
Abstract
Background
Before embarking on administrative research, validated case ascertainment algorithms must be developed. We aimed at developing algorithms for identifying inflammatory bowel disease (IBD) patients, date of disease onset, and IBD type (Crohn’s disease [CD] vs ulcerative colitis [UC]) in the databases of the four Israeli Health Maintenance Organizations (HMOs) covering 98% of the population.
Methods
Algorithms were developed on 5,131 IBD patients and 2,072 controls, following independent chart review (60% CD and 39% UC). We reviewed 942 different combinations of clinical parameters aided by mathematical modeling. The algorithms were validated on an independent cohort of 160,000 random subjects.
Results
The combination of the following variables achieved the highest diagnostic accuracy: IBD-related codes, alone if more than five to six codes or combined with purchases of IBD-related medications (at least three purchases or ≥3 months from the first to last purchase) (sensitivity 89%, specificity 99%, positive predictive value [PPV] 92%, negative predictive value [NPV] 99%). A look-back period of 2–5 years (depending on the HMO) without IBD-related codes or medications best determined the date of diagnosis (sensitivity 83%, specificity 68%, PPV 82%, NPV 70%). IBD type was determined by the majority of CD/UC codes of the three recent contacts or the most recent when less than three contacts were recorded (sensitivity 92%, specificity 97%, PPV 97%, NPV 92%). Applying these algorithms, a total of 38,291 IBD patients were residing in Israel, corresponding to a prevalence rate of 459/100,000 (0.46%).
Conclusion
The application of the validated algorithms to Israel’s administrative databases will now create a large and accurate ongoing population-based cohort of IBD patients for future administrative studies.
Introduction
Population-based cohorts of inflammatory bowel disease (IBD) hold a large potential to facilitate our understanding of this disease by exploring its different aspects such as epidemiology, the effectiveness of treatments, and predictors of disease outcomes. Israel may be an ideal place to study IBD on a population level using administrative databases. It has a universal health care system in which each resident has a unique identifying code from birth, and all are required by law to be insured by one of four Israeli Health Maintenance Organizations (HMOs), namely, Clalit Health Services, Maccabi Healthcare Services, Meuhedet Health Services, and Leumit Health Services, covering 52%, 25%, 14%, and 9% of the population, respectively.Citation1 The Israeli health care system is composed of hospitals and ambulatory care centers; the latter facility is provided by the HMOs insuring 98% of the Israeli population (excluding nonpermanent residents or those with a “tourist” status). All HMOs have “paperless central computerized electronic databases” with extensive data on all health contacts, purchases of medications, procedures (eg, endoscopic evaluations and imaging), laboratory test results, hospitalizations, and mortality, as well as demographic information. The cost of medications is covered almost entirely by the HMO, ensuring high accuracy of drug purchasing records. Records of the HMOs from the hospitals are mostly limited to discharge diagnoses, but in some circumstances, more information is available.
Research on administrative databases can only be performed following rigorous development and validation of algorithms for case ascertainment to accurately identify true IBD patients within the databases.Citation2,Citation3 Such algorithms may include a combination of diagnostic codes (eg, International Classification of Disease [ICD] Version 9), health care contacts (hospitalizations or outpatient visits), prescription records, and/or procedure codes.
We thus aimed at developing algorithms for each of the four Israeli HMOs for identifying true IBD patients (ie, prevalence algorithm), date of disease onset (ie, incidence algorithm), and IBD type (Crohn’s disease [CD] vs ulcerative colitis [UC]). We also aimed at validating the chosen algorithms on independent large cohorts randomly selected from each HMO.
Methods
Algorithm derivation: reference standard cohorts
IBD-related diagnostic codes (“codes” henceforth) were defined as codes from the ICD9: CD, 555.x and UC, 556.x (excluding isolated “colitis” [code 555.1], as this is a nonspecific diagnosis). One HMO had internal general codes of “IBD” which were also included (Table S1 provides the complete list of codes).
We first established two reference cohorts of true positive (TP; ie, patients with IBD) and true negative (TN; ie, subjects without IBD), composed of patients who were seen in the gastroenterology outpatient clinics of seven hospitals in Israel (affiliated with the authors’ list above) independent of the HMO databases (), by individual chart reviews. For the TP cases, the chart reviewers also identified the date of diagnosis and IBD type (CD, UC, or IBD unclassified [IBDU]). The chart reviewers were medical professionals, were experienced in pediatric IBD, and were trained by DT. The process itself included an in-depth longitudinal review of all available information in the charts, including the clinician’s coding, free text of medical history and discussion/plan, medications, and procedures and investigations. Questionable cases were judged by DT.
Figure 1 Study flowchart.
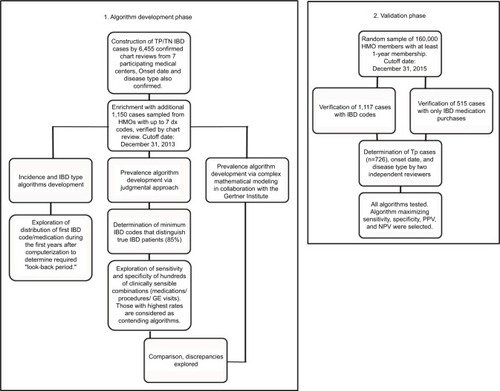
In parallel, we sampled from the HMOs random charts of members who had been insured for at least 1 year with seven or less IBD-related diagnostic codes and determined by individual chart review those who truly had IBD (added to the TP cohort) and those who did not (added to the TN cohort). This was done in order to enrich the cohort with those who had only a few IBD-related codes and thus represent a more challenging group to diagnose. In three HMOs, we sampled 25–100 subjects in each code stratum from one to seven codes (the exact number of subjects depended on local technical constraints). The combined TP and TN groups formed the reference cohort, from which the diagnostic accuracy of algorithms was explored to differentiate IBD from non-IBD, to differentiate IBD type (CD vs UC), and to determine the true date of diagnosis.
Development of the algorithm for identifying IBD cases (ie, prevalence algorithm)
We first verified that the TP cases from the hospitals had at least one code within the HMOs’ databases. Next, we linked clinical data from the HMOs to each TP case and TN subject, including IBD codes of diagnoses, physicians’ health contacts, procedures, imaging, and purchase of IBD-related medications using the following definitions:
Codes accompanied by the suffix “rule out” or “suspected” and the nonspecific code “colitis” or “radiation colitis” were excluded, as done by others.Citation4,Citation5
Multiple codes registered by the physicians of the same medical specialty on the same day were considered as one.
At least 1-year interval was required between the first code or purchase of IBD-related medication and the last follow-up (ie, date of data lock, death, or discontinuation of membership in the HMO), to allow a sufficient “look-forward” period for accumulation of codes.
Procedures performed for screening purposes (ie, Israeli Ministry of Health code 5255) as opposed to diagnostic purposes were not counted as procedures.
In the first stage of the algorithm development, we constructed multiple 2×2 contingency tables to differentiate TP patients from TN subjects, utilizing clinically relevant combinations of the following variables: the number of IBD codes, IBD-related medications (Table S2), time periods between purchases of medications, IBD-related procedures (Table S3), and visits to a gastroenterology clinic. In parallel, statisticians from the Biostatistics Unit of the Gertner Institute for Epidemiology and Health Policy Research independently attempted to derive data-driven algorithms using statistical modeling methods on the same data. The top contending algorithm was selected based on maximizing sensitivity and specificity and was then tested on the validation data set (“Validation of all three algorithms” section).
Development of the algorithms to identify incident cases of IBD
The transition from paper to electronic records in the HMOs, which occurred during 1998–2003 (depending on the HMO), posed a challenge to accurately identify the true diagnosis date because the first recorded code in the database could be a true incident date or a prevalent case who is merely new to the electronic system. This bias is an unavoidable phenomenon of all computerized databases.Citation6 The longer the preceding period without an indication of IBD in the database (ie, “look-back” period), the higher the likelihood that the first documented code or IBD-related medication in the database indeed reflects the true diagnosis date. To determine the required look-back period, the true date of disease onset recorded by the chart reviewers in the TP reference cohort was compared with the date of the first IBD code or IBD-related medication purchase in the HMOs’ databases. Those who had their first code or medication purchase within the look-back period cannot be used for constructing an incidence cohort, since their date of disease onset cannot be determined with certainty.
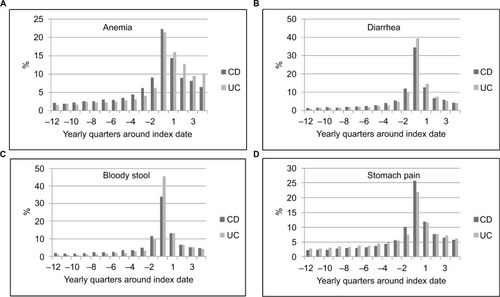
We explored several combinations of codes, medications, and procedures to develop an incidence algorithm for the date of diagnosis ±1 year. For internal validation, we employed a nontargeted approach in Clalit and Maccabi, the two largest HMOs, by exploring histograms of dates of first codes and medications of all IBD patients in the HMOs (identified by the aforementioned prevalence algorithm), as well as the distribution of codes of anemia, abdominal pain, and diarrhea around the proposed index year, determined by the incidence algorithm. If most of the codes were on or around the proposed index date, this would lend further validity to identifying the index year by the proposed algorithm. Finally, the chosen algorithm was validated on an independent cohort (“Validation of all three algorithms” section).
Development of the algorithms to classify IBD disease type (CD or UC)
IBD type was determined by comparing recorded codes (CD or UC) in the HMOs’ databases with the true diagnosis recorded by the chart reviewers in the TP cohort. Several combinations of codes were explored, and the algorithm that maximized predictive values was then validated on an independent cohort (“Validation of all three algorithms” section).
Validation of all three algorithms
Independent of the aforementioned reference cohorts, the validation cohort was composed of 160,000 subjects randomly selected from the HMO’s databases (40,000 subjects per HMO) with the only inclusion criterion being a member in the HMO for at least 1 continuous year. Based on our prior findings that almost all IBD patients are identified in the HMO’s databases by at least one code, members without any IBD-related codes were automatically categorized in the TN group, while all charts with any IBD-related codes were reviewed independently by two trained chart reviewers. However, to be conservative, we reviewed also subjects with the purchase of any IBD-related medication (Table S2) even in the absence of IBD-related codes. Disagreements between the reviewers were resolved by the principal investigator (DT). In only Clalit, charts were reviewed by the treating gastroenterologist. Based on this chart review process, the 160,000 subjects were dichotomized into TP IBD patients and TN subjects. The aforementioned developed algorithms were then tested on this cohort for sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV).
IBD prevalence
Following the validation process, we applied the algorithms on the databases of all four HMOs and identified IBD patients as of December 31, 2015. Denominators rates were derived from the Israeli National Insurance Institute.
Statistical analysis
The diagnostic accuracy of all algorithms was explored by constructing 2×2 contingency tables to calculate sensitivity, specificity, PPV, and NPV, with 95% confidence intervals (CI). In parallel, the Gertner Institute independently used logistic regression and Classification and Regression Trees analysis to develop data-driven algorithms. Models were tested by applying an automated procedure for Recursive Partitioning and Regression Trees. Inter-rater agreement was calculated via the κ statistic. Data analyses were conducted by using SPSS Version 22.0 0 (IBM Corporation, Armonk, NY, USA), the “rpart”: recursive partitioning. R package version 3.2.2 (R Development Core Team, 2013; https://www.r-project.org), and SAS software Version 9.4 (SAS Institute Inc., Cary, NC, USA). This study received approval from all ethics committees of the research institutions taking part in the study (Shaare Zedek Medical Center, Tel Aviv Sourasky Medical Center, Rabin Medical Center, Hadassah Medical Center, Soroka Medical Center, Rambam Health Care Campus, Chaim Sheba Medical Center, Clalit Health Services, and Leumit Health Services) and was performed according to their instructions.
Results
Prevalence algorithms
We reviewed the charts of 6,455 subjects who visited the gastroenterology clinics of the participating hospitals (ie, outside the HMOs), including 4,886 (76%) TP IBD cases and 1,569 (24%) TN (non-IBD) subjects. Of the hospitals’ TP cohort, 4,693 (97%) had at least one IBD-related code in the HMOs. This implies that the likelihood of IBD in a given subject without any codes within the HMOs’ databases is negligible, and those not identified by at least one code could be considered as not having IBD. We confirmed this observation later in the validation cohort (see below).
In order to ensure that subjects with only a few codes are properly represented in the cohort, additional 1,150 cases with seven or less codes were added to the TP cohort (n=554, 48%) and TN cohort (n=596, 52%) from the HMOs’ databases following individual chart reviews (; 272 members in the four HMOs with one code, 237 with two codes, 209 with three codes, 145 with four codes, 110 with five codes, 107 with six codes, and 118 with seven codes). The final derivation cohort thus included 7,203 subjects: 5,131 (71%) TPs, and 2,072 (29%) TNs ().
Table 1 Characteristics of subjects constituting the derivation algorithm data sets in the 4 HMOs
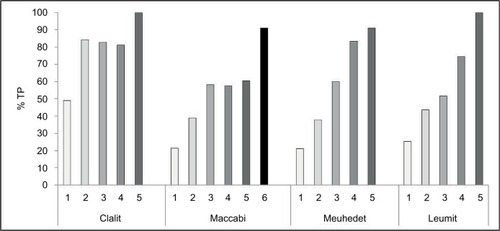
As expected, there was a positive correlation between the TP rate and the number of codes recorded for the subjects until a saturation of >80% TPs had been reached (determined a priori as the sufficient cutoff): in Clalit, Meuhedet, and Leumit after four codes and in Maccabi after five codes (). We thus concluded that at least five to six IBD codes (depending on the HMO) were necessary to determine TP IBD status, irrespective of other variables. In Clalit, at least one code defined as “permanent” by the physician with one regular code or one hospital discharge IBD-related code with one regular code was also sufficient to represent TP cases with 99% accuracy. All other cases required supportive data to determine the diagnosis of IBD. We thus constructed 942 combinations of codes, procedures, and medications (the number of purchases, time interval between purchases, and cumulative months of intake) to explore in each HMO (Table S4).
Figure 2 Association between the number of IBD-eligible codes and true positive rates.
One combination was found to perform best in all HMOs: at least one IBD-related code with either of the following: at least three purchases of IBD-related medications, or ≥3-month interval between the first and last purchase, or ≥2 purchases of steroids/5-aminosalicylic acid enemas (Appendix 1). The statistical modeling yielded an algorithm that was slightly inferior to the judgmental one in its discriminant utility and was less clinically intuitive; thus, it was not included in the final analysis (data not shown).
In the 160,000 subjects of the validation data set, 1,117 (0.7%) subjects had at least one IBD-related code, and an additional 515 (0.3%) subjects had purchased IBD-related medications in the absence of codes. The charts of these 1,632 subjects (1%) were individually reviewed; the interobserver agreement between the chart extractors was excellent with an agreement rate of 93% (κ 0.87, 95% CI 0.78–0.97).
Only eight (1.5%) of the 515 patients without IBD codes who had commenced on IBD-related medications were true IBD cases. Based on these findings, as well our previous finding from the hospital cases, we confirmed that those without any IBD codes do not have IBD with an accuracy of almost 100%. Eventually, only 718 (64%) of the 1,117 subjects with at least one code were determined as true IBD patients by the chart review (0.5% of the entire validation cohort).
We then applied our derived algorithm to the validation cohort. Although each HMO was analyzed separately, the chosen algorithm achieved high and similar accuracy in all four HMOs (pooled diagnostic accuracy: sensitivity 89% [95% CI 87%–92%], specificity 99% [99.95%–99.97%], PPV 92% [90%–94%], NPV 99% [99.94%–99.96%]; Appendix 1).
Identifying diagnosis date (ie, incidence algorithm)
We determined a priori that the look-back period should achieve an accuracy of at least 80% for identifying the date of diagnosis, to balance between the accuracy of the algorithm and allowing enough years of follow-up. This has been achieved in 2005 in three of the four HMOs. Maccabi achieved this threshold in 2003, but in order to standardize the incidence cohort, we decided to implement 2005 as the cutoff year across all four HMOs – translating to a look-back period of 5 years in Clalit and Maccabi, 3 years in Meuhedet, and 2 years in Leumit (dictated by the inception date of the computerized systems).
The HMO-specific look-back period in combination with ≥1 year of membership has been determined as the most accurate incidence algorithm, after reviewing many options by 2×2 tables. By this algorithm, 82% of cases in the incidence cohort had an incidence date that matched the true date within ±1 year, meeting our a priori threshold. Further combinations that included codes of anemia, diarrhea, and abdominal pain, as well as excess use of medical services or IBD-related procedures, did not enhance the diagnostic accuracy.
For internal validation in Clalit and Maccabi, we confirmed that codes related to anemia, diarrhea, and stomach pain were most frequent around the index year determined by the aforementioned algorithm (). Finally, we validated the algorithms in the four HMOs on the validation data set of 160,000 subjects resulting in a pooled sensitivity of 83% (95% CI 78%–88%), specificity 68% (60%–75%), PPV 82% (78%–85%), and NPV 70% (64%–76%; Appendix 1).
Figure 3 (A–D) Distribution of IBD-related symptoms around the diagnosis date determined by the algorithm in Clalit and Maccabi.
Algorithms to classify IBD disease type (CD or UC)
The most accurate algorithm of all options was the majority of CD- or UC-specific codes out of the three most recent health care contacts or the most recent code when only one or two codes were available or when there was one CD, one UC, and one IBD diagnosis. This algorithm achieved a pooled sensitivity of 92% (95% CI 88%–95%), specificity 97% (94%–99%), PPV 97% (94%–98%), and NPV 92% (89%–94%) on the validation cohort (Appendix 1). As there is no specific code for IBDU in either the ICD9 system or the HMOs, this phenotype could not be categorized by our algorithm. Of the 38 IBDU cases from the hospitals, 16 were recorded in the HMO databases as CD, 19 as UC patients, and three with a general “colitis” code.
IBD prevalence
On December 31, 2015, a total of 38,291 IBD patients were residing in Israel, corresponding to a national prevalence rate of 459/100,000 (0.46%), of whom 20,196 (52.7%) had CD, 17,810 (46.5%) had UC, and 285 (0.8%) had only a general IBD code (available in one of the HMOs) and thus could not be classified as either UC or CD. A manuscript with complete analyses of the epidemiology of IBD in Israel based on these algorithms is underway.
Discussion
Following a rigorous multistep process, we developed and validated novel algorithms for exploring population-based IBD in Israel using health administrative data. These algorithms included a prevalence algorithm, an incidence algorithm (for constructing a population-based inception cohort), and an algorithm differentiating CD from UC. We found that codes were very sensitive, but not specific. In fact, nearly one third of those with at least one IBD-related code did not have IBD by chart review, in both the derivation and validation cohorts in all four HMOs. This emphasizes the importance of developing accurate classification algorithms prior to the utilization of any administrative database worldwide.Citation2
Using health administrative data is an efficient method for constructing population-based surveillance cohortsCitation4 while minimizing selection and referral biases. However, using these data that were recorded for nonresearch purposes may be hampered by several inherent limitations.Citation5 Misclassification of the target population is the most notable barrier, and therefore, rigorous validation of diagnostic algorithms is of upmost importance.Citation2,Citation7,Citation8 The validity of using codes to identify the disease under study varies between different diseases.Citation9 IBD may be a particularly challenging disease to ascertain, given the diversity of phenotypes and disease course. Another inherent limitation of any electronic database stems from the relatively recent computerization of health records, resulting in suboptimal performance of the algorithms. It is possible that patients diagnosed long ago and entered complete sustained remission without any IBD treatment may be missed from our prevalence cohort. However, ~98% of existing patients from the medical centers had at least one code within the HMO; thus, this misclassification bias is likely negligible. The bias in the incidence cohorts may be higher (as it is unknown always whether the first code is indeed the first ever or merely the first after computerization), but we reached sufficiently accurate algorithm that is expected to gradually improve further as the time interval increases from the inception of computerization. A third limitation, specific to Israel, is that our data do not include a code for IBDU, and these patients are coded as either CD or UC. Finally, HMO data do not typically include hospital data (except for general discharge diagnoses) or the explicit findings of procedures (eg, endoscopic, radiologic, and histologic results).
Our algorithms are among the most accurate IBD algorithms reported to date (). We performed the derivation and validation processes independently in each of the HMOs, and the fact that the same algorithms achieved the best accuracy across all four HMOs lends further support for their validity. In addition, Israel is unique in several parameters that may improve the accuracy of administrative data. Every citizen is entitled to health care provided by an HMO, who in turn holds records of comprehensive paperless clinical data on centralized servers. Medication records are highly accurate since their cost is covered if purchased through the HMO. Indeed, we found that the purchase of IBD-related medications was the most effective identifying characteristic of IBD cases in addition to physicians’ codes. Another advantage of our database, overcoming to some extent the aforementioned limitations, is that the subjects’ de-identified unique number can be linked to other national repositories including cancer, mortality, hospitalization, and surgeries.
Table 2 Previously published algorithms for IBD ascertainment in administrative databases
Population-based administrative IBD research has been conducted in several regions of the world, such as in Canada’s Ontario, Manitoba, and Alberta provinces, as well as in the UK, Denmark, Kaiser Permanente, and the USA’s PharMetrics database.Citation3,Citation10–Citation17 Not all published case ascertainment algorithms were thoroughly developed and validated (). The Ontario Crohn’s and Colitis Cohort is based on hospital discharge data, billing claims, and demographic data, but medication data are available only for patients >64 years, which improves the accuracy in this age group.Citation10,Citation11 Similar to our findings, they found that 99.5% of IBD patients had at least one IBD code.Citation2,Citation10 Rezaie et al achieved high accuracy in Alberta via an algorithm that incorporated the number of hospitalizations and physician contacts without medication data.Citation3 Additional IBD algorithms are based mainly on IBD-related codes and hospitalizations ().Citation17–Citation19
Conclusion
We developed and validated algorithms to identify IBD cases in the four Israeli HMO databases. The algorithms are now being used for constructing the population-based Epidemiology of the Israeli IBD Research Nucleus administrative database that includes 38,291 IBD patients as of the end of 2015. The diagnosis date can be determined in 13,910 (36%) patients for constructing inception cohorts. This work forms the basis for extensive future research of IBD in Israel. The rigorous methodology described in this manuscript may be adapted to other countries in order to ensure exploiting the full potential of population-based research in IBD.
Study highlights
Current knowledge
Changes in the natural history of inflammatory bowel diseases (IBDs), risk factors, disease trends, and poor disease outcomes are best studied in a population-based setting.
Few validated IBD national cohorts exist with the potential to link extensive medical, environmental, and socioeconomic data to the cohort; the structure of the Israeli health care systems provides such an opportunity, provided that validated algorithms accurately identifying the patients are developed.
What is new here?
We have developed and validated powerful algorithms to correctly identify true IBD patients in Israel, as well as diagnosis date and disease type.
After applying the algorithms to the four Israeli Health Maintenance Organizations’ databases, we calculated the national prevalence rate of IBD at the end of 2015.
The implementation of these algorithms will form the bases for extensive IBD population-based research, impacting numerous clinical aspects.
The rigorous methodology described here may be adopted in other countries in order to ensure exploiting the full potential of population-based research in IBD.
Author contributions
Mira Y Friedman, Gili Focht, Malka Avitzour, Yael Shachar, Iris Goren, Nirit Borovsky, Moshe B Hoshen, Ran D Balicer, Eric I Benchimol, and Dan Turner involved in the conception and design of the study. Mira Y Friedman, Maya Leventer-Roberts, Joseph Rosenblum, Nir Zigman, Iris Goren, Vered Mourad, Natan Lederman, Nurit Cohen, Eran Matz, Doron Z Dushnitzky, Nirit Borovsky, Moshe B Hoshen, Gili Focht, Yael Shachar, Yehuda Chowers, Rami Eliakim, Shomron Ben-Horin, Shmuel Odes, Doron Schwartz, Iris Dotan, Eran Israeli, Zohar Levi, Ran D Balicer, and Dan Turner involved in data collection. Mira Y Friedman, Maya Leventer-Roberts, Joseph Rosenblum, Iris Goren, Nurit Cohen, Yael Shachar, Vered Mourad, Nir Zigman, Doron Z Dushnitzky, Ran D Balicer, Nirit Borovsky, Moshe B Hoshen, Gili Focht, Malka Avitzour, Eric I Benchimol, and Dan Turner involved in the data analysis and interpretation. Mira Y Friedman and Dan Turner drafted the manuscript. All authors contributed toward data analysis, drafting and revising the paper and agree to be accountable for all aspects of the work.
Acknowledgments
The authors are grateful to Raya Barishev, Dr Ofer Ben-Bassat, Zvika Birenbuim, Yana Buyanover, Elana Chernin, Dr Dror Cohen, Leah Della Pergola Berman, Ruth Eliezer, Prof Laurence Freedman, Galina Garberg, Dr Amos Kahan, Dalia Katz, Prof Aharon Klar, Ruth Kurzberg, Dr Oren Ledder, Tami Lederfein, Nina Levhar, Mor Livni, Alina Livshitz, Dana Marcus, Aya Matter, Betty Mazouz, Iris Milner, Sandra Neuman, Dr Ilya Novikov, Dr Joerge Pfeffer, Dimitry Rubinchik, Dr Daher Saleh, Suzie Sharki, Avital Shaul, Terri Singer, Dr Sharon Steinberg, Dr Eyal Shteyer, Dr Yoram Wolf, Liron Yahav, and Arnona Ziv. This study was supported by a grant from the Leona M. and Harry B. Helmsley Charitable Trust.
Disclosure
The authors report no conflicts of interest in this work.
References
- CohenRHealth Maintenance Organization membership 2014, periodic surveys2015 [cited September 2015]. Available from: https://www.btl.gov.il/Publications/survey/Documents/seker_271.pdfAccessed May 15, 2017
- BenchimolEIManuelDGToTGriffithsAMRabeneckLGuttmannADevelopment and use of reporting guidelines for assessing the quality of validation studies of health administrative dataJ Clin Epidemiol201164882182921194889
- RezaieAQuanHFedorakRNPanaccioneRHilsdenRJDevelopment and validation of an administrative case definition for inflammatory bowel diseasesCan J Gastroenterol2012261071171723061064
- NewtonKMWagnerEHRamseySDThe use of automated data to identify complications and comorbidities of diabetes: a validation studyJ Clin Epidemiol199952319920710210237
- PetersenLAWrightSNormandSLDaleyJPositive predictive value of the diagnosis of acute myocardial infarction in an administrative databaseJ Gen Intern Med199914955555810491245
- GriffithsRIO’MalleyCDHerbertRJDaneseMDMisclassification of incident conditions using claims data: impact of varying the period used to exclude pre-existing diseaseBMC Med Res Methodol20131313223496890
- VirnigBAMcBeanMAdministrative data for public health surveillance and planningAnnu Rev Public Health20012221323011274519
- IezzoniLIAssessing quality using administrative dataAnn Intern Med19971278 Pt 26666749382378
- GuttmannANakhlaMHendersonMValidation of a health administrative data algorithm for assessing the epidemiology of diabetes in Canadian childrenPediatr Diabetes201011212212819500278
- BenchimolEIGuttmannAGriffithsAMIncreasing incidence of paediatric inflammatory bowel disease in Ontario, Canada: evidence from health administrative dataGut200958111490149719651626
- BenchimolEIGuttmannAMackDRValidation of international algorithms to identify adults with inflammatory bowel disease in health administrative data from Ontario, CanadaJ Clin Epidemiol201467888789624774473
- Garcia RodriguezLAGonzález-PérezAJohanssonSWallanderMARisk factors for inflammatory bowel disease in the general populationAliment Pharmacol Ther200522430931516097997
- FonagerKSorensenHTOlsenJChange in incidence of Crohn’s disease and ulcerative colitis in Denmark. A study based on the National Registry of Patients, 1981–1992Int J Epidemiol1997265100310089363521
- BernsteinCNBlanchardJFRawsthornePWajdaAEpidemiology of Crohn’s disease and ulcerative colitis in a central Canadian province: a population-based studyAm J Epidemiol19991491091692410342800
- KappelmanMDMooreKRAllenJKCookSFRecent trends in the prevalence of Crohn’s disease and ulcerative colitis in a commercially insured US populationDig Dis Sci201358251952522926499
- KappelmanMDRifas-ShimanSLKleinmanKThe prevalence and geographic distribution of Crohn’s disease and ulcerative colitis in the United StatesClin Gastroenterol Hepatol20075121424142917904915
- HerrintonLJLiuLLewisJDGriffinPMAllisonJIncidence and prevalence of inflammatory bowel disease in a Northern California managed care organization, 1996–2002Am J Gastroenterol200810381998200618796097
- FonagerKSørensenHTRasmussenSNMøller-PetersenJVybergMAssessment of the diagnoses of Crohn’s disease and ulcerative colitis in a Danish Hospital Information SystemScand J Gastroenterol19963121541598658038
- BüschKLudvigssonJFEkström-SmedbyKEkbomAAsklingJNeoviusMNationwide prevalence of inflammatory bowel disease in Sweden: a population-based register studyAliment Pharmacol Ther2014391576824127738
- LewisJDBrensingerCBilkerWBStromBLValidity and completeness of the General Practice Research Database for studies of inflammatory bowel diseasePharmacoepidemiol Drug Saf200211321121812051120
- HerrintonLJLiuLLafataJEEstimation of the period prevalence of inflammatory bowel disease among nine health plans using computerized diagnoses and outpatient pharmacy dispensingsInflamm Bowel Dis200713445146117219403
- LiuLAllisonJEHerrintonLJValidity of computerized diagnoses, procedures, and drugs for inflammatory bowel disease in a northern California managed care organizationPharmacoepidemiol Drug Saf200918111086109319672855
- LehtinenPAshornMIltanenSIncidence trends of pediatric inflammatory bowel disease in Finland, 1987–2003, a nationwide studyInflamm Bowel Dis20111781778178321744433
- HouJKTanMStidhamRWAccuracy of diagnostic codes for identifying patients with ulcerative colitis and Crohn’s disease in the Veterans Affairs Health Care SystemDig Dis Sci201459102406241024817338
- HeinRKösterIBollschweilerESchubertIPrevalence of inflammatory bowel disease: estimates for 2010 and trends in Germany from a large insurance-based regional cohortScand J Gastroenterol201449111325133525259808
- Di DomenicantonioRCappaiGArcàMOccurrence of inflammatory bowel disease in central Italy: a study based on health information systemsDig Liver Dis201446977778224890621
- KurtiZVeghZGolovicsPANationwide prevalence and drug treatment practices of inflammatory bowel diseases in Hungary: a population-based study based on the National Health Insurance Fund databaseDig Liver Dis201648111302130727481587
- JakobssonGLSternegårdEOlénOValidating inflammatory bowel disease (IBD) in the Swedish National Patient Register and the Swedish Quality Register for IBD (SWIBREG)Scand J Gastroenterol201752221622127797278
- LudvigssonJFBüschKOlénOPrevalence of paediatric inflammatory bowel disease in Sweden: a nationwide population-based register studyBMC Gastroenterol20171712328143594
- LeddinDTamimHLevyARDecreasing incidence of inflammatory bowel disease in eastern Canada: a population database studyBMC Gastroenterol20141414025108544
- BittonAVutcoviciMPatenaudeVSewitchMSuissaSBrassardPEpidemiology of inflammatory bowel disease in Quebec: recent trendsInflamm Bowel Dis201420101770177625159452