 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Objective
The aim of this study was to review statistical techniques for estimating the mean population cost using health care cost data that, because of the inability to achieve complete follow-up until death, are right censored. The target audience is health service researchers without an advanced statistical background.
Methods
Data were sourced from longitudinal heart failure costs from Ontario, Canada, and administrative databases were used for estimating costs. The dataset consisted of 43,888 patients, with follow-up periods ranging from 1 to 1538 days (mean 576 days). The study was designed so that mean health care costs over 1080 days of follow-up were calculated using naïve estimators such as full-sample and uncensored case estimators. Reweighted estimators – specifically, the inverse probability weighted estimator – were calculated, as was phase-based costing. Costs were adjusted to 2008 Canadian dollars using the Bank of Canada consumer price index (http://www.bankofcanada.ca/en/cpi.html).
Results
Over the restricted follow-up of 1080 days, 32% of patients were censored. The full-sample estimator was found to underestimate mean cost ($30,420) compared with the reweighted estimators ($36,490). The phase-based costing estimate of $37,237 was similar to that of the simple reweighted estimator.
Conclusion
The authors recommend against the use of full-sample or uncensored case estimators when censored data are present. In the presence of heavy censoring, phase-based costing is an attractive alternative approach.
Introduction
Accurate estimates of health care costs have a wide range of applications and are of growing importance to both policy makers and clinicians, given the burgeoning costs of health care delivery, budgetary constraints, and the aging population. Therefore, it is important for health services researchers to be familiar with robust methods for description, inference, and prediction using costing data.
A number of statistical properties of costing data preclude the use of traditional statistical tools.Citation1,Citation2 There is a rich econometric and statistical literature focused predominantly on three specific properties of cost data: first, a substantial proportion of the general population may be healthy, requiring little medical care and having zero costs; second, the distribution of health care costs for those who do incur costs is usually heavily right skewed, with a few very high-cost individuals on the tail; third, investigators have shown that the assumption of homoscedasticity (ie, constant variance in the error term) is often violated and thereby alternative modeling techniques are required.Citation2–Citation6
A fourth obstacle is incomplete data when health care expenses are not available for all participants for the entire period of interest. Although this area is one of active research, much of this work has been presented in health economics or statistical journals.Citation3,Citation7–Citation13 The objective of the present review is to examine this fourth obstacle in detail, targeting an audience of health services researchers without an advanced statistical background. The authors will focus on the basic operation of estimating mean health care costs, using both simulations and a case study to illustrate these concepts. In the process, the goal is to provide some of the necessary background to make this important area of study more accessible.
The case study was of patients with heart failure (HF) in Ontario, Canada.Citation14 Briefly, all patients with an admission for HF, based on International Classification of Disease Version 10 Code I50, during the period 2004–2006 were identified in the Canadian Institute for Health Information’s Discharge Abstract Database. Costs for hospital admission, same-day surgeries, physician services, ambulatory care, and HF medications were estimated in 30-day intervals until March 31, 2008.Citation14 Throughout the text, the example of cumulative 3-year costs, approximated as 1080 days based on the 30-day costing interval, will be used. Costs were adjusted to 2008 Canadian dollars using the Bank of Canada consumer price index (http://www.bankofcanada.ca/en/cpi.html). The dataset consisted of 43,888 patients, with follow-up periods ranging from 1 day to 1538 days (mean 576 days). Mean age was 76 years (range 25–106 years), with 51% females and 72% with an ischemic cardiomyopathy.
Cumulative cost functions
For a longitudinal health care costing study, the costing value of greatest interest is the mean health cost (also known as incidence-based costs), defined as the cumulative cost from the index event over some interval. The incidence-based costs must be contrasted with prevalence-based costs, where the costs for the entire population are assessed in a cross-sectional fashion and are then divided by the number of members. Incidence-based cumulative cost functions for an individual can be complex, as illustrated in . The rate of cost accumulation tends to increase around index events such as hospitalizations and death, as shown by the dashed line and the varying slope of the solid curve in . Moreover, the pattern of cost accumulation may be different between any two individuals. One could theoretically follow all participants until death; however, death will rarely be observed for every participant because of short study horizons. Indeed, the portion of health care cost that is unobserved in this setting may be especially important, because health care costs tend to rise dramatically in the period prior to death.Citation2,Citation15–Citation17 To avoid this issue, a study may instead focus on the mean total costs for a restricted time period (eg, 1080-day total health care costs).Citation18 This creates two major issues.
Figure 1 (A) Cumulative costs and flow of costs in complete case; (B) cumulative costs in censored case.
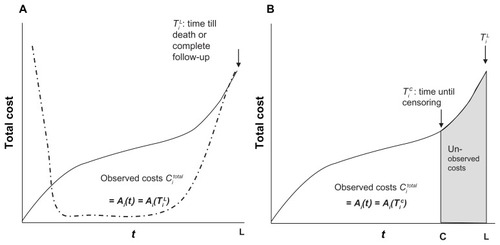
First, among the participants who die, death drives up costs in the period before death as seen in . Conversely, cumulative costs may in fact be driven down because no costs are accrued after death. The accepted method of dealing with this is to consider death as a terminal event.Citation7,Citation9,Citation11,Citation12,Citation18 Subjects will accrue costs until they die, or until they reach the time horizon of the analysis. A complete case is defined as one in which death occurs, or where follow-up is complete until the end of the restricted time period. In each of these situations, participants are no longer accumulating relevant costs.
The second issue is how to deal with the individuals who are not complete cases. A portion of the relevant health costs for these participants will be unobserved, as illustrated by the shaded area in .Citation18 Such data are said to be right censored, defined as an observation that ends prematurely, before the outcome of interest has occurred (death or 1080 days, in the present example).Citation18 Right censoring of health care costs can arise from a number of mechanisms. Patients may be lost to follow-up at varying times; alternatively, a study may enroll patients over a period of time but discontinue follow-up on a fixed calendar date. In both of these cases, the censoring occurs completely at random, and the observed health care costs represent the lower limit of the relevant costs. One way of adjusting cumulative cost estimates for censoring is to develop a function that describes the way in which data are censored and to use that function to reweight the observed cost data. Kaplan-Meier techniques are a well-established method to achieve such reweighting.
Kaplan-Meier estimates for survival and censoring
First, the traditional Kaplan-Meier estimator for survival will be reviewed, and then an analogous estimator for censoring will be introduced.Citation12 Please see for explanation of the nomenclature in this section. A traditional Kaplan-Meier estimator, S(t) is the probability of surviving beyond a time, t. In this method, patients who are censored are no longer at risk for death and are therefore excluded. The probability of survival for any interval is equal to the proportion surviving among those still at risk of death at the beginning of the interval (ie, uncensored cases). The Kaplan-Meier estimator at time t is calculated by multiplying the probabilities of surviving each time interval preceding point t – hence, it is also referred to as the product-limit estimator.
Table 1 Nomenclature
The Kaplan-Meier estimate for censoring, Sc(t), is defined as the probability for being uncensored beyond time t.Citation12 Here, the role of death and censoring are reversed relative to a conventional survival analysis. Censoring is the outcome of interest, and death simply means that the patient is excluded from further observations. The risk of being uncensored in a particular interval is calculated for those who are “at risk” of being censored at the beginning of the interval. These are the patients who have not been removed or excluded – that is, those who have not died or been censored. Again, Sc(t) for time t is the product of all probabilities of being uncensored across intervals prior to time t.
To illustrate these concepts, four hypothetical patients are presented in , followed over 6 months. Patients A and B are followed for all 6 months, while patient C dies in month 3 and patient D is censored in month 4. The components for both the Kaplan-Meier estimates for survival, S(t), and the Kaplan-Meier estimates for censoring conditional on being alive, Sc(t), are shown on the right of the . When calculating the Kaplan-Meier estimate for survival, it is necessary to determine the probability of death and of survival for each month. These are shown with the number of patients at risk at the beginning of the month in the denominator. Importantly, patients who are censored are removed from the denominator. For example, in the third month, four patients are at risk for death at the beginning of the month, with three alive at the end of the month (probability of survival is 3/4 = 0.75). In month 5, only two are at risk for death at the beginning of the interval, because one patient was censored in the previous month (probability of survival is 2/2 = 1). S(t) is the product across the months of the probability of survival: S(4) = 1*1*0.75*1 = 0.75.
Table 2 Hypothetical patient cohort to illustrate Kaplan-Meier techniques
The corresponding calculations for Sc(t) are shown on the far right side of . Here, the denominator for each interval contains only patients at risk for censoring at the beginning of the interval; patients who died in the preceding interval are removed. For example, at the beginning of the fourth month, only three patients continue to be at risk for censoring. In the end of the fourth month, one patient was censored, so the probability of being uncensored is 2/3 = 0.67. The Kaplan-Meier estimate Sc(t) is the product across intervals of the probability of remaining uncensored: Sc(4) = 1*1*1*0.67 = 0.67.
In , the Kaplan-Meier survival curve is constructed from the HF study over a follow-up period of 1080 days, with the probability of survival, S(t), at the end of follow-up being 43%. It is evident that the probability of dying – the complement of S(t) – increases with larger values of t, after accounting for censoring.
Figure 2 (A) Kaplan-Meier survival curve (B) Kaplan-Meier curve for censoring
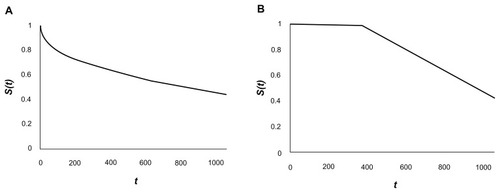
Over the full follow-up period of 1080 days, 14,107 patients of the original 43,888 patients were censored and therefore were no longer available for observation. In , the corresponding Kaplan-Meier curve is constructed, with the probability of being uncensored, Sc(t), decreasing at greater values of t. It is important to note that at greater values of time t, the probability of censoring increases – the complement of Sc(t).
Restricted time period total costs
First, the issues related to censoring in a restricted time period will be tackled. In order to understand the techniques, some nomenclature is necessary (see ). Let N be the total sample size of the study, including both censored and uncensored cases. For each participant, i, there is an observed accumulated medical cost, denoted by Citotal. Each individual has an observation time, denoted by ti. For complete cases who are observed until death or until the end of the restricted time period, ti is equal to the time to death/restricted time limit, denoted by Ti L. For a censored case, ti is equal to the time to censoring, denoted by Ti C. Finally, an indicator variable is defined for each participant, Δi, which will take the value of 0 for censored cases and of 1 for complete cases. Citotal for each participant will be expressed as a function Ai:
Each of these terms is illustrated in . shows the cumulative costs over time for a complete case, defined as a participant who is observed until Ti L. is a censored patient, observed only until the censoring time, Ti C. As illustrated by the shaded area, a censored patient will continue to accumulate relevant costs (ie, until Ti L) and these will be unobserved.
Full-sample and uncensored case estimators
Two potential estimators for mean restricted time total costs (Ci total) in the face of censored data are the full-sample and uncensored case estimators.Citation1,Citation9,Citation13 In the full-sample estimator, the accumulated cost for each participant is averaged, irrespective of whether the patient died, was observed for the full follow-up period, or was censored.Citation1,Citation13 As censored patients will continue to accumulate relevant costs while unobserved (shaded portion in ), the full-sample estimator would include only a portion of their relevant costs, and therefore it will always be an underestimate.Citation1
In the uncensored case estimator, only the values from complete cases are used.Citation13 As illustrated in , the probability of remaining uncensored, Sc(t), is not uniform at all values of t. Instead, as t increases, the probability of being uncensored, Sc(t), decreases. Therefore, the uncensored case estimator would be biased toward the costs of participants who died early – those who had smaller values of ti.Citation1,Citation13
Reweighted estimators
One approach to estimate mean health care costs when censoring is present is to reweight each complete case so that each complete case represents not only itself but also some number of incomplete/censored cases. In this setting, the cumulative cost of each participant who died or reached the full period of observation must represent not only the cost of that participant but also the censored cases that would have been observed had there been no censoring. The number of censored cases that must be represented by a complete case at observation time t is proportional to the probability of that case being censored.Citation18,Citation19 It follows that costs for complete cases with a short follow-up should be weighted less than cases with a longer observation period, accounting for the higher probability of censoring with longer observation periods.
Different reweighted estimators have been developed.Citation1,Citation9,Citation13,Citation18,Citation20,Citation21 These are conceptually similar and are equivalent under certain conditions.Citation12,Citation21 The Lin 1997 estimator was the first to be described and is based on dividing observation time into a number of equal intervals.Citation9 Lin et alCitation9 described two alternative methods: one if cost histories are available, and a second if only total cumulative costs are available for all individuals. In the latter, more basic scenario, the mean cost for each interval is calculated, based only on the costs of patients who die during the interval. The cumulative cost for the entire period of observation is the sum of the mean costs for each interval, weighted by the Kaplan-Meier probability of surviving to the beginning of each interval.Citation9 A limitation of the Lin 1997 estimator is the assumption of discrete censoring times that coincide with the beginning of the costing intervals.Citation22 Bang and TsiatisCitation7 described an inverse probability weighted (IPW) estimator that did not require interval costs and which accommodated continuous censoring times. As an illustration, the IPW method of Bang and TsiatisCitation7 will be worked through in detail here. Interested readers are encouraged to refer to the source documentation for a full description of the other estimators, and for recommendations as to their appropriate use.Citation1,Citation9,Citation12,Citation13,Citation18,Citation20,Citation21
In the IPW estimator, sample weighting is done using the Kaplan-Meier estimate for censoring, Sc(ti).Citation1,Citation21 Each uncensored participant (Δi value of 1) with TiL of observation time has Sc(Ti L) probability of being uncensored, as seen in . Each uncensored observation represents on average 1/Sc(Ti L) patients who are censored (Δi value of 0).Citation12 Because uncensored observations are weighted by the inverse of Sc(ti), it is apparent that patients who die early in the study (smaller values of ti), and who therefore have smaller values of Ti L, are weighted less than those who die at longer follow-up times or who are followed up until the restricted time limit. The mean IPW total cost is estimated as:
Several key points from this merit discussion. Costs from all individuals are included, as N is the full sample. However, the costs of the censored participants are multiplied by the indicator variable of “0,” with only the costs of complete participants reweighted accordingly. An important limitation for this estimator is inefficiency, because only data from uncensored/complete cases inform the final value.Citation13 Using simulation, Raikou and McGuireCitation13 found that in the presence of very heavy censoring (>50%), the simple IPW estimator becomes unstable.
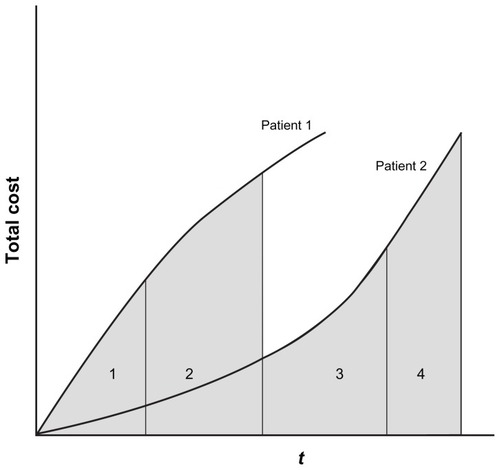
An alternative “partitioned estimator” is possible when cumulative cost histories are available for each participant. This is shown in , where costs are available for subintervals of the full period of observation.Citation12 Censored patients are likely to have full costs for some of the subintervals. For example, in , patient 2 is a complete case over the entire restricted time period (shaded area), and therefore patient 2 has complete costs for all four sub-intervals; patient 1 is censored in subinterval 3 but has full costs for subinterval 1 and 2 (shaded area). Because a censored patient is likely to have complete costs for some intervals, it is possible to make use of these data to further inform the estimator of mean cost.
Figure 3 Partitioned cost histories: the full period of observation is subdivided into four partitions. Patient 1 is censored in partition 3, while patient 2 is a complete case.
Bang and colleaguesCitation7,Citation21 developed a partitioned extension of their IPW estimator, in which the total time period is divided into K partitions or subintervals. For each subinterval, denoted as j, a participant will either be censored or have full observation, defined as dying within the subinterval or observation for the full subinterval. Thus, one can define variables Δi j, Ti C, Ti L, ti j specific to each subinterval j of interest. Mi j designates the total cost for each subinterval j. Mi j is calculated as the difference between cumulative cost up to the end of the subinterval j and the cumulative cost in the preceding subinterval. This is given by the formula:
For illustration, in , the cost for patient 1 for subinterval 2 is the difference between the entire shaded area – the first term in equation 4: Ai j(ti j) – and the shaded area to the left of the line separating the first and second interval – the second term in equation 4: Ai (j−1)(ti(j−1)). By summing the cost estimate for each subinterval, the mean total cost can be determined. The mean partitioned IPW estimator for total restricted time costs will then be:
Investigators have shown that the Lin 1997 method and the IPW estimator are equivalent when the intervals for the Lin 1997 method become infinitesimally small (ie, approach continuous censoring time).Citation12 In order to extend beyond estimation of the mean and make formal inferences, both the Lin 1997 and Bang-Tsiatis methods allow for the calculation of variances. These calculations are necessarily complex – readers are encouraged to review the source documentation on this area and are strongly encouraged to involve a statistician. Moreover, using the simple IPW or the partitioned IPW as response variables, these methods can be expanded within a regression framework to control for covariates.Citation10,Citation11,Citation18 However, the IPW techniques have a number of limitations, especially when evaluating covariate effects, as the effects on cost accumulation cannot be distinguished from the effects on survival.Citation22 Moreover, these techniques do not account for the differential rates of heath care cost accumulation near death, as seen in . Alternative models have been developed to deal with these issues.Citation22
Simulations
The authors used a similar simulation method to Basu and ManningCitation22 to generate a cohort of 1000 patients, evaluated over a maximum of ten equally spaced intervals. Patients who died or who completed observation until the end of the ten periods were considered to be complete observations. Survival and censoring times were generated from an exponential distribution and a uniform distribution, respectively.Citation22 As per previous investigators, the present authors generated a cumulative cost profile for individuals, such that there was an increased initial cost reflecting diagnosis and an increased terminal cost in the event of death.
The authors used combinations of censoring and survival times to create datasets with increasing degrees of censoring. Using 500 simulations per dataset, the authors then compared a full-sample, uncensored, and simple IPW estimator with the true mean costs. These results are shown in .
Table 3 Simulations to evaluate impact of censoring
As expected, with increasing censoring, the full-sample estimator underestimated the true costs. The simple IPW estimator performed well with mild to moderate degrees of censoring in the simulated datasets; however, with heavy censoring (53%) it substantially overestimated true costs. This is consistent with reports with other investigators as to its instability in the presence of high censoring.
HF case study
Using data from the 43,888 patients in the HF case study, the authors calculated estimators for the mean 1080-day total cost. Cost histories were available for 180-day partitions. Statistical models were created using R software (v 2.9.0; R Foundation for Statistical Computing, Vienna, Austria) and are available upon request. Of the 43,888 patients, 32.1% were censored over the 1080-day restricted time period, with 50.9% of patients dying and 17% having complete follow-up to 1080 days. In , the full-sample estimator, uncensored case estimator, simple IPW estimator, and the partitioned 180-day estimator are shown. In addition, the authors estimated costs using the Lin 1997 method based on total accumulated costs. Two versions of the Lin 1997 method, using 180- and 30-day intervals, were utilized to highlight issues that may arise from the choice of time-interval.
Table 4 Mean 1080-day costs using different estimating methods
As anticipated, the full-sample estimator was the lowest, at $30,420 for the 3-year (1080-day) period, which is a biased underestimate. A total of 14,107 patients were censored within the restricted time period and had costs that would have otherwise accrued in the absence of censoring (ie, the shaded portion in ). The uncensored estimate is higher, at $33,940, and disproportionately biased patients with short survival times, who in this dataset have higher costs. The simple IPW cost of $36,490 only makes use of the 67.2% of data not censored. With the partitioned IPW estimator, which makes use of data from all the subjects, the estimate for mean 1080-day cumulative cost was $33,230. In contrast, the Lin 1997 method, based on intervals of 180 days, provides a substantially lower mean estimate of $20,059, while the Lin 1997 estimate using a 30-day interval of $37,042 closely approximated the simple IPW estimate. This highlights the differences between the Lin 1997 methods and the IPW estimator when longer time intervals are used.
Lifetime costs
Although using a restricted time period allows one to circumvent the issue of extrapolating lifetime costs and is often used in practice, a restricted time period cost has important limitations. Citation18 For example, two patients may have the same lifetime cumulative costs but because of differences in survival times (ie, one patient dies at 3 years and the other dies at 5 years), may have substantially different time-restricted costs at 3 years.Citation18 When studying interventions with significant influences on mortality, having the same distribution of lifetime costs in the control and study groups is not synonymous with having the same distribution of time-restricted costs, because the survival distributions in the groups may be different.
Given the critical relationship between survival time and health care costs, it is tempting to use Kaplan-Meier techniques, substituting time to death with cost to death as the dependent variable. However, investigators have found that this results in biased estimates.Citation3,Citation8,Citation18,Citation23 A fundamental requirement for a Kaplan-Meier survival curve is independent censoring.Citation3,Citation8,Citation18,Citation23 For survival time, this requires that the time to censoring is independent of the time to death. In most cases this is true; however, in the parallel form for costs, the cumulative cost to censoring for a particular participant will not be independent from the cumulative costs to death because both are related to the participant’s unique pattern of cost accumulation ().Citation3,Citation8,Citation18,Citation23 This is most obvious in the situation of a constant rate of cost accumulation, R, where the cumulative cost at censoring time, Ti C, is simply the product of R*Ti C, while that at time of death, Ti L, is R*Ti L. Both values are clearly not independent but are related to each other by R.Citation3,Citation8,Citation18,Citation23
Phase-based costing
An alternative method for estimating cumulative costs is using is a phase-based modeling approach.Citation14,Citation24–Citation26 This is particularly attractive for estimating lifetime costs or cost in the presence of heavy censoring. The steps for the phase-based approach are as follows:Citation14,Citation24–Citation26
Define a priori clinically important phases of disease. Examples are the phase immediately after diagnosis, associated with higher costs; a stable phase, with constant and low costs; and the phase prior to death, which again has high costs.
Determine inflection points in cumulative cost, which define the duration of each phase. This will be disease specific.
Allocate observation time and costs for each patient to the phases.
Once the costs for all patients have been assigned, determine the mean cost per phase (or per subdivision of each phase).
Using both the data on cost per phase and time to death, determine the cumulative lifetime costs.
Each of these steps will now be worked through in the HF example. First, based on content experts, the authors expected that HF would be characterized by at least three phases: (1) a post-discharge phase after index hospitalization, (2) a pre-death phase, and (3) a relatively stable phase (Step 1). To confirm this hypothesis, the authors evaluated the cost per 30 days for patient subgroups that survived 9–12, 21–24, and 33–36 months post discharge (). The mean 30-day cost curves confirmed the hypothesis of discrete cost phases with inflection points separating the post-discharge and stable phases, and the stable and pre-death phases estimated at 3 months post discharge and 6 months prior to death, respectively (Step 2).
Figure A1 Exploratory analysis on phases of long-term costa associated with heart failure care.
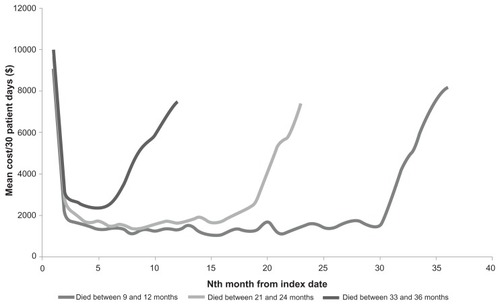
The cumulative cost history for each individual over the 1080-day period of the study was partitioned and sequentially allocated to phases (Step 3). For example, for each patient the cumulative costs for the first 3 months of observation were assigned to the post-diagnosis phase, the costs associated with the 6 months prior to death were assigned to the predeath phase, and the remainder were assigned to the stable phase. Once the entire cohort was analyzed in this manner, a mean cost was calculated for each of the phases (Step 4). In the present study, the mean costs were determined for each 30-day block within each phase (). Other investigators have used a simpler approach in which a single mean cost is determined per phase.Citation27 It is important to note that costs should be adjusted to the current year in order to account for health care inflation, using a multiplier such as the consumer price index.
Table A1 Phase-based costing example using heart failure cohort
To calculate cumulative costs, one utilizes both the mean costs per phase and a survival function that spans the time horizon of the study (lifetime or shorter) (Step 5). Although the survival and cost data are from the same cohort in the earlier techniques, this need not be the case in the phase-based approach.Citation28 In the present study, the authors used a survival curve from a separate HF cohort that had been followed for 12 years, over which period 99% of patients died.
First, the survival curve is divided into intervals. In the present example the authors used 30-day time intervals. For any time interval on the survival curve, the proportion of the original cohort in each phase is determined. This proportion is multiplied by the mean cost for that particular phase. In , for example, at the 120- to 150-day time interval on the survival curve, 68.4% of the original HF cohort were in the stable phase – the cost for this phase was 0.684*$617 = $422. None of the patients were in the postdischarge phase, and 10.5% were in the pre-death phase (for a cost of $614). Thus, the cost for t = 120- to 150-day interval is $422 + $614 = $1036. The costs for all time intervals are calculated in this manner and are summed to produce the mean cost for the entire time horizon.
Figure 4 Merging phase-based costs on the survival curve. For the time interval 120–150 days, 68.4% of the original cohort was in the stable phase, with 10.5% in the pre-death phase. To determine the cost for the time interval of 120–150 days, the proportion of patients in each phase is multiplied by the mean cost per phase, as shown in .
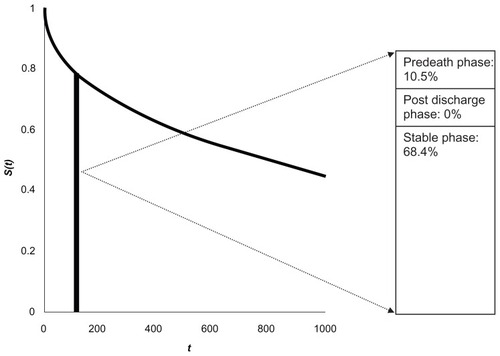
The authors found that over a mean life expectancy of 3.87 years, HF patients had a mean lifetime cost of $61,870.Citation14 To provide a comparison with the methods already mentioned, the authors also calculated the mean cost at 1080 days, using a phase-based approach. The phase-based estimate of $37,237 was similar to that from the other methods – specifically, the simple IPW and the Lin 1997 methods.
Data comparing such phase-based estimates with those from IPW methods are sparse, but with investigators to date finding that they are comparable.Citation26 The benefits of the phase-based approach are that actual costs for the cohort over the entire period of interest (ie, lifetime) do not need to be observed, thereby overcoming the major limitation of the previous methods.Citation14,Citation24–Citation26 Using these methods, investigators have been able to produce widely used estimates of the lifetime costs of cancer.Citation26,Citation29 However, greater understanding of when one technique is favored over another is important and should be a focus for further methodological study.
Conclusion and recommendations
This review has provided an overview for the uninitiated reader who wishes to tackle the literature on health care costing with data that are incomplete because of incomplete follow-up. The authors offer the following recommendations:
Censoring will have substantial methodological impact on a study, and investigators must evaluate their data to determine if any cases are right censored.
If censoring is present, the use of either a full-sample estimator or an uncensored case estimator in the estimation of mean cost is potentially inaccurate.
The choice of estimator when censoring is present is not clear-cut. Options include a weighted estimator (preferably a partitioned estimator, to make use of all the data efficiently) or a phase-based approach.
Given the importance of health care costing for comparative effectiveness research and in the shaping of future health policy, the authors believe that further work on developing accurate yet transparent techniques should be a priority; the authors’ hope is that this review serves as a stimulus for such work.
Disclosure
The authors report no conflicts of interest in this work.
References
- BangHMedical cost analysis: application to colorectal cancer data from the SEER Medicare databaseContemp Clin Trials200526558659716084777
- DiehrPYanezDAshAHornbrookMLinDYMethods for analyzing health care utilization and costsAnnu Rev Public Health19992012514410352853
- AustinPCGhaliWATuJVA comparison of several regression models for analysing cost of CABG surgeryStat Med20032217279981512939787
- BarberJThompsonSMultiple regression of cost data: use of generalised linear modelsJ Health Serv Res Policy20049419720415509405
- BloughDKRamseySDUsing generalized linear models to assess medical care costsHealth Serv Outcomes Res Methodol200012185202
- MihaylovaBBriggsAO’HaganAThompsonSGReview of statistical methods for analysing healthcare resources and costsHealth Econ201120889791620799344
- BangHTsiatisAAEstimating medical costs with censored dataBiometrika2000872329343
- EtzioniRDFeuerEJSullivanSDLinDHuCRamseySDOn the use of survival analysis techniques to estimate medical care costsJ Health Econ199918336538010537900
- LinDYFeuerEJEtzioniRWaxYEstimating medical costs from incomplete follow-up dataBiometrics19975324194349192444
- LinDYLinear regression analysis of censored medical costsBiostatistics200011354712933524
- LinDYRegression analysis of incomplete medical cost dataStat Med20032271181120012652561
- O’HaganAStevensJWOn estimators of medical costs with censored dataJ Health Econ200423361562515120473
- RaikouMMcGuireAEstimating medical care costs under conditions of censoringJ Health Econ200423344347015120465
- WijeysunderaHCMachadoMWangXCost-effectiveness of specialized multidisciplinary heart failure clinics in Ontario, CanadaValue Health201013891592121091970
- ScitovskyAACapronAMMedical care at the end of life: the interaction of economics and ethicsAnnu Rev Public Health1986759753087376
- ScitovskyAA“The high cost of dying” revisitedMilbank Q19947245615917997219
- ScitovskyAA“The high cost of dying”: what do the data show? 1984Milbank Q200583482584116279969
- HuangYCost analysis with censored dataMed Care2009477 Suppl 1S115S11919536024
- EtzioniRRileyGFRamseySDBrownMMeasuring costs: administrative claims data, clinical trials, and beyondMed Care200240Suppl 6III63III7212064760
- ZhaoHTianLOn estimating medical cost and incremental cost-effectiveness ratios with censored dataBiometrics20015741002100811764238
- ZhaoHBangHWangHPfeiferPEOn the equivalence of some medical cost estimators with censored dataStat Med200726244520453017380543
- BasuAManningWGEstimating lifetime or episode-of-illness costs under censoringHealth Econ20101991010102820665908
- LipscombJAncukiewiczMParmigianiGHasselbladVSamsaGMatcharDBPredicting the cost of illness: a comparison of alternative models applied to strokeMed Decis Making199818Suppl 2S39S569566466
- BrownMLRileyGFPotoskyALEtzioniRDObtaining long-term disease specific costs of care: application to Medicare enrollees diagnosed with colorectal cancerMed Care199937121249125910599606
- BrownMLRileyGFSchusslerNEtzioniREstimating health care costs related to cancer treatment from SEER-Medicare dataMed Care200240Suppl 8IV104IV117
- YabroffKRWarrenJLSchragDMComparison of approaches for estimating incidence costs of care for colorectal cancer patientsMed Care2009477 Suppl 1S56S6319536010
- KrahnMDZagorskiBLaporteAHealthcare costs associated with prostate cancer: estimates from a population-based studyBJU Int2010105333834619594734
- EtzioniRUrbanNBakerMEstimating the costs attributable to a disease with application to ovarian cancerJ Clin Epidemiol1996491951038598518
- YabroffKRWarrenJLKnopfKDavisWWBrownMLEstimating patient time costs associated with colorectal cancer careMed Care200543764064815970778