
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We propose a semi-automatic staging area for efficiently building an accurate database of experimental physical properties of superconductors from literature, called SuperCon2, to enrich the existing manually-built superconductor database SuperCon. Here we report our curation interface (SuperCon2 Interface) and a workflow managing the state transitions of each examined record, to validate the dataset of superconductors from PDF documents collected using Grobid-superconductors in a previous work. This curation workflow allows both automatic and manual operations, the former contains ‘anomaly detection’ that scans new data identifying outliers, and a ‘training data collector’ mechanism that collects training data examples based on manual corrections. Such training data collection policy is effective in improving the machine-learning models with a reduced number of examples. For manual operations, the interface (SuperCon2 interface) is developed to increase efficiency during manual correction by providing a smart interface and an enhanced PDF document viewer. We show that our interface significantly improves the curation quality by boosting precision and recall as compared with the traditional ‘manual correction’. Our semi-automatic approach would provide a solution for achieving a reliable database with text-data mining of scientific documents.
Graphical abstract
IMPACT STATEMENT
This work makes a contribution to the realms of materials informatics and superconductors research, achieved through the evolution and update of SuperCon. We provide results from experiments that support the utilisation of computational analysis and machine learning for collecting experimental data from scientific articles.
1. Introduction
The emergence of new methodologies using machine learning for materials exploration has given rise to a growing research area called materials informatics (MI) [Citation1,Citation2]. This field leverages the knowledge of the materials data accumulated in the past to efficiently screen candidates of the materials with desired properties. As a matter of course, such an approach requires a larger amount of material-related data for training models. Researchers have been developing large aggregated databases of physical properties generated by first-principles calculations based on Density Functional Theory (DFT), such as Materials Project [Citation3], JARVIS (Joint Automated Repository for Various Integrated Simulations) [Citation4], NOMAD (Novel Materials Discovery) [Citation5], that played a role of a strong driving force for the development of materials informatics. Using DFT data for machine learning (ML) in materials science has become popular since, in principle, it allows researchers to simulate and obtain various types of physical properties of the target materials only by knowing the crystal structures of the subjects. Those DFT codes are designed to reproduce/simulate the physical properties that should be observed by experiments in reality. Nonetheless, caution must be exercised while utilising these computed figures for constructing ML models aimed at steering experiments. This caution arises due to the potential lack of validity in their predictions when dealing with specific simplifications of the interactions between atoms and electrons in solids, such as electron-electron Coulomb correlation, spin-orbit coupling, and similar factors.
On the contrary, accumulated datasets of experimental data from scientific publications are still scarce, despite abundant publication availability, and exponential growth in materials science [Citation6]. Currently, only a few limited resources exist, such as the Pauling File [Citation7] and SuperCon [Citation8], necessitating reliance on manual extraction methods. This scarcity can be attributed to inadequate infrastructure and a shortage of expertise in computer science within the materials science field.
The SuperCon database was built manually from 1987 [Citation8] by the National Institute for Materials Science (NIMS) in Japan and it is considered a reliable source of experimental data on superconductors [Citation9–12]. However, the updates of SuperCon have become increasingly challenging due to the high publication rate. In response to the need for a more efficient approach to sustain productivity, we embarked on the development of an automated system for extracting material and property information from the text contained in relevant scientific publications. This automated process enabled the rapid creation of ‘SuperCon2 Database’, a comprehensive database of superconductors containing around 40,000 entries, within an operational duration of just a few days [Citation1]. Matching the level of quality seen in SuperCon while simultaneously automating the extraction of organised data can be achieved with a properly designed curation process. We use the term curation to describe the overall process of reviewing and validating database records, while correction refers to the specific action of altering the values of one or more properties within an individual record. At the moment of writing this article, we are not aware of any other curation tool focusing on structured databases of extracted information. There are several tools for data annotation, such as Inception [Citation13], and Doccano [Citation14] which concentrate on text labelling and classification.
In this work, we designed and developed a workflow with a user interface, ‘SuperCon2 Interface’, crafted to produce structured data of superior quality and efficiency to the one obtained by the ‘traditional’ manual approach consisting of reading documents and noting records, usually on an Excel file. We developed this framework around the specific use case of SuperCon, however, our goal is to be adapted to alternative data frameworks.
Our contributions can be summarised as follows:
We developed a workflow and a user interface that allow the curation of a machine-collected database. We demonstrate that using it for data correction resulted in higher quality than the ‘traditional’ (manual) approach.
We devise an anomaly detection process for incoming data lower rejection rate (false positive rate) from domain experts.
We propose a mechanism that selects training data based on corrected records, and we demonstrate that such selections are rapidly improving the ML models.
The subsequent sections, Section 2 describes the curation workflow and Section 3 the user interface on top of it. Finally, we discuss our evaluation experiments and results in Section 4.
2. Curation workflow
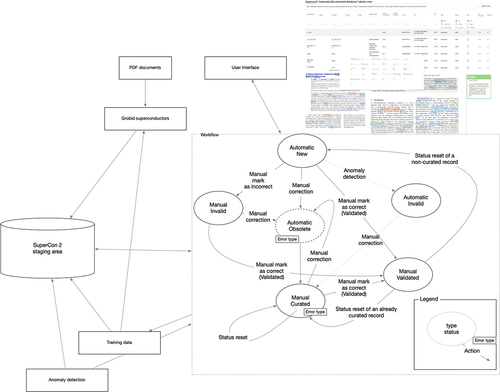
The curation of the SuperCon2 Database acts as a workflow where user actions result in database records state transitions (). Allowed manual actions include a) mark as valid (validation) when a record is considered correct or corrected by someone else. When a record is not valid, users can: b) mark as invalid when considered ‘potentially’ invalid (or the curator is not confident), c) perform manual correction to update it according to the information from the original PDF document, and d) remove the record when it was not supposed to be extracted.
Figure 1. Schema of the curation workflow. Each node has two properties: type and status (Section 2.1.1). Each edge indicates one action. The workflow starts on the left side of the figure. The new records begin with ‘automatic, new’. Changes of state are triggered by automatic (Section 2.2) or manual operations (update, mark as valid, etc. Section 3.1) and results in changes of the properties in the node. Each combination of property values identifies each state. ‘(*)’ indicates a transition for which the training data are collected (Section 2.3).
Besides manual operations from users, this workflow supports also automatic actions: ‘anomaly detection’ for pre-screening records (Section 2.2) and the ‘training data collector’ for accumulating training data for improving ML models (Section 2.3).
Although only the most recent version of a record can be viewed on this system, the correction history is recorded (Section 3.3).
2.1. Workflow control
The workflow state is determined by the ‘curation status’ (Section 2.1.1), the user action, and the error type (Section 2.1.2).
2.1.1. Curation status
The curation status () is defined by type of action, manual or automatic, and status, which can assume the following values:
new: default status when a new record is created.
curated: the record has been amended manually.
validated: the record was manually marked as valid.
invalid: the record is wrong or inappropriate for the situation (e.g. Tm or Tcurie extracted as superconducting critical temperature).
obsolete: the record has been updated and the updated values are stored in a new record (internal statusFootnote1).
removed: the record has been removed by a curator (internal status).
2.1.2. Error types
We first introduced error type in [Citation1] and extended their scope in this work to consider data curation and anomaly detection.
Users are required to select one Error Type at every record update or removal. This information is stored in the ‘original’ record and can be different at every record modification. The error type values can be summarised as follows:
From table: the entities Material
Tc
Extraction: The material, temperature, and pressure are not extracted (no box) or extracted incorrectly.
Linking: The material is incorrectly linked to the Tc given that the entities are correctly recognised.
Tc classification: The temperature is not correctly classified as ‘superconductors critical temperature’ (e.g. Curie temperature, Magnetic temperature…).
Composition resolution: The exact composition cannot be resolved (e.g. the stoichiometric values cannot be resolved).
Value resolution: The extracted formula contains variables that cannot be resolved, even after having read the paper. This includes when data is from tables
Anomaly detection: The data has been modified by anomaly detection, which facilitates their retrieval from the interface.
Curation amends: The curator is updating the data which does not present issues due to the automatic system.
2.2. Anomaly detection
Anomaly detection is the process of identifying unusual events or patterns in data. In our context, this means identifying data that are greatly different from the expected values. This post-process was introduced in a limited scope to draw attention to certain cases during the curation.
The anomaly detection uses a rule-based approach and marks any record that matches the following conditions
the extracted Tc is greater than room temperature (273 K), negative, or contains invalid characters and cannot be parsed (e.g. ‘41]’)
the chemical formula cannot be processed by an ensemble composition parser that combines Pymatgen [Citation15], and text2chem [Citation16]
the extracted applied pressure cannot be parsed or falls outside the range 0–250 GPa.
Records identified as anomalies have status ‘invalid’ and error type ‘anomaly detection’ for easy identification. Since this process may find false positives, its output requires validation from curators. For example, in certain contexts, Tc values above room temperature or applied pressure up to 500 GPa may be valid in researchers’ hypotheses, calculations, or simulated predictions.
We ran the anomaly detection on the full SuperCon2 Database (40324 records [Citation1]). The anomaly detection identified 1506 records with invalid Tc, 5021 records with an incomplete chemical formula, 304 records with invalid applied pressure, and 1440 materials linked to multiple Tc values. Further analysis and cross-references with contrasting information may be added in future.
2.3. Automatic training data collector
The curation process is a valuable endeavour demanding significant knowledge and human effort. To maximise the use of this time for collecting as much information as possible. We integrated an automatic procedure in the curation process that, for every correction, accumulates the related data examples that can be used to improve the underlying ML models.
2.3.1. Training data collection
In the event of a correction (update, removal) in a database record, this process retrieves the corresponding raw data: the text passage, the recognised entities (spans), and the layout tokens information. This information is sufficient to be exported as training examples, which can be examined and corrected, and feedback to the ML model.
2.3.2. Training data management
We designed a specific page of the interface (Section 3) to manage the collected data () in which each row corresponds to a training example composed by the decorated text showing the identified entities, the document identifier, and the status. The users can examine the data, delete it, send it to the annotation tool to be corrected, and then export them. We integrated our interface with Label-studio [Citation17] for the correction of the collected training examples. Label-studio is an open-source, python-based, and modern interface supporting many different TDM tasks (NER, topic modelling, image recognition, etc.).
Figure 2. Screenshot of the training data management page in the SuperCon2 interface. Each row contains one potential training data example. Each example is composed of a sentence and its extracted entities (highlighted in colour) with potential annotation mistakes that need to be corrected using an external tool: we used label-studio [Citation17]. The column ‘status’ indicate whether the example has been sent or not to the external tool.
![Figure 2. Screenshot of the training data management page in the SuperCon2 interface. Each row contains one potential training data example. Each example is composed of a sentence and its extracted entities (highlighted in colour) with potential annotation mistakes that need to be corrected using an external tool: we used label-studio [Citation17]. The column ‘status’ indicate whether the example has been sent or not to the external tool.](/cms/asset/104dd4f0-b034-402c-be3f-d028f2f781f7/tstm_a_2286219_f0002_oc.jpg)
3. Curation interface
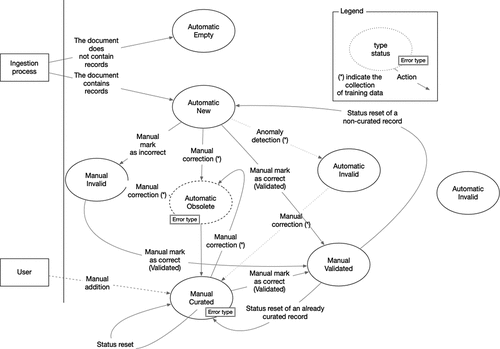
The workflow is operated through the user interface, which offers several key features to facilitate the data curation process (). It provides a comprehensive view of materials and their related properties as a table which includes search, filtering, and sorting functionality (). The detailed schema, including examples, is reported in our previous work [Citation1].
Figure 3. Screenshot of SuperCon2 interface showing the database. Each row corresponds to one material-Tc pair. On top, there are searches by attribute, sorting and other filtering operations. On the right there are curation controls (mark as valid, update, etc.). Records are grouped by document with alternating light yellow and white.
During the curation process, it is often necessary to switch back and forth between the database record and the related context in the paper (the related paragraph or sentence). Our interface provides a viewer for individual documents, which visualises in the same window a table with the extracted records and the original PDF document decorated with annotations that identify the extracted materials and properties ().
Figure 4. PDF document viewer showing an annotated document. The table on top is linked through the annotated entities. The user can navigate from the record to the exact point in the PDF, with a pointer (the red bulb light) identifying the context of the entities being examined.

3.1. Manual curation approach
In this section, we discuss our strategy concerning manual curation, which is still indispensable for developing high-quality structures.
We selected curators from domain experts in the field, to certify sufficient data quality. Nevertheless, as confirmed from our experiment in Section 4.3, the experience of each individual may have an impact on the final result. We followed two principles to guarantee robustness in the curation process. First, we built solid curation documentation as a form of example-driven guidelines with an iterative approach we first introduced in [Citation18]. Then, we used a double-round validation approach, in which the data was initially corrected by one person, and validated in a second round, by a different individual.
3.2. Curation guidelines
The guidelines consist mainly of two parts: the general principles and the correction rules with examples of solutions. The guidelines are designed to provide general information applied to corrections and very basic explanations containing illustrations for a faster understanding (e.g. the meaning of the colours of the annotations). Differently from our previous work [Citation18], these guidelines are divided into examples for different scenarios based on the error types mentioned in Section 2.1.2. Each example described the initial record, its context, the expected corrected record and a brief explanation, as illustrated in .
Figure 5. Sample curation sheet from the curation guidelines. The sheet is composed of the following information: (a) Sample input data: a screenshot of the record from the ‘SuperCon2 interface’, (b) Context represented by the related part of the annotated document referring to the record in exams. (c) The Motivation, describing the issue, (d) The Action to be taken, and the expected output.

3.3. Curation and processing logs
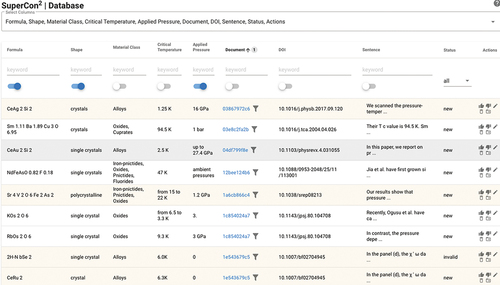
The Supercon2 interface gives access to information regarding the ingestion (processing log) and the curation process (curation log). The processing log is filled up when the new data is ingested, it was built to have minimal functions able to explain why certain documents haven’t been processed ( top). For example, sometimes documents fail because they don’t contain any text (image PDF documents) or they are too big (more than 100 pages).
Figure 6. Top: Processing log, showing the output of each ingestion operation and the outcome with the detailed error that may have occurred. Bottom: Correction log, indicating each record, the number of updates, and the date/time of the last updates. By clicking on the ‘record id’, is possible to visualise the latest record values.
The curation log provides a view of what, when and how a record has been corrected ( bottom).
4. Results and evaluation
In this section, we illustrate the experiments we have run to evaluate our work. The evaluation is composed of three sets of results. The anomaly detection rejection rate (Section 4.1) indicates how many anomalies were rejected by curators after validation. Then, we demonstrate that the training data automatically selected contributed to improving the ML model with a small set of examples (Section 4.2) Finally, we evaluated the quality of the data extraction using the interface (and the semi-automatic TDM process) against the classical method of reading the PDF articles and noting the experimental information in an Excel file. In Section 4.3 we find out that using the interface improves the quality of the curated data by reducing missing experimental data.
4.1. Anomaly detection rejection rate
We evaluated the anomaly detection by observing the ‘rejection rate’ which consists of the number of detected anomalies that were rejected by human validation. Running the anomaly detection on a database subset with 667 records, it found 17 anomalies in Tc, 1 anomaly in applied pressure, and 16 anomalies in the chemical formulas. Curators examined each reported record and rejected 4 (23%) anomalies in Tc, 6 anomalies (37%) in chemical formulas and 0 anomalies in applied pressure. This indicates an appropriate low rate of false positives although a study with a larger dataset might be necessary.
4.2. Training data generation
We selected around 400 records in the Supercon2 Database that were marked as invalid by the anomaly detection process and we corrected them following the curation guidelines (Section 3.2). Then, we examined the corresponding training data corrected by the interface (Section 2.3) and obtained a set of 352 training data examples for our ML models. We call the obtained dataset curation to be distinguished from the original SuperMat dataset which is referred to as base.
We prepared our experiment using SciBERT [Citation19] that we fine-tuned for our downstream task as in [Citation1]. We trained five models that we evaluated using a fixed holdout dataset from SuperMat averaging the results to smooth out the fluctuations. We use the DeLFT (Deep Learning For Text) [Citation20] library for training, evaluating, and managing the models for prediction. A model can be trained with two different strategies:
‘from scratch’: when the model is initialised randomly. We denote this strategy with an (s).
‘incremental’: when the initial model weights are taken from an already existing model. We denote this strategy with an (i).
The latter can be seen as a way to ‘continue’ the training from a specific checkpoint. We thus define three different training protocols:
base(s): using the base dataset and training from scratch (s).
(base+curation)(s): using both the base and curation datasets and training from scratch (s).
base(s)+(base+curation)(i): Using the base dataset to train from scratch (s), and then continuing the training with the curation dataset (i).
We merge ‘curation’ with the base dataset because the curation dataset is very small compared to ‘base’, and we want to avoid catastrophic forgetting [Citation21] or overfitting.
The trained models are then tested using a fixed holdout dataset that we designed in our previous work [Citation1] and the evaluation scores are shown in .
Table 1. F1-score from the evaluation of the fine-tuned SciBERT models. The training is performed with three different approaches. The base dataset is the original dataset described in [18], and the curation dataset is automatically collected based on the database corrections by the interface and manually corrected. s indicate ‘training from scratch’, while i indicate ‘incremental training’. The evaluation is performed using the same holdout dataset from SuperMat [18]. The results are averaged over five runs or train and evaluation.
This experiment demonstrates that with only 352 examples (2% of the SuperMat dataset) comprising 1846 additional entities (11% of the entities from the SuperMat dataset) (), we obtain an improvement of F1-score from 76.67%Footnote2 to values between 77.44% (+0.77) and 77.48% (+0.81) for (base+curation)(s) and base(s)+(base+curation)(i), respectively.
Table 2. Data support, the number of entities for each label in each of the datasets used for evaluating the ML models. The base dataset is the original dataset described in [18], and the curation dataset is automatically collected based on the database corrections by the interface and manually corrected.
This experiment gives interesting insight relative to the positive impact on the way we select the training data. However, there are some limitations: the curation dataset is small compared to the base dataset. This issue could be verified by correcting all the available training data, repeating this experiment, and studying the interpolation between the size of the two datasets and the obtained evaluation scores. A second limitation is that the hyperparameters we chose for our model, in particular, the learning rate and batch size could be still better tuned to obtain better results with the second and third training protocols.
4.3. Data quality
We conducted an experiment to evaluate the effectiveness and accuracy of data curation using two methods: a) the user interface (interface), and b) the ‘traditional’ manual approach consisting of reading PDF documents and populating an Excel file (PDF documents).
We selected a dataset of 15 papers, which we assigned to three curators – a senior researcher (SD), a PhD student (PS), and a master’s student (MS). Each curator received 10 papers: half to be corrected with the interface and half with the PDF Document method. Overall, each pair of curators had five papers in common which they had to process using opposite methods. For instance, if curator A receives paper 1 to be corrected with the interface, curator B, who receives the same paper 1, will correct it with the PDF document method. After curation, a fourth individual manually reviewed the curated content. The raw data is available in and .
We evaluated the curation considering a double perspective: time and correctness. Time was calculated as the accumulated minutes required using each method. Correctness was assessed using standard measures such as precision, recall, and the F1-score. Precision measures the accuracy of the extracted information, while recall assesses the ability to capture all expected information. F1-Score is a harmonic means of precision and recall.
4.3.1. Discussion
Overall, both methods required the same accumulated time: 185 minutes using the interface and 184 minutes using the PDF Document method. When the experiment was carried out, not all the curators were familiar with the interface method. Although they had access to the user documentation, they had to get acquainted with the user interface, thus the accumulated 185 minutes included such activities.
We examined the quality of the extracted data and we observed an improvement of + 5.55% in precision and a substantial + 46.69% in recall when using the interface as compared with the PDF Document method (). The F1-score improved by 39.35%.
Table 3. Evaluation scores (P: precision, R: recall, F1: F1-score) between the curation using the SuperCon2 interface (Interface) and the traditional method of reading the PDF document (PDF document.).
The disparity in experience significantly influenced the accuracy of curation, particularly in terms of high-level skills. Senior researchers consistently achieved an average F1-Score approximately 13% higher than other curators (see ). Furthermore, we observed a modest improvement between master’s students and PhD students. These findings indicate also that for large-scale projects, employing master students instead of PhD students may be a more cost-effective choice. Thus, using only a few senior researchers for the second round of validation (Section 3.1).
Table 4. Evaluation scores (P: precision, R: recall, F1: F1-score) aggregated by experience (MS: master student, PD: PhD student, SR: senior researcher). Each person corrected 10 documents.
Finally, the collected data suggest that all three curators had overall more corrected results by using the interface as illustrated in .
Table 5. Evaluation scores (P: precision, R: recall, F1: F1-score) listed by experience (MS: master student, PD: PhD student, SR: senior researcher), and method (PDF document, interface).
The results of this experiment confirmed that our curation interface and workflow significantly improved the quality of the extracted data, with an astonishing improvement in recall, thus preventing curators from overlooking important information.
5. Code availability
This work is available at https://github.com/lfoppiano/supercon2. The repository contains the code of the SuperCon2 interface, the curation workflow, and the ingestion processes for harvesting the SuperCon2 Database of materials and properties. The guidelines are accessible at https://supercon2.readthedocs.io.
6. Conclusions
We built a semi-automatic staging area, called SuperCon2, to validate efficiently new experimental records automatically collected from superconductor research articles (SuperCon2 Database [Citation1]) before they are ingested into the existing, manually-build database of superconductors, SuperCon [Citation8]. The system provides a curation workflow and a user interface (SuperCon2 Interface) tailored to efficiently support domain experts in data correction and validation with fast context switching and an enhanced PDF viewer. Under the hood, the workflow ran ‘anomaly detection’ to automatically identify outliers and a ‘training data collector’ based on human corrections, to efficiently accumulate training data to be feedback to the ML model.
Compared with the traditional manual approach of reading PDF documents and extracting information in an Excel file, SuperCon2 significantly improves the curation quality by approximately 6% and + 47% for precision and recall, respectively. In future, this work can be expanded to support other materials science domains such as magnetic materials, spintronic and thermoelectric research and expanding the evaluation to a larger [Citation22] dataset.
Author contribution
LF wrote the manuscript and KT helped with the editing. LF and POS discussed the ML results and experiments. LF implemented the workflow as a standalone service, and TM wrote the front end of the user interface. LF designed the user interface experiment with KT, TT and WS as curators. KT led the materials-science work on the data with CS, TT and WS. KT, TA, YT and MI revised the paper. YT and MI supervised the work of the respective teams.
Acknowledgements
Our warmest thanks to Patrice Lopez, the author of Grobid [22], DeLFT [20], and other open-source projects for his continuous support and inspiration with ideas, suggestions, and fruitful discussions. We thank Pedro Baptista de Castro for his support during this work. Special thanks to Erina Fujita for useful tips on the manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article was originally published with errors, which have now been corrected in the online version. Please see Correction (http://dx.doi.org/10.1080/27660400.2023.2286219).
Additional information
Funding
Notes
1. ‘internal status’ indicates that their records should be hidden in the interface.
2. In our previous work [Citation1] we reported 77.03% F1-score. There is a slight decrease in absolute scores between DeLFT 0.2.8 and DeLFT 0.3.0. One cause may be the use of different hyperparameters in version 0.3.0 such as batch size and learning rate. However, the most probable cause could be the impact of using the Huggingface tokenizers library which is suffering from quality issues https://github.com/kermitt2/delft/issues/150.
References
- Foppiano L, Castro PB, Suarez PO, et al. Automatic extraction of materials and properties from superconductors scientific literature. Sci Technol Adv Mater. 2023;3(1):2153633. doi: 10.1080/27660400.2022.2153633
- Oliveira ON, Oliveira MJ. Materials discovery with machine learning and knowledge discovery. Front Chem. 2022;10:10. doi: 10.3389/fchem.2022.930369
- Jain A, Ong SP, Hautier G, et al. Commentary: the materials project: a materials genome approach to accelerating materials innovation. APL Mater. 2013;1(1):011002. doi: 10.1063/1.4812323
- Curtarolo S, Setyawan W, Hart GL, et al. Aflow: an automatic framework for high-throughput materials discovery. Comput Mater Sci. 2012;58:218–12. https://www.sciencedirect.com/science/article/pii/S0927025612000717
- Draxl C, Scheffler M. The nomad laboratory: from data sharing to artificial intelligence. J Phys Mater. 2019;2(3):036001. doi: 10.1088/2515-7639/ab13bb
- Pratheepan T. Global publication productivity in materials science research: a scientometric analysis. Indian J Inf Sources Serv. 2019 Feb;9(1):111–116. https://ojs.trp.org.in/index.php/ijiss/article/view/583
- Blokhin E, Villars P. The PAULING FILE project and materials platform for data science: from big data toward materials genome. Cham: Springer International Publishing; 2018. p. 1–26. doi: 10.1007/978-3-319-42913-7_62-1
- Ishii M, Sakamoto K. Structuring superconductor data with ontology: reproducing historical datasets as knowledge bases. Sci Technol Adv Mater. 2023;3(1):2223051. doi: 10.1080/27660400.2023.2223051
- Roter B, Dordevic S. Predicting new superconductors and their critical temperatures using machine learning. Phys C. 2020;575:1353689. doi: 10.1016/j.physc.2020.1353689
- Stanev V, Oses C, Kusne A, et al. Machine learning modeling of superconducting critical temperature. Npj Comput Mater. 2017;4(1):4. doi: 10.1038/s41524-018-0085-8
- Tran H, Vu TN. Machine-learning approach for discovery of conventional superconductors. arXiv preprint arXiv:221103265. 2022.
- Konno T, Kurokawa H, Nabeshima F, et al. Deep learning model for finding new superconductors. Phys Rev B. 2021;103(1):014509. doi: 10.1103/PhysRevB.103.014509
- Klie JC, Bugert M, Boullosa B, et al. The INCEpTION platform: machine-assisted and knowledge-oriented interactive annotation. In: Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations; Santa Fe, New Mexico; 2018. p. 5–9. https://www.aclweb.org/anthology/C18-2002
- Nakayama H, Kubo T, Kamura J, et al. Doccano: text annotation tool for human; 2018. Software. https://github.com/doccano/doccano
- Ong SP, Richards WD, Jain A, et al. Python materials genomics pymatgen: a robust open-source python library for materials analysis. Comput Mater Sci. 2013 2;68:314–319. doi: 10.1016/j.commatsci.2012.10.028
- Kononova O, Huo H, He T, et al. Text-mined dataset of inorganic materials synthesis recipes. Sci Data. 2019 Oct;6(1):203. doi: https://doi.org/10.1038/s41597-019-0224-1
- Tkachenko M, Malyuk M, Holmanyuk A, et al. Label studio: data labeling software; 2020-2022. Open source software https://github.com/heartexlabs/label-studio
- Foppiano L, Dieb S, Suzuki A, et al. Supermat: construction of a linked annotated dataset from superconductors-related publications. Sci Technol Adv Mater: Methods. 2021;1(1):34–44. doi: 10.1080/27660400.2021.1918396
- Beltagy I, Lo K, Cohan A. SciBERT: a pretrained language model for scientific text. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Nov; Hong Kong, China: Association for Computational Linguistics; 2019. p. 3615–3620. https://aclanthology.org/D19-1371
- DeLFT contributors. Delft https://github.com/kermitt2/delft. 2018–2023.
- Kirkpatrick J, Pascanu R, Rabinowitz NC, et al. Overcoming catastrophic forgetting in neural networks. CoRr.2016;abs/1612.00796. http://arxiv.org/abs/1612.00796
- Contributors G. Grobid https://github.com/kermitt2/grobid 2008 — 2023.
Appendix A.
Evaluation
Table A1. Timetable recording the time spent for each of the 15 articles. Each row indicates the time and the event (Start, Finish) from each of the curators: master student (MD), PhD student (PD), and senior researcher (SR). Duration is expressed in minutes.
Table A2. Evaluation scores obtained for each document and method (I: interface, P: PDF) combination. TP: true positive, FP: false positive, FN: false negative. P: precision, R: recall, F1: F1-score.