
Abstract
Purpose
This study aims to enhance the clinical use of automated sleep-scoring algorithms by incorporating an uncertainty estimation approach to efficiently assist clinicians in the manual review of predicted hypnograms, a necessity due to the notable inter-scorer variability inherent in polysomnography (PSG) databases. Our efforts target the extent of review required to achieve predefined agreement levels, examining both in-domain (ID) and out-of-domain (OOD) data, and considering subjects’ diagnoses.
Patients and Methods
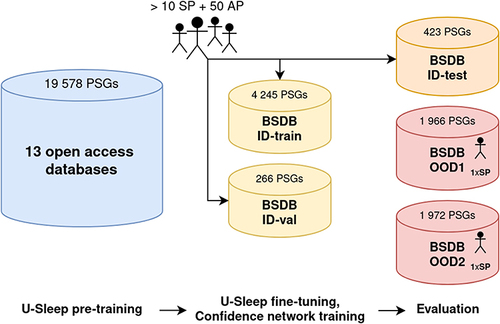
A total of 19,578 PSGs from 13 open-access databases were used to train U-Sleep, a state-of-the-art sleep-scoring algorithm. We leveraged a comprehensive clinical database of an additional 8832 PSGs, covering a full spectrum of ages (0–91 years) and sleep-disorders, to refine the U-Sleep, and to evaluate different uncertainty-quantification approaches, including our novel confidence network. The ID data consisted of PSGs scored by over 50 physicians, and the two OOD sets comprised recordings each scored by a unique senior physician.
Results
U-Sleep demonstrated robust performance, with Cohen’s kappa (K) at 76.2% on ID and 73.8–78.8% on OOD data. The confidence network excelled at identifying uncertain predictions, achieving AUROC scores of 85.7% on ID and 82.5–85.6% on OOD data. Independently of sleep-disorder status, statistical evaluations revealed significant differences in confidence scores between aligning vs discording predictions, and significant correlations of confidence scores with classification performance metrics. To achieve κ ≥ 90% with physician intervention, examining less than 29.0% of uncertain epochs was required, substantially reducing physicians’ workload, and facilitating near-perfect agreement.
Conclusion
Inter-scorer variability limits the accuracy of the scoring algorithms to ~80%. By integrating an uncertainty estimation with U-Sleep, we enhance the review of predicted hypnograms, to align with the scoring taste of a responsible physician. Validated across ID and OOD data and various sleep-disorders, our approach offers a strategy to boost automated scoring tools’ usability in clinical settings.
Introduction
Sleep, often dubbed as the third pillar of health alongside diet and exercise, plays a critical role in our well-being. Polysomnography (PSG), a comprehensive sleep monitoring technique, captures detailed biosignals – primarily the electroencephalogram (EEG), the electrooculogram (EOG), and the electromyogram (EMG). Adhering to guidelines of American Academy of Sleep Medicine (AASM),Citation1 physicians score PSG recordings into specific sleep stages, on 30-second windows (epochs). Such structured scoring, called hypnogram, divides sleep into five distinct stages: W, REM, N1, N2, and N3, each representing a unique physiological state.Citation2 The proportions of sleep stages, as well as patterns in their transitions, are basic indicators of sleep health,Citation3,Citation4 and also biomarkers of certain disorders.Citation5–7
While manual scoring remains the gold standard, the procedure may be labor-intensive, often demanding up to 2 hours for a comprehensive evaluation of a single PSG recording.Citation8 Research into automatic sleep scoring, which aims to support the manual scoring of physicians by computational algorithms, dates back to the 1960s.Citation9 Recent advancements in Artificial Intelligence (AI) have significantly improved automatic scoring solutions, especially those based on Machine and Deep Learning (ML/DL) methodologies. Notably, the U-Sleep algorithm introduced by Perslev et al,Citation10 and further investigated by Fiorillo & Monachino et al,Citation11 stands at the forefront due to its balance between performance rivaling human scorers and the diversity of its training data.
Supervised automated sleep scoring algorithms can reach considerable performance but are to-date not able to overcome an intrinsic problem. The different interpretations of AASM scoring standards by physicians result in an inter-scorer agreement of about 76%.Citation12–14 This human-based variability in the annotations introduces approximately 20% noise-level, technically limiting the performance of scoring algorithms optimized in a supervised way, as the ability of an AI algorithm can hardly be better than the quality of its training data. Consequently, despite the breadth of training databases available, the ceiling for ML/DL model generalizability is limited by this prevailing inter-scorer agreement. Therefore, despite the technological advancements AI has brought to sleep scoring, physicians – who are still irreplaceable and responsible for clinical decisions – must subject the predicted hypnograms to a thorough review and compare whether the algorithm-proposed predictions are consistent with their personal interpretation of patterns present in the original PSG biosignals. While some level of error in sleep-scoring models is deemed clinically acceptable,Citation15 the review process of predicted hypnograms can be time-consuming and costly. Specifically, if physicians lack prior insights into problematic segments of the biosignal, the review might be as resource-intensive as conducting manual scoring without any algorithmic assistance.
Given the limits posed by inter-scorer variability, a subset of research has pivoted towards quantifying prediction uncertainty to elevate model performance by enabling review of the least confident predictions. Such semi-automated approaches combining predictions proposed by algorithms with physician’s expertise represent a promising solution for integration of sleep scoring tools in clinical settings.Citation9 Van Gorp et al delved into the theoretical aspects of such (un)certainty.Citation16 Kang et al advanced this notion by proposing an uncertainty detection mechanism via Shannon’s entropy of the softmax output of a statistical classifier.Citation17 By allowing physicians to correct uncertain predictions, they managed to substantially enhance the agreement (K-score) between classifier and physician’s scoring taste. In the realm of DL-based algorithms, Fiorillo et al employed a query procedure targeting a predetermined percentage of the most uncertain predictions based on the maximum and variance of the softmax output.Citation18 Hong et al presented a novel method, Dropout-Correct-Rate, and showcased its potential to boost model performance with targeted human review.Citation19 Meanwhile, Phan et al utilized a transformer-based sleep scoring model and identified uncertain epochs through normalized entropy scores, demonstrating that a substantial fraction of misclassified predictions were within the most uncertain epochs.Citation20 Most recently, Rusanen et al evaluated several softmax-based measures of aSAGA, a convolutional neural classifier, and reported effective identification of predictions in the mismatch to the consensus-scoring of 5 scorers.Citation21
The integration of sleep-scoring algorithms into clinical practice demands a deep understanding of the physician’s real needs and expectations. However, these are seldom considered in existing work, which approaches this problem in isolation from the human experts. Our study builds upon the U-Sleep algorithm, a state-of-the-art DL-based sleep scoring model trained on a broad spectrum of open-access clinical databases. Considering the intrinsic limitations of sleep scoring, rather than just aiming to improve the model’s epoch-wise performance, which might already be at its ceiling level due to the inter-scorer variability, our study seeks to integrate this established system in a manner that actively involves physicians.
By investigating various strategies for pinpointing the least confident predictions and streamlining their review, we aim to redefine the collaboration between sleep-scoring algorithms and clinicians. Utilizing clinically rich Berner Sleep Data Base (BSDB),Citation22 we systematically investigate (i) the optimal strategies to gather uncertain sleep stage predictions for the physicians’ review and based on that we (ii) quantify the volume of predictions that need to be reviewed (ie, physician’s effort) to reach certain agreement benchmarks. Leveraging details on physicians involved in scoring of individual BSDB PSGs, we robustly assess the efficacy of our combined system integrating the sleep-scoring algorithm with uncertainty estimation, considering both in-domain (ID), and potentially more challenging out-of-domain (OOD) test data.
Semi-automated approaches for sleep staging have been explored in various modalities and frameworks.Citation9,Citation16–21 However, comprehensive testing of these methods against their limitations has been relatively sparse. To the best of our knowledge, our study is the first one extensively addressing a wide range of challenges specific to semi-automated scoring. This includes an in-depth examination and adaptation to individual scoring tastes of single (OOD) physicians, the impact of different sleep-disorder diagnoses on our approach’s validity, the metrics employed, as well as the dimensions and diversity of the datasets involved.
Materials and Methods
Dataset
For our primary evaluations, we exploited the Berner Sleep Data Base (BSDB) from our partner clinic, Inselspital, University Hospital Bern. A total of 8832 PSGs have been collected from 2000 to 2021 on individuals covering the whole spectrum of age (0–91 years), sleep disorders, as well as healthy controls. The signals were recorded at 200 Hz and, across 20 years of data collection, scored manually by more than 10 senior and 50 assistant physicians according to the AASM rules. To match older recordings scored according to Rechtschaffen and Kales with AASM standard, the N3 and N4 stages were merged into a single-stage N3. Secondary usage of the dataset was approved by the local ethics committee (KEK-Nr. 2020–01094). Participants provided written general consent upon its introduction at Inselspital in 2015, and data were maintained with confidentiality. Most individuals underwent PSG due to the suspicion of a sleep disorder. Together 66 individuals represented healthy subjects that took part as controls in clinical trials. The BSDB provides various levels of diagnoses based on individual tests (eg, actigraphy- or PSG-based). For our evaluations, we considered the clinically most relevant conclusive diagnoses made by physicians considering all test-based diagnoses, clinical anamnesis, and the context. The amount of available conclusive diagnoses is compared to the test-based ones smaller but provides the most reliable and highly trustworthy information.
For the purpose of our research, we divided the BSDB into three parts: one in-domain (ID) subset – consisting of training, validation, and test data splits consisting of PSGs, each scored by one of >50 physicians – used for optimization and baseline evaluation of the algorithmic approaches adopted – and, utilizing the information about the scorers, we created two out-of-domain (OOD) held-out subsets, each containing PSGs scored by a unique senior physician not presented in ID data with potentially different “scoring taste” than the population of ID-included physicians. Hence, such stratified evaluations on OOD subsets represent a more robust generalizability assessment close to the scenario happening in clinics, where typically a single physician takes decisions (eg, about scoring, diagnosis). As one patient can have multiple PSGs recorded, all data splits were done per subject, assuring that the individual’s data are present only in one subset. A summary of data splits with respect to the number of PSGs, physicians involved, and demographic characteristics of subjects is provided in . Moreover, provides details on the occurrence of different classes of sleep disorders among conclusive diagnoses of subjects.
Table 1 Demographic Characteristics of BSDB Subjects with Respect to Individual Data Splits
Table 2 Occurrence of Different Classes of Sleep Disorders Among Conclusive Diagnoses of Subjects per Individual Data Splits of BSDB
In addition to BSDB, part of our work replicated the training of the sleep-scoring algorithm U-Sleep, using 19,578 PSGs from 13 open-access databases. A detailed description of these data, including demographic characteristics, is provided in the original publication.Citation11
U-Sleep: The Sleep Scoring Algorithm
The U-Sleep, introduced by Perslev et al,Citation10 is a deep convolutional neural network for sleep stage classification inspired by the U-Net, an architecture originally used for image segmentation.Citation23 The U-Sleep takes as its input at least one pair of EEG-EOG channels (re)sampled at 128 Hz and outputs an array of softmax values quantifying the plausibility of each signal window (epoch) of a specified length, usually 30 seconds, to represent one of the 5 sleep stages. If more input channel-pairs are available, the U-Sleep averages the softmax outputs over all of them. The architecture of U-Sleep consists of an encoder-decoder part – compressing and decompressing the input signal using convolutional operations – followed by a classifier layer.
In-depth technical details on the U-Sleep architecture, including the preprocessing steps implemented to unify signals from different devices, and the training process, are thoroughly described in the original work.Citation10 This study also reports the state-of-the-art performance on 16 databases of more than 15,000 participants, achieving an average F1-score of 79%. The robustness of U-Sleep was confirmed even after its original implementation was corrected for a channel-derivation bug, achieving an average F1-score of 76.5%.Citation11
Our work replicated the training run on 13 open-access databases of 19,578 PSGs using the most recent implementation of U-Sleep.Citation11 Based on that, we exploit the rich BSDB and fine-tune (re-train) the U-Sleep using training and validation ID-splits as described in . Finally, we use such fine-tuned U-Sleep as a basis for the selection of the most suitable approach of uncertainty estimation to enable an efficient review of predicted hypnograms by physicians. The generalizability of both sleep scoring and predictive uncertainty-quantification approaches were rigorously evaluated on the ID test set and two single-scorer OOD subsets of the BSDB.
Estimation of Predictive Uncertainty
In advancing sleep scoring algorithms for clinical practice, one crucial component is the quantification of predictive uncertainty, which encompasses both epistemic and aleatoric aspects. Epistemic uncertainty, in a sleep-scoring context, arises from the variability in how physicians interpret AASM guidelines, leading to ~20% noise in sleep-stage labels due to ~80% inter-scorer agreement. On the other hand, aleatoric uncertainty, inherent in the variability of sleep patterns themselves, represents a natural randomness that cannot be mitigated.
In this section, we elaborate on our approach with the U-Sleep classifier. First, we detail measures of predictive uncertainty based on the classifier’s softmax output. Next, we describe adapting an auxiliary confidence network, specifically designed for sleep-related time-series representations derived from the U-Sleep, to estimate confidence in its predictions. The terms uncertainty and confidence can be understood as complementary and will be used according to the appropriateness of the context. The integration of uncertainty quantification is pivotal not only in elevating the trustworthiness of the automated sleep-scoring solutions but also in enabling physicians to efficiently review and verify algorithm-proposed predictions.
Softmax-Based Measures
The confidence level of a classifier’s predictions can be gauged from its softmax output, which can be graphically represented as hypnodensity.Citation24 This can be analyzed either visually or, when uncertain epochs should be automatically gathered, by numerical assessment of the softmax values. At its simplest, the maximum value of the predicted softmax can be perceived as a representation of the epoch’s likelihood of belonging to a specific class (ie, sleep-stage). The closer the max-softmax is to 1, the higher the confidence, while lower values indicate uncertainty. There are a variety of measures, rooted in softmax outputs, that can be employed to discern these uncertainties. For instance, several works employed entropy-based measures because as entropy rises, the distribution of softmax values becomes more uniform.Citation17,Citation20,Citation21
Regardless of the chosen measure, uncertain predictions from each predicted hypnogram can be highlighted in two ways: (i) by showcasing a fixed percentage of the most uncertain epochs or (ii) by indicating epochs that surpass a specific value threshold. The latter is more advocated as it may consider the sampling distribution of classification accuracy. Moreover, the fixed-percentage approach has greater potential to introduce undesired results (false positives/negatives) if the predetermined percentage does not coincide with the actual amount of misclassified epochs. In our research, we sought methods that adeptly identify uncertain predictions for subsequent review by clinical experts. A comprehensive mathematical detailing of all measures employed in our work is provided in , whereas a comparison in terms of their ability to discern predictions discordant with human scoring is presented in Results.
Table 3 Measures Evaluating Prediction’s Uncertainty Using U-Sleep Softmax Output
Uncertainty Quantification Using an Auxiliary Confidence Network
Neural networks, while powerful, often exhibit overconfidence, manifested as a disparity between the predicted softmax value and the actual probability of an observation belonging to a specific class.Citation25 This may limit the use of softmax-base measures to gather uncertain predictions accurately. To counteract this issue, Corbiere et al proposed an auxiliary confidence network, which aims to estimate the True Class Probability (TCP) score, designed to work in tandem with an already-trained classifier network.Citation26 The TCP is defined as the value of the predicted softmax that aligns with the true label, meaning, for misclassified predictions, it diverges from the softmax maximum value. Upon the completion of classifier training, the TCP scores are extracted from training and validation data and serve as a target for the confidence network. This positions the training of the confidence network as a regression problem, where the objective is to predict the TCP – a single float value within the (0, 1) range – for each observation. In the original work, the confidence network was applied to image data, supplementing a convolutional network classifier, which involved reusing the classifier’s architecture and its pre-trained weights, adding additional layers to facilitate the prediction of the TCP outcome, and finally optimizing the modified architecture.Citation26
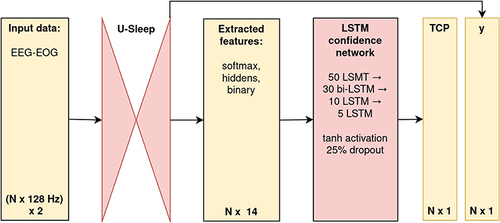
Our contribution extends this idea specifically to PSG time-series data. Leveraging the U-Sleep output, we designed a lightweight sequence-to-sequence long-short-term-memory (LSTM) confidence network.Citation27 For each EEG-EOG input channel-pair of U-Sleep, our confidence network is fed by representations extracted from U-Sleep layers, including the 5-dimensional softmax output, the binary code of the same dimensionality as softmax indicating the predicted class, and the five-dimensional hidden features extracted from the layer preceding the softmax. The adoption of a bidirectional-LSTM-based architecture was driven by our beliefs that the uncertainty in predicting sleep stages is intrinsically tied to sequential information – namely, the representations preceding and succeeding a given epoch. Recognizing the functional dependencies in the softmax output (that sums up to 1), we applied to it the additive log-odds ratio (ALR) transformation, which reduces the dimension by one (ie, to 4) and decreases the co-linearity.Citation28 Building on the premise that combined data offers a richer perspective for identifying the most uncertain predictions, we fed the confidence network with all such extracted features simultaneously. The final architecture of our confidence network had 35,628 parameters and consisted of three main parts: an input layer with batch normalization; 4 hidden layers (LSTM of 50 neurons, bidirectional-LSTM of 30 neurons enabling information flow from the past as well as future states, two LSTMs of 10 and 5 neurons) returning sequences, with tanh activation function and 25% drop-out; and a final layer with an output LSTM neuron with the custom activation function, (tanh(x)+1)/2, returning a sequence in desired (0, 1) range, corresponding to the predicted sequence of TCP confidence scores for each PSG-epoch. These are then, consistent with U-Sleep’s mechanism, averaged across all input channel-pairs used.
The TCP confidence score using a more complex input information processed by a specifically designed neural network extended the set of rather simpler softmax-based measures. Our evaluations focused on their in-depth comparison in terms of identifying U-Sleep-predicted epochs that do not align to the physician’s scoring, forming a basis for creating a system that allows physicians to effectively utilize automatic sleep scoring algorithms.
Utilizing Uncertainty Estimates for an Efficient Review of Predicted Hypnograms
Our analysis, tailored towards the efficient use of uncertainty estimates for the review of predicted hypnograms, was guided by a three-tiered evaluation approach: (i) selection of the best-suited uncertainty measure; (ii) statistical evaluations of its discriminative power; and (iii) the impact-evaluation when physicians rescore the most uncertain predictions gathered. While the first two aspects focus on the technical aspects, the conclusive part evaluates the practical implications, comparing the physician’s effort – quantified as the amount of epochs reviewed – in relation to the boost of the agreement between their scoring taste and partially reviewed predictions of the scoring algorithm.
Best-Suited Uncertainty Measure
Initially, in order to pinpoint the most suitable uncertainty measure, we treated identifying epochs diverging from human scoring as a binary classification task. The diverging epochs from human scoring, ie, the U-Sleep-misclassified predictions, were considered a positive class. Using this setup, we selected the most apt measure based on their Receiver Operating Characteristic (ROC) and Precision-Recall (PR) curve performances. The choice of ROC and PR curves stems from their ability to handle class imbalances and effectively comparing the true-positive against false-positive rates.
Statistical Tests to Assess the Discriminative Power of the Superior Uncertainty Metric
Upon identifying the superior metric, we further sought to statistically assess its efficacy in two distinct manners. Firstly, we proposed the null hypothesis H01:
There is no significant difference between the on-subject mean-aggregated uncertainty scores of epochs congruent with human scoring and those diverging from it.
In other words, this would imply that the uncertainty in correctly scored epochs would be the same as for the misclassified ones. With H01, we aimed to test whether predictions in line with human scoring systematically differed from those diverging in terms of their uncertainty score, effectively probing the metric’s ability to distinguish between correctly versus incorrectly classified epochs.
Further, the null hypothesis H02 postulated:
There is no significant correlation between the mean-aggregated on-subject uncertainty scores and the on-subject classification performance metrics.
Both assessments were conducted separately for ID and OOD data, with consideration of sleep-disorder status of individuals. Given the skewed non-normal nature of the uncertainty measures with bounded value ranges, the non-parametric bootstrap was employed to calculate confidence intervals (CI) to assess both hypotheses.Citation29
Impact-Evaluation of Physician Intervention on Uncertain Epochs
The culmination of our analysis revolved around varying the threshold employed to discern the uncertain epochs for the superior uncertainty metric identified. Under each threshold specification from a predefined grid, a physician review was enacted, with discordant predictions being rectified and agreeing epochs being kept. Subsequently, the classification metrics were recalculated to encapsulate this simulated physician’s intervention. While the relation between increased reviewed epochs and monotonic performance improvement is evident, our objective was to quantify the rescoring effort required to meet distinct performance benchmarks. This examination was undertaken across both ID and OOD test data splits, fortifying the robustness of our conclusions. Further, in order to make fair comparisons with existing research, we enumerated the performance improvements across diverse metrics: accuracy (Acc), weighted F1-score (F1w), and Cohen’s kappa (K).
Results
In this section, we provide the main findings with respect to the algorithmic methods exploited and developed (U-Sleep algorithm along with the auxiliary confidence neural network), and their validation on individual data domains, as depicted within the workflow in .
Figure 1 Schematic overview of datasets used, their size, and purpose.
U-Sleep Classification Performance
As a sleep scoring classifier, we employed U-Sleep and replicated the training experiment of its most recent implementation using 13 open-access databases of 19,578 PSGs.Citation11 Next, the model was fine-tuned on the BSDB, leveraging the ID training and validation splits as elaborated in . The U-Sleep optimization based on minimization of the categorical cross-entropy loss converged after 539 training epochs. To ensure a comprehensive comparison with existing research, we enumerated three distinct classification performance metrics: Acc, F1w, and K, computed in three different ways: epoch-wise (pertaining to all 30-second windows in the relevant data split), as well as subject-wise mean- and median-aggregated. summarizes the performance across the ID and the two OOD test data. The results indicate that the epoch-wise performance on ID (test) slightly exceeded that of the OOD2 and was marginally inferior to OOD1, with a maximum difference of 2.9% in the F1w between ID vs OOD1. These findings were consistent for on-subject metrics. Noteworthy, on the ID test split, which contains “tastes” of more than 50 different physicians involved in scoring of PSGs, U-Sleep reached the subject-wise agreement level of κ = 76.2% that corresponds to the interscorer agreement of K = 76% reported in the literature.Citation12–14 This points to the robustness of U-Sleep’s scoring ability in line with the theoretically justifiable performance ceiling that can be achieved on human-scored hypnograms. Marginal over- and under-performance on OOD data splits can be attributed to the greater or lesser consistency of the given (split-specific) senior physician with the “overall” population scoring pattern encoded in U-Sleep.
Table 4 Classification Performance of U-Sleep on Individual Data Splits
Evaluation of Approaches for Uncertainty Estimation
The primary objective in this phase was to pinpoint the best approach that adeptly identifies U-Sleep-predicted epochs that deviate from human scoring. This consisted of two main strands of investigation: comparing softmax-based uncertainty metrics and evaluating the confidence scores based on the adapted confidence neural network.
Softmax-Based Measures
We initially took into consideration all the softmax-based metrics, as delineated in . The metrics (i–v) identify uncertain epochs based on a distributional threshold, while metrics (vi–vii) are designed to accumulate a predetermined percentage of the most uncertain predictions. The fixed-percentage strategies do not include an approach based on the softmax ratio (ρ) as it is monotonically dependent on the maximum of the softmax (µ) and would lead to the same results. Calculation of these metrics was straightforward, as they involved only the U-Sleep softmax output based on each input channel-pair. The performance of individual measures in terms of identifying predictions discordant from human scoring is listed in . The majority of the metrics achieved comparable results with the superiority of the distributional-threshold-based metrics over the fixed-percentage strategies, confirming the need for a flexible approach adapting to possibly different amounts of difficult-to-score (uncertain) epochs per PSG. The best performing approach was µ – the maximum of the majority-softmax (= softmax averaged over all input channel pairs) – reaching AUROC of 76.5% on the ID-test and 82.4–81.1% on the two OOD sets.
Table 5 Performance of Uncertainty Measures to Identify U-Sleep Predictions Discerning from Human Scoring on Individual Data Splits
Auxiliary Confidence Network
Our evaluations continued with the auxiliary confidence network leveraging the joint information of the transformed softmax output and the hidden representations extracted from U-Sleep to predict the True Class Probability (TCP) score. We trained the confidence network on the ID training and validation splits, targeting the actual TCP scores calculated based on predictions of the already trained U-Sleep classifier. The training was based on minimizing the mean-absolute-error (MAE) loss, adopting mini-batches of U-Sleep-derived features for one PSG channel pair (EEG-EOG) at the same time, and adhering to the default configurations of the Adam optimizer in Tensorflow 2.6.0. The training process achieved convergence after 16 epochs, marking a validation MAE of 0.0827. This indicates the confidence network’s capability to predict the TCP with an average error of 8.27% in probabilistic terms. It is worth noting that the training set incorporated epochs labeled as “unknown” by physicians, reflecting the inherent challenges in scoring such signals, often due to untouched electrodes yielding constant (zero) signal. These particular epochs were assigned a target TCP of 0, given that none of the softmax values would match the correct class (ie, sleep-stage).
Having the trained confidence network, we evaluated how its predicted TCP-score performs to detect discordant epochs. Focusing on the last column of , we observe its superiority in comparison to all simpler softmax-based approaches across all test data subsets. It outperformed the other approaches in terms of both ROC and PR assessments, reaching AUROC of 85.7% on ID, 85.6–82.5% on the two OOD sets, and AUPR of 63.1% for ID and 52.3–50.7%, respectively. Furthermore, the robustness of the confidence network was confirmed, as it delivered comparable performance on both ID and OOD splits, highlighting its generalizability to potentially different scoring patterns introduced by different senior physicians. Given its demonstrated efficacy, the TCP confidence score was selected as the key metric for the following evaluations simulating physician’s interventions, focusing on the review and eventual correction of the most uncertain predictions.
Confidence-Supplemented Hypnogram
Using the TCP as the most reliable uncertainty quantification measure, depicts the combined output of the U-Sleep-predicted hypnogram (in white) with the estimated confidence TCP-scores as a green-red color scale in the background. This dual output is a result of our final pipeline, depicted as a diagram in , detailing the process of transforming original biosignals into a joint presentation of predicted sleep stages and their associated confidence levels. Such visual representation is designed to guide the physician in identifying specific segments of the PSG that deserve closer review. For demonstration, the actual physician’s scoring on given PSG, referred to as true, is depicted in blue. A close examination reveals that segments with lower predicted TCP scores often (eg, 1:30–2:30h of sleep) predominantly align with U-Sleep misclassifications. In contrast, regions with higher scores (eg, from 3:30h onwards) mostly point to accurately scored epochs. It is important to note that since the estimated TCP scores are model-derived, occasional discrepancies can arise. For instance, around 1:45h, a brief period marked with high confidence corresponds to discordant scoring. Even though this segment erroneously indicates high confidence, its neighborhood areas of low confidence might draw physician’s attention for a review. Despite occasional inconsistencies, the results from indicate that TCP-score has the best ability to identify discordant epochs.
Figure 2 Combined output of the predicted hypnogram (in white) and the associated confidence. TCP-scores (in the background), supplemented with the physician-scored hypnogram (in blue).
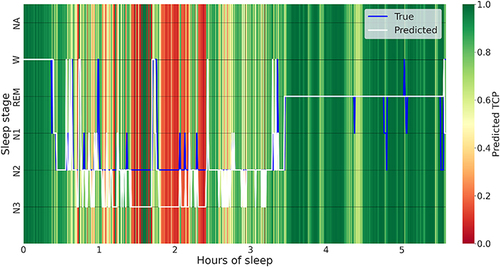
Figure 3 Schematic overview of the implemented pipeline.
Statistical Tests of on-Subject TCP Scores with Respect to Clinical Diagnosis
Further, we investigated in-depth the discriminative power of the TCP-score to reveal discordant predictions. Firstly, to evaluate H01, we calculated the on-subject difference between averaged TCP-scores of predictions that align and those that disagree with human scoring: . Next, for the evaluation of H02, the on-subject performance metrics (Acci, F1w,i, Ki) and the overall average TCP score (
), for each subject’s predicted hypnogram were calculated. The
can be understood as an assessment of the confidence over the entire predicted hypnogram of a given subject. We employed a non-parametric bootstrap approach, with 5000 repetitions, for both hypotheses to compute confidence intervals (CIs). Having a database rich in sleep-disorder diagnoses enabled us to assess both hypotheses considering individual classes of diagnoses, as described in . To assess the generalizability of our findings, we considered subjects from the ID-test and the two OOD test data with confirmed conclusive diagnoses. Since the subjects – except for healthy controls – suffer in many cases from several sleep disorders, we always included in a given class all who have at least one corresponding diagnosis. Both hypotheses were assessed on disorder classes of at least 10 subjects, separately on the ID test data, and – to achieve a larger sample size in each class – the pooled OOD data.
gives an overview of bootstrapped 95% CIs and the medians related to H01 for each diagnosis class considered. Based on the CIs obtained, H01 can be rejected (p-value < 0.05 in all cases), and one can conclude that the difference between the mean-aggregated TCP-scores of aligning and discordant predictions significantly differs and is consistently greater than 0. All that across the entire diagnosis spectrum, on both ID and OOD test domains. The median differences ranged as 0.20–0.23 and 0.19–0.26, for ID and OOD, respectively, which affirms that the TCP-score was in terms of a probability about 20% lower for the discordant predictions. In an extension of our analysis, we conducted the same evaluation on a subgroup of 76 children under 6 years old, using pooled OOD data. Compared to the mean classification metrics presented in , U-Sleep demonstrated lower scoring performance with Acc of 71.28%, F1w of 73.15%, and K of 59.19%. This performance drop is likely attributable to specific AASM scoring rules applied to children. Nonetheless, the average on-subject difference between aligning and discordant TCP scores was significantly greater than zero, indicating a mean difference of 0.19 with a 95% CI of (0.17, 0.22). These findings suggest that the confidence network and the resulting TCP score can efficiently guide physicians on hypnogram and respective PSG sections needing review and potential correction, regardless of subject’s diagnosis status, including pediatric cases.
Table 6 Bootstrap Confidence Intervals for Difference of on-Subject Mean-Aggregated Confidence TCP-Scores of Aligning Vs Discordant Predictions
Further, relates to H02 and details the bootstrapped 95% CIs for the correlation between the average on-patient TCP score and the classification performance metrics. Based on the CIs obtained, we conclude that for all diagnoses of both ID and OOD test data, the correlation with any performance metric was consistently significant (p-value < 0.05 in all cases) and positive. The TCP correlated – on average – the most with the accuracy with a range of 0.67–0.74 across individual diagnosis classes of ID test data, and of 0.58–0.81 for OOD data. Consistent findings were identified even for the 76 OOD children aged under 6 years, where TCP was significantly positively correlated with all the performance metrics: 0.62 with 95% CI of (0.43, 0.76) for Acc, 0.56 (0.36, 0.72) for F1w, and 0.60 (0.41, 0.75) for K. These findings suggest that the aggregated TCP score can efficiently pinpoint subjects whose biosignals are challenging to classify and also those with high prediction performance, including children with different AASM scoring rules applied.
Table 7 Bootstrap Confidence Intervals for Correlation Between on-Subject Mean-Aggregated Confidence TCP-Scores and the Performance Metrics
Performance Boost Under Physician’s Intervention
In the final part of our evaluations, we aimed to quantify the potential improvement in sleep-scoring classification performance when the most uncertain predictions underwent physician’s review. We simulated an intervention in which predictions with a TCP confidence score falling below a designated threshold, incremented in 0.01 steps across the [0,1] range, were set aside for human assessment. Within this set, predictions that did not align with the physician’s assessment were subsequently adjusted to reflect the physician’s scoring evaluation. Alongside observing the uplift in performance, we also monitored the amount of predictions subjected to review. This amount is indicative of the physician’s time spent on re-scoring, prompting us to quantify the effort needed to reach specific performance benchmarks.
depicts the impact of the physician’s review on the classification performance for the ID-test and the two OOD test data. The lower x-axis depicts the TCP-score threshold used to gather uncertain predictions, whereas the upper x-axis to the corresponding total % of the epochs re-scored (ie, the physician’s effort). The % refers to the aggregate over all PSGs in a given data split, as from each PSG were extracted only epochs below a given threshold and so, the individual % differed. At a TCP-threshold of 0, when no uncertain epochs are extracted, the performance as depicted on the vertical axis corresponds to the original epoch-wise performance as shown in . From , we can observe a monotonic improvement in all the performance metrics with the increasing amount of epochs gathered for the review. Based on that, we can identify, that to reach, eg, at least 90% in all the evaluation metrics, a rescoring effort of about 26% for ID-test, 19% for OOD1, and 27% for OOD2 is needed, respectively, whereas the corresponding TCP threshold lies consistently around 0.75.
Figure 4 Performance boost with physician’s review of epochs having confidence TCP-score lower than a given threshold.
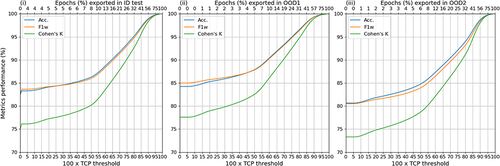
Further, based on and summarizes the % of epochs needed to be reviewed to achieve the performance benchmarks of at least (80, 85, 90, 95)% for each evaluation metric, which we use for the comparison with other existing works in the Discussion. For example, to reach at least 90% in K, a physician’s review of 25.6% of epochs is needed on the ID-test, and 18.8–29.0% on the two OOD datasets.
Table 8 Rescoring Amounts Needed to Achieve Desired Levels of Sleep-Scoring Performance
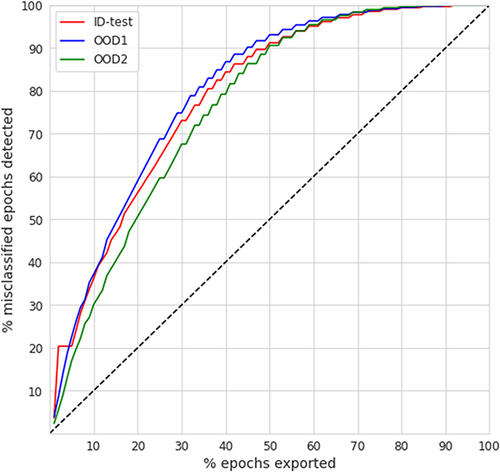
Finally, compares the rescoring effort based on an appropriate TCP-threshold in comparison to the % of all the misclassified epochs detected (ie, the true positive rate) per individual test data splits. The diagonal depicts a “random strategy”, where physician’s review would be conducted without any prior guidance on uncertain epochs. We observe that independently of the data domain, less than 50% of epochs need to be reviewed in order to detect at least 90% of all misclassified epochs. Similarly, to detect more than 95% of all misclassified epochs, a review of less than 60% of all epochs is needed. At a hypothetical 20% error rate, the 50% review effort with a corresponding detection of 90% out of all the discordant predictions leads to a boost of 18% resulting in a scoring performance of 98%, conforming with proposed clinical standards and being far beyond acceptable scoring error rates.Citation15 Since in our case is the error rate less than 20% for all domains (accuracy is always >80%) (as indicated in ), the 50% review effort corresponds to obtaining almost perfectly aligned hypnograms with agreement above 98%.
Figure 5 Review amounts (% of epochs exported) versus the % of all discordant predictions gathered.
Discussion
Our study was motivated by a key clinical application in the field of sleep medicine, where physicians reach a consensus of about 76% when scoring PSG into sleep stages.Citation12–14 This level of agreement sets a technical limit on the accuracy metrics attainable when training scoring algorithms on multiple domains (scorers/databases). Consequently, when incorporating a scoring algorithm into clinical practice, its predictions must be subjected to a rigorous review by a human expert. If this is not guided to the uncertain regions of the predicted hypnogram and the respective PSG biosignals, such review may require a similar time effort as manual scoring done from scratch. Motivated by these challenges, we designed a pipeline where a state-of-the-art scoring algorithm is combined with an uncertainty estimation to guide the human review of the predicted hypnograms, with a particular focus on the quantification of the effort required to achieve certain performance benchmarks. We took advantage of the rich clinical database (BSDB) and evaluated our approach on both in-domain (ID) and the two out-of-domain (OOD) test data, considering individuals’ conclusive sleep-disorder diagnoses. Such stratified analysis subjected our pipeline to a dual robustness test. In the case of the ID data, counting PSGs scored by >50 physicians, the evaluations related to the expected generalizability on an “average” pattern of sleep-scoring based on a broad population of physicians involved. On the other hand, the evaluations on OOD single-scorer splits were essential, because they assessed how well our system adapts to a real clinical setting, where PSG-scoring is performed by a single expert with a unique interpretation of the AASM rules.
As a sleep scoring classifier within our pipeline, we exploited the well-established U-Sleep, which we trained on 13 open-access databases and fine-tuned on ID (training and validation) data of BSDB. Such trained U-Sleep reached a robust performance of Κ = 76.2% for ID test data and Κ = (78.8, 73.8)% on the two single-scorer OOD sets, respectively.
Following that, we extensively investigated different uncertainty estimation approaches and assessed their performance on both ID and OOD datasets. Remarkably, our designed confidence network, specifically trained for PSG time-series data working in tandem with the U-Sleep, emerged as the superior approach, adeptly identifying predictions discordant with human scoring across both ID (AUROC = 85.7%) and the two OOD test data (AUROC of 85.6–82.5%). Identifying an approach that accurately pinpoints disagreeing predictions was a key prerequisite to enabling efficient review of predicted hypnograms by physicians.
Furthermore, our research extended into statistical examinations of the predicted uncertainty estimates, namely confidence scores based on our auxiliary network, leading to two pivotal conclusions: (i) the on-subject confidence scores were significantly different and lower for epochs discordant with human scoring, and (ii) the on-subject aggregated confidence scores significantly and positively correlated with all on-subject classification performance metrics. Both findings were consistent over the entire spectrum of sleep diagnoses present in both ID and OOD test data. Additional evaluations confirmed these conclusions even on 76 OOD children under 6 years of age, highlighting the generalizability of the predicted confidence scores for subjects with slightly different AASM scoring rules applied. These insights not only validate the efficacy of our approach for physician’s review but also highlight its capacity to pinpoint sections of PSG biosignals that are inherently challenging to score, independently of the subject’s diagnosis status, including pediatric cases.
As a pivotal component of our evaluations, we examined the extent to which guiding physicians in reviewing uncertain epochs could augment the efficacy of sleep staging. To attain a commendable classification performance of at least 90% in (Κ, Acc, F1w) metrics, our approach necessitated physicians to examine under 25.6% for Κ, 16.5% for Acc, and 17.2% for F1w of the epochs on ID test data. For both OOD data, these figures were less than 29.0%, 19.0%, and 21.9%, respectively. These outpace the findings by Hong et al,Citation19 where about 35% and 25% of epochs needed a review to achieve a similar 90% rate in (Κ, F1w) on ID data primarily from sleep-disordered subjects. In the broader context, the review effort of our approach closely mirrors that of Phan et al.Citation20 In their study on the Sleep-EDF dataset of healthy subjects, they reported a requirement to review 50% of epochs to identify 90% of all misclassified epochs. In our setup, with a dataset predominantly featuring sleep-disordered subjects, our efforts resonated closely, demanding a review of 45–50% of epochs, on both ID and OOD test data. Notably, the review of 50% of all the epochs leads, in our case, to an agreement of >98% for all ID and OOD test datasets. Furthermore, aiming for a more stringent identification of 95% of all misclassifications, our approach stands out, demanding a review of less than 60% of epochs on both ID and OOD test data - a subtle improvement over the 61.4% reported by Hong et al.Citation19 In addition, our efforts are in line with the findings of the most recent work of Rusanen et al,Citation21 who identified about 90% of all misclassified cases by reviewing 50% of all epochs on consensus-hypnograms of the DOD database of 81 subjects (56 OSA + 25 healthy), where each PSG was scored by multiple experts. In our case, the level of this performance was achieved on ID as well as on two OOD single-scorer datasets of a considerably larger size containing subjects from a full spectrum of sleep-disorders. We consider results on our OOD datasets to be remarkably positive since the adaptation of the approach to the scoring taste of a single scorer is expected to be more difficult for algorithms (U-Sleep, confidence network) trained on data containing scorings of different physicians, as it represents a change of domain from multiple- to single-scorer ones. Adapting to the single-scorer’s taste is closer to the current setup in clinical practice, where obtaining multiple-scorers’ consensus is costly, and a single physician evaluates the PSG and makes the final clinical decisions. These results spotlight not only the efficacy of our approach and its robustness to OOD data with different diagnosis statuses but also underscore the potential to reduce the physicians’ workload on manual sleep staging, which is paramount in practical scenarios.
Yet, our work is not without limitations. The field of uncertainty quantification for sleep staging is relatively new, and it does not include well-established baselines that would also incorporate publicly available data covering the full spectrum of sleep disorders. The data in the BSDB are mostly observational, ie, subjects undergo sleep studies due to suspicion or symptoms, and so, the presence of different diagnoses is not randomized or balanced. The training of both classification and uncertainty-estimation algorithms was done without explicit control for gender, ethnicity, age, and clinical diagnosis, which may – together with non-randomized data – contribute to computational bias.
Conclusion
The significant challenges in automatic sleep staging, such as noise-amounts due to inter-scorer disagreement, and heterogeneity in PSG databases – reflecting the large inter-individual variability in sleep manifestation – underscore the complexities in achieving an AI model that could perfectly generalize to data from different domains. While automated sleep scoring algorithms have achieved excellent performances despite these hurdles, they are still bound by the limitations inherent to the quality of their training labels. Consequently, despite the technological advancements, the critical role of physicians in reviewing and verifying predicted hypnograms remains – so far – irreplaceable and imperative. With the increasing prevalence of sleep-wake disorders, and with the massive amounts of data present in PSGs, it is therefore necessary to drive research efforts to optimize physician’s review by directing them to potential areas of uncertainty, while ensuring an efficient examination compliant with clinical needs.
In this study, we developed a pipeline aimed at enhancing the use of automated sleep-scoring algorithms in clinical practice. By retraining of the U-Sleep algorithm on 19,578 PSGs coming from 13 open-access databases, we reached state-of-the-art performance (F1w ≥80.5% on all test data) and encoded the sleep-scoring expertise of a broad range of physicians. Utilizing the comprehensive BSDB database of 8832 additional PSGs, we compared various approaches for uncertainty quantification, including a novel confidence network that we designed to work in tandem with U-Sleep. Compared to softmax-based measures, our confidence network demonstrated its superiority for identifying predictions discordant from physician’s scoring (AUROC ≥ 82.5% on all test data) and built a prerequisite for successful implementation of a system that efficiently incorporates physician’s insights.
Our study makes a significant contribution to sleep science by demonstrating the potential of incorporating a semi-automated approach into clinical settings. This is achieved through a unique combination of the U-Sleep robustness, the precision of an added confidence network, and the richness of the BSDB database, enabling in-depth validations with respect to individuals’ diagnoses and accommodating the scoring preferences of different physicians. The combined approach of our pipeline ensures that while insights from the automatic sleep-scoring tool are utilized, physicians can concentrate their efforts on reviewing segments of biosignals where potential disagreements or algorithmic errors may occur. This has a great potential to significantly reduce the workload in the analysis of sleep studies. Moreover, the design of our pipeline can be applied beyond the sleep-scoring framework, for any use case where expert verification of algorithmic predictions is needed.
We believe that the adoption of scoring algorithms for clinical practice does not consist in replacing the physician’s expertise with an algorithm, but mainly in enabling the effective use of the algorithm’s insights and their thorough validation.
Disclosure
Mrs Francesca Faraci reports grants from Eurostar Eureka, outside the submitted work. The authors report no other conflicts of interest in this work.
Acknowledgments
The secondary usage of Berner Sleep Data Base (BSDB) from Inselspital, University Hospital Bern, was approved by the local ethics committee (KEK-Nr. 2020-01094) in the framework of the E12034 – SPAS (Sleep Physician Assistant System) Eurostar-Horizon 2020 program. Participants provided written general consent as of its introduction at Inselspital in 2015, and data were maintained with confidentiality. The BSDB dataset access may be granted upon individual request, after data transfer agreements were put in place.
References
- Berry RB, Brooks R, Gamaldo C, et al. AASM Scoring Manual Updates for 2017 (Version 2.4). J Clin Sleep Med. 2017;13(5):665–666. doi:10.5664/jcsm.6576
- Patel AK, Reddy V, Shumway KR, Araujo JF. Physiology, Sleep Stages. In: StatPearls. Treasure Island (FL): StatPearls Publishing; 2022.
- Dorffner G, Vitr M, Anderer P. The effects of aging on sleep architecture in healthy subjects. Adv Exp Med Biol. 2015;821:93–100.
- Kahn A, Dan B, Groswasser J, Franco P, Sottiaux M. Normal sleep architecture in infants and children. J Clin Neurophysiol. 1996;13(3):184–197. doi:10.1097/00004691-199605000-00002
- Liu Y, Zhang J, Lam V, et al. Altered sleep stage transitions of REM sleep: a novel and stable biomarker of narcolepsy. J Clin Sleep Med. 2015;11(8):885–894. doi:10.5664/jcsm.4940
- Wei Y, Colombo MA, Ramautar JR, et al. Sleep stage transition dynamics reveal specific stage 2 vulnerability in insomnia. Sleep. 2017;40(9):10.1093/sleep/zsx117.
- Goh DY, Galster P, Marcus CL. Sleep architecture and respiratory disturbances in children with obstructive sleep apnea. Am J Respir Crit Care Med. 2000;162(2):682–686. doi:10.1164/ajrccm.162.2.9908058
- Malhotra A, Younes M, Kuna ST, et al. Performance of an automated polysomnography scoring system versus computer-assisted manual scoring. Sleep. 2013;36(4):573–582. doi:10.5665/sleep.2548
- Fiorillo L, Puiatti A, Papandrea M, et al. Automated sleep scoring: a review of the latest approaches. Sleep Med Rev. 2019;48:101204. doi:10.1016/j.smrv.2019.07.007
- Perslev M, Darkner S, Kempfner L, Nikolic M, Jennum PJ, Igel C. U-Sleep: resilient high-frequency sleep staging. NPJ Digit Med. 2021;4(1):72. doi:10.1038/s41746-021-00440-5
- Fiorillo L, Monachino G, van der Meer J, et al. U-Sleep’s resilience to AASM guidelines. NPJ Digit Med. 2023;6(1):33. doi:10.1038/s41746-023-00784-0
- Danker-Hopfe H, Anderer P, Zeitlhofer J, et al. Interrater reliability for sleep scoring according to the rechtschaffen & kales and the new AASM standard. J Sleep Res. 2009;18(1):74–84.
- Younes M, Raneri J, Hanly P. Staging sleep in polysomnograms: analysis of inter-scorer variability. J Clin Sleep Med. 2016;12(6):885–894. doi:10.5664/jcsm.5894
- Penzel T, Zhang X, Fietze I. Inter-scorer reliability between sleep centers can teach us what to improve in the scoring rules. J Clin Sleep Med. 2013;9(1):89–91. doi:10.5664/jcsm.2352
- Penzel T. Sleep scoring moving from visual scoring towards automated scoring. Sleep. 2022;45(10):zsac190. doi:10.1093/sleep/zsac190
- van Gorp H, Huijben IAM, Fonseca P, van Sloun RJG, Overeem S, van Gilst MM. Certainty about uncertainty in sleep staging: a theoretical framework. Sleep. 2022;45(8):zsac134. doi:10.1093/sleep/zsac134
- Kang DY, DeYoung PN, Tantiongloc J, Coleman TP, Owens RL. Statistical uncertainty quantification to augment clinical decision support: a first implementation in sleep medicine. NPJ Digit Med. 2021;4(1):142. doi:10.1038/s41746-021-00515-3
- Fiorillo L, Favaro P, Faraci FD. DeepSleepNet-lite: a simplified automatic sleep stage scoring model with uncertainty estimates. IEEE Trans Neural Syst Rehabil Eng. 2021;29:2076–2085. doi:10.1109/TNSRE.2021.3117970
- Hong JK, Lee T, Delos Reyes RD, et al. Confidence-based framework using deep learning for automated sleep stage scoring. Nat Sci Sleep. 2021;13:2239–2250. doi:10.2147/NSS.S333566
- Phan H, Mikkelsen K, Chen OY, Koch P, Mertins A, De Vos M. SleepTransformer: automatic sleep staging with interpretability and uncertainty quantification. IEEE Trans Biomed Eng. 2022;69(8):2456–2467. doi:10.1109/TBME.2022.3147187
- Rusanen M, Jouan G, Huttunen R, et al. aSAGA: automatic Sleep Analysis with Gray Areas. arXiv:2310.02032; 2023. Available from: https://arxiv.org/abs/2310.02032. Accessed May 15, 2024.
- Aellen FM, Van der Meer J, Dietmann A, et al. Disentangling the complex landscape of sleep-wake disorders with data-driven phenotyping: a study of the Bernese center. Eur J Neurol. 2023;31. doi:10.1111/ene.16026
- Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing; 2015: 234–241.
- Stephansen JB, Olesen AN, Olsen M, et al. Neural network analysis of sleep stages enables efficient diagnosis of narcolepsy. Nat Commun. 2018;9(1):5229. doi:10.1038/s41467-018-07229-3
- Nguyen A, Yosinski J, Clune J. Deep neural networks are easily fooled: high confidence predictions for unrecognizable images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2015:427–436.
- Corbiere C, Thome N, Saporta A, Vu TH, Cord M, Perez P. Confidence estimation via auxiliary models. IEEE Trans Pattern Anal Mach Intell. 2021;44(10):6043–6055. doi:10.1109/TPAMI.2021.3085983
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9(8):1735–1780. doi:10.1162/neco.1997.9.8.1735
- Aitchison J. The statistical analysis of compositional data. J R Stat Soc Series B Methodol. 1982;44(2):139–160. doi:10.1111/j.2517-6161.1982.tb01195.x
- Efron B. The Jackknife, the Bootstrap, and Other Resampling Plans. SIAM; 1982.