
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This work proposes a wavelet shrinkage rule under asymmetric LINEX loss function and a mixture of a point mass function at zero and the logistic distribution as prior distribution to the wavelet coefficients in a nonparametric regression model with gaussian error. Underestimation of a significant wavelet coefficient can lead to the bad detection of features of the unknown function, such as peaks, discontinuities, and oscillations. It can also occur under asymmetrically distributed wavelet coefficients. Thus, the proposed rule is suitable when overestimation and underestimation have asymmetric losses. Statistical properties of the rule, such as squared bias, variance, frequentist, and bayesian risks, are obtained. Simulation studies are conducted to evaluate the performance of the rule against standard methods and an application in a real dataset involving infrared spectra is provided.
1. Introduction
Wavelet shrinkage methods are important tools to be applied in nonparametric regression models under wavelet basis expansion of the unknown function. In the wavelet domain, coefficients of the representation of a function are typically sparse and the few nonzero coefficients are localized at important positions of the function to be recovered, such as peaks, discontinuities, and oscillations. However, the observed (empirical) wavelet coefficients, which are obtained by the application of a discrete wavelet transformation on the data, are not sparse in practice due to the presence of noise. In this sense, wavelet shrinkage rules act by denoising the empirical coefficients and estimating the true wavelet coefficients of the basis expansion of the unknown function. The concept of wavelet shrinkage was introduced in the seminal works of Donoho (Citation1993, Citation1995), Donoho and Johnstone (Citation1994, Citation1995), and Donoho et al. (Citation1995).
There are several wavelet shrinkage rules available in the literature, most of them are thresholding. A thresholding rule shrinks a small empirical coefficient that is less than a threshold value to exactly zero. The hard and soft thresholding rules of Donoho and Johnstone (Citation1994) are the most famous and applied in the literature and policies to obtain the threshold value were proposed since then, such as the universal threshold by Donoho and Johnstone (Citation1994), the Stein unbiased risk estimator (SURE) by Donoho and Johnstone (Citation1995), and the cross validation threshold by Nason (Citation1996), among others. Bayesian wavelet shrinkage rules have also been proposed along the last decades. In fact, bayesian procedures allow the incorporation of prior information about the wavelet coefficients in the estimation process such as sparseness level and boundedness (if they are limited) through the elicitation of a prior probabilistic distribution to them. Chipman et al. (Citation1997) proposed a mixture of two zero mean normal distributions as prior, one of them with very small variance, in the same idea of a spike and slab prior. Mixtures of a point mass function at zero and a symmetric and unimodal distribution centered at zero were proposed by Vidakovic and Ruggeri (Citation2001) with the Laplace distribution, the Bickel distribution by Angelini and Vidakovic (Citation2004), the double Weibull distribution by Remenyi and Vidakovic (Citation2015), the logistic distribution by Sousa (Citation2020), and the beta distribution by Sousa et al. (Citation2020).
Although the Bayesian shrinkage rules mentioned above and others are suitable for many real data applications, they were built under symmetric loss functions, in particular, the quadratic loss function, which implies that overestimation and underestimation with the same magnitudes of a given wavelet coefficient have the same loss. Moreover, when the quadratic loss function is considered, mathematical advantages are gained such as differentiation and easier analytical manipulation, in addition to the fact that the Bayesian rule is the posterior expected mean of the wavelet coefficient. However, when overestimation and underestimation should have different losses, the proposed shrinkage rules are not suitable and it is necessary the development of a shrinkage rule that is built under an asymmetric loss function. In this sense, this article proposes a Bayesian shrinkage rule under a point mass function at zero and the logistic distribution as prior to the wavelet coefficient and that is obtained under the so called linear-exponential (LINEX) loss function. This asymmetric loss function that was originally proposed by Varian (Citation1975) penalizes exponentially the underestimation (overestimation) and linearly the overestimation (underestimation) according to convenient choices of its parameters. Under the wavelet estimation point of view, its application is interesting once underestimation of significant wavelet coefficients could not detect relevant features of the unknown function, such as peaks and/or discontinuities for example. Huang (Citation2002) and Torehzadeh and Arashi (Citation2014) proposed policies to obtain the threshold value to the soft thresholding rule under LINEX loss function with a Bayesian interpretation of the estimation process; however, the Bayesian shrinkage rule to be proposed in this work allows prior information about the wavelet coefficients to be taken into account in the Bayesian inference about them.
This article is organized as follows: the statistical model is defined in Section 2. The estimation procedure, including the proposed shrinkage rule under LINEX loss, is described in Section 3. Section 4 is dedicated to simulation studies that were conducted to evaluate the performance of the proposed rule. An application in a real dataset about infrared spectra denoising is done in Section 5. Final considerations are in Section 6.
2. Statistical model
We start with the unidimensional nonparametric regression problem, that is, one observes n = 2J points , J∈ℕ, from the model
(2.1)
(2.1)
where
are equidistant scalars,
is an unknown function and
are independent zero mean normal random errors with unknown common variance σ2, σ > 0. The goal is to estimate the function f from the sample
without any assumption regarding the functional structure of f, except that it is squared integrable.
The classical approach to estimate f under the nonparametric point of view is to expand it in terms of some functional basis, such as polynomials, Fourier, splines, and wavelets for example, see Takezawa (Citation2005). In this work, we represent f in model (Equation2.1(2.1)
(2.1) ) in terms of wavelet basis,
(2.2)
(2.2)
where
is an orthonormal wavelet basis for 𝕃2(ℝ) constructed by dilations j and translations k of a function ψ called wavelet or mother wavelet and θj, k are wavelet coefficients that describe features of f at spatial location 2−jk and scale 2j or resolution level j. Note that the problem of estimating f becomes a problem of estimating the wavelet coefficients in (Equation2.2
(2.2)
(2.2) ). In fact, wavelet is a function that satisfies the admissibility condition
, where Ψ(⋅) is the Fourier transformation of ψ. The admissibility condition implies that
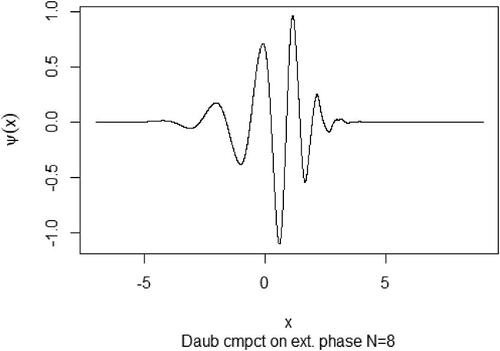
, which motivates the name wavelet. There are several wavelet functions available in the literature, see Vidakovic (Citation1999). For the development of this work, we considered the Daubechies’ compactly supported orthogonal wavelet, that does not have closed form but it is shown in .
Figure 1. Daubechies’ compactly supported orthogonal wavelet with eight null moments.
We can rewrite the model (Equation2.1(2.1)
(2.1) ) in vector notation,
(2.3)
(2.3)
where
,
, and
. We apply a discrete wavelet transform (DWT) on the original data to take them to the wavelet domain. Although DWT is usually performed by fast algorithms such as the pyramidal algorithm, it is possible to represent it by a transformation matrix 𝑾 with dimension n×n which is applied on both sides of (Equation2.3
(2.3)
(2.3) ). Since DWT is linear, we obtain the following model in the wavelet domain
(2.4)
(2.4)
where
is the vector of empirical (observed) wavelet coefficients,
is the sparse vector of unknown wavelet coefficients of f, and
is the vector of random errors. Thus, we can see the empirical wavelet coefficients 𝒅 as noised versions of the unknown wavelet coefficients 𝜽. Further, the random errors in the wavelet domain
remain independent zero mean normal with common variance σ2 since the DWT is orthogonal. We will drop the subindices and consider the model
for a single wavelet coefficient along the text for simplicity.
The estimation of the vector of wavelet coefficients 𝜽 will be done coefficient by coefficient under a Bayesian framework. In this sense, a prior distribution is assigned to a single wavelet coefficient θ that incorporates our knowledge about its sparsity and symmetry around zero. Then, we consider the prior distribution based on a mixture of a point mass function at zero δ0(⋅) and a symmetric around zero logistic distribution
proposed by Sousa (Citation2020),
(2.5)
(2.5)
where
, τ > 0 and 𝕀ℝ(⋅) is the indicator function on the real set ℝ. Thus, the prior distribution has two hyperparameters to be elicited, α and τ. As discussed in Sousa (Citation2020), these hyperparameters control the severity of the shrinkage imposed by the Bayesian rule on the empirical coefficients. In fact, the empirical coefficients are shrunk more for higher values of α and smaller values of τ since the prior distribution becomes more concentrated around zero. In the same work, the author suggests values of τ≤10 and the elicitation of α according to Angelini and Vidakovic (Citation2004),
(2.6)
(2.6)
where
, J0 is the primary resolution level, J is the number of resolution levels, J = log2(n) and γ > 0. They also suggest that in the absence of additional information, γ = 2 can be adopted. Finally, it is necessary to estimate σ for a complete (hyper)parameter elicitation. According to Donoho and Johnstone (Citation1994), based on the fact that much of the noise information present in the data can be obtained on the finer resolution scale, they proposed
(2.7)
(2.7)
3. Estimation procedure
The estimation of the wavelet coefficients vector 𝜽 is done by the application of the Bayesian wavelet shrinkage rule associated to the models (Equation2.4
(2.4)
(2.4) ) and (Equation2.5
(2.5)
(2.5) ) on the empirical wavelet coefficients vector 𝒅, that is, for a single wavelet coefficient θ, its estimator
is
(3.1)
(3.1)
In fact the estimator is a shrunk (denoised) version of the empirical coefficient d. Since we have the estimated wavelet coefficients vector
, the function values 𝒇 are then estimated by the inverse discrete wavelet transformation (IDWT) that can be represented by the transpose matrix 𝑾′,
(3.2)
(3.2)
The Bayesian rule is obtained by minimizing the posterior expected loss
, that is
(3.3)
(3.3)
according to a loss function specification L(δ, θ), which is done depending on the estimation problem and its costs. For symmetric losses as example, the well-known quadratic loss function
is generally applied and its associated Bayesian rule is the posterior expected mean
, see Robert (Citation2007) for a complete development of Bayesian frameworks. In this work, however, we consider wavelet coefficients estimation problem under asymmetric losses, in the sense that underestimation and overestimation of θ lead to different costs. Thus, the LINEX loss function is a very suitable function to be considered in this context. The next subsections describe the LINEX loss function, the associated Bayesian rule, and its statistical properties.
3.1. LINEX loss function
We consider the unidimensional LINEX loss function by Varian (Citation1975) given by
(3.4)
(3.4)
for a≠0 and b > 0. The sign of a indicates the direction of the exponential and linear losses. In fact, for a > 0, the loss is exponential when δ > θ and linear when δ < θ, that is, the loss is greater in overestimation. On the other hand, for a < 0, the loss is exponential when δ < θ and linear when δ > θ, that is, the loss function penalizes more the underestimation. The parameter b controls the general magnitudes of the losses.
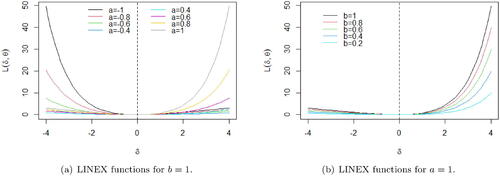
(a) and (b) show the LINEX function L(δ, 0) for , b = 1 and for a = 1,
, respectively. Higher absolute values of a imply in higher losses. For example, in (a), when a = 0. 8,
while for a = 1,
. Thus the loss of an overestimation of 4 units under a = 1 is almost 2.44 times the loss under a = 0. 8. Higher values of b also increase the loss, as can be seen in (b). For example, when b = 0. 8,
, against 49. 59 when b = 1.
Figure 2. LINEX loss functions L(δ, 0) (i.e., the loss when θ = 0) for , b = 1 (a) and for a = 1,
(b).
3.2. Bayesian shrinkage rule
The Bayesian rule δ* is obtained by minimizing the posterior expected loss . According to Zellner (Citation1986), under the LINEX loss function we have
(3.5)
(3.5)
and the Bayesian rule is
(3.6)
(3.6)
where log is the natural logarithm. Note that the Bayesian rule under LINEX loss function does not depend on the parameter b. Finally, it is easy to show that under the model, one has that
(3.7)
(3.7)
where ϕ(⋅) is the standard normal density function and the integrals involved in (Equation3.7
(3.7)
(3.7) ) can be obtained numerically. (a) shows the Bayesian rules for σ = 1, α = 0. 9, τ = 1 and
on the interval
. In this figure, it is possible to observe an important feature: the Bayesian rule (Equation3.6
(3.6)
(3.6) ) is not a shrinkage rule in the sense of wavelet shrinkage for all values of a, although the shape of the rules mimics wavelet shrinkage rules. For example, when a = 4, small values of the empirical coefficient d are not shrunk toward zero by the Bayesian rule. Further, if d = 0 then
. The main idea of a wavelet shrinkage rule is to shrink small empirical coefficients toward zero, even in an asymmetrically way, as it is the case under asymmetric loss functions or priors for the wavelet coefficients θ.
Figure 3. Bayesian rules (Equation3.6(3.6)
(3.6) ) for σ = 1, α = 0. 9, τ = 1, and
(a) and bayesian shrinkage rules (in wavelet shrinkage sense) for
(b).
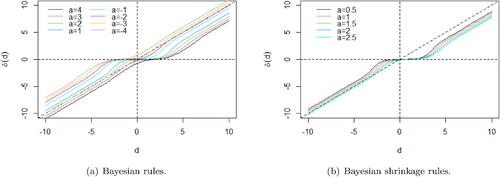
Hopefully, we can obtain shrinkage rules for convenient choices of a, as it is shown in (b), for . Note that the rules shrink small empirical coefficients toward zero in an asymmetrically manner. Moreover, for empirical coefficients far from zero, the rule acts with different severity according to the sign of the coefficient. Since the LINEX loss penalizes exponentially the overestimation when a > 0, the associated shrinkage rules shrink severely empirical coefficients greater than zero to avoid overestimation of θ, given the prior belief that most of the θ’s are zero, and the severity increases for higher values of a. Although it is not shown in the article, the behavior of the rule is similar when a < 0, but in the opposite sense to avoid underestimation.
3.3. Statistical properties of the shrinkage rule
The squared bias of the shrinkage rules (Equation3.6
(3.6)
(3.6) ) for σ = 1, α = 0. 9, τ = 1 and
were obtained numerically and are shown in (a). In fact, the rules have small bias when θ is close to zero and the minimum squared bias is achieved when θ = 0. Since LINEX loss is exponential for δ > θ under positive values of a, that is, the estimation procedure penalizes more overestimation, the squared bias is higher when θ is greater than zero. The shrinkage rule is built under the prior information that most of the wavelet coefficients are zero or close to zero. Then, for coefficients greater than zero, the shrinkage rule tends to underestimate them due to exponential loss imposed by the LINEX loss function against overestimation. Further, the bias increases when a increases, once the loss increases for higher a values. On the other hand, the bias is small when θ is less than zero because the loss is only linear for δ < θ and then, even under the prior belief of sparsity, the estimation procedure allows a good recover of wavelet coefficients less than zero. Analogous interpretation could be made for the frequentist risks
of the rules (Equation3.6
(3.6)
(3.6) ) and displayed in (c).
Figure 4. Squared bias (a), variances (b), and frequentist risks (c) of the shrinkage rules (Equation3.6(3.6)
(3.6) ) for σ = 1, α = 0. 9, τ = 1, and
.
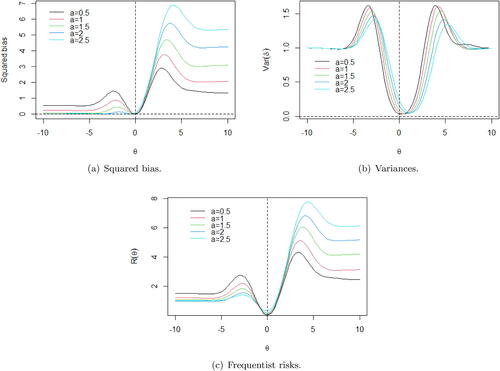
The variances of the shrinkage rules are provided in (b). Unlike the squared bias and frequentist risks, the variances have symmetric shapes and are small when θ is close to zero. They increase as
increases and achieve two maxima. Finally, the variances stabilize close to one for higher values of
. Further, the obtained maxima are higher as the LINEX parameter a decreases.
The general behaviors of the squared bias, variance, and frequentist risk are quite similar. They are small when θ is close to zero, increase until two local maxima and then stabilize for sufficiently high values of . Moreover, the two local maxima occur at the same locations where their associated shrinkage rules leave the x-axis and start to approximate to the line y = x. For example, when the LINEX parameter a = 1 (red curves in ), the global maxima of squared bias, variance, and frequentist risk occur at θ = 3. 12 and are equals to 3.77, 1.12, and 4.99, respectively.
Additionally, the squared bias, variance, and frequentist risk of the shrinkage rule (Equation3.6(3.6)
(3.6) ) seem to achieve limit values for large wavelet coefficients, according to numerical evaluations. show those statistical properties for the shrinkage rule with parameters a = 1, σ = 1, τ = 1, and α = 0. 9 applied to some values of θ. When θ increases in the positive sense,
goes to 2.07269, Varδ(θ) goes to 1.00000, and Rδ(θ) goes to 3.18357. On the other hand, when θ increases in the negative sense,
goes to 0.24752, Varδ(θ) goes to 1.00000, and Rδ(θ) goes to 1.16713.
Table 1. Squared bias , variances Varδ(θ), and frequentist risks Rδ(θ) of the shrinkage rule (Equation3.6
(3.6)
(3.6) ) for σ = 1, a = 1, α = 0. 9, and τ = 1.
Finally, the Bayesian risks rδ = 𝔼π[Rδ(θ)] of the shrinkage rules are available in . We note that the Bayesian risk increases as the LINEX parameter a increases. For example, for a = 0. 5, we obtain rδ = 0. 1521 and for a = 2. 5 we have rδ = 0. 4644, which is almost three times the risk for a = 0. 5. Since shrinkage rules under higher values of a shrink in a more severe way empirical coefficients greater than zero (once the loss is exponential), we have that the Bayesian risks associated to more severe shrinkage rules are greater than less severe ones.
Table 2. Bayesian risks of the shrinkage rule (Equation3.6(3.6)
(3.6) ) for σ = 1, α = 0. 9, τ = 1, and
.
3.4. Comparison with quadratic loss function
The quadratic loss function is perhaps the most considered loss function in statistical decision problems due to several reasons. Under a mathematical point of view, it is more tractably analytically than other loss functions and differentiable. Further, in statistical inference, when it is dealt with an unbiased estimator, the quadratic loss function becomes the variance of the estimator, with several nice properties and a rich theory, see Schervish (Citation1995).
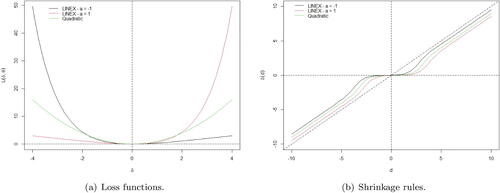
One important feature of the quadratic loss function is the symmetry around θ, which means that underestimation and overestimation with the same magnitudes of a parameter θ by an estimator δ imply in the same polynomial (quadratic) loss. On the other hand, the LINEX loss function penalizes exponentially one side and linearly the other side depending on its parameters, that is, the losses are asymmetric. (a) presents the LINEX loss functions for and a = 1 and the quadratic loss function when θ = 0. Under overestimation, that is, when δ≫0, the LINEX loss for a = 1 is considerably greater than the quadratic loss, as its loss increases exponentially. The LINEX loss for
increases only linearly and has the lowest loss. The same interpretation occurs for the underestimation case, but the roles of the LINEX rules change with each other.
Figure 5. LINEX (, a = 1, and b = 1) and quadratic loss functions for θ = 0, that is, L(δ, 0) (a) and their associated shrinkage rules under the prior model (Equation2.5
(2.5)
(2.5) ) for α = 0. 9 and
(b).
In the Bayesian framework, the rule under the quadratic loss function is given by the posterior expected value of θ, that is, . In this case, Sousa (Citation2020) showed that under the prior model (Equation2.5
(2.5)
(2.5) ), the shrinkage rule is given by
The shrinkage rules under LINEX loss for and a = 1 and the shrinkage rule under quadratic loss and prior model (Equation2.5
(2.5)
(2.5) ) for α = 0. 9 and
are shown in (b). In fact, the shrinkage rule under quadratic loss acts symmetrically around zero and shrinks the empirical coefficients with intermediate severity in both sides. The shrinkage rule under LINEX loss with a = 1 shrinks empirical coefficients greater than zero with strong severity and the rule with
is severe for coefficients less than zero.
In general, the choice of the loss function has a great impact on the behavior of the associated shrinkage rule. Symmetric loss functions like the quadratic assigns equals losses for underestimation and overestimation and imply in a symmetric shrinkage rule. Asymmetric loss functions like LINEX are suitable when the loss of underestimation is different to overestimation. In this case, the associated shrinkage rule is then asymmetric around zero.
4. Simulation studies
Simulation studies were conducted to evaluate the performance of the shrinkage rule (Equation3.6(3.6)
(3.6) ) and to compare it against standard and recent proposed shrinkage and thresholding rules. Wavelet coefficients were generated from a mixture of a point mass function at zero and the beta distribution with right asymmetries given by coefficient of asymmetry (skewness) equals to 0.48 (scenario 1) and 1.73 (scenario 2) and two sample sizes, n = 512 and 2048. Then, empirical wavelet coefficients were obtained from model (Equation2.4
(2.4)
(2.4) ) with iid zero mean gaussian random errors and common variance σ2 selected according to two signal to noise ratios (SNR), SNR = 3 and 9. For each replication, r we applied the proposed shrinkage rule under LINEX loss and the comparison rules to the generated empirical coefficients and calculated the mean squared error (MSE)
and the mean absolute error (MAE)
For each scenario of asymmetry, sample size and signal to noise ratio values, 200 replications were run and the averaged mean squared error (AMSE) and the averaged mean absolute error (AMAE) were calculated as performance measures of the rules, given, respectively, by
and
We compared the proposed shrinkage rule (LINEX - Logistic) against the soft thresholding rules with the threshold value chosen according to the universal thresholding (Universal) proposed by Donoho and Johnstone (Citation1994), cross validation (CV) by Nason (Citation1996) and the Stein unbiased risk estimator (SURE) of Donoho and Johnstone (Citation1995), the bayesian shrinkage rules under symmetric beta prior (Beta symmetric) proposed by Sousa et al. (Citation2020) and asymmetric beta prior (Beta asymmetric) by Sousa (Citation2022), and the soft thresholding rule under LINEX loss proposed by Torehzadeh and Arashi (Citation2014). In all the simulated data, the full DWT was applied by using a Daubechies basis with 10 null moments. Further, the adopted primary resolution level was J0 = 3 for both considered sample sizes. The R package wavethresh (Nason Citation2022) was used to perform the DWT and to apply the thresholding methods Universal, CV, and SURE.
shows the results of the scenario 1 under asymmetric distributed wavelet coefficients with skewness equals to 0.48. The proposed shrinkage rule had great performances for both values of sample sizes and SNR. Actually, the SNR had the main impact on the performances of the rules and the sample size did not have significant influence on them. For SNR = 3, the shrinkage rule under asymmetric beta prior was the best one in terms of AMSE and AMAE. The proposed rule and the shrinkage rule under symmetric beta prior also worked well and had performances close to the asymmetric beta rule one. SURE and the thresholding rule by Torehzadeh and Arashi had intermediate performances and Universal and CV thresholding rules did not worked well. For example, the AMSE and AMAE of the CV thresholding rule were, respectively, 10.24 and 3.38 times the AMSE and AMAE of the asymmetric beta shrinkage rule. For SNR = 9, the proposed rule was the best for both performance measures, with AMSE = 0.0004 and AMAE = 0.0121 when n = 512 and AMSE = 0.0003 and AMAE = 0.0113 when n = 2048. The shrinkage rule under asymmetric beta prior and SURE thresholding rule also had good behavior, but with performances worse than the proposed rule. For example, the SURE thresholding rule (the second best performance) had AMSE and AMAE, respectively, almost 3 and 2 times of the proposed rule ones when n = 2048. On the other hand, the thresholding rule by Torehzadeh and Arashi did not have good performance, which suggests that it works better for low signal to noise ratios.
Table 3. AMSE and AMAE with the standard deviations of the MSEs and MAEs of the shrinkage and thresholding rules for generated wavelet coefficients under asymmetric distribution with skewness equals to 0.48 - scenario 1.
The results of the simulation study under scenario 2 is available in . In fact, the proposed shrinkage rule had the best performance for both measures in the four combinations of sample sizes and SNR. It suggests that the rule works better for denoising higher asymmetric distributed wavelet coefficients. The symmetric and asymmetric beta shrinkage rules also had good performances and so the SURE thresholding rule. It should be noted that the thresholding rule under LINEX loss by Torehzadeh and Arashi did not work well in these contexts. Further, its performance decreased for SNR = 9 under both sample size values. The standard thresholding rules under Universal and CV policies had intermediate performances relative to the comparison rules, but they were overcome by the proposed rule. For example, under n = 512 and SNR = 3, the AMSE and AMAE of CV rule were about 10.34 and 3.34 times of the proposed rule ones respectively.
Table 4. AMSE and AMAE with the standard deviations of the MSEs and MAEs of the shrinkage and thresholding rules for generated wavelet coefficients under asymmetric distribution with skewness equals to 1.73 - scenario 2.
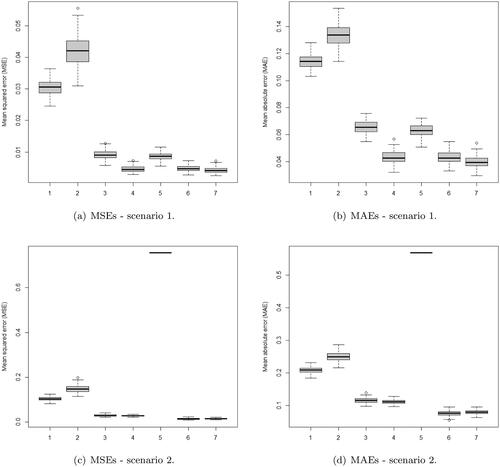
Finally, presents the boxplots of the MSEs and MAEs of the rules in the scenario 1 (a) and (b) and scenario 2 (c) and (d), for n = 512 and SNR = 3. The boxplots of scenario 1 show the well behavior of the shrinkage rules under beta prior and the proposed rule in both measures. Universal and CV had high MSEs and MAEs relative to the others. On the other hand, the boxplots of scenario 2 emphasize the atypical behavior of the thresholding rule of Torehzadeh and Arashi, with MSEs and MAEs considerably higher than the others ones. Similar behaviors were obtained for the other values of sample size and SNR.
Figure 6. Boxplots of MSEs and MAEs of the shrinkage and thresholding rules of the simulation studies in scenario 1 (a) and (b) and scenario 2 (c) and (d) for n = 512 and SNR = 3. The rules are: 1 - Universal, 2 - CV, 3 - SURE, 4 - Beta symmetric, 5 - Torehzadeh and Arashi, 6 - LINEX - Logistic (proposed rule) and 7 - Beta asymmetric.
Thus, the simulation studies showed that the proposed shrinkage rule can be considered under asymmetric distributed wavelet coefficients context as an alternative to the shrinkage rule under asymmetric beta prior. Their performances were close to each other and for higher kurtosis value, the proposed rule overcome the asymmetric beta shrinkage rule for both measures and all the combinations of sample size and SNR. These results show that although the simulated wavelet coefficients were generated under beta asymmetric distribution with parameters according to the considered kurtosis, which allowed some advantage in the estimation process to the shrinkage rule under asymmetric beta prior in the scenario 1 for SNR = 3, this advantage was not observed in the scenario 2 against the shrinkage rule under LINEX loss and even in the scenario 1 for SNR = 9. In fact, when the chosen parameters of the shrinkage rule under asymmetric beta are not closed enough to the parameters of the distribution which generates the data, its performance is reduced for higher values of kurtosis (scenario 2) and signal-to-noise ratio. The hyperparameters of the asymmetric beta shrinkage rule were chosen according to Sousa (Citation2022) and they are different of the parameters of the beta distribution in the data generation procedure in the simulation studies, which were defined according to the kurtosis value for each scenario.
5. Application in real dataset
Serenoa repens or Saw Palmetto is a palm native from North America whose extracted essential oil is applied in several medical treatments, such as Benign Prostatic Hyperplasia (BPH) in men, disorder of urinary system, sexual impotence, and others. When the essential oil is adulterated by the addition of substances such as olive oil, the contaminated oil loses its chemical and biological properties and becomes inactive against BPH for example. Chemists usually apply infrared (IR) spectroscopy on samples of Saw Palmetto essential oil to detect peaks of absorbance and classify a given sample in pure or adulterated.
(a) shows the IR spectra of a sample of pure Saw Palmetto oil in points. This dataset is available in the R package ChemoSpec by Hanson (Citation2023). Actually the complete dataset consists of IR spectra of 14 samples of pure and adulterated samples in 1868 points. The particular data considered here is the IR spectra of the second oil sample and the considered sample size is the closest dyadic number that is smaller than 1868, i.e,
. Since the goal is to obtain the peaks of absorbance, it is necessary to filter the data and remove noise that can lead to a misclassification of a peak. In this sense, the application of a wavelet shrinkage rule is suitable to denoise this data.
Figure 7. Infrared spectra of Saw Palmetto essential oil (a) and its empirical wavelet coefficients by resolution level after a DWT application (b).
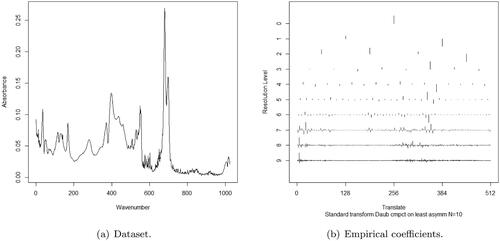
The first step is to obtain the full DWT of the data. (b) presents the magnitudes of the empirical wavelet coefficients of the dataset by resolution level. The considered wavelet basis was Daubechies with 10 null moments. In fact large empirical coefficients in the coarser resolution levels are associated to the positions of the absorbance peaks. On the other hand, the empirical coefficients in the finest resolution level are typically related to noise. The wavelet shrinkage rule acts mainly in these coefficients by reducing their magnitudes.
The proposed shrinkage rule (Equation3.6(3.6)
(3.6) ) was applied in the empirical coefficients and the denoised version of the IR spectra was recover by the IDWT application (Equation3.2
(3.2)
(3.2) ). The chosen parameter of the LINEX loss function was a = 1, the scale hyperparameter of the logistic density in the prior (Equation2.5
(2.5)
(2.5) ) was τ = 5, the hyperparameter α was chosen to be level dependent according to (Equation2.6
(2.6)
(2.6) ), the estimated standard deviation was
according to (Equation2.7
(2.7)
(2.7) ), and the adopted primary resolution level was J0 = 3. The obtained denoised IR spectra is showed in (a). It is possible to observe the action of denoising in the wavenumber interval [500, 700] and [800, 1024], where local noise peaks were smoothed. (b) presents a plot of the empirical coefficients in the interval
versus estimated wavelet coefficients. This plot is interesting to see the range of shrunk coefficients, which occurred mainly in the interval of empirical coefficients
. Once the signal-to-noise ratio of the data is high, the shrinkage rule was active only in small empirical coefficients typically localized in the finer resolution levels. This procedure can be applied in the other samples for better identification of peaks and noise removal.
Figure 8. Denoised version of the infrared spectra of Saw Palmetto essential oil by the application of the shrinkage rule under LINEX loss function (a) and empirical coefficients in versus estimated (shrunk) wavelet coefficients (b).
![Figure 8. Denoised version of the infrared spectra of Saw Palmetto essential oil by the application of the shrinkage rule under LINEX loss function (a) and empirical coefficients in [−0.10,0.10] versus estimated (shrunk) wavelet coefficients (b).](/cms/asset/9517b848-d0db-48b4-9351-390b16ad7b62/urst_a_2362926_f0008_b.jpg)
6. Final considerations
The present work proposed a wavelet shrinkage rule under LINEX loss function and a mixture of a point mass function at zero and the logistic distribution as prior distribution to the wavelet coefficients. The application of this rule is suitable when overestimation and underestimation of the coefficients have asymmetric losses. In the wavelet domain, underestimated significant coefficients can lead to a bad detection of important features to be recovered of the unknown function such as peaks, discontinuities and oscillations. In this sense, to assign higher losses to underestimation should be interesting. Further, the simulation studies suggested a good performance of the proposed shrinkage rule in terms of averaged mean squared error and averaged mean absolute error measures to estimate asymmetrically distributed wavelet coefficients against standard shrinkage and thresholding rules.
The magnitudes of the losses and the severity that the empirical coefficients are shrunk by the rule are well controlled according to convenient choices of the parameters of the LINEX function and the hyperparameters of the prior distribution, which is important to have flexibility in real datasets analysis. The impact of the wavelet basis in the estimation process and the proposal of other asymmetric loss functions are suggested as future works.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Angelini C, Vidakovic B. 2004. Gama-minimax wavelet shrinkage: a robust incorporation of information about energy of a signal in denoising applications. Stat Sin. 14:103–125.
- Chipman HA, Kolaczyk ED, McCulloch RE. 1997. Adaptive Bayesian wavelet shrinkage. J Am Stat Assoc. 92:1413–1421. doi:10.1080/01621459.1997.10473662.
- Donoho, DL. 1993. Nonlinear wavelet methods of recovery for signals, densities, and spectra from indirect and noisy data, Proceedings of Symposia in Applied Mathematics, Vol. 47. American Mathematical Society; Providence, RI.
- Donoho DL. 1995. De-noising by soft-thresholding. IEEE Trans Inform Theory. 41:613–627. doi:10.1109/18.382009.
- Donoho DL, Johnstone IM. 1994. Ideal spatial adaptation by wavelet shrinkage. Biometrika. 81:425–455. doi:10.1093/biomet/81.3.425.
- Donoho DL, Johnstone IM. 1995. Adapting to unknown smoothness via wavelet shrinkage. J Am Stat Assoc. 90:1200–1224. doi:10.1080/01621459.1995.10476626.
- Donoho DL, Johnstone IM, Kerkyacharian G, Picard D. 1995. Wavelet shrinkage: Asymptopia?. J. Royal Stat. Soc. Ser. B: Stat. Methodol. 57:301–337. doi:10.1111/j.2517-6161.1995.tb02032.x.
- Hanson B. 2023. ChemoSpec: Exploratory Chemometrics for Spectroscopy. R package version 6.1.9. URL: https://bryanhanson.github.io/ChemoSpec/
- Huang S-Y. 2002. On a Bayesian aspect for soft wavelet shrinkage estimation under an asymmetric Linex loss. Stat Probab Lett. 56:171–175. doi:10.1016/S0167-7152(01)00181-X.
- Nason GP. 1996. Wavelet shrinkage using cross-validation. J Royal Stat Soc Ser B: StatMethodol. 58:463–479. doi:10.1111/j.2517-6161.1996.tb02094.x.
- Nason GP. 2022. wavethresh: Wavelets Statistics and Transforms. R package version 4.7.2. URL: https://cran.r-project.org/web/packages/wavethresh/index.html
- Reményi N, Vidakovic B. 2015. wavelet shrinkage with double Weibull prior. Commun Stat - Simul Comput. 44:88–104. doi:10.1080/03610918.2013.765470.
- Robert C. 2007. The Bayesian choice: from decision-theoretic foundations to computational implementation. New York (NY): Springer.
- Schervish MJ. 1995. Theory of statistics. New York (NY): Springer.
- Sousa ARS. 2020. Bayesian wavelet shrinkage with logistic prior. Commun Stat Simul Comput. 51:4700–4714.
- Sousa ARS. 2022. Asymmetric prior in wavelet shrinkage. Rev Colomb Estad. 45:41–63.
- Sousa ARdS, Garcia NL, Vidakovic B. 2021. Bayesian wavelet shrinkage with beta priors. Comput Stat. 36:1341–1363. doi:10.1007/s00180-020-01048-1.
- Takezawa K. 2005. Introduction to nonparametric regression. New York (NY): Wiley.
- Torehzadeh S, Arashi M. 2014. A note on shrinkage wavelet estimation in Bayesian analysis. Stat. Probab. Lett. 84:231–234. doi:10.1016/j.spl.2013.10.006.
- Varian HR. 1975. Studies in Bayesian Econometrics and Statistics in Honor of, Leonard J. Savage. A Bayesian approach to real estate assessment. Amsterdam: North-Holland. p. 195–208.
- Vidakovic B. 1999. Statistical modeling by wavelets. New York (NY): Wiley.
- Vidakovic B, Ruggeri F. 2001. BAMS method: theory and simulations. Sankhya: Indian J Stat Ser. B. 63:234–249.
- Zellner A. 1986. Bayesian estimation and prediction using asymmetric loss functions. J Am Stat Assoc. 81:446–451. doi:10.1080/01621459.1986.10478289.