
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Dependence of the linear discriminant analysis on location and scale weakens its performance when predicting class under the presence of homogeneous covariance matrices for the candidate classes. Further, outlying samples render the method to suffer from higher rates of misclassification. In this study, we propose the minimization approximation cost classification (MACC) method that accounts for some specific cost function . The theoretical derivation is made to find an optimal linear hyperplane
, which yields maximum separation between the dichotomous groups. Real-life data and simulations were used to validate the method against the standard classifiers. Results show that the proposed method is more efficient and outperforms the standard methods when the data are crowded at the class boundaries.
1. Introduction
The idea to optimize the cost function has been of interest since the second half of twentieth century (Gibra, Citation1967). For instance, engineers in a factory may need to control and optimize the total production cost of goods associated with high quantity and quality in a short time (Zavvar Sabegh et al., Citation2016). Minimizing the cost is important and has several applications. For example, in the health sector, the risk of misclassifying an infected person with a very contagious disease such as COVID-19 and influenza can be disastrous as many more people could get infected. Researchers in health science may need to minimize the cost of misclassifying patients, especially as they allocate them to wards so as to minimize the undesired outcomes.
Models have been used in medicine and engineering to predict the class membership such as multilevel logistic model (Dey & Raheem, Citation2016). However, classification when data are crowded around the separable hyperplane still remains a major statistical research problem. The popularly used standard linear discriminant analysis as well as the quadratic discriminant analysis are often characterized with high misclassification rates(Young, D. M.,Raudys,Citation2004). The dependence of these methods on location and covariance weakens their class prediction performance under the assumption of homogeneity of the covariance matrix.
Besides, presence of outlying samples may also render these methods amenable to high misclassification rates. Therefore, the major contribution of our study was to develop suitable cost function that can be used in the classification problem so as to minimize misclassification rates.
1.1. Defining the classification problem
The multivariate classification problem involves grouping the features in
space to one of the group membership
. The general form of linear classification function for the binary outcomes
where
and
The linear discriminant analysis (LDA), sometimes called the Fisher’s approach, is the most basic linear classifier. As indicated in other studies, this method does not require to satisfy the normality assumption (Liong & Foo, Citation2013; Tillmanns & Krafft, Citation2017). Its main assumption is homogeneity of the group covariance matrices, as is the case for the two-group classification (Puntanen, Citation2013). The general idea of the LDA is to construct a linear hyperplane so as to separate the two groups as much as possible. Suppose we have a random variable
from one of the two groups
with
and
, where
is any multivariate distribution, which is not necessarily the normal distribution. We wish to classify each data vector
of size
to the binary group membership
where the number of groups
. The overall covariance matrix is indicated by:
such that
, where:
and
where: and
are the between and within class covariance matrices. The data vector
in the
with
being its true mean vector for the
class, while
is the overall true mean vector.
The theoretical mechanism of finding the optimal linear separable hyperplane is estimating the parameter that maximizes data variation between the classes and minimizes the variations within each class. In other words, it is equivalent to maximizing the standardized squared distance from their centroids:
where is the transformed data vector that belongs to the
classes. The parameter for the linear hyperplane is
while
is the variance for the transformed values of
and
is the pooled covariance matrix of
Consequently, the middle part of the expression in EquationEquation [1](1)
(1) can be shown to be equivalent to the right hand part, by assuming that the parent populations have different population means but equal variances. Thereby, one unbiased estimator of population variance
is the combined variance:
, where
,
are the sample variances for the transformed values of class 1 and class 2 respectively.
The idea of Fisher’s approach in binary classification is to find a vector () that maximizes the standardized squared distance between the two centroid groups. The algebraic representation for this idea is in the following maximization problem:
where, is the standard deviation for all N data vectors. By having sufficient samples
from both population groups
, it can be assumed that our populations are normally distributed. Hence, the maximum likelihood estimators for the overall mean vector
and
, that is,
and
respectively, can be used. By using these estimators,
and
, we can show the following:
The right hand side of the last inequality is the Fisher-Roa’s Criterion, where is the between-class sample covariance matrix,
is the total-class sample covariance matrix and
is the within-class sample covariance matrix, and all these estimates are the maximum likelihood estimators. Hence, maximizing the standardized squared distance between groups involves minimizing the within group-sample covariance matrices.
The lemma by Johnson and Wichern (Puntanen, Citation2013) who used the extended Cauchy-Schwarz inequality for optimization was adopted in our search for an optimal estimate of in EquationEquation (1)
(1)
(1) .
Lemma 1.1. Let be a symmetric positive definite matrix and
be a given vector. Then for any arbitrary nonzero vector
,
attained at for any scalar
.
After matching the vector with the right hand side of EquationEquation (1)
(1)
(1) , we found that
and
. Taking into account a normalized vector x gives c = 1.
The new version of this estimated hyperplane resulted by an iterative method that tries to minimize the covariance within each group . We used the cost function
to minimize the data points from their corresponding centroids and consequently minimized the denominator containing
.
1.2. A motivating example
The search for another method that minimizes the misclassification between groups has been motivated by a number of studies (Croux & Joossens, Citation2005; Shen et al., Citation2011; Velilla & Hernndez, Citation2005; Zhang, Citation2004). Further motivation was from our exploratory analysis of simulation results from different distributions of data that revealed the effect of dispersion on the MCR. It was observed that as more data concentrate around boundary (separable hyperplane), their separation becomes very difficult as seen in . There are many data points close to the linear separable hyperplane such as the points; 10, 17, 34 and 56 from the squares group, which are highly likely to be misclassified. In other words, the risk of losing the information in estimating the optimal hyperplane is expected to be higher for the points around the hyperplane than the other points in the same group, where (Mengyi et al., Citation2012).
Figure 1. Distribution of simulated binary-class data to demonstrate the misclassification problem.
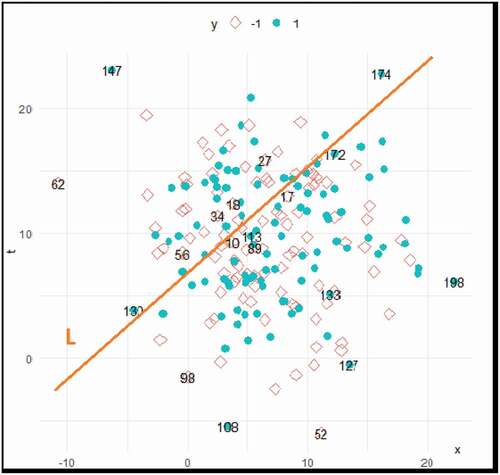
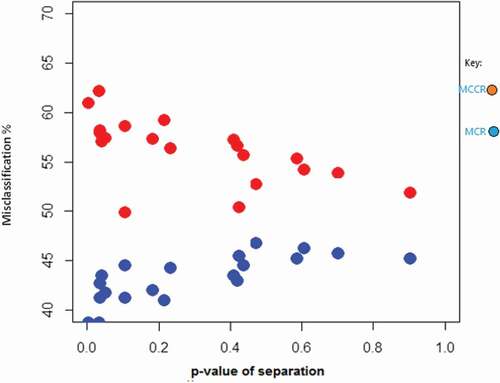
Figure 2. Relationship between p-value separation and misclassification.
Moreover, among the circular points, there are also data points such as 113,172 and 174 which are highly likely to be misclassified. It is logical, therefore, that fixing the same cost of misclassification for all data points is unfair. This leads to our idea that introducing a suitable cost function using the MM-principle(Mairal, Citation2013; Shen et al., Citation2011; Wang & Zou, Citation2018) would vary the cost for each data value according to how far this data point locates from the class mean vector. Hence, we will refer to the misclassification rate for the new method as minimal cost classification rate (MCCR), while the new method will be referred to as approximation minimization cost classifier (AMCC).
Thus, the aim of our study was to develop an optimal separable linear hyperplane using the MM-principle with cost function (discussed in section 2) that minimizes the rate of misclassification MCR. Also, in the next section we show how the algorithm to obtain the updated separable hyperplane that depends on the current one was derived. In section 3, we validate the proposed method by simulating some datasets and comparing them with the classical approaches in terms of misclassification rate. Further, real life datasets were used to further assess the proposed method by utilizing various train-test methods such as; SLDA, BSM, LOOCV and KFCV. All these train-test techniques are discussed in details in section 4. Ultimately, simulated dataset were used to discover the asymptotic behaviour of the proposed method and MCCR comparison to the MCR of SLDA.
2. Methodology
2.1. Developing the MACC based on the loss function
To achieve the study objectives, we applied a loss function to map values of one or more observed variables onto a real number representing some “cost” associated with the training item in the data (Shen et al., Citation2011). The total information lost can be represented by the cost function. In fact, the history of minimizing the MCR by using the loss function is a motivation to many researchers, for example, those who have worked to obtain optimum estimators of precision matrix under quadratic loss function (Mengyi et al., Citation2012). Cost may be taken as the average of the losses. We explored a quadratic loss function represented by
where
is the expected value of
. It measures how much information is lost between the observed and its predicted value for each data item. A specific form of this cost function is the mean square error abbreviated by MSE.
where the is the corresponding expected value of
. In this study we used the quadratic loss function. Therefore, for the linear discriminant analysis (LDA), our cost function is:
: the transformed value of the vector item
in the
group.
: the transformed value of the mean vector of the
group.
The reason for choosing quadratic cost function was for its ease to show that the total cost for both groups in terms of hyperplane can be written as:
. Therefore, minimizing the total cost requires minimizing the within-class variance for both groups by choosing the optimal value of
. Thus, this mechanism is similar to the approach of the Fisher-Roa’s Criterion which attempts to project the data points towards the centres of the groups, especially when many data points are concentrated around the marginal boundaries (Ahn & Marron, Citation2010). In some studies this process is called the data piling method which is projecting the high-dimensional data
into the low dimension leading to maximizing the marginal distance between groups and projecting the data values that are concentrated on the boundaries towards the centres of groups. On the other hand, our proposed method tries to vary the cost needed to minimize based on the location of the data points from their class centres. The main difference is that in data piling, a kernel trick is used, whereas in our method we use the cost function. Therefore, our method works in parallel with classifiers, making it easy to validate against the classical methods of classification.
2.2. Overview of the Proposed MACC Method
We applied the majorization-minimization (MM) principle to find an expression that solves the iteratively updated separable hyperplane in terms of the current solution
such that
. After some iterations, the updated
gives an optimum such that the total cost
is at minimum. One limitation is how to obtain an optimum single closed form of
from the direct differentiation of the cost function
. However, a mechanism of direct differentiation does not always lead to a closed form of
neither does it produce right desired solution. It can be shown that expressing cost function (7) in terms of
and differentiating partially yields
which is logically impossible. Generally, the MM-principle operates in two steps. The first step searches for the majorization function
such that
for any
The second step involves differentiating the
with respect to
and setting it to
and iteratively finding an expression that involves
and
(Lange & TongWu, Citation2008; Wang & Zou, Citation2018). In fact, based on Fisher’s approach (Shin, Citation2008),
takes the form of
for
predictors. Finding the convex supremum majorization function
for any
is quite difficult. By doing some manipulation using this principle, it can be called approximation-minimization principle. This can be reached algebraically using quadratic convex approximated function of the cost function (3), such that for any
, the function:
where is the cost function and
is the corresponding value of the linear classification function with unknown parameter
. Note that the right hand side of this inequality is approximated by the Taylor series approximation (Wu et al., Citation2019). In addition,
is the current solution and
is the updated solution (Mairal, Citation2013; Wang & Zou, Citation2018).
2.3. Deriving the minimization maximization cost classification (MACC)
Given the data matrix with the
row
. Let
be an
vector with the
element
,
be the current solution and
the updated solution, then
is the linear classification function.
Since for any
and
, then
Now in order to find the iterative equation of in terms of
, we differentiate the majorization (approximation) function
with respect to
, and set it equal to
as follows:
Solving EquationEquation (5)(5)
(5) for
gives (EquationEquation 6
(6)
(6) ):
The EquationEquation (6)(6)
(6) can be iterated a number of times to get an updated solution
(the hyperplane) until a desired minimum misclassification rate is reached. A threshold
is the desired minimum misclassification rate that can be set by the researcher. It can also be defined as
where
is the updated solution and
the previous solution. Moreover, if the issue of over fitting arises, it can be solved through the cross-validation method. In Algorithm (1) we show how the estimated value of
can be iteratively determined such that the rate of misclassification MCR does not exceed
However, the proposed method performs well under the assumptions of homogeneity of groups and the nonsingularity of the matrix
. Also using the Taylor’s approximation in the majorization function, and putting the parameter
in the explicit form of the Fisher’s approach:
gives one property of this majorization function
based on its partial derivatives with respect to the two mean vectors.
Further, we let in our majorization function
and taking partial with respect to
and
, to get expressions in EquationEquations (7)
(7)
(7) and (12) respectively:
consequently:
The last partial differential equation implies that in order to minimize the majorization function and consequently minimize the cost function
, leads to minimum misclassification rate
. Note that the rate of change of
with respect to
should be approximately the same rate change of
with respect to
but in the opposite direction, while preserving homogeneity within groups.
2.4. A Pseudocode for the updated MACC hyperplane
To illustrate the application of the proposed minimal cost classification rate (MCCR), the pseudocode in algorithm (1) describes the procedure for updating the hyperplane . It is necessary to set the desired misclassification rate
, sample size,
and number of iteration,iter that represent the maximum number of iterations required to update the hyperplane
. Then, the parameters
and
are set to be positive so as to control the variances in the covariance matrices
and
, where
is an identity matrix. We then, simulate
samples for each group and estimate the covariance matrix and population mean
for both groups from previous samples. If real data set is available, simulation part may not be required. After which, we suggest conducting a test for homogeneity between groups
as well as their separation
to ascertain meaningful classification and separation required for using this method. Finally, we update
at each iterative step
by using EquationEquation (6)
(6)
(6) to find the minimum misclassification rate (MCCR) that corresponds to the optimum
.
Algorithm 1: The Pseudo code to implement Minimal Cost Function based on LDA
Data: file.txt
Result: calculate the MCCR
Test ;
initialization ;
while do
Calculate ;
Find the Lost information of using Quadratic cost;
Update using EquationEquation 6
(6)
(6) ;
Calculate MCR;
if MCR then
current is updated;
else
MCCR MCR;
Exit;
end
end
3. Validation of the proposed MACC method by monitoring the MCCR
The efficiency of our method is validated by comparing its misclassification rate, MCCR against that from four different classification methods, including; the standard linear discriminant analysis SLDA, bootstrapping sampling method BSM, leave-one-out-cross-validation LOOCV and the k-fold cross-validation KFCV. We compare them by assessing their performance based on their resulting misclassification rates MCR. Here is a brief description for each method:
(1) The SLDA is the Fisher’s approach for classification (Puntanen, Citation2013; Shin, Citation2008).
(2) In the BSM, some samples are selected randomly from the dataset with specific sample sizes, fitting the linear model that leads to predict the group’s memberships for the remaining unselected samples and consequently compute the MCR. This process was repeated many times and finally the average MCR is calculated (Shao, Citation1993).
(3) The LOOCV splits the data set into two parts; the “train”, a frame that contains all samples except one data subject and the “test” frame. Train set is used to fit the linear classifier which takes the one left subject to predict its corresponding group membership. This process was continued until all subjects in the dataframe were completed giving the final result for the MCR (Xu & Goodacre, Citation2018).
(4) Under the KFCV, the data is divided the data into k-parts, which should contain relatively equal subjects. It is an extension for the LOOCV, but the test set contains more than one subject. At each time, one fold was treated as test frame and the others used to fit the model. At the end, we averaged the MCRs (Xu & Goodacre, Citation2018).
(5) MCCR is the misclassification rate calculated from the new proposed method that uses the cost function based on the MM-principle.
3.1. Validation of the MACC method using simulation study
Datasets of different sizes with
data values in each each group and seven predictors
were generated from two multivariate normal distributions with known parameters
. In each iteration, the covariance matrices were tested using the Box-M test for homogeneity, so as to check validity of the linear discrimination. Moreover, the hypothesis of population mean vectors
was also tested in order to check for existence of sufficient separation between groups, as required to perform meaningful classification. This process of simulation was conducted with different set seeds for each dataset. presents the results of these calculations. Note that each calculated MCR is based on an average of 100 iterations for each dataset.
Table 1. Comparison of MCR and MCCR based on simulated data
It can be seen from that in most cases there are small differences in the misclassification between the standard classical LDA and our proposed method, the MACC. More specifically, when the separation between the groups becomes more difficult as it is indicated by the increase of p-value, the MACC method performs more efficiently than the standard linear discriminant analysis, LDA method.
3.2. Validation of the MACC method using data from real life studies
In this section, we present validation analysis of the MACC method based on five real life datasets. These may not necessarily meet the assumptions of the new method (MACC), but are good for exploratory purposes for the performance of the new method. The first one includes 12 predictors and sample size n of 872 students. We performed logistic regression to select the 5 most significant predictors that were used in the discrimination at the next stage. The group membership of the discriminant function were on time or late graduation. Before conducting the standard linear classification, the equality of two vector means were tested using the Hotelling’s test. A significant difference between them resulted implying that there was a possibility to separate the two groups from each other by classification methods. In addition, we tested for the equality of the covariance matrices for the two groups
using the Box-M test statistic, small p-values
indicated that linear classification was not the appropriate method for classification. Nevertheless, the previous indication, SLDA was conducted and resulted in
. However, after performing 100 iteration using EquationEquation 6
(6)
(6) , the MACC method’s minimal cost classification rate MCCR was
which is the same misclassification rate as that obtained by the standard linear classifier.
The second database analysed was (students-performance). It contained sample size of 604 students. The purpose of this dataset was to predict their group membership success or fail
using five predictors. Implementing the Box-M test gave a high p-value (
) which reflected the homogeneity of data values in the two groups was acceptable. On the other hand, p-value of testing equality of the mean vectors was small (
) indicating significant difference between
and
that reflected possible separation between these two groups. The SLDA and MACC methods were conducted and ended up with very close misclassification rates, MCR
and MCCR
.
The third database was collected from the Department of Psychology at the Sultan Qaboos University Hospital SQUH. It contained information about eighty patients including five features. These were as follows: age of patients (), gender (
), primary weight of patient (
), age group (
) and drug group (
). The response for this model had two levels; over weight if the weight increased by more than or equal to eight kilograms after taking the drug otherwise there was no significant difference. Equality of covariance matrices was tested
allowing the use of linear classification. Further, the possibility of separation between group was tested
reflecting difficulty of separation of these data values since the centres of group approximately in the same location. Standard linear discriminant method was implemented yielding MCR of
. By contrast, the MACC method gave on the average of 100 iterations a minimal cost classification rate MCCR of
, which reflects great improvement in using the proposed MACC method, particularly for this data set.
illustrates the results of analysis of these three data sets plus two other datasets; Bullying and Purchased, which were collected by using questionnaires. They were conducted as mini-projects among students of the College of Nursing and College of Economics and Political Science, respectively. Because of the marginal significant difference between centroids, and extreme significance between covariances of the dichotomous groups, the performance of the proposed MACC method was poor in the Bullying dataset.
Table 2. Misclassification rates and minimal cost classification rates of real life data
Furthermore, using the train-test approach, we validated the efficiency of our proposed MACC method (Xu & Goodacre, Citation2018). Findings from these analyses continue to confirm the superiority of the proposed MACC method over the standard LDA or QDA particularly when data points are crowded at boundaries with no significant covariances and separation between groups. We provide detailed discussion in the next section.
4. Discussion
The aim of our study was to propose a new method so as to improve the classification performance of data often clustered around the linear separable hyperplane. Referring to , it is clear that the performance of the proposed method varies from one data set to another. It depends on the degree of overlap between groups as well as the significant difference on their homogeneity.(Calabrese, Citation2014; Naranjo et al., Citation2019) For instance, in the first validation dataset , the classification performance for both methods
were approximately the same. Because of low overlap between groups and significant difference in the homogeneity between groups, the results were reasonable. Moreover, for the second dataset
, it was found that the performance of SLDA was relatively better than MACC’s since having marginal significant mean vectors still indicates that not too much overlap existed between the groups, consequently, no crowded data were expected along boundaries. Thus, we expect little to no contribution of the cost function to minimize the misclassification rate. On the other hand, applying the proposed MACC method on the
data gave better improvements for the MCCR (
) as compared to the MCR
. That was due to the fact that there were overlaps between groups and also the existence of equivalent group covariances. This signalled more importance for the quadratic cost function to influence the data points contributing in estimating the hyperplane
. Further, the poor performance of MCCR using the fourth data set
can be explained by the same reason of existence of marginal significant separation and differences in homogeneity.
It has been shown in others studies that splitting datasets into two parts that is, the train and test data could improve the performance of classification methods (Shao, Citation1993; Xu & Goodacre, Citation2018). In this section we discuss its effect on the MCR. The splitting methods considered included; Bootstrap splitting method BSM, k-Fold Splitting method KFSM(k = 5,10) and Leave-one-out-cross-validation LOOCV. Moreover, we tested some of them by using the Chi-square goodness of fit test-statistic as well as compared their performance by taking the mean of MCR for a number of iterations. Ultimately, comparing their performance was important to help draw some important conclusions.
We utilized real life data sets as demonstrated in the . We developed R programming functions to fit five linear discriminant functions using three splitting methods for each proposed real dataset. This process was repeated 100 times until the final p-value (average of 100 p-value’s) as presented in correspond to each fitted model. Although, some of these models gave good classification performance, most of them did not fit the data well, meaning that the hypothesized goodness of fit was rejected. Further, we used the proposed MACC method for the five real data sets using train-test approach with 100 repetitions and calculated the average of the MCCR, which resulted in more classification efficiency improvement than the classical LDA. Thus, we concluded that using different splitting methods does not improve the MCR nor its goodness of fit. Besides, the train-test splitting method (,
) was relatively the most appropriate choice for the MACC to solve the over-fitting issue.
Table 3. Comparison the three classification splitting methods based on MCR
Furthermore, we compared the effect of increasing crowdedness of data points around the boundaries on misclassification using both methods. To verify that, we simulated 20 distinct data sets with two classes from multivariate normal distribution with equal covariance matrices and increase the centroids separation in each data set. The resultant relationship is presented in . It has been noticed that as the separation between groups decrease (increasing the p-value), the MCCR decreases. On the other hand, the flow of blue dots shows that decreasing the separation (much overlap and large p-value) yields poorer misclassification rates (increase) using the standard method LDA.
The main challenge for any classification problem is existence of overlaps between groups, especially where there is no clear separation, often resulting in poor classifier performance. (Naranjo et al., Citation2019; Pires et al., Citation2020) This phenomena happens when the centroids of the two groups are too close to each other, identified by very large p-value of the Hotelling’s test. For this reason, we suggest to test the separation of groups and their homogeneity before using the proposed MACC method.
5. Conclusion
Our study sought to develop a method based on the quadratic cost function through majorization minimization principle to improve the classification of data that are more concentrated at the boundaries and infused into another group. The proposed method, MACC has been validated against the standard methods through simulations and real life data. The findings show that the proposed method gives minimal misclassification rate compared to the standard classification methods. The method outperforms the linear discriminant analysis for more homogenous groups, when data are crowded at the boundaries.
In order to solve overfitting, we illustrated numerically that using distinct splitting methods such as bootstrapping and k-fold algorithms the performance of SLDA did not improve the classification. However, reduced misclassification rates were realised from the proposed method. Therefore, we recommend using the proposed MACC method to perform classification under the threat of group homogeneity.
Pubic interest statement
There are many life applications that are difficult to classify due to the presence of similarities between the prior classes. Failure to correctly classify could be dangerous and cost is prohibitive. The misclassification cost could be as financial loss, death of a misdiagnosed patient or just sending a student abroad to study a major that is incompatible with his abilities. As an application is to correctly classify a patient with either influenza or COVID-19 based on their signs and symptoms. To overcome this problem, our study introduces a suitable classification method that provides a minimal cost compared to the current classifiers.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors

Mubarak Al-Shukeili
Mubarak Al-Shukeili holds an MSc in Statistics and is currently a final year PhD student. His area of research is to investigate the methods that can result into minimization of classification rates. Also, he is interested in doing research in medical science, mathematical modelling and computational statistics.

Ronald Wesonga
Mubarak Al-Shukeili holds an MSc in Statistics and is currently a final year PhD student. His area of research is to investigate the methods that can result into minimization of classification rates. Also, he is interested in doing research in medical science, mathematical modelling and computational statistics.
Ronald Wesonga holds PhD in Statistics; he is a professional statistician with vast knowledge, skills and experience gained over years through collaborative networks with other professionals across the world. As a university professor, he has has published widely in high-impact journals, inspired many students, groomed junior staff and is currently enthusiastic about estimation error minimization as well as creating deeper understanding and new knowledge in data, computing & statistics.
References
- Ahn, J., & Marron, J. S. (2010). The maximal data piling direction for discrimination. Biometrika, 97(1), 254–11. https://doi.org/https://doi.org/10.1093/biomet/asp084
- Calabrese, R. (2014). Optimal cut-off for rare events and unbalanced misclassification costs. Journal of Applied Statistics, 41(8), 1678–1693. https://doi.org/https://doi.org/10.1080/02664763.2014.888542
- Croux, C., & Joossens, K. (2005). Influence of observations on the misclassi cation probability in quadratic discriminant analysis. Journal of Multivariate Analysis, 96(2), 384–403. https://doi.org/https://doi.org/10.1016/j.jmva.2004.11.001
- Dey, S., & Raheem, E. (2016). Multilevel multinomial logistic regression model for identifying factors associated with anemia in children 6–59 months in northeastern states of India. Cogent Mathematics & Statistics, 3(1), 1159798. https://doi.org/https://doi.org/10.1080/23311835.2016.1159798
- Gibra, I. N. (1967). Optimal control of processes subject to linear trends. Journal of Industrial Engineering, 18, 35–41.
- Lange, K., & TongWu, T. (2008). An MM algorithm for multicategory vertex discriminant analysis. Journal of Computational and Graphical Statistics, 17(3), 527–544. https://doi.org/https://doi.org/10.1198/106186008X340940
- Liong, C. Y., & Foo, S. F. (2013, April). Comparison of linear discriminant analysis and logistic regression for data classification. In AIP Conference Proceedings, AIP, Vol. 1522, No. 1, pp. 1159–1165.
- Mairal, J. (2013). Stochastic majorization-minimization algorithms for large-scale optimization. Advances in Neural Information Processing Systems, 2283–2291.
- Mengyi, Z., Rubio, F., & Palomar, D. P. “Calibration of high-dimensional precision matrices under quadratic loss.” 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2012.
- Naranjo, L., Pérez, C. J., Martín, J., Mutsvari, T., & Lesaffre, E. (2019). A Bayesian approach for misclassified ordinal response data. Journal of Applied Statistics, 46(12), 2198–2215. https://doi.org/https://doi.org/10.1080/02664763.2019.1582613
- Pires, M. C., Colosimo, E. A., Veloso, G. A., & Ferreira, R. D. S. B. (2020). Interval-censored data with misclassification: A Bayesian approach. Journal of Applied Statistics, 1–17.
- Puntanen, S. (2013). Methods of multivariate analysis, by Alvin C. by Alvin C. Rencher, William F. Christensen. International Statistical Review, 81(2), 328–329. https://doi.org/https://doi.org/10.1111/insr.12020_20
- Shao, J. (1993). Linear model selection by cross-validation. Journal of the American Statistical Association, 88(422), 486–494. https://doi.org/https://doi.org/10.1080/01621459.1993.10476299
- Shen, Y., Miao, Z., & Wang, Z. (2011). A cost function approach for multi-human tracking,” 2011 18th IEEE international conference on image processing, Brussels, pp. 481–484.
- Shin, H. (2008). An extension of Fisher’s discriminant analysis for stochastic processes. Journal of Multivariate Analysis, 99(6), 1191–1216. https://doi.org/https://doi.org/10.1016/j.jmva.2007.08.001
- Tillmanns, S., & Krafft, M. (2017 Logistic Regression and Discriminant Analysis). . Handbook of Market Research (), https://doi.org/https://doi.org/10.1007/978-3-319-57413-4_20.
- Velilla, S., & Hernndez, A. (2005). On the consistency properties of linear and quadratic discriminant analyses. Journal of Multivariate Analysis, 96(2), 219–236. https://doi.org/https://doi.org/10.1016/j.jmva.2004.10.009
- Wang, B., & Zou, H. (2018). Another look at distance‐weighted discrimination. Journal of the Royal Statistical Society. Series B, Statistical Methodology, 80(1), 177–198. https://doi.org/https://doi.org/10.1111/rssb.12244
- Wu, S., Khan, M. A., & Haleemzai, H. U. (2019). Refinements of Majorization inequality involving convex functions via Taylor’s theorem with mean value form of the remainder. Mathematics, 7(8), 663. https://doi.org/https://doi.org/10.3390/math7080663
- Xu, Y., & Goodacre, R. (2018). On splitting training and validation set: A comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. Journal of Analysis and Testing, 2(3), 249–262. https://doi.org/https://doi.org/10.1007/s41664-018-0068-2
- Young, D. M., & Young, D. M., & Raudys. (2004). Results in statistical discriminant analysis: A review of the former Soviet Union literature. Journal of Multivariate Analysis, 89(1), 1–35. https://doi.org/https://doi.org/10.1016/S0047-259X(02)00021-0
- Zavvar Sabegh, M. H., Mirzazadeh, A., Maass, E. C., Ozturkoglu, Y., Mohammadi, M., & Moslemi, S. (2016). A mathematical model and optimization of total production cost and quality for a deteriorating production process. Cogent Mathematics, 3(1), 1264175. https://doi.org/https://doi.org/10.1080/23311835.2016.1264175
- Zhang, T. (2004). Statistical behavior and consistency of classification methods based on convex risk minimization. Annals of Statistics (32) 1 , 56–85 doi:https://doi.org/10.1214/aos/1079120130.