapter 7]). This percentile p-value corresponds to the intended critical p-value for the test (e.g. 0.05).Footnote4 Envelope models to quantify the range of observed 5th percentile p-values based on the table dimensions and row and column margin totals were then determined.
2.1. Monte Carlo simulations
Monte Carlo simulations were used to estimate the 5th percentile p-values ( for contingency tables with independent row and column variables and fixed margin totals (i.e. Method II sampling [Fleiss, Citation1981, p.27]), for each of the hypothesis tests described in Subsection 2.1.1. This involved first generating a set of randomly sampled contingency tables with independent row and column variables and fixed
and
margin totals. Then, for each hypothesis test: the p-values for each randomly sampled table were calculated; the empirical distribution of the p-values was determined; and the 5th percentile p-value was calculated; as depicted by the examples in . This process is described in more detail in Appendix A. All of the results in this paper were calculated using MATLAB version 9.0 (R2016a) with the Statistics and Machine Learning Toolbox version 10.2 (R2016a) (MathWorks, Citation2016).
Figure 1. Distributions of observed hypothesis test p-values for a random sample of tables with independent row and column variables,
and
![Figure 1. Distributions of observed hypothesis test p-values for a random sample of 2×3 tables with independent row and column variables, r=[39,11] and c=[35,9,6]](/cms/asset/78910317-ca48-48a1-8ef8-9b33fc384a80/oama_a_1934959_f0001_oc.jpg)
Example cumulative probability distributions of observed p-values from three hypothesis tests of randomly sampled tables are shown in . The vertical and horizontal scales of the P–P plots in this figure have been transformed by the cube root of the numerical values to place more emphasis on the smaller probability values that are of interest for hypothesis testing. The cumulative probabilities of the observed values were estimated by the mean rank [Electronics Reliability Subcommittee, Citation1987, pp.83–84].
Ideally the distribution of calculated p-values for each hypothesis test would be uniformly distributed between 0 and 1 if the null hypothesis is true. Therefore the ’th percentile p-value for each test would ideally be
, and all of the
symbols in would ideally be on the diagonal dotted lines. For example,
would ideally be 0.05. The deviation in the observed percentile p-values from the ideal values, as depicted by the
symbols in and the solid horizontal line, is the main subject of this analysis.
There are at least two sources of deviation depicted in . The first is a staircase effect associated with the discrete number of possible p-values for tables with the same row and column margin totals. This staircase effect is most apparent in Sub for the Fisher-Freeman-Halton exact test, where the sizes of the adjacent steps are about the same, but the overall size trend is increasing, and there are no other sources of error such as asymptotic approximations. The sum of the horizontal step lengths is 1. Therefore, the horizontal length of each step, which represents the minimum and maximum deviation in the observed p-values from the ideal values, tends to be inversely proportional to the number of possible unique p-values (e.g. ). The steps for the Fisher-Freeman-Halton test are also to the right of the diagonal line, indicating the observed p-values tend to be equal or greater than the ideal p-value, and therefore the test tends to be conservative.
The second source of deviation from the ideal p-value, which is present in Sub , but not Sub , is due to the inaccuracy of the assumed reference distribution or asymptotic approximation. This effect is most apparent in Sub , where the calculated p-values between 0.004 and 0.07 tend to be less than the ideal values, based on the assumption that is normally distributed (see Appendix D.3), and therefore tends to be liberal. Furthermore the extreme tails of the calculated p-value distribution are also truncated in the other direction (i.e. tends to be conservative) because
. This later condition occurred for one of the observed values in Sub where
,
, and the resulting p-value is 0.000330 (see the first row in Table A1). The example results in Sub suggest that the discrete staircase and asymptotic approximation effects on the Pearson chi-square test p-values have similar magnitudes, and that the overall trend tends to be unbiased.
P-value distributions were calculated for all combinations of the row and column margin totals (i.e. and
) within the simulation domain summarized in . This comprised all
tables with
between the minimum and maximum values listed in columns 3 and 4, inclusive. The
table dimensions comprised
plus
tables. Tables with
dimensions were not included because the p-values for the hypothesis tests considered herein are same as the transposed table. The
tables were included to better elucidate potential independent effects of table dimensions and degrees-of-freedom.
Table 4. contingency table simulation domain
The simulation method and example results are described in more detail in Appendix A.
2.1.1. Hypothesis test P-values
P-values for each of the following hypothesis tests were calculated for each unique table:
• Fisher and Fisher-Freeman-Halton exact tests. P-values for tables were calculated using the fishertest function in the MATLAB statistics toolbox. P-values for
,
, and
tables were calculated using Cardillo’s myfisher23, myfisher24, and myfisher33 functions (Cardillo, Citation2007a, Citation2007b and Citation2007c).
• Pearson chi-square test. This test assumes that has a
distribution with
degrees-of-freedom if
is true. The p-value is the probability of the observed or larger
value if
is true, which was calculated using the chi2cdf function in the MATLAB statistics toolbox.
This assumption is one of convenience because the “ statistic has approximately a chi-square distribution for large samples sizes. It is difficult to specify what ‘large’ means, but
is sufficient” [Agresti, Citation1996, p. 28]. The accuracy of the p-value resulting from this assumption and approximation is one of the subjects of this study.
• Goodman-Kruskal’s gamma test. There is more than one version of the Goodman-Kruskal gamma test. The original version proposed by Goodman and Kruskal is described in Appendix D.3.2. A modified version based on (Brown & Benedetti, Citation1977), which is implemented in SAS [SAS, Citation2013, p. 160] and SPSS [SPSS, Citation2010, p. 161], is described in Appendix D.3.1. This test assumes that has a normal distribution with zero mean and unit standard deviation if
, where
and
are calculated according to the equations in Appendix D.3. The subscript
denotes the modifed (
) or original (
) version of the test. The p-value is the probability of the observed or larger
value if
is true, which was calculated using the normcdf function in the MATLAB statistics toolbox.
This assumption is also one of convenience because according to (Goodman & Kruskal, Citation1979) (e.g. pages 78 and 93) and (Brown & Benedetti, Citation1977), actually has an approximate, asymptotically unit-normal distribution for large
. The
value is approximately normally distributed because
is limited to
. The accuracy of the p-value resulting from this assumption and approximation is also one of the subjects of this study.
2.2. Candidate accuracy assessment envelope models
It is assumed herein that the accuracy of the hypothesis test p-values can vary depending on the contingency table dimensions and the row and column margin totals. Candidate envelope models and indices to quantify this relationship are described is this section.
2.2.1. Candidate quantile models
The accuracy of the hypothesis tests is described herein by the 2.5% and 97.5% quantiles of the observed values. These quantiles represent the lower bounds (
) and upper bounds (
) of a 95% interval enclosed by the envelope model. Note the 0.0% and 100% quantiles were not used because these quantiles are numerically ill-defined and non-unique. For example, one numerical solution for the 100% quantile of observed
values is simply 1, which is not very descriptive of the upper bounds. It was also generally assumed that the
and
will tend to (e.g. asymptotically) converge to the ideal value (
) (e.g. 0.05) as the candidate indices tend towards a limiting value. This limiting value can be either infinity or zero, depending on the type of index. Therefore, the following empirical model forms were considered for the
,
, and median quantiles:
where ,
, and
are one or more candidate indices. The
in EquationEquation (1)
(1)
(1) are assumed polynomial powers for
. The
and
are unknown coefficients to be estimated by quantile regression (e.g. (Grinsted, Citation2008)). The
coefficient in EquationEquation (2)
(2)
(2) is either +1 or −1, and
and
are unknown coefficients to be estimated by quantile regression. The form of these equations guarantee that
for
and
if all
and
. These two models are equivalent if
,
, and all other
and
.
The polynomial model form in EquationEquation (1)(1)
(1) is well suited for fitting one or more indices simultaneously for assumed
values. The assumed values for
included [Citation1], [−0.5], [−1], [−1,-2], and [−1,-2,-3] depending on the test and candidate index. Higher degree polynomials can fit the data better than lower degree polynomials, but can result in overparameterized models, which is undesirable.
The logarithmic model form in EquationEquation (2)(2)
(2) is only applicable to a single index but can be used to estimate a scalar value for
. These models tend to be more parsimonious, which is desirable.
2.2.2. Candidate accuracy assessment indices
Four types of candidate indices based on the table dimensions and margin totals were considered to assess different potential effects on p-value accuracy. The first three types of indices have positive values that tend to increase for tables with larger margin totals or overall counts. The last type of index has a value between 0 and 1.
2.2.2.1. Candidate discreteness indices
The following indices were considered to represent effects of the discrete p-value distribution resulting from the whole number table counts (e.g. as depicted by the staircase shaped curve in Sub ):
The number of unique
tables with
and
marginal totals (
in this context denotes the cardinality of set
, and
is the set of all unique
C tables as defined in Appendix b.1) The rationale for this candidate index is that the distribution of sampled p-values depends on the maximum possible number of unique sampled p-values, which is less than or equal to
. An algorithm to calculate
given
,
, and the margin totals is in Appendix B.1. Other algorithms are described in (Diaconis & Gangolli, Citation1994; Gail & Mantel, Citation1977).
The number of unique nominal probabilities for
tables with
and
marginal totals. The rationale for this index is that the distribution of sampled nominal (e.g. the Fisher-Freeman-Halton exact test) p-values depends on
. An algorithm to calculate
given
,
, and the margin totals is in Appendix B.2. Note that
.
The number of unique ordinal probabilities for
tables with
and
marginal totals. The rationale for this index is that the distribution of sampled ordinal (e.g. the Goodman-Kruskal gamma test) p-values depends on
. An algorithm to calculate
is in Appendix B.3. Note that
.
2.2.2.2. Candidate approximation indices
The following indices were also considered for the Pearson chi-square and Goodman and Kruskal gamma tests to represent approximation accuracy and asymptotic standard error effects:
• The minimum expected cell count, which is . The rationale for this candidate index is that Fleiss [Fleiss, Citation1981, p. 25] and others have warned that the Pearson chi-square test may not be accurate if
is small, (e.g.
5, 10, or 20).
• The sum and the average of the smallest expected cell counts, which are
and
, where
is the
’th smallest expected cell count. The rationale for these indices is that they can account for multiple small expected cell counts in higher dimension tables. These indices are equal to
for
tables.
• The harmonic mean and the root harmonic mean of the expected cell counts, which are , and
. The rationale for these indices is that they can also account for multiple small expected cell counts.
Scaled and offset versions of the candidate expected cell count indices () were also considered (i.e.
). The offset
was considered to avoid small numerical values which, when inverted by a negative
power in EquationEquation (1)
(1)
(1) , become very large and can adversely affect the overall model fit. Scaling factors
and
were considered to address potential effects of different contingency table dimensions.
The scaling factor was also considered to potentially normalize the effects of different table dimensions on the Pearson chi-square p-values. This scaling factor and values are described in Appendix D.1.
2.2.2.3. Candidate sample size indices
The total table count was also considered for the Pearson chi-square and Goodman and Kruskal gamma test envelope models. The rationale is that
appears in the gamma test based on
but not the original test based on
(see Equations D.3 and D.8). Therefore, the difference between the two gamma test p-values goes to zero if
. The scaled indices
,
,
, and
were also considered to address potential effects of different contingency table dimensions. Koehler and Larntz (Koehler & Larntz, Citation1980) also investigated the effects of sample size (
) and the number of cells (
) on the accuracy of the Pearson chi-square approximation.
2.2.2.4. Candidate P-value range indices
The minimum and maximum possible p-values for a given test and row and column margin totals may also be related to the domain-of-validity and the accuracy of the hypothesis test p-values. These indices are denoted by and
. They can be calculated by the algorithms in Appendix B to calculate
and
.
In general tends to approach 0 and
tends to approach 1, for tables with large numerical values. There are two special cases for the Fisher-Freeman-Halton exact test:
• because the p-value for a given table is defined as the sum of the probabilities for all of the tables with the same
and
that are as extreme or more extreme as the given table [Fleiss, Citation1981, p. 25] and [MathWorks, Citation2016, p. 25–1564]. There will always be at least one extreme table for which this sum includes all of the possible tables.
• if
because the sum of the probabilities for the only unique probability is 1.0.Footnote5
This leads to the following proposed p-value domain-of-validity criterion:
If the critical p-value (e.g. 0.05) is less than or greater than
then the row and column margin totals are outside the test p-value domain-of-validity for the critical p-value.
This criterion would be in addition to other possible test accuracy criteria to be identified.
The indices were not considered for the candidate envelope models.
2.2.3. Quantile regression method
Quantile regressions were accomplished using the quantreg3.m function (see the Supplementary Online Material). This function finds the value for that minimizes fval, defined as
where ,
is a
matrix of
observed dependent variable values (e.g.
),
is a corresponding
matrix of
corresponding independent variable values (e.g.
),
is an estimate of
, and
is the desired quantile (e.g. 0.025 or 0.975), and
is an output transformation (e.g.
). The quantreg3 function is based on Grinsted’s quantreg.m function (Grinsted, Citation2008) with the following extensions:
(1) optional input to provide an initial guess for the estimated values (
), otherwise it is assumed that
.
(2) optional input to provide an output transformation function , otherwise it is assumed that
.
(3) optional output to return the fval value calculated by the fminsearch.m function.
The average difference between the observed and modeled quantile () was then calculated by dividing fval by the number of observations in the regression for candidate model comparison purposes.
The initial guesses for the and
models were
where ,
is an
identity matrix, and
is a
matrix of zeroes. The
additional rows in EquationEquation (4)
(4)
(4) helps to prevent large
values if
is ill-conditioned. The initial guess for the median model was the average of the estimated
values for the
and
models.
In some cases, the quantile regression did not converge within the default number of iterations, possibly due to overparameterization. If this occurred then submodels with one or more dropped terms were evaluated, and the submodel yielding in the minimum fmin value was selected. In this case the estimated values for the missing terms were set to 0. As a final step, the quantile regression with all of the candidate terms was reattempted using the best estimated submodel as an initial guess. This was accomplished by the quantreg_s3.m function, which calls the quantreg3.m function (which was in turn based on Grinsted’s quantreg.m function (Grinsted, Citation2008)).
The 95% confidence intervals for the estimated model coefficients were estimated using the jackknife method described by Kahane [Kahane, Citation2012, pp. 64–66]. This involved classifying the observations into (e.g. 14) groups (
) based on the
table dimensions and whether or not
was even or odd. The quantile regression model coefficients were then re-estimated by removing the data for one group
at a time (i.e.
). Pseudo estimates of the model coefficients (
) were then determined based on
. The 95% confidence intervals were then estimated based on variation in
. The rationale for the jackknife grouping is to address potential table dimension sampling effects, and potential effects of “even-size samples” mentioned in [Goodman and Kruskal, Citation1979, p. 363].
3. Results
Single index trends and envelope model search results for the 5th percentile Fisher-Freeman-Halton exact, Pearson chi-square, and Goodman-Kruskal gamma test p-values are presented in separate subsections.
3.1. Fifth percentile Fisher-Freeman-Halton exact test P-values
3.1.1. Single Index Trends
The results in compare the 5th percentile p-values from the Monte Carlo simulations of the Fisher and Fisher-Freeman-Halton exact tests to ,
, and
respectively. The results for four different
table dimensions are depicted by different symbol types as indicated in the legend. The number of observed
values for each table dimension are also indicated in the legend. The total number of
observations in each figure is 14,154,495 .Footnote6 Each of the
observations is based on the p-values from 100,000 randomly sampled tables. Therefore, the results in these figures are based on 1,415,449,500,000 randomly sampled tables. The horizontal dotted lines indicate
, 1, and 2 times the ideal 5th percentile p-value value (0.05) for reference purposes. Sub also includes a reference curve for
, which represents a theoretical maximum deviation from the ideal p-value assuming that the
possible unique p-values are equally spaced.
Figure 2. Fifth percentile Fisher-Freeman-Halton p-values versus ,
, and
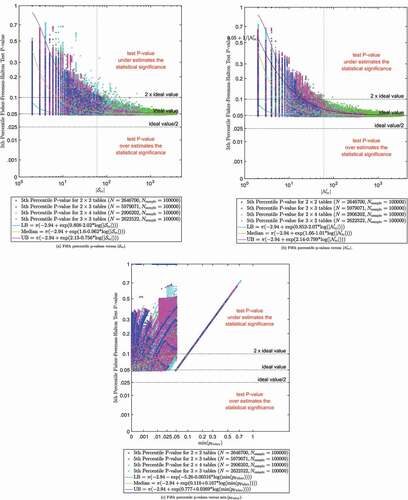
This figure shows that all of the 5th percentile p-values are greater than or equal to 0.05. This indicates that the Fisher-Freeman-Halton exact test tends to be conservative, a result which has been observed by others (e.g. [Agresti, Citation2002, pp. 93–94]).
The vertical dotted lines indicate the index values for all tables with row margins = [39,11] and column margins = [35,9,6] (e.g. ). These subfigures indicate that
tends to be between 0.05 and 0.10 for these index values, which is desirable from a test accuracy viewpoint.Footnote7
also shows estimated curves for the candidate , median, and
models based on EquationEquation (2)
(2)
(2) . The equations for the curves are also indicated in the legend. The models were fit to 13,696,372 observed
values for
tables with
. The other 458,123 observations with
were excluded because they were outside the 0.05 p-value domain-of-validity for the Fisher-Freeman-Halton exact test. The excluded observations included 475
values for
tables with
.
These subfigures indicate the observed values tend to converge towards the ideal 5th percentile p-value as
or
increases. This result was anticipated based on the example results in Sub , which indicated that the deviation in the observed p-values from the ideal p-values tends to be inversely proportional to the number of possible unique test p-values. The estimated
curve in Sub tends to follow the theoretical
curve, allowing for differences due to the assumed logistic form of the
model and variation in unique probability spacing. The range of data and the estimated
curve indicates that the lower bounds for
are approximately equal to the ideal 5th percentile p-value, which is expected for the exact tests. This result was also anticipated based on Sub , which showed that the observed p-values were greater than or equal to the ideal p-values.
Sub is similar to Sub with the following exceptions. The candidate index is . The horizontal axis scale has been transformed to correspond to the vertical axis because they are both probabilities. Sub shows a large number of observations with
, and therefore outside the test 0.05 p-value domain-of-validity. The observations outside the 0.05 p-value domain-of-validity were not used to fit the candidate envelope models.
Results for the candidate single index models are summarized in Table C.1 in Appendix C. The results are rank ordered from the smallest (most desirable) combined value to the largest. These results indicate that the single index model based on
has the best fit, with
−0.799
0.357 for the
curve.
3.1.2. Envelope model search results
Envelope models based on EquationEquation (1)(1)
(1) with one or two indices were also investigated. The candidate
for the candidate
and
indices included [−0.75] and [−0.8] based on the estimated
results in Table C.1, plus [−0.5], [−1], [−1,-2], and [−1,-2,-3]. It was assumed that
for the candidate
index because the model envelope was assumed to converge to the ideal value if
. The candidate model indices and the resulting
figure-of-merit values are summarized in Table C.2. The tabulated results are rank ordered from the smallest (most desirable) combined
value to the largest.
These results, like Table C.1, indicate that envelope models based on tend to fit the range of observed 5th percentile Fisher-Freeman-Halton p-values better than corresponding models based on
. This was expected because the magnitude of the discrete staircase effect indicated in is more closely related to the number of unique nominal probabilities than the number of unique tables.
The results in Table C.2 indicate that the candidate envelope model based on with
and
has the best overall fit to the observed
values with a combined
0.000712 figure-of-merit. However, only one of the four estimated
model coefficients was statistically significant at the 0.05 level. Therefore, the model with four coefficients may be overparameterized. We would expect the coefficients for the
model to be small and statistically significant because the lower bounds for the exact test should be approximately equal to the expected p-value.
The candidate envelope model with the smallest combined and all statistically significant
model coefficients is based on
with
and
. The estimated coefficients for this model are listed in Table D.2. The combined
figure-of-merit for this model is 0.000745, a 5% increase compared to the best overall fit in Table C.2. However, the estimated coefficient for
in the
model is negative. This result indicates that the upper bounds for
tends to increase as
, which is counterintuitive. These results appear to be associated with
tables that have small
values and large 5th percentile p-values. This can occur, for a given set of row and column margin totals, if there is a
table with Fisher-Freeman-Halton p-value near the critical p-value and the next larger p-value is much larger than the critical p-value, typically due to a tie or near tie. For example, given the set of
tables with
and
,
and the 5th percentile p-value is 0.164648 (see Figure D.1). This is because the p-value for the table with [1,3,7; 1,5,58] cell counts is 0.049238, which is slightly less than 0.05, and the next largest p-values are 0.164648 for tables with [1,2,8; 1,6,57] and [0,3,8; 2,5,57] cell counts.
If the term is dropped, then the envelope model with the next smallest combined
is based on
with
. The estimated coefficients for this model are listed in , and the estimated
coefficient for the
term is statistically significant. The combined
figure-of-merit for this envelope model is 0.000753, which is a 1% increase compared to the aforementioned model with the
term. The
term for the
model is small and not statistically significant, as would be expected for an exact test.
Table 5. Fifth percentile Fisher-Freeman-Halton p-value envelope model fit to
According to the estimated model coefficients in the 95% interval for would exceed 0.10 if
.Footnote8 Therefore, a possible p-value accuracy criterion for the Fisher-Freeman-Halton exact test is
.
3.2. Fifth percentile Pearson Chi-square test P-values
3.2.1. Single index trends
The results in compare the 5th percentile p-values from the Monte Carlo simulations of the Pearson chi-square test to ,
,
, and
respectively. The format of this figure is similar to . The results for seven different
table dimensions are depicted by different symbol types as indicated in the legend. The total number of
observations in each figure is 24,578,997 . These observations are based on 2,457,899,700,000 randomly sampled tables.
Figure 3. Fifth percentile Pearson p-values versus ,
,
, and
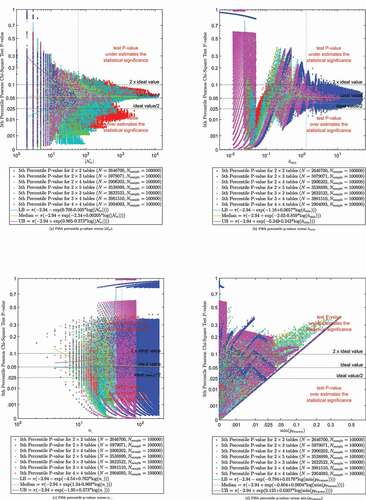
The results in Sub indicate that the observed values tend to converge towards the ideal 5th percentile p-value as
or
increases, but not when
increases. The converging
results in Sub are somewhat consistent with traditional criteria that the expected cell counts should be greater than some minimum value (e.g. 5, 10, or 20). The results in Sub also show that small
values are undesirable, which was also expected based on the results in Sub and similar results in Sub for the Fisher-Freeman-Halton test. The lack of convergence for
in Sub may be attributed to small
or
values.
The results in Sub show that the Pearson chi-square test p-values are outside the test p-value domain-of-validity if is greater than the ideal value (e.g. 0.05). Therefore 46,578 observations with
were excluded from the envelope model quantile regression analysis.
The results in Sub also indicate an abrupt change near . This change was further explored in Figure D.5, which shows that the differences between the 5th percentile Pearson and Fisher-Freeman-Halton p-values tends to peak near
. Therefore, all of the observations with
were also excluded from the quantile regression analysis of the Pearson chi-square test p-values because these observations were also expected a priori to be outside the Pearson domain-of-validity and could adversely affect the overall fit to the assumed candidate model form. The estimated models for the Pearson chi-square test p-value envelope are therefore based on a fit to the remaining 10,249,393 observations, as depicted in Figure D.6. The results SubFigure D.6a more clearly shows the convergence to the ideal p-value as
increases.
and D.6 also show the estimated curves for the candidate , median, and
models based on EquationEquation (2)
(2)
(2) . The estimated
and
figure-of-merit values for these and other candidate single index models are summarized in Table C.3.
3.2.2. Envelope model search results
The convergence of the observed Pearson chi-square test values towards the ideal 5th percentile p-value as
or
increases indicates the need to determine the independent effects of discreteness and approximation on the accuracy of the test. This was accomplished by considering envelope models based on EquationEquation (1)
(1)
(1) with up to four candidate indices to address different effects. The assumed candidate powers for the candidate indices based on
or
,
, and
where
and
. The rationale for these negative powers is that the range of observed
values is assumed to converge to the ideal 5th percentile p-value as these indices increase towards infinity, and the −0.5 and −1.0 values represent the range of
results in Table C.3. The assumed candidate power for the candidate
index was
.
The candidate model indices and the resulting figure-of-merit values for the Pearson chi-square test are summarized in Table C.4. The results are rank ordered from the smallest (most desirable) combined
value to the largest. These results indicate that the model with
,
,
, and
had the smallest combined
. However, the estimated
and
model coefficients for the
and
terms were not statistically significant; the term based on
was not consistent in the top ranked models; and the
term did not improve the fit very much. This suggests that these three-term and four-term models may be overparameterized, which is undesirable. Dropping the terms based on
and
from the model search increases the combined
slightly from
to
. The estimated model coefficients for this top ranked one-term or two-term model are listed in .
Table 6. Fifth percentile Pearson p-value envelope model fit to and
Note that the estimated model coefficient for the
term in has a small positive value that is not statistically significant. A positive value indicates that the lower bounds tends to increase for small
values, which is counter intuitive. If a negative sign constraint is imposed on the
model coefficients then the
term drops out, the
coefficient for the
model changes from
to
, and
increases slightly from
to
. This result appears to be consistent with the results in Figure D.6, which indicate that
has a stronger effect on the convergence then
for
. Dropping the
term from the
model is not recommended because
increases substantially from 0.000741 to 0.001110 as indicated in Table C.4.
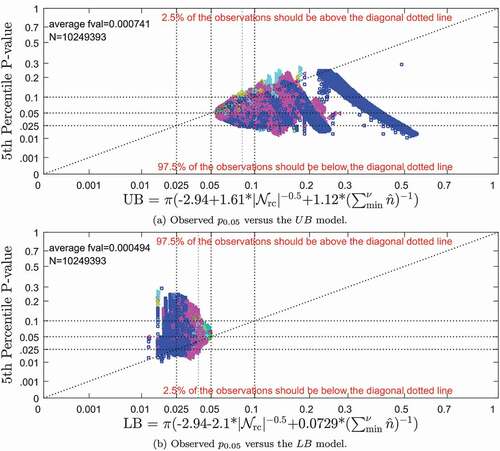
Scatter plots of the 5th percentile Pearson p-values versus the and
models based on
and
are depicted in . The diagonal dotted lines indicate the p-values corresponding to the
and
models. Therefore, 2.5% of the observed
values in Sub should be above the diagonal line, and 2.5% of the
values in Sub should be below the diagonal line. The horizontal and vertical dotted lines indicate
, 1, and 2 times the ideal 5th percentile p-value for reference purposes.
Figure 4. Fifth percentile Pearson p-values versus functions of and
depicts contours of the estimated lower and upper bound models for the 5th percentile Pearson p-value versus and
. The lower bounds is depicted in Sub . The small
symbols are a locus of points that satisfy
and the adjacent shaded region depicted by the
symbols indicates where
. The asymptotic values for the
contour are
when
, and
undefined when
because the model coefficient is non-negative. If the
term is removed from this
model then the
contour is simply
7.690 . The
and
symbols indicate the relative distributions of observed
values
and
. The upper bounds is depicted in Sub in a similar manner. The small
symbols are a locus of points that satisfy
and the shaded region indicates where
. The asymptotic values for the
contour are
and
when the other index goes to infinity. These results indicate that
tends to be between 0.025 and 0.10, which is desirable, if the
and
coordinate is in the unshaded region of both subfigures. The
criterion when
is consistent with Cochran’s statement that “there is little disturbance to the 5% level when a single expectation is as low as
” [Cochran, Citation1952, p. 329].
Figure 5. Fifth percentile Pearson p-value envelope model contours
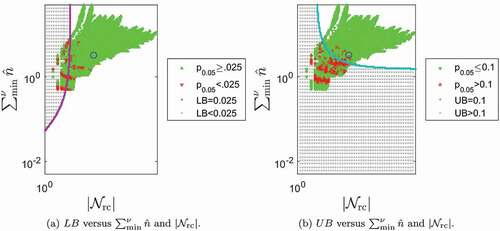
The symbol in indicates the coordinates for
tables with
and
(e.g. ). This symbol is located in the unshaded region of both subfigures. This indicates the 5th percentile p-values for randomly sampled tables with these margin totals tend to be between 0.025 and 0.10, which is desirable from a test accuracy viewpoint.
The same and
models can also be applied to more stringent limits such as 0.04 to 0.06. The value for the
contour would be
72.9 if the
term is dropped. The asymptotic values for the
contour would be
and
when the other index goes to infinity. This more stringent
criteria is within the range of the
5 or 10 criterion recommended by others.
3.3. Fifth percentile Goodman-Kruskal gamma test P-values
3.3.1. Single Index trends
The results in compare the 5th percentile p-values from the Monte Carlo simulations of the Goodman–Kruskal Gamma test based on to
,
,
, and
respectively. The format of this figure is also similar to . The total number of
observations was 24,578,997.
Figure 6. Fifth percentile Goodman-Kruskal p-values (based on ASE0) versus,
,
,
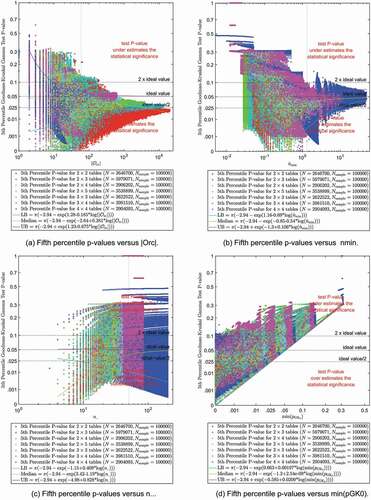
Like the results for the Pearson chi-square test, the results in Sub for the Goodman-Kruskal gamma test indicate that the observed values tend to converge towards the ideal 5th percentile p-value as
increases, but not when
increases. The results in Sub indicate that the observed
values appear to converge to values less than the ideal 5th percentile p-value as
increases, indicating possible liberal bias.
The results in Sub show that the Goodman-Kruskal gamma test p-values are outside the test p-value domain-of-validity if is greater than the ideal value (e.g. 0.05). Therefore 152,072 observations with
were excluded from the envelope model quantile regression analysis.
In addition, it was observed in Figure D.4 that the differences between the 5th percentile p-values from two different versions of the Goodman-Kruskal gamma test are the largest when is about 0.5. This result is similar to, but more pronounced than, the differences between the Fisher-Freeman-Halton and Pearson
values observed in Figure D.5. Therefore, all of the observations with
were excluded from the quantile regression analysis of the Goodman-Kruskal gamma test p-values because they could adversely affect the overall fit to the assumed candidate model form. The estimated models for the Goodman-Kruskal gamma test p-value envelope are therefore based on a fit to the remaining 10,143,899 observations with
, as depicted in Figure D.7. The results in SubFigure D.7a also more clearly shows convergence, but not to the ideal p-value, as
increases.
3.3.2. Envelope model search results
Like the Pearson chi-square test, the convergence of the observed Goodman-Kruskal gamma test values as
or
increases also indicates the need to elucidate the independent effects of discreteness and approximation on the accuracy of the test. This was also accomplished by considering envelope models based on EquationEquation (1)
(1)
(1) with up to four candidate indices. The assumed candidate
were the same as for the Pearson chi-square test envelope models, based on similar rationale.
The candidate model indices and the resulting figure-of-merit values for the Goodman-Kruskal gamma test are summarized in Table C.6. The results in this table are also rank ordered from the smallest (most desirable) combined
value to the largest. These results indicate that of the candidate model with
,
,
, and
had the smallest combined
. However, the top ranked model with only three indices fits almost as well. This model drops the
index and the combined
value increases slightly from 0.000537 to 0.000547 . The estimated model coefficients for this envelope model are listed in ().Footnote9
Table 7. Fifth percentile Goodman-Kruskal () p-value envelope model fit to
,
, and
Scatter plots of the 5th percentile Goodman-Kruskal p-values (based on ) versus the
and
models in are depicted in . The format and interpretation of these plots are similar to
Figure 7. Fifth percentile Goodman-Kruskal p-values (based on ASE0) versus ,
, and
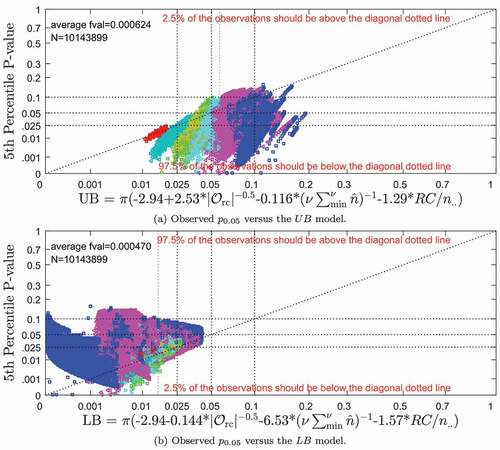
. Fifth percentile Goodman-Kruskal p-values (based on ) versus functions of
,
, and
.
Contours of the estimated lower and upper bound models for the 5th percentile Goodman-Kruskal p-value versus ,
, and
are depicted in Figure D.8 in Appendix D. These plots graphically illustrate that
tends to be between 0.025 and 0.10, which is desirable, if the
,
, and
coordinate is in the unshaded region of all of the subfigures. The
symbols, which represent the indices for the example in , are outside this desired (i.e. unshaded) region. This could explain the anomalous Goodman-Kruskal gamma test result listed in .
4. Limitations
The results herein are based on Monte Carlo analysis of contingency tables within the simulation domain listed in . It is assumed that the results for tables with
are equivalent to results for tables with
due to the symmetry of the hypothesis tests. It is also assumed that the
tables are randomly sampled with fixed row and column margin totals. The observed 5th percentile p-value for each row and column margin total combination is based a random sample of 100,000 tables. The p-value accuracy results are limited to tables with row and column margin totals within the p-value domain-of-validity. The results for the Fisher-Freeman-Halton exact test envelope models are also limited to tables with
; and the Pearson chi-square test and Goodman-Kruskal gamma test envelope models are limited to tables with
. The estimated envelope models are based on the assumption that all of the 5th percentile p-values for each set of fixed row and column margin totals within the simulation domain are equally weighted. The results are based on a critical test p-value of 0.05, but the methodology and results could be extended to other critical p-values.
5. Recommendations
The following criteria to determine whether or not a hypothesis test should be used for a given contingency table are recommended based on the results in the previous section. These criteria comprise two parts and are based on the table dimensions and margin totals.
First, the critical p-value must be within the p-value domain-of-validity of the hypothesis test. This can be evaluated by calculating the minimum possible hypothesis test p-value using the most extreme table with the same row and column margin totals. If the minimum possible p-value is greater than or equal to the critical p-value then the test is not reliable and should not be used. It is assumed that the maximum possible p-value is always greater than the critical p-value and does not need to be evaluated.
If the p-value domain-of-validity criterion is met, then the p-value accuracy criteria is evaluated. Ideally the ’th percentile p-value for a hypothesis test would be
/100% if the null hypothesis is true. We propose that the lower and upper bounds for the percentile p-value corresponding to the critical p-value should be within a factor of two of the critical p-value. For example, if the critical p-value is 0.05, then the
and
for the 5th percentile p-value should be between 0.025 and 0.10.Footnote10 If not then the test p-value may be inaccurate (i.e. either too liberal or too conservative) and unreliable. This involves calculating the
and
values using EquationEquation (1)
(1)
(1) . Indices and estimated coefficients for the Fisher-Freeman-Halton exact test for tables up to
and
are provided in for the 5th percentile p-value. Indices and estimated coefficients for the Pearson chi-square test and the
version of the Goodman-Kruskal gamma test for tables up to
and
are provided in for the 5th percentile p-value, provided that
.Footnote11 Example envelope model calculations are in Appendix E. R run scripts to evaluate the recommended criteria are also provided in the supplemental material (see Appendix G).
5.1. Fisher-Freeman-Halton exact test accuracy criteria
The p-value accuracy criterion for the Fisher-Freeman-Halton test with a critical p-value of 0.05 is satisfied if . The
value can be calculated by the algorithm in Appendix B.2.
5.2. Pearson Chi-Square test accuracy criteria
The p-value accuracy criteria for the Pearson chi-square test depend on both and
. This criteria can be graphically evaluated by referring to . If the
versus
coordinate is in one or both of shaded regions in then the test p-value may be either too liberal or too conservative. If the coordinate is in the unshaded region of both subfigures then the recommended criteria for the Pearson chi-square test are satisfied.
The p-value accuracy criteria for the Pearson chi-square test can also be numerically evaluated using EquationEquation (1)(1)
(1) and the model coefficients in . The
and
values should be within a factor of two of the ideal value (0.05). Otherwise the test could be too liberal if
or too conservative if
.
An example calculation for the 5th percentile Pearson chi-square test p-value envelope is in Table E.2. This example indicates that the 5th percentile p-value for randomly sampled tables with
and
is between 0.039402 and 0.083430 for 95% of the tables. This range is between 0.025 and 0.10, which is desirable from a test accuracy viewpoint.
5.3. Goodman–Kruskal Gamma test accuracy criteria
The p-value accuracy criteria for the Goodman-Kruskal gamma test depend on ,
, and
. This criteria require the calculation of
and
to determine if the range is within a factor of two of the ideal value (e.g. 0.05). The
and
values are calculated using EquationEquation (1)
(1)
(1) and the model coefficients in . The
value can be calculated by the algorithm in Appendix B.3.
An example calculation for the 5th percentile Goodman-Kruskal gamma test p-value envelope is in Table E.3. This example indicates that the 5th percentile p-value for randomly sampled tables with
and
is between 0.015660 and 0.057842 for 95% of the tables. This range is not within a factor of two of the ideal value (0.05), which is undesirable from a test accuracy viewpoint.
Therefore, these recommended criteria indicate that the example table listed in is within the domain-of-validity of the Fisher-Freeman-Halton exact test and the Pearson chi-square test, but not within domain-of-validity of the Goodman-Kruskal gamma test. This could explain the apparently inconsistent hypothesis test results listed in .
6. Conclusions
The domain-of-validity and accuracy of the Fisher-Freeman-Halton exact, Pearson chi-square, and Goodman-Kruskal gamma tests for small contingency tables were investigated. The Fisher-Freeman-Halton exact test and the Pearson chi-square test consider whether or not the frequencies in a contingency table have equal underlying proportions or independence. The Goodman-Kruskal gamma test considers whether or not a measure of association based on the frequencies in the table is statistically significant.
The investigation involved Monte Carlo simulations of randomly sampled contingency tables up to and
in which the row and column variables were independent (i.e. equal underlying proportions). One hundred thousand tables were randomly sampled from each set of fixed row and column margin totals, for all margin total sets up to a pre-determined maximum table total (e.g. 200 for
tables). P-values for each test were calculated for each sampled table, and the 5th percentile p-values were determined for each set of row and column margin totals.
It was observed that there were some sets of row and column margin totals for which the minimum possible p-value for a given hypothesis test was greater than likely critical p-values (e.g. 0.05). If this condition occurs than the table is outside the p-value domain-of-validity of the hypothesis test and the test should not be used.
Envelope models were then estimated using quantile regressions to describe the range of the 5th percentile p-values observed in the Monte Carlo simulations. Candidate indices related to the discreteness and approximation accuracy of the p-value distributions, the total table counts, and the minimum possible p-value were considered. The indices can be calculated from ,
, and the row and column margin totals using the equations and algorithms described herein. The 2.5% and 97.5% quantiles were used to describe the lower and upper bounds of the range in the 5th percentile p-values. Data outside the p-value domain-of-validity were not used for these regressions.
The results for the Fisher-Freeman-Halton exact test indicated that this test tends to be conservative (i.e. the 5th percentile p-value tends to be greater than 0.05), and that the p-value accuracy depends on the number of possible tables with unique nominal probabilities (
). The lower bounds is approximately equal to the ideal 5th percentile p-value provided that
. The upper bounds is within a factor of two of the ideal 5th percentile p-value if
.
The results for the Pearson chi-square test indicated that this test tends to be unbiased (i.e. the median 5th percentile p-value tends to be about 0.05), and that the p-value accuracy depends on and the sum of the
smallest expected cell counts (
), where
is the number of degrees-of-freedom for the chi-square statistic. Equations and model coefficients are provided in to estimate the range of 5th percentile chi-square test p-values based on
,
, and the row and column margin totals. The values for
and
for which the lower and upper bounds for the 5th percentile p-values are within 0.025 and 0.10 are graphically depicted in .
The results for the Goodman-Kruskal gamma test indicated that the p-value accuracy depends on the number of possible tables with unique ordinal probabilities (
),
, and
. Equations and model coefficients are provided in to estimate the range of 5th percentile gamma test p-values based on
,
, and the row and column margin totals.
We propose that the lower and upper bounds for the percentile p-value corresponding to the critical p-value should be within a factor of two of the critical p-value. Therefore, if the critical p-value is 0.05, then the and
for the 5th percentile p-value should be between 0.025 and 0.10. The accuracy of the 5th percentile Fisher-Freeman-Halton p-value is with this range if
. Other levels of p-value accuracy can also be specified, such as between 0.04 and 0.06. The accuracy criteria for the Pearson chi-square test depends on
and
, and the Goodman-Kruskal gamma test depends on
,
, and
.
An example application of the proposed criteria to a contingency table was also given. These criteria indicated that the example
table is within the domain-of-validity of two of the three hypothesis tests investigated.
The criteria presented herein is specific to the 0.05 critical p-value. Criteria specific to other critical p-values (e.g. 0.01) or other hypothesis tests could also be determined using the methods described herein.
Supplemental Material
Download PDF (19.9 MB)Disclosure statement
No potential conflict of interest was reported by the authors.
Supplementary Material
Supplemental data for this article can be accessed here.
Additional information
Funding
Notes on contributors
R. M. Van Auken
R. M. Van Auken and S. A. Kebschull have been involved in various multi-disciplinary applied research projects primarily for the ground vehicle industry. Research activities involved modeling, simulation, testing, and analysis of human-vehicle-environmental systems; including vehicle dynamics, manual control, biomechanics, accident data analysis, and risk/benefit analysis. They have also been involved in regulation, testing and standards development. Some of these activities involved analysis of contingency tables using hypothesis tests such as the Fisher exact, Pearson chi-square, and Goodman-Kruskal gamma tests. The results of the research reported herein provided useful insight and understanding for suitability and interpretation of these hypothesis test results.
Notes
1. The results in this paper are specific to a critical p-value of 0.05 because this value is widely used. See [Box, Hunter, and Hunter, 1978, p. 109] and (Wasserstein & Lazar, Citation2016). Other critical p-values such as 0.01 have also been used. The methods used herein could be extended to these other critical p-values in the future.
2. Norušis states `[i]f you reject the null hypothesis that two variables are independent, you may want to describe the nature and strength of the relationship between the two variables’ [Norušis, 2008, p. 172]. This suggests that association is only meaningful if the null hypothesis for independence can be rejected.
3. In our notation and
.
4. See footnote 1.
5. This condition can occur in tables even for large
if one of the row margin totals is equal to 1 and the column margin totals are equal. For example, if
and
.
6. Many of the 14,154,495 symbols in Figure 2 mask other symbols due to the symbol size and drawing order. The symbols were drawn in random order in order to depict the relative distribution of the table dimensions. The absolute distribution of the observed p-values is not depicted because of masking.
7. The criteria for a desirable range of values is arbitrary but directly relates to test p-value accuracy. Cochran [Cochran, 1952, pp. 328–329] suggested a range between 0.04 and 0.06 for a critical p-value of 0.05. Cochran acknowledged that these `limits are, of course, arbitrary; some would be content with less conservative limits.’ We are using a range of 0.025 to 0.10, which corresponds to a relative factor of 2, and is less conservative then Cochran’s suggested limits.
8. If we use the estimated alternative model coefficients in Table D.2 then the 95% interval for the Fisher-Freeman-Halton test would exceed 0.10 if
and
.
9. The envelope model search results in Tables C.5 and C.6 indicate that models based on tend to fit the distribution of 5th percentile Goodman-Kruskal gamma test p-values almost as well as
. The
index requires less effort to calculate than
, which is desirable. Estimated coefficients for an alternative Goodman-Kruskal gamma test envelope model based on
are listed in Table D.3 in Appendix D.5.
10. Cochran [Cochran, 1952, pp.328–329] suggested a range between 0.04 and 0.06 for a critical p-value of 0.05, and a range between 0.007 and 0.015 for a critical p-value of 0.01. Cochran acknowledged that these `limits are, of course, arbitrary; some would be content with less conservative limits.’ Our proposed limits are also arbitrary and less conservative than Cochran’s limits.
11. We can reasonably assume that the Pearson chi-square and Goodman-Kruskal gamma tests are not valid if based on traditional criteria and extrapolation of the envelope models.
References
- Agresti, A. (1996). An introduction to categorical data analysis. John Wiley & Sons, Inc.
- Agresti, A. (2002). Categorical data analysis. John Wiley & Sons, Inc. http://mathdept.iut.ac.ir/sites/mathdept.iut.ac.ir/files/AGRESTI.PDF
- Box, G. E., Hunter, W. G., & Hunter, J. S. (1978). Statistics for experimenters, an introduction to design, data analysis, and model building. John Wiley & Sons.
- Brown, M. B., & Benedetti, J. K. (1977). Sampling behavior of tests for correlation in two-way contingency tables. Journal of the American Statistical Association, 72(358), 309–20. DOI: https://doi.org/10.1080/01621459.1977.10480995
- Cardillo, G. (2007a). Myfisher23: A very compact routine for fisher’s exact test on 2x3 matrix (version 2.0, updated 2018-05-04) [The mathworks, inc.]. https://www.mathworks.com/matlabcentral/fileexchange/15399-myfisher23
- Cardillo, G. (2007b). Myfisher24: A very compact routine for fisher’s exact test on 2x4 matrix (version 2.0, updated 2018-04-06) [The mathworks, inc.]. https://www.mathworks.com/matlabcentral/fileexchange/19842-myfisher24
- Cardillo, G. (2007c). Myfisher33: A very compact routine for fisher’s exact test on 3x3 matrix (version 2.0, updated 2018-04-06) [The mathworks, inc.]. https://www.mathworks.com/matlabcentral/fileexchange/15482-myfisher33
- Cochran, W. G. (1952). The χ2 test of goodness of fit. The Annals of Mathematical Statistics, 23(3), 315–345. https://doi.org/https://doi.org/10.1214/aoms/1177729380
- Cochran, W. G. (1954). Some methods for strengthening the common χ2 tests. Biometrics, 10(4), 417–451. https://doi.org/https://doi.org/10.2307/3001616
- Craddock, J. M., & Flood, C. R. (1970). The distribution of the χ2 statistic in small contingency tables. Journal of the Royal Statistical Society. Series C, Applied Statistics, 19(2), 173–181. https://rss.onlinelibrary.wiley.com/doi/abs/ https://doi.org/10.2307/2346547
- Cramer, H. (1946). Mathematical Methods of Statistics. Princeton University Press, Princeton.
- Diaconis, P., & Gangolli, A. (1994). Rectangular arrays with fixed margins (pp. 452). Department of Statistics, Stanford University. https://statistics.stanford.edu/sites/g/files/sbiybj6031/f/EFS%20NSF%20452.pdf
- Ehwerhemuepha, L., Sok, H., & Rakovski, C. (2019). A more powerful unconditional exact test of homogeneity for 2 × c contingency table analysis. Journal of Applied Statistics, 46(14), 2572–2582. https://doi.org/https://doi.org/10.1080/02664763.2019.1601689
- Ekstrøm CT. (2020). MESS: Miscellaneous esoteric statistical scripts. R package version 0.5.7. https://CRAN.R-project.org/package=MESS
- Electronics Reliability Subcommittee. (1987). Automotive electronics reliability handbook. Society of Automotive Engineers, Inc.
- Fisher, R. A. (1934). Statistical methods for research workers (5th ed.). Oliver and Boyd.
- Fleiss, J. L. (1981). Statistical methods for rates and proportions (2nd ed.). John Wiley & Sons.
- Freeman, G., & Halton, J. (1951). Note on an exact treatment of contingency, goodness of fit and other problems of significance. Biometrika, 38(1–2), 141–149. https://doi.org/https://doi.org/10.1093/biomet/38.1-2.141
- Gail, M., & Mantel, N. (1977). Counting the number of contingency tables with fixed margins. Journal of the American Statistical Association, 72(360a), 859–862. DOI: https://doi.org/10.1080/01621459.1977.10479971
- Göktaş, A., & İşçi, O. (2011). A comparison of the most commonly used measures of association for doubly ordered square contingency tables via simulation. Metodološki Zvezki, 8(1), 17–37. http://mrvar.fdv.uni-lj.si/pub/mz/mz8.1/goktas.pdf
- Good, I. J., Gover, T. N., and Michell, G. (1970). Exact distributions for X2 and the likelihood ratio statistic for the equiprobable multinomial distribution. Journal of the American Statistical Association, 65(1), 267.
- Goodman, L. A., & Kruskal, W. H. (1979). Measures of association for cross classifications. Springer-Verlag.
- Grinsted, A. (2008). quantreg: Quantile regression with bootstrapping confidence intervals (version 1.3.0.0) [The mathworks, inc.]. https://www.mathworks.com/matlabcentral/fileexchange/32115-quantreg-x-y-tau-order-nboot
- Kahane, C. (2012). Relationships between fatality risk, mass, and footprint in model year 2000–2007 passenger cars and LTVs - final report. National Highway Traffic Safety Administration. DOT HS 811 665 https://www.regulations.gov/document/NHTSA-2010-0152-0040
- Kendal, M. G. (1952). The Advanced Theory of Statistics (5th Ed. Vol. 1). Griffin, London
- Koehler, K. J., & Larntz, K. (1980). An empirical investigation of goodness-of-fit statistics for sparse multinomials. Journal of the American Statistical Association, 75(370), 336–344. https://doi.org/https://doi.org/10.1080/01621459.1980.10477473
- Kroese, D. P., & Chan, J. C. C. (2014). Statistical modeling and computation. Springer.
- MathWorks. (2016). Statistics and machine learning toolboxTM user’s guide.
- Mehta, C. R., & Patel, N. R. (1986). Algorithm 643: Fexact: A fortran subroutine for fisher’s exact test on unordered r × c contingency tables. ACM Transactions on Mathematical Software (TOMS), 12(2), 154–161. https://doi.org/https://doi.org/10.1145/6497.214326
- Norušis, M. J. (2008). SPSS 16.0 statistical procedures companion. Prentice Hall, Inc.
- Ott, R. L., Larson, R., Rexroat, C., and Mendenhall, W. (1992). Statistics, a tool for the social sciences. Duxbury Press.
- R Core Team. (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
- Rosenthal, I. (1966). Distribution of the sample version of the measure of association, gamma. Journal of the American Statistical Association, 61(314):440–453. https://doi.org/https://doi.org/10.1080/01621459.1966.10480880
- SAS. (2013). Base SAS® 9.4 procedures guide: Statistical procedures, second edition. SAS Institute Inc. http://support.sas.com/documentation/cdl/en/procstat/66703/PDF/default/procstat.pdf
- SPSS. (2009). PASW® statistics 18 command syntax reference.
- SPSS. (2010). IBM SPSS statistics 19 algorithms. Available from: http://www.sussex.ac.uk/its/pdfs/SPSS_Algorithms_19.pdf
- Tate, M. W., & Hyer, L. A. (1973). Inaccuracy of the x2 test of goodness of fit when expected frequencies are small. Journal of the American Statistical Association, 68(344), 836–841. DOI: https://doi.org/10.1080/01621459.1973.10481433
- Wasserstein, R. L., & Lazar, N. A. (2016). The asa’s statement on p-values: Context, process, and purpose. The American Statistician, 70(2), 440–453. https://doi.org/https://doi.org/10.1080/00031305.2016.1154108