
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Background
A pilot study can be an important step in the assessment of an intervention by providing information to design the future definitive trial. Pilot studies can be used to estimate the recruitment and retention rates and population variance and to provide preliminary evidence of efficacy potential. However, estimation is poor because pilot studies are small, so sensitivity analyses for the main trial’s sample size calculations should be undertaken.
Methods
We demonstrate how to carry out easy-to-perform sensitivity analysis for designing trials based on pilot data using an example. Furthermore, we introduce rules of thumb for the size of the pilot study so that the overall sample size, for both pilot and main trials, is minimized.
Results
The example illustrates how sample size estimates for the main trial can alter dramatically by plausibly varying assumptions. Required sample size for 90% power varied from 392 to 692 depending on assumptions. Some scenarios were not feasible based on the pilot study recruitment and retention rates.
Conclusion
Pilot studies can be used to help design the main trial, but caution should be exercised. We recommend the use of sensitivity analyses to assess the robustness of the design assumptions for a main trial.
Introduction
Prior to a definitive intervention trial, a pilot study may be undertaken. Pilot trials are often small versions of the main trial, undertaken to test trial methods and procedures.Citation1,Citation2 The overall aim of pilot studies is to demonstrate that a future trial can be undertaken. To address this aim, there are a number of objectives for a pilot study including assessing recruitment and retention rates, obtaining estimates of parameters required for sample size calculation, and providing preliminary evidence of efficacy potential.Citation3–Citation6
We illustrate how to use pilot studies to inform the design of future randomized controlled trials (RCTs) so that the likelihood of answering the research question is high. We show how pilot studies can address each of the objectives listed earlier, how to optimally design a pilot trial, and how to perform sample size sensitivity analysis. Our example uses a continuous outcome, but most of the content can be applied to pilot studies in general.
Considerations for trial design
When designing a definitive trial, one must consider
The target effect size, such as the difference in means for continuous outcomes;
The variance about the estimates for continuous outcomes, which is used to give a range of responses for individuals in the trial;
Feasibility, including referral, recruitment, and retention rates.
Pilot trial results can inform each of these elements. Factors such as type I error and power are set independent of the pilot and are discussed in detail elsewhere.Citation7 We focus on external pilot studies, where the trial is run before the main trial, and results are not combined.Citation8
Feasibility
The first consideration is feasibility: will the researchers be able to recruit the required number of participants within the study timeframe and retain them in the main trial? While review of clinical records can be used to give some indication of potential participant pool, pilot studies provide estimates of the number of participants that actually enroll and consent to randomization, and these estimates should be included in the manuscripts that report the pilot study results.Citation9 Many trials struggle to reach their sample size goal, which can result in trial extensions or failure to recruit to their prespecified sample size.Citation10 Failure to recruit is a major issue in UK publicly funded trials, where 45% fail to reach target sample size.Citation10 Along with review of prior trials at the same centers in similar populations, pilot studies can also give estimates of retention rates and adherence rates.Citation11 Missing data and dropouts are issues in most RCTsCitation12 and need to be considered at each step of the research process,Citation13 including design, reporting,Citation9 and progression to a larger definitive trial.Citation11,Citation14
Target effect size and potential efficacy
Hislop et alCitation15 undertook a systematic review to identify seven approaches for determining the target effect size for an RCT and classified them as clinically important and/or realistic. A specific type of clinically important difference is the smallest value that would make a difference to patients or that could change care, a quantity referred to as the minimum important difference (MID), or sometimes minimally clinical important difference. The MID can be difficult to determine, particularly as it can change with patient population. However, researchers in various fields have investigated MID estimation and provide guidance on estimation.Citation16,Citation17 In the absence of a known MID for continuous outcomes, particularly patient-reported outcomes, a standardized effect sizeCitation15 between 0.3 and 0.5 has been recommended.Citation17,Citation18 Expert opinion is also used to specify important differences.Citation15 Although some researchers use the pilot effect size to power the definitive trial, this is a practice that should be avoided in general, as estimation is poor due to the small sample size, and is likely to mislead.Citation19
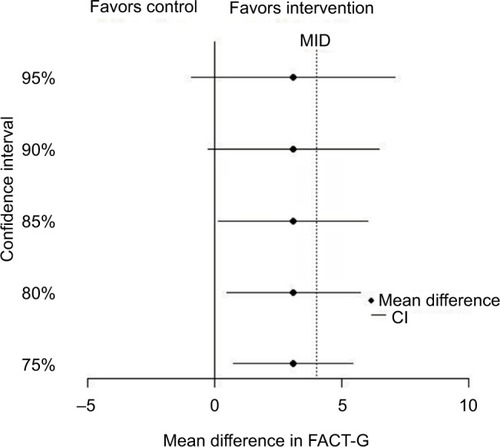
The target effect size must also be realistic, and the estimated effect size and confidence interval (CI) from the pilot can give some evidence here, ie, whether there is any indication that the intervention is effective and important differences might be obtained in the main trial.Citation5 The small sample size of a pilot makes estimation uncertain, so caution must be exercised.Citation19,Citation20 One approach for handling this uncertainty is to use significance levels other than the “traditional” 5% to provide preliminary evidence for efficacy, with corresponding CIs such as 85 and 75% in addition to 95% CIs.Citation21 A figure showing these CIs, the MID, and the null value can be a helpful way of displaying pilot results, by facilitating an assessment of both statistical significance and the potential for clinical significance.Citation31 While some authors argue against carrying out hypothesis tests and assessing efficacy from pilots, even potential efficacy, most pilot studies do undertake hypothesis tests.Citation6 We strongly stress that preliminary efficacy evidence from a pilot study should not be overstated, and researchers should avoid temptation to forgo the main trial.Citation20,Citation22
Estimating the standard deviation (SD)
The population SD is another key element of sample size estimation for continuous outcomes, and its estimation is one of the objectives for conducting a pilot study. However, similar to the effect size, the SD can be imprecisely estimated due to the pilot’s small sample size. Using a pilot study’s SD to design a future sample size has been shown to often result in an underpowered study.Citation23,Citation24 Thus, sensitivity analyses should be undertaken.
Sensitivity analysis for sample size
Sensitivity analyses are important to assess the robustness of study results to the assumptions made in the primary analysis.Citation25 Sensitivity analyses should also be performed in the design stageCitation26 and can take the form of accounting for the uncertainty in estimation by calculating sample sizes based on a range of plausible SDs and retention/dropout rates. BrowneCitation23 suggested using the pilot study’s upper limit of the 80% CI for the SD to calculate sample size in the subsequent trial. One may also consider SDs from the literature.
Pilot study sample size
In order to have the best chance of answering the research question, researchers should carefully consider the size of not only the definitive trial but also the pilot as well. Although traditional power calculations are inappropriate for pilot studies (since the primary aim of a pilot study is not to test superiority of one treatment over the other), a sample size justification is important. While there are several rules of thumb for the size of a pilot study, ranging from 12 to 35 individuals per arm,Citation5,Citation27 none of these guidelines account for the likely size of the future trial.
Whitehead et alCitation27 showed how, if you know the main trial’s target effect size, you can estimate the pilot study’s optimum sample size, minimizing the number of patients recruited across the two studies. From this work, they proposed stepped rules of thumb for pilot studies based on the target effect size and the size of the future trial. These rules are summarized in . For example, if the future trial will be designed around a small effect, then the number of patients per arm for the pilot study should be 25 for 90% power. Using these rules increases the likelihood of appropriate power for the future trial. Cocks and TorgersonCitation5 also recommend basing the pilot study size on the future trial’s size, if the SD is known.
Table 1 Stepped rules of thumb for pilot study sample size per arm, as a function of the target effect size (standardized difference) and power of the main trial
Example
Suppose a research team is planning a pilot in the anticipation of designing a definitive trial. The main trial will be a two-arm RCT comparing a new supportive care regimen for cancer patients to usual care, with assessments at baseline, 6 weeks, and 3 months. Their primary outcome is the quality of life at 3 months as measured by the Functional Assessment of Cancer Therapy-General (FACT-G), a 27-item questionnaire covering aspects of physical, social, family, emotional, and functional well-being.Citation28
Pilot study sample size
To use the stepped rules of thumb for pilot sample size, the researchers must consider the target effect size and SD for the main trial in order to calculate the standardized difference (effect size). They find that the estimated FACT-G MID is between three and six pointsCitation29 and an SD estimate from the literatureCitation30 is 14 in similar populations. Using an MID estimate of four points, and an SD of 14, the standardized effect size is 4/14=0.29. For a 90% powered main trial, they should use a sample size of 25 per arm for the pilot ().
Pilot study results
Suppose now the researchers undertake the pilot study of 50 participants with recruitment over 2 months. Of the 100 potential participants, 70 participants were referred by their oncologist, 60 participants met eligibility criteria, and 50 participants agreed to participate. This indicates a recruitment rate of 50% of eligible patients, at 25 recruitments per month. Of the 50 participants, 40 participants completed all three assessments; retention is 80%. These rates will aid in estimating the main trial duration.
The difference in the quality of life between the arms at 3 months is estimated at 3.1 points, with 95% CI −1.8 to 8.0, and SD =11.2. shows several CIs demonstrating that the intervention is promising, as each CI contains the MID of 4. Thus, the objective of the pilot study to provide preliminary evidence of efficacy has been met.
Figure 1 Mean difference in FACT-G scores between pilot study intervention and control arms with confidence intervals.
Sample size calculations and sensitivity analyses
shows sample sizes based on the pilot study’s SD, its upper 80% CI limit (taken as the square root of the CI for the variance), and the original estimate from the literature. Sample sizes are also given for the observed dropout rate (20%) and for >5 and <5%. For 90% power, sample size ranges from 392 to 692. For 80% power, sample sizes range from 296 to 518. Note that the sensitivity analysis is quantified in terms of the effect of assumptions on the sample size. An alternative approach is to fix the sample size (at 392 say) and observe how power varies based on assumptions.
Table 2 A range of sample sizes varying dropout, recruitment rate, and estimated SD assuming an effect size of four points
Feasibility of the main trial
We now consider feasibility. Specifically, are the researchers likely to be able to recruit the required number of participants within the study timeframe? Based on the funding and the follow-up time of 3 months, recruitment can take 1.5 years. If the pilot recruitment rate of 25 participants per month is a good estimate, then the study will be able to recruit and enroll 450 participants. This falls below several of the estimates in . Further consideration may be needed how to expand the pool of participants.
Conclusion
We have illustrated how pilot studies can aid in the design of future trials with continuous outcomes by providing estimates of population SD, evidence of potential for intervention effectiveness, and quantification of feasibility in the form of recruitment and retention rates. We have introduced guidelines on pilot study sample size and demonstrated sample size sensitivity analysis. The example demonstrated how main trial sample size estimates can vary dramatically by plausibly altering assumptions.
The decision to progress from a pilot trial to a main trial is generally made using feasibility estimates, as well as issues such as protocol nonadherence. For more information on progression, refer to Avery et al,Citation11 and for information on the context of internal pilots, refer to Hampson et al.Citation14 Whether researchers decide to progress to a definitive trial or not, results of pilot studies should be published. A CONSORT extension for reporting results of pilot and feasibility studies gives detailed guidelines.Citation9
Acknowledgments
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors. The current address of ALW is Southampton Clinical Trials Unit, University of Southampton, Southampton, UK.
Disclosure
Professor MLB is supported by the University of Arizona Cancer Center, through NCI grant P30CA023074. Professor SAJ is funded by the University of Sheffield. Dr ALW was funded by a University of Sheffield studentship. The authors report no other conflicts of interest in this work.
References
- ThabaneLMaJChuRA tutorial on pilot studies: the what, why and howBMC Med Res Methodol201010120053272
- ArainMCampbellMJCooperCLLancasterGAWhat is a pilot or feasibility study? A review of current practice and editorial policyBMC Med Res Methodol2010106720637084
- CraigPDieppePMacintyreSDeveloping and evaluating complex interventions: the new Medical Research Council guidanceBMJ2008337a165518824488
- LancasterGCampbellMEldridgeSTrials in primary care: statistical issues in the design, conduct and evaluation of complex interventionsStat Methods Med Res201019434937720442193
- CocksKTorgersonDJSample size calculations for pilot randomized trials: a confidence interval approachJ Clin Epidemiol201366219720123195919
- ShanyindeMPickeringRMWeatherallMQuestions asked and answered in pilot and feasibility randomized controlled trialsBMC Med Res Methodol201111111721846349
- JuliousSASample sizes for clinical trials with normal dataStat Med200423121921198615195324
- WittesJBrittainEThe role of internal pilot studies in increasing the efficiency of clinical trialsStat Med199091–265722345839
- EldridgeSMChanCLCampbellMJCONSORT 2010 statement: extension to randomised pilot and feasibility trialsBMJ2016355i523927777223
- SullyBJuliousSANichollJA reinvestigation of recruitment to randomised, controlled, multicenter trials: a review of trials funded by two UK funding agenciesTrials20131416623758961
- AveryKNLWilliamsonPRGambleCInforming efficient randomised controlled trials: exploration of challenges in developing progression criteria for internal pilot studiesBMJ Open201772e013537
- BellMLFieroMHortonNJHsuCHHandling missing data in RCTs; a review of the top medical journalsBMC Med Res Methodol201414111825407057
- BellMLFaircloughDLPractical and statistical issues in missing data for longitudinal patient-reported outcomesStat Methods Med Res201423544045923427225
- HampsonLVWilliamsonPRWilbyMJJakiTA framework for prospectively defining progression rules for internal pilot studies monitoring recruitmentStat Methods Med Res Epub2017101
- HislopJAdewuyiTEValeLDMethods for specifying the target difference in a randomised controlled trial: the Difference ELicitation in TriAls (DELTA) systematic reviewPLoS Med2014115e100164524824338
- RevickiDACellaDHaysRDSloanJALenderkingWRAaronsonNKResponsiveness and minimal important differences for patient reported outcomesHealth Qual Life Outcomes200647017005038
- KingMA point of minimal important difference (MID): a critique of terminology and methodsExpert Rev Pharmacoecon Outcomes Res201111217118421476819
- NormanGRSloanJAWyrwichKWThe truly remarkable universality of half a standard deviation: confirmation through another lookExpert Rev Pharmacoecon Outcomes Res20044558158519807551
- KraemerHCMintzJNodaATinklenbergJYesavageJACaution regarding the use of pilot studies to guide power calculations for study proposalsArch Gen Psychiatry200663548448916651505
- LoscalzoJPilot trials in clinical research: of what value are they?Circulation2009119131694169619349331
- LeeECWhiteheadALJacquesRMJuliousSAThe statistical interpretation of pilot trials: should significance thresholds be reconsidered?BMC Med Res Methodol20141414124650044
- LancasterGADoddSWilliamsonPRDesign and analysis of pilot studies: recommendations for good practiceJ Eval Clin Pract200410230731215189396
- BrowneRHOn the use of a pilot sample for sample size determinationStat Med19951417193319408532986
- VickersAJUnderpowering in randomized trials reporting a sample size calculationJ Clin Epidemiol200356871772012954462
- ThabaneLMbuagbawLZhangSA tutorial on sensitivity analyses in clinical trials: the what, why, when and howBMC Med Res Methodol20131319223855337
- LewisJAStatistical principles for clinical trials (ICH E9): an introductory note on an international guidelineStat Med199918151903194210440877
- WhiteheadAJuliousSCooperCCampbellMJEstimating the sample size for a pilot randomised trial to minimise the overall trial sample size for the external pilot and main trial for a continuous outcome variableStat Methods Med Res20162531057107326092476
- CellaDFTulskyDSGrayGThe functional assessment of cancer therapy scale: development and validation of the general measureJ Clin Oncol19931135705798445433
- WebsterKCellaDYostKThe functional assessment of chronic illness therapy (FACIT) measurement system: properties, applications, and interpretationHealth Qual Life Outcomes200317914678568
- BellMLMcKenzieJEDesigning psycho-oncology randomised trials and cluster randomised trials: variance components and intra-cluster correlation of commonly used psychosocial measuresPsychooncology20132281738174723080401
- BellMLFieroMHDhillonHMBrayVJVardyJLStatistical controversies in cancer research: using standardized effect size graphs to enhance interpretability of cancer-related clinical trials with patient-reported outcomesAnn Oncol20172881730173328327975