
Abstract
Coronary artery disease (CAD) is the leading cause of death and disability worldwide, and its prevalence is expected to increase in the coming years. CAD events are caused by the interplay of genetic and environmental factors, the effects of which are mainly mediated through cardiovascular risk factors. The techniques used to study the genetic basis of these diseases have evolved from linkage studies to candidate gene studies and genome-wide association studies. Linkage studies have been able to identify genetic variants associated with monogenic diseases, whereas genome-wide association studies have been more successful in determining genetic variants associated with complex diseases. Currently, genome-wide association studies have identified approximately 40 loci that explain 6% of the heritability of CAD. The application of this knowledge to clinical practice is challenging, but can be achieved using various strategies, such as genetic variants to identify new therapeutic targets, personal genetic information to improve disease risk prediction, and pharmacogenomics. The main aim of this narrative review is to provide a general overview of our current understanding of the genetics of coronary artery disease and its potential clinical utility.
Introduction
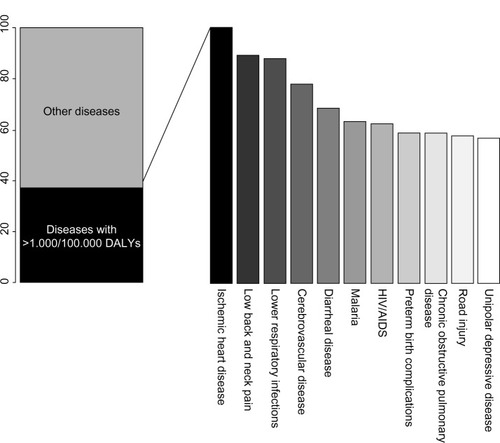
Coronary artery disease (CAD) is the principal individual cause of mortality and morbidity worldwide. A recent report on the Global Burden of Disease, which proposes disability-adjusted life years (DALYs, calculated as the sum of years of life lost and years lived with disability) as a new metric to measure disease burden, indicates that CAD accounted for the largest proportion of DALYs due to a single cause worldwide in 2010, explaining 5% of the total number of DALYS ().Citation1
Figure 1 The top eleven diseases explain 37.7% of the global burden of disease measured as DALYs, with coronary artery disease as the leading cause of DALYs in 2010.
CAD is a complex chronic inflammatory disease, characterized by remodeling and narrowing of the coronary arteries supplying oxygen to the heart. It can have various clinical manifestations, including stable angina, acute coronary syndrome, and sudden cardiac death. It has a complex etiopathogenesis and a multifactorial origin related to environmental factors, such as diet, smoking, and physical activity, and genetic factorsCitation2 that modulate risk of the disease both individually and through interaction.
In this narrative review, we summarize the main etiopathogenic mechanisms that underlie CAD, with a focus on current knowledge concerning the genetic architecture of the disease and the clinical utility of this knowledge.
Atherosclerosis, the main etiopathogenic mechanism of CAD
Atherosclerosis is the main etiopathogenic process that causes CAD, and its progression is related to an interplay between environmental and genetic factors, with the latter exerting their effects either directly or via cardiovascular risk factors (). Although clinical ischemic cardiovascular events usually appear after the fifth decade of life in men and the sixth decade of life in women, this process starts early in life, even during fetal development.Citation3
Figure 2 Genetic and environmental causes of development and progression of atherosclerosis act directly or through known intermediate traits.

Briefly, atherosclerosis is a silent progressive chronic process characterized by accumulation of lipids, fibrous elements, and inflammatory molecules in the walls of the large arteries.Citation4–Citation8 This process begins with the efflux of low-density lipoprotein (LDL) cholesterol to the subendothelial space, which can then be modified and oxidized by various agents. Oxidized/modified LDL particles are potent chemotactic molecules that induce expression of vascular cell adhesion molecule and intercellular adhesion molecule at the endothelial surface, and promote monocyte adhesion and migration to the subendothelial space. Monocytes differentiate to macrophages in the intima media. Recently, different subsets of monocytes have been identified, and their roles appear to be different according to the phase of atherosclerosis in which they are involved.Citation9 Macrophages bind oxidized LDL via scavenger receptors to become foam cells,Citation5 and also have proinflammatory functions, including the release of cytokines such as interleukins and tumor necrosis factor. The final result of this process is formation of the first typical atherosclerotic lesion, ie, the fatty streak, in which foam cells are present in the subendothelial space.
Other types of leukocytes, such as lymphocytes and mast cells, also accumulate in the subendothelial space.Citation10 The cross-talk between monocytes, macrophages, foam cells, and T-cells results in cellular and humoral immune responses, and ultimately in a chronic inflammatory state with the production of several proinflammatory molecules.Citation11,Citation12 This process continues with the migration of smooth muscle cells from the medial layer of the artery into the intima, resulting in the transition from a fatty streak to a more complex lesion.Citation5 Once smooth muscle cells are in the intima media, they produce extracellular matrix molecules, creating a fibrous cap that covers the original fatty streak. Foam cells inside the fibrous cap die and release lipids that accumulate in the extracellular space, forming a lipid-rich pool known as the necrotic core.Citation13 The result of this process is formation of the second atherosclerotic lesion, the fibrous plaque.
The thickness of the fibrous cap is key for maintaining the integrity of the atherosclerotic plaque,Citation8 and two types of plaque can be defined depending on the balance between formation and degradation of this fibrous cap, ie, stable and unstable or vulnerable. Stable plaques have an intact, thick fibrous cap composed of smooth muscle cells in a matrix rich in type I and III collagen.Citation14 Protrusion of this type of plaque into the lumen of the artery produces flow-limiting stenosis, leading to tissue ischemia and usually stable angina. Vulnerable plaques have a thin fibrous cap made mostly of type I collagen and few or no smooth muscle cells, but abundant macrophages and proinflammatory and prothrombotic molecules.Citation8,Citation10 These plaques are prone to erosion or rupture, exposing the core of the plaque to circulating coagulation proteins, causing thrombosis, sudden occlusion of the artery lumen,Citation8,Citation10 and usually an acute coronary syndrome. Intraplaque hemorrhage is also a potential contributor to progression of atherosclerosis, and appears to occur when the vasa vasorum invades the intima from the adventitia.Citation15
Study of the genetic architecture of disease
In order to study the genetic factors associated with a disease, several sequential steps must be followed. The first step involves quantification of the genetic component of the disease, which can be expressed as its heritability, ie, the proportion of the total population variance of the phenotype at a particular time or age that is attributable to genetic variation.Citation16 The heritability of some phenotypes associated with arteriosclerosis has already been determined, and generally ranges from 40% to 55% ().Citation17,Citation18
Table 1 Main results of different studies analyzing the heritability of several phenotypes associated with arteriosclerosis
The second step is to study the genetic architecture of the disease, ie, identify the loci, and within these loci, the genetic variants that modulate disease susceptibility. However, this task is one of the greatest challenges in current genetic research. Depending on the observed patterns of inheritance, it is possible to classify genetic diseases in two broad classes, ie, monogenic or Mendelian diseases, in which genetic variation in one gene accounts for most or all of the variation in disease risk;Citation19 and complex diseases, which are characterized by complex patterns of inheritance caused by the combination of multiple genetic variants (often with a small effect) and environmental factors, and modulated by their mutual interaction.Citation20 For example, in the case of CAD, the effects of known genetic variants range from an odds ratio of 1.04 to approximately 1.30 per copy of the risk allele.Citation21 Studies of the genetic architecture of a disease generally have two approaches, ie, linkage and association studies.Citation17
Linkage studies
In these studies, large families with several affected and unaffected relatives across one or more generations are identified and recruited.Citation22,Citation23 Classically, large numbers of genetic markers, uniformly distributed throughout the genome, are analyzed to see if their transmission from generation to generation is associated with the presence of the disease (segregation). The initial objective is to identify regions of the genome that contain genes predisposing to or causing the disease under study. Thereafter, the chromosomal region that segregates with the disease can be fine-mapped to identify the causal gene.Citation17,Citation22,Citation23 This type of study has been successful in identifying many disease genes, particularly those that cause Mendelian traits, but less successful in identifying genes associated with complex diseases.Citation24 In the case of CAD, notable successes include the identification of variants in ALOX5AP as being associated with coronary and cerebrovascular diseases,Citation25 in MEF2A as being associated with CAD,Citation26 and in PCSK9 as a gene for which variation is relevant in the metabolism of cholesterol.Citation27
Association studies
Association studies are likely to be more effective tools than linkage studies for studying genetically complex traits because they can have greater statistical power to detect genetic variants with small effects.Citation28 These types of studies evaluate the association between genetic variants (usually single nucleotide polymorphisms or copy number variations) and the presence/absence of a disease or a specific phenotype. The biggest challenges for this type of study are the accuracy of phenotype definition and replication of the findings. In order to identify genetic variants with small effects, large sample sizes are required, which are usually obtained by pooling different samples and populations, potentially with different phenotyping methods or criteria. In many cases, this heterogeneity results in dilution of the effects of causal genetic variants. In other cases, the phenotype itself may be difficult to define (eg, fibromyalgia) or show substantial intraindividual variability (eg, blood pressure), diluting the observable effect of the causal variant on the phenotype of interest. There are several types of association studies, as follows.
Candidate gene studies
Association studies in candidate genes, usually known to be related to intermediate traits, have been widely used for the study of complex diseases.Citation4,Citation29,Citation30 This approach is based on an a priori hypothesis generated from knowledge of the disease pathogenesis or previous results.Citation17,Citation31 In the 1990s, this type of research became very popular and many studies analyzing the relationship between genetic variants and phenotypes were published, although their main findings were often difficult to replicate.Citation32
Genome-wide association studies
The goal of genome-wide association studies (GWAS) is to identify genetic variants associated with complex phenotypes without the need for prior selection of candidate loci or genes.Citation33 GWAS are based on two assumptions: first, a large proportion of common variation in the genome can be captured by a relatively small number of genetic variants, an hypothesis that is supported by evidence from the HapMap project;Citation34 and, second, common complex diseases are mainly caused by common genetic variants.
This type of study became possible through technologic advances that allowed large numbers of single nucleotide polymorphisms to be genotyped throughout the genome and common patterns of linkage disequilibrium in different populations to be determined, thanks to studies like the Human Genome Project and the HapMap Project.Citation34,Citation35 This evidence allowed the possibility of searching the human genome for common variants associated with a huge variety of phenotypes and diseases.Citation36 Moreover, powerful association analysis methods and software have also been developed.Citation37,Citation38 These studies are hypothesis-free, and due to the multiple comparisons and the need to reduce the burden of potential type I errors, they have to correct the P-value to be considered statistically significant according to the number of tests performed. Usually, this statistical significance threshold is located at a P-value, 10−8.
In parallel, international collaborations and consortia have provided new insights in medical research.Citation39 While the number of studies that use this methodology has increased rapidly in recent years (), this type of design is known to have some limitations (). These include the low proportion of heritability explained by the genetic variants identified, which has been found to be lower than 10% for most phenotypes,Citation4,Citation40 and the fact that the results are based on statistical association and do not provide functional insights. However, these studies have consistently identified hundreds of loci in dozens of clinically important phenotypes,Citation4,Citation41 providing further insights into the genetics of complex diseases.
Figure 3 Number of articles published per year according to the genome-wide association studies catalog (accessed on September 27, 2013).
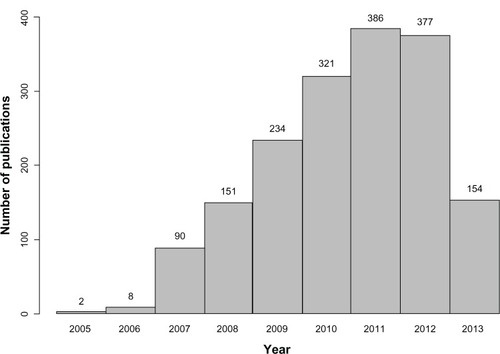
Table 2 Comparison between candidate gene studies and GWAS
Whole-genome sequencing studies
The human genome contains approximately 3.1 billion nucleotides with approximately 56 million genetic variants. The exome, ie, the part of the genome formed by protein-coding exons, comprises approximately 30 million nucleotides and 23,500 genes.Citation42 Rapidly improving whole-genome sequencing (WGS) technologies are creating new research avenues based on sequencing entire individuals,Citation39,Citation42 and the rapidly decreasing costs of WGS will soon allow this technology to be used for tackling the genetic architecture of disease.Citation43 WGS are expected to contribute to better definition of the genetic basis of a range of phenotypes, responses to therapy, and clinical outcomes. Although WGS mainly focus on Mendelian disorders, the WGS approach is becoming important for identifying and analyzing rare variants, which might have larger effects on disease risk than the common variants identified by GWAS.Citation42
One of the main disadvantages of WGS is the rate of false positive/false negative results in variant calling, and identification of the true causal genetic variant. Considering a false positive rate of 2%, an analysis of three billion genetic variants per genome would yield 60,000,000 miscalled variants. Therefore, false positives are expected to remain a major limitation of WGS, and alternative methods for validating variants identified by this approach will be necessary. Also, WGS will have a real challenge in identifying the true causal genetic variants among all alleles because all genes and proteins carry several nonpathogenic variants. For this reason, a classification of genetic variants according to the strength of the evidence for causality has been proposed as follows: disease-causing, likely disease-causing, disease-associated, functional but not associated with disease; and unknown biological function.Citation42
Current knowledge of genetic architecture of CAD
Our understanding of the genetic architecture of CAD has improved considerably since 2007 when the first GWAS of this disease were published. The first two studies were published simultaneously and identified the 9p21 locus to be associated with myocardial infarctionCitation44 and CAD,Citation45 and a third study replicated these findings.Citation46 At the beginning of 2013, a meta-analysis of several GWAS identified a final set of about 40 genetic variants associated with CAD () that explains approximately 6% of the heritability of CAD.Citation21 Some of these variants are related to lipid metabolism, blood pressure, and inflammation, which confirms the importance of these pathways in the pathogenesis of CAD.Citation21 In contrast, this study found no overlap between these CAD loci and those associated with type 2 diabetes or glucometabolic traits. Moreover, most of these CAD loci are located in intergenic regions, or in regions with unknown function or where the relationship to atherosclerosis or its intermediate traits is unknown.
Table 3 Summary of main findings of most recent meta-analysis of genome-wide association studies in coronary artery disease, showing the lead single nucleotide polymorphism of each locus, the closest gene, chromosomal location, risk allele and frequency, P-value, and effect size of the reported associations
Genetics of cardiovascular risk factors
Classical cardiovascular risk factors, such as hypertension, diabetes, dyslipidemia, and obesity, are also considered to be complex traits caused by the interplay between genetic and environmental factors, as in the case of CAD. The GWAS approach has had a similar degree of success in identifying the genetic architecture of these risk factors and that of CAD, in that only a small fraction of the heritability of these phenotypes has been explained ().Citation47–Citation53 While some of these genetic variants are also associated with CAD risk, others are not, ie, they have such small effects that very sample sizes would be required to detect them.
Table 4 Summary of main findings of most recent meta-analyses of genome-wide association studies of cardiovascular risk factors, showing the lead single nucleotide polymorphism of each locus, the closest gene, chromosomal location, risk allele and frequency, and P-value of the reported associations
Clinical utility of genetic knowledge
The identification of genetic variants associated with disease has allowed us to improve our understanding of its pathogenesis, and ultimately to reduce the burden of disease at both the individual and population levels. Information derived from genetic studies could potentially help to reduce the burden of disease in three main ways, ie, the identification of new pharmacologic targets, improvements in identification of high-risk individuals, and pharmacogenomics.
Identification of new pharmacologic targets
Genetic studies can shed light on new metabolic pathways associated with the development and progression of atherosclerosis, and provide clues for identifying new pharmacologic targets. The following two examples illustrate the promise as well as the potential difficulties of this field.
PCSK9
A clear example of the success of genetic studies in identifying molecules that may become new therapeutic targets is the PCSK9 gene. This gene was initially discovered by linkage studies to be associated with autosomal dominant hypercholesterolemia,Citation27 for which new causal mutations were identified in 2003.Citation54 The PCSK9 protein is crucial for metabolism of LDL cholesterol through its role in degradation of the LDL receptor, such that inhibition of this protein could become a viable treatment for hypercholesterolemia.Citation55 Recent clinical trials in patients with primary hypercholesterolemia have shown that combination treatment with REGN727/SAR236553, a human monoclonal antibody to PCSK9, and either 10 mg or 80 mg of atorvastatin resulted in significantly greater reduction of LDL cholesterol than that obtained by 80 mg of atorvastatin alone.Citation56
9p21 region
The genetic variants associated with CAD at the 9p21 locus, which has been the top hit in all CAD GWAS since 2007, lie in an intergenic region close to a cluster of cell-cycle regulating tumor suppressor genes (CDKN2A and CDKN2B) that overlap with a nonprotein coding RNA (CDKN2BAS or ANRIL). While various hypotheses have been proposed to explain the functional basis of this association, the mechanism remains unclear,Citation39,Citation57 and this has prevented the identification of a therapeutic target.
Improved identification of high-risk individuals
In the case of CAD, primary prevention strategies in healthy asymptomatic individuals are very important because the first clinical manifestation of the disease is often catastrophic (MI or sudden death). Two main prevention strategies can be defined: the population approach, based on public health policies that affect the whole population, such as smoking bans;Citation58 and the approach that targets high-risk individuals, based on implementing intensive preventive treatment in individuals at high risk of having the disease, based on their cardiovascular risk factor profile.Citation59 Two main screening strategies are usually undertaken to identify high-risk individuals, ie, opportunistic screening and high-risk screening. In opportunistic screening, evaluation of cardiovascular risk factors and estimation of CAD risk is carried out in all individuals who come into contact with the health care system for any reason. Risk functions are the most commonly used method for estimating individual risk of having a CAD event, usually for a 10-year period.Citation59–Citation61 Risk functions are mathematical equations that estimate the probability of developing CAD/cardiovascular disease using information about cardiovascular risk factors that are strongly and independently related to CAD and can be evaluated by simple procedures in the laboratory or doctor’s office.
Depending on their estimated risk, it is possible to categorize individuals into different risk categories (low, intermediate, high, and very high), and these categories are used to determine the intensity of preventive cardiovascular measures to be applied, which may range from lifestyle recommendations to prescription of drugs with various clinical objectives. Although risk functions can accurately predict the numbers of events that will occur in each risk category, many CAD events occur in individuals whose risk is too low to justify intensive treatment.Citation62 For this reason, considerable effort has been invested in improving the classification of these intermediate-risk individuals into more appropriate risk categories.
Several biomarkers, including genetic variants, have been analyzed as candidates for improving the predictive capacity of risks functions.Citation63 The main advantage of genetic variants is that they remain invariable throughout life, so it is possible to determine a person’s genetic risk profile before the development of an adverse cardiovascular risk factor profile, which would allow primary prevention measures to be undertaken earlier in life.Citation2,Citation63 Another advantage is the lower cost and higher replicability of genotyping compared with other cardiovascular risk factors. Among the limitations, the small effect sizes of known variants are most notable, despite the highly statistically significant associations between these variants and CAD risk.
Several studies have evaluated the effects on the predictive capacity of classical risk functions when genetic factors are taken into account. While most of the studies have found that these genetic variants (usually expressed as a single variable corresponding to the number of risk alleles carried, known as a genetic risk score) are associated with risk of future CAD events, they have not been found to improve the ability to discriminate between those individuals at particular risk who will develop the disease, although they do improve the reclassification of individuals into more appropriate risk categories, especially those at intermediate risk ().
Table 5 Main characteristics and results of studies assessing improvement of predictive capacity of classical cardiovascular risk functions after inclusion of genetic information
Pharmacogenomics
Pharmacogenomics is the study of the relationship between genetic variability and a patient’s response to drug treatment, ie, the efficacy of the drug and/or its adverse effects.Citation64–Citation68 Candidate gene and GWAS approaches have been used to identify genetic variants associated with variability in drug response, including several examples in the cardiovascular field,Citation69,Citation70 the majority of which have focused on statins, antiplatelet drugs, oral anticoagulants, or beta-blockers. The case of statins and the antiplatelet agent clopidogrel provide two interesting examples in this area.
Statins are widely prescribed to reduce plasma cholesterol levels and cardiovascular risk, and although the majority of patients show a 30%–50% reduction in LDL cholesterol, high interindividual variability is observed.Citation71 Several genetic variants in the HMGCR, APOE, CETP, and CLMN genes have been reported to be associated with this interindividual variability, but the results have been discordant.Citation69,Citation70 Similarly, a variant in the KIF6 gene has been reported to modulate the effect of statins on clinical outcome,Citation72,Citation73 but recent studies have not corroborated this finding.Citation74,Citation75 Finally, more than one variant in the SLCO1B1 gene is consistently associated with the risk of simvastatin-induced myopathy, with an odds ratio >4.Citation69,Citation76
Our second example concerns the prodrug clopidogrel, which is converted into an active metabolite that selectively and irreversibly binds to the P2Y12 receptor on the platelet membrane. Conversion is achieved by the hepatic cytochrome P450 system in a two-step oxidative process, and cytochrome P450 2C19 is involved in both of these steps. The response to treatment with clopidogrel varies markedly between individuals, and the causes of a poor response are not clearly understood, but have been suggested to be related to clinical, cellular, or genetic factors.Citation66,Citation77,Citation78 In March 2010, the US Food and Drug Administration added a “boxed warning” to the labeling of clopidogrel, including a reference to patients who do not effectively metabolize the drug and therefore may not receive the full benefits on the basis of their genetic characteristics.Citation79 Recently, the American College of Cardiology Foundation and the American Heart Association have published a consensus document addressing this US Food and Drug Administration warning,Citation80 stating that the role of genetic tests and the clinical implications and consequences of this testing remain to be determined. Moreover, three recent meta-analyses question the validity of this warning based on the fact that the reported associations are mainly driven by studies with small sample sizes;Citation78,Citation81,Citation82 thus, they concluded that current evidence does not support the use of individualized clopidogrel regimens guided by the CYP2C19 genotype.
Conclusion
In the past 7 years, GWAS have contributed substantially to our understanding of the genetic architecture of complex diseases, including CAD. To date, approximately 40 unique loci have been found to be robustly associated with disease risk in large samples from several populations, a much higher number than those identified by linkage and candidate gene association studies. However, these variants explain only a small proportion of the heritability of CAD.Citation40 Additional efforts to improve the analysis strategies, including new imputation and meta-analytic methods, analysis of gene-gene and gene-environment interactions, the integration of different omics, and use of sequencing technologies, are being performed.Citation83–Citation85
Although it is not yet clear if or how all of this information on the genetic architecture of CAD can be translated into clinical practice,Citation86 we already have some exciting examples of its potential utility. To identify new therapeutic targets, we must first make the difficult transition from the statistical associations reported in GWAS to the functional mechanisms behind these associations. Research on the use of genetic information to improve cardiovascular risk estimation in individuals at intermediate risk can be carried out as a second step or in parallel, and further studies to develop new ways to include this information in risk functions, to evaluate its cost-effectiveness, and to explore the ethical issues are also warranted.Citation87–Citation89 Finally, although medicine is always a “personalized science and art”, use of genetic information to identify the most effective and least harmful drug for each patient is also a goal of so-called genetic personalized medicine.
Acknowledgments
This work was supported by the Spanish Ministry of Science and Innovation through the Carlos III Health Institute (Red de Inves-tigación Cardiovascular; Programa HERACLES RD12/0042), Health Research Fund (FIS-PI09/90506), and the Government of Catalunya through the Agency for Management of University and Research Grants (2009 SGR 1195). We acknowledge the contribution of ThePaperMill (http://www.thepapermill.cat) to the critical reading and English language review of this paper.
Disclosure
The authors report no other conficts of interest in this work.
References
- MurrayCJVosTLozanoRDisability-adjusted life years (DALYs) for 291 diseases and injuries in 21 regions, 1990–2010: a systematic analysis for the Global Burden of Disease Study 2010Lancet20123802197222323245608
- Lluis-GanellaCGenetic Factors Associated with Coronary Heart Disease and Analysis of their Predictive CapacityBarcelona, SpainUniversitat Pompeu Fabra2012
- MecchiaDLavezziAMMauriMMatturriLFeto-placental atherosclerotic lesions in intrauterine fetal demise: role of parental cigarette smokingOpen Cardiovasc Med J20093515619572018
- LusisAJMarRPajukantaPGenetics of atherosclerosisAnnu Rev Genomics Hum Genet2004518921815485348
- GlassCKWitztumJLAtherosclerosis. the road aheadCell200110450351611239408
- SanzJMorenoPFusterVThe year in atherothrombosisJ Am Coll Cardiol201324621131114323916939
- TabasIGlassCKAnti-inflammatory therapy in chronic disease: challenges and opportunitiesScience201333916617223307734
- SakakuraKNakanoMOtsukaFLadichEKolodgieFDVirmaniRPathophysiology of atherosclerosis plaque progressionHeart Lung Circ20132239941123541627
- GhattasAGriffithsHRDevittALipGYShantsilaEMonocytes in coronary artery disease and atherosclerosis: where are we now?J Am Coll Cardiol2013621541155123973684
- LibbyPRidkerPMHanssonGKProgress and challenges in translating the biology of atherosclerosisNature201147331732521593864
- WitztumJLLichtmanAHThe infuence of innate and adaptive immune responses on atherosclerosisAnnu Rev Pathol872013 [Epub ahead of print.]
- LibbyPInflammation in atherosclerosisArterioscler Thromb Vasc Biol2012322045205122895665
- TabasIMacrophage death and defective infammation resolution in atherosclerosisNat Rev Immunol201010364619960040
- FinnAVNakanoMNarulaJKolodgieFDVirmaniRConcept of vulnerable/unstable plaqueArterioscler Thromb Vasc Biol2010301282129220554950
- DoyleBCapliceNPlaque neovascularization and antiangiogenic therapy for atherosclerosisJ Am Coll Cardiol2007492073208017531655
- VisscherPMHillWGWrayNRHeritability in the genomics era – concepts and misconceptionsNat Rev Genet2008925526618319743
- ElosuaRLluis-GanellaCLucasGResearch into the genetic component of heart disease: from linkage studies to genome-wide genotypingRev Esp Cardiol Suppl20099Suppl24B38B
- PedenJFFarrallMThirty-fve common variants for coronary artery disease: the fruits of much collaborative labourHum Mol Genet201120R198R20521875899
- ChialHMendelian genetics: patterns of inheritance and single-gene disordersNature Education200811 Available from: http://www.nature.com/scitable/topicpage/mendelian-genetics-patterns-of-inheritance-and-single-966Accessed November 4, 2013
- LoboIMultifactorial inheritance and genetic diseaseNature Education200811 Available from: http://www.nature.com/scitable/topicpage/multifactorial-inheritance-and-genetic-disease-919Accessed November 4, 2013
- DeloukasPKanoniSWillenborgCLarge-scale association analysis identifies new risk loci for coronary artery diseaseNat Genet201345253323202125
- DawnTMBarrettJHGenetic linkage studiesLancet20053661036104416168786
- KathiresanSSrivastavaDGenetics of human cardiovascular diseaseCell20121481242125722424232
- WangJGStaessenJAFranklinSSFagardRGueyffierFSystolic and diastolic blood pressure lowering as determinants of cardiovascular outcomeHypertension20054590791315837826
- HelgadottirAManolescuAThorleifssonGThe gene encoding 5-lipoxygenase activating protein confers risk of myocardial infarction and strokeNat Genet20043623323914770184
- WangLFanCTopolSETopolEJWangQMutation of MEF2A in an inherited disorder with features of coronary artery diseaseScience20033021578158114645853
- VarretMRabesJPSaint-JoreBA third major locus for autosomal dominant hypercholesterolemia maps to 1p34.1-p32Am J Hum Genet1999641378138710205269
- RischNMerikangasKThe future of genetic studies of complex human diseasesScience1996273151615178801636
- ZhuMZhaoSCandidate gene identification approach: progress and challengesInt J Biol Sci2007342042717998950
- TaborHKRischNJMyersRMCandidate-gene approaches for studying complex genetic traits: practical considerationsNat Rev Genet2002339139711988764
- AttiaJIoannidisJPThakkinstianAHow to use an article about genetic association. C: What are the results and will they help me in caring for my patients?JAMA200930130430819155457
- LohmuellerKEPearceCLPikeMLanderESHirschhornJNMeta-analysis of genetic association studies supports a contribution of common variants to susceptibility to common diseaseNat Genet20033317718212524541
- VisscherPMBrownMAMcCarthyMIYangJFive years of GWAS discoveryAm J Hum Genet20129072422243964
- The International HapMap ConsortiumA haplotype map of the human genomeNature20054371299132016255080
- US Department of Energy Human Genome Project Available from: http://www.ornl.gov/hgmisAccessed November 4, 2013
- ArkingDEChakravartiAUnderstanding cardiovascular disease through the lens of genome-wide association studiesTrends Genet20092538739419716196
- PurcellSNealeBTodd-BrownKPLINK: a tool set for whole-genome association and population-based linkage analysesAm J Hum Genet20078155957517701901
- AulchenkoYSRipkeSIsaacsAvan DuijnCMGenABEL: an Rlibrary for genome-wide association analysisBioinformatics2007231294129617384015
- RobertsRStewartAFGenes and coronary artery disease: where are we?J Am Coll Cardiol2012601715172123040572
- ManolioTACollinsFSCoxNJFinding the missing heritability of complex diseasesNature200946174775319812666
- HindorffLAJunkinsHAMehtaJPManolioTAA catalog of published genome-wide association studies Available from: http://www.genome.gov/gwastudiesAccessed November 4, 2013
- MarianAJChallenges in medical applications of whole exome/genome sequencing discoveriesTrends Cardiovasc Med20122221922322921985
- AlmasyLThe role of phenotype in gene discovery in the whole genome sequencing eraHum Genet20121311533154022722752
- HelgadottirAThorleifssonGManolescuAA common variant on chromosome 9p21 affects the risk of myocardial infarctionScience20073161491149317478679
- McPhersonRPertsemlidisAKavaslarNA common allele on chromosome 9 associated with coronary heart diseaseScience20073161488149117478681
- Wellcome Trust Case Control ConsortiumGenome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controlsNature200744766167817554300
- DupuisJLangenbergCProkopenkoINew genetic loci implicated in fasting glucose homeostasis and their impact on type 2 diabetes riskNat Genet20104210511620081858
- EhretGBMunroePBRiceKMGenetic variants in novel pathways infuence blood pressure and cardiovascular disease riskNature201147810310921909115
- HeidIMJacksonAURandallJCMeta-analysis identifies 13 new loci associated with waist-hip ratio and reveals sexual dimorphism in the genetic basis of fat distributionNat Genet20104294996020935629
- SpeliotesEKWillerCJBerndtSIAssociation analyses of 249,796 individuals reveal 18 new loci associated with body mass indexNat Genet20104293794820935630
- TeslovichTMMusunuruKSmithAVBiological, clinical and population relevance of 95 loci for blood lipidsNature201046670771320686565
- VoightBFScottLJSteinthorsdottirVTwelve type 2 diabetes susceptibility loci identified through large-scale association analysisNat Genet20104257958920581827
- WainLVVerwoertGCO’ReillyPFGenome-wide association study identifies six new loci influencing pulse pressure and mean arterial pressureNat Genet2011431005101121909110
- AbifadelMVarretMRabesJPMutations in PCSK9 cause autosomal dominant hypercholesterolemiaNat Genet20033415415612730697
- LambertGSjoukeBChoqueBKasteleinJJHovinghGKThe PCSK9 decadeJ Lipid Res2012532515252422811413
- RothEMMcKenneyJMHanotinCAssetGSteinEAAtorvastatin with or without an antibody to PCSK9 in primary hypercholesterolemiaN Engl J Med20123671891190023113833
- McPhersonRChromosome 9p21.3 locus for coronary artery disease: how little we knowJ Am Coll Cardiol201362151382138323933540
- AgueroFDeganoIRSubiranaIImpact of a partial smoke-free legislation on myocardial infarction incidence, mortality and case-fatality in a population-based registry: the REGICOR studyPLoS One20138e5372223372663
- PerkJDe BackerGGohlkeHEuropean guidelines on cardiovascular disease prevention in clinical practice (version 2012)Rev Esp Cardiol20126566241
- Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in AdultsExecutive Summary of The Third Report of The National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, And Treatment of High Blood Cholesterol In Adults (Adult Treatment Panel III)JAMA20012852486249711368702
- WilsonPWD’AgostinoRBLevyDBelangerAMSilbershatzHKannelWBPrediction of coronary heart disease using risk factor categoriesCirculation199897183718479603539
- MarrugatJVilaJBaena-DiezJMRelative validity of the 10-year cardiovascular risk estimate in a population cohort of the REGICOR studyRev Esp Cardiol20116438539421482004
- WangTJAssessing the role of circulating, genetic, and imaging biomarkers in cardiovascular risk predictionCirculation201112355156521300963
- CandoreGBalistreriCRCarusoMPharmacogenomics: a tool to prevent and cure coronary heart diseaseCurr Pharm Des2007133726373418220812
- EvansWEMcLeodHLPharmacogenomics – drug disposition, drug targets, and side effectsN Engl J Med200334853854912571262
- MarinFGonzalez-ConejeroRCapranzanoPBassTARoldanVAngiolilloDJPharmacogenetics in cardiovascular antithrombotic therapyJ Am Coll Cardiol2009541041105719744613
- MotulskyAGDrug reactions enzymes, and biochemical geneticsJ Am Med Assoc195716583583713462859
- RosesADPharmacogenetics and future drug development and deliveryLancet20003551358136110776762
- VooraDGinsburgGSClinical application of cardiovascular pharmacogeneticsJ Am Coll Cardiol20126092022742397
- VerschurenJJTrompetSWesselsJAA systematic review on pharmacogenetics in cardiovascular disease: is it ready for clinical application?Eur Heart J20123316517521804109
- SimonJALinFHulleySBPhenotypic predictors of response to simvastatin therapy among African-Americans and Caucasians: the Cholesterol and Pharmacogenetics (CAP) StudyAm J Cardiol20069784385016516587
- IakoubovaOASabatineMSRowlandCMPolymorphism in KIF6 gene and benefit from statins after acute coronary syndromes: results from the PROVE IT-TIMI 22 studyJ Am Coll Cardiol20085144945518222355
- IakoubovaOATongCHRowlandCMAssociation of the Trp719Arg polymorphism in kinesin-like protein 6 with myocardial infarction and coronary heart disease in 2 prospective trials: the CARE and WOSCOPS trialsJ Am Coll Cardiol20085143544318222353
- HopewellJCParishSClarkeRNo impact of KIF6 genotype on vascular risk and statin response among 18,348 randomized patients in the heart protection studyJ Am Coll Cardiol2011572000200721458191
- RidkerPMMacFadyenJGGlynnRJChasmanDIKinesin-like protein 6 (KIF6) polymorphism and the efficacy of rosuvastatin in primary preventionCirc Cardiovasc Genet2011431231721493817
- LinkEParishSArmitageJSLCO1B1 variants and statin-induced myopathy – a genomewide studyN Engl J Med200835978979918650507
- JohnsonJACavallariLHBeitelsheesALLewisJPShuldinerARRodenDMPharmacogenomics: application to the management of cardiovascular diseaseClin Pharmacol Ther20119051953121918509
- ZabalzaMSubiranaISalaJMeta-analyses of the association between cytochrome CYP2C19 loss- and gain-of-function polymorphisms and cardiovascular outcomes in patients with coronary artery disease treated with clopidogrelHeart20129810010821693476
- US Department of Health and Human ServicesInformation on clopidogrel bisulfate. 27-10-2007 Available from: http://www.fda.gov/Drugs/DrugSafety/PostmarketDrugSafetyInformationforPatientsandProviders/ucm190836.htmAccessed November 4, 2013
- HolmesDRJrDehmerGJKaulSLeiferDO’GaraPTSteinCMACCF/AHA Clopidogrel clinical alert: approaches to the FDA “boxed warning”: a report of the American College of Cardiology Foundation Task Force on Clinical Expert Consensus Documents and the American Heart AssociationCirculation201012253755720585015
- BauerTBoumanHJvan WerkumJWFordNFten BergJMTaubertDImpact of CYP2C19 variant genotypes on clinical efficacy of antiplatelet treatment with clopidogrel: systematic review and meta-analysisBMJ2011343d458821816733
- HolmesMVPerelPShahTHingoraniADCasasJPCYP2C19 genotype, clopidogrel metabolism, platelet function, and cardiovascular events: a systematic review and meta-analysisJAMA20113062704271422203539
- MaoucheSSchunkertHStrategies beyond genome-wide association studies for atherosclerosisArterioscler Thromb Vasc Biol20123217018122258900
- EvangelouEIoannidisJPMeta-analysis methods for genome-wide association studies and beyondNat Rev Genet20131437938923657481
- PrinsBPLagouVAsselbergsFWSniederHFuJGenetics of coronary artery disease: genome-wide association studies and beyondAtherosclerosis201222511022698794
- ManolioTABringing genome-wide association findings into clinical useNat Rev Genet20131454955823835440
- ChatterjeeNWheelerBSampsonJHartgePChanockSJParkJHProjecting the performance of risk prediction based on polygenic analyses of genome-wide association studiesNat Genet20134540040323455638
- HudsonKLHolohanMKCollinsFSKeeping pace with the times – the Genetic Information Nondiscrimination Act of 2008N Engl J Med20083582661266318565857
- NoraJJLortscherRHSpanglerRDNoraAHKimberlingWJGenetic-epidemiologic study of early-onset ischemic heart diseaseCirculation1980615035087353240
- ZdravkovicSWienkeAPedersenNLMarenbergMEYashinAIde FaireUHeritability of death from coronary heart disease: a 36-year follow-up of 20 966 Swedish twinsJ Intern Med200225224725412270005
- WienkeAHolmNVSkyttheAYashinAIThe heritability of mortality due to heart diseases: a correlated frailty model applied to Danish twinsTwin Res2001426627411665307
- PeyserPABielakLFChuJSHeritability of coronary artery calcium quantity measured by electron beam computed tomography in asymptomatic adultsCirculation200210630430812119244
- XiangAHAzenSPBuchananTAHeritability of subclinical atherosclerosis in Latino families ascertained through a hypertensive parentArterioscler Thromb Vasc Biol20022284384812006400
- FoxCSPolakJFChazaroIGenetic and environmental contributions to atherosclerosis phenotypes in men and women: heritability of carotid intima-media thickness in the Framingham Heart StudyStroke20033439740112574549
- SwanLBirnieDHInglisGConnellJMHillisWSThe determination of carotid intima medial thickness in adults – a population-based twin studyAtherosclerosis200316613714112482560
- NorthKEMacCluerJWDevereuxRBHeritability of carotid artery structure and function: the Strong Heart Family StudyArterioscler Thromb Vasc Biol2002221698170312377752
- HuntKJDuggiralaRGoringHHGenetic basis of variation in carotid artery plaque in the San Antonio Family Heart StudyStroke2002332775278012468769
- HennekensCHBuringJEEpidemiology in MedicineBoston, MALittle, Brown and Company1987
- HirschhornJNLohmuellerKByrneEHirschhornKA comprehensive review of genetic association studiesGenet Med20024456111882781
- HulleySCummingsSRBrownerWSDesigning Clinical Research: An Epidemiologic ApproachBaltimore, MDLippincott, Williams and Wilkins2001
- KhouryMJBeatyTCohenBFundamentals of Genetic EpidemiologyNew York, NYOxford University Press1993
- IoannidisJPWhy most discovered true associations are infatedEpidemiology20081964064818633328
- IoannidisJPWhy most published research findings are falsePLoS Med20052e12416060722
- PearsonTAManolioTAHow to interpret a genome-wide association studyJAMA20082991335134418349094
- DaviesRWDandonaSStewartAFImproved prediction of cardiovascular disease based on a panel of single nucleotide polymorphisms identified through genome-wide association studiesCirc Cardiovasc Genet2010346847420729558
- AndersonJLHorneBDCampNJJoint effects of common genetic variants from multiple genes and pathways on the risk of premature coronary artery diseaseAm Heart J201016025025620691829
- QiLMaJQiQHartialaJAllayeeHCamposHGenetic risk score and risk of myocardial infarction in HispanicsCirculation201112337438021242481
- QiLParastLCaiTGenetic susceptibility to coronary heart disease in type 2 diabetes: 3 independent studiesJ Am Coll Cardiol2011582675268222152955
- LvXZhangYRaoSJoint effects of genetic variants in multiple loci on the risk of coronary artery disease in Chinese Han subjectsCirc J2012761987199222664640
- PatelRSSunYVHartialaJAssociation of a genetic risk score with prevalent and incident myocardial infarction in subjects undergoing coronary angiographyCirc Cardiovasc Genet2012544144922767652
- HughesMFSaarelaOStritzkeJGenetic markers enhance coronary risk prediction in men: the MORGAM prospective cohortsPLoS One20127e4092222848412
- VaarhorstAALuYHeijmansBTLiterature-based genetic risk scores for coronary heart disease: the Cardiovascular Registry Maastricht (CAREMA) prospective cohort studyCirc Cardiovasc Genet2012520220922373668
- MorrisonACBareLAChamblessLEPrediction of coronary heart disease risk using a genetic risk score: the Atherosclerosis Risk in Communities studyAm J Epidemiol2007166283517443022
- KathiresanSMelanderOAnevskiDPolymorphisms associated with cholesterol and risk of cardiovascular eventsN Engl J Med20083581240124918354102
- TalmudPJCooperJAPalmenJChromosome 9p21.3 coronary heart disease locus genotype and prospective risk of CHD in healthy middle-aged menClin Chem20085446747418250146
- BrautbarABallantyneCMLawsonKImpact of adding a single allele in the 9p21 locus to traditional risk factors on reclassification of coronary heart disease risk and implications for lipid-modifying therapy in the Atherosclerosis Risk in Communities studyCirc Cardiovasc Genet2009227928520031596
- PaynterNPChasmanDIBuringJEShiffmanDCookNRRidkerPMCardiovascular disease risk prediction with and without knowledge of genetic variation at chromosome 9p21.3Ann Intern Med2009150657219153409
- PaynterNPChasmanDIPareGAssociation between a literature-based genetic risk score and cardiovascular events in womenJAMA201030363163720159871
- RipattiSTikkanenEOrho-MelanderMA multilocus genetic risk score for coronary heart disease: case-control and prospective cohort analysesLancet20103761393140020971364
- ShiffmanDO’MearaESRowlandCMThe contribution of a 9p21.3 variant, a KIF6 variant, and C-reactive protein to predicting risk of myocardial infarction in a prospective studyBMC Cardiovasc Disord2011111021406102
- ThanassoulisGPelosoGMPencinaMJA genetic risk score is associated with incident cardiovascular disease and coronary artery calcium – the Framingham Heart StudyCirc Cardiovasc Genet2012511312122235037
- Lluis-GanellaCSubiranaILucasGAssessment of the value of a genetic risk score in improving the estimation of coronary riskAtherosclerosis201222245646322521901
- GransboKAlmgrenPSjogrenMChromosome 9p21 genetic variation explains 13% of cardiovascular disease incidence but does not improve risk predictionJ Intern Med201327423324023480785
- IsaacsAWillemsSMBosDRisk scores of common genetic variants for lipid levels infuence atherosclerosis and incident coronary heart diseaseArterioscler Thromb Vasc Biol2013332233223923766260
- GannaAMagnussonPKPedersenNLMultilocus genetic risk scores for coronary heart disease predictionArterioscler Thromb Vasc Biol2013332267227223685553
- TikkanenEHavulinnaASPalotieASalomaaVRipattiSGenetic risk prediction and a 2-stage risk screening strategy for coronary heart diseaseArterioscler Thromb Vasc Biol2013332261226623599444