 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Mainstream theories of the Stroop effect suggest that faster colour classification on congruent trials (say, the word RED printed in red colour) relative to incongruent trials (GREEN in red) is due to channel interaction. Namely, information from the irrelevant word channel perturbs processing of the print colour, causing in turn slower processing of incongruent displays. In this note, I advance a new model in which colour and word are processed in parallel and completely independent channels. The Stroop effect is then the outcome of signal redundancy in congruent displays, where both colour and word contribute to the same response. Numerical computations show that the model can produce the Stroop effect (along with high accuracy rates) for a subset of parameter values. Thus, it provides a proof of existence for a separate channel theory, and a challenge to many existing theories.
The Stroop effect (CitationStroop, 1935) is the prime example of the human failure to attend selectively to an individual aspect of a stimulus. When naming the colour in which colour words are printed, people seem unable to ignore the meaning of the carrier word. They engage the meaning of the word even when such processes are irrelevant to the task at hand and can hurt performance. To gauge the influence of the irrelevant words, the Stroop effect is defined as the difference in colour‐naming performance between congruent (the word naming its colour) and incongruent (word and colour conflict) stimuli. For instance, when presented with the word GREEN printed in red, observers are slower in responding ‘red’ than they are when presented with the word RED printed in red.
Mainstream theories of the Stroop effect posit that the detriment to performance on incongruent trials and facilitation on congruent trials is due to the automatic activation of word meaning (e.g., CitationAnderson, 1995; CitationAshcraft, 1994; and more recently, CitationCatena, Fuentes, & Tudela, 2002, but see CitationBesner, Stoltz, & Boutilier, 1997 for a different view). Consequently, channel interaction is indispensable for the Stroop effect to ensue. The term ‘Stroop interference’ (or Stroop facilitation, cf. CitationMacLeod, 1991) reflects this deep‐seated notion.
The central role of word colour cross‐talk in existing theories can be exemplified by examining CitationCohen, Dunbar, and McClelland's prominent connectionist Stroop model (1990), which allows ‘interactions between processes. . . when pathways intersect’. (p. 335). These interactions can result in either interference when patterns of activation are dissimilar, or facilitation when ‘patterns of activation are very similar’. Cohen et al.'s three‐layer network accrues evidence forward along word and colour pathways, and the total activation received by the output units (e.g., ‘red’, ‘green’) determines which will cross its threshold first and determine the response. Because activation from colour and word pathways is pooled together, decisions based on colour activation cannot happen independently from activation on the word pathway, and vice versa.
In this note, I entertain a new, indeed revolutionary, idea. I wish to show that a stochastic model that does not entail a cross‐talk between the channels for word and colour can, nonetheless, produce the behavioural Stroop effect (i.e., faster colour performance on congruent than on incongruent trials). In a nutshell, faster responses on congruent trials as opposed to incongruent trials may be a special case of the well‐known redundant‐target effect: Responses to a congruent Stroop stimulus (say, RED in red) are faster simply because it comprises a double‐ or redundant‐target display, whereas the incongruent stimulus (say, GREEN in red) is a single‐target display. The critical point is that the redundant‐target effect may ensue in a strictly parallel and independent system, where the different sources of information (namely, word and colour) need not interact. The proposed model is not that simple, yet this gives the gist of the idea.1 Notice that a somewhat similar idea was considered by CitationMacLeod and MacDonald (1998), and supported empirically by CitationEidels, Townsend et al. (2010). Neither, however, developed a complete formal model. If successful, such a model invites a wholesale revision of existing theories of the Stroop effect.
STROOP AS A REDUNDANT‐TARGETS EFFECT
How can the Stroop effect emerge under a strictly parallel‐independent regime? Consider the congruent stimulus (say, RED printed in red). Both of its presented attributes lead to the same response, ‘red’. Hence, this stimulus is also a double‐target stimulus. Such a trial is a race between separate processes (each generating a detection decision with respect to its individual target), with the response determined by whichever channel finishes processing first. The incongruent stimulus, in contrast, is a single‐target stimulus because the target is presented in one channel (RED), but a non‐target is presented in the other channel (GREEN). A race develops on this trial, too, with the former channel generating the correct response. Therefore, congruent and incongruent stimuli differ in the number of presented targets. A congruent Stroop stimulus is practically a display containing two targets. An incongruent Stroop stimulus, in contrast, is a display containing a single target (along with a single distractor).
An immense literature on target search (e.g., CitationBen‐David & Algom, 2009; CitationEgeth & Dagenbach, 1991; CitationFeintuch & Cohen, 2002; CitationGrice, Canham, & Boroughs, 1984; CitationMiller, 1982; CitationMordkoff & Yantis, 1991; CitationTownsend & Eidels, 2011; CitationTownsend & Nozawa, 1995) shows that performance is faster with displays containing redundant targets than with displays containing a single target. Notably, this redundant‐target effect is present even when processing is strictly parallel as it is in the present model, by way of statistical facilitation (CitationRaab, 1962). According to this notion, responses on redundant‐target trials, within the purview of a race model, are especially fast because they are produced by the faster of two stochastic processes. The generally faster process determines the response on the majority of redundant‐target trials; the other process does so on the remaining trials on which it is uncharacteristically fast. Therefore, on average, response time (RT) on redundant‐target trials will be shorter than on single‐target trials.
We immediately see that the Stroop effect is equivalent to the redundant‐target effect. One can say that the Stroop effect is a special case of the redundant‐target effect where the pertinent displays are colour words printed in various colours. If so, the Stroop effect can derive without any form of interaction between colour and word (e.g., automatic dominance of reading over naming, semantic interference and facilitation, or response competition at the response buffer). Word and colour do not communicate with one another or share a decision mechanism. The colour horse does not ‘know’ the content, indeed the very existence of the word horse.
THE MODEL
Consider the standard Stroop task of naming the colour of colour words in a simple 2 (word: RED, GREEN) × 2 (colour: red, green) matrix. The word RED printed in red and the word GREEN printed in green both comprise congruent stimuli. RED in green and GREEN in red comprise incongruent stimuli. A Stroop effect ensues if, for example, participants are faster to name the colour ‘red’ when presented with the congruent stimulus RED in red than they are with the incongruent stimulus GREEN in red.
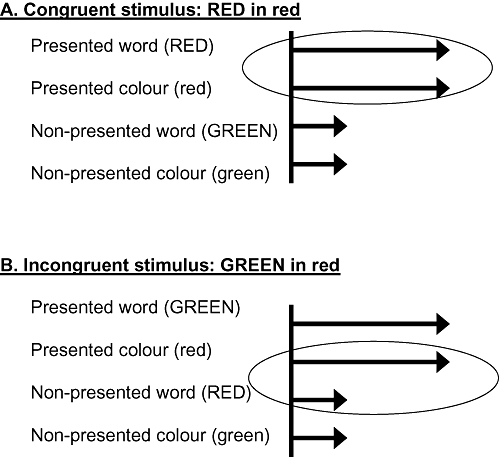
The Stroop process is formalised as a counter model (CitationTownsend & Ashby, 1983), with four parallel and independent counters. A prototypical schemata for a four‐channel parallel model is shown in Fig. 1. All of the words and colours included in the stimulus ensemble are activated on each trial. Given the aforementioned 2 × 2 matrix of colour words and colours, the four channels for RED, GREEN, red, and green are activated on each trial of the experiment regardless of the single combination presented for view on any particular trial. In a different situation, for example given a Stroop matrix of 6 colours and 10 words, 16 channels are activated on each and every trial. This is a stochastic modelling instantiation of a well‐known result from information theory. Perception depends not only on the stimulus presented for view but also on its alternatives, those stimuli that could have been presented although were not presented on that particular trial (CitationGarner, 1974; CitationMelara & Algom, 2003).
Figure 1 Illustration of activations in a separate channels model with four parallel and independent channels. Each panel shows activation on four channels for a particular Stroop stimulus. Longer arrows represent higher processing rates for presented over non‐presented attributes. The circled channels contribute to the correct response. When presented with the word RED written in the congruent colour red (Rr; panel A), activation rates for the presented attributes (word RED, colour red) are higher than the respective rates for the non‐presented attributes (GREEN, green). Notably, these potent channels contribute to the correct response (‘red’). When presented with the incongruent combination of the word GREEN written in red (Gr; panel B), the presented colour red and the non‐presented word RED contribute to a correct ‘red’ response. The total ‘red’ activation on a congruent trial (from channels RED, red—panel A) is higher than the total ‘red’ activation on an incongruent trial (channels RED, red—panel B).
With four processing channels, each working as a counter that accumulates evidence towards some criterion at a given rate, there are eight parameters in the model. There are four rate parameters, one for each of the channels (presented word, presented colour, non‐presented word, non‐presented colour), and there are four corresponding criterion values. By criterion, or threshold, I refer to the critical amount of evidence that is necessary in order for a particular channel to win the race and initiate response. The rate of each channel corresponds to the speed by which it accumulates evidence. Thus, a high rate in a particular channel, say the presented colour red, implies that in a fixed unit of time, this channel gathers a lot of evidence in favour of responding ‘red’. Concomitantly, a high rate implies that a particular channel needs little time to collect enough evidence to exceed its criterion. Channels with high rates and/or low criterion values are more likely to win the race, and consequently determine the response.
I present the model by first introducing the notation for rates and criteria. Let VA, VB, VC, and VD be the processing rates for the channels of the presented word, presented colour, non‐presented word, and non‐presented colour, respectively. Let kA, kB, kC, and kD be the corresponding criterion values for each of the channels. For processing rates, it is sensible to assume that the rates for presented features are faster than the rates for non‐presented features, MIN(VA, VB) > MAX(VC, VD). For example, when stimulus GREEN in red is presented, the GREEN and red counters will accumulate evidence at a faster rate than will the RED and green counters. Perceived stimuli (i.e., the attributes presented for view on a particular trial) are processed more efficiently than those merely remembered from previous trials, although, again, all channels are activated on each and every trial. This assumption is captured by the length of the arrows in the visual illustration of the model, presented in Fig. 1. Note, though, that when fitting the model to data, I relaxed this assumption and let the rates vary freely. To foreshadow the outcome, it was reassuring to find out that this rates‐order assumption was maintained in the fitting results.
Next, I derive the conditional processing‐time density functions for congruent and incongruent trials (i.e., completion time conditioned on correct responding). With these expressions at hand, I can fit the new model to empirical Stroop data (from CitationEidels, Townsend et al., 2010; Experiment 4), or simulate it for a range of parameter values (see Appendix).
Let f(t) = P(T = t) be the probability density function (PDF) of processing time, T, that represents the likelihood of a process to finish at time t. Let F(t) = P(T ≤ t) be the cumulative distribution function of processing time that tells the probability of a process to finish at or before time t. Finally, let us define the survivor function S(t) = P(RT>t) = 1‐F(t) as the probability that the process is finished later than time t. Now, assume that there are two parallel and independent processing channels, A and B, that race against each other to determine the response, and that the overall processing in the system terminates as soon as the faster of the two channels finishes (minimum‐time stopping rule). CitationTownsend and Ashby (1983) showed that for a two‐channel independent parallel model with a minimum‐time stopping rule, the survivor function for the faster of the two channels (i.e., the winner of the race) is the product of the survivor functions of each channel alone, such that
1
1
Observe that neither A nor B alone always win. Because processing is stochastic, on some cases A wins, and on others B wins. The overall processing of the system only lasts as long as both processes are unfinished. Once the winner terminates, processing in the system ceases and a response is initiated. If we take the derivative (d/dt) from both sides of Equation (1), we obtain the (unconditional) probability distribution for the winner of the race, which, by product rule, turns to be
2
2
It is termed unconditional density as it gives the probability of the faster of the two channels (A, B) to finish at time t, regardless of whether the response was correct or not. In other words, this is the probability distribution of the winner of the race that is not conditioned on the response being correct. For example, consider a letter identification experiment where either A or B can be presented as stimuli, and ‘A’ or ‘B’ are the corresponding responses. Suppose that the letter A is presented on the screen. Then, if performance is better than chance, on most trials, channel A wins and determines the response. On some trials, however, channel B wins and leads to an incorrect response, ‘B’. The unconditional density gives the RT distribution of the winner of the race, regardless of whether it was A or B, and thus it includes responses from both correct and incorrect trials. Similarly, with four channels rather than two, the survivor function and the (unconditional) probability distribution of the winner are as follows, respectively:
3
3
4
4
Now, we are ready to move on from the general case, where A, B, C, and D can be any four channels, to our Stroop situation where colours and colour words are the subject of processing. Let A be the processing channel of the presented word (with rate VA and criterion kA). Similarly, let B, C, and D be the processing channels of the presented colour, non‐presented word, and non‐presented colour, with rates VB, VC, and VD (and criteria kB, kC, and kD), respectively. Consider first the congruent condition, say the word RED printed in red (Rr). A correct response (‘red’) ensues if and only if the word RED (with rate VA) or the colour red (with rate VB) wins the race. To obtain the conditional PDF for either RED or red winning (‘conditional’ as it is conditioned on the response being correct), we take only the first two terms from Equation (4), where the first term corresponds to the probability that channel A (processing the word RED) satisfies the prescribed criterion, but channels B, C, and D do not, and similarly the second term corresponds to B (colour red) but not A, C, and D reaching criterion. We then divide by the overall probability of a correct response, that is, the probability that either RED or red wins, which is given by integrating the numerator from zero to infinity.
The PDF of a correct response ‘red’ on a congruent trial Rr in which either RED or red wins the race is, thus, given by
5
5
In a similar fashion, we can obtain the PDF of a correct response on an incongruent trial, Gr. For Gr, the presented attributes are the word GREEN and the colour red. Because the task remains that of colour naming, the correct response is still ‘red’. As in the congruent case, a correct response (‘red’) ensues if and only if the word RED or the colour red (with rate VB) wins the race. Unlike the congruent case, however, the word RED is not presented for view, hence it is processed at a slower rate, VC. To obtain the conditional density for either RED or red winning, I now take the second and the third terms from Equation (4), and divide by their integrals from zero to infinity.
The PDF for a correct response ‘red’ on an incongruent trial Gr in which either RED (with rate VC) or red (with rate VB) wins the race is
6
6
Using the PDF for the congruent and incongruent RTs in Equations (5) and (6), respectively, one can simulate the model or fit it to data, as I report next. Before moving on to the results, the reader may have noticed at this point two interesting properties of the model: First, it explains Stroop effect as the difference between RTs for incongruent versus congruent displays. Thus, it has no separate mechanism for ‘interference’ (slowdown on incongruent trials compared with neutral trials) and ‘facilitation’ (faster responses on congruent trials compared with neutral trials). I shall address this point in the final section of the article. Second, the model is ‘error‐driven’, meaning that it requires errors in order to manifest a Stroop effect. Namely, for a Stroop effect to ensue in the current regime, the (irrelevant) presented‐word channel has to occasionally win. On congruent trials, this will lead to faster responses via the redundant‐target effect, but on incongruent trials, such as GREEN in red, if the GREEN channel wins, then the outcome is an erroneous ‘green’ response. Thus, an important prediction of the model is that human performance in the Stroop task is imperfect. A related prediction then follows: The presented‐word channel winning results in incorrect responses on incongruent trials but correct responses on congruent trials. Therefore, the model predicts a higher error rate on incongruent compared with congruent trials. Finally, the most important prediction of the model was iterated before, here and in many other articles: RTs on congruent trials are predicted to be faster than incongruent trials (the Stroop effect).
In the next section, I test the above predictions by examining the Stroop data collected by CitationEidels, Townsend et al. (2010). I consider RTs, error rates, and their relationships. I then report results of fitting these data to the generic form of the new model (Equations 5 and 6).
RESULTS
CitationEidels, Townsend et al. (2010, Experiment 4) presented 22 participants with a standard Stroop task, where they had to classify the print colour of the colour words RED and GREEN by pressing one key if the colour was red and another key if the colour was green. Conveniently, this stimulus ensemble perfectly matches the 2 colours × 2 words stimulus set‐up presented earlier in the Model section (and in Fig. 1), making these data readily available for fitting.
Response‐time Stroop effect
One participant (#18) had an error rate of 31% and was excluded from the analysis. presents individual data for each of the remaining 21 participants as well as their average. For the data pooled over the participants, there was a large Stroop effect of 32.9-ms (t(20) = 6.1, p < .001). Positive Stroop effects were observed for virtually all participants except for Participant 4.
Table 1 Mean RT (ms) and error rate from CitationEidels, Townsend et al. (2010), Experiment 4
Error rates
The Stroop effect for error amounted to 1.2% (t(20) = 2.4, p < . 05). In line with the model's prediction, more errors were observed in the incongruent condition compared with the congruent condition. This pattern holds at the individual level for most participants (only four out of 21 observers exhibited higher error rate on congruent trials). Evidently, the majority of the participants exhibited some amount of errors, as predicted by the model.
Stroop effect and error rates
Because Stroop effect in the model is driven by errors, the model qualitatively suggests that RT and error measures will be positively correlated. As the proposed model is offered as a challenge to existing theories rather than as a comprehensive new theory, there is no space for an exhaustive meta‐analysis of Stroop and error rates. Nevertheless, examining the RT–error relationship in the limited dataset I have surveyed so far can be proven useful. Indeed, there was a small (although non‐significant) positive linear correlation between the magnitude of the Stroop effects and error rates (both averaged across conditions), rPearson = .201, p = .19. When converted to a rank order scale, to account for the non‐linear relationship between RT and accuracy (e.g., CitationLuce, 1986), this correlation was stronger and close to significant, rSpearman = .303, p < .1.
Model fitting
To fit CitationEidels, Townsend et al. (2010) Stroop data, I used the likelihood functions of the new model, given in Equations (5) and (6). Notice that the likelihoods (the expression in the numerator) are specified in general terms, as f(t) and S(t). Therefore, for the actual fitting, one can substitute f(t) and S(t) with comparable functions from practically any parametric process model that accounts for accumulation of evidence within independent channels. I have chosen to use the Linear Ballistic Accumulator (LBA, CitationBrown & Heathcote, 2008) for two main reasons: first, because of its analytical tractability, which makes it simple to use and relatively easy to fit; second, because unlike several other successful choice RT models (e.g., the Leaky Competing Accumulator, CitationUsher & McClelland, 2001), accumulation of evidence within each channel is completely independent of whatever happens in other channels. This, of course, is the trademark property of the model I developed here, and must be satisfied when fitting the data. A brief description of the LBA and fitting procedure follows, succeeded by fitting results.
The LBA assumes that evidence about a decision (say, whether to press the ‘red’ key) is accumulated, at some rate, until it exceeds a prescribed threshold. On each trial, the initial level of evidence in an accumulator is drawn from a uniform distribution with a zero minimum and a maximum determined by the parameter A. The accumulator's rate is drawn from a normal distribution with mean v and standard deviation s. Evidence in the accumulator increases linearly, at a speed given by the drift rate, until it reaches a response threshold determined by parameter b. RT is the time taken for the evidence to reach threshold plus non‐decision time, or base time, which we model as a constant, t0. The latter component represents the time consumed by early sensory processes, as well as by response preparation and execution. Overall then, the behaviour of each accumulator is controlled by five parameters. CitationBrown and Heathcote (2008) derived closed‐form solutions for the cumulative density, F(t), and density, f(t), of the time taken for a single accumulator to reach threshold. By plugging these expressions into Equations (5) and (6) (recalling that S(t) = 1‐F(t)), one can obtain the necessary likelihood functions for congruent and incongruent RTs in the Stroop task.
To model the Stroop task used by CitationEidels, Townsend et al. (2010), the LBA instantiation should have four channels (presented word, presented colour, non‐presented word, and non‐presented colour), with five parameters each. To simplify the fitting, I have employed a couple of conventions used by CitationEidels, Donkin et al. (2010). First, I treated the s parameter as a scaling factor and fixed it at s = 1. Second, I assumed that the A and t0 parameter values are identical across the four accumulators. Thus, I ended up with ten free parameters: A, t0, four mean rate parameters (one for each channel: VA, VB, VC, and VD), and four criteria (kA, kB, kC, and kD).2
shows the best‐fitting parameter values for CitationEidels, Townsend et al. (2010) data, using maximum likelihood estimation. The values in the top row were estimated by pooling the data from all 21 participants into a single set, and treating the set as if it came from a single participant. This is essential because, for some participants, error rate was low, with only few error data points to rely on. I then used the best‐fitting parameter values from this ‘super‐set’ as starting values for the parameter‐space search when fitting individual data. The bottom row of shows the individual best‐fitting parameter values averaged across 16 participants. Participants 3, 5, 7, 8, and 10 had a 0% error rate in either one of the conditions (congruent, incongruent), or both, and had to be excluded from the analysis, as the model cannot accommodate error‐free performance.3
Table 2 Best‐fitting parameter values for CitationEidels, Townsend et al.'s (2010) Experiment 4 Stroop data. The rate parameter, for each channel, represents the mean of a normal distribution from which rates are sampled on each trial. The criterion parameter represents the distance between the to‐be‐reached threshold and the end of the start point distribution, A. The base time parameter, t0, represents a proportion of the fastest response in a dataset. If the fastest measured RT was about 200-ms (depending on the participant), then base time is estimated as 0.84 × 200-ms = 168-ms
At first inspection, some of parameter values in may look alarming, so a clarification is needed. First, the V parameter represents the mean of a normal distribution from which rates are drawn on each trial. Thus, negative values do not mean that the actual accumulation rate is negative. Nevertheless, on many trials, the actual rate in certain channels may have been negative. That is not a problem as long as at least one of the channels accumulates evidence at a positive rate, which is almost always the case. Notice that this channel will often be the presented‐colour channel, which leads to a correct response, in compliance with the task's instructions. Second, the zero values for the k parameter are also not a problem. This parameter represents the distance between the to‐be‐reached threshold and the end of the start point distribution, A. Since the start point values are drawn from a uniform distribution ranging from zero to A, there is only a miniscule chance that the actual distance will be zero. In fact, the expected value of the start point is A/2, so the average distance given k = 0 should be A‐A/2 = A/2.
Importantly, for interpreting the fitting results, all rate and criterion parameters, as well as A and t0, were allowed to vary freely. Thus, instead of imposing any constraints or assumptions, I let the data tell the story. A close examination of reveals interesting patterns: first, parameter estimates from the pooled data, and those estimated for individual participants and then averaged, are in close qualitative agreement; second, the rate for the presented‐colour channel was higher than any of the other rates. This is sensible in a Stroop task, where participants are asked to report the presented print colour. The presented word rate was also larger than (or equal to) the rates of the non‐presented channels. This is also sensible in this model as this channel has to win on some trials to contribute to a Stroop effect. Thus, although channel rates were free parameters, higher rate values were estimated for presented channels compared with non‐presented channels, in complete agreement with the assumption entertained in the Model section.
The relative magnitudes of the criterion values provide a more intricate picture. The criterion value for the presented‐colour channel was higher than any of the other channels. It is possible that through the complex dynamics of the LBA model, rates and criterion values trade off in a way that is difficult to predict. In this case, the fact that the rate for presented colour was much higher than any other rate might mitigate the high criterion value estimated for this channel. Finally, while fitting the model to data generally resulted in sensible parameter values, parameters became distorted when trying to capture data patterns they cannot really manage (namely, 0% errors). Thus, the model can accommodate data from most but not all participants.4
The theoretical weight of the present outcomes invited replication and generalisation. To reinforce the conclusions, I have simulated (numerically computed, to be exact) the general model presented in Equations (5) and (6) using alternate expressions for f(t) and S(t). Instead of plugging in the f(t) and S(t) expressions of the LBA model, I assumed that completion times in each of the channels are gamma distributed. The latter is a convenient test case (see, e.g., CitationTownsend & Ashby, 1983) as it has two parameters akin to rate and criterion. Using f(t) and S(t) of a gamma distribution, I have tested a wide range of rate and criterion values, and found that a considerable subset of the parameter combinations that satisfy the rate assumption led to a positive Stroop effect (96,229 out of the 200,880 parameter combinations). Full details are provided in the Appendix.
CONCLUSIONS
I proposed and tested a new model for the Stroop effect, in which colour and word are processed in parallel and completely independent channels. Model fitting to empirical data and subsequent simulations show that the model can produce the Stroop effect (along with high accuracy rates), at least for a subset of parameter values. Thus, it provides a proof of existence for a separate channel theory, and a challenge to many existing theories.
The theoretical implications are nothing less than startling. Given the present results, the Stroop effect cannot be exclusively viewed as the inevitable outcome of word–colour conflict. In many occasions, it may simply be an instance of the redundant‐target effect by which the congruent (i.e., double‐target) stimulus enjoys the benefit of target redundancy over the incongruent (single‐target) stimulus. Faster responses for the former merely reflect the activation gained from processing channels of two presented attributes as opposed to processing just one.
One must be circumspect, though, before drawing too strong conclusions. Although a substantial part of the parameter combinations that were used in the simulations produced the behavioural Stroop effect, a smaller subset produced the high accuracy rates observed often in experimental data (see Appendix). Note also that I did not demonstrate that other more traditional models of the Stroop effect are incorrect; I have merely shown that, under realistic conditions, the effect can emerge based on completely independent processing of the colour and the word.
In its present form, the independent‐channels model concerns the Stroop effect, namely the difference in performance between incongruent and congruent stimuli. However, a third class of stimuli is often presented in Stroop experiments, non‐colour words in colour. Considering performance with these neutral stimuli, the Stroop effect is conveniently divided into interference (the difference in performance between incongruent and neutral stimuli) and facilitation (the complementary difference in performance between neutral and congruent stimuli). Again, the present development concerns the Stroop effect—as do the majority of existing Stroop theories (cf. CitationBrown, 2011; CitationMacLeod, 1991; CitationMelara & Algom, 2003)—and not the components of interference and facilitation. The reason is that (1) it is not clear which stimulus qualifies as a neutral one (CitationMacLeod, 1991), that (2) a vast variability is observed with different types of neutral or control stimuli (CitationBrown, 2011), and that (3) it is not prima facie clear that such stimuli belong in the Stroop realm in the first place (CitationEidels, Townsend et al., 2010).
Nevertheless, how does the present model account for the often‐found difference in performance between the neutral and the incongruent conditions favouring the former (but see CitationAlgom, Dekel, & Pansky, 1996; CitationMelara & Algom, 2003; or CitationMelara & Mounts, 1993 for the lack of interference or a reverse pattern)? In the present model, strain on capacity with incongruent stimuli is the root cause for the longer RTs observed (in comparison with neutral stimuli). With an incongruent stimulus, the observer must process (at least) four pieces of information (the presented and non‐presented colours, as well as the presented and non‐presented words), whereas she or he processes merely two pieces of information (presented and non‐presented colour) with neutral stimuli. As Townsend and colleagues have proven (CitationTownsend & Ashby, 1983; CitationTownsend & Eidels, 2011; CitationTownsend & Wenger, 2004), the presence of multiple signals can facilitate performance (the redundant‐target effect) but can impair performance especially as the number of signals increases. The limitation on capacity is expressed as longer RTs with incongruent stimuli (cf. CitationBen‐David & Algom, 2009).
A comprehensive Stroop theory should explain further pertinent phenomena, such as the reduction in the Stroop effect when word and colour are spatially separated (CitationWuhr & Frings, 2008), Stroop dilution (CitationKahneman & Chajczyk, 1983), or practice effects (CitationMelara & Mounts, 1993). The current model is offered as a challenge to the central claim of many existing Stroop theories—that word must interact with colour processing—and provides a proof of existence for a completely independent model of processing. The model should be augmented in various ways in future development (for example, by adding a memory‐decay function, it may account for practice and other sequential effects) as long as the basic architecture remains that of parallel independent channels.
In conclusion, I showed that a parallel race model with four independent channels can generate the Stroop effect. The model leads to the surprising result that what appears as ‘interference’ or ‘facilitation’ at the behavioural level may actually be sustained by completely separate processes at the underlying microscopic level. Because I do not postulate a processing conflict to stand for an apparent behavioural conflict, the theory is favoured by applying Occam's razor. The theory serves as a yardstick against which theories assuming actual interaction in processing must be measured and compete.
APPENDIX: NUMERICAL COMPUTATIONS OF THE STROOP EFFECT
To reinforce the results reported in the main text using the LBA model, I have simulated the same general model (Equations 5 and 6) using f(t) and S(t) expressions of a gamma distribution. This distribution is convenient to use in RT modelling in general and here in particular, as it has two parameters akin to rate and criterion.
In order to estimate numerically the Stroop effect that the model can generate, one first needs to compute the probability distribution functions and survivor functions in each channel, and insert them then into Equations (5) and (6). From there, it is trivial to estimate the expected value of processing time on congruent and incongruent trials, and calculate their difference—the Stroop effect. The probability distribution functions and survivor functions of a gamma distribution for channel A (presented word) are given, respectively, by
7
7
8
8
where VA is the scale parameter (corresponding to the processing rate of channel A), and kA is the shape parameter (corresponding to the criterion value of that channel). We can similarly compute probability distribution functions and survivor functions for the other channels by using their corresponding rates and criteria.
I numerically computed the Stroop effect, using gamma distributions, for a range of values that satisfied the assumption concerning the relative magnitude of the rate parameters. I allowed the rates for the presented‐word channel, VA, and for the presented‐colour channel, VB, to take any value between 1 and 11 (due to memory constraints, I used steps of 2, i.e., 1, 3, 5 . . . 11). I allowed the rates for the non‐presented word and colour channels, VC and VD, to take any value between 1 and 11 (in steps of 2) as long as they were smaller than MIN (VA, VB). So the possible values for rate across the four channels were 11 ≥ VA, VB > VC, VD. The values of criterion were assigned, in steps of 2, such that 12 ≥ kA, kB, kC, kD ≥ 2.5
On a considerable number of cases (96,299 out of 200,880 parameter combinations), the expected processing time of a congruent stimulus was faster than that of an incongruent stimulus, thus manifesting a positive Stroop effect.
What is truly revealing about these results is the fact that the Stroop effects are obtained in the environment of a strictly parallel, independent model. One can say that within the parallel independent race of colour and word, the colour horse knows neither the position nor indeed the very existence of the word horse (and vice versa). Given the absence of cross‐talk, word and colour cannot interact. In these cases, the terms ‘Stroop interference’ or ‘Stroop conflict’ are not interpretative of any underlying process.
I note, though, that only a subset of the tested parameter combinations led to a positive Stroop. When one imposes the additional constraint of high accuracy (say, P(correct) > .9 on both congruent and incongruent trials), this number further decreases (to 3,635 combinations). Nevertheless, the present outcome comprises a proof of existence for the possibility of a Stroop effect in the absence of channel cross‐talk for a variety of reasonable set parameters.
ACKNOWLEDGEMENTS
I am grateful to Daniel Algom for his thoughtful suggestions. I also thank Jonathon Love (who was supported by ARC DP‐110100234A to Heathcote, A. A., Marley, R. D., & Morey, J. N.) for his invaluable assistance.
Notes
1. To be accurate, with the current realisation of four channels, the incongruent stimulus GREEN in red also possesses two sources of information for a correct ‘red’ response: the presented colour and the non‐presented word. However, as the processing rate of non‐presented attributes is slower than that of presented attributes (see the rates assumption in the Model section below), the non‐presented word RED does not contribute to the correct response as much as the presented RED would when a congruent combination, RED in red, is displayed. Therefore, the example in the text serves as a good approximation to illustrate the difference in the processing of congruent and incongruent stimuli, until we provide a full description of the model in the upcoming section. Of course, the model itself makes use of all four channels, and no approximations are made.
2. Parameter k is analogous to the distance from the start point to the criterion, which is denoted b‐a in the LBA framework. To be consistent with the more general notation used earlier in the Model section, I use k instead of b‐a.
3. For participants 5 and 10, the model compensated for the lack of errors by assigning kC values (criterion for the non‐presented word channel) that were four and seven orders of magnitude larger than other participants’ values. For participants 3, 7, and 8, there were smaller irregularities but in more than one parameter.
4. How do we know if the model can accommodate the data? What are sensible parameter values? Because I do not compare several models, measures such as deviance or Bayesian information criterion are not very helpful. A useful strategy is to plug the best‐fitting parameter values back in the model, simulate it, and test whether the model can reproduce the important qualitative patterns that were observed in the empirical data. Using the pooled data parameter values from , the model successfully recovered a positive Stroop effect in mean RT (albeit smaller than observed empirically) and in error rate, accompanied with high yet imperfect accuracy (2.6% errors).
5. I did not use criterion values of 1 as the gamma probability distribution is then reduced to an exponential form, which does not permit an important distinction between a co‐active and an independent race model (see CitationEidels, Townsend et al., 2010, for details).
REFERENCES
- Algom, D., Dekel, A., & Pansky, A. (1996). The perception of number from the separability of the stimulus: The Stroop effect revisited. Memory & Cognition, 14, 557–572.
- Anderson, J. (1995). Cognitive psychology and its implications. New York: W. H. Freeman.
- Ashcraft, M. H. (1994). Human memory and cognition. New York, NY: Harper Collins.
- Ben‐david, B. M., & Algom, D. (2009). Species of redundancy in visual target detection. Journal of Experimental Psychology: Human Perception and Performance, 35, 958–976.
- Besner, D., Stoltz, J. A., & Boutilier, C. (1997). The Stroop effect and the myth of automaticity. Psychonomic Bulletin & Review, 4, 221–225.
- Brown, S. D., & Heathcote, A. (2008). The simplest complete model of choice reaction time: Linear ballistic accumulation. Cognitive Psychology, 57, 153–178.
- Brown, T. L. (2011). The relationship between Stroop interference and facilitation effects: Statistical artifacts, baselines, and a reassessment. Journal of Experimental Psychology: Human Perception and Performance, 37, 85–99.
- Catena, A., Fuentes, L. J., & Tudela, P. (2002). Priming and interference effects can be dissociated in the Stroop task: New evidence in favor of the automaticity of word recognition. Psychonomic Bulletin & Review, 9, 113–118.
- Cohen, J. D., Dunbar, K., & Mcclelland, J. L. (1990). On the control of automatic processes: A parallel‐distributed processing account of the Stroop effect. Psychological Review, 97, 332–361.
- Egeth, H. E., & Dagenbach, D. (1991). Parallel versus serial processing in visual search: Further evidence from subadditive effects of visual quality. Journal of Experimental Psychology: Human Perception and Performance, 17, 550–559.
- Eidels, A., Donkin, C., Brown, S. D., & Heathcote, A. (2010). Converging measures of workload capacity. Psychonomic Bulletin & Review, 17, 763–771.
- Eidels, A., Townsend, J. T., & Algom, D. (2010). Comparing perception of Stroop stimuli in focused versus divided attention paradigms: Evidence for dramatic processing differences. Cognition, 114, 129–150.
- Feintuch, U., & Cohen, A. (2002). Visual attention and coactivation of response decisions for features from different dimensions. Psychological Science, 13, 361–369.
- Garner, W. R. (1974). The processing of information and structure. Potomac, MD: Erlbum.
- Grice, G. R., Canham, L., & Boroughs, J. M. (1984). Combination rule for redundant target information in reaction time tasks with divided attention. Perception & Psychophysics, 35, 451–463.
- Kahneman, D., & Chajczyk, D. (1983). Tests of the automaticity of reading: Dilution of Stroop effects by colour‐irrelevant stimuli. Journal of Experimental Psychology: Human Perception and Performance, 9, 497–509.
- Luce, R. D. (1986). Response times: Their role in inferring elementary mental organization. New York: Oxford University Press.
- Macleod, C. M. (1991). Half a century research on the Stroop effect: An integrative review. Psychological Bulletin, 109, 163–203.
- Macleod, C. M., & Macdonald, P. A. (1998). Facilitation in the Stroop task is illusory: The inadvertent learning hypothesis (Unpublished manuscript). University of Toronto.
- Melara, R. D., & Algom, D. (2003). Driven by information: A tectonic theory of Stroop effects. Psychological Review, 110, 422–471.
- Melara, R. D., & Mounts, J. R. W. (1993). Selective attention to Stroop dimensions: Effects of baseline discriminability, response mode, and practice. Memory & Cognition, 21, 627–645.
- Miller, J. (1982). Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology, 14, 247–279.
- Mordkoff, J. T., & Yantis, S. (1991). An interactive race model of divided attention. Journal of Experimental Psychology: Human Perception and Performance, 17, 520–538.
- Raab, D. H. (1962). Statistical facilitation of simple reaction times. Transactions of the New York Academy of Sciences, 24, 574–590.
- Stroop, J. R. (1935). Studies of interference in serial verbal reaction. Journal of Experimental Psychology, 18, 643–662.
- Townsend, J. T., & Ashby, F. G. (1983). The stochastic modeling of elementary psychological processes. Cambridge: Cambridge University Press.
- Townsend, J. T., & Eidels, A. (2011). Workload capacity spaces: A unified methodology for response times. Psychonomic Bulletin & Review, in press.
- Townsend, J. T., & Nozawa, G. (1995). Spatio‐temporal properties of elementary perception: An investigation of parallel, serial, and coactive theories. Journal of Mathematical Psychology, 39, 321–359.
- Townsend, J. T., & Wenger, M. J. (2004). A theory of interactive parallel processing: New capacity measures and predictions for a response time inequality series. Psychological Review, 111, 1003–1035.
- Usher, M., & Mcclelland, J. L. (2001). On the time course of perceptual choice: The leaky competing accumulator model. Psychological Review, 108, 550–592.
- Wuhr, P., & Frings, C. (2008). A case for inhibition: Visual attention suppresses the processing of irrelevant objects. Journal of Experimental Psychology: General, 137, 116–130.