
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Characterizing the relations between exposures and diseases is the central tenet of epidemiology. Researchers may want to evaluate exposure-disease causation by assessing whether the disease under concern is induced by the various exposures – the so-called “attribution”. In this paper, the authors propose a method to attribute diseases to multiple pathways based on the causal-pie model. The method can also be used to evaluate the potential impact of an intervention strategy and to allocate responsibility in tort-law liability issues.
Introduction
Characterizing the relations between exposures and diseases is the central tenet of epidemiology. Epidemiologists may be interested in knowing the influence of a single exposure on a disease (using effect measures such as risk difference, risk ratio, and odds ratio) or the total influence of multiple exposures on the disease. They may also be interested in knowing any possible interaction between exposures. Through epidemiological studies, the complex relations between multiple exposures and a disease can be clarified.Citation1
Attention has also been given to the “processes”, “pathways”, or “mechanisms” themselves, through which an exposure brings about the disease. For example, one may want to know whether the causal relationship between an exposure and a disease is mediated by a specific “mediator”. If so, the influence of the exposure on the disease can be decomposed: the “indirect effect” is the effect mediated by the mediator, and the “direct effect” is the one not mediated by it. A statistical method that can decompose the exposure effect is structural equation modeling (SEM).Citation2–Citation4 Effect decomposition in SEM is straightforward; the effect pertaining to a specific pathway is simply the product of the path coefficients of the traveled paths. For the indirect effect, we sum up the effects of those pathways that pass through the mediator, and for the direct effect, those that do not pass through it. However, this only works for a continuous mediator and continuous disease. The methods proposed by Robins and Greenland,Citation5 Pearl,Citation6 and VanderWeeleCitation7 are more general. These methods can accommodate any variable type and can cope with exposure–mediator interactions and nonlinear relations between variables.
The aforementioned methods evaluate exposure–disease causation by going from exposures to a disease. Sometimes we may be interested in backward induction by assessing whether the disease under concern is induced by the various exposures – the so-called “attribution”. (Note that the attribution here is based on epidemiologic data,Citation8–Citation14 and should not be confused with attribution in social psychology where the human perception of causations is in focus.)Citation15 For example, when planning intervention strategies, policymakers may want to compare the effectiveness of various intervention programs directed at removing different exposures in the population. In this case, we need to know the proportion of disease that was induced by each exposure. As another example, in some tort litigation, the court is concerned about the contribution of a specific exposure to the disease occurrence of the plaintiff. If probabilistic apportionment of causal responsibilityCitation16,Citation17 is adopted, the court needs to know the probability that the occurrence of the disease was induced by this exposure. In situations like these, we can use indices such as the attributable fractionCitation8–Citation12 and the causal-pie weightCitation13,Citation14 for attribution. When there are multiple exposures, a summation of the attributable fractions for all exposures may exceed 100%. Clearly, this makes no sense, and the index needs some rectifications.Citation18–Citation23 When there are multiple exposures, one can compute a panel of causal-pie weights (summing up to 100%) for the individual effects of each and every exposure as well as the interactive effects between them. However, neither the attributable fraction nor the causal-pie weight takes disease pathways into account.
In this paper, we propose a method to attribute diseases to multiple pathways based on the causal-pie model.Citation1,Citation24 The method can also be used to evaluate the potential impact of an intervention strategy and to allocate responsibility in tort-law liability issues.
Methods
Relations between an exposure, a mediator, and a disease
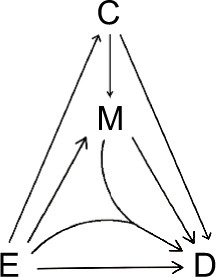
A “directed acyclic graph” (DAG)Citation1,Citation25,Citation26 is used to depict the causal relations between an exposure (E) and a disease (D), which can be mediated by a mediator (M) (). Causality (also referred to as causation, or cause and effect) is a process (arrows in ) that connects one set of variables (the “causes” or “risk factors”) with another set of variables (the “effects” or “outcomes”), where the first is partly responsible for the second, and the second is partly dependent on the first. An effect (outcome) can, in turn, be a cause (risk factor) for many other effects (outcomes). Note that a DAG depicts a simplified biology, ignoring any feedback loop where an effect can feed back to the same cause that leads to the very effect in the first place.
Figure 1 The two paths for M-stage and four paths for D-stage.
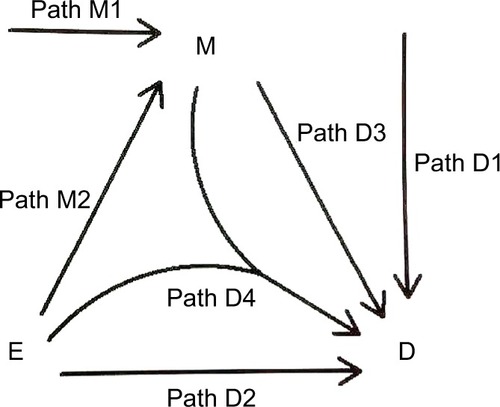
We consider the exposure, the disease, and the mediator as dichotomous variables. We call the occurrence of the mediator, the M-stage, such as the paths M1 and M2, and the occurrence of the disease, the D-stage, such as the paths D1, D2, D3, and D4 (). Note that to indicate “interaction”, we allow two DAG arrows to meet and merge before pointing at the same variable, such as the D4 path in .
A causal-pie model for mediator and disease
We follow the causal-pie framework for mediator and disease proposed by Hafeman.Citation27 We invoke the “sufficient-cause positive monotonicity assumption” at the individual level, that is, the effects of the exposure on the mediator and on the disease as well as the effect of the mediator on the disease, if any, can only be harmful and cannot be preventive for any individual.Citation1,Citation13,Citation14,Citation27,Citation28 In , under the assumption, there is a total of six classes of causal pies – two for the M-stage and four for the D-stage. The two causal-pie classes for the M-stage are: 1) a causal-pie class not containing E as its component and 2) a causal-pie class containing E as its component (1 and 2 correspond to paths M1 and M2 in , respectively). The four causal-pie classes for the D-stage are: 3) a causal-pie class containing neither E nor M as its component, 4) a causal-pie class containing E but not M as its component, 5) a causal-pie class containing M but not E as its component, and 6) a causal-pie class containing both E and M as its components (3, 4, 5, and 6 correspond to paths D1, D2, D3, and D4 in , respectively).
Figure 2 The total six causal-pie classes for M-stage and D-stage.
Abbreviations: D, disease; E, exposure; M, mediator; U, unknown components.
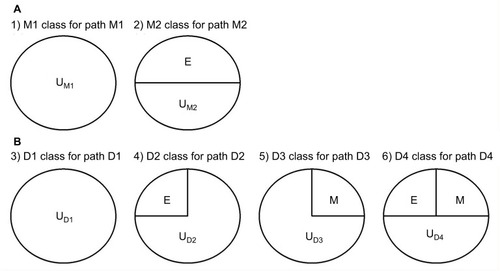
Aside from the exposure and the mediator, each causal-pie class contains a distinct constellation of unknown components. We denote these by U – the UM1, UM2, UD1, UD2, UD3, and UD4, respectively, in . When all components in a causal pie appear, the causal pie is completed, and the corresponding mediator or disease is meant to occur. The arrivals of the unknown components (U) are random events. When the U of a particular causal pie arrives and other component(s) (E, M, or both), if any, in the causal pie all exists, the causal pie is completed, and as mentioned previously, the corresponding mediator or disease occurs. Otherwise, the U departs, and the completion of this causal pie is contingent on the events that the same U arrives again.
Disease pathways
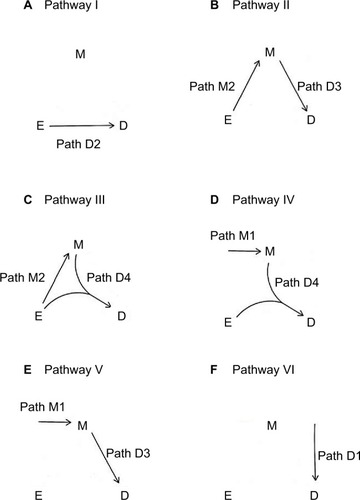
An individual can follow the paths depicted in to become diseased. A total of six distinct disease pathways can thus be identified ():
I. The exposure causes the disease directly (D2).
II. The exposure causes the mediator, which in turn causes the disease (M2D3).
III. The exposure causes the mediator, and then both interact to cause the disease (M2D4).
IV. The exposure and an exogenous mediator interact to cause the disease (M1D4).
V. An exogenous mediator causes the disease directly (M1D3).
VI. Neither the exposure nor the mediator causes the disease (D1).
Figure 3 The six disease pathways.
Abbreviations: D, disease; E, exposure; M, mediator.
Estimation of the causal-pie parameters
We assume that in the follow-up period, the arrival rates of U in the six classes of causal pies, denoted by λM1, λM2, λD1, λD2, λD3, and λD4, respectively, are constant. We also invoke the “no redundancy assumption”,Citation28,Citation31,Citation32 that is, for each and every subject in the population, at most one U can arrive in a sufficiently short time interval.
One can conduct a cohort study to estimate the aforementioned six causal-pie parameters – λM1, λM2, λD1, λD2, λD3, and λD4. Suppose that there are n exposed subjects and m unexposed subjects in the cohort. At the start of the follow-up (t=0), all the subjects are mediator- and disease-free. During the follow-up period (from t=0 to t=T), for subjects who contracted the disease, the researcher records their mediator status at the moments they contracted the disease. For subjects who did not contract the disease during the following period, the researcher records their mediator status at the end of the follow-up (t=T). A tally of subjects at the end of the follow-up is shown in . This dataset has a total of 6 degrees of freedom (2Citation2 − 1=3 for the exposed subjects and 2Citation2 − 1=3 for the unexposed), which is equal to the number of the unknown parameters. Therefore, λM1, λM2, λD1, λD2, λD3, and λD4 are just identifiable. See Supplementary materials for details of the estimation procedure.
Table 1 A tally of subjects at the end of the follow-up of a cohort study
Attribution, a backward induction process
As pointed out earlier, attribution is a backward induction process, assessing whether the outcome under concern is induced by some variables. Thus, we reverse the direction of the usual DAG arrows in to become the “attribution arrows” ( and ). When an attribution arrow points at a variable (exposure or mediator), it means that the indicated variable is one cause of the outcome (disease or mediator, depending on the point from which the arrow originates). When an attribution arrow points at the exposure and the mediator simultaneously, it means that the exposure and the mediator interact to cause the disease. When an attribution arrow points at nothing, it means that neither the exposure nor the mediator is a cause of the disease (or the mediator).
Figure 4 Formulae for attribution.
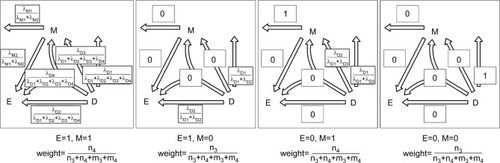
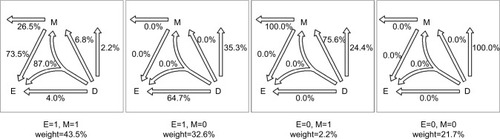
Figure 5 Disease attributions for the example cohort.
Given the six causal-pie parameters, we can compute the probability for any path (). Consider the M-stage first (begin with the “M” in and follow the attribution arrows), an unexposed subject who acquires the mediator during the follow-up can only acquire it through path M1 (probability=1) but not path M2 (probability=0). An exposed subject who acquires the mediator can acquire it either through path M1 or M2, but not both (because of the no redundancy assumption). By Bayes theorem (Supplementary materials), the probabilities are (path M1) and
(path M2), respectively. Next, consider the D-stage (begin with the “D” in and follow the attribution arrows) and also apply the Bayes theorem. An unexposed subject who acquires the disease but not the mediator during the follow-up can do so only through path D1 (probability=1). An unexposed subject who acquires the disease and the mediator can take either path D1 or D3 (with probabilities
and
, respectively). An exposed subject who acquires the disease but not the mediator can take either path D1 or D2 (with probabilities
and
, respectively). An exposed subject who acquires the disease and the mediator can take either path D1, D2, D3, or D4 (with probabilities
,
,
, and
, respectively).
Now we can compute the probability for any pathway. First, we note that under the no redundancy assumption, no one can acquire the disease and the mediator at the same time. A subject who acquires both the disease and the mediator during the follow-up must acquire the mediator before acquiring the disease. To calculate the probability for a pathway that straddles an M-stage path and a D-stage path, we simply multiply the two corresponding probabilities for the two paths. Following this multiplication rule, we can attribute the disease to multiple pathways probabilistically for a diseased subject with known exposure and mediator status. For a subject with unknown exposure and/or mediator status or for all the diseased subjects in the population, we can use the cell counts inside the box in as the weights (shown underneath each panel in ) for attribution.
Next, we discuss attribution from three different perspectives: 1) attributing diseases to multiple pathways, 2) evaluating the potential impact of an intervention strategy, and 3) allocating responsibility in tort-law liability issues.
Attributing diseases to multiple pathways
We can attribute the diseases in the population to the aforementioned six pathways. The population attributable fractions (PAF), which take into account all the diseased subjects in the population, are:
(1)
(2)
(3)
(4)
(5) and
(6) for Pathways I, II, …, VI, respectively. It is worth noting that the six PAFs sum to one.
Evaluating the potential impact of an intervention strategy
We now consider the impact of a specific intervention. We note that if an intervention can block a segment of a pathway (for example, either path M2 or D3, but not necessarily both, of Pathway II), the whole pathway is blocked. To calculate the impact fraction for an intervention, we sum the PAFs for those pathways that are blocked by this intervention.
The impact fractions for a number of interventions are detailed: 1) a complete removal of the exposure from the population: this would block paths M2, D2, and D4 and therefore Pathways I, II, III, and IV. The impact fraction for this intervention is PAFI + PAFII + PAFIII + PAFIV. 2) A complete obstruction of the exposure effect on the mediator: this would block path M2 and therefore Pathways II and III. The impact fraction for this intervention is PAFII + PAFIII. 3) A complete obstruction of the mediator effect on the disease: this would block paths D3 and D4 and therefore Pathways II, III, IV, and V. The impact fraction of this intervention is PAFII + PAFIII + PAFIV + PAFV.
Allocating responsibility in tort-law liability issues
As pointed out earlier, if probabilistic apportionment of causal responsibility is adopted for tort-law liability issues,Citation16,Citation17 the court needs to know the probability that the occurrence of the disease was induced by the particular exposure. We can follow the attribution arrow(s) of a pathway and examine whether the arrow points at the exposure to decide whether the exposure is involved in the pathway. If the attribution arrow of the disease points at the exposure and the mediator simultaneously, the probability that the exposure is involved is taken to be 0.5 (since there is no further information about which path is more likely to be actually taken). But when the attribution arrow of the mediator points again at the exposure, it is then known for certain that the exposure is involved somewhere in the causal chain. Using these rules, the full attributable fractions for Pathways I, II, and III, a half of the attributable fraction for Pathway IV, and none for Pathways V and VI are allocated to the exposure, respectively.
To be precise, for an exposed subject who contracts the disease, the contribution of the exposure to his/her disease – the “attributable fraction among the exposed” (AFE) – is as follows: 1) if the subject does not acquire the mediator during the follow-up (the “E=1, M=0” panel in ),
(7) 2) if the subject acquires the mediator during the follow-up (the “E=1, M=1” panel in ),
(8) and 3) if the mediator status of the subject is unknown,
(9)
Example
We use Richiardi et al’sCitation33 cohort data (m1=9900, m2=490, m3=100, m4=10, n1=4850, n2=800, n3=150, and n4=200, using the notations in ) as an example. For this dataset, using Robins and Greenland’sCitation5 and Pearl’sCitation6 methods, we can decompose the total effect of the exposure on the disease (0.048) into direct effect (0.028) and indirect effect (0.020). Using VanderWeele’sCitation7 method, we can further decompose the total effect into four components: controlled direct effect (0.02), reference interaction (0.008), mediated interaction (0.019), and pure indirect effect (0.001). However, we cannot accomplish attribution using these previous methods.
We use the present method to analyze the data (R code in Supplementary materials). The estimates of causal-pie parameters are as follows: ,
,
,
,
, and
, respectively (Richiardi et alCitation33 did not mention the duration of the follow-up in their paper; as such, we assume T=1, and Supplementary materials show that assuming different Ts will cause the six s to change according to a constant proportion and thus, the estimates of the attributable fractions remain the same). presents the path probabilities.
The PAFs for the six pathways are as follows: PAFI=22.8%, PAFII=2.2%, PAFIII=27.8%, PAFIV=10.0%, PAFV=2.4%, and PAFVI=34.7%, respectively. The total sum of the six PAFs is 22.8%+2.2%+27.8%+10.0%+2.4%+34.7%=100.0%.
The impact fraction for a complete removal of the exposure from the population is 62.8%, for a complete obstruction of the exposure effect on the mediator is 30.0%, and for a complete obstruction of the mediator effect on the disease is 42.4%.
For an exposed subject who contracts the disease, if the subject does not acquire the mediator during the follow-up, AFEM=0=64.7%; if the subject acquires the mediator during the follow-up, AFEM=1=84.5%; and if the mediator status of the subject is unknown, AFE=76.0%.
Discussion
In this paper, we invoke three assumptions for the causal-pie model. The first assumption is the monotonicity assumption.Citation1,Citation13,Citation14,Citation27,Citation28 Without this assumption, the number of the causal-pie classes (12; 3 for the M-stage and 9 for the D-stage) will be larger than the degrees of freedom of the data (6), which makes the causal-pie parameters non-identifiable. Researchers who use the present method should have prior knowledge that the effects of the exposure on the mediator and on the disease and the effect of the mediator on the disease are “monotonic”. To be precise, neither the “no exposure” nor the “no mediator” can be a component of any causal pie. Second, we assume that the arrival rates of the U’s are constant in the follow-up period. When the follow-up time is not too long (for example, less than 5 years), the assumption is reasonable or approximately so. The third assumption is the no redundancy assumption.Citation28,Citation31,Citation32 This is a Poisson-like assumption, which is weaker than the assumption of independent competing causes.Citation13,Citation14,Citation34 Even though two causal-pie classes have overlapping components, the assumption still holds if the overlapping components are not the last one arriving. In addition, the assumption only specifies at most one arrival event of the U’s in an infinitesimally short time interval. Non-rarity of the mediator or the disease for the entire follow-up period by itself does not necessarily imply the violation of the no redundancy assumption.
Controlling for confounding is essential in observational studies. One can stratify the data by the confounders and compute the attributable fractions for each and every stratum. One then uses the count of the diseased subjects in each stratum as the weight to pool the results. This will yield “adjusted” attributable fractions. The present method can also be extended to accommodate other variable types or more general situations. If the exposure or the mediator is multilevel (a continuous variable can be categorized into a multilevel one for an approximation; but caution should be exercised as this may create bias)Citation35 – for example, the exposure has a total of k1 levels and the mediator, a total of k2 levels – under the monotonicity assumption there will be a total of k1 × k2 causal-pie classes for the D-stage. Furthermore, if the disease has a total of k3 subtypes, each with a total of k1 × k2 causal-pie classes, then there will be a total of k1 × k2 × k3 causal-pie classes. In addition, if there are multiple exposures or multiple mediators (an exposure-induced mediator-disease confounderCitation36–Citation38 can be viewed as another mediator; ), the total number of causal-pie classes will be even larger. It seems rather complex. But if one can conduct a large-scale cohort study and use appropriate statistical models, such as a multistate model,Citation39–Citation42 the many causal-pie parameters (or the state transition rates, using the terminology of a multistate model) can be amenable to estimation. Then, one simply follows the present method for attribution.
Figure 6 An exposure-induced mediator-disease confounder as another mediator.
Last but not least, the causal-pie model by itself deserves careful scrutiny. Like the DAG, a causal-pie model depicts an overtly simplified biology. But unfortunately, a direct biological modeling of exposure-disease relations considering all physical or chemical reactions among exposures, their metabolites, or their reaction products within individuals is seldom feasible. Previously, Siemiatycki and ThomasCitation43 and ThompsonCitation44 held a pessimistic view that there is a limit of biological inference from epidemiologic data, since a number of very dissimilar mechanisms or models for disease development can often fit the same data equally well. Recently, an emerging interdisciplinary science, the molecular pathological epidemiology (MPE), has come into focus.Citation45–Citation47 MPE uses molecular pathology tools to dissect disease pathways and mechanisms at molecular, individual, and population levels. Casting the causal-pie model in the MPE framework is a promising future research direction.
Acknowledgments
This paper is partly supported by grants from the Ministry of Science and Technology, Taiwan (MOST 105-2314-B-002-049-MY3 and MOST 104-2314-B-002-118-MY3). No additional external funding was received for this study. The funder had no role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Disclosure
The authors report no conflicts of interest in this work.
References
- RothmanKJGreenlandSLashTLModern Epidemiology3rd edPhiladelphia, PALippincott Williams & Wilkins2008
- BollenKAStructural Equations with Latent VariablesNew York, NYJohn Wiley & Sons1989
- KaplanDStructural Equation Modeling: Foundations and Extensions2nd edThousand Oaks, CASAGE2009
- KlineRBPrinciples and Practice of Structural Equation Modeling4th edNew York, NYGuilford2015
- RobinsJMGreenlandSIdentifiability and exchangeability for direct and indirect effectsEpidemiology1992321431551576220
- PearlJDirect and Indirect Effects: Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, 2001San Francisco, CAMorgan KaufmannAugust 2–5 2001Seattle, Washington
- VanderWeeleTJA unification of mediation and interaction: a 4-way decompositionEpidemiology201425574976125000145
- ColePMacMahonBAttributable risk percent in case-control studiesBrit J Prev Soc Med19712542422445160433
- MiettinenOSProportion of disease caused or prevented by a given exposure, trait or interventionAm J Epidemiol19749953253324825599
- WalterSDThe estimation and interpretation of attributable risk in health researchBiometrics19763248298491009228
- BruzziPGreenSBByarDPBrintonLASchairerCEstimating the population attributable risk for multiple risk factors using case-control dataAm J Epidemiol198512259049144050778
- BenichouJA review of adjusted estimators of attributable riskStat Methods Med Res200110319521611446148
- LiaoSFLeeWCWeighing the causal pies in case-control studiesAnn Epidemiol201020756857320538201
- LeeWCCompletion potentials of sufficient component causesEpidemiology201223344645322450695
- KelleyHHMichelaJLAttribution theory and researchAnn Rev Psychol19803145750120809783
- WrightRWCausation in tort lawCalifornia Law Review19857317351828
- RobinsonGOProbabilistic causation and compensation for tortious riskJ Legal Stud198514779798
- EideGEGefellerOSequential and average attributable fractions as aids in the selection of preventive strategiesJ Clin Epidemiol19954856456557730921
- LandMGefellerOA game-theoretic approach to partitioning attributable risks in epidemiologyBiom J199739777792
- LandMVogelCGefellerOPartitioning methods for multifactorial risk attributionStat Methods Med Res200110321723011446149
- McElduffPAttiaJEwaldBCockburnJHellerREstimating the contribution of individual risk factors to disease in a person with more than one risk factorJ Clin Epidemiol200255658859212063100
- LlorcaJDelgado-RodrıguezMA new way to estimate the contribution of a risk factor in populations avoided nonadditivityJ Clin Epidemiol200457547948315196618
- RabeCLehnert-BatarAGefellerOGeneralized approaches to partitioning the attributable risk of interacting risk factors can remedy existing pitfallsJ Clin Epidemiol200760546146817419957
- RothmanKJCausesAm J Epidemiol19761046587592998606
- GreenlandSPearlJRobinsJMCausal diagrams for epidemiologic researchEpidemiology199910137489888278
- PearlJCausality: models, reasoning, and inference2nd edNew York, NYCambridge University Press2009
- HafemanDMA sufficient cause based approach to the assessment of mediationEur J Epidemiol2008231171172118798000
- SuzukiEYamamotoETsudaTOn the relations between excess fraction, attributable fraction, and etiologic fractionAm J Epidemiol2012175656757522343634
- VanderWeeleTJMediation and mechanismEur J Epidemiol200924521722419330454
- SuzukiEYamamotoETsudaTIdentification of operating mediation and mechanism in the sufficient-component cause frameworkEur J Epidemiol201126534735721448741
- GattoNMCampbellUBRedundant causation from a sufficient cause perspectiveEpidemiol Perspect Innov20107520678223
- LeeWCAssessing causal mechanistic interactions: a peril ratio index of synergy based on multiplicativityPLoS One201386e6742423826299
- RichiardiLBelloccoRZugnaDMediation analysis in epidemiology: methods, interpretation and biasInt J Epidemiol20134251511151924019424
- RobinsJMGreenlandSEstimability and estimation of excess and etiologic fractionsStat Med1989878458592772444
- VanderWeeleTJChenYAhsanHInference for causal interactions for continuous exposures under dichotomizationBiometrics20116741414142121689079
- VansteelandtSVanderWeeleTJNatural direct and indirect effects on the exposed: effect decomposition under weaker assumptionsBiometrics20126841019102722989075
- Tchetgen TchetgenEJVanderweeleTJIdentification of natural direct effects when a confounder of the mediator is directly affected by exposureEpidemiology201425228229124487211
- VanderweeleTJVansteelandtSRobinsJMEffect decomposition in the presence of an exposure-induced mediator-outcome confounderEpidemiology201425230030624487213
- KalbfleischJLawlessJFThe analysis of panel data under a Markov assumptionJ Am Stat Assoc198580392863871
- KayRA Markov model for analysing cancer markers and disease states in survival studiesBiometrics19864248558652434150
- JacksonCHMulti-state models for panel data: the msm package for RJ Stat Softw2011388128
- WeltonNJAdesAEEstimation of Markov chain transition probabilities and rates from fully and partially observed data: uncertainty propagation, evidence synthesis, and model calibrationMed Decis Making200525663364516282214
- SiemiatyckiJThomasDCBiological models and statistical interactions: an example from multistage carcinogenesisInt J Epidemiol1981104382387
- ThompsonWDEffect modification and the limits of biological inference from epidemiologic dataJ Clin Epidemiol19914432212321999681
- OginoSChanATFuchsCSGiovannucciEMolecular pathological epidemiology of colorectal neoplasia: an emerging transdisciplinary and interdisciplinary fieldGut201160339741121036793
- OginoSNishiharaRVanderWeeleTJThe role of molecular pathological epidemiology in the study of neoplastic and non-neoplastic diseases in the era of precision medicineEpidemiology201627460261126928707
- RichiardiLBarone-AdesiFPearceNCancer subtypes in aetiological researchEur J Epidemiol201732535336128497292