 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
There are some problems with the traditional emergency plans of hydraulic engineering, such as low digitisation, poor knowledge relevance, insufficient intelligent decision-making, and so on. This paper proposes an intelligent method for generating the hydraulic engineering emergency plan for patrol text based on knowledge graph and machine learning. Firstly, based on the electronic documents of various plans, the knowledge graph of the emergency plan is constructed to realise the high organisation of scattered knowledge, using the skills of knowledge modelling, knowledge extraction, knowledge fusion, and knowledge storage. Then, based on bidirectional encoder representation from transformers (BERT) and bidirectional long-short-term memory with conditional random fields (BiLSTM+CRF), the entity recognition model is constructed to intelligently recognise dangers, projects, parts, and other entities in the patrol text. The Jaccard entity similarity algorithm based on the word2vec model matches the danger entity with the graph danger entities and generates the emergency plan through knowledge retrieval and reasoning. With the performance of the model and the verification of the “Channel Leakage” example, this method has high accuracy in identifying entities (the F1 value is 96.21%) and has high reliability in the generation of emergency plans, which can be applied to the emergency rescue of hydraulic engineering.
RÉSUMÉ
Les plans d’urgence traditionnels dans les projets hydrauliques rencontrent fréquemment des problèmes, tels que la faible numérisation des données, la faible pertinence des connaissances, l’insuffisance dans le processus de prise de décision, etc. Cet article propose une méthode de génération intelligente du plan d’urgence du génie hydraulique pour le texte de monitoring à partir d’un graphe de connaissances et la technique de l’apprentissage automatique. Tout d’abord, sur la base des documents de plusieurs plans, le graphe de connaissances du plan d’urgence est construit pour formaliser l’organisation des connaissances dispersées dans les différents documents, en utilisant les techniques de modélisation des connaissances, d’extraction des connaissances, de fusion des connaissances et de stockage des connaissances. Ensuite, sur la base de BERT (représentation codée bidirectionnelle à partir de transformateurs) et de BiLSTM+CRF (mémoire bidirectionnelle à long terme avec champs aléatoires conditionnels), le modèle de reconnaissance d’entités est construit pour reconnaître intelligemment les dangers, les projets, les pièces et autres entités dans le texte de monitoring. L’algorithme de similarité d’entités de Jaccard basé sur le modèle Word2vec fait correspondre l’entité de danger avec les entités de danger du graphique et génère le plan d’urgence par le biais de la récupération de connaissances et du raisonnement. Grâce à la performance du modèle et à la vérification de l’exemple “Fuite de canal”, cette méthode a une grande précision dans l’identification des entités (la valeur F1 est de 96,21 %) et a une grande fiabilité dans la génération de plans d’urgence, qui peuvent être mis en œuvre dans le cadre de grand projets hydrauliques.
1. Background
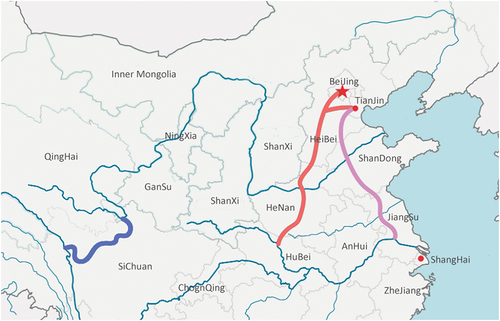
Since the South-to-North Water Diversion Project officially began operation in December 2014, the allocation of water resources has extended farther along the route, playing a significant role in ensuring water security, restoring water ecology, and improving the water environment (Li et al., Citation2022). As the South-to-North Water Transfer Project spans many provinces and cities, the project route is long and the environment along the route is complex and varied (the three South-to-North Water Transfer routes are shown in ). There are inevitably many risks associated with the operation of the project, so an agile and effective emergency response to hazards is important.
Figure 1. The three routes of the South-to-North Water Transfer Project, with the blue line representing the western route of the South-to-North Water Transfer Project, the red line representing the middle route of the South-to-North Water Transfer Project and the pink line representing the eastern routeof the South-to-North Water Transfer Project.
Most of the Water Conservancy Project emergency plan materials are stored in the form of paper texts and electronic documents. There are some problems such as poor query and retrieval efficiency, weak content correlation, and insufficient intelligent auxiliary decision-making during use. Therefore, it is necessary to explore scientifically efficient methods for the intelligent generation of emergency plans and to design better decision support systems to deal with all types of hazards (Ramsbottom et al., Citation2017; Sorensen et al., Citation2017).
At present, the intelligent generation method of emergency plans mainly relies on case-based reasoning (CBR). CBR solves emergencies by matching the similarity between the target case and historical cases, as well as reusing or modifying emergency plans of historical cases with the highest similarity (Sekar et al., Citation2019). Many scholars have applied CBR to the field of emergency decision-making. For example, Fan et al. used CBR based on the case retrieval method and hybrid similarity calculation (Fan et al., Citation2014); and Zhang et al. proposed a new case adjustment method to modify and generate the emergency plan for grid stroke disasters (Zhang et al., Citation2015). Jiang et al. combined ontology with improved CBR to create a decision method for safety risk management (Jiang et al., Citation2020). Hadj-Mabrouk set the goal to develop a new approach to the analysis and evaluation of the validity of decision support, based on machine learning and the CBR (Hadj-Mabrouk, Citation2020). The above research relies on the scale of the historical case base and the calculation weight of the case attributes. The generated emergency plans are presented as documents, with a low degree of digitisation and weak knowledge correlation. The knowledge graph (Chen et al., Citation2021), created in 2012, was initially applied to semantic search (Dong et al., Citation2014), question answering (Hao et al., Citation2017), intelligent recommendation (Gong et al., Citation2021), and so on. It involved the rapid acquisition, rational organisation and scientific utilisation of massive amounts of knowledge. In recent years, knowledge graphs have also been applied in the field of emergency management. Li et al. used knowledge representation to provide auxiliary decision-making for natural disasters (Li et al., Citation2020). Liu et al. constructed a knowledge map of geological disaster emergency plans for rapid emergency response actions (Liu et al., Citation2021). Ni et al. constructed an emergency plan knowledge system to provide reliable information for emergency responders (Ni et al., Citation2019). Yang et al. constructed a knowledge co-occurrence network to analyse the importance of emergency management in public health emergencies (Yang et al., Citation2020).
As a kind of semantic network, the knowledge graph has a strong ability in knowledge organisation and expression, and it also has preliminary applications in the field of water conservancy (Diaz & Vilches-Blazquez, Citation2022; Yan et al., Citation2018), but it has not been applied to water emergency management. Therefore, taking the South-to-North Water Diversion Project as an example, this paper constructs a knowledge graph of emergency plans for water conservancy projects and combines machine learning technology to realise the intelligent generation of emergency plans.
2. Knowledge graph construction of the emergency plan
The knowledge graph construction process generally includes four stages: knowledge modelling (Ayachi et al., Citation2022), knowledge extraction (Al-Moslmi et al., Citation2020; Smirnova & Cudre-Mauroux, Citation2019), knowledge fusion (Zhao et al., Citation2020) and knowledge storage (Wylot et al., Citation2019; Zou & Özsu, Citation2017). Knowledge modelling refers to organising entities and related information for building a knowledge graph schema using knowledge representation language. Based on the schema, knowledge extraction extracts entities, relationships and attributes from data sources. Knowledge fusion solves the problem of ambiguity of entities during extraction. Knowledge storage refers to storing the merged entities, relationships and attributes in the graph database, which is convenient for downstream applications. shows the process of construction of the knowledge graph in the emergency plan for the middle route of the South-to-North Water Diversion Project.
Figure 2. The process of construction of an emergency plan knowledge map for the middle route of the South-to-North Water Transfer Project.
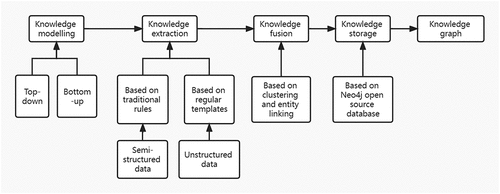
2.1. Knowledge modelling
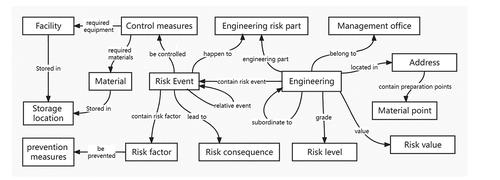
Knowledge modelling includes two methods: one is top-down, and the other is bottom-up. Taking the Risk Prevention and Control Manuals of the 47 management offices of the middle route of the South-to-North Water Diversion Project and the Overall Plan of the emergency rescue system for engineering risks as data sources, in this paper we combined the top-down and bottom-up methods to define knowledge graph ontologies and relationships. Then, we construct the knowledge graph schema of the emergency plan on the middle route of the South-to-North Water Diversion Project, as shown in . This schema includes 15 kinds of entities such as engineering, risk events, risk factors, equipment, materials, and so on, and includes 18 kinds of relationships such as risk events, risk factors, rescue equipment, rescue materials, etc.
Figure 3. Knowledge graph schema of the emergency plan of the middle route of the South-to-North Water Transfer Project.
2.2. Knowledge extraction
Under the guidance of the knowledge graph schema, this paper adopts different ways to complete knowledge extraction based on the structural characteristics of data sources.
2.2.1. Knowledge extraction from the Risk Prevention and Control Management Manual
Since the Risk Prevention and Control Management Manual is mainly composed of semi-structured data, this paper uses the traditional manual extraction method combined with the regular template method to achieve knowledge extraction. Some examples are shown in .
Table 1. Entity examples from the Risk Prevention and Control Manual.
2.2.2. Knowledge extraction from the Overall Plan of the emergency rescue system for engineering risks
The Overall Plan of the emergency rescue system for engineering risks is mainly composed of unstructured data, but it has a clear text structure which has the mode of “keyword + short text”. Therefore, in the process of knowledge extraction, this mode is used to extract entities and relationships, as shown in .
Table 2. Entity examples of the overall scheme of the emergency rescue system.
2.3. Knowledge fusion
In the process of graph construction, entity ambiguity cannot be avoided, so knowledge fusion needs to be performed before storing data to obtain a standardised and unified description. This paper realises entity fusion by clustering and linking. Since the knowledge graph of the emergency plan for the middle route of the South-to-North Water Diversion Project belongs to the vertical domain knowledge graph and data sources are scarce, this graph only fuses three kinds of entities: engineering, risk event and risk factor.
The entity fusion process includes three parts: entity name expansion, candidate entity generation and candidate entity sorting. According to the background of the entity reference, the entity reference extension is expanded into a full name to reduce ambiguity; for example, “overloading” can be expanded to “vehicle overloading”. For each entity reference M, the candidate entity generation returns the candidate entity set E < E1, E2, E3, … > according to its label in the knowledge graph. For example, the entity reference M “water channel destruction” returns candidates with the same label such as E1 “structural failure”, E2 “component failure”, etc. Based on the generated entity set E, the candidate entity sorting means that we extract the semantic feature vector of the entity reference M and each candidate entity Ei with the Word2Vec model, calculate the spatial distance between M and Ei with a support vector machine model, sort and select the optimal entity Etop from the <M, Etop> pairs used as an alias attribute of Ei. For example, the matching of M “water conveyance channel damage” and Ei “structural damage” in set E has the highest score, so we return and save the optimal entity pair <water conveyance channel damage, structure damage>. Finally, knowledge fusion is realised, and entity ambiguity is eliminated.
2.4. Knowledge storage
Compared with the relational database, the graph database has the characteristics of high traversal efficiency and strong relational expression. Moreover, the scale of the knowledge graph for emergency plans of the middle route of the South-to-North Water Diversion Project is small, and the downstream tasks have higher requirements for relational expression. Therefore, this study adopts the Neo4j graph database to achieve knowledge storage which has a high query efficiency in seeking entities and relations. We organise the entity relationships obtained by knowledge extraction and knowledge fusion into a triplet (entity1, relationship, entity2), such as (plumbing, risk factor, ant-rat-hole hazard), (Zhangzhuang Bridge, risk value, 4.0), etc.
3. Method for intelligent generation of emergency plan
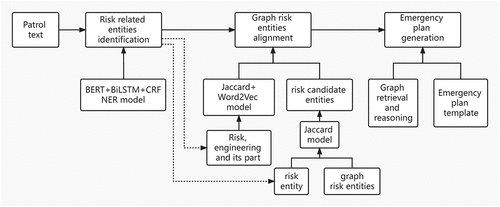
This paper proposes an intelligent generation method for the emergency plan of the middle route of the South-to-North Water Diversion Project based on the knowledge graph. The specific flow chart is shown in . First, based on the bidirectional encoder representation from transformers (BERT) and bidirectional long-short-term memory with conditional random felds (BiLSTM+CRF) model, we identified the engineering, location, risk, engineering risk part, and other entities in the patrol text. Then, we sorted the risk entities of the map by the Jaccard algorithm in a coarse-grained manner to generate a set of risk candidate entities. Second, based on the Word2Vec model combined with the Jaccard algorithm, we fused the three identified entity features – risk, engineering, and engineering risk part – and align the identified risk entity with the set of risk candidate entities by calculating the feature similarity. Finally, by combining the emergency plan template, we used graph reasoning technology to intelligently generate the emergency plan (Chen et al., Citation2016, Citation2020).
Figure 4. The pipeline of intelligent emergency plan generation for the middle route of the South-to-North Water Transfer Project.
3.1. Entity recognition model based on BERT+BiLSTM+CRF
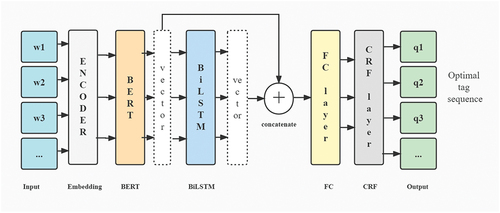
Entity recognition methods include dictionary-rule-based methods (Rau, Citation1991), traditional machine learning methods (Liu et al., Citation2011) and deep learning methods (Zhiheng et al., Citation2015). The entity recognition model based on dictionary rules or traditional single machine learning methods is limited by a lack of universality and by low accuracy. Therefore, based on the BERT deep learning model (Devlin et al., Citation2018), this paper constructed a BERT+BilSTM+CRF model to identify risk entities. The model is fine-tuned and trained based on Google’s large-scale Chinese corpus pre-training model, which can effectively avoid a large amount of labelled data and achieve high entity recognition accuracy. The specific structure of the model is shown in . The model initially converts the patrol text into a list of numbers through the encoding layer and then generates a matrix T carrying semantic features through the BERT pre-training model. The vector T is input to the BiLSTM layer to obtain the contextual semantic information and to output as a matrix O. Then the concatenation layer concatenates the matrix T with the matrix O to get the output matrix E. The fully connected layer (FC) is used to reduce the dimension of matrix E and the CRF layer is used to correct the output matrix. Finally, the optimal label sequence is generated.
Figure 5. The BERT+BiLSTM+CRF model framework.
3.2. Jaccard entity similarity algorithm based on Word2Vec model
The traditional entity similarity calculation method was primarily based on the Jaccard algorithm, which has high accuracy but low recall and lacks semantic information. There are three common methods for calculating entity similarity: One is based on a dictionary or a certain classification system. Common dictionaries include Hownet, Wordnet and synonym word forest; their construction methods are different from each other, but they are all limited to the general field and are difficult to apply to the professional field of hydraulic engineering. The second is a statistical method based on the context space vector, represented by Google’s Word2Vec (Mikolov et al., Citation2013). This method maps words into space vectors and calculates the similarity by the distance of the vectors. The last method is based on deep learning, which requires a huge corpus and high computation and cost. In this paper we select the Jaccard entity similarity algorithm based on the Word2Vec model to calculate the similarity of risk entities. The overall idea of the algorithm is as follows:
Step 1: Use the Overall Plan of the emergency rescue system for the middle route of the South-to-North Water Diversion Project and the unstructured text information in the Risk Prevention and Control Manual as the corpus to train the Word2Vec model and obtain the word vector.
Step 2: Take the risk, engineering, and engineering risk part which are obtained by the entity recognition model in Section 3.1 as the target entity set A[a1, a2, a3].
Step 3: Bring the target risk entity a1 and the risk candidate entity set T[t1,t2,t3, …] into the graph as the input of the Jaccard entity similarity algorithm, output the list of risk candidate entities W[w1,w2,w3, …] by coarse-grained sorting, and use the Word2Vec model to convert the list W into the feature vector H[h1,h2,h3, …]. The equation for the Jaccard entity similarity algorithm is as follows:
Step 4: Input the target entity set A into the Word2Vec model to obtain the vector V[v1,v2,v3], use the weighted average method to fuse various entity feature vectors vi into a target feature vector aim, calculate the cosine similarity of ai with candidate feature vector hi, and finally return the score S[s1,s2,s3, …] of each risk candidate entity ti. The cosine similarity calculation equation is as follows:
Step 5: Take the target entity set A and the risk candidate entity set T as the input of the Jaccard algorithm, and output the score Q[q1,q2,q3, …] of each risk candidate entity ti.
Step 6: Add the scores S and Q, sort and return the top five risk candidate entities R[r1, r2, r3, r4, r5] with the highest scores.
3.3. Emergency plan template
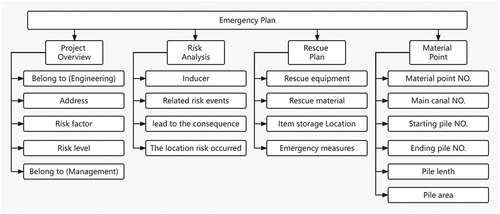
We analysed the Risk Prevention and Control Manual of the middle route of the South-to-North Water Diversion Project and the Overall Plan of the emergency rescue system for the project. The emergency plan is divided into four parts, namely project overview, risk analysis, rescue plan and material preparation point. The project overview includes the project, the location, the risk value and the risk level. The risk analysis includes the inducing factors, related risk events, the consequences and the engineering risk part. The rescue plan includes equipment, materials, storage locations and rescue measures. The material preparation point includes the material preparation point numbers, the main channel number, length, area, etc. The specific emergency plan template is shown in .
Figure 6. The emergency plan template.
Based on the risk entity of the graph matched in Section 3.2 and the engineering, location, engineering risk part and other entities identified in Section 3.1, in this paper we combined various elements of the emergency plan template, and used knowledge graph reasoning and knowledge graph retrieval to realise the intelligent generation of the emergency plan.
4. Analysis of experimental results
4.1. Experimental environment
The experimental running environments of this paper are CPU (Intel (R) Core (TM) i7-8700), GPU (NVIDIA GeForce GT 710), running memory of 16 GB, python version 3.6, operating platform pycharm 2020.3, Keras neural network framework. Some parameters of the BERT+BiLSTM+CRF model are shown in .
Table 3. Some parameters of the bidirectional encoder representation from transformers (BERT) and bidirectional long-short-term memory with conditional random felds (BiLSTM+CRF) model.
4.2. Analysis of knowledge graph construction results
4.2.1. Entity and relation extraction results
Taking 47 risk prevention and control manuals for the middle route of the South-to-North Water Diversion Project and the Overall Plan of the emergency rescue system as the data sources, a knowledge map of emergency plans for the middle-line project of the South-to-North Water Diversion Project was constructed based on the construction plan of the knowledge graph.
We extracted 15 kinds of entities such as projects, locations, management institutions, risk values, risk events, etc. (as shown in for specific entity statistics), and extracted 17 kinds of relationships such as risk events (engineering to risk events), engineering risk value (engineering to risk value), engineering risk level (project to risk level), location (project to location), including risk factor (risk event to risk factor), etc. (as shown in for specific relationship statistics).
Table 4. Statistics on entity extraction of the middle route of the South-to-North Water Transfer Project.
Table 5. Statistics on extraction of relationships for the middle route of the South-to-North Water Transfer Project.
4.2.2. Knowledge graph results
Due to the large number of entities and relationships of the middle route of the South-to-North Water Diversion Project, this article shows only part of the entities and relationships of the knowledge map, as shown in .
Figure 7. Part entities and relationships of the knowledge map.
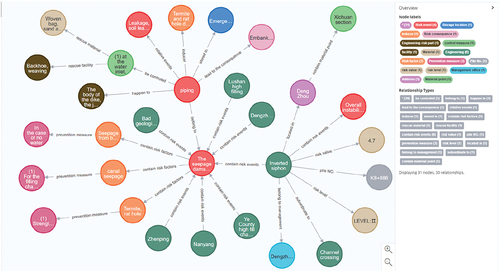
Inverted siphons of the trunk canal end branch canals in Taocha county, subordinated to the canal crossing bridge inverted siphon, which is located in Dengzhou and affiliated with the Dengzhou administrative office. This engineering has a risk event, seepage damage, which includes two sub-risk events, seepage soil and piping. Each sub-risk event entails different risk factors, and the risk event and risk factor correspond to control measures and preventive measures, respectively. The control measures involve two kinds of entities, emergency equipment and emergency materials, and the risk events have different control measures according to different engineering risk parts. In this way, we can associate entities such as engineering, risk, control measure, rescue equipment and rescue material.
4.3. Analysis of entity recognition model results
The BERT+BiLSTM+CRF entity recognition model constructed in this paper mainly identifies eight types of entities: project, stake number, location, management office, risk value, risk event, risk factor and engineering risk part. We divided more than 28,000 pieces of manually marked data into independent and different training sets, validation sets and test sets. And, based on templates, we use data augmentation methods to expand the training sets and validation sets and finally input them into the BERT+BiLSTM+CRF model for training. The model training results are shown in . The results show that the model has an F1 value of 96.21% and can accurately identify risk entities and related entities. The model can also be used for knowledge extraction when updating the graph in the future, which has significant importance.
Table 6. Model training results on bidirectional encoder representation from transformers (BERT) and bidirectional long-short-term memory with conditional random felds (BiLSTM+CRF).
4.4. Analysis of entity similarity algorithm results
In this paper we design a Jaccard entity similarity algorithm based on the Word2Vec model, manually construct a test set for the risk entities similarity algorithm and compare the effects of a single Word2vec model and a single Jaccard algorithm. The test set contains a total of 300 groups of entity lists in the form of [(engineering, risk1, engineering risk part), (risk2)], and each group of entity lists is used as the input for the entity similarity algorithm. If five risk entities of the output contain risk2, it is regarded as a correct matching. The evaluation results of the three algorithms are shown in .
Table 7. Three groups of algorithm evaluation results (%).
The experimental results show that the Jaccard entity similarity algorithm based on the Word2Vec model is better than the single Word2vec model and the single Jaccard algorithm. The matching results of some risk entities are shown in . It can be seen from that when the input risk entity is a terrorist attack, the algorithm returns the correct matching risk entity terrorist attack and other matching risk entities related to the terrorist attack. For example, drone attacks and terrorist hijacking events are the manifestations of terrorist attacks, and control system failures are the result of cyber-attack damage in terrorist attacks. Users can select the different matching risk entities to intelligently generate different emergency plans according to their needs.
Table 8. The matching situation of some risk entities on the knowledge graph.
4.5. Intelligent generation of emergency plans
Based on the risk entity and related entities identified by the BERT+BiLSTM+CRF model, we use the Word2Vec model trained in the vertical domain and the Jaccard algorithm to match risk entities in the graph and intelligently generate emergency plans with graph retrieval and reasoning.
Take the patrol text of “the seepage phenomenon occurred in the embankment of the high-fill channel at pile number K15 + 125~ K16 + 140 in Dengzhou Management Office” as an example. Based on the entity recognition model, we can obtain the risk entity and related entities: management office (Dengzhou management office), engineering (high-fill channel), stake number (K15 + 125⁓K16 + 140), engineering risk part (embankment body) and risk (seepage phenomenon).
According to the coarse-grained sorting of the Jaccard algorithm, 20 risk candidate entities are generated. Based on the Jaccard algorithm and the Word2Vec model, we integrate the three entity features of engineering, risk and engineering risk parts to obtain the top five risk entities in the graph in the order of the similarity scores, and we use the graph retrieval method to return the corresponding disposal measures, as shown in .
Table 9. List of risk candidate entities.
shows that the identified risk entity “Leakage phenomenon” matches the risk entity “Canal seepage” in the graph. Based on the identified entity list and emergency plan template, we use the graph reasoning method and graph retrieval method to intelligently generate emergency plans, as shown in .
Figure 8. Emergency plan page.

shows that the content of the emergency plan for “Canal seepage” includes identified entities of the patrol text, related risk events, matching risk list in the graph, risk control methods, graph overview, project overview, rescue plan, risk analysis and material preparation points. The graph overview shows the knowledge related to the risk entity “Canal seepage” in the form of a knowledge graph. The project overview contains the relevant information about the project entity “Dengzhou high fill channel”. The rescue plan includes the material and equipment needed for emergency rescue. And the risk analysis includes causes, consequences, related risks and the engineering risk part of the risk entity “Canal seepage”.
5. Conclusion
Because of the frequent occurrence of risk in the middle route of the South-to-North Water Diversion Project, this paper proposes an intelligent method for the generation of emergency plans based on knowledge graphs, and draws the following conclusions:
Based on the Risk Prevention and Control Manual of the middle route of the South-to-North Water Diversion Project and the Overall Plan of the emergency rescue system, this paper analyses and organises the knowledge of danger, engineering, etc., and uses knowledge extraction, knowledge fusion and knowledge storage to construct a knowledge graph of the emergency plan for the middle route of the project. Furthermore, we provide inquiry and retrieval services of knowledge related to risk.
In this paper we design an entity recognition model based on BERT+BiLSTM+CRF, which achieves a better recognition effect through a smaller data set, and realises automatic identification and extraction of entities such as projects, locations, stake numbers, etc. We propose the Jaccard entity similarity algorithm based on the Word2Vec model and verify the reliability of the model in calculating the similarity of the risk entities, and then realise the intelligent alignment of the risk entities.
Based on the danger inspection text submitted by the inspectors, this paper combines the two machine learning models mentioned above to automatically extract the danger, location and engineering information in the text and match it with the danger in the knowledge graph, and, finally, use knowledge retrieval and reasoning to intelligently generate an emergency plan, which contains an overview of engineering knowledge, rescue measures and danger analysis to effectively assist professionals to make emergency decisions and improve the safe operation of water conservancy projects. However, there are limitations to this approach, such as its reliance on the method of describing hazards in the inspection text and the number of hazards in the graph. In the future, we need to improve the knowledge matching and knowledge updating techniques and expand the breadth and depth of the water conservancy projects knowledge map to serve other downstream tasks of water conservancy projects and enhance the intelligent management of water conservancy information.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data that support the findings of this study are available from the corresponding author, H. K. Lu, upon reasonable request https://github.com/luhankang/emergency_plan
Additional information
Funding
References
- Al-Moslmi, T., Ocana, M. G., Opdahl, A. L., & Veres, C. (2020). Named entity extraction for knowledge graphs: A literature overview. IEEE Access, 8, 1–12. https://doi.org/10.1109/ACCESS.2020.2973928
- Ayachi, R., Guillon, D., Aldanondo, M., Vareilles,E., Coudert, T., Beauregard, Y., & Geneste, L. (2022). Risk knowledge modeling for offer definition in customer-supplier relationships in engineer-to-order situations. Computers in Industry, 138, 103608. https://doi.org/10.1016/j.compind.2022.103608
- Chen, Y., Goldberg, S., Wang, D. Z., & Johri, S. S. (2016). Ontological pathfinding. In Proceedings of the 2016 International Conference on Management of Data. (pp 835–846).
- Chen, X. J., Jia, S. B., & Xiang, Y. (2020). A review: Knowledge reasoning over knowledge graph. Expert Systems with Applications, 141, 112948. https://doi.org/10.1016/j.eswa.2019.112948
- Chen, X. L., Xie, H. R., Li, Z. X., & Cheng, G. (2021). Topic analysis and development in knowledge graph research: A bibliometric review on three decades. Neurocomputing, 461, 497–515. https://doi.org/10.1016/j.neucom.2021.02.098
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre training of deep bidirectional transformers for language understanding. https://doi.org/10.48550/arXiv.1810.04805
- Diaz, J. R. D., & Vilches-Blazquez, L. M. (2022). Characterizing water quality datasets through multi-dimensional knowledge graphs: A case study of the Bogota river basin. Journal of Hydroinformatics, 24 (2), 295–314. https://doi.org/10.2166/hydro.2022.070
- Dong, X. L., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., Strohmann, T., Sun, S., & Zhang, W. (2014). Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. (pp 601–610).
- Fan, Z. P., Li, Y. H., Wang, X. H., & Liu, Y. (2014). Hybrid similarity measure for case retrieval in CBR and its application to emergency response towards gas explosion. Expert Systems with Applications, 41(5), 2526–2534. https://doi.org/10.1016/j.eswa.2013.09.051
- Gong, F., Wang, M., Wang, H. F., Wang, S., & Liu, M. Y. (2021). SMR: Medical knowledge graph embedding for safe medicine recommendation. Big Data Research, 23, 100174. https://doi.org/10.1016/j.bdr.2020.100174
- Hadj-Mabrouk, H. (2020). Application of case-based reasoning to the safety assessment of critical software used in rail transport. Safety Science, 131, 104928. https://doi.org/10.1016/j.ssci.2020.104928
- Hao, Y., Zhang, Y., Liu, K., He, S., Liu, Z., Wu, H., & Zhao, J. (2017). An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. (pp 221– 231).
- Jiang, X. Y., Wang, S., Wang, J., Lyu, S. N., & Skitmore, M. (2020). A decision method for construction safety risk management based on ontology and improved CBR: Example of a subway project. International Journal of Environmental Research and Public Health, 17(6), 2020. https://doi.org/10.3390/ijerph17062020
- Li, H. M., Guo, Y. J., Li, F., Cao, Y. C., Wang, L. Y., & Ma, Y. (2022). Assessment of operation safety risk for south-to-north water diversion project: A fuzzy VIKOR-FMEA approach. Water Supply, 22(4), 3685–3701. https://doi.org/10.2166/ws.2022.009
- Li, B., Li, T. T., Jiang, Q., Huang, H., Wang, R. J., Zhang, Z. Y., Wang, L. S., Wei, Y. Y., & Xiao, Z. X. (2020). A knowledge-based system for disaster emergency relief. International Journal of Pattern Recognition and Artificial Intelligence, 34(11), 2059038. https://doi.org/10.1142/S0218001420590387
- Liu, X. H., Liu, Z., Liu, Y. W., & Tian, J. K. (2021). Integration of a geo-ontology-based knowledge model and spatial analysis into emergency response for geologic hazards. Natural Hazards, 108(2), 1489–1514. https://doi.org/10.1007/s11069-021-04742-5
- Liu, X., Zhang, S., Wei, F., & Zhou, M. (2011). Recognizing named entities in tweets. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. (pp 359–367).
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. https://doi.org/10.48550/arXiv.1301.3781
- Ni, Z. J., Rong, L. L., Wang, N., & Cao, S. (2019). Knowledge model for emergency response based on contingency planning system of China. International Journal of Information Management, 46, 10–22. https://doi.org/10.1016/j.ijinfomgt.2018.10.021
- Ramsbottom, D., Frank, E., Weisgerber, A., & Beros, M. (2017). Developing a national programme of flood risk management measures: Moldova. La Houille Blanche – Revue Internationale De L'Eau, 103(4), 46–52. https://doi.org/10.1051/lhb/2017031
- Rau, L. F. (1991). Extracting company names from text. In Proceedings The Seventh IEEE Conference on Artificial Intelligence Application. (pp 29–32).
- Sekar, B. D., Lamy, J. B., Larburu, N., Seroussi, B., Guezennec, G., Bouaud, J., Muro, N., Wang, H., & Liu, J. (2019). Case-based decision support system for breast cancer management. International Journal of Computational Intelligence Systems, 12(1), 28–38. https://doi.org/10.2991/ijcis.2018.25905180
- Smirnova, A., & Cudre-Mauroux, P. (2019). Relation extraction using distant supervision: A survey. ACM Computing Surveys, 51(5), 1–35. https://doi.org/10.1145/3241741
- Sorensen, C., Jebens, M., & Piontkowitz, T. (2017). Danish risk management plans of the EU floods directive. La Houille Blanche – Revue Internationale De L'Eau, 103(4), 31–39. https://doi.org/10.1051/lhb/2017029
- Wylot, M., Hauswirth, M., Cudré-Mauroux, P., & Sakr, S. (2019). RDF data storage and query processing schemes. Acm Computing Surveys, 51(4), 1–36. https://doi.org/10.1145/3177850
- Yang, R., Du, G. M., Duan, Z. W., Du, M. J., Miao, X., & Tang, Y. H. (2020). Knowledge system analysis on emergency management of public health emergencies. Sustainability, 12(11), 4410. https://doi.org/10.3390/su12114410
- Yan, J. Z., Lv, T. T., & Yu, Y. C. (2018). Construction and recommendation of a water affair knowledge graph. Sustainability, 10(10), 3429. https://doi.org/10.3390/su10103429
- Zhang, B. S., Li, X. Y., & Wang, S. Y. (2015). A novel case adaptation method based on an improved integrated genetic algorithm for power grid wind disaster emergencies. Expert Systems with Applications, 42(21), 7812–7824. https://doi.org/10.1016/j.eswa.2015.05.042
- Zhao, X. J., Jia, Y., Li, A. P., Jiang, R., & Song, Y. C. (2020). Multi-source knowledge fusion: A survey. World Wide Web-Internet and Web Information Systems, 23(4), 2567–2592. https://doi.org/10.1007/s11280-020-00811-0
- Zhiheng H, Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF models for sequence tagging. https://doi.org/10.48550/arXiv.1508.01991
- Zou, L., & Özsu, M. T. (2017). Graph-based RDF data management. Data Science and Engineering, 2(1), 56–70. https://doi.org/10.1007/s41019-016-0029-6