 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Aims:
In many physiologic systems, the evolution from health to disease correlates with a loss of complexity in the system’s output. We analyze the difference in complexity of the glycemic profile in healthy volunteers (H), patients with the metabolic syndrome (MS), and patients with type 2 diabetes mellitus (DM).
Methods:
We measured interstitial fluid glucose every 5 minutes for 3 days in 10 H, 10 MS, and 10 DM. Complexity of the glycemic profile was evaluated by means of detrended fluctuation analysis (DFA). Mean amplitude of glycemic excursions (MAGE) was also calculated.
Results:
Glucose profile was more complex (lower DFA) in healthy subjects than in patients with MS or DM (mean DFA [SD]: H: 1.25 (0.10), MS: 1.39 (0.07), DM: 1.42 (0.10). ANOVA: F2,27 = 9.94, p = 0.001). DM had also a less complex profile than MS, but this difference was not statistically significant. There was an inverse relation between complexity (lower DFA) and the number of MS defining criteria (rho = 0.55, p = 0.002) and between complexity and MAGE (r = 0.68, p < 0.0001).
Conclusions:
There is a progressive loss of complexity in the glycemic profile from health, through the metabolic syndrome to type 2 diabetes mellitus. This loss of complexity precedes hyperglycemia and correlates with other markers of disease progression. Complexity analysis may be a useful tool to track the evolution from health to type 2 diabetes. Furthermore, it may provide a way to measure glycemic control in real-life situations and has some distinct advantages over other conventional variability metrics.
Introduction
Type 2 diabetes mellitus (DM) affects about 5% of adults worldwide, and this prevalence is rising rapidly (CitationSecree and Zimmet 2003). Individuals with impaired fasting glucose (IFG) or impaired glucose tolerance are asymptomatic but are at high risk of future type 2 diabetes and vascular disease (CitationUnwin et al 2002). Nevertheless, these definitions of prediabetes have limitations and even the current cut-off levels proposed by the American Diabetes Association for IFG (fasting plasma glucose >100 mg/dl) are open to debate (CitationCheng et al 2006; CitationAndreozzi et al 2007; CitationNichols et al 2007; CitationRijkelijkhuizen et al 2007).
During the past few years, the term “metabolic syndrome” (MS) has been increasingly used in medical literature. It describes the clustering in an individual of several traits, including insulin resistance, obesity, hypertension, and dyslipidemia, which are all highly prevalent in the Western lifestyle and each represent a major risk factor for cardiovascular disease (CitationWHO 1999; CitationNCEP 2002). Several recent reports show that the metabolic syndrome is associated with a large increase in the risk of cardiovascular events (CitationLakka et al 2002; CitationGirman et al 2004) and several pieces of evidences suggest a common pathophysiological background for this syndrome, at the center of which lies insulin resistance (CitationZimmet 1992). Patients with the MS are also at increased risk of developing DM (CitationHanley et al 2004).
The MS is very prevalent in developed countries (CitationFord and Giles 2003; CitationPark et al 2003). The increasing burden of obesity worldwide is the driving force behind the rising prevalence of the DM and MS (CitationPark et al 2003; CitationCarr et al 2004).
The progress from normal health through the MS to overt DM is arguably a gradual evolution, and its division into distinct steps is probably artificial. A smoother, more quantitative approach may provide a better description of this evolution. Unfortunately, the hallmark of this progress, insulin resistance, is not easy to measure in real-life conditions. We intend to ascertain whether complexity analysis may provide a new tool to describe this process.
Complex biological systems are characterized by a highly elaborate output. Often, one of the first symptoms of disease is a “decomplexification” of this output, due to uncoupling or loss of its processing capacities (CitationGoldberger 1997; CitationGoldberger et al 2002). Complexity analysis techniques may provide an easy and sensitive way of displaying this phenomenon (CitationVarela et al 2005, Citation2006).
This is probably the case in the evolution from health through MS until DM. Namely, we suggest that the derangement of glucose metabolism that underlies this evolution is displayed as a gradual and progressive loss of complexity in the glycemic time series as each patient walks his way from normality to full-blown DM.
We intend to develop an instrument that may give some quantitative insight into the evolution from the normal, healthy state through the MS to DM, in real-life conditions. We correlate this tool with a classic measure of variability: the mean amplitude of glycemic excursions (MAGE). This metric has been used to assess acute glucose fluctuations and was found to be related with activation of oxidative stress markers in DM (CitationMonnier et al 2006).
Patients and methods
Ten successive patients with the MS (defined by National Cholesterol Education Program – Adult Treatment Panel III (NCEP-ATPIII) criteria (CitationSecree and Zimmet 2003), excluding type 2 diabetes) and 10 successive patients with DM (defined as fasting plasma glucose ≥126 mg/dl in two consecutive occasions and/or on antidiabetic treatment) were selected from the outpatient internal medicine and vascular risk clinics of a urban 400-bed teaching hospital in Madrid, Spain. Only patients with a recent diagnosis of DM (less than one year), and only on dietary or oral antidiabetic treatment were selected. 10 healthy volunteers were used as controls. To avert the influence of gender and hormonal status, only men were selected. We intentionally chose early DM to highlight the possible differences in these first stages of DM. The study was approved by the Hospital’s Ethics Committee, and an informed consent was obtained from each patient.
The characteristics of patients and controls are displayed in .
Table 1 Patient’s characteristics
On admission to the study, after a full clinic exam, blood was extracted to measure basic biochemical parameters (including fasting plasma glucose, glycosylated hemoglobin, insulin, and lipids). Then a sensor was inserted in the abdominal subcutaneous tissue, and interstitial glucose was recorded every 5 minutes for at least 48 hours (CGMS System Gold, Medtronic MiniMed, Medtronic Diabetes, Northridge, CA, USA). Subjects were asked to record at least 3 fingerstick measurements daily. Otherwise, patients carried on with their normal ambulatory life, followed their normal treatment, and were not required to take any special care.
A glucose time series was obtained from each subject. From this series, we extracted a 24-hour long series (from 06.00 AM on day 2 to 06.00 AM on day 3) for study. We selected day 2 to avert the stressing influences of insertion and laboratory exams, and we excluded day 4 because of the concern of claudication of the capillary probe. shows an example of a healthy subject, a patient with the MS, and a patient with DM.
Figure 1 Example of a glycemic profile of a patient of each group.
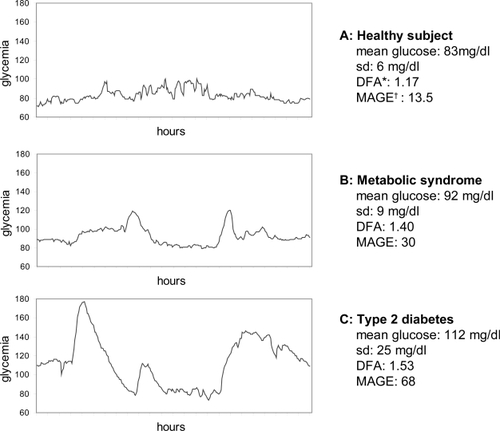
Conventional statistics (mean or median, standard deviation [SD], or interquartile range) were recorded from the time series. MAGE was calculated according to CitationService and colleagues (1987).
Complexity analysis
The complexity of the glucose profile was evaluated by means of detrended fluctuation analysis (DFA). DFA is a well established technique to measure the complexity of a time series. An in-depth discussion on DFA is outside the scope of this paper, and may be seen in CitationPeng and colleagues (2000). A summary is presented in the Appendix. Very schematically, DFA analyses how a time series and its linear regression diverge as the “time window” increases. Intuitively, DFA can be conceived as representing the span of influence of the different points in a time series. In a series with high complexity, the influence of each point rapidly fades away, while in a “smoother” series the influence of each point lasts longer. As a rule of thumb, higher complexities are displayed as lower DFA (until a minimum of 0.5).
Statistics
Differences among groups were evaluated by means of ANOVA, with post-hoc analysis (Tukey) when necessary. Univariate ANOVA was used to correct for other covariables. When normality conditions were not fulfilled, Kruskal-Wallis test was employed.
Spearman correlation was used to analyze the relation between complexity and the number of metabolic syndrome-defining criteria.
Linear regression was used to correlate DFA and MAGE.
In every case, statistical significance was assumed if p < 0.05. The statistical software employed was SPSS version 12 (SPSS Inc., Chicago, IL, USA).
Results
The patient’s characteristics are displayed in . The glucose profile was clearly more complex (ie, lower DFA) in healthy subjects than in patients with the metabolic syndrome or in diabetic patients (mean DFA [SD] in healthy controls: 1.25 (0.10), MS: 1.39 (0.07), DM 1.42 (0.10); ANOVA: F2,27 = 9.94, p = 0.001). In the post-hoc analysis, healthy subjects differed both from patients with the MS (p = 0.006) and with DM (p = 0.001). Diabetic patients had also a less complex profile than patients with the metabolic syndrome, but this difference did not achieve statistical significance (). This results did not change significantly when corrected for the effect of age (ANOVA F2,26 = 8.72, p = 0.002), body mass index (F2,26 = 8.06, p = 0.002), waist circumference (F2,26 = 7.85, p = 0.002), or fasting plasma glucose (F2,26 = 4.90, p = 0.016). Also, correcting for systolic or diastolic blood pressure, total cholesterol, high-density lipoprotein-cholesterol, low-density lipoprotein-cholesterol, or triglycerides did not change significantly these results (F > 7.80, p < 0.002 in every case). If the whole time series recorded was analyzed (in stead of just the second day), the results were similar (DFA in healthy controls:1.26 [SD 0.05]; MS:1.36 [SD 0.05]; DM:1.42 [SD 0.07]).
Figure 2 Differences in detrended fluctuation analysis among healthy subjects, patients with the metabolic syndrome and patients with type 2 diabetes.
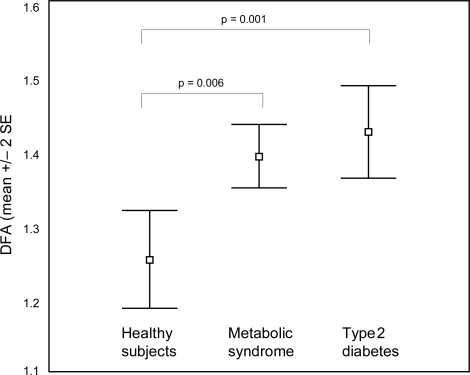
There was a statistically significant inverse relation between profile complexity and the number of metabolic syndrome defining criteria (NCEP-ATPIII criteria [CitationSecree and Zimmet 2003] (rho = 0.55, p = 0.002). These results did not differ if patients with full blown DM were excluded (rho = 0.58, p = 0.008), nor when adjusted for age (rho = 0.55, p = 0.002).
By way of contrast, variability, as measured through MAGE, increased from health (30.0 [SD 14.3]) to MS (45.5 [17.2]) and DM (62.7 [27.5]). With ANOVA, the post-hoc analysis could differentiate between healthy subjects and diabetic patients, but it could not discriminate between healthy subjects and MS or between MS and DM. These results did not change significantly when correcting for age, body mass index, or waist circumference, but when correcting for fasting glucose, MAGE became nonsignificant (F2,26 = 0.551, p = 0.58).
A highly significant correlation was observed between DFA and MAGE (r = 0.68, p < 0.0001): high variability correlated with high DFA (and thus, low complexity) ()
Figure 3 Correlation between detrended fluctuation analysis and mean amplitude of glycemic excursions.
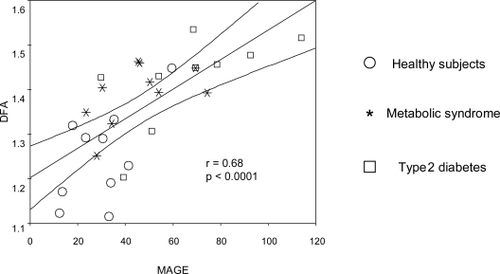
Discussion
The evolution from health to DM seems to be marked by a progressive loss of complexity in the glycemic profile, probably reflecting increasing insulin resistance and a failing glucoregulation. This loss of complexity appears well before the development of hyperglycemia. Overall, our MS patients had a fasting plasma glucose lower than 110 mg/dl, and 40% of them less than 100 mg/dl.
We did not find significant differences in the glycemic profile complexity in MS patients when compared with DM. However, the significant inverse correlation between the complexity of the glycemic profile and the number of MS criteria in each patient suggests that the path from health through the MS to DM is more a quantitative than a qualitative change, and highlights the fuzziness of their limits.
Blood glucose variability has recently emerged as an important variable in critical care both in diabetic and nondiabetic patients (CitationEgi et al 2006), as well as an independent risk factor for diabetic complications in DM (CitationSaudek et al 2006). We found a tight inverse correlation between glycemic variability (measured with MAGE) and complexity (measured with DFA). It would seem as if all through the evolution from health to full-blown DM, the glucoregulatory system became progressively more “sloppy” and slow-reacting, and required bigger departs from baseline to launch a counteregulatory response. Thus, although the coincidence of increased variability and loss of complexity may at first glance seem contradictory, it probably represents just two different aspects of the same disorder, namely, the loss of fine regulation on glycemic levels.
Complexity measures may have some advantages over classic MAGE. In the first place, it is less operator-dependent. In order to measure MAGE, each peak has to be assessed as to decide whether it qualifies as an excursion. Furthermore, the qualifying limit (usually, 1 SD) is arbitrary, and minor imprecisions on this measure have substantial consequences on the results. Finally, the discriminant power of MAGE depends heavily on plasma glucose, and correcting for this variable invalidates its diagnostic capacity.
By way of contrast, DFA is not operator-dependent and does not depend on an arbitrary limit. Furthermore, it explores the glucoregulatory response throughout the whole time series, thereby analyzing all the span of glycemic variations and not just the biggest ones.
It could be argued that the loss of complexity observed in MS and DM may be an artifact due to differences in body composition. Both groups have higher body mass index and probably their subcutaneous tissue will have an increase adiposity that could influence the sampling of interstitial fluid. Nevertheless, adjusting for body mass index or waist circumference does not significantly change the results.
Recently, CitationOgata and colleagues (2006, Citation2007) analyzed diabetes-related alterations of glucose control by means of DFA on a continuous glucose monitoring system. Their results on healthy volunteers (DFA 1.25 [SD 0.29]) are almost identical to ours. DFA in diabetic patients is slightly higher in their series (DFA 1.65 [0.30] vs 1.42 [0.10]), probably reflecting more advanced diabetes. These authors propose that the break down of the physiologic negative long-range correlation in glycemia observed in patients with diabetes proves that the net effects of the flux and reflux persist for many hours and may reflect a central pathogenic mechanism in diabetes, ie, the lack of tight control in blood glucose. These observations support our hypothesis that new metrics derived from complexity analysis could improve diagnostic and prognostic work-up in diabetes, and help in the understanding of glucose dysregulation in this disease.
An objection that can be raised is that subjects did not follow a standardized life regime, and variation on meals or activity may confound our results. Nevertheless, we tried to develop a real-life model, displaying what happens in normal life, easy to apply in daily practice, rather than a research instrument.
Also, it could be argued that glucose levels in interstitial fluid may not accurately reflect plasma levels, and that our results may show differences in the plasma/interstitium kinetics rather than in plasmatic values. Obviously, this caveat would also apply to other routine uses of CGMS (ie, insulin dose adjustment, insulin infusion pumps, etc) that don’t consider these limitations.
In conclusion, if corroborated, complexity analysis of the glycemic profile may provide a useful technique to track the evolution from health through the MS to DM in real-life conditions. Glucose instability and its contribution to diabetic cardiovascular risk could also be assessed in this way. Furthermore, complexity analysis may be helpful in the evaluation of the new “insulin-sensitizing” drugs and their possible contribution in improving glucoregulation.
Acknowledgments
We acknowledge Maria Jose Lopez Ribera and Guadalupe Castro Toril for their help in the data collection. The authors declare no conflicts of interest in this work.
References
- AndreozziFSuccurroEMancusoMR2007Metabolic and cardiovascular risk factors in subjects with impaired fasting glucose: the 100 versus 110 mg/dL thresholdDiabetes Metab Res Rev235475017311284
- CarrDBUtzschneiderKMHullRL2004Intra-abdominal fat is a major determinant of the National Cholesterol Education Program Adult Treatment Panel III criteria for the metabolic syndromeDiabetes5320879415277390
- ChengCKushnerHFalknerBE2006The utility of fasting glucose for detection of prediabetesMetabolism55434816546472
- EgiMBellomoRStachowskiE2006Variability of blood glucose concentration and short-term mortality in critically ill patientsAnesthesiology1052445216871057
- FordESGilesWH2003A comparison of the prevalence of the metabolic syndrome using two proposed definitionsDiabetes Care265758112610004
- GirmanCJRhodesTMercuriM2004The metabolic syndrome and risk of major coronary events in the Scandinavian Simvastatin Survival Study (4S) and the Air Force/Texas Coronary Atherosclerosis Prevention Study (AFCAPS/TexCAPS)Am J Cardiol931364114715336
- GoldbergerAL1997Fractal variability versus pathologic periodicity: complexity loss and stereotypy in diseasePerspect Biol Med40543619269744
- GoldbergerALAmaralLAHausdorffJM2002Fractal dynamics in physiology: alterations with disease and agingProc Natl Acad Sci U S A99Suppl 124667211875196
- HanleyAJFestaAD’AgostinoRBJr2004Metabolic and inflammation variable clusters and prediction of type 2 diabetes: factor analysis using directly measured insulin sensitivityDiabetes5317738115220201
- LakkaHMLaaksonenDELakkaTA2002The metabolic syndrome and total and cardiovascular disease mortality in middle-aged menJAMA28827091612460094
- MonnierLMasEGinetC2006Activation of oxidative stress by acute glucose fluctuations compared with sustained chronic hyperglycemia in patients with type 2 diabetesJAMA2951681716609090
- [NCEP] National Cholesterol Education Program2002Third report of the National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults (Adult Treatment Panel III) final reportCirculation106314342112485966
- NicholsGAHillierTABrownJB2007Progression from newly acquired impaired fasting glusose to type 2 diabetesDiabetes Care302283317259486
- OgataHTokuyamaKNagasakaS2006Long-range negative correlation of glucose dynamics in humans and its breakdown in diabetes mellitusAm J Physiol Regul Integr Comp Physiol291R16384316873556
- OgataHTokuyamaKNagasakaS2007Long-range correlated glucose fluctuations in diabetesMethods Inf Med46222617347760
- ParkYWZhuSPalaniappanL2003The metabolic syndrome: prevalence and associated risk factor findings in the US population from the Third National Health and Nutrition Examination Survey, 1988–1994Arch Intern Med1634273612588201
- PengCKHausdorffJMGoldbergerAL2000Fractal mechanisms in neural control: Human heartbeat and gait dynamics in health and diseaseWalleczekJSelf-Organized Biological Dynamics and Nonlinear ControlCambridgeCambridge University Press
- RijkelijkhuizenJMNijpelsGHeineRJ2007High risk of cardiovascular mortality in individuals with impaired fasting glucose is explained by conversion to diabetes: the Hoorn studyDiabetes Care30332617259503
- SaudekCDDerrRLKalyaniRR2006Assessing glycemia in diabetes using self-monitoring blood glucose and hemoglobin A1cJAMA29516889716609091
- SecreeRSJZimmetP2003Diabetes and impaired glucose tolerance: prevalence and projectionsDGAllgotBKingHDiabetes AtlasBrusselsInternational Diabetes Federation1771
- ServiceFJO’BrienPCRizzaRA1987Measurements of glucose controlDiabetes Care10225373582083
- UnwinNShawJZimmetP2002Impaired glucose tolerance and impaired fasting glycaemia: the current status on definition and interventionDiabet Med197082312207806
- VarelaMCalvoMChanaM2005Clinical implications of temperature curve complexity in critically ill patientsCrit Care Med3327647116352958
- VarelaMChurrucaJGonzalezA2006Temperature curve complexity predicts survival in critically ill patientsAm J Respir Crit Care Med174290816690981
- [WHO] World Health Organization1999Definition, diagnosis and classification of diabetes mellitus and its complications, GenevaReport of a WHO Consultation. Part 1: Diagnosis and classification of diabetes mellitusGenevaWorld Health Organization
- ZimmetPZ1992Kelly West Lecture. 1991. Challenges in diabetes epidemiology – from West to the restDiabetes Care15232521547680
Appendix
Detrended fluctuation analysis
Detrended fluctuation analysis (DFA) attempts to disclose patterns of self-similarity in time plots. That is, it looks for the presence of “memory” in the curve; memory understood as long-range correlations.
In order to be able to perform DFA, it is first necessary to integrate the time series:(Figure 4) where Gi is each individual point and Gmean is the mean of the series as a whole.
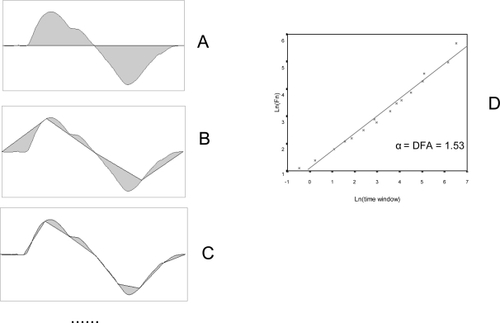
Next, the integrated curve is divided into time segments of size n (). A regression line is calculated for each segment, and the difference between the integrated curve and the different regression lines is computed:where F(n) is the measure of the difference between the integrated curve and the regression lines, N is the total curve at each point, and yn(k) is the value of the regression number of data points, y(k) is the value of the integrated line at that point.
Figure 4 Detrended fluctuation analysis (1). From the original time series, an integrated curve is obtained:
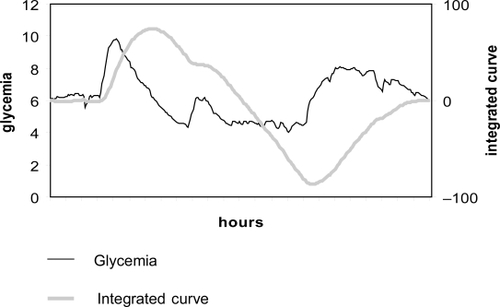
This operation is repeated for different time frames (that is, for different values of n). The smaller the time scale (n), the better the fit of the regression lines to the integrated curve, and the lower the value of F(n). Conversely, the value of F(n) tends to increase exponentially as the time frame (n) increases.
Finally, the relation between F(n) and the size of n is analyzed. A plot is drawn with log[F(n)] on the y-axis and log(n) on the x-axis (). A good fit to a regression line indicates the existence of scaling (self-similarity), and a fractal structure can be assumed.
DFA is the slope of the regression line (α). It displays the scaling exponent, and is an indicator of the degree of complexity of the curve. In an entirely random time series (“white noise”) α = 0.5. A 1/f type time series will have α = 1. A “random walk” (the integration of a random series, “Brown noise”) will display α = 1.5. Long range negatively correlated fluctuations will show α < 1.5, while in positive correlations α >1.5.
On the whole, a curve is more complex (less predictable) the closer its value of α is to 0.5. (Values of α lower than 0.5 reveal anticorrelations, which also implies a certain degree of predictability, and hence a lower level of complexity).
Figure 5 Detrended fluctuation analysis (DFA) (2). The integrated curve is divided into progressively smaller time segments (A, B, C, etc). A regression line is calculated for each segment, and the total difference between the integrated curve and the regression lines is calculated for each time window (F(n), gray area). The smaller the time window, the better the fit of the regression line and the lower the value of F(n). Finally, a plot is drawn (D) with log(F(n)) in the y-axis and log(time-window) in the x-axis. A good fit reveals the presence of scaling (self-similarity). DFA is the slope of the regression line. It displays the scaling exponent, and is an indicator of the degree of complexity of the curve.
In our series, N = 288.
The program used to calculate DFA was written in Python (http://www.python.org) and is available from the authors on request ([email protected]).