
Abstract
The general goal of reading is to obtain meaning from what is written on the page or screen. The numerous scripts around the world used to write different languages vary in terms of what aspects of language are encoded in the written form. The aim of the current review is to examine some recent research on lesser‐studied orthographies, in particular Thai, to illustrate the benefits of comparative studies in building a greater understanding of what processes are common or distinct when reading diverse writing systems. Three areas of reading are focused on where there is substantial variation across orthographies: (1) reading with and without interword spaces, (2) flexibility in letter position coding and initial letter position advantage, and (3) the role of lexical tone when reading. In order to effectively read a script, readers need to attend to the critical features of the script that interface with the particular language of the speaker. For example, in scripts with interword spaces, these salient visual cues form clear word boundaries, whereas in unspaced scripts other orthography‐specific cues need to be identified and utilised. Furthermore, comparative research shows that letter position encoding varies across languages, which is shaped by the characteristics of the orthography. Finally, research on Thai and Chinese indicates that tone takes a secondary role in comparison to segmental information (consonantal and vowel information) and appears to be processed at a later stage.
What is already known
The general goal of reading is to obtain meaning from what is written on the page or screen.
The processes and pathways involved in attaining this goal substantially differ between writing systems and orthographies.
What this topic adds
Some recent research on lesser‐studied orthographies, in particular, Thai, is examined to illustrate the benefits of comparative studies in building a greater understanding of what processes are common or distinct when reading diverse writing systems.
By investigating reading and reading processes in lesser‐studied writing systems or orthographies, we can gain a greater understanding of the underlying processes and mechanisms involved in reading.
INTRODUCTION
When we read our general aim is to understand, comprehend, and obtain meaning from what is written on the page or screen (Perfetti & Dunlap, Citation2008). Skilled readers appear to achieve this goal relatively effortlessly. However, for a child learning to read, it can be quite a challenge to learn how ‘to crack the code’ or learn how their particular writing system maps onto their spoken language (Perfetti & Zhang, Citation1995). This fundamental process involves converting written symbols into words, morphemes, and their underlying concepts (Perfetti & Dunlap, Citation2008). The numerous scripts around the world substantially differ in how and what aspects of language are encoded in the written form. For example, the predominant level represented might be the word or morpheme as in logographic Chinese, the syllable (or mora) as in Japanese or the phoneme as in alphabetic English, German, or Finnish (Byrne, Samuelsson, & Olson, Citation2014). Even though a writing system may predominantly represent a particular level of language, it also consistently represents other levels of language. For example, English and other European alphabets represent phonemes and also syllables, morphemes, and words. An overriding question is to what extent reading and reading processes are similar or different when reading these quite distinct writing systems.
Traditionally, reading research has focused on Roman script and a small number of European languages, in particular English. However, there has been a rapidly growing interest in investigating a broader range of languages and scripts, which are essential if we are to delineate between universal and orthography‐specific processes as well as build more comprehensive and representative universal models of reading (see Frost, Citation2012). This comparative research may also challenge various assumptions that have been made based on a limited group of languages and scripts (Frost, Citation2012; Share, Citation2008).
One of the much debated questions is whether universals in reading exist and can be specified and applied to all writing systems and orthographies. Coltheart and Crain (Citation2012) believe that there are no such universals of reading and consequently there cannot be a universal model of reading. On the other hand, Frost (Citation2012) advocates that in order to construct a universal model or theory of reading, we need to focus on what is invariant in orthographic processing across writing systems. This is quite a challenge since there is such diversity across orthographies and writing systems. Although the general goal of reading is to form a mental representation of text from decoding visual symbols, the processes involved in attaining this goal may substantially differ due to the large variation in the characteristics of writing systems and orthographies. The aim of the current review is to examine some recent research on lesser‐studied orthographies, in particular, Thai, to illustrate the benefits of comparative studies in building a greater understanding of reading mechanisms and processes. Thai forms a useful comparison with the much studied Roman script, as it is also alphabetic but has marked differences. In this short review, three aspects of reading where there are substantial differences in writing systems and orthographic coding will be examined. The three areas that are focused on are: (1) reading with and without interword spaces, (2) flexibility in letter position coding and initial letter position advantage, and (3) the role of lexical tone when reading. First, it is important to understand some of the distinctive characteristics of Thai prior to examining research in these three areas.
Thai, in contrast to Roman script, has a nonlinear configuration as it has vowels that can be written above, below, or to either side of the consonant as full letters or diacritics. Several vowels precede the consonant in writing but phonologically follow it in speech (e.g., แ-น<ε:bn> ‘flat’ is spoken as /bε:n/), whereas other vowels are spoken in the order that they are written, as occurs in English (e.g., บ-ท<ba:t>‘Baht’ is spoken as /ba:t/). This non‐alignment of vowels is a characteristic shared by other Brahmi‐derived scripts (e.g., Devanagari, Kannada, Sinhala, and Burmese). Thai is also a tonal language, which is a characteristic it shares with other regional neighbours (e.g., Chinese, Burmese, Lao, and Vietnamese) (for further discussion refer to Winskel, Citation2014; Winskel, Padakannaya, & Pandey, Citation2014a). Thai has five tones conceptualised as high, mid, falling, rising, and low and four tone markers that orthographically occur above the initial consonant in the syllable, for example, ข-ว /khã:w4/ (white) rising tone, ข่-ว /khà:w/ (news) low tone, and ข้-ว /khâ:w2/ falling tone (rice). The tone determination of a syllable is influenced by a combination of the class of initial consonant, the type of syllable (open or closed), the tone marker, and the length of the vowel (for further detail refer to Winskel, Citation2014; Winskel & Iemwanthong, Citation2010). Thai has a high degree of consistency in mapping between phonemes and graphemes but there are multigrapheme to phoneme correspondences, which mean that there are alternative spellings for some phonemes (e.g., ซ ศ ษ ส /s/). Thai also does not normally have interword spaces.
READING WITH AND WITHOUT INTERWORD SPACES
Thai similar to Chinese, Japanese, Lao, Khmer, Balinese, Sundanese, Tibetan, and Myanmar does not have salient interword spaces that demarcate word boundaries. Interword spaces are highly salient perceptual features that delineate between the beginning and end of a word, as illustrated by the current text. The lack of these salient visual word segmentation cues implies that during normal reading, there is a degree of ambiguity in relation to which word a given letter belongs to (an example to illustrate this difficulty: คุณพ่อของฉันชอบรับประทานอาหารที่มีรสจ-ด). Even some European languages such as Finnish and German have long unspaced compound words. Interword spaces form clear parafoveal word segmentation cues so that saccades can be readily targeted close to the centre or Optimal Viewing Position (OVP) (O'Reagan, Citation1990) of the next word to be read. In scripts that do not have these salient visual cues, other strategies need to be utilised by the reader to identify word boundaries and demarcate where a word begins and ends.
Not surprisingly in skilled Roman script readers, who have had a lifetime of reading spaced text, when these salient boundary cues are removed, the eye movement control and word identification are substantially disrupted (Morris, Rayner, & Pollatsek, Citation1990; Rayner, Fischer, & Pollatsek, Citation1998; Spragins, Lefton, & Fischer, Citation1976). In English, reading is typically slowed down by 30–50%, disrupting both the way the eyes move through the text and the word identification process. The masking or removal of interword spaces has been found to be more deleterious to the reading of (relatively unfamiliar) low‐frequency words than when reading length‐matched (relatively familiar) high‐frequency words (Rayner et al., Citation1998). These results are interpreted as indicating that removal of spaces interferes with word identification. Visuomotor control was also disrupted as indicated by substantial changes in the spatial distribution of incoming saccades or landing site distributions over target words. Readers tended to land a bit to the left of the middle of the word, whereas when spaces were removed they tended to land closer to the beginning of the word.
But what happens in readers who are accustomed to reading a script without these perceptually salient interword spaces, for example, Chinese, Japanese, or Thai? One possibility is that insertion of these salient perceptual cues may facilitate reading, or alternatively, as these readers have had a lifetime of experience reading text without interword spaces, adding spaces may have a deleterious effect on their reading.
With the aim of addressing this question, the eye movements of Thai–English bilinguals were examined when reading both Thai and English with and without interword spaces, and their eye movements were compared when reading English to those of English monolinguals (Winskel, Radach, & Luksaneeyanawin, Citation2009). The frequency of critical target words in the sentences was manipulated so that information could be gained about the effect of spacing on word identification (Radach & Kennedy, Citation2004; Rayner, Citation1998).
Several findings in this study (Winskel et al., Citation2009) suggested that spacing facilitated later word processing rather than word targeting or early lexical segmentation. The refixation measures (gaze duration and total fixation time) were significantly shorter in duration on the target words in the spaced than unspaced sentences, but notably first fixation durations were not different. First fixation landing positions and landing site distributions were also not influenced by the spacing manipulation. First fixation landing positions in both the spaced and unspaced condition were just left of word centre or what is termed the OVP (O'Reagan, Citation1990). Thus, these results gave qualified support for the view that interword spaces have a facilitative function, as word processing was found to be facilitated, but on the other hand, eye guidance (word targeting and lexical segmentation) was neither facilitated nor disrupted by the insertion of interword spaces. Similar findings were found in a subsequent study, in which initial and internal letter transpositions of target words as well as interword spacing were manipulated (Winskel, Perea, & Ratitamkul, Citation2012).
These results on Thai were similar in some respects to what has been found when reading Japanese sentences composed of mixed Hiragana‐Kanji script with interword spaces inserted (Sainio, Hyönä, Bingushi, & Bertram, Citation2007). Japanese has three distinct scripts: Hiragana and Katakana (syllabic scripts), and Kanji (an ideographic script originating from Chinese). For the mixed Kanji‐Hiragana text (ideographic with syllabic), Sainio et al. (Citation2007) found a tendency for spaced text to be read slower than unspaced text, although this difference did not reach significance. Results on reading Hiragana‐only script were similar to English, as spaces facilitated both eye guidance and word identification although the facilitatory effects of spacing were considerably smaller than in English (12% in Hiragana compared to 30–50% in English). In addition, similar to Thai, initial saccade landing positions for Kanji‐Hiragana were not affected by spacing, although the Preferred Viewing Location (PVL) for the two languages was not the same. In the Japanese study, the PVL was found to be at the word beginning, which is typically occupied by a perceptually salient Kanji character, whereas the PVL for Thai was observed to be just left of mid‐word position.
For Chinese, Bai, Yan, Liversedge, Zang, and Rayner (Citation2008) found that sentences with an unfamiliar word spaced format were as easy to read as visually familiar unspaced text. They also found that demarcating word boundaries, either through the use of spaces or highlighting neither hindered nor facilitated reading. In Chinese script, most words include only two to three characters and these characters are often perceptually quite distinct and vary in visual complexity, pointing to the possibility that pre‐attentive feature parsing may play a role in perceptual segmentation (Wang, Inhoff, & Chen, Citation1999). From research on these scripts without interword spaces, there appears to be a balance between two opposing forces that affect the reading of spaced or segmented text; the facilitation effects on word processing and the detrimental effect that the unfamiliar visual text format has on reading (Bai et al., Citation2008; Sainio et al., Citation2007).
If we consider the different demands of reading scripts without interword spaces with those that do, somewhat different processes emerge. Interword spaces serve an important function as they form clear segmentation or word boundary cues in the parafovea prior to word fixation, so that initial word processing can be readily instigated with the end goal of forming a coherent mental representation of the text. In contrast, when a writing system provides no spatial segmentation cues, determining the extent of the letter cluster or characters that forms a word becomes an intrinsic part of the initial stage of word processing. Thus, there is an additional in‐built process or step involved in reading an unspaced script, which involves demarcating where words begin and end using other segmentation cues besides salient interword spaces. Skilled readers of these scripts without interword spaces such as Chinese, Japanese, or Thai have presumably acquired knowledge of the language‐ or script‐specific word segmentation patterns or cues such as the frequency of characters or letter clusters occurring at word boundaries (Bertram, Pollatsek, & Hyönä, Citation2004). In Thai, potential language specific candidates for word or syllable segmentation are, for example, the vowels that occur prior to the consonant at the beginning of the syllable (e.g., โ-ค written as /o:rk/ but spoken as /ro:k/ disease), as they possibly form salient syllabic segmentation cues to the reader. In addition, tone markers that occur above the syllable or lexeme (e.g. หน้าต่-ง /nâ:tà:ŋ/ window) may form effective segmentation cues to the skilled reader. Future research can investigate whether children's reading benefits from the use of spaces or other segmentation cues such as alternating colour words (Perea, Tejero, & Winskel, Citation2015) when learning to read unspaced scripts such as Thai or Chinese.
LETTER POSITION CODING AND INITIAL LETTER ADVANTAGE
In order to understand the fundamentals of reading, it is necessary to examine the early stages of visual‐word recognition (Finkbeiner & Coltheart, Citation2009). Registration of both the identity and position of a letter in a word forms the preliminary but highly significant stage of visual‐word recognition in alphabetic orthographies (Chanceaux & Grainger, Citation2012; Frost, Citation2012; Grainger, Citation2008; Tydgat & Grainger, Citation2009). In order to recognise or distinguish between words (e.g., cat and act), it is essential to identify which letters are where in a given word (i.e., the order of letters in a word).
Research on Roman script indicates that there can be quite a degree of flexibility in the coding of letter position when transposition letter effects are examined (e.g., jugde is readily read as judge) (O'Connor & Forster, Citation1981; Perea & Carreiras, Citation2006; Perea & Lupker, Citation2004; Schoonbaert & Grainger, Citation2004, in English, French, Basque, and Spanish, respectively). Typically, when investigating letter transposition effects, the masked priming paradigm (Forster & Davis, Citation1984) is used with a lexical decision task (where participants decide as quickly as possible if a stimulus is a word or non‐word). It has been found that a given target word (e.g., JUDGE) is responded to more rapidly when it is briefly preceded by a forwardly masked transposed‐letter prime (e.g., jugde) than when it is preceded by an orthographic control (e.g., the replacement‐letter prime jupte). In Roman script, letter position coding is particularly noisy in middle positions, but not in the initial letter position, as an illustration of this, jugde closely resembles judge while ujdge does not. Research on Roman script has consistently failed to find a masked transposed‐letter priming effect when the initial letter is involved (e.g., Perea & Lupker, Citation2007). The commonly held view that has emerged from this research and related research on Roman script is that initial letter position has a privileged role for word recognition in comparison to internal letters (e.g., Chambers, Citation1979; Estes, Allmeyer, & Reder, Citation1976; Gómez, Ratcliff, & Perea, Citation2008; Jordan, Patching, & Thomas, Citation2003; Perea, Citation1998; Rayner & Kaiser, Citation1975; White, Johnson, Liversedge, & Rayner, Citation2008).
An initial letter advantage is also found when participants identify briefly presented strings of five letters (e.g., T G H K N) using a two‐alternative forced choice (2AFC) procedure. In the 2AFC procedure, a string of five characters are briefly presented followed by a choice of two characters, one occurring above and one below one of the characters in the array. Participants are then required to decide which character, either above or below, was present in that corresponding position of the preceding array. A W‐shaped serial position function and initial letter advantage (and to a lesser extent final letter advantage) has been found for Roman script (Tydgat & Grainger, Citation2009; Winskel, Perea, & Peart, Citation2014b; Ziegler, Pech‐Georgel, Dufau, & Grainger, Citation2010). However, a different Λ‐shaped serial position function is typically found when identifying symbols or shapes (e.g., & @ $ % <) (Tydgat & Grainger, Citation2009; Winskel et al., 2014b; Ziegler et al., Citation2010). With symbols, identification accuracy is optimal at the central letter position of fixation and declines as distance from the central position increases. Thus, a marked difference in how Roman script letters and symbols are processed has emerged (for a detailed explanation, see Grainger, Dufau, & Ziegler, Citation2016).
Thai makes an interesting comparison with Roman script, as it is alphabetic but also has characteristics that may result in it being particularly flexible with respect to letter position coding. It does not have interword spaces, which implies that during normal reading there is a degree of ambiguity in relation to which word a given letter belongs to and it also has misaligned vowels, where the orthographic and phonological order of vowels does not necessarily correspond (e.g., the written word ‘odg’ is read as /dog/). This again implies that position coding in Thai needs to be flexible enough so that readers can appropriately encode the letter positions of words with or without these types of vowels.
The masked priming paradigm was used with a lexical decision task (Forster & Davis, Citation1984) to investigate the importance of initial letter position in Thai (Perea, Winskel, & Ratitamkul, Citation2012). A significant masked transposed‐letter priming effect was found when the initial letter was transposed even in short words (e.g., า-ท‐บ-ท was faster than พ-ท‐บ-ท (transposed‐letter condition vs replacement‐letter condition)). This suggests that the role played by the initial letter in Thai is not as critical as in other languages. In a follow‐up study (Winskel et al., Citation2012), this line of research was extended by examining if initial letters have a privileged position in comparison to internal letters in Thai during normal silent reading. Participants’ eye movements were monitored while they read sentences with target words with internal (e.g., porblem) and external (e.g., rpoblem) transposed letters. The researchers were interested in how readily those words could be read when interword spacing and demarcation of word boundaries (using alternating bold text) was manipulated. Results revealed that there was no apparent difference in degree of disruption caused when reading internal and initial transposed‐letter non‐words. This is in marked contrast with results found in Roman script where, consistent with prior evidence from other paradigms in Indo‐European languages, there was greater disruption caused by initial than internal transpositions (White et al., Citation2008). Therefore, these findings on Thai give further support to the view that letter position encoding in Thai is quite flexible, even for initial letter position.
A similar 2AFC procedure as used by Tydgat and Grainger (Citation2009) was conducted to measure identification accuracy for all positions in a string of five characters in Thai native speakers who were also familiar with Roman script (Winskel et al., 2014b). The stimuli consisted of Roman letters, Thai letters, or symbols. A marked difference from what has previously been found for Roman script readers emerged, as there was not a letter/symbol dissociation; in fact, results were similar for letters and symbols (see Fig. 1). An advantage of initial character position for Roman letters, Thai letters, and symbols was found. The absence of a letter/symbol dissociation provides evidence for script‐specific adaptations that have occurred when reading this visually complex and non‐linear alphabetic script without interword spaces. More recently, a similar 2AFC procedure was conducted with biscriptal Sinhalese‐English readers (Jayawardena & Winskel, Citationunder review). The strings of five character stimuli consisted of Roman letters, Sinhala letters, or symbols. The Sinhalese native speakers were skilled readers of both Sinhala and Roman scripts. Sinhala provides an interesting comparison to Thai as it shares some characteristics due to having common origins, as both are Brahmi‐derived scripts. Both Sinhala and Thai are visually complex scripts with non‐linear configurations, as they have letters and diacritics that can occur above, below, or either side of a letter that they modify. Both scripts also have vowels where orthographic order does not necessarily correspond to phonological order (e.g., ‘odg’ would be read as /dog/). Thai has five of these types of vowels and Sinhala has one commonly occurring vowel (the Kombuwa
). A notable difference between the two scripts is that Thai does not have interword spaces.
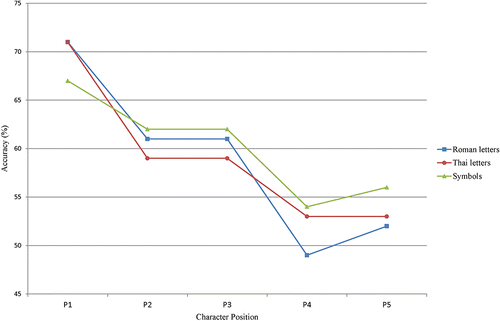
In contrast to the Thai readers, the biscriptal Sinhalese readers displayed distinct serial position functions for identifying letter characters in Roman script, Sinhala script, and symbols (see Fig. 2). For Roman script and symbols, the Sinhalese speakers displayed analogous results as in previous studies with French and English speakers (i.e., an initial letter advantage and W‐shaped function for Roman letters and a Λ‐shaped function for symbols) (Tydgat & Grainger, Citation2009; Winskel et al., 2014b; Ziegler et al., Citation2010). In contrast for Sinhala script, the Sinhalese speakers displayed a strong linear function with accuracy for letter positions 1, 2, and 3 similarly advantaged. There appears to be a heightened attentional response to initial letter positions rather than just the initial letter position occurring, which is in line with the non‐linear characteristics of Sinhala script.
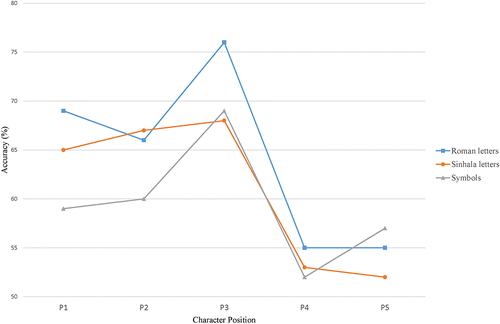
Even though, Sinhala and Thai scripts share some characteristics, the results for the Thai and Sinhalese speakers diverged. The Sinhalese speakers displayed distinct serial position functions for all three stimuli types (Roman letters, Sinhala letters, symbols) whereas the Thais displayed strikingly similar patterns for Roman letters, Thai letters, and symbols. An initial letter advantage was also apparent in the Thai data whereas letter positions 1, 2, and 3 were similarly advantaged when the Sinhalese speakers identified strings of Sinhala letters. These different patterns displayed may be due to script‐specific differences. Notably, Thai does not have interword spaces whereas Sinhala script does. Consequently, attending to word boundaries becomes an intrinsic part of the initial stage of word processing in Thai. An additional explanation is that these observed differences could be partially accounted for by the language proficiency levels of the Thai and Sinhalese participants in the different scripts. The Sinhalese participants were highly skilled at reading both Sinhala and Roman scripts, whereas the Thai participants were substantially more proficient in reading Thai than Roman script. Transference of attentional responses across scripts could have occurred which is influenced by proficiency levels in the two scripts. Thus, the highly proficient biscriptal Sinhalese readers showed quite distinct orthography‐specific patterns for identifying letters in Roman script and Sinhala script. In contrast, the more unbalanced Thai biscriptals displayed similar responses in both Thai and Roman scripts, which could be due to transference from the first learned orthography, Thai, to the second learned orthography, English. There were also shared similarities as both Thai and Sinhala had equivalent accuracy scores for letter positions 2 and 3, which diverges from the classic W‐shaped function found for Roman letters in French and English speakers (Tydgat & Grainger, Citation2009; Winskel et al., 2014b; Ziegler et al., Citation2010). These similar attentional responses on initial letters could be due to the shared nonlinear characteristics of these two orthographies. One suggestion is that these characteristic patterns observed for Sinhala, Thai, and Roman scripts have developed as a specialised adaptive mechanism to optimise the processing of letters when reading these distinctive scripts.
This research on letter position coding in different orthographies points to orthography‐specific effects operating, even in the early stages of letter encoding, in visual‐word recognition, and reading. Further experiments are required to verify and extend this line of research to other lesser studied Brahmi‐derived scripts such as the widely used Devanagari, Tamil, or Kannada. The Semitic languages (e.g., Hebrew, Arabic), in which the root letters play a key role in lexical access (Perea, Abu Mallouh, García‐Orza, & Carreiras, Citation2011; Velan & Frost, Citation2011), may also offer interesting opportunities for further research, as they may not be as sensitive to the initial letter position as European languages.
ROLE OF LEXICAL TONE
In many languages (e.g., Chinese, Vietnamese, Burmese, and Thai), tone forms an integral element of the syllable, and serves an essential function in distinguishing meanings of syllables and words with identical phonological structure. Even though tonal languages are very widely spoken, they still remain understudied. Tonal languages such as Thai and Mandarin Chinese have many different tone homophones where words differ only in lexical tone. For example in Mandarin Chinese, the most widely spoken tonal language, the syllable /da/ has quite distinct meanings depending on its tone: /da1/ (high level, first tone) (to put up), /da2/ (rising, second tone) (to answer), /da3/ (falling rising, third tone) (to hit), and /da4/ (falling, fourth tone) (big). Tone is not explicitly written in Chinese (e.g., /da1/, /da2/, /da3/, and /da4/ corresponds to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively), but significantly in Thai, tone is explicitly represented in its alphabetic script. Thus, Thai offers a unique opportunity to investigate the role of lexical tone during visual‐word recognition through manipulating its distinctive orthographic features. One important research question is whether tonal information plays a critical role in the early stages of lexical access when reading in tonal languages as segmental information (i.e., consonantal and vowel information) does, or whether its effect occurs at a later processing stage, or even after lexical retrieval. This research also allows us to examine whether common processes occur in alphabetic tonal orthographies such as Thai as in logographic tonal orthographies such as Mandarin Chinese.
, respectively), but significantly in Thai, tone is explicitly represented in its alphabetic script. Thus, Thai offers a unique opportunity to investigate the role of lexical tone during visual‐word recognition through manipulating its distinctive orthographic features. One important research question is whether tonal information plays a critical role in the early stages of lexical access when reading in tonal languages as segmental information (i.e., consonantal and vowel information) does, or whether its effect occurs at a later processing stage, or even after lexical retrieval. This research also allows us to examine whether common processes occur in alphabetic tonal orthographies such as Thai as in logographic tonal orthographies such as Mandarin Chinese.
Previous research on Mandarin Chinese has failed to find an effect of tonal information in visual‐word processing using the masked priming paradigm, a technique that taps into early processing (Forster & Davis, Citation1984; Grainger, Citation2008). In a series of word naming experiments, Chen, Lin, and Ferrand (Citation2003) found faster response times on a bisyllabic target word, when a briefly presented word prime shared the initial syllable with the target regardless of whether the syllable had the same tone or not as the target (e.g., the prime 爸 /ba4/ (father) facilitated the processing 拔营 /ba2 ying2/ (break up camp) more than the prime 败 /bai4/ (failure); see also You, Zhang, & Verdonschot, Citation2012, for a similar finding). The presence of an atonal effect of the syllable in Chinese suggests that ‘the syllable (lacking the tone) is a stored phonological chunk’ (Chen et al., Citation2003, p. 116) and that the tone does not play a special role early in visual‐word processing (see Taft, Zhu, & Peng, Citation1999). Thus, this research on Chinese using the masked priming paradigm indicates that at the phonological level, segmental information (i.e., the syllable) appears to be more important than the encoding of tone. Similarly, Taft and Chen (Citation1992) using a series of homophone judgement tasks found that segmental information played a prominent role in lexical access. In a more recent study, Wang, Li, and Lin (Citation2015) conducted two primed naming experiments using Chinese characters and Pinyin letters as primes presented at three different durations (57, 100, and 200-ms). Pinyin, which is taught to children prior to learning to read Chinese characters in mainland China, uses alphabetic Roman script for segmental and tonal information (e.g., mā means mother). Results indicated that with Chinese characters, segmental, and tonal constituents are represented and encoded as an integral unit, but with Pinyin where phonological information is explicitly represented, segmental and tonal information are represented separately and tonal information is accessed at a somewhat later stage.
Spinks, Liu, Perfetti, and Tan (Citation2000) also investigated whether phonological and tonal information is automatically activated in Mandarin Chinese visual‐word recognition using the Stroop task (Stroop, Citation1935). In the Stroop task, participants are required to name the colour of the word rather than the actual word. Typically, it is found that people are faster in naming the written colour of a congruent colour word (e.g., GREEN written in the colour green) and slower to name the colour of an incongruent colour word (e.g., GREEN written in red). In the Spinks et al. study, participants named the presentation colour of the following Chinese characters (e.g., 红, hong2, (red)), homophones of the colour characters (same segment (S)—same tone (T): S+T+; e.g., 洪 /hong2/ (flood)), homophones that only shared the same syllable segment (S+T—e.g., 轰, /hong1/ (boom)), and a neutral stimulus (S–T—e.g.,贯, /guan4/ (passing through)). They found significant facilitation effects for congruent S+T+ (e.g., 洪 in red) and S+T—characters (e.g., 轰 in red), and an interference effect for incongruent S+T+ characters (e.g., 洪 in green). However, no significant effect was found for incongruent S+T—trials (e.g., 轰 in green) but as congruent S+T—characters did facilitate naming latencies, the authors suggested that syllable segments are activated independently of tones. Also as incongruent S+T—did not produce significant inhibition, whereas incongruent S+T+ did, they concluded that tones as well as segments are both activated. In a follow‐up study, Li, Lin, Wang, and Jiang (Citation2013) used a similar Stroop task with Mandarin Chinese speakers but with the inclusion of an S–T+ condition. They found that the Stroop effect was stronger for S+T—than for S–T+ trials, and was similar between S+T+ and S+T—trials. From these critical comparisons, they concluded that both tonal and segmental information contribute to lexical access, however, segmental information appears to play a more prominent role than tonal information.
There was a discrepancy in results found for tone activation in the studies that used the Stroop paradigm in contrast to the other studies. This is likely due to differences in task characteristics. In the Stroop task, the target colour and character or word are presented simultaneously and stay on the screen until a naming response is made whereas in the priming paradigm, for example, the prime and target are presented consecutively (Wang et al., Citation2015). Moreover, the prime is only presented for a brief duration which may prevent separate activation of segmental and tonal information occurring.
Winskel and Perea (Citation2014) manipulated the distinctive orthographic features of Thai to investigate the contribution of tone at the orthographic/phonological level during the early stages of word processing using a masked priming experiment—with both lexical decision and word naming tasks. For a given target word (e.g., ห้-ง /hᴐ^:ŋ/ (room)), five priming conditions were created: (1) identity (e.g., ห้-ง /hᴐ^:ŋ/), (2) same initial consonant, but with a different tone marker (e.g., ห่-ง /hᴐ`:ŋ/), (3) different initial consonant, but with the same tone marker (e.g., ศ้-ง /sᴐ^:ŋ/), (4) orthographic control (different initial consonant, different tone marker) (e.g., ศ่-ง /sᴐ`:ŋ/), and (5) same tone homophony, but with a different initial consonant and different tone marker (e.g., ธ่-ง /thᴐ^:ŋ/). Results revealed that there was an advantage of the identity condition (ห้-ง /hᴐ:ŋ2/–ห้-ง /hᴐ:ŋ2/ C+T+) relative to the priming condition, which had the same initial consonant but with a different tone marker (ห่-ง /hᴐ:ŋ1/—ห้-ง /hᴐ:ŋ2/ C+T–). Moreover, the lack of a purely phonological effect of tone occurred both when the tone in the prime had the same orthographic tone marker (ศ้-ง /sᴐ^:ŋ/—ห้-ง /hᴐ^:ŋ/ C‐T++) and when the tone had the same phonological tone (ธ่-ง /thᴐ^:ŋ/—ห้-ง /hᴐ^:ŋ/ C‐T−+) as in the target word. It was surmised that segmental information (i.e., consonantal information) is more important than tone information (i.e., tone marker) in the early stages of visual‐word processing in Thai and that access to (phonological) tone information during the process of visual‐word recognition occurs relatively late.
More recently, Winskel, Ratitamkul, and Charoensit (Citationin press) used Thai colour words and their orthographic neighbours as stimuli to investigate the role of lexical tone using the Stroop task. In this study, it was found that the colour words (e.g., ข-ว /khã:w/ (white)) were not more facilitative than the tone different words (e.g., ข่-ว /khà:w/(news)), which supports the view that segmental information is better represented in the Thai mental lexicon than tonal information. However, a greater interference effect of the colour words than the tone different words was found, but which only occurred when the syllable segment was the same as the colour target word. Thus, tonal information had a constraining effect when segmental and tonal information corresponded to the colour target word. Furthermore, we did not find that tonal information in isolation was activated, as the S‐T+ condition (where the tone was the same as the target colour word) (e.g., ผ-ม /ph
![]() :m/ (thin)) was not more facilitative than the neutral control word S‐T‐condition (where the tone was not the same) (e.g., ถ้-ย /thûaj/ (cup)). In contrast, Li et al. (Citation2013) found a significant facilitation effect of the congruent S‐T+ homophone condition in Mandarin Chinese. On this basis, they proposed that tonal information plays an independent role in visual‐word recognition in Mandarin Chinese. The more influential role of tone in Mandarin Chinese in comparison to Thai could be due to the importance of tone in distinguishing between the numerous homophones in Chinese. In Thai, tonal information is represented orthographically in its script and homophones are not as extensive as in Chinese, so phonological activation of tone is possibly not as critical as in Mandarin Chinese.
:m/ (thin)) was not more facilitative than the neutral control word S‐T‐condition (where the tone was not the same) (e.g., ถ้-ย /thûaj/ (cup)). In contrast, Li et al. (Citation2013) found a significant facilitation effect of the congruent S‐T+ homophone condition in Mandarin Chinese. On this basis, they proposed that tonal information plays an independent role in visual‐word recognition in Mandarin Chinese. The more influential role of tone in Mandarin Chinese in comparison to Thai could be due to the importance of tone in distinguishing between the numerous homophones in Chinese. In Thai, tonal information is represented orthographically in its script and homophones are not as extensive as in Chinese, so phonological activation of tone is possibly not as critical as in Mandarin Chinese.
In summary, it appears from this research on Thai and Chinese that segmental information takes precedence over tonal information in visual‐word recognition. Importantly, Tong, Francis, and Gandour (Citation2007) have pointed out that each tone is associated with more words than each segment. Consequently, tonal information exerts fewer constraints on word recognition than segmental information, which could account for these unbalanced results. Li et al. (Citation2013) have further suggested that segmental and tonal information could be activated in a hierarchical order such that readers first look for segmental information and then if necessary look for tonal information to resolve any ambiguity. Future research needs to include the study of a broader range of tonal languages such as Vietnamese and Burmese, so we can build a fuller more representative picture of lexical tone processing in reading.
CONCLUSIONS
The general goal of reading is to obtain meaning from what is written on the page through decoding the visual symbols of a script; however, the processes and pathways involved in attaining this mental representation substantially differ between writing systems and orthographies. The numerous scripts around the world used to write different languages vary in terms of both their visual characteristics and what aspects of language are encoded in their script. In the current review, three areas of reading have been focused on where there is substantial variation across orthographies: (1) reading with and without interword spaces, (2) flexibility in letter position coding and initial letter position advantage, and (3) the role of lexical tone when reading. Different orthographies exert different processing demands and challenges to the reader. In order to effectively read a script, readers need to attend to the distinctive features of the visual symbols of the script and how they interface with the particular language of the speaker. Attention needs to be focused on these critical or salient features of the orthography that are vital in forming a mental representation. Thus, attentional resources need to be differentially allocated dependent on the specific characteristics of the orthography and the role that they play in forming a coherent mental representation of the words or text. For example, in scripts with interword spaces, these salient visual word segmentation cues form distinct perceptual markers for word boundaries, whereas in unspaced scripts, other orthography‐specific cues need to be identified and utilised.
From investigating the function of interword spaces in Thai, a script that does not have such salient visual segmentation cues, we found qualified support for the facilitative function of interword spaces, as word processing was facilitated but eye guidance was neither facilitated nor disrupted by the insertion of spaces. Thus, comprehending words were facilitated by insertion of the spaces, but the movement of the eyes through the text was not affected. In Chinese, sentences with an unfamiliar word spaced format were as easy to read as visually familiar unspaced text (Bai et al., Citation2008). A more complex picture emerged for Japanese with its mixed script. When reading Japanese Hiragana‐only script, Sainio et al. (Citation2007) found similar results to English, as spaces facilitated both eye guidance and word identification to some extent. However, for mixed Kanji‐Hiragana text, a tendency was found for spaced text to be read slower than unspaced text. Thus, there are script‐specific differences in the effect that spacing or segmentation has on reading these scripts. Readers of such scripts without salient interword spaces need to learn script‐specific cues for segmenting words. This becomes an intrinsic part of the initial stage of lexical processing when reading these types of scripts.
Research indicates that letter position uncertainty varies across languages. In Roman script, there is flexibility in letter position coding for internal letters but not for initial letters, as the initial letter plays a critical role in lexical processing. In contrast in Thai, initial letter position also appears to be relatively flexible and the initial letter position is not as critical as in Roman script, which is in line with the characteristics of Thai. This contrasts with research on Semitic languages where letter position coding has been shown to have a high degree of rigidity due to the key role that root letters play in these languages (Frost, Citation2012; Perfetti et al., Citation2007; Velan & Frost, Citation2007, Citation2009). Thus, research supports the view that letter position encoding varies across languages and is influenced by the architecture of the language and how it maps onto its script.
Lexical tone plays a critical role in many languages in the world, as it differentiates between phonologically similar syllables and words. In some scripts, such as Thai, tone is visually represented in the script, so readers have these visual cues when reading Thai, whereas in Chinese other more top‐down processes need to be used. A key question is whether tonal information plays a role in the early stages of lexical access in tonal languages (as segmental information does) or whether its effect occurs at a later processing stage, or even after lexical retrieval. Research, so far, on Thai and Chinese indicates that segmental information takes precedence over tonal information in visual‐word recognition and tonal information is processed at a later stage in lexical access.
A contentious and much debated question is whether universals in reading do exist and can be specified and generalised to all writing systems and orthographies. Some researchers have the view that there are no such universals of reading and a universal model of reading cannot be attained (e.g., Coltheart & Crain, Citation2012). In contrast, Frost (Citation2012) advocates that, we need to focus on what is invariant in orthographic processing across writing systems, for example ‘common cognitive procedures’, if we are to achieve this goal. However, determining what are common processes or mechanisms is quite a challenge as writing systems and orthographies around the world vary enormously. Gómez and Silins (Citation2012) argue that the starting point of any ‘universal’ theory of visual‐word recognition should be the visual system that is shared by all readers. In addition, recent neuroimaging research looks like a promising area for future research. The visual word form area (VWFA) appears to play a key role in visual‐word recognition and the processing of orthographic information (Cohen et al., Citation2000; Dehaene & Cohen, Citation2011). It is also important to recognise that reading involves a much more complex process than just identifying words in isolation, as reading is ultimately the comprehension of strings of words, sentences, and text (Liversedge et al., Citation2016).
Finally, by investigating reading and reading processes in lesser studied writing systems or orthographies, we can gain a greater understanding of the underlying processes and mechanisms involved in reading. We can also gain greater insights into what are common or universal processes in reading and what are shaped by the particular orthography of the speaker. Research on more diverse or lesser studied orthographies not only make useful comparisons with the much studied Roman script and European languages but also contributes to our understanding of reading in meaningful and significant ways and broadens as well as challenges our current understanding of reading and reading processes.
REFERENCES
- Bai, X. , Yan, G. , Liversedge, S. P. , Zang, C. , & Rayner, K. (2008). Reading spaced and unspaced Chinese text: Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 34, 1277–1287. doi:https://doi.org/10.1037/0096-1523.34.5.1277
- Bertram, R. , Pollatsek, A. , & Hyönä, J. (2004). Morphological parsing and the use of segmentation cues in reading Finnish compounds. Journal of Memory and Language, 51, 325–345. doi:https://doi.org/10.1016/j.jml.2004.06.005
- Byrne, B. , Samuelsson, S. , & Olson, R. K. (2014). Reading and reading acquisition in European languages. In H. Winskel & P. Padakannaya (Eds.), South and Southeast Asian psycholinguistics (pp. 159–170). Cambridge, England: Cambridge University Press.
- Chambers, S. M. (1979). Letter and order information in lexical access. Journal of Verbal Learning and Verbal Behavior, 18, 225–241.
- Chanceaux, M. , & Grainger, J. (2012). Serial position effects in the identification of letters, digits, symbols, and shapes in peripheral vision. Acta Psychologica, 141(2), 149–158. doi:https://doi.org/10.1016/j.actpsy.2012.08.001
- Chen, J.‐Y. , Lin, W.‐C. , & Ferrand, L. (2003). Masked priming of the syllable in Mandarin Chinese speech production. Chinese Journal of Psychology, 45, 107–120.
- Cohen, L. , Dehaene, S. , Naccache, L. , Lehéricy, S. , Dehaene‐lambertz, G. , Hénaff, M. A. , & Michel, F. (2000). The visual word form area: Spatial and temporal characterization of an initial stage of reading in normal subjects and posterior split‐brain patients. Brain, 123, 291–307. doi:https://doi.org/10.1093/brain/123.2.291
- Coltheart, M. , & Crain, S. (2012). Are there universals of reading? We don't believe so. Behavioral and Brain Sciences, 35, 282–283. doi:https://doi.org/10.1017/S0140525X12000155
- Dehaene, S. , & Cohen, L. (2011). The unique role of the visual word form area in reading. Trends in Cognitive Sciences, 15, 254–262. doi:https://doi.org/10.1016/j.tics.2011.04.003
- Estes, W. K. , Allmeyer, D. H. , & Reder, S. M. (1976). Serial position functions for letter identification at brief and extended exposure durations. Perception & Psychophysics, 19, 1–15.
- Finkbeiner, M. , & Coltheart, M. (2009). Letter recognition: from perception to representation. Cognitive Neuropsychology, 26(1), 1–6. doi:https://doi.org/10.1080/02643290902905294
- Forster, K. I. , & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 680–698.
- Frost, R. (2012). Towards a universal model of reading. Behavioral and Brain Sciences, 35, 263–279. doi:https://doi.org/10.1017/S0140525X11001841
- Gómez, P. , Ratcliff, R. , & Perea, M. (2008). The overlap model: A model of letter position coding. Psychological Review, 115, 577–601. doi:https://doi.org/10.1037/a0012667
- Gómez, P. , & Silins, S. (2012). Visual word recognition models should also be constrained by knowledge about the visual system. Behavioral and Brain Sciences, 35, 287. doi:https://doi.org/10.1017/S0140525X12000179
- Grainger, J. (2008). Cracking the orthographic code: An introduction. Language and Cognitive Processes, 23, 1–35. doi:https://doi.org/10.1080/01690960701578013
- Grainger, J. , Dufau, S. , & Ziegler, J. (2016). A vision of reading. Trends in Cognitive Science, 20, 171–179. doi:https://doi.org/10.1016/j.tics.2015.12.008
- Jayawardena, R. , & Winskel, H. (under review). Assessing the Modified Receptive Field (MRF) Theory: Evidence from Sinhalese‐English Bilinguals. Acta Psychologica.
- Jordan, T. R. , Patching, G. R. , & Thomas, S. M. (2003). Assessing the role of hemispheric specialization, serial‐position processing and retinal eccentricity in lateralized word perception. Cognitive Neuropsychology, 20, 49–71. doi:https://doi.org/10.1080/02643290244000185
- Li, C. , Lin, C. Y. , Wang, M. , & Jiang, N. (2013). The activation of segmental and tonal information in visual word recognition. Psychonomic Bulletin Review, 20, 773–779. doi:https://doi.org/10.3758/s13423-013-0395-2
- Liversedge, S. P. , Drieghe, D. , Li, X. , Yan, G. , Xuejun, X. , & Hyönä, J. (2016). Universality in eye movements and reading: A trilingual investigation. Cognition, 147, 1–20.
- Morris, R. K. , Rayner, K. , & Pollatsek, A. (1990). Eye movement guidance in reading: The role of parafoveal letter and space information. Journal of Experimental Psychology: Human Perception and Performance, 16, 268–281.
- O'connor, R. E. , & Forster, K. I. (1981). Criterion bias and search sequence bias in word recognition. Memory and Cognition, 9, 78–92.
- O'reagan, J. K. (1990). Eye movements and reading. In E. Kowler (Ed.), Reviews of Oculomotor research: Eye movements and their role in visual and cognitive processes (Vol. 4, pp. 395–453). Amsterdam, the Netherlands: Elsevier.
- Perea, M. (1998). Orthographic neighbours are not all equal: Evidence using an identification technique. Language and Cognitive Processes, 13, 77–90.
- Perea, M. , Abu mallouh, R. , García‐orza, J. , & Carreiras, M. (2011). Masked priming effects are modulated by expertise in the script. Quarterly Journal of Experimental Psychology, 64, 902–919. doi:https://doi.org/10.1080/17470218.2010.512088
- Perea, M. , & Carreiras, M. (2006). Do transposed‐letter similarity effects occur at a prelexical phonological level? Quarterly Journal of Experimental Psychology, 59, 1600–1613.
- Perea, M. , & Lupker, S. J. (2004). Can CANISO activate CASINO? Transposed‐letter similarity effects with nonadjacent letter positions. Journal of Memory and Language, 51, 231–246. doi:https://doi.org/10.1027/1618-3169.53.4.308
- Perea, M. , & Lupker, S. J. (2007). La posición de las letras externas en el reconocimiento visual de palabras. Psicothema, 19, 559–564.
- Perea, M. , Tejero, P. , & Winskel, H. (2015). Can colours be used to segment words when reading? Acta Psychologica, 159, 8–13.
- Perea, M. , Winskel, H. , & Ratitamkul, T. (2012). On the flexibility of letter position coding during lexical processing: The case of Thai. Experimental Psychology, 59(2), 68–73. doi:https://doi.org/10.1027/1618-3169/a000127
- Perfetti, C. A. , & Dunlap, S. (2008). Learning to read: General principles and writing system variations. In K. Koda & A. Zehler (Eds.), Learning to read across languages (pp. 13–38). Mahwah, NJ: Erlbaum.
- Perfetti, C. A. , Liu, Y. , Fiez, J. , Nelson, J. , Bolger, D. J. , & Tan, L.‐H. (2007). Reading in two writing systems: Accommodation and assimilation of the brain's reading network. Bilingualism: Language and Cognition, 10, 131–146. doi:https://doi.org/10.1017/S1366728907002891
- Perfetti, C. A. , & Zhang, S. (1995). Very early phonological activation in Chinese reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(1), 24–33.
- Radach, R. , & Kennedy, A. (2004). Theoretical perspectives on eye movements in reading. Past controversies, current deficits and an agenda for future research. European Journal of Cognitive Psychology, 16, 3–26. doi:https://doi.org/10.1080/09541440340000295
- Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422.
- Rayner, K. , Fischer, M. H. , & Pollatsek, A. (1998). Unspaced text interferes with both word identification and eye movement control. Vision Research, 38, 1129–1144.
- Rayner, K. , & Kaiser, J. S. (1975). Reading mutilated text. Journal of Educational Psychology, 67, 301–306.
- Sainio, M. , Hyönä, J. , Bingushi, K. , & Bertram, R. (2007). The role of interword spacing in reading Japanese: An eye movement study. Vision Research, 47, 2575–2584. doi:https://doi.org/10.1016/j.visres.2007.05.017
- Schoonbaert, S. , & Grainger, J. (2004). Letter position coding in printed word perception: Effects of repeated and transposed letters. Language and Cognitive Processes, 19, 333–367. doi:https://doi.org/10.1080/01690960344000198
- Share, D. L. (2008). On the Anglocentricities of current reading research and practice: The perils of overreliance on an “outlier” orthography. Psychological Bulletin, 134, 584–615. doi:https://doi.org/10.1037/0033-2909.134.4.584
- Spinks, J. A. , Liu, Y. , Perfetti, C. A. , & Tan, L. H. (2000). Reading Chinese characters for meaning: The role of phonological information. Cognition, 76, B1–B11.
- Spragins, A. B. , Lefton, L. A. , & Fischer, D. F. (1976). Eye movements while reading and searching spatially transformed text: A developmental perspective. Memory and Cognition, 4, 36–42.
- Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18, 643–662. doi:https://doi.org/10.1037/0096-3445.121.1.15
- Taft, M. , & Chen, H. C. (1992). Judging homophony in Chinese: The influence of tones. Advances in Psychology, 90, 151–172.
- Taft, M. , Zhu, X. , & Peng, D. (1999). Positional specificity of radicals in Chinese character recognition. Journal of Memory and Language, 40, 498–519.
- Tong, Y. X. , Francis, A. L. , & Gandour, J. T. (2007). Processing dependencies between segmental and suprasegmental features in Mandarin Chinese. Language & Cognitive Processes, 23, 689–708. doi:https://doi.org/10.1080/01690960701728261
- Tydgat, I. , & Grainger, J. (2009). Serial position effects in the identification of letters, digits and symbols. Journal of Experimental Psychology: Human Perception and Performance, 35, 480–498. doi:https://doi.org/10.1037/a0013027
- Velan, H. , & Frost, R. (2007). Cambridge University Vs. Hebrew University: The impact of letter transposition on reading English and Hebrew. Psychonomic Bulletin & Review, 14, 913–918.
- Velan, H. , & Frost, R. (2009). Letter‐transposition effects are not universal: The impact of transposing letters in Hebrew. Journal of Memory and Language, 61, 285–302. doi:https://doi.org/10.1016/j.jml.2009.05.003
- Velan, H. , & Frost, R. (2011). Words with and without internal structure: What determines the nature of orthographic and morphological processing? Cognition, 118, 141–156. doi:https://doi.org/10.1016/j.cognition.2010.11.013
- Wang, J. , Inhoff, A. W. , & Chen, H.‐C. (1999). Reading Chinese script. A cognitive analysis. Mahwah, NJ: Erlbaum.
- Wang, M. , Li, C. , & Lin, C. Y. (2015). The contributions of segmental and suprasegmental information in reading Chinese characters aloud. PLoS One, 10(11), e0142060.
- White, S. J. , Johnson, R. L. , Liversedge, S. P. , & Rayner, K. (2008). Eye movements when reading transposed text: The importance of word‐beginning letters. Journal of Experimental Psychology: Human Perception and Performance, 34, 1261–1276. doi:https://doi.org/10.1037/0096-1523.34.5.1261
- Winskel, H. (2014). Learning to read and write in Thai. In H. Winskel & P. Padakannaya (Eds.), South and Southeast Asian psycholinguistics (pp. 171–178). Cambridge, England: Cambridge University Press.
- Winskel, H. , & Iemwanthong, K. (2010). Reading and spelling acquisition in Thai children. Reading and Writing: An Interdisciplinary Journal, 23, 1021–1053. doi:https://doi.org/10.1007/s11145-009-9194-6
- Winskel, H. , Padakannaya, P. , & Pandey, A. (2014a). Eye movements and reading in the alphasyllabic scripts of South and Southeast Asia. In H. Winskel & P. Padakannaya (Eds.), South and Southeast Asian psycholinguistics (pp. 315–328). Cambridge, England: Cambridge University Press.
- Winskel, H. , & Perea, M. (2014). Does tonal information affect the early stages of visual‐word processing in Thai? Quarterly Journal of Experimental Psychology, 67(2), 209–219. doi:https://doi.org/10.1080/17470218.2013.813054
- Winskel, H. , Perea, M. , & Peart, E. (2014b). Testing the flexibility of the modified receptive field (MRF) theory: Evidence from an unspaced orthography (Thai). Acta Psychologica, 150, 55–60. doi:https://doi.org/10.1016/j.actpsy.2014.04.008
- Winskel, H. , Perea, M. , & Ratitamkul, T. (2012). On the flexibility of letter position coding during lexical processing: Evidence from eye movements when reading Thai. Quarterly Journal of Experimental Psychology, 65(8), 1522–1536. doi:https://doi.org/10.1080/17470218.2012.658409
- Winskel, H. , Radach, R. , & Luksaneeyanawin, S. (2009). Eye movements when reading spaced and unspaced Thai and English: A comparison of Thai‐English bilinguals and English monolinguals. Journal of Memory and Language, 61, 339–351. doi:https://doi.org/10.1016/j.jml.2009.07.002
- Winskel, H. , Ratitamkul, T. , & Charoensit, A. (in press). The role of tone and phonological and orthographic information in visual‐word recognition in Thai. Quarterly Journal of Experimental Psychology.
- You, W.‐P. , Zhang, Q.‐F. , & Verdonschot, R. G. (2012). Masked syllable priming effects in word and picture naming in Chinese. PLoS One, 7(10), e46595. doi:https://doi.org/10.1371/journal.pone.0046595
- Ziegler, J. C. , Pech‐georgel, C. , Dufau, S. , & Grainger, J. (2010). Rapid processing of letters, digits and symbols: what purely visual‐attentional deficit in developmental dyslexia? Developmental Science, 13(4), F8–F14. doi:https://doi.org/10.1111/j.1467-7687.2010.00983.x