
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Cloud database services platforms (CDSP) have aided in both the generation of new ideas and the reduction of costs. Choosing the finest CDSP is a critical part of enterprise management for helping businesses respond to increasing market pressure and client demand. This study tried to solve this problem and proposed the integration concept of the TODIM (TOmada de Decisão Interativa e Multicritério) and the probability uncertain linguistic (PUL), which is a typical decision-making technique focused on the theory of prospects (PT-PUL-TODIM). The concept of probability uncertainty linguistic term sets (PULTS) is discussed. The cumulative weight of probabilistic double hierarchy linguistic knowledge is then determined by using the following cumulative prospect theory. Based on the experts’ opinions, complex expressions with experience in the Vietnam market were collected and further transformed into a PULTS matrix. However, the CRiteria Importance Through Inter-Criteria Correlation (CRITIC) technique is implemented to calculate the objective criteria weights. The PT-PUL-TODIM optimization approach is developed and adopted for the CDSP. Finally, we compared other methods and conducted a sensitivity analysis to compare the PT-PUL-TODIM approach with other ways to assess the validity, practicality, and usefulness of the technique, and the comparison revealed the merits and limitations of the model.
1. Introduction
Zadesh (1965) was the first to mention fuzzy sets (FS) [Citation1]. Novel fuzzy set concepts, including intuitionistic fuzzy sets (IFS) [Citation2], picture fuzzy sets (PFS) [Citation3] and Pythagorean fuzzy sets (PyFS), have been developed one after the other [Citation4,Citation5]. According to Liu et al. [Citation6], a new concept of normal wiggly hesitant fuzzy linguistic term set (NWHFLTS) has been a more significant instrument for assisting us in locating additional appropriate data. For probabilistic linguistic word sets, [Citation7] developed a new probability linguistic term set (PLTS). Mo [Citation8] combined PLTS with D number theory. Under PLTS, Du and Liu [Citation9] created multi-Muirhead average operators. Under PLTS, He et al. [Citation10] proposed the generalized Dice similarity metric. Lin et al. [Citation11] define a new set of linguistic terms called probabilistic uncertain linguistic terms set (PULTS). The probabilistic uncertain linguistic (PUL) and the grey relational projection (GRP) approach were defined by [Citation12]. Aisaiti et al. [Citation13] developed the PULTS preference relation. He et al. [Citation14] developed the Evaluation based on Distance from Average Solution (EDAS) within the context of PULTS. X. Gou et al. [Citation15] developed an MCDM method named the probabilistic double hierarchy linguistic alternative queuing method (PDHL-AQM), where the decision-making result is intuitive by a directed graph or a 0–1 precedence relationship matrix, which applied the PDHL-AQM to solve a practical MCDM problem involving the real economy development evaluation under the perspective of economic financialization. Krishankumar et al. [Citation16] presented a new big data-driven decision model with data in the form of complex expressions, which were transformed into a holistic decision matrix by adopting probabilistic linguistic information and based on the distance from average solution (EDAS) approach is extended to probabilistic linguistic information for the rational ranking of cloud vendors selection for a healthcare center in India. Ramadass et al. [Citation17] proposed the PROMETHEE–Borda method is extended to PLTS for the evaluation of cloud vendors from probabilistic linguistic information with unknown/partial weight values. Feng et al. [Citation18] developed a QUALItative FLEXible (QUALIFLEX) multiple criteria model based on PULTS. Wei et al. [Citation19] examined the Multi-Attributive Border Approximation area Comparison (MABAC) technique in a PULTS setting. Bashir et al. [Citation20] developed new PULTS procedures, metrics and operators.
The TOmada de Decisão Interativa e Multicritério (TODIM) refers to interactive multi-criteria decision-making [Citation21–24], MABAC means multi-attributive border approximating areas comparisons technique [Citation19,Citation25], the VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR) method [Citation26–30], the Evaluation based on Distance from Average Solution (EDAS) typically, these strategies are employed to address the multi-attribute decision-making (MADM) or (MAGDM) difficulties [Citation14,Citation24,Citation31–33]. The cosine similarity-based DHHFL-ELECTRE II method was proposed to solve MADM problem in the double hierarchy hesitant fuzzy linguistic environment in the performance evaluation of financial logistics enterprises [Citation34]. The TODIM technique is different from these well-known systems due to its diverse treatment of profits and losses. According to He et al. [Citation24], TODIM could be utilized to identify the optimum river-water transfer strategy [Citation35] performed an additional application research based on the TODIM methodology for the site location of low-speed wind turbines. To avoid multicollinearity, [Citation22,Citation36,Citation37] devised the TODIM approach in a fuzzy Pythagorean environment with interval values, [Citation38] enhanced the standard TODIM technique's applicability in a green supplier chosen using probabilistic hesitant fuzzy information. In a fuzzy T-spherical environment [Citation39] employed the TODIM approach. Luo and Liang (2021) evaluated the quality of cleaning products using the TODIM approach. The TODIM technique was defined by [Citation40] as an interval-valued intuitionistic fuzzy set (IVIFSs). Zhao et al. [Citation41] developed a behavioural linguistics distribution model of MCGDM using the TODIM approach. Arya and Kumar [Citation28] used an image fuzzy set to merge the TODIM and VIKOR methods (PFS). Luo et al. [Citation7] suggested a TOPSIS-TODIM hybrid model in their investigation of the fuzzy set of linguistic pictures created from PFS. However, the newly proposed intuitionistic fuzzy statistical variance method and finally, ranking of cloud vendor is done using newly proposed three-way VIKOR method under intuitionistic fuzzy environment which introduces neutral category along with cost and benefit for better understanding the nature of criteria [Citation42].
According to a survey of existing studies, there have been many studies applying the classic TODIM approach. In fact, the TODIM approach has been expanded from the numerical value to various fuzzy sets, and it has been integrated with other decision methods. Based on Li et al. [Citation43] addressed multiple-attribute group decision-making challenges utilizing interval intuitionistic fuzzy set theory, a technique analysis of existing TODIM is discussed, in addition to an application that focuses on the facility location of airport terminals to illustrate the method. Irvanizam et al. [Citation44] proposed based on the TODIM technique employing MCDM was described across an assessment for finding solutions and a smartphone selection problem. The proposed design utilized triangle fuzzy set theory to adjust the linguistic terms of the set of criteria weights and applied therefore the average score of Beta distribution to convert the triangular fuzzy values into crisp values. When evaluating the degree of dominance for every alternative pairing focused on loss and gain, the TODIM technique may identify the best smartphone depending on the recommendations of the decision maker [Citation45]. Extending the concept of evidence theory, a ranking model under probabilistic hesitant fuzzy set (PHFS) was proposed, which was a robust form of the hesitant fuzzy set that correlates occurrence probabilities with numerous membership grades, providing flexibility to experts during preference elicitation and facilitating the right management of uncertainty. Irvanizam et al. [Citation46] suggested an expanded TODIM decision-making technique towards multiple-attribute decision-making (MADM) issues in a linguistics context applying dual-connection numbers (DCNs). The weights of attributes are determined by using CRITIC in the non-linear space. Following this, cloud vendors are ranked in a personalized fashion using the proposed algorithm that encompasses the WASPAS procedure and rank fusion schemes [Citation47]. The extensive method incorporates fuzzy linguistics that the scores of alternatives and criteria for all these are expressed as triangular fuzzy numbers (TFNs) to convey uncertainty information. A cadre selection problem is used as an example to demonstrate the conformance and validity of the extended TODIM technique and to compare it with other methods. The compromise between the strengths of the prospect theory with the TODIM approach; scenario research involving the NSSP decision-making problems was provided to highlight the value of the proposed techniques [Citation37]. The application of CPT-SVN-TODIM method was developed by [Citation48], which is used in the assessment of medical emergency management. The reliability of the CPT-SVN-TODIM method is confirmed by comparing it with some other methods. However, limited investigations have been conducted to modify the TODIM approach by incorporating unique theoretical ideas into the TODIM model [Citation38,Citation41,Citation49]. PT was proposed, which altered the factors influencing choice outcomes from probability and final resources to weighting and potential losses [Citation37,Citation50]. Integration of PT and TODIM with PULTS to provide any type of decision maker with a robust psychology explanation and accurate actual data. Using the PT-PUL-TODIM technique to identify cloud database service providers (CDSPs) becomes extremely beneficial for business managerial decisions.
Based on the above motivation, the innovations and the primary contributions of this research within the prospect theory focused TODIM proposed model developed within the perspective of PUL to MADM and MAGDM provide as follows:
Give a weight-determining method to obtain the weight vector of criteria, which is the important element in the process of decision-making using the PT-PUL-TODIM.
Develop the CRITIC to calculate the objective weight of attributes under PULTSs, which to deal with MAGDM problem for PT-PUL-TODIM model is proposed.
Apply the PT-PUL-TODIM technique to solve a practical MAGDM problem involving the CDSPs. Additionally, some comparative analyses are made to show the advantages and reasonableness of the PT-PUL-TODIM.
A case study relate to the evaluation critical factors that impact the selecting of cloud database providers is conducted with the model constructed based on PT-PUL-TODIM. The decision result can provide some reference values for the enterprises to make decisions and also to adjust products and services for increasing clients’ satisfaction.
The proposed model in this paper is compared with the existing models.
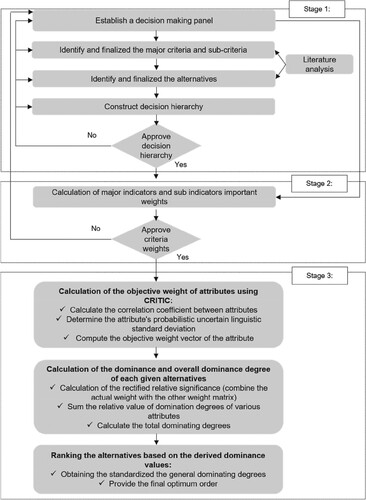
The following are the article's primary sections: basic theoretical information on PULTS is introduced in Section 1. In Section 2, the prospect theory, which represents the main idea behind the new method, is explained in more detail. The most important part of this work is Section 3, which discusses the article's proposed approach. The CDSPs are the focus of the example in Section 4. Finally, to determine whether it satisfies the specified technique’s application effect, in Section 5, we selected different current techniques in the probability uncertain linguistic environment and evaluated by comparing the others with the PT-PUL-TODIM technique. A flow chart is drawn to show the main work of this paper in Figure .
Figure 1. The flow chart of the proposed TODIM method.
2. Preliminary knowledge
In this section, we start to explain several fundamentals concerning the probability uncertain linguistic term set (PULTS).
Theorem 1:
[Citation51]: is an illustration of the common LTS
whereby each characteristic
represents for a linguistic. The classification method
could assist us to replace the definition
onto the evident
.
(1)
(1) In contrast, the function
restores the sharp
to the linguistic term
in the reverse direction.
(2)
(2) Following the development of the hesitant fuzzy term sets (HFTS) and probability linguistic term sets (PLTS), Lin et al. (2018) established the probability uncertainty linguistic term sets (PULTS).
Theorem 2:
[Citation52]: According to the , as PULTS are formulated with:
(3)
(3) where
are the lowest and highest points of uncertain linguistic term (ULT)
, respectively
. In addition,
represents the corresponding probability of ULT
, as well as the overall quantity of ULT in PULTS
is #
.
Specifically, it is required to synthesize the original PULTS if there is an exclusion or crossing connection between various separate ULTs in the equation . For purposes of inclusion, the more comprehensive ULT is further segmented, such as in the following:
are divided into
so that
For crossovers, relatively similar part is differentiated out of existing PULTSs, for illustration,
is turned into
.
Theorem 3:
[Citation11]: According to the , the PULTS
compatible with standardization easel
.
Theorem 4:
[Citation11]: In facilitating the computation of PULTS, we generally perform the following minimal ULTs with zero probability from PULTS
is added in PULTS
.
Theorem 5:
[Citation11]: The expectation value and deviation value
of PULTS
are respectively defined by the following equations (4) and (5).
Moreover, there are following rules for any two PULTSs:
First, when , we can directly acquire that
. Second, when
and
, we can also get the identical conclusion that
. Finally, if and only if
and
appears.
(4)
(4)
(5)
(5)
Theorem 6:
[Citation53]: If we assume that and
are both PULTS, therefore the formula (6) is the Hamming distance expansion. (#PU
(6)
(6)
3. The PT-TODIM technique with PULTS for MAGDM
3.1 The theory of prospects
This concept also explains how individuals regularly adopt unreasonable or inconsistent decisions [Citation54]. Even though prospect theory has been utilized to explain decision-making in economics, law, political science and medical fields, its applications to interpreting decision in the implementation of CDSP has not been explored [Citation55]. The perspective that a decision maker’s choice can be influenced by two factors, advantages, but also loss, and decision weights, is demonstrated by prospect theory (PT), which illustrates this viewpoint as demonstration. This distinctive approach was defined by [Citation50] through the utilization of the following equations (7)–(8), the prospects operate , the values function
and calculate the weights perform
as follows as Equation (9):
(7)
(7)
(8)
(8)
(9)
(9)
For the value function , the value
indicates gains for decision-makers if the real value
is not smaller than all the chosen normal point
. If not, its value
will result in losses for decision makers. During actual decision-making, decision-makers with distinct types of personalities have varying psychological evaluations of profit and losses. Therefore, the variables
and in equation (8) represent the decision makers’ psychology. In summary, the bigger overall acceptable risk of the decision maker, the higher the value of
relative to
and
. Throughout most situations, the decision maker is risk adverse, which corresponds to
including
.
The adjustment of the probabilities that have been skewed as a result of the psychology of the decision makers is represented by the weight function . According to Kahneman and Tversky (1979) research, the psychology of decision makers can have an impact on how such individuals think about the objective probability that an event will take effect. As a result, to reach a decision that is more precise, it is essential to adjust the value of the subjective probability according to the weights function
. The curve of the weights function
is represented by the values of
.
3.2 The integration of PT-PUL-TODIM technique
This research aims to develop an innovative PULTS of MAGDM concept based on the integration of the theory of prospects and TODIM methods. In this part, we will describe how this new model actually functions. There is pertinent background information in the following. represent sets of options, attributes and decision-makers, in which the attribute weight values are fully unidentified. In addition, decision-makers use the uncertainty linguistic term sets (ULTS) to articulate their perspectives that are compiled in
ULTS decision matrix:
Consequently, the following is the detailed procedure:
Step 1: Changing the negative attributes must be transformed into a positive one for ensuring information accuracy. Specifically, if such a value of the negative attributes is , then it should be transformed into
.
Step 2: Using the persistent ULTS decision matrix and Theorem 3, the pretreatment and reorganized PULTS matrices may be obtained as . Significantly,
represents the potential of ULTS
showing in alternatives
within attributes
.
Step 3: Determine the weight value using the CRITIC method [Citation56]. Criteria Importance Through Inter-Criteria Correlation (CRITIC), which was proposed by Diakoulaki, Mavrotas, and Papayannakis (1995), will be discussed in this part to determine the objective weights of attributes. The precise computation algorithms for this combined weight methodology are provided below.
Construct the probabilistic uncertain linguistic correlation coefficient matrix
by calculating the correlation coefficient between attributes using Equation (10)
Determine the attribute's probabilistic uncertain linguistic standard deviation
As in Equations (12) and (13), compute the objective weight vector of attribute
4. Case study and sensitivity analysis
4.1. Case study of CDSPs selection in Vietnam
The enterprise aiming a complete digital transformation must plan for the use of a cloud database. The adoption of technology will provide them with greater flexibility and agility while also lowering risk and operational expenses. There is no generally applicable solution. Each enterprise must first set priorities. Only then can a cloud database service provider that matches its requirements be found. For each enterprise, it is critical to adopt cloud database services for data storage, and increasingly, analytics and computation. This implies that enterprises are essentially outsourcing a great deal of anxiety that comes with storing and maintaining large amounts of data. Space, power utilization, networking infrastructure, and security become problems for cloud database service providers, who are generally well-equipped to cope with them. Another significant advantage of employing cloud database solutions is that enterprises may be highly scalable. Most provide plans that allow them to start small and gradually increase the amount of storage capacity available as their demand develops.
Our investigation was started at the beginning of 2022; at this step of the suggested model, several round-table discussions with members of the board were conducted. The study's entry requirements and decision options were created with consultation from an expert panel. The panel members were chosen from a pool of talented capable professionals, with multiple criteria taken into consideration. Researchers discovered that expertise in the cloud database services industry was the most important attribute. The second condition was advanced-level professional experience (at least ten years as a senior executive or company owner in the field), and the third requirement was member of the executive of a corporation. If necessary, this is the first exhaustive and extensive evaluation of expert opinion over a lengthy period. All of these experts participated in a face-to-face discussion, where they were first asked open-ended questions and then tasked with compiling a list of the necessary criteria and alternatives for evaluating the impact variables associated with CDSP adoption. After collecting these lists, redundant selection criteria and alternatives were deleted, leaving the final selection criteria and alternatives. The membership of the board of experts is provided in Table .
Table 1. The board of experts and their detail
Additionally, providers all provide additional services that can meet enterprises’ analytics and data visualization demands without their valuable data ever leaving the safety of the cloud. Selecting the best cloud database services provider (CDSP) from the market is a crucial enterprise management decision-making activity, in accordance with the benefit-and-return principle. The evaluation of CDSPs usually is based on the following four aspects: (1) is the improving agility and innovation; (2)
is the lower cost; (3)
is the faster time to market; (4)
is the reducing risks. In addition, panel members
provided relevant validation data to five CDSPs
, as shown in Tables .
The example that follows illustrates how PT-PUL-TODIM can be used in CDSP selection.
Table 2. The ULT matrix .
Table 3. The ULT matrix .
Table 4. The ULT matrix .
Table 5. The ULT matrix .
Table 6. The ULT matrix .
Step 1: Tables contain the outcomes of the transformation, which is to make the negative attribute into a positive one.
Table 7. The standard ULT matrices with .
Table 8. The standard ULT matrices with .
Table 9. The standard ULT matrices with .
Table 10. The standard ULT matrices with
Table 11. The standard ULT matrices with .
Step 2: Using the persistent ULTS decision matrix and Theorem 3, we obtain the pretreatment and reorganized PULTS matrices as
, as shown in Table .
Table 12. PULTS matrices with .
Step 3: As with Equations (10)–(13), CRITIC technique is adopted like a method for finding the objective weight vector of attribute
Step 4: According to the deviations of attribute probabilities in PT, Equations (14) and (15) combine the actual weight with the other weight matrices to exactly the right attribute weight, and Table presents finally the rectified relative significance
is calculated (Note that the value of constants
in Equation (14) were being taken from Kahneman's (1992) observational evidence).
Table 13. Rectified relative significance.
Step 5: Compute the relative dominance degree based on Equation (17), the results can be found in Table . In fact, Table shows the distance
calculated using Equation (16). By then, all values of the relative domination level that correlate to the same attributes can be recorded in the same matrices
. (Note that parameter values estimated
in Equation (17) were obtained by [Citation57]).
Table 14. Distance between each two alternatives.
Step 6: Using Equation (19), sum the value of the relative domination degrees for various attributes to get the total dominating degrees
. Gather the results into matrices
one at a time.
Step 7: Using Equation (21), obtain the standardized general dominating degrees
that serve as the ultimate criterion for identifying the optimum path. In general, the higher value of
, the better option.
4.2. Sensitivity analysis
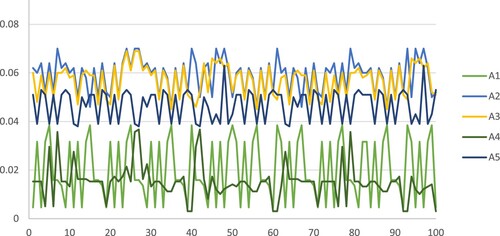
To demonstrate that the results obtained by this technique are stable and resistant to modification by the vector of weighting factors. Then, using the Sensitivity Analyzer App, we generated 100 sets of random numbers with 5 values and a sum of one as the values of the weights for the criteria. In addition, a single of the criteria carries the most weight in every set. As depicted in Figure , the proposed technique has been used again to compute the results, and the mean scores of 100 sets of weights have been obtained. The overall average is proportional to the alternative ordering, so the alternative ranking can be derived from Figure . Still, we can observe that alternative A2 has always been superior to all other alternatives and is compatible with the optimal solution we determined in Section 4.1. Accordingly, the method we developed has a high level of stability, and its findings are robust to changes in criterion values. In addition, it demonstrates further that outcomes of the TODIM approach in MAGDM are reliable and not susceptible to external interference; consequently, much more precise results can be obtained when compared to other ranking methods.
Figure 2. The score of alternatives in different criterion sets.
5. Solving the case with some existing techniques and comparative analysis
5.1. Solving the case with some existing techniques
5.1.1 Solving the case by the PUL-EDAS and PUL-GAR
In this part, PUL-EDAS [Citation14] and PUL-GAR [Citation19] have been chosen and calculated using the same starting data. Table shows the results of the final calculation. The theory of prospects and PUL-TODIM technique and another two approaches all generate the same consistently acceptable outcome, demonstrating the predictability of the new PT-PUL-TODIM model's decision-making outcomes. The PT-PUL-TODIM model indicates the proposed variation is observed between alternative solutions. Furthermore, from the point of view of model ideology, our proposed technique completely accommodates the contribution of DM's psychology to decision results.
Table 15. The ranking result of based on PUL-EDAS and PUL-GAR techniques.
5.1.2 Solving the case by the PDHL-VIKOR method
We try to solve the case by the PDHL-VIKOR method [Citation42,Citation58]. Since the following method may be affected by the values of the criteria weights, we use the maximum deviation method [Citation59] to determine the weight information first.
We get the following optimization model to determine the weight vector of criteria:
(22)
(22) According to the Lagrange function, the formula above in Equation (22) can be solved and the weight of each criterion can be obtained by
(23)
(23) Thus, using Equation (23) we get the vector of the criteria weights. The three measures of the VIKOR method are calculated. Therefore, the ranking of alternatives based on three measures is shown in Table .
Table 16. The numerical results and rank derived by the PDHL-VIKOR.
From the result based on the PDHL-VIKOR method, the ranking of the five alternatives can be obtained as and the most best CDSP is
.
5.2 Comparative analysis
The PT-PUL-TODIM is developed given the following benefits: probabilistic uncertainty linguistic terms are close to managers’ and businesses’ decision-marking linguistic phrases. A new PULTS for the MAGDM approach focused on the integration of the theory of prospects and TODIM methods to examine the significance levels and probability distribution of linguistic terms. In other words, decision-makers often hesitate among many linguistic terms and have varying preferences. The primary and differentiating concept of the PT-PUL-TODIM technique is matched among multi-criteria methods with minimal implementation complexity and high predictive power, given that it is founded on a value function that adheres more closely to prospect theory.
Additionally, based on the PDHL-VIKOR method, we conclude that alternative A2 is the compromise solution, and we cannot obtain the compromise solution when we employ the traditional VIKOR method. By deleting the second hierarchy linguistic terms and the probability information, respectively, the optimal alternative is A2 based on the existing methods in probabilistic linguistic environment [Citation35,Citation39,Citation60,Citation61]. Although the optimal alternative of all methods discussed above is the same as A2, their final rankings are different as shown in Table .
Table 17. Ranking results based on different methods.
Considering the lack of knowledge or the loss of assessment data, some experts do not provide any evaluation information for an attribute. In the framework of the language phrase, the decision-making challenge with missing evaluation values can be transformed into a probability problem. It can be used to explain unknown and uncertain values rather than replace them with null values, which is crucial for collaborative decision-making and large data decision making.
5.3. Discussion
From the preceding analysis, it is evident that the order determined by the PT-PUL-TODIM approach differs slightly from that determined by PUL-EDAS, PUL-GAR and PDHL-VIKOR. These three approaches provide the same optimal alternative, which is A2. This demonstrates that the strategy we suggested is acceptable and effective for this study. The cloud database service providers in Vietnam can be a solid ground for developing best practice guides regarding digital transformation and digital economics, which have an immediate need for a set of effective decision-making models based on selecting CDSP evaluation challenges. There is now the PT-PUL-TODEM to provide a better choice strategy for MAGDM scenarios, which is significant for clients and enterprises. Information from the surveys was conducted to determine and rank the criteria for success supported by the experts’ opinions and a review of the relevant literature. Five criteria from the available CDSP evaluation literature are employed in this regard. Five experts in the field of cloud database services information for evaluating sustainable CDSP. The analysis results found that improving agility and innovation, lower cost, faster time to market, and reducing risks which were impacted by selecting cloud database service provider followed, and the ranking of alternatives is followed by A2 > A3 > A5 > A4 > A1.
The core concept of each technique may result in fine distinctions between negative and positive characteristics, but the concentration is on MADM in the actual number. In addition, the initial weight vector of the attributes is regarded as the ultimate weight vector. Integration of the information entropy and EDAS method under PULTS provides an integrated model, in which information entropy is used for deriving the priority weights of each attribute and EDAS with PULTS is used to determine the final ranking of all alternatives. In addition, the PUL-GAR technique, which combines weight information, emphasizes only the degree of distance near the frontier approximate solution region for all attributes. The primary objective of PUL-GAR is to simplify the computation of PULTS through an effort to accomplish extra precise numerical results. PUL-GAR becomes a simple yet reliable mathematical approach that may be integrated with many other techniques; the prospective profits and losses are regarded to ensure that the overall ranking outcome may become detailed. VIKOR is a decision-making technique for selecting a compromise solution that is closest to the positive ideal solution and obtaining the compromise solution [Citation7,Citation28,Citation62]. Gou et al. [Citation29] introduced the theory of a probabilistic double hierarchy linguistic term set and then presented the PDHL–VIKOR approach, which was the expanded form of VIKOR in a PDHL environment. Particularly, the PDHL-VIKOR is more exhaustive since it considers the links between each alternative and both positive and negative ideal solutions. Our suggested PT-PUL-TODIM technique takes psychological aspects that influence the behaviour of decision markers into greater account. In addition, the comparison between the suggested technique and early standardization and distance measurement reveals disparities. In the meantime, we approach the model approach construction differently. The theory of He et al. [Citation14] is limited in its scope of applicability and understanding of random dominance. Therefore, we utilized the cumulative prospect theory which is studied by Wei et al. [Citation19] to overcome the above limitation.
6. Conclusion and future research directions
Our proposed technique in this study does have an important improvement over existing techniques regarding the general development of the concept logic structure. The merits of the PT-PUL-TODIM method established in this article include: (1) the proposed model is an expansion of the traditional TODIM approach; (2) the method improves the way MAGDM problems are solved; (3) the model generates an original PUL evaluation model; (4) the method is effectively implemented for the selection of cloud database service providers with novel data transformation, data imputation and decision making; (5) the sensitivity analysis of the significance of the criteria’s and reveals the robustness of the model. To ensure the application effect, the proposed technique was compared with the three present approaches. The method integrates the benefits of the PT as well as the TODIM technique, which ensures that the DM's psychology is considered throughout the entire operation for processing decision-related data. A case study on the CDSP selection problem was presented to demonstrate the effectiveness of the offered techniques. Although there are minor differences in the overall score of the options, these variations are likely attributable to the distinctive assessment criteria of the various methodologies.
Despite the fact that the study has positive aspects, several limitations highlight the potential for future research. In the near future, our team will continue to focus on MADM and MAGDM, where novel innovation and design will be explored. First, the developed algorithms and methodologies may apply to several additional advantageous MAGDM problems. Using the following concepts [Citation63–65], the suggested methodologies could be expanded or included in many more fuzzy configurations to address group decision-making problems more effectively. Second, we will investigate further CDSP concerns, such as the inability to perform implementation system activities with the highest level of customer satisfaction [Citation62,Citation66–68].
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Acknowledgments
This work was supported by Posts and Telecommunications Institute of Technology, Vietnam (PTIT).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
Additional information
Funding
References
- Zadeh LA. Fuzzy sets. Inf Control. 1965;8:338–353. doi:10.1016/S0019-9958(65)90241-X.
- Atanassov KT. Intuitionistic fuzzy sets. Int J Bioautom. 2016;20:S1–S6. doi:10.1007/978-3-7908-1870-3_1.
- Cuong BC. Picture fuzzy sets. J Comp Sci Cybernet. 2015;30:409–420. doi:10.15625/1813-9663/30/4/5032.
- Yu X, Xu Z. Prioritized intuitionistic fuzzy aggregation operators. Inf Fusion. 2013;14:108–116. doi:10.1016/j.inffus.2012.01.011.
- Yager RR. Pythagorean membership grades in multicriteria decision making. IEEE Trans Fuzzy Syst. 2013;22:958–965.
- Liu P, Xu H, Geng Y. Normal wiggly hesitant fuzzy linguistic power Hamy mean aggregation operators and their application to multi-attribute decision-making. Comput Ind Eng. 2020;140:1–21. doi:10.1016/j.cie.2019.106224.
- Luo D, Zeng S, Chen J. A probabilistic linguistic multiple attribute decision making based on a new correlation coefficient method and its application in hospital assessment. Mathematics. 2020;8:1–17. doi:10.3390/math8030340.
- Mo H. An emergency decision-making method for probabilistic linguistic term sets extended by d number theory. Symmetry (Basel). 2020;12:12030380. doi:10.3390/sym12030380.
- Du Y, Liu D. A novel approach for probabilistic linguistic multiple attribute decision making based on dual muirhead mean operators and VIKOR. Int J Fuzzy Syst. 2021;23:243–261. doi:10.1007/s40815-020-00897-8.
- He T, Wei G, Wu J, et al. QUALIFLEX method for evaluating human factors in construction project management with pythagorean 2-tuple linguistic information. J. Intell Fuzzy Syst 2021;40:4039–4050. doi:10.3233/JIFS-200379.
- Lin M, Xu Z, Zhai Y, et al. Multi-attribute group decision-making under probabilistic uncertain linguistic environment. J Oper Res Soc. 2018;69:157–170. doi:10.1057/s41274-017-0182-y.
- Hu X, Wang Z, Liu J. The impact of digital finance on household insurance purchases: evidence from micro data in China. Geneva Papers Risk Insurance Issues Practice. 2022;12:1039. doi:10.1057/s41288-022-00267-5.
- Aisaiti G, Liu L, Xie J, et al. An empirical analysis of rural farmers’ financing intention of inclusive finance in China: The moderating role of digital finance and social enterprise embeddedness. Ind Manag Data Syst. 2019;119:1535–1563. doi:10.1108/IMDS-08-2018-0374.
- He Y, Lei F, Wei G, et al. Edas method for multiple attribute group decision making with probabilistic uncertain linguistic information and its application to green supplier selection. Int J Comput Intell Sys. 2019;12:1361–1370. doi:10.2991/ijcis.d.191028.001.
- Gou X, Xiao P, Huang D, et al. Probabilistic double hierarchy linguistic alternative queuing method for real economy development evaluation under the perspective of economic financialization. Econom Res. 2021;34:3225–3244. doi:10.1080/1331677X.2020.1870520.
- Krishankumar R, Sivagami R, Saha A, et al. Cloud vendor selection for the healthcare industry using a big data-driven decision model with probabilistic linguistic information. Appl Intell. 2022;52:13497–13519. doi:10.1007/s10489-021-02913-2.
- Ramadass S, Krishankumar R, Ravichandran KS, et al. Evaluation of cloud vendors from probabilistic linguistic information with unknown/partial weight values. Appl Soft Comput. 2020;97:106801. doi:10.1016/j.asoc.2020.106801.
- Feng X, Liu Q, Wei C. Probabilistic linguistic QUALIFLEX approach with possibility degree comparison. J. Intell Fuzzy Syst. 2019;36:719–730. doi:10.3233/JIFS-172112.
- Wei G, He Y, Lei F, et al. MABAC method for multiple attribute group decision making with probabilistic uncertain linguistic information. J. Intell Fuzzy Syst. 2020;39:3315–3327. doi:10.3233/JIFS-191688.
- Bashir Z, Ali J, Rashid T. Consensus-based robust decision making methods under a novel study of probabilistic uncertain linguistic information and their application in Forex investment. Artif Intell Rev. 2021;54:2091–2132. doi:10.1007/s10462-020-09900-y.
- Gomes AMLF, Duncan RLA. An application of the TODIM method to the multicriteria rental evaluation of residential properties. Eur J Oper Res. 2009;193:204–211. doi:10.1016/j.ejor.2007.10.046.
- Liu P, Teng F. Probabilistic linguistic TODIM method for selecting products through online product reviews. Inf Sci (Ny). 2019;485:441–455. doi:10.1016/j.ins.2019.02.022.
- Sang X, Liu X. An interval type-2 fuzzy sets-based TODIM method and its application to green supplier selection. J Oper Res Soc. 2016;67:722–734. doi:10.1057/jors.2015.86.
- He T, Wei G, Lu J, et al. A novel edas based method for multiple attribute group decision making with pythagorean 2-tuple linguistic information. Technol Econ Dev Econ. 2020;26:1125–1138. doi:10.3846/tede.2020.12733.
- Pamučar D, Ćirović G. The selection of transport and handling resources in logistics centers using multi-attributive border approximation area comparison (MABAC). Expert Syst Appl. 2015;42:3016–3028. doi:10.1016/j.eswa.2014.11.057.
- Krishankumar R, Saranya R, Nethra RP, et al. A decision-making framework under probabilistic linguistic term set for multi-criteria group decision-making problem. J. Intell Fuzzy Syst. 2019;36:5783–5795. doi:10.3233/JIFS-181633.
- Liao H, Xu Z. A VIKOR-based method for hesitant fuzzy multi-criteria decision making. Fuzzy Optim Decis Mak. 2013;12:373–392. doi:10.1007/s10700-013-9162-0.
- Arya V, Kumar S. A novel TODIM-VIKOR approach based on entropy and Jensen–Tsalli divergence measure for picture fuzzy sets in a decision-making problem. Int J Intell Syst. 2020;35:2140–2180. doi:10.1002/int.22289.
- Gou X, Xu Z, Liao H, et al. Probabilistic double hierarchy linguistic term set and its use in designing an improved VIKOR method: The application in smart healthcare. J Oper Res Soc. 2021;72:2611–2630. doi:10.1080/01605682.2020.1806741.
- Liao H, Jiang L, Lev B, et al. Novel operations of PLTSs based on the disparity degrees of linguistic terms and their use in designing the probabilistic linguistic ELECTRE III method. Appl Soft Comput J. 2019;80:450–464. doi:10.1016/j.asoc.2019.04.018.
- Huang Y, Lin R, Chen X. An enhancement EDAS method based on prospect theory. Techn Econ Dev Econ. 2021;27:1019–1038. doi:10.3846/tede.2021.15038.
- Ghorabaee MK, Zavadskas EK, Olfat L, et al. Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (EDAS). Informatica (Netherlands). 2015;26:435–451. doi:10.15388/Informatica.2015.57.
- De Tre G, Hallez A, Bronselaer A. Performance optimization of object comparison. Int J Intell Syst. 2014;29:495–524. doi:10.1002/int.
- Zhang R, Xu Z, Gou X. ELECTRE II method based on the cosine similarity to evaluate the performance of financial logistics enterprises under double hierarchy hesitant fuzzy linguistic environment. Fuzzy Optim Decis Mak. 2022;21:1–19. doi:10.1007/s10700-022-09382-3.
- zhi Luo S, zhang Liang W. A hybrid TODIM approach with unknown weight information for the performance evaluation of cleaner production. Comput Appl Math. 2021;40:1–28. doi:10.1007/s40314-020-01401-6.
- Zhang D, Su Y, Zhao M, et al. CPT-TODIM method for interval neutrosophic magdm and Its application To third-party logistics service providers selection. Techn Econ Dev Econ. 2021;28:201–219. doi:10.3846/tede.2021.15758.
- Zhao M, Gao H, Guiwu W, et al. Model for network security service provider selection with probabilistic uncertain linguistic TODIM method based on prospect theory. Technol Econ Develop Econ. 2022;28:638–654. doi:10.3846/tede.2022.16483.
- Tian X, Niu M, Ma J, et al. A novel TODIM with probabilistic hesitant fuzzy information and Its application in green supplier selection. Complexity. 2020;2540798:1–26. doi:10.1155/2020/2540798.
- Ju Y, Liang Y, Luo C, et al. T-spherical fuzzy TODIM method for multi-criteria group decision-making problem with incomplete weight information. Soft Comput. 2021;25:2981–3001. doi:10.1007/s00500-020-05357-x.
- Li M, Li Y, Peng Q, et al. Evaluating community question-answering websites using interval-valued intuitionistic fuzzy DANP and TODIM methods. Appl Soft Comput. 2021;99:1–17. doi:10.1016/j.asoc.2020.106918.
- Zhao M, Wei G, Wei C, et al. Pythagorean fuzzy TODIM method based on the cumulative prospect theory for MAGDM and Its application on risk assessment of science and technology projects. Int J Fuzzy Syst. 2021;23:1027–1041. doi:10.1007/s40815-020-00986-8.
- Krishankumar R, Ravichandran KS, Tyagi SK. Solving cloud vendor selection problem using intuitionistic fuzzy decision framework. Neural Comput Appl. 2020;32:589–602. doi:10.1007/s00521-018-3648-1.
- Li Y, Shan Y, Liu P. An extended TODIM method for group decision making with the interval intuitionistic fuzzy sets. Math Probl Eng. 2015;2015:1–9. doi:10.1155/2015/672140.
- Irvanizam I, Marzuki M, Patria I, et al. An application for smartphone preference using TODIM decision making method. 2018 International Conference on Electrical Engineering and Informatics (ICELTICs); 2018: pp. 122–126. doi:10.1109/ICELTICS.2018.8548820.
- Krishankumaar R, Mishra AR, Gou X, et al. New ranking model with evidence theory under probabilistic hesitant fuzzy context and unknown weights. Neural Comput Appl. 2022;34:3923–3937. doi:10.1007/s00521-021-06653-9.
- Irvanizam I, Usman T, Iqbal M, et al. An extended fuzzy TODIM approach for multiple-attribute decision-making with dual-connection numbers. Adv Fuzzy Sys. 2020;2020:1–10. doi:10.1155/2020/6190149.
- Byabartta Kar M, Krishankumar R, Pamucar D, et al. A decision framework with nonlinear preferences and unknown weight information for cloud vendor selection. Expert Syst Appl. 2023;213:118982. doi:10.1016/j.eswa.2022.118982.
- Zhang D, Zhao M, Wei G, et al. Single-valued neutrosophic TODIM method based on cumulative prospect theory for multi-attribute group decision making and its application to medical emergency management evaluation. Econ Res. 2022;35:4520–4536. doi:10.1080/1331677X.2021.2013914.
- Su Y, Zhao M, Wei C, et al. PT-TODIM Method for probabilistic linguistic MAGDM and application to industrial control system security supplier selection. Int J Fuzzy Syst. 2022;24:202–215. doi:10.1007/s40815-021-01125-7.
- Kahneman D, Tversky A. Prospect theory: An analysis of decision under risk. Exp Environ Econom. 2018;1:143–172. doi:10.2307/1914185.
- xin Nie R, qiang Wang J. Prospect theory-based consistency recovery strategies with multiplicative probabilistic linguistic preference relations in managing group decision making. Arab J Sci Eng. 2020;45:2113–2130. doi:10.1007/s13369-019-04053-9.
- Gou X, Xu Z, Liao H, et al. Multiple criteria decision making based on distance and similarity measures under double hierarchy hesitant fuzzy linguistic environment. Comp Indus Eng. 2018;126:516–530. doi:10.1016/j.cie.2018.10.020.
- Wei G, Wei C, Guo Y. EDAS method for probabilistic linguistic multiple attribute group decision making and their application to green supplier selection. Soft Comput. 2021;25:9045–9053. doi:10.1007/s00500-021-05842-x.
- Verma AA, Razak F, Detsky AS. Understanding choice: Why physicians should learn prospect theory. J Am Med Assoc. 2014;311:571–572. doi:10.1001/jama.2013.285245.
- Khan WU, Shachak A, Seto E. Understanding decision-making in the adoption of digital health technology: The role of behavioral economics’ prospect theory. J Med Internet Res. 2022;24:e32714. doi:10.2196/32714.
- Wei G, Lei F, Lin R, et al. Algorithms for probabilistic uncertain linguistic multiple attribute group decision making based on the GRA and CRITIC method: application to location planning of electric vehicle charging stations. Econ Res. 2020;33:828–846. doi:10.1080/1331677X.2020.1734851.
- Tversky A, Kahneman D. Advances in prospect theory: cumulative representation of uncertainty. J Risk Uncertain. 1992;5:297–323. doi:10.1007/BF00122574.
- Gou X, Liao H, Wang X, et al. Consensus based on multiplicative consistent double hierarchy linguistic preferences: venture capital in real estate market. Int J Strat Prop Manage . 2019;24:1–23. doi:10.3846/ijspm.2019.10431.
- Yingming W. Using the method of maximizing deviation to make decision for multiindices. J Syst Eng Electron. 1997;8:21–26.
- Feng X, Liu Q, Wei C. Probabilistic linguistic QUALIFLEX approach with possibility degree comparison. J Intell Fuzzy Syst. 2019;36:719–730. doi:10.3233/JIFS-172112.
- Liao H, Wu X. DNMA: A double normalization-based multiple aggregation method for multi-expert multi-criteria decision making. Omega (UK). 2020;94:1–15. doi:10.1016/j.omega.2019.04.001.
- Büyüközkan G, Mukul E. Evaluation of smart health technologies with hesitant fuzzy linguistic MCDM methods. J Intell Fuzzy Syst. 2020;39:6363–6375. doi:10.3233/JIFS-189103.
- Irvanizam I, Zulfan Z, Nasir PF, et al. An extended MULTIMOORA based on trapezoidal fuzzy neutrosophic sets and objective weighting method in group decision-making. IEEE Access. 2022;10:47476–47498. doi:10.1109/ACCESS.2022.3170565.
- Irvanizam I, Syahrini I, Zi NN, et al. An improved EDAS method based on bipolar neutrosophic set and its application in group decision-making. Appl Comput Intell Soft Comp. 2021;1474629. doi:10.1155/2021/1474629.
- Irvanizam I, Zi NN, Zuhra R, et al. An extended MABAC method based on triangular fuzzy neutrosophic numbers for multiple-criteria group decision making problems. Axioms. 2020;9:1–18. doi:10.3390/axioms9030104.
- Belarmino A, Raab C, Tang J, et al. Exploring the motivations to use online meal delivery platforms: before and during quarantine. Int J Hosp Manag. 2021;96:102983. doi:10.1016/j.ijhm.2021.102983.
- Chao X, Dong Y, Kou G, et al. How to determine the consensus threshold in group decision making: a method based on efficiency benchmark using benefit and cost insight. Ann Oper Res. 2021;316:143–177. doi:10.1007/s10479-020-03927-8.
- Nguyen VP. Evaluating the FinTech success factors model to achieve a sustainable financial technology business: an empirical study in Vietnam. Cogent Eng. 2022;9:2109317. doi:10.1080/23311916.2022.2109317.