Abstract
The microtubule network, the major organelle of the eukaryotic cytoskeleton, is involved in cell division and differentiation but also with many other cellular functions. In plants, microtubules seem to be involved in the ordered deposition of cellulose microfibrils by a so far unknown mechanism. Microtubule-associated proteins (MAP) typically contain various domains targeting or binding proteins with different functions to microtubules. Here we have investigated a proposed microtubule-targeting domain, TPX2, first identified in the Kinesin-like protein 2 in Xenopus. A TPX2 containing microtubule binding protein, PttMAP20, has been recently identified in poplar tissues undergoing xylogenesis. Furthermore, the herbicide 2,6-dichlorobenzonitrile (DCB), which is a known inhibitor of cellulose synthesis, was shown to bind specifically to PttMAP20. It is thus possible that PttMAP20 may have a role in coupling cellulose biosynthesis and the microtubular networks in poplar secondary cell walls. In order to get more insight into the occurrence, evolution and potential functions of TPX2-containing proteins we have carried out bioinformatic analysis for all genes so far found to encode TPX2 domains with special reference to poplar PttMAP20 and its putative orthologs in other plants.
Introduction
Similar to other eukaryotes, the cytoskeleton of plant cells consists of tubulin and actin networks which render multiple morphological functions during various phases of cellular development, growth, and movement (CitationVassilyev 1996; CitationHasek et al 2003; CitationMathur 2004; CitationWasteneys and Yang 2004). Unlike animal cells, plant cells have prominent cell walls formed by networks of cellulose microfibrils, hemicelluloses, lignin, and structural proteins. In secondary cell walls, the cellulose microfibrils are strictly aligned and form multiple layers designated S1, S2, and S3, which are characterized by different microfibril angles. Several lines of evidence suggest that interphase cortical microtubules somehow influence the ordered deposition of cellulose microfibrils (CitationGoddard et al 1994; CitationRoberts et al 2004; CitationOda et al 2005). For example, it has been shown that all three secondary cell wall associated CesA proteins colocalize with bands of cortical microtubules in older xylem vessels in Arabidopsis (CitationGardiner et al 2003). It has also been demonstrated recently that the CesA complexes in the Arabidopsis plasma membrane move at constant rates in linear tracts that coincide with cortical microtubules (CitationParadez et al 2006). Furthermore, studies of developing wood cells in both conifers and angiosperms indicate reorientation of microtubules upon changes in microfibril orientation during the formation of the successive cell layers S1–S3 (CitationChaffey et al 1997, Citation1999, Citation2002; CitationFunada et al 2001).
The assembly, bundling and stability of microtubules depend on the activity of various microtubule-associated proteins (MAPs) and their regulatory kinases and phosphatases (CitationSedbrook 2004; CitationAmos and Schlieper 2005). Domains are conserved sequence units that frequently determine the function of proteins and that often correspond to structural units (CitationElofsson and Sonnhammer 1999). Microtubule associated proteins typically contain a variety of conserved domains and motifs (CitationAmos and Schlieper 2005). One of these is TPX2 (Pfam: PF06886), a putative microtubule-targeting domain first identified in Kinesin-like proteins in Xenopus (CitationWittmann et al 2000; CitationBayliss et al 2003; CitationBrunet et al 2004). The current Pfam database (July 2007) contains about 68 proteins containing significantly conserved TPX2 domains. Among plant MAPs (CitationSedbrook 2004), WVD2 and WVL1 in Arabidopsis contain a TPX2 domain (CitationKorolev et al 2007; CitationPerrin et al 2007). We have recently identified a new MAP, denoted PttMAP20, which exhibits particularly high level of expression in the wood forming tissues of hybrid aspen (Populus tremula × P. tremuloides) (Rajangam et al pers comm). We also showed that this protein binds specifically the herbicide 2,6-dichlorobenzonitrile (DCB), which is a known inhibitor of cellulose synthesis (CitationSabba and Vaughn 1999). This finding is consistent with the hypothesis that cellulose synthesis is coupled with cortical microtubules (CitationGoddard et al 1994; CitationRoberts et al 2004; CitationOda et al 2005), and suggests that PttMAP20 may have a role in mediating such interactions in poplar secondary cell walls.
In order to get more insight into the occurrence, evolution, and potential functions of TPX2-containing proteins we have carried out a bioinformatic analysis for all genes so far found to encode TPX2 domains with special reference to the poplar PttMAP20 and its putative orthologs in other plant species.
Material and methods
Sequence retrieval
Genome sequences and their allied gene predictions were retrieved for Arabidopsis (v 5, January 2004, tigr.org), rice (v 4, January 12, 2006, rice.tigr.org) and Populus trichocarpa (v 1.1, 2006, jgi.org, DoE Joint Genome Institute and Poplar Genome Consortium). A prerelease of Medicago truncatula genome (December 14, 2006), including gene predictions, was downloaded from http://www.medicago.org/. Zea maize contigs were analyzed and downloaded from www.plantgdb. org in April 2007. Animal TPX2 proteins (Q2U500, A2APB8, Q6P9S6, Q6DDV8, Q643R0, Q805A9, Q6NUF4, Q5ZIC6, TPX2, Q5RAF2, Q96RR5 and Q8BTJ3) were downloaded from the Pfam website (http://pfam.sanger.ac.uk/), and redundant sequences were ignored.
Similarity search and alignments
Sequence similarity searches for mRNA and EST support for genes were primarily conducted using NCBI’s online Blast using full-length protein sequences. The HMMER package (CitationEddy 1998) was used for the alignment and identification of TPX2 domains, using the Pfam model PF06886.1. The Pfam website was used for general domain architectural analysis. The assembly of ESTs to putative transcripts was done with CAP3 (CitationHuang and Madan 1999). Multialignments were computed using Kalign (CitationLassmann and Sonnhammer 2005), Muscle (CitationEdgar 2004), and MAFFT (CitationKatoh et al 2002, Citation2005). Visualization of the alignments was done using TeXShade (CitationBeitz 2000). The quality of conservation of a sequence alignment of plant TPX2 domains was plotted using the EMBOSS plotcon software (Available from: http://bioweb.pasteur.fr/seqanal/interfaces/plotcon.html), with a standard window size of 4 for both DNA and protein sequences.
Phylogenetic analysis
Phylogeny studies were done using MrBayes (CitationRonquist and Huelsenbeck 2003). Each analysis had four MCMC chains running for 4 × 106 iterations, default thinning, and the first 10% iterations removed as burnin. The mixed amino acid model with gamma-distributed rate-change over sites was chosen. Analysis of possible adaptive evolution was performed with codeml in the PAML package (CitationYang 1997).
Gene mapping
Mapping of the transcripts or proteins to genome sequences and the determination of exon/intron-structure was done using Exonerate (CitationSlater and Birney 2005). Promoter analyses were conducted using TSSP (CitationSolovyev and Shahmuradov 2003) and PLACE (CitationHigo et al 1999). Phylogenetic footprinting for motif finding was done with MEME (CitationBailey and Elkan 1994; CitationBailey and Gribskov 1998) with settings chosen to look for up to five motifs, present in some but not necessarily all sequences. Local genomic alignments were computed using DBA (CitationJareborg et al 1999).
Expression profiling
The expression profiling data for the Arabidopsis TPX2 genes were extracted from the Gene Atlas performed with ATH1 (22K full genome Arabidopsis Affymetrix GeneChip) available online http://www.arabidopsis.org/.
Results and discussion
Identification of TPX2 proteins
Proteins containing a TPX2 domain were identified in the completely sequenced genomes of poplar (Populus trichocarpa) (CitationTuskan et al 2006), Arabidopsis thaliana (CitationArabidopsis Genome Initiative 2000), and rice (Oryza sativa) (CitationGoff et al 2002; CitationGoff 2005), using the Pfam model of TPX2. The fully sequenced animal genomes only contain one gene encoding a single TPX2 domain. In contrast, plant genomes were found to encode rich repertoires of different proteins containing a TPX2 domain, 14 in Arabidopsis, 10 in rice, and 19 in Populus. Here we have compared the TPX2 domains in all fully sequenced plant and animal genomes as well as other known TPX2 containing proteins from the Pfam database. Sequence alignments show that these proteins exhibit low or no similarity with each other beyond their TPX2 domains (). This indicates that the TPX2 domain is a common nominator of many multi-domain proteins that overall do not have common evolutionary origins. However, a common origin is apparent for the TPX2 domains suggesting that these domains share a similar function.
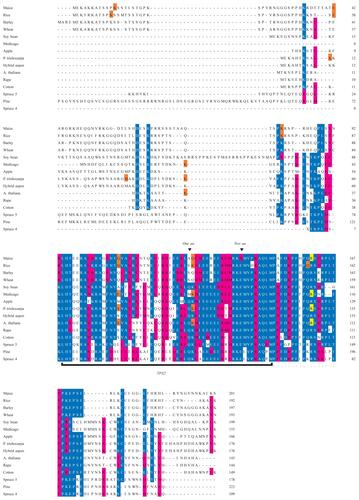
Figure 1 Sequence alignment of M20L proteins made with the MAFFT alignment tool. The TPX2 domain is marked with a black bar and the extended TPX2 domain by a dotted line under the sequences. Notes above the TPX2 domain indicate sites where residues are lost relative to the Pfam domain model of TPX2. The identity or similarity to a consensus sequence is indicated in blue and red (respectively), the last codon of an exon in orange, and the exon/intron boundary in frame 2 in yellow.
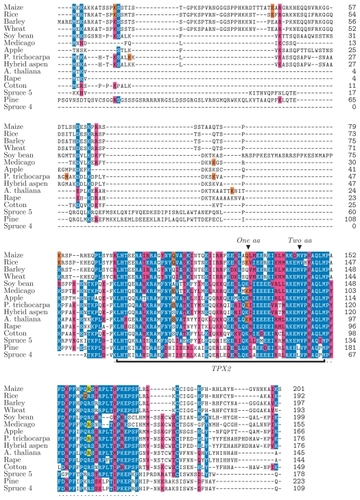
Identification and sequences analysis of PttMAP20 orthologs
Due to the possible involvement of PttMAP20 in cellulose biosynthesis (Rajangam et al pers comm.), putative orthologs (as defined by CitationFitch 1970) were searched for corresponding genes in all published plant genomes and in the NCBI dbEST (). The current annotations of the gene models Os09g13650.1 in rice and At5g37478 in A. thaliana had to be adjusted since sequences homologous to the other TPX2 proteins were detected beyond the current gene models (see Materials and Methods). Reannotation of the rice gene was facilitated by an EST sequence, NM_001069361.1, and in both cases the new gene models were more similar to PttMAP20 than the current gene models. summarizes the gene models identified in different plant species. These gene models are hereafter designated as ‘Map20-Like’ (M20L). None of the animal TPX2 proteins were found to show any significant similarity with PttMAP20 beyond the TPX2 domain (data not shown).
Table 1 A list of MAP20-Like gene models (M20L) in different plant species
Putative PttMAP20 orthologs were easy to detect among monocots and dicots by simple analysis of sequence similarity. In most cases, phylogenetic analysis (see below) would corroborate the highest scoring sequences as orthologs of PttMAP20. In cases when the best database hit was not an ortholog, the similarity score had already indicated a more distant relationship to PttMAP20.
In gymnosperms, however, thorough phylogenetic analysis was required in order to find putative orthologs of PttMAP20. In this way, 11 sequences in Pinus and 10 sequences in Picea (with ESTs from P. engelmanii, P. glauca, and P. sitchensis) were found to encode a TPX2 domain.
Multiple alignments of the MAP20-like proteins were computed using MUSCLE, MAFFT, and KALIGN, but no reliable full-length alignment could be found. In particular, there was little consensus at the N- and C-terminal ends of the proteins (see and Supplemental Figure 1 for MAFFT and MUSCLE alignments, respectively). However, the programs did agree on a strongly conserved 81-residue region containing the TPX2 domain, here called the extended TPX2 domain. It was verified that no other known domain structures are located in the regions flanking the TPX2 domain of the M20L proteins.
Conservation of extended TPX2 domain of M20L
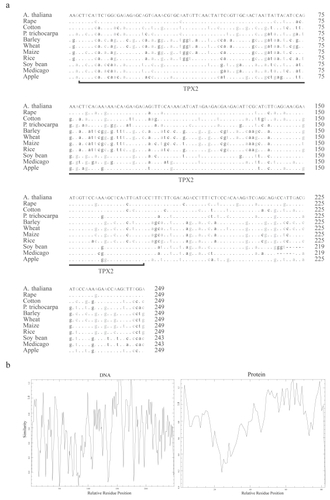
To understand the conservation of the TPX2 domain in plants, a multiple alignment was made with DNA sequences of the extended TPX2 domain within the M20L sequences. The similarity plots were made with both DNA and protein sequences of the extended M20L TPX2 domain to check the quality of conservation. The similarity score was low for the DNA sequences compared to protein sequences (), mainly due to silent mutations in the 3rd nucleotide of the triplet codon ().
Figure 2 (a) A multiple alignment made with DNA sequences of the extended TPX2 domains of the M20L protein sequences. Differences with respect to A. thaliana are noted, and the conserved bases are indicated by dots. The third codon position is printed in grey. (b) Similarity plot graph made with the extended TPX2 domain with reference to relative residue position (both DNA and Protein sequences) using EMBOSS plotcon software using a standard window size of 4.
Phylogenetic analysis of TPX2 domain
Molecular evolution of the TPX2 domain was studied with phylogenetic analysis of all available TPX2 domain sequences (). The phylogenetic tree has two distinct branches, one with and one without animals. The plant-only branch contains a subtype of TPX2 containing the so-called KLEEK motif previously identified in the Arabidopsis WVD2 protein (CitationYuen et al 2003). Proteins containing a KLEEK motif form a monophyletic clade, and have several branches each with its own monocot and dicot sub-branches, as exemplified by WDL5/WDL6 and WDL4 in . The animal-containing branch is where our analysis put the M20L genes. Notice that gymnosperm sequences are present in both major branches and that there are two likely orthologs to PttMAP20 in Picea.
Figure 3 Phylogenetic tree made with all the available and newly found eukaryotic proteins containing a TPX2 domain. The Bayesian posterior probability is indicated by numbers to the right of the edge in question. The clades with M20L proteins and KLEEK motif are marked. Genes with reported phenotypes in Arabidopsis are marked in red (CitationYuen et al 2003). The gene noted as AtTPX2 by (CitationPerrin et al 2007) is annotated in green.
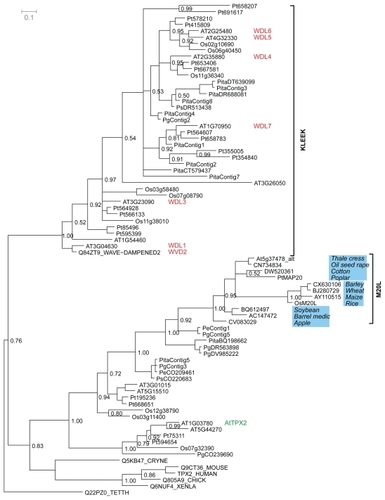
The subtrees in the phylogeny mostly follow the established species history (), but there are peculiarities to note. For example, the M20L orthologs deviate from the established species phylogeny (see eg, the apple sequence) and the branching is not fully resolved. The lack of phylogenetic resolution is seen also in other parts of the tree, including several branches with low statistical support. However, these problems are to be expected as the phylogeny is estimated from the short TPX2 domain alone, with only 58 informative positions in the alignment. We chose to root the phylogeny using the protozoan Tetrahymena thermophila as an outgroup. Although the eukaryotic rooting has long been contested, recent data suggests protozoa as outgroup to animals and plants (CitationArisue et al 2005; CitationCiccarelli et al 2006). The displayed structure of the tree, although weakly supported at the crucial edges, allow us to speculate that a first duplication occurred before plants and animals diverged. This would imply that animals lost at least one TPX2 gene, while plants took advantage of the redundancy by further evolutionary diversification. This old duplication could reflect different functions in the two main branches of the TPX2 phylogeny. Regardless of where the root of the phylogeny is correctly placed, the expansion of proteins containing a TPX2 domain among plants is in striking contrast to animal TPX2. There are several duplications implied for plants in both parts of the tree, but animals contain only one TPX2 gene.
Figure 4 A phylogenetic tree made with the extended TPX2 domain.
All genes in the TPX2 gene family in P. trichocarpa, except MAP20, seem to come in pairs and they are all more recent than the last species split in this phylogeny. This is consistent with the likely whole-genome duplication event (CitationTuskan et al 2006).
While there are plenty of duplications in the TPX2 gene family in general, none of the species included in the present study has more than a single copy of M20L genes. Such a singleton representation suggest that M20L genes have characteristics that render them duplication resistant (CitationPaterson et al 2006) during events of polyploidy. A recent study on gene family evolution dynamics (CitationWapinski et al 2007) showed that duplication resistant characteristics are typical for genes related to essential growth processes, genes active in organelles and nucleus, and genes essential for viability. It is possible that the proposed, but as yet undefined role of MAP20 in cellulose biosynthesis would fulfill the requirements of such a process in angiosperms.
Phylogenetic analysis of the extended TPX2 domain in M20L proteins
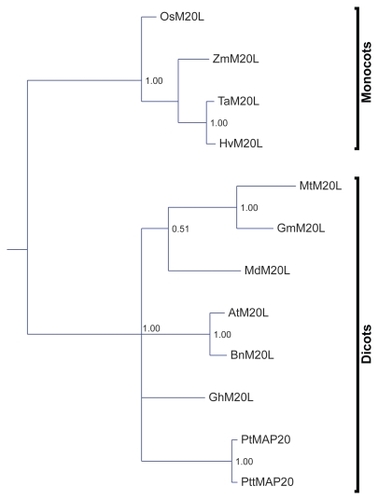
The M20L clade was revisited by reconstructing a phylogeny based on all Angiosperm-extended TPX2 domains of M20L whereby the branching was significantly improved. Several branches are still not resolved or lack statistical support. Those parts that do have statistical support are in agreement with the accepted species tree. In particular, the M20L phylogeny clearly separates monocots and dicots ().
The M20L phylogeny formed the basis for a search for signs of adaptive evolution (CitationYang 1997; CitationBielawski and Yang 2003). Only the extended TPX2 domain was studied since we could not derive a reliable multialignment over the full protein sequences ( and Supplemental Figure 1). The hypothesis was that key properties in this conserved region could have changed, especially after the monocot/dicot split. However, no signs of positive selection were found, either over branches or on sequence sites. The extended TPX2 domain thus seems to have been under negative selection only.
Genomic organization of TPX2 genes
The organization of TPX2 genes was mapped in all the three fully sequenced model plants: the universal model Arabidopsis, the wood model Populus and the grass model Oryza (). We could not find a general pattern for the TPX2 gene locations in the three genomes. Synteny comparisons suggested that many recent paralogs, eg, WDL1/WVD2 and WDL6/WDL5 in our phylogeny, could be due to large scale duplications (). The linkage groups previously found in the three species were used to overlay the location of these gene pairs (CitationArabidopsis Genome Initiative 2000; CitationGoff et al 2002; CitationGoff 2005; CitationTuskan et al 2006). The many recent paralogs, especially in Poplar, could make the gene localization ambiguous, but the highest scoring alignment stood out in cases. When aligning a protein sequence to the genome, the second-best match had incomplete sequence coverage, several or many mutations, and significantly lower score compared to the highest scoring match. The TPX2 paralogs in the poplar genome that arose due to the genome duplication are noted in the gene models and their respective linkage groups ( and ). Microarray experiments in Arabidopsis indicate that WDL1 (At3g04630) and WVD2 (At1g3780) have similar expression patterns () with increased expression in inflorescence tissue, rich in cellulose biosynthesis, consistent with a duplicated regulatory module. Even WDL5 (At4g32330) exhibits somewhat increased expression in inflorescence tissue.
Figure 5 Genomic organization (to scale) of TPX2 genes in the genomes of (a) Populus trichocarpa, (b) Oryza sativa, and (c) Arabidopsis thaliana.
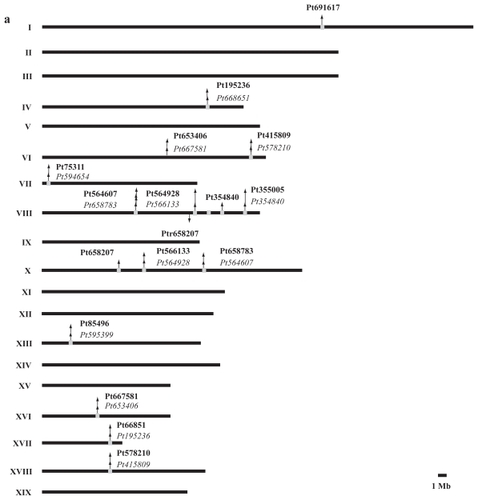

Figure 6 Relative expression levels of the TPX2 genes in different tissue types of Arabidopsis thaliana. Data from http://www.arabidopsis.org/. The expression patterns for WDL1 (At3g04630) and WVD2 (At1g3780) are roughly the same, with elevated levels in inflorescence tissue.
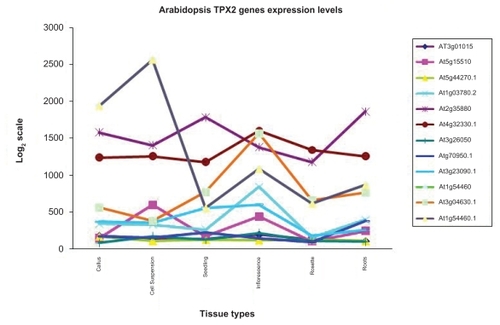
Table 2 Gene pairs and their respective linkage groups present in Populus trichocarpa, Oryza sativa and Arabidopsis thaliana
A search for TPX2-containing pseudogenes was conducted in the P. trichocarpa genome using translating Blast and the known TPX2 domains. Even at a relatively low threshold (E = 0.001), no hits were found outside the known TPX2 genes. Unless some predicted genes are false positives, the P. trichocarpa does not have any TPX2 containing pseudogenes.
Gene structure determination and comparison of M20L genes
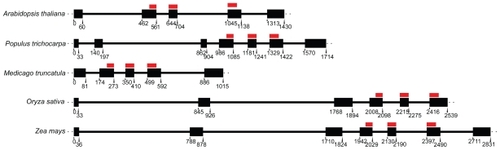
A comparison of the exon/intron structures of known M20L genes in A. thaliana, P. trichocarpa, O. sativa, M. truncatula, and Z. mays revealed variation in both the exon numbers and the intron lengths (). In particular, monocot members showed longer introns. Interestingly, the TPX2 domain intersects three exons in all studied species and the domain covers 48 bp in the first and 63 bp in the last of the three exons. Consequently, the mid exon is 60 bp in all cases. This is another indication of strong selective pressure on the TPX2 domain.
Figure 7 M20L gene structure: the positions (in base pairs from the translation start) of gene CDS are marked, to scale, with dark boxes while the thick lines correspond to introns. The TPX2 regions are marked with dark red lines.
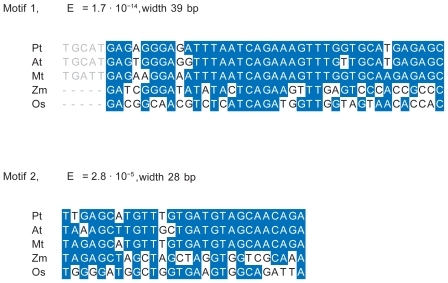
In order to identify potential gene regulatory elements, 3000 bp of the genome sequence was extracted upstream from the M20L start-of-translation point in O. sativa, A. thaliana, M. truncatula, and P. trichocarpa. In M. truncatula the M20L gene was found to be located in a contig (CT963077, from chromosome 3) including 3000 bp upstream of the translation start of the gene. The Zea mays gene had a match against two contigs (ZmGSStuc11-12-04.70298.1 and ZmGSStuc11-12-04.9118.1). As they were seemingly overlapping, they were reassembled (using CAP3) into one contig from which 1975 bp upstream of start-of-translation was extracted. In an alignment of the five genomic regions, the pairwise identity was lower than 44% in all cases, indicating considerable divergence on regions without selection. However, two motifs were revealed using phylogenetic footprinting ( and ). Motif 1 (39 bp) was significant in all five species (E = 1.7 × 10−14). In dicots, a slightly wider motif of 43 bp was found (). Motif 2 consisting of 28 bp was also found in all five species (E = 2.8 × 10−5) but this width was reduced by two bases on the 5′ flanking region if applying MEME to dicots only. No further significant motifs could be found in all five species. These motifs were, with small differences, corroborated by pairwise genome alignments using DBA. It was furthermore verified that the motifs are noncoding and not covered by any ESTs, and are hence not likely to be part of the translated regions of these genes. It has been demonstrated (CitationBejerano et al 2004; CitationSandelin et al 2004), that extremely conserved regions can be regulators for genes far away from the motifs, but the proximity to the M20L genes make them interesting and ideal candidates for experiments. These motifs are larger than what is common for a transcription factor binding site (TFBS), suggesting that they may represent two regulatory modules. It is interesting to note that although dicots and monocots share little similarity in TPX2 gene structure and protein sequence, their TFBS motifs are well conserved.
Figure 8 Possible regulatory elements and promoters of M20L. Upstream regions with predicted TATA boxes are indicated by a green triangle, motif 1 by a red box, motif 2 by a blue box, and EST hit regions by dark pink lines. For A. thaliana, the core promoter given in AGRIS (CitationPalaniswamy et al 2006) is indicated by a red line. The lines are scaled to actual sequence length and positions are given in base pairs from translation start.
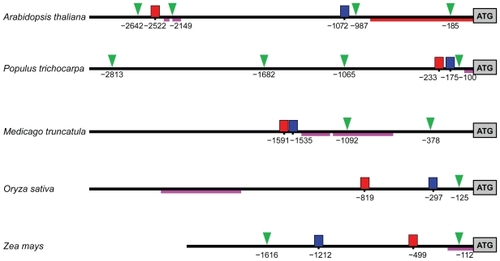
Figure 9 Sequence alignments for the motifs 1 and 2. Blue color indicates identity to the consensus sequence. The left flank of motif 1 shows the extension of this motif in dicots.
There were no promoter regions found by homology and known cis-acting regulatory elements had no hits of statistical significance. Putative TATA-boxes upstream of M20L were predicted and the same regions were also used to search dbEST in order to identify likely UTRs. In Poplar there are 4 putative TATA boxes. Considering EST hits at this region, the TATA box at the position -100 might be important (). A similar arrangement is seen in M. truncatula although with two TATA boxes downstream of the TFBS motifs. In this case, ESTs suggest a promoter, which is close to the conserved TFBS motifs similar to Populus, but this would render both predicted TATA boxes false. The locations of the motifs in Arabidopsis are quite different in that they are distant from each other. Short EST hits are reported for the downstream region of the first motif, but offer no real support for any of the predicted TATA boxes. Looking at the monocots, O. sativa has the motifs in the same order as the dicots and EST hits are found in the downstream region of motif 2, clearly an extension of the first exon. It is reasonable to assume these ESTs represent an UTR and a predicted TATA box is consistent with this hypothesis. The results are similar for Z. mays, with exon-extending and UTR-indicating EST hits, except that the order of the motifs is switched. The long EST hit prior to the motifs in Oryza, as well as the long EST hit in Medicago, escape our interpretation, but in the light of the results of the ENCODE project (CitationBirney et al 2007) this might be randomly transcribed regions.
Conclusions
Proteins containing a TPX2 domain are only found in highly evolved members of Eukaryota. Representative members of this family of proteins show an interesting species distribution as reported in Pfam (July, 2007). Though this representation might still reflect the prevailing sequence data available across the different species, there are no exceptions so far. Among the Protists, TPX2 is reported in the Ciliate Tetrahymena thermophila SB210 where the cilia is made up of assembled tubulin and axonemal protein units (CitationRedeker et al 2005). There are 15 reported TPX2 proteins in animals, representing only the vertebrates, and 2 in fungi (order: Tremellales). As many as 50 TPX2-containing plant proteins have been reported in Pfam and all of them so far in Angiosperms. However, with stringent searches using the EST database, more TPX2 gene sequences were identified also in the Gymnosperms. The TPX2 domain thus seems to be a common nominator of a number of plant and animal proteins.
Analyses of domain structures in different multidomain proteins reveal that domains pairing with other domains generally occur in the same combination (CitationApic et al 2001; CitationVogel et al 2004). This suggests that such domains have evolved interdependent functions and that the order of the domains has therefore been maintained during evolution. All known animal TPX2 proteins have an Aurora binding domain as well as RNA binding and recognition domains, and thus probably fulfil the same function in the different species (CitationWeiner and Bornberg-Bauer 2006). In contrast, the TPX2 domain is the only clearly conserved part of these proteins in different plant species, and the overall sizes and sequences of these proteins are quite different. It is therefore likely that, apart from a capacity to interact with microtubules, these proteins have different functions.
Plant TPX2 genes in general are duplicating liberally while M20L genes are apparently strictly resistant to duplications. The extended TPX2 domains in the M20L proteins are under strong selective pressure as evidenced by the conservation of residues and nucleotide patterns and the exon/intron structure. Since the extended TPX2 domain is the sole strictly conserved part of these genes, it is arguably the source of the apparent duplication resistance in the M20L clade. We draw the conclusion that M20L is, in some respect, more important than its paralogs.
There is presently too little data to make a good interpretation of the origins of the TPX2 domain. However, there are signs that there was a first duplication before the separation of animals and plants. As more data become available, especially protist TPX2 genes and more gene-order data, this question may be resolvable.
Acknowledgments
We thank Professor Jens Lagergren for critical reading of the manuscript. This work was supported by the Swedish Research Council Formas (ASR, TTT). The authors report no conflicts of interest in this work.
Supplementary Files
Supplementary Figure 1 Sequence alignment of MAP20 proteins made with the MUSCLE alignment tool. The TPX2 domain is marked with a black bar and the extended TPX2 domain is indicated using dots. Notes above the TPX2 domain indicate where residues are lost relative to the Pfam domain model. Colors indicate similarity to consensus sequence.
Supplementary Table 1 Microtubule associated and binding protein reported in pfam by July 2007
Supplementary Table 2 Protein sequences of gene models
References
- AmosLASchlieperD2005Microtubules and mapsAdv Protein Chem712579816230114
- ApicGGoughJTeichmannSA2001Domain combinations in archaeal, eubacterial and eukaryotic proteomesJ Mol Biol3103112511428892
- Arabidopsis Genome Initiative2000Analysis of the genome sequence of the flowering plant Arabidopsis thalianaNature40879681511130711
- ArisueNHasegawaMHashimotoT2005Root of the Eukaryota tree as inferred from combined maximum likelihood analyses of multiple molecular sequence dataMol Biol Evol224092015496553
- BaileyTLElkanC1994Fitting a mixture model by expectation maximization to discover motifs in biopolymersProceedings of the Second International Conference on Intelligent Systems for Molecular BiologyAAAI PressMenlo Park, CA2836
- BaileyTLGribskovM1998Combining evidence using p-values: application to sequence homology searchesBioinformatics1448549520501
- BaylissRSardonTVernosI2003Structural basis of Aurora-A activation by TPX2 at the mitotic spindleMol Cell128516214580337
- BeitzE2000TeXshade: shading and labeling of multiple sequence alignments using LaTeX2eBioinformatics16135910842735
- BejeranoGPheasantMMakuninI2004Ultraconserved elements in the human genomeScience3041321515131266
- BielawskiJPYangZ2003Maximum likelihood methods for detecting adaptive evolution after gene duplicationJ Struct Func Genomics320112
- BirneyEStamatoyannopoulosJADuttaA2007Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot projectNature44779981617571346
- BrunetSSardonTZimmermanT2004Characterization of the TPX2 domains involved in microtubule nucleation and spindle assembly in Xenopus egg extractsMol Biol Cell1553182815385625
- ChaffeyNBarlowPSundbergB2002Understanding the role of the cytoskeleton in wood formation in angiosperm trees: hybrid aspen (Populus tremula × P. tremuloides) as the model speciesTree Physiol222394911874720
- ChaffeyNBarnettJBarlowP1999A cytoskeletal basis for wood formation in angiosperm trees: the involvement of cortical microtubulesPlanta2081930
- ChaffeyNJBarnettJRBarlowPW1997Cortical microtubule involvement in bordered pit formation in secondary xylem vessel elements of Aesculus hippocastanum L (Hippocastanaceae): A correlative study using electron microscopy and indirect immunofluorescence microscopyProtoplasma1976475
- CiccarelliFDDoerksTvon MeringC2006Toward automatic reconstruction of a highly resolved tree of lifeScience3111283716513982
- EddySR1998Profile hidden Markov modelsBioinformatics14755639918945
- EdgarRC2004MUSCLE: multiple sequence alignment with high accuracy and high throughputNucleic Acids Res321792715034147
- ElofssonASonnhammerELL1999A comparison of sequence and structure protein domain families as a basis for structural genomicsBioinformatics1548050010383473
- FitchWM1970Distinguishing homologous from analogous proteinsSyst Zool19991135449325
- FunadaRMiuraHShibagakiM2001Involvement of localized cortical microtubules in the formation of a modified structure of woodJ Plant Res1144917
- GardinerJCTaylorNGTurnerSR2003Control of cellulose synthase complex localization in developing xylemPlant Cell151740812897249
- GoddardRHWickSMSilflowCD1994Microtubule components of the plant-cell cytoskeletonPlant Physiol1041612232055
- GoffSA2005A draft sequence of the rice genome (Oryza sativa L. ssp. japonica) (April, pg 92, 2002)Science30987916081721
- GoffSARickeDLanTH2002A draft sequence of the rice genome (Oryza sativa L. ssp japonica)Science2969210011935018
- HasekJTrachtulcovaPKohlweinSD2003Colocalization of cortical microtubules and F-actin in Dipodascus magnusii using confocal laser scanning microscopyFolia Microbiol481778212800500
- HigoKUgawaYIwamotoM1999Plant cis-acting regulatory DNA elements (PLACE) database: 1999Nucleic Acids Res272973009847208
- HuangXQMadanA1999CAP3: A DNA sequence assembly programGenome Res98687710508846
- JareborgNBirneyEDurbinR1999Comparative analysis of noncoding regions of 77 orthologous mouse and human gene pairsGenome Res98152410508839
- KatohKKumaKTohH2005MAFFT version 5: improvement in accuracy of multiple sequence alignmentNucleic Acids Res33511815661851
- KatohKMisawaKKumaK2002MAFFT: a novel method for rapid multiple sequence alignment based on fast Fourier transformNucleic Acids Res3030596612136088
- KorolevAVBuschmannHDoonanJH2007AtMAP70-5, a divergent member of the MAP70 family of microtubule-associated proteins, is required for anisotropic cell growth in ArabidopsisJ Cell Sci1202241717567681
- LassmannTSonnhammerELL2005Kalign – an accurate and fast multiple sequence alignment algorithmBMC Bioinfo6298
- MathurJ2004Plant cytoskeleton: Reinforcing lines of division in plant cellsCurr Biol14R287915062125
- OdaYMimuraTHasezawaS2005Regulation of secondary cell wall development by cortical microtubules during tracheary element differentiation in Arabidopsis cell suspensionsPlant Physiol13710273615709154
- PalaniswamySKJamesSSunH2006AGRIS and AtRegNet. A platform to link cis-regulatory elements and transcription factors into regulatory networksPlant Physiol1408182916524982
- ParadezAWrightAEhrhardtDW2006Microtubule cortical array organization and plant cell morphogenesisCurr Opin Plant Biol9571817010658
- PatersonAHChapmanBAKissingerJC2006Many gene and domain families have convergent fates following independent whole-genome duplication events in Arabidopsis, Oryza, Saccharomyces and TetraodonTrends Genetics22597602
- PerrinRMWangYYuenCYL2007WVD2 is a novel microtubule-associated protein in Arabidopsis thalianaPlant J499617117319849
- RedekerVLevilliersNVinoloE2005Mutations of tubulin glycylation sites reveal cross-talk between the C termini of alpha- and beta-tubulin and affect the ciliary matrix in TetrahymenaJ Biol Chem28059660615492004
- RobertsAWFrostAORobertsEM2004Roles of microtubules and cellulose microfibril assembly in the localization of secondary-cell- wall deposition in developing tracheary elementsProtoplasma2242172915614483
- RonquistFHuelsenbeckJP2003MrBayes 3: Bayesian phylogenetic inference under mixed modelsBioinformatics191572412912839
- SabbaRPVaughnKC1999Herbicides that inhibit cellulose biosynthesisWeed Sci4775763
- SandelinABaileyPBruceS2004Arrays of ultraconserved non-coding regions span the loci of key developmental genes in vertebrate genomesBMC Genomics59915613238
- SedbrookJC2004MAPs in plant cells: delineating microtubule growth dynamics and organizationCurr Opin Plant Biol76324015491911
- SlaterGSBirneyE2005Automated generation of heuristics for biological sequence comparisonBMC Bioinfo631
- SolovyevVVShahmuradovIA2003PromH: promoters identification using orthologous genomic sequencesNucleic Acids Res313540512824362
- TuskanGADiFazioSJanssonS2006The genome of black cottonwood, Populus trichocarpa (Torr and Gray)Science313159660416973872
- VassilyevAE1996The cytoskeleton of animals and higher plants: The comparison of structure and functionsZhurnal Obshchei Biol57293325
- VogelCBashtonMKerrisonND2004Structure, function and evolution of multidomain proteinsCurr Opin Struct Biol142081615093836
- WapinskiIPfefferAFriedmanN2007Natural history and evolutionary principles of gene duplication in fungiNature449546117805289
- WasteneysGOYangYB2004New views on the plant cytoskeletonPlant Physiol13638849115591446
- WeinerJBornberg-BauerE2006Evolution of circular permutations in multidomain proteinsMol Biol Evol237344316431849
- WittmannTWilmMKarsentiE2000TPX2, a novel Xenopus MAP involved in spindle pole organizationJ Cell Biol14914051810871281
- YangZ1997PAML: a program package for phylogenetic analysis by maximum likelihoodComput Appl Biosci1355569367129
- YuenCYLPearlmanRSSilo-SuhL2003WVD2 and WDL1 modulate helical organ growth and anisotropic cell expansion in ArabidopsisPlant Physiol13149350612586874