
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This research studies variational inclusion problems, which is a branch of optimization. A modified projective forward-backward splitting algorithm is constructed to solve this problem. The algorithm adds the inertial technique for speeding up the convergence, and the projective method for several regularization machine learning models to meet good model fitting. To evaluate the performance of the classification models employed in this research, four evaluation metrics are computed: accuracy, F1-score, recall, and precision. The highest performance value of 92.86% accuracy, 62.50% precision, 100% recall, and 76.92% F1-score shows that our algorithm performs better than the other machine learning models.
1. Introduction
The variational inclusion problem (VIP) is to find a point in a real Hilbert space
such that
(1)
(1)
where
is a single valued mapping and
is a multivalued mapping. Solving the VIP (Equation1
(1)
(1) ) has many benefits for specific applications since many problems can be formulated in the form of the VIP (Equation1
(1)
(1) ), such as minimization problems, machine learning, image processing, signal processing, etc., see in [Citation1–3]. This paper focuses on modifying efficient algorithms to solve the VIP (Equation1
(1)
(1) ) and applying them to decrypt data classification. The inertial extrapolation technique, which was introduced in 1964, is one of the techniques for ensuring the algorithm's good convergence [Citation4]. The main feature of the inertia extrapolation technique is that the next iterate is constructed by the previous two iterates. This technique was used extensively with variational inclusion algorithms later by many authors, see in [Citation5–9]. The inertial forward-backward algorithm (IFB) is the original variational inclusion algorithm introduced by Moudafi and Oliny [Citation10]. The algorithm was generated by
and
(2)
(2)
where
is a sequence of positive real numbers. The weak convergence of the iterative sequence was established based on the condition generated in terms of the sequence
and parameter
under a co-coercivity condition
about the solution set. Following the idea of Moudafi and Oliny [Citation10], Peeyada et al. [Citation11] introduced an inertial Mann forward-backward splitting algorithm (IMFB) for the VIP (Equation1
(1)
(1) ) by taking
and
(3)
(3)
where
is a sequence of positive real numbers and
. Under the same conditions on a co-coercivity condition
, the parameters
, and
, weak convergence of algorithm was proved. The IMFB was used in machine learning for breast cancer classification, and its efficiency was presented by comparing it with other algorithms. The regularized least square model was solved by setting the VIP (Equation1
(1)
(1) ) for getting an optimal fitting model in machine learning, thus the IMFB is very useful for breast cancer classification. Many optimization branches have been used in various neural networks and medical fields in recent years [Citation12–16]. Parkinson's disease is a gradual degenerative disease of the brain that is common in the elderly. There is currently no cure for this disease, although early detection and treatment by a medical practitioner can help reduce the progression of the disease and improve the quality of life. Many machine learning methods such as Bayesian optimization (BO), Support Vector Machine (SVM), Random Forest (RF), Logistic Regression (LR), etc. (see in [Citation17]) have been used for Parkinson's disease detection. The extreme learning machine (ELM) is also used in Parkinson's disease detection (see in [Citation18]), with the aid of the feature selection techniques the method got an efficient model.
To solve the VIP (Equation1(1)
(1) ), we present a modified inertial two-step Mann forward-backward splitting algorithm with projective methods inspired by prior research. Weak convergence is demonstrated under appropriate conditions to confirm solution convergence. In the final section, we show how our algorithm can be used to Parkinson's disease detection by the ELM without data cleaning technique and compare it to various machine learning methods.
2. Preliminaries
In this section, we provide various definitions and lemmas that will be needed to prove our optimization algorithm in Section 3. We use the symbols and
to denote weak and strong convergence, respectively.
Definition 2.1
is called
-Lipschitz continuous if there exists
such that
for all
.
is nonexpansive mapping for
.
Definition 2.2
Assume that is a multivalued mapping and its graph mapping is denoted by
.
is called
| (i) | monotone if ∀ | ||||
| (ii) | maximal monotone if ∀ | ||||
| (iii) | α-inverse strongly monotone if ∃ | ||||
Lemma 2.3
[Citation19]
Assume is a mapping and that
is a maximal monotone mapping. Let
,
, and
be the set of the fixed points of
. Then
.
Lemma 2.4
[Citation20]
Assume is a maximal monotone mapping and that
is a Lipschitz continuous and monotone mapping. Then the mapping
is maximal monotone.
Lemma 2.5
[Citation21]
Assume is α-inverse-strongly monotone mapping. Then
is
If
Lemma 2.6
[Citation22]
Assume is a α-inverse-strongly monotone mapping and that
is maximal monotone mapping. Then
For
For
Lemma 2.7
[Citation23]
Assume is a nonexpansive mapping with
. If there exists a sequence
in
with
and
, then
.
Lemma 2.8
[Citation24]
Assume that and
are nonnegative real sequences with
and
Then,
is convergent.
Lemma 2.9
[Citation19, Opial]
Assume that is a nonempty set of
and
is a sequence in
. Assume that the following are true.
Every weak sequential cluster point of
Then
3. Optimization algorithm
The section aims to present the convergence analysis. Let be a nonempty closed convex subset of a real Hilbert space
, and consider the following conditions.
| (C1) |
| ||||
| (C2) |
| ||||
| (C3) |
| ||||

Remark 3.1
From Algorithm 1, we see that; (i) by setting , and
, Algorithm 1 can be reduced to other modified forward-backward splitting algorithms, e.g. if
, the reduced algorithm is in the form:
(ii) Algorithm 1 recovers the inertial forward-backward algorithm in [Citation10] when we take
, and
; (iii) the difference between an inertial projective method and a standard method is an inertial projective method is more relaxing than a standard method with the inertial term which can be set to need faster convergence and the projection operator can be focussed to meet faster solution, the following structure shows the first step of the comparison between an inertial projective method and a standard method in
:
From Figure , we see that is updated to
by
every step, thus speeding up the convergence of the algorithm depends on setting the right
.
(black vector) is also updated to new
(e.g. orange or blue vector) by setting
.
We are now ready for the main convergence theorem.
Figure 1. The structure comparison of an inertial projective method and a standard method.
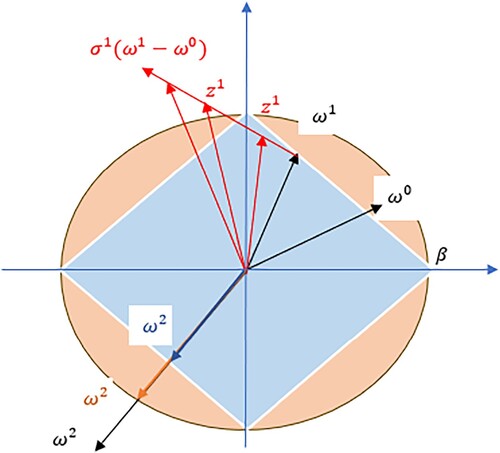
Figure 2. Training-validation accuracy plots of Algorithm 1 which is considered by the RLS ELM mode.
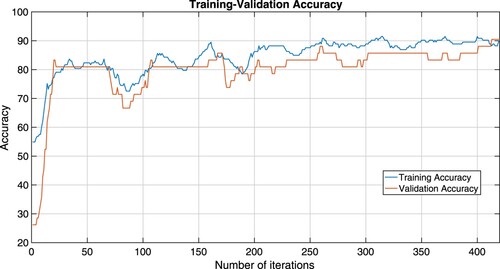
Figure 3. Training-validation loss plots of Algorithm 1 which is considered by the RLS ELM mode.
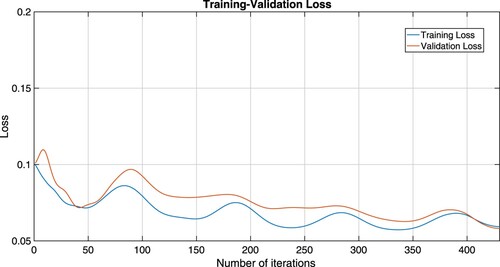
Figure 4. Training-validation accuracy plots of Algorithm 1 which is considered by the RLS-C
ELM mode.
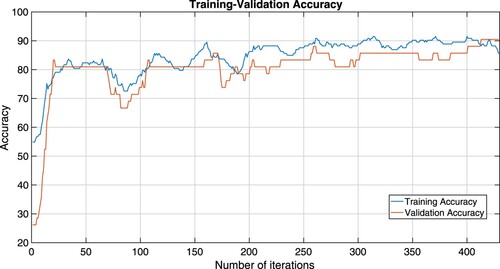
Figure 5. Training-validation loss plots of Algorithm 1 which is considered by the RLS-C
ELM mode.
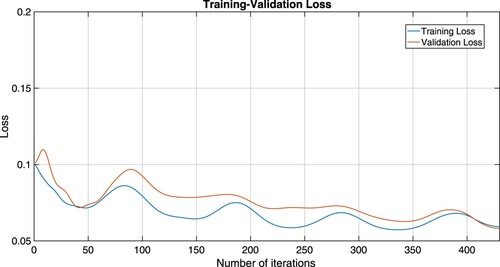
Figure 6. Training-validation accuracy plots of IMFB (Equation3(3)
(3) ) which is considered by the RLS
ELM mode.
Theorem 3.2
Let the sequence generated by Algorithm 1 satisfying the conditions
. Then,
converges weakly to an element of Ψ.
Proof.
Let . Sine
and
are nonexpansive, we have
(4)
(4)
By Lemma 2.8, we obtain that
exists. Since
, we also obtain
(5)
(5)
This implies that
is bounded and also
and
are also bounded. Since
is α-inverse-strongly monotone mapping by Lemma 2.5, then by (Equation4
(4)
(4) ) and
is firmly nonexpansive mapping, we have
It follows from (Equation5
(5)
(5) ) and
and
that
(6)
(6)
Sine
, there exists
such that
. By Lemma 2.6(ii), we obtain
It follows from (Equation6
(6)
(6) ) that
(7)
(7)
We next let
be a weak sequential cluster point of
. Since
is closed convex set,
. It follows from (Equation5
(5)
(5) ) and (Equation7
(7)
(7) ) that
by Lemma 2.7. Since
exists, by Lemma 2.9, we obtain
converges weakly to
. Theorem 3.2 is completed.
4. Data classification problem
Parkinson's disease (PD) is a non-communicable disease that is a movement disorder characterized by the progressive degeneration of dopaminergic neurones in the midbrain. Its severity level is classified as stage 1, 2, 3, and severe condition. In the medical world, it is often difficult to identify the severity of Parkinson's disease and predict the progression of the disease. The disease often occurs in individuals older than 60. Parkinson's disease is a disease that, if not adequately treated, can lead to an inability to control walking, leading to accidents. and may cause disability risk. Therefore, if it is found that a family member has symptoms related to this disease, they should be taken to see a doctor immediately for treatment and to prevent harm to the patient. Therefore, using machine learning to help analyze the likelihood that a patient will likely develop a disease is very important. In this paper, we applied our proposed Algorithm 1 in an extreme learning machine (ELM) to find the optimal weights using the PD dataset from UCI Machine Learning Repository. This dataset is available online at the well-known UCI machine learning website [Citation25] and was published in [Citation26, Citation27]. The dataset consists of 23 attributes and 195 instances which were first created in a collaboration between Oxford University and the National Centre for Voice and Speech by Max Little. The overview of the data is shown in Table .
Table 1. The overview of PD dataset from UCI Machine Learning Repository.
Very recently, Elshewey et al. [Citation17] presented using Bayesian optimization (BO) [Citation28] or optimizing the hyperparameters of machine learning models: Support Vector Machine (SVM) [Citation29], Random Forest (RF) [Citation30], Logistic Regression (LR) [Citation31], Naive Bayes (NB) [Citation32], Ridge Classifier (RC) [Citation33], and Decision Tree (DT) [Citation34] to obtain better accuracy by using PD dataset with min–max normalization. Table shows the different accuracy of the machine learning methods between using BO optimizing the hyperparameters and the default parameters compared with our algorithm in an extreme learning machine (ELM).
To understand ELM, which was first introduced by Huang et al. [Citation35], we let be a training set of N distinct samples where
is an input training data and
is a training target. The output function of ELM for single-hidden layer feed forward neural networks (SLFNs) with L hidden nodes is
where g is an activation function,
and
are parameters of weight and finally the bias at the i-th hidden node, respectively, and
is the optimal output weight at the i-th hidden node. The hidden layer output matrix
is defined as follows:
The main goal of ELM is to find optimal output weight
such that
, where
is the training target dataset. In some cases, finding the exact solution of a linear equation
may be difficult, therefore least square problem has been considered to approximate the solution. Also, for suitable prediction, overfitting of the model should be considered. In this paper, we avoid overfitting our model by using regularized least squares (RLS) and show the excellent fit of our model by considering accuracy and loss porting. The six regularized least squares problem models can be solved by our proposed algorithm by setting as follows: for a regularization parameter
and constrained constant
,
setting
setting
setting
setting
setting
setting
Table 2. The accuracy comparison between Elshewey et al. [Citation17] methods and ours.
Remark 4.1
The novelty of Algorithm 1 is applied to solve regularization problem models on constrained sets in many directions (Equation10(10)
(10) )–(Equation13
(13)
(13) ) which is different from algorithms in the literature and achieves good results.
The binary cross entropy loss function calculates the loss of an example by computing the following average:
where
is the k-th scalar value in the model output,
is the corresponding target value, and the output size is the number of scalar values in the model output.
In this work, we present four measures: Accuracy, Recall, Precision, and F1-score for the performance reports. The formulations of three measures are defined as follows:
where
:=True Negative,
:= False Positive,
:=False Negative, and
:=True Positive.
For comparison experiments, optimization models (Equation8(8)
(8) ) and (Equation9
(9)
(9) ) are considered for IFB (Equation2
(2)
(2) ) and IMFB (Equation3
(3)
(3) ) algorithms. The necessary parameters which are used in our Algorithm 1, IFB (Equation2
(2)
(2) ) and IMFB (Equation3
(3)
(3) ) algorithms can be seen in Table where
where K is a number of iterations that we want to stop.
This experiment, we use sigmoid as an activation function and 130 hidden nodes. The results of all algorithms our Algorithm 1, IFB (Equation2(2)
(2) ) and IMFB (Equation3
(3)
(3) ) are shown in Table .
From Table , we see that our Algorithm 1 when it's considered by the RLS and RLS
-C
ELM model gives the highest accuracy precision, recall, and F1-score efficiency, respectively. To show that our Algorithm is efficient without model over-fitting, we consider the following training and validation loss with the accuracy plots.
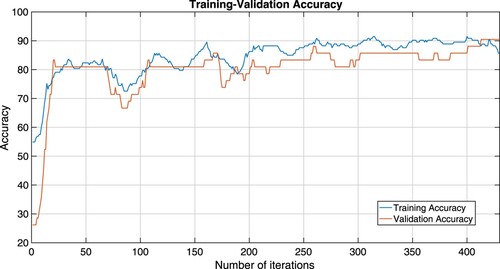
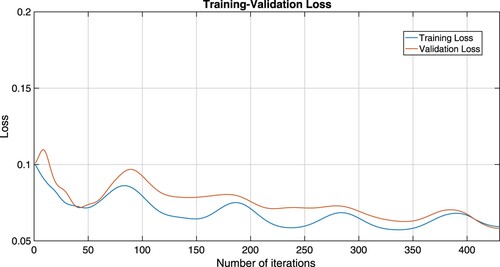
From Figures –, we see that training-validation loss, and accuracy plots are almost the same throughout, even though they oscillate, indicating that our models are well fitting. This means that our machine learning model adapts well to data similar to the data on which it was trained.
Figure 7. Training-validation loss plots of IMFB (Equation3(3)
(3) ) which is considered by the RLS
ELM mode.
5. Conclusion
In this paper, we study extreme learning machine and introduce a new modified projective forward-backward splitting algorithm to solve variational inclusion problems. We also prove weak convergence theorem under mind condition on the control stepsize. Parkinson's disease dataset from UCI machine learning repository was used for data training applying the proposed algorithm. The comparison with other machine learning models and existing algorithms show that our algorithm provides the highest performance value of 92.86% accuracy, 62.50% precision, 100% recall, and 76.92% F1-score considering on regularized least squares by (RLS
) and regularized least squares by
on constrained set
(RLS
-C
). Moreover, considering training and validation loss, and the accuracy plots show that our algorithm has good fit model. Our future research is to develop a more relaxed condition of the inertial extrapolation parameter
. We also develop forward-backward splitting algorithms for multi-layer ELM (deep learning), which would be interesting to apply in machine learning.
Author's contributions
Writing – Original Draft and Software, W.C.; Review and Editing, S.D.. All authors have contributed to the development of each section of the paper and finally read and approved it for publication.
Disclosure statement
The authors have no competing interests to declare that are relevant to the content of this article.
Data availability statement
Parkinson's disease dataset is available on the UCI website (https://archive.ics.uci.edu/ml/datasets/parkinsons).
Additional information
Funding
References
- Bauschke HH, Borwein JM. On projection algorithms for solving convex feasibility problems. SIAM Rev. 1996;38:367–426. doi: 10.1137/S0036144593251710
- Bauschke HH, Combettes PL. Convex analysis and monotone operator theory in Hilbert spaces. Berlin: Springer; 2011.
- Chen M, Li Y, Luo X, et al. A novel human activity recognition scheme for smart health using multilayer extreme learning machine. IEEE Internet Things J. 2019;6:1410–1418. doi: 10.1109/JIoT.6488907
- Polyak B. Some methods of speeding up the convergence of iteration methods. USSR Comput Math Math Phys. 1964;4(5):1–17. doi: 10.1016/0041-5553(64)90137-5
- Bot RI, Csetnek ER. An inertial forward-backward-forward primal-dual splitting algorithm for solving monotone inclusion problems. Numer Algorithms. 2016;71(3):519–540. doi: 10.1007/s11075-015-0007-5
- Hanjing A, Bussaban L, Suantai S. The modified viscosity approximation method with inertial technique and Forward–Backward algorithm for convex optimization model. Mathematics. 2022;10(7):1036. doi: 10.3390/math10071036
- Inthakon W, Suantai S, Sarnmeta P, et al. A new machine learning algorithm based on optimization method for regression and classification problems. Mathematics. 2020;8(6):1007. doi: 10.3390/math8061007
- Peeyada P, Dutta H, Shiangjen K, et al. A modified forward-backward splitting methods for the sum of two monotone operators with applications to breast cancer prediction. Math Methods Appl Sci. 2023;46(1):1251–1265. doi: 10.1002/mma.v46.1
- Tan B, Cho SY. Strong convergence of inertial forward–backward methods for solving monotone inclusions. Appl Anal. 2022;101(15):5386–5414. doi: 10.1080/00036811.2021.1892080
- Moudafi A, Oliny M. Convergence of a splitting inertial proximal method for monotone operators. J Comput Appl Math. 2003;155:447–454. doi: 10.1016/S0377-0427(02)00906-8
- Peeyada P, Suparatulatorn R, Cholamjiak W. An inertial Mann forward-backward splitting algorithm of variational inclusion problems and its applications. Chaos Solit Fractals. 2022;158:112048. doi: 10.1016/j.chaos.2022.112048
- Al-Dhaifallah M, Nisar KS, Agarwal P, et al. Modeling and identification of heat exchanger process using least squares support vector machines. Therm Sci. 2017;21(6 Part B):2859–2869. doi: 10.2298/TSCI151026204A
- Baleanu D, Hasanabadi M, Vaziri AM, et al. A new intervention strategy for an HIV/AIDS transmission by a general fractional modeling and an optimal control approach. Chaos Solit Fractals. 2023;167:113078. doi: 10.1016/j.chaos.2022.113078
- Baleanu D, Arshad S, Jajarmi A, et al. Dynamical behaviours and stability analysis of a generalized fractional model with a real case study. J Adv Res. 2023;48:157–173. doi: 10.1016/j.jare.2022.08.010
- Boonsatit N, Rajchakit G, Sriraman R, et al. Finite-fixed-time synchronization of delayed Clifford-valued recurrent neural networks. Adv Differ Equ. 2021;2021(1):1–25. doi: 10.1186/s13662-021-03438-1
- Rajchakit G, Agarwal P, Ramalingam S. Stability analysis of neural networks. Singapore: Springer; 2021.
- Elshewey AM, Shams MY, El-Rashidy N, et al. Bayesian optimization with support vector machine model for Parkinson disease classification. Sensors. 2023;23(4):2085. doi: 10.3390/s23042085
- Chen HL, Wang G, Ma C, et al. An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson's disease. Neurocomputing. 2016;184:131–144. doi: 10.1016/j.neucom.2015.07.138
- Bauschke HH, Combettes PL. Convex analysis and monotone operator theory in Hilbert spaces. New York: Springer; 2011. (CMS Books in Mathematics).
- Brézis H. Opérateurs maximaux monotones et semi-groupes de contractions dans les espaces de Hilbert. Amsterdam, Netherlands: North-Holland; 1973. (Math. Studies 5).
- Zhang J, Li Y, Xiao W, et al. Non-iterative and fast deep learning: multilayer extreme learning machines. J Franklin Inst B. 2020;357(13):8925–8955. doi: 10.1016/j.jfranklin.2020.04.033
- López G, Martn-Mrquez V, Wang F, et al. Forward-backward splitting methods for accretive operators in Banach spaces. Abstr Appl Anal. 2012;2012:109236.
- Goebel K, Kirk WA. Topics in metric fixed point theory. Cambridge: Cambridge University Press; 1990.
- Auslender A, Teboulle M, Ben-Tiba S. A logarithmic-quadratic proximal method for variational inequalities. Boston, MA: Springer; 1999.
- Dua D, Graff C. UCI machine learning repository. Irvine, CA: University of California, School of Information and Computer Science; 2019. Available at http://archive.ics.uci.edu/ml.
- Little M, Mcsharry P, Roberts S, et al. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. Nat Preced. 2007;2007:1–1.
- Little M, McSharry P, Hunter E, et al. Suitability of dysphonia measurements for telemonitoring of Parkinson's disease. Nat Preced. 2008;2008:1–1.
- Cho H, Kim Y, Lee E, et al. Basic enhancement strategies when using Bayesian optimization for hyperparameter tuning of deep neural networks. IEEE Access. 2020;8:52588–52608. doi: 10.1109/Access.6287639
- Jakkula V. Tutorial on support vector machine (SVM). Sch EECS Wash State Univ. 2006;37:3.
- Cutler A, Cutler DR, Stevens JR. Random forests. In: Zhang C, Ma Y, editors. Ensemble machine learning. Berlin, Germany: Springer; 2012. p. 157–175.
- Nick TG, Campbell KM. Logistic regression. Top Biostat. 2007;404:273–301. doi: 10.1007/978-1-59745-530-5
- Zhang H. The optimality of naive Bayes. Aa. 2004;1(2):3.
- Xingyu MA, Bolei MA, Qi F. Logistic regression and ridge classifier; 2022.
- Kotsiantis SB. Decision trees: a recent overview. Artif Intell Rev. 2013;39:261–283. doi: 10.1007/s10462-011-9272-4
- Huang GB, Zhu QY, Siew CK. Extreme learning machine: a new learning scheme of feedforward neural networks. In 2004 IEEE international joint conference on neural networks, IEEE Cat. 2004;2(04CH37541):985–990.