 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Dissolution of protein macromolecules from poly(lactic-co-glycolic acid) (PLGA) particles is a complex process and still not fully understood. As such, there are difficulties in obtaining a predictive model that could be of fundamental significance in design, development, and optimization for medical applications and toxicity evaluation of PLGA-based multiparticulate dosage form. In the present study, two models with comparable goodness of fit were proposed for the prediction of the macromolecule dissolution profile from PLGA micro- and nanoparticles. In both cases, heuristic techniques, such as artificial neural networks (ANNs), feature selection, and genetic programming were employed. Feature selection provided by fscaret package and sensitivity analysis performed by ANNs reduced the original input vector from a total of 300 input variables to 21, 17, 16, and eleven; to achieve a better insight into generalization error, two cut-off points for every method was proposed. The best ANNs model results were obtained by monotone multi-layer perceptron neural network (MON-MLP) networks with a root-mean-square error (RMSE) of 15.4, and the input vector consisted of eleven inputs. The complicated classical equation derived from a database consisting of 17 inputs was able to yield a better generalization error (RMSE) of 14.3. The equation was characterized by four parameters, thus feasible (applicable) to standard nonlinear regression techniques. Heuristic modeling led to the ANN model describing macromolecules release profiles from PLGA microspheres with good predictive efficiency. Moreover genetic programming technique resulted in classical equation with comparable predictability to the ANN model.
Video abstract
Point your SmartPhone at the code above. If you have a QR code reader the video abstract will appear. Or use:
Introduction
Poly(lactic-co-glycolic acid) (PLGA) microparticles play a prominent role in many drug formulations. PLGA is flexible and has a satisfactory safety profile. It also has the ability to modify the drug dissolution profile for controlled-release formulations.Citation1 Moreover, the drug protective properties of PLGA were found to be suitable for unstable active pharmaceutical ingredients (APIs).Citation2 Therefore, PLGA has wide applications as an excipient.
PLGA can be formulated as films, discs, microcapsules, and nano- or microspheres.Citation3–Citation6 The current study is focused on the formulation of PLGA nano- and microspheres. One of the most studied properties of PLGA particles over the past years is the API release mechanism. There are often contradictory results reported in the literature, which demonstrate the high level of complexity of PLGA-based dosage forms. The drug release from the PLGA matrix is mainly governed by two mechanisms: diffusion and degradation/erosion.Citation7 The work of D’Souza and DeLucaCitation8 and Mollo and CorriganCitation9 showed that the drug release profile can be divided into two stages. Initially, the release is considered to be diffusion-controlled, corresponding to the low amount of released drug. Afterwards, the drug release is controlled primarily by the degradation and erosion of the PLGA matrix. There are many factors influencing the diffusion and degradation rate of PLGA. For example, pore diameters, matrix–API interactions, API–API interactions, and formulation composition;Citation10–Citation13 however, there is, to date, no versatile quantitative model describing the relationships among these factors in a consistent, mathematical manner. Recently, Fredenberg et al proposed four so-called “true” drug release mechanisms from PLGA matrices: 1) diffusion through water-filled pores; 2) diffusion through the polymer; 3) osmotic pumping; and 4) polymer erosion. The release profile of large and hydrophilic molecules, such as proteins and peptides, is mostly limited by diffusion through water-filled pores.Citation7
Over the past 2 decades, there have been several publications covering the model development of the drug release profile from PLGA microspheres. Among the most recognized are the works of Zygourakis and MarkenscoffCitation14 and Göpferich,Citation15 in which Monte Carlo and cellular automata microscopic models were introduced. The authors used a two-dimensional model of the polymer matrix based on the physicochemical characterization to predict erosion and therefore the release rate of small molecules. Later, Siepmann et al implemented a model coupling a Monte Carlo simulator with sets of partial differential equations.Citation16 The model described the chemical reactions and physical mass transport processes involved in erosion-controlled drug release from PLGA beads. Nevertheless, the predictability of classical models (empirical/semiempirical or mechanistic models) has not been thoroughly assessed in many studies and the versatility remains questionable.Citation14–Citation16 A recent study by Barat et alCitation17 applied Göpferich’s theoryCitation15 on multi-agent systems. Good agreement between modeling and experimental results was obtained for polymer erosion coupled with a partial differential equation model of lysozyme release profiles from PLGA spheres;Citation17 however, to the authors’ best knowledge, there is no general model able to predict the release rate of the various macromolecules from PLGA systems. Therefore, the design of the PLGA microsphere formulations loaded with macromolecules depends heavily on the trial-and-error approach.
The objective of this work was to demonstrate the cooperative use of feature selection, artificial neural networks (ANNs), and genetic programming (GP) to create a simple predictive model of the macromolecule dissolution rate from the PLGA dosage form, based on the gathered literature data.
Materials and methods
Data set
Data were collected from the literature. After careful screening of about 200 publications, release rates of 68 PLGA formulations from 18 publications were selected for data extraction (Supplementary material ). Selected PLGA formulations were prepared using four methods: 1) a double-emulsion water-in-oil-in-water solvent extraction process; 2) a solid-in-oil-in-water emulsion method; 3) an oil-in-oil solvent evaporation technique; and 4) a spray-drying process. Formulations included 14 model substances: bovine serum albumin; recombinant human erythropoietin; recombinant human epidermal growth factor; lysozyme; recombinant human growth hormone; hen ovalbumin; human serum albumin; beta-amyloid; insulin; recombinant human erythropoietin coupled with human serum albumin; L-asparaginase; bovine insulin; alpha-1 antitrypsin; and chymotrypsin. The release profiles presented in the literature were manually digitized, taking mean values of the observations if possible. Standard deviations and/or errors were not included due to the manual character of the digitization and lack of this information in some sources. Overall there were 745 data records with 320 variables (Supplementary material ). The independent parameters contained 319 inputs covering the formulation characteristics (PLGA inherent viscosity, PLGA molecular weight, lactide-to-glycolide ratio, inner and outer phase Polyvinyl alcohol (PVA) concentration, PVA molecular weight, inner phase volume, encapsulation rate, mean particle size, and PLGA concentration); the experimental conditions (dissolution pH, number of dissolution additives, dissolution additive concentration and production method, and dissolution time); and the molecular descriptors of the macromolecules and excipients. The molecular descriptors were computed using Marvin cxcalc plugin, UK (version 5.11; ChemAxon, Budapest, Hungary) for the drug substance as well as the excipients.Citation18 The amount of the drug substance released (Q) was the only dependent variable. Prior to feature selection, the initially obtained 319 inputs were further reduced to 300 inputs by removing all the null and missed input during the data set preprocessing procedure. The data set was then processed in several ways:
Noise addition to prevent models from over-fitting. The noised data records were produced numerically with ±5% amplitude for each variable value and two times more records number (noted in the text as “rand”),
Data set split according to the tenfold cross-validation scheme, with the aim of excluding all the data belonging to the particular formulation, thus simulating the real application of the model forced to predict the behavior of the unknown formulation (noted in the text and tables as “10cv”),
Linear scaling using either the output range of <0.2, 0.8> or <−0.8, 0.8>, in order to match nonlinear activation functions domains were used for ANNs only (noted in text and tables as “scale”).
Feature selection
It is considered state of the art to implement the feature selection technique prior to the actual modeling stage when dealing with multidimensional data sets. Two variable selection techniques were used to reduce redundant or irrelevant information gathered during data set preparation: based on the methodology proposed by Żurada et alCitation19 with further modification by Mendyk and Jachowicz,Citation20 which uses ANNs trained with the back propagation algorithm as the modeling tools; and feature ranking created by the fscaret package of the R environment (The R Foundation for Statistical Computing, Vienna, Austria).Citation21,Citation22
The main parameters of the applied techniques are listed in . The resulting feature rankings were then inspected on the substantial decrease of variable significance; two cutoff points were chosen for each method.
Table 1 Feature selection parameters used in the assay according to applied methods for artificial neural networks and fscaret
ANNs
Based on reduced vectors of inputs, two types of ANN model were obtained, namely, multi-layer perceptron artificial neural networks (MLP-ANNs) and monotone multi-layer perceptron artificial neural networks (MON-MLP) networks. The tools used during modeling were the Nets2012 ANNCitation23 simulator (developed in-house, Aleksander Mendyk, Jagiellonian University, Krakow, Poland), and R environment with the monmlpCitation24 package for MON-MLP networks.Citation23,Citation24 MLP-ANNs and MON-MLP were trained on reduced vectors after feature selection procedure.
MLP-ANNs
MLP-ANNs used the backpropagation training algorithm and were tested with activation functions such as linear (“lin”), logistic (“sigma”), hyperbolic tangent (“tanh”), and logarithmic function (“fsr”). The architecture of MLP-ANNs comprised one to seven hidden layers. In addition to the MLP-ANNs, neuro-fuzzy systems (NFs) were employed by adapting the simplest Mamdani type and contained from five to 100 nodes in the hidden layer. All models were multiple input/single output (MISO) type.Citation25 Considering a tenfold cross-validation, a total of 3,680 models were trained in a single run. Each model was trained up to 10,000,000 epochs with several stop points. The generalization error was assessed in order to find the most optimal training conditions. The stop points were selected as 100,000, 200,000, 500,000, 1,000,000, 1,500,000, 2,000,000, 3,000,000, 5,000,000, and 10,000,000 epochs. The epoch size was equal to 1. Other parameters were as follows:
momentum technique, with the momentum factor 0.3,
delta-bar-delta algorithm, with the initial learning factor 0.65,
jog-of-weights technique designed to prevent getting stuck in the local minima of the cost function; a simple noise addition to the weights was performed when the ANN was not improving its efficiency during the 100,000 epochs (the patience criterion).
The root-mean-square error (RMSE) was used to measure the goodness of fit and was calculated according to EquationEquation 1[1] ; additionally, relative RMSEs (relRMSEs) for each dissolution profile were calculated (EquationEquation 2
[2] ).
where obsi, predi = observed and predicted values respectively, i = data record number, and n = total number of records.
where RMSEi = RMSE for formulation i and Qmax and Qmin = maximum and minimum percentage of released molecule, respectively.
MON-MLP
MON-MLP networks were created and trained by the “monmlp.fit” function of the monmlp R package.Citation24 Bootstrap aggregation was used to avoid over-fitting of models. All models consisted of two hidden layers with three to 32 nodes per layer. Two transfer functions for hidden layer modification of hyperbolic tangent (“tansig”) and for output layer linear function were applied in each model. The prepared ensemble system consisted of ten or 20 neural networks. Performance of the models was assessed using RMSE. Other parameters were as follows:
“trials” function, set to 5, was used to avoid local minima in ensemble,
Iteration number for learning models was set to 100, 500, 1,000, or 2,000.
GP and symbolic regression
Mathematical equations were produced by means of GP and the symbolic regression mode available in the rgp package of the R environment.Citation26 Direct mapping of the input and output variables was applied. GP was performed on reduced input vectors after the feature selection procedure.
The parameters of the function “symbolicRegression” of the rgp package were set as follows:
“individualSizeLimit” (the chromosome length) varied from 10 to 300 and was the subject of the optimization in regard to the RMSE (EquationEquation 1
[1] ),
“populationSize” was set to 10,000,
“myfunctionSet,” a set of prototype functions, was restricted to the simplest arithmetic operators like addition, subtraction, multiplication, and division, together with power, natural logarithm, square root, and exponent function,
the algorithm stop condition makeFitnessStopCondition (RMSE) was equal 1.0,
“makeTimeStopCondition” was set to 1 hour for the indirect and 120 hours for the direct modeling mode.
The direct mapping approach applied GP on the original data set to create functional relationships between the amount of the macromolecule released (Q) and the vector of parameters containing the time variable (t), formulation characteristics, and molecular descriptors.
Although GP provides the model with optimized values of its parameters, to achieve better generalization, the multivariate optimization of equation parameters was applied using the optimx package (The R Foundation for Statistical Computing).Citation27
Parameters used for the “optimx” function were:
“par” – initial value for the parameters was set to 0.1,
“all.methods” was set to “true”, which means that all available (and suitable) methods were used,
“follow.on” was set to “false.” All optimization methods were used separately.
Fitting was performed in the mode of tenfold cross-validation. The latter procedure was done with the same training/testing data sets as for MLP and MON-MLP ANNs in order to compare the two systems’ generalization abilities. The selection criterion for the parameters was the model goodness of fit expressed as the RMSE obtained on the training data set.
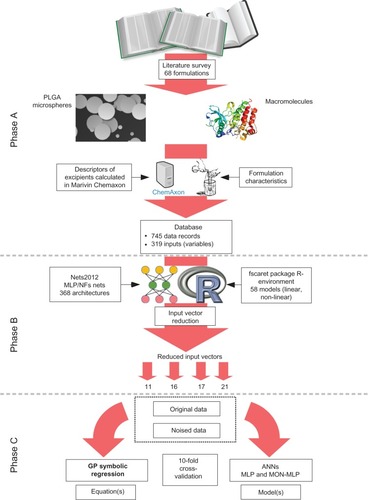
The outline of the workflow, in conjunction with some of the results of feature selection, is presented in .
Figure 1 Schematic representation of the experimental setup.
Notes: Data acquisition (Phase A). Data preprocessing (Phase B). Modeling (Phase C).
Abbreviations: ANNs, artificial neural networks; GP, genetic programming; MLP, multi-layer perceptron artificial neural networks; MON-MLP, monotone multi-layer perceptron artificial neural networks; NFs, neuro-fuzzy systems; PLGA, poly(lactic-co-glycolic acid).
Hardware environment
All calculations were performed using 21 professional workstations equipped mainly with Xeon central processing units (Intel Corporation, Santa Clara, CA, USA) with a total of 120 cores and at least 16 GB of RAM operating on the openSUSE 12.3 (x86_64) operating system (SUSE, Nürnberg, Germany).
Results and discussion
Feature selection
According to the feature ranking created by ANNs and fscaret, four reduced input vectors containing 21, 17, 16, and eleven independent variables were selected. The resulting input vectors for 17 and eleven independent variables, which yielded the best results for GP and ANNs, respectively, are shown in and . They originate from two different feature-ranking methods and gave the lowest RMSE when applied to ANNs and GP. Evaluation of the input vector was based on the generalization error (RMSE). A substantial reduction of RMSE from 22.8% (ANN models trained on tenfold cross-validation with all 300 inputs) to 15%–18% was obtained for all four reduced input vectors ( and ). Further attribute reduction applied to reduced vectors was unsuccessful, giving about 2%–3% higher generalization errors in each case.
Table 2 Reduction to 17-variable input vector
Table 3 Reduction to eleven-variable input vector
Table 4 Artificial neural network–MLP results, according to the lowest root-mean-square error SE obtained
Table 5 MON-MLP results, according to the lowest root-mean-square error SE obtained
Reduced input vectors mostly consisted of formulation characteristics, which is consistent with previous publications stating that the method of preparation and parameters describing the particles, influence in great extent the drug dissolution rate from the PLGA particles.Citation1,Citation4,Citation7 Sandor et al stated that the release rate of proteins is dependent on the protein molecular weight;Citation28 however, distance-based geometry properties coded as hyper-Wiener index and Szeged index were not discussed in the literature.
ANNs
The best result obtained using the ANN modeling tools had a relRMSE of 15.4% for MON-MLP networks with a vector consisting of eleven inputs ( and ).
Although the generalization error of the ANN models was about 15%–18%, the relRMSE (related to single formulation) of the best MON-MLP model range was from 1.75% to 36.03% between formulations, indicating that there is good potential for further improvements. To accomplish this task, the data set should be enriched with other crucial parameters influencing the dissolution, such as the porosity of particles, pore diameters, chemical descriptors of polymer, and particle size of the excipients. Unfortunately, data were not available or scant in the selected publications, therefore not useful for systematic quantitative analysis. As a consequence, the model has inferior performance when compared to classical models, although it is important to note that all the predictive model generalization errors were a result of the tenfold cross-validation procedure, which is not the case in classical approaches.Citation7–Citation9,Citation14,Citation15 Moreover, our models are universal in terms of the drug encapsulated in PLGA microspheres, whereas most of the classical models are focused on a limited and/or predefined number of drugs.Citation1,Citation4,Citation5,Citation7,Citation9
Symbolic regression
Obtained using GP classical equation, though complicated and derived from a database consisting of 17 inputs, not symbolic regression but equation yielded better generalization error (14.3%) and narrower relRMSE, ranging from 4.76% to 32.83% between formulations, in comparison to the MON-MLP model. The equation was characterized by four parameters (EquationEquation 3[3] ). Moreover, during the evolution process, the GP algorithm further reduced the number of necessary variables by eliminating input numbers 2, 4, 9, 10, 12, 13, 15, and 16. The simplified mathematical model still retained all the types of input variables (with one exception of the production method), yet its predictive performance was comparable to the more complex MON-MLP model ( and Supplementary material [full results]).
Table 6 The results of the formulation-to-formulation relRMSE (%)
in which In1–In17 correspond to labels in and C1–C4 = constants. Equation parameters: C1 =0.1382595046751, C2 =0.1063092562504, C3 =4.3209748739209, and C4 =0.3010676275288.
Due to the lack of data, only 68 formulations and 14 model substances were included. Nonetheless, since our model is based on the molecular descriptors, it is able to predict the behavior of a completely unknown drug substance. An example of such accurate prediction is formulation 54 (MON-MLP model relRMSE 7.6%, GP relRMSE 10.2%, molecule recombinant human erythropoietin coupled with human serum albumin []).
Figure 2 Comparison of predicted versus observed values for two best models (MON-MLP and classical equation).
Note: Data from the gathered database ().
Abbreviations: GP, genetic programming; MLP, multi-layer perceptron artifical neural networks; MON-MLP, monotone multi-layer perceptron neural networks; relRMSE, relative root-mean-square error.
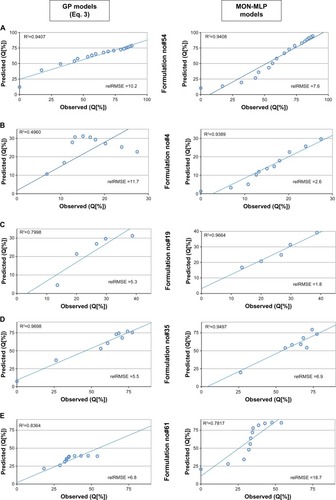
In general, when considering the relRMSE of formulations, almost 60% of the release profiles had a relRMSE less than 15% when the MON-MLP model was applied. Moreover, the equation obtained by GP yielded 64% of profiles with a rel-RMSE less than 15%. Formulation-to-formulation comparison indicates that ten formulations yielded a relRMSE below 10%. It is important to note that those formulations consisted of medium-to-large molecules with a molecular weight ranging from 14.2 kDa (lysozyme) to 66.5 kDa (bovine serum albumin). Formulations that have a relRMSE of more than 30% could be perceived as outliers, with two formulations consisting of a relatively small molecule of bovine insulin (5.8 kDa).
It has been observed that, in some cases, the GP model yielded better predictions than MON-MLP, and vice versa (). The GP model had over- or underestimated the initial burst of molecule release () and the end-point release (), while the midpoints of release profiles were in good accordance with the observed data. In contrast, for the MON-MLP models, even if it yielded worse generalization error, the shapes of the predicted profiles were preserved for most formulations ().
Based on the exploratory analysis of the modeling results, it could be concluded that the GP models are inferior in the presence of recombinant human epidermal growth factor and human serum albumin, showing much higher errors (Supplementary material and ), whereas the MON-MLP model responded poorly to the presence of beta-amyloid, L-asparaginase and bovine insulin (). Moreover, if the value of the variable “mean particle size” is above 20 μm, the GP model predictions are most likely poor () and, in the case of the MON-MLP model, the values below 1 μm yielded worse predictions. The above presents limitations of our model, which will be a subject of its development in the future. Due to the heuristic nature of the models, it is difficult to explain all the unexpected behaviors of the models, such as the erratic profile seen in , where the MON-MLP model creates a completely opposite profile at the time of 20 days. Thus we wanted to present our analysis of the models and their advantages (generic for the molecule) versus disadvantages (limitations of predictions) in order to allow every user to understand their applicability. The predicted versus observed release profiles of discussed formulations are presented in , with the “observed” data derived from the literature.Citation29–Citation33
Conclusion
In this paper, a new approach was presented for modeling the dissolution of macromolecules from PLGA particles. It was also shown which aspects of the method of production coupled with molecular description of the formulation have the most impact on the release rate. Heuristic modeling techniques showed their usefulness in the complex and still not fully understood process of dissolution from PLGA particles. Moreover, they led to the mathematical formula (EquationEquation 3[3] ) describing the process with predictive efficiency comparable to the ANN models.
With predictive modeling, knowledge extraction was performed simultaneously as a part of the modeling protocol. The major procedure employed feature selection techniques for reduction of input vector. A successful reduction from an initial 300 to 17 and eleven provided both information about the analyzed problem and appropriate generalization ability of MON-MLP and mathematical model, avoiding the well-known problem of “curse of dimensionality.” Analysis of crucial variables confirmed the dominating role of PLGA formulation characteristics; however, geometric characteristics of protein molecules and plasticizer ionic descriptor were also found to be important features. Analysis of the selected variables is a direct source of knowledge and a possible hint for creating a more general theory of how macromolecules are released from the PLGA particles.
This work was possible thanks to the application of two key elements:
Marvin, a cheminformatic tool, which allowed direct computation of macromolecule descriptors – an ability not present in every cheminformatic package;Citation18 and
heuristic modeling tools for feature selection and predictive modeling integrating various types of information into the single model.
The resulting models are versatile in terms of prediction of the unknown macromolecule release profiles from the PLGA particles, thus it might be useful for the future development of PLGA microparticles as a decision support system.
Acknowledgments
This work was funded by Poland-Singapore bilateral cooperation project no 2/3/POL-SIN/2012 and IPROCOM Marie Curie Initial Training Network project no 316555.
Supplementary material
Table S1 List of publications used in data extraction
Table S2 Full data base used in the study
Table S3 The results of the formulation-to-formulation relRMSE (%)
Disclosure
The authors report no conflicts of interest in this work.
References
- MakadiaHKSiegelSJPoly lactic-co-glycolic acid (PLGA) as biodegradable controlled drug delivery carrierPolymers (Basel)201131377139722577513
- DanhierFAnsorenaESilvaJMCocoRLe BretonAPréatVPLGA-based nanoparticles: an overview of biomedical applicationsJ Control Release2012161250552222353619
- HouchinMLToppEMPhysical properties of PLGA films during polymer degradationJ Appl Polym Sci200911428482854
- WangJNgCWWinKYRelease of paclitaxel from polylactide-co-glycolide (PLGA) microparticles and discs under irradiationJ Microencapsul200320331732712881113
- HamishehkarHEmamiJNajafabadiARPharmacokinetics and pharmacodynamics of controlled release insulin loaded PLGA microcapsules using dry powder inhaler in diabetic ratsBiopharm Drug Dispos2010312–318920120238376
- DeSRobinsonDHParticle size and temperature effect on the physical stability of PLGA nanospheres and microspheres containing BodipyAAPS PharmSciTech200454e5315760050
- FredenbergSWahlgrenMReslowMAxelssonAThe mechanisms of drug release in poly(lactic-co-glycolic acid)-based drug delivery systems – a reviewInt J Pharm2011415345221640806
- D’SouzaSSDeLucaPPDevelopment of a dialysis in vitro release method for biodegradable microspheresAAPS PharmSciTech200562E323E32816353991
- MolloRCorriganOIAn investigation of the mechanism of release of the amphoteric drug amoxycillin from poly(D,L-lactide-co-glycolide) matricesPharm Dev Technol2002733334312229265
- KangJSchwendemanSPPore closing and opening in biodegradable polymers and their effect on the controlled release of proteinsMol Pharm2007411041817274668
- BlancoMDAlonsoMJDevelopment and characterization of protein-loaded poly(lactide-co-glycolide) nanospheresEur J Pharm Biopharm1997433287294
- KangJLambertOAusbornMSchwendemanSPStability of proteins encapsulated in injectable and biodegradable poly(lactide-co-glycolide)-glucose millicylindersInt J Pharm20083571–223524318384984
- MainardesRMEvangelistaRCPLGA nanoparticles containing praziquantel: effect of formulation variables on size distributionInt J Pharm20052901–213714415664139
- ZygourakisKMarkenscoffPAComputer-aided design of bioerodible devices with optimal release characteristics: a cellular automata approachBiomaterials19961721251358624389
- GöpferichAMechanisms of polymer degradation and erosionBiomaterials19961721031148624387
- SiepmannJFaisantNBenoitJPA new mathematical model quantifying drug release from bioerodible microparticles using Monte Carlo simulationsPharm Res2002191885189312523670
- BaratACraneMRuskinHJQuantitative multi-agent models for simulating protein release from PLGA bioerodible nano- and microspheresJ Pharm Biomed Anal200848236136818436414
- Marvin ChemAxon (http://www.chemaxon.com)Accessed 10, Jan 2013
- ŻuradaJMMalinowskiAUsuibSPerturbation method for deleting redundant inputs of perceptron networksNeurocomputing199714177193
- MendykAJachowiczRUnified methodology of neural analysis in decision support systems built for pharmaceutical technologyExpert Syst Appl20073211241131
- SzlękJThe fscaretAutomated feature selection using variety of models provided by caret package Available from: http://cran.r-project.org/web/packages/fscaret/index.htmlAccessed Jun 2013
- R Core TeamR: a language and environment for statistical computingVienna: The R Foundation for Statistical Computing Available from: http://www.R-project.org/Accessed 1, Jun 2013
- MendykATuszyńskiPKPolakSJachowiczRGeneralized in vitro-in vivo relationship (IVIVR) model based on artificial neural networksDrug Des Devel Ther20137223232
- CannonAJmonmlp: Monotone multi-layer perceptron neural network [webpage on the Internet] Available from: http://cran.r-project.org/web/packages/monmlp/index.htmlAccessed Jun 2012
- YagerRRFilevDPEssentials of Fuzzy Modeling and ControlNYJohn Wiley & Sons1994
- FlaschOMersmannOBartz-BeielsteinTStorkJZaeffererMrgp: R genetic programming framework [webpage on the Internet] Available from: http://CRAN.R-project.org/package=rgpAccessed 1, Jun 2013
- NashJCVaradhanRUnifying optimization algorithms to aid software system users: optimx for RJ Stat Softw201143911422003319
- SandorMEnscoreDWestonPMathiowitzEEffect of protein molecular weight on release from micron-sized PLGA microspheresJ Control Release200176329731111578744
- HeJFengMZhouXStabilization and encapsulation of recombinant human erythropoietin into PLGA microspheres using human serum albumin as a stabilizerInt J Pharm20114161697621699969
- KangFSinghJEffect of additives on the release of a model protein from PLGA microspheresAAPS PharmSciTech2001243014727867
- BlancoDAlonsoMJProtein encapsulation and release from poly(lactide-co-glycolide) microspheres: effect of the protein and polymer properties and of the co-encapsulation of surfactantsEur J Pharm Biopharm19984532852949653633
- BuskeJKönigCBassarabSLamprechtAMühlauSWagnerKGInfluence of PEG in PEG-PLGA microspheres on particle properties and protein releaseEur J Pharm Biopharm2012811576322306701
- JiangHLJinJFHuYQZhuKJImprovement of protein loading and modulation of protein release from poly(lactide-co-glycolide) microspheres by complexation of proteins with polyanionsJ Microencapsul200421661562415762319