Abstract
Estimation based on effect sizes, confidence intervals, and meta‐analysis usually provides a more informative analysis of empirical results than does statistical significance testing, which has long been the conventional choice in psychology. The sixth edition of the American Psychological Association Publication Manual now recommends that psychologists should, wherever possible, use estimation and base their interpretation of research results on point and interval estimates. We outline the Manual's recommendations and suggest how they can be put into practice: adopt an estimation framework, starting with the formulation of research aims as ‘How much?’ or ‘To what extent?’ questions. Calculate from your data effect size estimates and confidence intervals to answer those questions, then interpret. Wherever appropriate, use meta‐analysis to integrate evidence over studies. The Manual's recommendations can assist psychologists improve they way they do their statistics and help build a more quantitative and cumulative discipline.
Geoff Cumming was a member of the APA Publication Manual Revision Working Group for Statistics, but the views expressed in this article are the authors'. This research was supported by the Australian Research Council. We thank Neil Thomason and Eleanor Wertheim for valuable comments on drafts.
In 1996, Geoff Hammond argued in this journal that ‘psychologists should dispense with statistical hypothesis testing and . . . report effect size measures together with an indication of their likely error’ (p. 104). Null hypothesis significance testing (NHST) is psychology's dominant approach to data analysis, but it has been subjected to cogent criticism since the 1960s. Hammond stated that ‘The criticisms [of NHST] themselves are not in dispute. . . . [They] are now a ground swell that can no longer be ignored’ (p. 104). Today, a decade and a half later, NHST may still dominate, but there are strong signs of change that, at last, justify Hammond's optimistic remark. The most important sign may be that the sixth edition of the American Psychological Association (CitationAPA; 2010) Publication Manual includes new statistical recommendations to use estimation.
Our aims are to discuss the statistical advice in the Manual (CitationAPA, 2010) and to offer suggestions for putting them into practice. First, we mention some developments since 1996, then outline an estimation approach that we feel provides the best framework for considering the Manual's recommendations and for improving statistical practices in psychology.
SIGNS OF CHANGE SINCE 1996
As Hammond was writing, the APA was responding to ongoing criticism of NHST by establishing its Task Force on Statistical Inference (TFSI). The report of the task force (CitationWilkinson & TFSI, 1999) ranged widely beyond NHST, recommended confidence intervals (CIs), and is an excellent guide to conducting research. It is now freely available from the APA Style website (http://www.tinyurl.com/tfsi1999). In 2004, Rex CitationKline published Beyond Significance Testing: Reforming Data Analysis Methods in Behavioral Research. Chapter 3 gave an overview of the deficiencies of NHST, and recommendations for what psychology should do. That chapter also is now available from the APA website (http://www.tinyurl.com/klinechap3). Wilkinson et al. and Kline's Chapter 3 provide a basic rationale and blueprint for improved statistical practices.
Changes to practice have been slow but are now convincing. CitationCumming et al. (2007) reported a survey of 10 leading psychology journals and found that the percentage of articles reporting CIs was small, but increased markedly, from 4% in 1998 to 11% in 2005–2006. The percentage of articles that included a figure with error bars increased from 11% to 38% over the same period. Many psychology journals now encourage or require reporting of effect sizes (ESs) and CIs, including the Journal of Consulting and Clinical Psychology (CitationLa Greca, 2005) and Neuropsychology (CitationRao, 2008). NHST may still dominate, but statistical reform is making important progress.
AN ESTIMATION FRAMEWORK FOR RESEARCH
We see the Manual's recommendations as fitting within an estimation framework, which we recommend as a much more informative approach than NHST. It is based on ESs, CIs, and meta‐analysis. For a start, formulate research aims as ‘How much?’ or ‘To what extent?’ estimation questions, rather than the much more limited ‘Is there an effect?’ questions that NHST seeks to answer. Estimation questions naturally prompt answers that are ES estimates, and CIs on those ESs indicate the precision of the estimates. Meta‐analysis permits the integration of evidence over a number of studies and usually gives ES estimates that are more precise—have narrower CIs—than any single study can give. Interpretation of results should focus on the ESs and CIs, and there should be discussion of theoretical and practical importance.
We do not underestimate the difficulty for many psychologists of changing to estimation thinking after a lifetime of using p‐values to reject or not reject a null hypothesis. However, estimation, including meta‐analysis, should support the development of more quantitative theories in psychology and a more cumulative, progressive discipline. Most basically, estimation is simply more informative than NHST.
We suspect that, once the requirement to use NHST is weakened, an estimation approach may feel natural. What could be more logical than asking ‘How large is the effect?’ and finding an answer ‘This much, give or take that margin of error (MOE)’. Many scientific disciplines, including physics and chemistry, have made enormous progress while routinely using estimation and seldom using NHST.
CitationFaulkner, Fidler, and Cumming (2008) reported that clinical psychologists, when asked what information they wanted from a randomised control trial (RCT) report, said that they wanted to know about the size and clinical importance of the effect of the therapy, as well as whether the therapy had an effect. Faulkner at el. analysed 193 reports of RCTs of psychological therapies published in leading psychology and psychiatry journals. They reported that 99% of the articles used NHST, but CIs were rarely provided. They thus identified a large mismatch between what was typically published—predominantly conclusions based on NHST as to whether an effect existed—and what practitioners need to know—the size and clinical importance of effects. An estimation framework and full interpretation of ESs and CIs is required, to give practitioners what they need—as well as to improve research progress. In other words, psychologists who wish to adopt evidence‐based practice require quantitative research‐based guidance, and estimation and meta‐analysis are the best ways to formulate such guidance.
A fuller discussion of the topics covered in this article, and practical examples, are provided by CitationCumming (2012), a book entitled Understanding the New Statistics: Effect Sizes, Confidence Intervals, and Meta‐Analysis. A software package (Exploratory Software for Confidence Intervals (ESCI)) that runs under Microsoft Excel accompanies the book and may be downloaded freely from http://www.thenewstatistics.com. We now turn to the sixth edition of the Manual.
THE SIXTH EDITION OF THE APA PUBLICATION MANUAL
In Australia and North America, the Publication Manual is usually referred to as the ‘A‐P‐A’ manual, with the letters spelled out. In Spain, Italy, and a number of other southern European countries at least, we understand that it is generally called the ‘AAH‐pa’ manual. In Pakistan, it is also referred to in this way, which is notable because ‘AAH‐pa’ is the Urdu word for respected elder sister, whose advice is valued.Footnote1 The Manual is used by more than 1,000 journals across a very wide range of disciplines and is part of the lives of enormous numbers of students in many countries around the world. Its advice is highly influential.
The sixth edition of the Publication Manual (CitationAPA, 2010) includes the most far‐reaching changes to statistical guidelines since statistical advice was introduced in the first edition (CitationAPA, Council of Editors, 1952). It mentions statistics in numerous places, but of most relevance are Chapter 2, which describes all parts of a journal article; the sections in Chapter 4 that specify formats for reporting statistics; and Chapter 5, which covers figures and tables. There are two new appendices, which present the Journal Article Reporting Standards (JARS) and Meta‐Analysis Reporting Standards (MARS). These are detailed checklists of what should be included in reports of studies presenting new data (JARS) and reports of systematic reviews and meta‐analyses (MARS). CitationCooper (2011) explained the standards and how to use them. The sixth edition, like the previous editions, includes guidelines for researchers wishing to report NHST, but in the sections below, we focus on its recommendations relating to ESs, CIs, and meta‐analysis, and suggest how they can be put into practice.
ESs
An ES is simply an amount of anything of interest (CitationCumming & Fidler, 2009), and therefore means, percentages, correlations, and many other familiar quantities are ESs. A sample ES is calculated from data and typically used as our point estimate of the corresponding population ES. The Manual statesFootnote2 (p. 34) that reporting ESs is almost always necessary and explains that ESs can be reported in original units, for example, milliseconds or scale score units, or in some standardised or units‐free measure, for example, Cohen's d. ESs in original units may be more readily interpreted, but a standardised ES can assist comparison over studies and is usually necessary for meta‐analysis. Reporting both can often be useful. CitationKirk (2003) and CitationGrissom and Kim (2005) are good sources of advice on ESs.
If results are published, only if they reach statistical significance, there is bias in the published literature, and meta‐analyses are likely to overestimate ESs. That is the file‐drawer effect. The Manual acknowledges the problem and makes clear (p. 32) that ESs should be reported for all effects studied, whether large or small, statistically significant or non‐significant.
Interpretation of ESs
Interpretation is a matter of informed judgment in context. Researchers should trust their expertise and report their assessment of an ES as large or small, important or trivial, of practical value or not. Theoretical or practical significance (CitationKirk, 1996), or clinical significance (CitationKazdin, 1999), rather than statistical significance should guide ES interpretation. CitationCohen (1988) famously suggested 0.2, 0.5, and 0.8 as values of d that can be regarded as small, medium, and large, respectively. He suggested these as a ‘conventional frame of reference which is recommended for use only when no better basis . . . is available’ (p. 25). He chose his values shrewdly, but they are often not appropriate, and using them needs to be a deliberate choice. Some tiny effects may save lives or have theoretical importance; some large effects are of little interest. Whenever interpreting an ES, give reasons.
The Beck Depression Inventory is an example of a measure with published reference points that can guide interpretation. For the BDI‐II (CitationBeck, Steer, Ball, & Ranieri, 1996), scores of 0–13, 14–19, 20–28, and 29–63 are labelled, respectively, minimal, mild, moderate, and severe levels of depression. Less formally, a neuropsychology colleague tells us a rough guideline he uses is that a decrease of 15% in a client's memory score is the smallest change he regards as possibly of clinical interest. As those examples illustrate, the ES for interpretation may be either a value on a scale or a change. Increasing attention to ES interpretation may prompt the emergence of additional formal or informal conventions for interpreting various sizes of effect; that would be a good development, likely to help researchers interpret ESs in particular research contexts, and practitioners make practical sense of research reports.
CIs
The format specified (p. 117) by the Manual for reporting a CI in text is M = 457 ms, 95% CI (377, 537). If further intervals are reported in the same paragraph, the ‘95% CI’ may be omitted if the meaning is clear. The unit of measurement should be stated with the ES, but not repeated with the CI. CitationCumming and Finch (2005) is an article available from the APA website (http://tinyurl.com/inferencebyeye) that discussed CIs and their interpretation, and suggested four approaches to interpreting a CI. We summarise these here, referring to a 95% CI for µ, then describe two further approaches.
| 1 | One from an infinite sequence. The CI we calculate from our data is one from a notional infinite sequence, shown partly in Fig. 1, 95% of which include µ. The population mean µ is unknown but fixed, whereas the interval varies, as Fig. 1 illustrates. In the long run, around 95% of the CIs a researcher encounters will include the population parameter, and an unidentified 5% will miss. | ||||
| 2 | Focus on our interval. Our calculated interval defines a set of plausible or likely values for µ, and values outside the interval are relatively implausible. We can be 95% confident that our interval includes µ, and we can think of the lower limits (LL) and upper limits (UL) as likely lower and upper bounds for µ. | ||||
| 3 | Link with NHST. If a null hypothesised value µ0 lies outside the CI, then two‐tailed p < .05, and the null hypothesis can be rejected. If the CI falls, so µ0 is inside the interval, then p > .05. Fig. 1 illustrates the relationship. The closer the dot marking the sample mean is to the µ0 line, the larger is p. Simple benchmarks can help eyeball estimation of p by simply noting where the interval falls in relation to the null value (CitationCumming, 2007). CitationCoulson, Healey, Fidler, and Cumming (2010, http://tinyurl.com/cisbetter), and CitationFidler and Loftus (2009) reported evidence that CIs can prompt better interpretation if NHST is avoided, and so other approaches to CI interpretation should usually be preferred. | ||||
Figure 1 Results of 25 replications of a simulated experiment (Exp), numbered at the right. Each comprises a single sample of N = 16 scores, from a normally distributed population with mean µ = 60 and σ = 20. Means (grey dots), and 95% confidence intervals (CIs) are shown. The p‐values are two‐tailed, for a null hypothesis referring to a reference population with µ0 = 50, and σ = 20 assumed known. The population effect size is 10, or 0.5σ, a medium‐sized effect. Triple, double, and single asterisks mark p < .001, .001 < p < .01, and .01 < p < .05, respectively, and ‘?’ marks .05 < p < .10. The mean whose CI does not capture µ is shown as an open circle. The curve is the sampling distribution of the sample mean, and the central 95% of the area under the distribution is shaded.
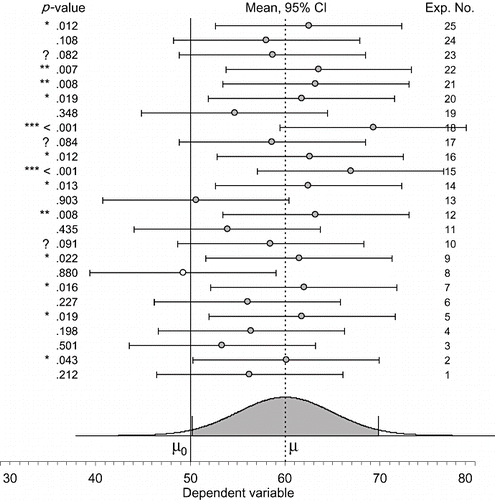
Fig. 1 shows considerable bouncing around of the CIs from successive replications, but even more dramatic variation of the p‐value. This extent of variation in p is typical of many realistic situations in psychology (CitationCumming, 2008) and is a further large disadvantage of NHST.
| 4 | Precision. The length of one arm of a CI is the MOE and our measure of precision. The estimation error is the (M – µ) difference, where M is the sample mean; it is the distance from our sample M to the unknown population mean µ. We can be 95% confident that this distance is no greater than MOE in absolute value. Large MOE indicates low precision and that an experiment may have little worth; small MOE is a prized achievement. A central goal of meta‐analysis is to combine evidence to increase precision. (Below, we discuss an additional use of precision—to assist research planning.) | ||||
| 5 | Prediction. If an experiment is repeated, where is the mean likely to fall? Fig. 1 illustrates that a replication mean—the mean of a replication experiment—is likely to fall within the original interval. For Experiments 7, 8, 12, 13, 17, and 18, the following replication mean (the next above) does not fall within the interval. In the other 18/24 cases (75%), the interval captures the next replication mean. On average, a 95% CI has an 83% chance of capturing the next replication mean (CitationCumming & Maillardet, 2006; CitationCumming, Williams, & Fidler, 2004). If the simulation underlying Fig. 1 runs for a long time, in 83% of cases, the interval will include the following mean. The fifth way to interpret a 95% CI is as an 83% prediction interval for the mean of a repeat experiment. | ||||
| 6 | The shape of an interval. The curve at the bottom of Fig. 1 shows where sample means fall in relation to µ: Most fall close, and progressively fewer fall at greater distances. The curve is also the distribution of estimation errors around µ. The most likely errors are close to zero, and larger errors become progressively less likely. In the long run, 95% of errors will lie in the shaded area. Given the usual situation of knowing M but not µ, appreciating that the most likely estimation errors are small implies our interval has probably fallen, so M is close to µ. Therefore, values close to M are our best bet for µ, and values towards either limit of our CI are successively less good bets. The curve in Fig. 1, if centred on our CI rather than on µ, indicates the relative plausibility, or relative likelihood, of values across our interval being the true value of µ. The shaded area corresponds to the extent of the interval, and the unshaded tails to values beyond it. The height of the curve is about seven times greater at the centre than at either boundary of the shaded area, which indicates that the centre of our CI is about seven times as plausible for µ as one of the limits. Considering plausibility or relative likelihood, the shaded part of the curve in Fig. 1 is the shape of a 95% CI (CitationCumming, 2007; CitationCumming & Fidler, 2009). | ||||
If SE is the standard error, the shaded area in Fig. 1 extends 1.96SE either side of µ; for 99% CIs use 2.58SE and for SE bars, 1.0SE. Fig. 2 represents these three intervals as conventional error bars, and as cat's eye figures, in which the width of the black bulge indicates relative likelihood at any point in the interval. The sixth approach to interpreting a CI is to have in mind the shape, as depicted in Fig. 2. Whatever the interpretation, however, always remember that our interval may be one of the 5% that miss µ.
Figure 2 Conventional error bar and cat's eye figures. Graphic a is the distribution of estimation errors, as in Fig. 1, and its mirror image. Its horizontal width represents the relative likelihood across the full range of values of the dependent variable. Graphics b, d, and f are conventional error bar representations of, respectively, the 99% and 95% CIs, and standard error (SE) bars. Graphics c, e, and g show as black the corresponding parts of the relative likelihood distribution, for those three intervals. The black areas picture the ‘shape’ of the intervals. The numbers at the top indicate the ratio of width at the widest point (the sample mean) and at the end of the black area.
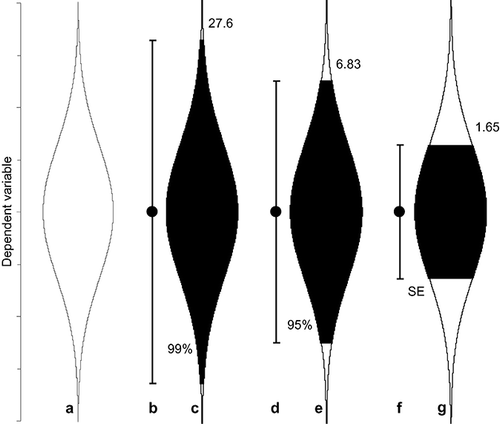
Fig. 2 illustrates how, for different levels of confidence, the twin outlines of the cat's eye figure remain the same, for a given sample of data. In stark contrast, the shapes of the shaded areas are very different for different levels of confidence. The likelihood distribution—each of those twin outlines—summarises the inferential information in the data, and a CI represents just a proportion of those curves. Therefore, if we know the 95% CI, we implicitly know also the 99% CI, the 50% CI, and the CI with any other level of confidence.
The level of confidence might be chosen to reflect the situation—for example, report 99% CIs, or even 99.9% CIs for life‐or‐death recommendations about a new drug. On the other hand, for the given data, the CI length varies greatly with the level of confidence, so it can be difficult to interpret CIs appropriately if a variety of levels of confidence is used. We recommend routinely using 95% CIs, unless there are strong reasons for some other choice in a particular situation. Interpretation 3 above notes the correspondence between 95% CIs and the traditional .05 criterion for statistical significance, but we recommend 95% not because of this correspondence but because 95% CIs are by far the most common, and consistency is likely to encourage better understanding and interpretation. As we mentioned above, we discourage the use of Interpretation 3, so we hope that the 95% CIs can thrive as the norm and eventually convey no echo of NHST and .05.
Calculation of CIs
If, as usual in practice, the population standard deviation is not known, 95% CIs are based on t rather than z and would vary in length over replications. The cat's eye figure of such intervals follow a t rather than the normal distribution, although for eyeballing purposes Fig. 2 remains adequate. CIs on other ESs, notably proportions and correlations, which have restricted ranges, are not symmetric; their cat's eye pictures are therefore also not symmetric (CitationCumming, 2012, Chapter 14). We now mention some resources intended to assist with calculating and understanding CIs on a variety of ESs. ESCI (developed by Professor Geoff Cumming, DPhil., School of Psychological Science, La Trobe University (Bundoora), Melbourne, VIC, Australia) JPP is a software freely available from http://www.latrobe.edu.au/psy/esci that accompanies CitationFinch and Cumming (2009) and supports calculation and display of CIs for a variety of common ESs, including proportions and correlations. CitationAltman, Machin, Bryant, and Gardner (2000) provided formulas and software for calculation of CIs for a number of ESs used in medicine, including odds ratios. CitationCumming and Finch (2001) and CitationCumming (2012, Chapter 11) discussed CIs on Cohen's d, and CitationCumming and Fidler (2009) evaluated a good approximate method for calculating such intervals. CitationSmithson (2003) gave guidance for finding CIs in more complex situations, including analysis of variance (ANOVA), regression, and analysis of categorical data. CitationBird (2004) discussed CIs for a range of ANOVA models.
Interpretation of CIs
The Manual states unequivocally (p. 34) that interpretation of results should, if possible, be based on ES estimates and CIs. Consider Fig. 3, which shows fictitious means of independent groups with their 95% CIs. Many psychologists may want to know which effects, or which differences, are ‘real’ and which are not. But ‘real’ in NHST terms means only that p is smaller than some benchmark, and this should not be taken as ‘true’. A 95% CI conveys all the information that data give about the population effect; if we note only whether the interval does or does not include µ0, we are neglecting much of that information.
Figure 3 Fictitious means, from independent groups, with their 95% CIs. Reference effect sizes are marked by dotted lines.
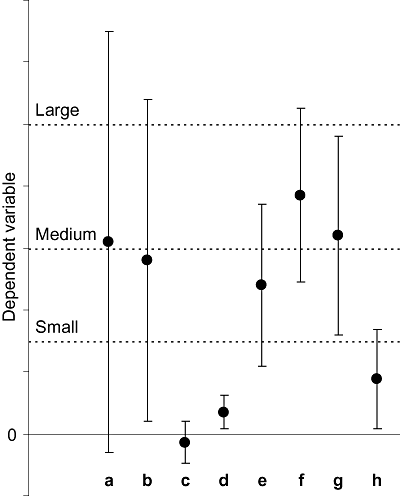
Fig. 3 shows reference ES values marked by dotted lines. Reference values could be chosen that are clinically important, predicted by different theories under test (CitationVelicer et al., 2008), or expected based on previous research. Any interpretation must depend on the research context, but the figure suggests it is irrelevant to note that b and d reach statistical significance (two‐tailed p < .05, for a null hypothesis of zero) whereas a and c do not. It is probably of little interest whether the difference between c and d just reaches statistical significance or not. The very wide a and b intervals should remove any temptation to conclude that the a and b effects are approximately equal, and tell us mainly that the next experiment needs increased precision. Conversely, the c and d intervals are so narrow that we can probably conclude that these effects are negligible. Effects e and f could be described as small to medium and medium to large, respectively. The pattern of the e, f, and g means and CIs suggests that we have no evidence of any substantial differences among those three effects. Effect h is at most small. If a comparison of f and h had been planned, the clear non‐overlap of CIs justifies a conclusion of a marked or clear difference—similarly if a comparison of any of e, f, or g had been planned with c or d. Those suggested interpretations are based mainly on seeing a CI as a range of plausible values for the true effect, but any of the other five approaches to interpreting intervals that we mentioned earlier could be used. We suggest that the first step of interpretation should be to express in words whatever aspects of a figure like Fig. 3 are most informative in the research context. Usually, that will be the main ESs, and the CI widths are considered as indicators of precision.
We briefly consider three possible objections to this approach to interpretation. First, it is too subjective. Yes, interpretation of ESs is based on judgment but so are numerous other aspects of planning, conducting, and reporting research. Reporting point and interval estimates, and the authors’ reasons for their interpretation, gives a reader full information on which to judge the research and the authors’ conclusions.
A second objection may be that wording like ‘medium to large’ and ‘at most small’ is fuzzy, hard to summarise, and gives no clear take‐home message. Yes, but if the extent of fuzziness of wording approximately matches uncertainty as indicated by CI width, our words are accurately representing the findings. Any greater specificity of wording would be misleading.
A third possible objection is that such wording is, or should be, consistent with what p‐values indicate and is thus merely NHST by stealth, and it would be better to have it out in the open. It is true that if non‐overlap of independent 95% CIs is taken as reasonably clear evidence of a difference, that is approximately equivalent to using a p < .01 criterion (CitationCumming, 2009; CitationCumming & Finch, 2005). However, considering the CIs as ranges of plausible true values gives a clear interval‐based rationale for interpreting non‐overlap of independent CIs as evidence of a difference; it keeps the focus on ESs and suggests how large the difference is likely to be.
We are under no illusion that our few wording suggestions above give sufficient guidance for interpreting ESs and CIs. We encourage psychologists to explore how best to think about and discuss point and interval estimates, towards the goal of a more quantitative discipline.
Power, precision, and planning
The Manual advises (p. 30) researchers to take statistical power seriously. That is important advice for anyone using NHST because awareness of power—often depressingly low—can prompt steps to increase power. However, statistical power only has meaning in the context of NHST. Taking an estimation approach, the corresponding concept is precision, measured by MOE, which has the advantage that no null hypothesis and no population ES need be specified. During planning, the sample size can be selected to achieve expected precision of a chosen amount (CitationCumming, 2012, Chapter 13; CitationMaxwell, Kelley, & Rausch, 2008). The Manual recognises in two places (pp. 31, 248) this use of precision for planning. The approach holds great promise, but better guidance and more accessible software tools are needed.
Tables and figures
The Manual states (p. 138) that any table reporting point estimates, whether means, correlations, or other ESs, should also include CIs if possible. There are four sample tables that include CIs (pp. 139–143). CIs can be included in tables by using either the [. . . , . . .] format, or separate columns for the LL and UL of the intervals.
The Manual notes (p. 151) that figures can include error bars to represent the precision of estimates. Unfortunately, error bars may be used to represent CIs, SEs, or other quantities (CitationCumming, Fidler, & Vaux, 2007). We recommend 95% CIs and not SE bars because it is the CI that gives inferential information (CitationCumming & Finch, 2005). Also, it is CIs that medicine has recommended since the 1980s. The Manual recognises the problem by stating (p. 160) the important requirement that any figure with error bars must be accompanied by a statement of what the error bars represent.
The sample figure with error bars (p. 156) illustrates the useful strategy of slightly displacing horizontally the means, so error bars do not overlay and can all be easily seen. If your display software does not make that easy, building the figure as an Excel scatterplot is one option.
Meta‐analysis
The MARS appendix and other discussions of meta‐analysis in the Manual (especially pp. 36–37, 183) give good guidance for reporting meta‐analyses. CitationCooper (2009) described the process of conducting a large meta‐analysis, and CitationBorenstein, Hedges, Higgins, and Rothstein (2009) discussed many aspects of the data analysis, including mention of the widely used CMA (BiostatTM, Englewood, NJ 07631,USA) software (http://www.Meta‐Analysis.com).
A forest plot is a simple CI picture that summarises a research literature. Fig. 4 is an example showing three fictitious studies and suggests that meta‐analysis combining even a few results—the minimum is two—can give a valuable increase in precision (CitationCumming, 2008, pp. 291–293). We encourage the use of a forest plot whenever it helps. Software based on the forest plot can make it easy to explain the basic ideas of meta‐analysis, even in the introductory statistics course (CitationCumming, 2006, http://tinyurl.com/teachma).
Figure 4 Forest plot showing results of three fictitious studies and their meta‐analytic combination. Cohen's d‐values and square symbols are labelled as ‘Std diff in means’ (standardised difference in means). Positive d favours the experimental condition (Exp); negative favours the comparison (Comp). Relative weights are the percentages contributed by the three studies to the overall meta‐analysis. The diamond indicates the 95% CI for the random effects combination of the effect sizes from the three studies. The CMA software (see text) was used to carry out the calculation and produce the figure.
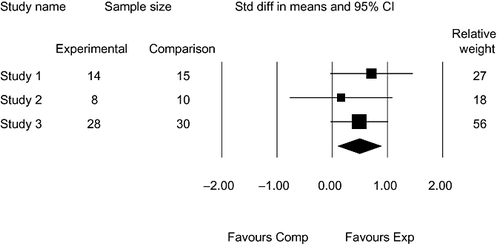
The Manual confirms meta‐analysis as part of the mainstream. A future step may be a requirement similar to The Lancet's that any report of a clinical trial make ‘direct reference to an existing systematic review and meta‐analysis. When a systematic review or meta‐analysis does not exist, authors are encouraged to do their own’ (CitationYoung & Horton, 2005, p. 107). In meta‐analysis, the statistical significance of individual results is irrelevant, and so it may be that wider use of meta‐analysis, rather than impassioned advocacy by reformers, will prompt a general swing to estimation and withering of NHST.
Complex situations
How practical is it to use estimation in complex situations? One approach to complexity is to look for simplicity within. The Manual suggests (p. 34) decomposing multiple degree‐of‐freedom effects into meaningful one degree‐of‐freedom effects. For example, planned comparisons may be more interpretable and match the research aims more closely than a main effect over multiple groups. In addition, CIs on comparisons are often easier to calculate and interpret (CitationSteiger, 2004) than CIs on multiple degree‐of‐freedom effects.
CitationFidler, Faulkner, and Cumming (2008) discussed how CIs can be used to enhance the presentation and interpretation of RCTs, which pose a challenge because they usually include both between‐groups and within‐groups factors. The major statistical software packages can in many cases calculate CIs for complex situations, even if default settings do not include them. At least one widely used multivariate text (CitationTabachnick & Fidell, 2007) now gives substantial attention to CIs. CitationKelley and Maxwell (2008) discussed CIs and the use of precision for planning in the context of multiple regression. We conclude that, while still in some cases a challenge, it is becoming less difficult to use estimation in a wide variety of situations.
CONCLUSION
CitationHammond's (1996) article was followed by two thoughtful and wide‐ranging commentaries. Both CitationGregson (1997) and CitationGrayson, Pattison, and Robins (1997) supported Hammond's argument, then took the analysis further. They considered a wide range of issues, including Bayesian approaches, model selection, conceptualisations of probability, and the central role of judgment by the researcher in a particular context.
In this article, we have mainly considered simple estimation based on populations assumed normally distributed. The discussions of Gregson and Grayson et al., however, emphasise that many statistical techniques can contribute beyond those we have considered. For example, using trimmed means and other robust statistics (CitationWilcox, 2005), and resampling methods (CitationGood, 1999) can considerably broaden the range of applicability of an estimation approach. They can often be good choices when the assumption of normality is in doubt. In addition, shifting from NHST to estimation does not sidestep the issue of possibly capitalising on chance when interpreting multiple effects (CitationCumming, 2012, Chapter 15). We believe, however, that the shift from dichotomous hypothesis testing to estimation is a fundamental and highly important shift that can improve research and theorising, whatever statistical techniques are used.
Hammond argued that the shortcomings of NHST ‘demand a fundamental change in the way we analyse the results of psychological research and the way in which we teach students to analyse data’ (CitationHammond, 1996, p. 104). Many approaches hold great promise, but perhaps the most general is the development and evaluation against data of quantitative models (CitationRodgers, 2010). The recommendations in the sixth edition of the Manual define the first major step of fundamental change, which is adoption of an estimation framework. For a start, ask ‘How large?’ questions, run experiments to give answers to those questions that are as precise as possible, then use meta‐analysis to integrate evidence and give the most detailed and accurate guidance for future research and for professional practice. Use knowledgeable judgment to interpret in the research context.
We close with the words of Roger Kirk: ‘It is time for researchers to avail themselves of the full arsenal of quantitative and qualitative statistical tools. . . . The current practice of focusing exclusively on a dichotomous reject–non‐reject decision strategy of null hypothesis testing can actually impede scientific progress. . . . The focus of research should be on . . . what data tell us about the magnitude of effects, the practical significance of effects, and the steady accumulation of knowledge’ (CitationKirk, 2003, p. 100).
Notes
Geoff Cumming was a member of the APA Publication Manual Revision Working Group for Statistics, but the views expressed in this article are the authors'. This research was supported by the Australian Research Council. We thank Neil Thomason and Eleanor Wertheim for valuable comments on drafts.
1. We thank Fatima Saleem for this information.
2. The APA does not give permission for any direct quotation from the Publication Manual, so we describe the recommendations in different words and give page numbers so they can be easily located.
REFERENCES
- Altman, D. G., Machin, D., Bryant, T. N., & Gardner, M. J. (2000). Statistics with confidence: Confidence intervals and statistical guidelines (2nd ed.). London: BMJ Books.
- American Psychological Association. (2010). Publication manual of the APA (6th ed.). Washington, DC: Author.
- American Psychological Association, Council of Editors. (1952). Publication manual of the American Psychological Association. Psychological Bulletin, 49(Suppl., Pt. 2), 389–450.
- Beck, A. T., Steer, R. A., Ball, R., & Ranieri, W. F. (1996). Comparison of Beck Depression Inventories‐IA and ‐II in psychiatric outpatients. Journal of Personality Assessment, 67, 588–597. doi:10.1207/s15327752jpa6703_13
- Bird, K. D. (2004). Analysis of variance via confidence intervals. London: Sage.
- Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta‐analysis. Chichester: Wiley.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Erlbaum.
- Cooper, H. M. (2009). Research synthesis and meta‐analysis: A step‐by‐step approach (4th ed.). Thousand Oaks, CA: Sage.
- Cooper, H. M. (2011). Reporting research in psychology: How to meet Journal Article Reporting Standards. Washington, DC: APA Books.
- Coulson, M., Healey, M., Fidler, F., & Cumming, G. (2010). Confidence intervals permit, but don't guarantee, better inference than statistical significance testing. Frontiers in Quantitative Psychology and Measurement, 1(26), 1–9. doi:10.3389/fpsyg.2010.00026
- Cumming, G. (2006). Meta‐analysis: Pictures that explain how experimental findings can be integrated. Paper presented at The 7th International Conference on Teaching Statistics (ICOTS‐7). Salvador, Brazil. In A. Rossman, & B. Chance (Eds.), ICOTS‐7 Proceedings. Retrieved from http://www.stat.auckland.ac.nz/~iase/publications/17/C105.pdf. Also available from http://tinyurl.com/teachma
- Cumming, G. (2007). Inference by eye: Pictures of confidence intervals and thinking about levels of confidence. Teaching Statistics, 29, 89–93. doi:10.1111/j.1467‐9639.2007.00267.x
- Cumming, G. (2008). Replication and p intervals: p values predict the future only vaguely, but confidence intervals do much better. Perspectives on Psychological Science, 3, 286–300. doi:10.1111/j.1745‐6924.2008.00079.x
- Cumming, G. (2009). Inference by eye: Reading the overlap of independent confidence intervals. Statistics in Medicine, 28, 205–220. doi:10.1002/sim.3471
- Cumming, G. (2012). Understanding the new statistics: Effect sizes, confidence intervals, and meta‐analysis. New York: Routledge.
- Cumming, G., & Fidler, F. (2009). Confidence intervals: Better answers to better questions. Zeitschrift für Psychologie / Journal of Psychology, 217, 15–26. doi:10.1027/0044‐3409.217.1.15
- Cumming, G., Fidler, F., Leonard, M., Kalinowski, P., Christiansen, A., Kleinig, A., . . . Wilson, S. (2007). Statistical reform in psychology: Is anything changing? Psychological Science, 18, 230–232.
- Cumming, G., Fidler, F., & Vaux, D. L. (2007). Error bars in experimental biology. Journal of Cell Biology, 177, 7–11. doi:10.1083/jcb.200611141
- Cumming, G., & Finch, S. (2001). A primer on the understanding, use and calculation of confidence intervals that are based on central and noncentral distributions. Educational and Psychological Measurement, 61, 532–574. doi:10.1177/0013164401614002
- Cumming, G., & Finch, S. (2005). Inference by eye: Confidence intervals, and how to read pictures of data. American Psychologist, 60, 170–180. doi:10.1037/0003‐066X.60.2.170. Retrieved from http://www.apastyle.org/manual/related/cumming‐and‐finch.pdf. Also available from http://tinyurl.com/inferencebyeye
- Cumming, G., & Maillardet, R. (2006). Confidence intervals and replication: Where will the next mean fall? Psychological Methods, 11, 217–227. doi:10.1037/1082‐989X.11.3.217
- Cumming, G., Williams, J., & Fidler, F. (2004). Replication, and researchers' understanding of confidence intervals and standard error bars. Understanding Statistics, 3, 299–311. doi:10.1207/s15328031us0304_5
- Faulkner, C., Fidler, F., & Cumming, G. (2008). The value of RCT evidence depends on the quality of statistical analysis. Behaviour Research and Therapy, 46, 270–281.
- Fidler, F., Faulkner, S., & Cumming, G. (2008). Analyzing and presenting outcomes: Focus on effect size estimates and confidence intervals. In A. M. Nezu, & C. M. Nezu (Eds.), Evidence‐based outcome research: A practical guide to conducting randomized controlled trials for psychosocial interventions (pp. 315–334). New York: OUP.
- Fidler, F., & Loftus, G. (2009). Why figures with error bars should replace p values: Some conceptual arguments and empirical demonstrations. Zeitschrift für Psychologie/Journal of Psychology, 217, 27–37. doi:10.1027/0044‐3409.217.1.27
- Finch, S., & Cumming, G. (2009). Putting research in context: Understanding confidence intervals from one or more studies. Journal of Pediatric Psychology, 34, 903–916. doi:10.1093/jpepsy/jsn118
- Good, P. I. (1999). Resampling methods: A practical guide to data analysis. Berlin: Birkhauser.
- Grayson, D., Pattison, P., & Robins, G. (1997). Evidence, inference, and the “rejection” of the significance test. Australian Journal of Psychology, 49, 64–70. doi:10.1080/00049539708259855
- Gregson, R. A. M. (1997). Signs of obsolescence in psychological statistics: Significance versus contemporary theory. Australian Journal of Psychology, 49, 50–63. doi:10.1080/00049539708259854
- Grissom, R. J., & Kim, J. J. (2005). Effect sizes for research: A broad practical approach. Mahwah, NJ: Erlbaum.
- Hammond, G. (1996). The objections to null hypothesis testing as a means of analysing psychological data. Australian Journal of Psychology, 48, 104–106. doi:10.1080/00049539608259513
- Kazdin, A. E. (1999). The meanings and measurement of clinical significance. Journal of Consulting and Clinical Psychology, 67, 332–339. doi:10.1037/0022‐006X.67.3.332
- Kelley, K., & Maxwell, S. E. (2008). Sample size planning with applications to multiple regression: Power and accuracy for omnibus and targeted effects. In P. Alasuutari, L. Bickman, & J. Brannen (Eds.), The Sage handbook of social research methods (pp. 166–192). London: Sage.
- Kirk, R. E. (1996). Practical significance: A concept whose time has come. Educational and Psychological Measurement, 56, 746–759. doi:10.1177/0013164496056005002
- Kirk, R. E. (2003). The importance of effect magnitude. In S. F. Davis (Ed.), Handbook of research methods in experimental psychology (pp. 83–105). Malden, MA: Blackwell.
- Kline, R. B. (2004). Beyond significance testing. Reforming data analysis methods in behavioral research. Washington, DC: APA Books. Chapter 3. Retrieved from http://www.apastyle.org/manual/related/kline‐2004.pdf Also available from http://tinyurl.com/klinechap3
- La greca, A. M. (2005). Editorial. Journal of Consulting and Clinical Psychology, 73, 3–5.
- Maxwell, S. E., Kelley, K., & Rausch, J. R. (2008). Sample‐size planning for statistical power and accuracy in parameter estimation. Annual Review of Psychology, 59, 537–563. doi:10.1146/annurev.psych.59.103006.093735
- Rao, S. (2008). Editorial. Neuropsychology, 22, 1–2.
- Rodgers, J. L. (2010). The epistemology of mathematical and statistical modeling: A quiet methodological revolution. American Psychologist, 65, 1–12. doi: 10.1037/a0018326
- Smithson, M. (2003). Confidence intervals. Thousand Oaks, CA: Sage.
- Steiger, J. H. (2004). Beyond the F test: Effect size confidence intervals and tests of close fit in the analysis of variance and contrast analysis. Psychological Methods, 9, 164–182.
- Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics (5th ed.). Boston, MA: Pearson.
- Velicer, W. F., Cumming, G., Fava, J. L., Rossi, J. S., Prochaska, J. O., & Johnson, J. (2008). Theory testing using quantitative predictions of effect size. Applied Psychology: An International Review, 57, 589–608. doi:10.1111/j.1464‐0597.2008.00348.x
- Wilcox, R. R. (2005). Introduction to robust estimation and hypothesis testing (2nd ed.). San Diego, CA: Academic Press.
- Wilkinson, L., & Task Force on Statistical Inference. (1999). Statistical methods in psychology journals: Guidelines and explanations. American Psychologist, 54, 594–604. doi:10.1037/0003‐066X.54.8.594. Retrieved from http://www.apastyle.org/manual/related/wilkinson‐1999.pdf. Also available from http://tinyurl.com/tfsi1999
- Young, C., & Horton, R. (2005). Putting clinical trials into context. The Lancet, 366, 107–108. doi:10.1016/S0140‐6736(05)66846‐8