Abstract
This paper reports our progress in developing techniques for “parsing” raw motion data from a simple surgical task into a labeled sequence of surgical gestures. The ability to automatically detect and segment surgical motion can be useful in evaluating surgical skill, providing surgical training feedback, or documenting essential aspects of a procedure. If processed online, the information can be used to provide context-specific information or motion enhancements to the surgeon. However, in every case, the key step is to relate recorded motion data to a model of the procedure being performed.
Robotic surgical systems such as the da Vinci system from Intuitive Surgical provide a rich source of motion and video data from surgical procedures. The application programming interface (API) of the da Vinci outputs 192 kinematics values at 10 Hz. Through a series of feature-processing steps, tailored to this task, the highly redundant features are projected to a compact and discriminative space. The resulting classifier is simple and effective.
Cross-validation experiments show that the proposed approach can achieve accuracies higher than 90% when segmenting gestures in a 4-throw suturing task, for both expert and intermediate surgeons. These preliminary results suggest that gesture-specific features can be extracted to provide highly accurate surgical skill evaluation.
Introduction
In recent years there has been increased public interest and debate concerning the objective assessment of surgical competence. Surgical training and evaluation has traditionally been a slow and interactive process in which interns and junior residents perform operations under the supervision of a faculty surgeon. This training paradigm lacks any objective means of quantifying and assessing surgical skills Citation[1–7] and is unsustainable in the long run. Meanwhile, the government and insurance companies wish to reduce costs associated with deaths due to iatrogenic causes. A 2003 study by the Agency for Healthcare Research and Quality (AHRQ) documented over 32,000 mostly surgery-related deaths, costing nine billion dollars and accounting for 2.4 million extra days in hospital in 2000 Citation[8]. At the same time, economic pressures influence medical schools to reduce the cost of training surgeons, and new labor laws have placed limitations on resident work hours. The result is a need for reliable and efficient methods to supplement traditional training paradigms.
With the advent of robot-assisted minimally invasive surgical systems, new paradigms can alter the current learning and evaluation paradigm. Although the steep learning curve of robotic surgery introduces new challenges in the acquisition and assessment of surgical skills, the ability of the systems to record quantitative motion and video data opens up the possibility of creating descriptive mathematical models to recognize and analyze surgical training and performance. These models can then form the basis for evaluating and training surgeons, producing quantitative measures of surgical proficiency, automatically annotating surgical recordings, and providing data for a variety of other applications in medical informatics.
Prior work
Much of the previous work on surgical skill evaluation has focused on the use of virtual reality (VR) simulators, in particular the Minimally Invasive Surgical Trainer – Virtual Reality (MIST-VR), which has been comprehensively validated as a surgical data analysis tool. With this simulator, a subject performs a task holding two standard laparoscopic instruments whose movements are electronically tracked, recorded and evaluated. The system provides low-level analysis of the positions, forces, and times recorded during training to assess surgical skill Citation[9]. However, no matter how exhaustive the VR library might be, simulators can only serve as a good complementary solution to training on real-world scenarios Citation[9]. Robot-assisted surgery provides a unique opportunity where movements can be accurately tracked and analyzed to provide valuable feedback to a trainee regarding real-world tasks Citation[10–13].
Non-VR approaches to surgical skill evaluation have focused on basic motion tracking and have derived simple signatures of varying skill levels. In the field of high-level surgical modeling, Rosen et al. Citation[14–16] demonstrated that statistical models derived from recorded force and motion data can be used to objectively classify surgical skill level as either novice or expert. The results show that the statistical distances between Hidden Markov Models (HMMs) representing varying levels of surgical skill were significantly different (α < 0.05). However, their approach expects an expert surgeon to provide specifications for building the topology of the HMMs, and hence it cannot be easily generalized to new procedures.
The Imperial College Surgical Assessment Device (ICSAD), developed by Darzi et al., uses electromagnetic markers to track a subject's hands during a standardized task Citation[17], Citation[18]. The motion data provides information about the number and speed of hand movements and the distance traveled by the hands. Together with task completion time, the motion data provides a correlation to the subject's surgical dexterity level. ICSAD has been validated in numerous studies, including both minimal access and open tasks Citation[9]. ICSAD assesses dexterity, but only through the use of basic motion and time metrics, and requires the use of external marker tracking equipment. Verner et al. Citation[19] recorded da Vinci motion data for several surgeons performing a training task, and analyzed the tool-tip path length, velocities, and time required to complete the task.
Our approach
Most surgical procedures can be broken down into gestures that are modular and occur frequently in different contexts and different sequences. In designing a general-purpose surgical skill evaluator, our approach models a surgical trial in terms of component gestures. This allows a modular, flexible and extensible method for skill evaluation, and is distinctly different from most previous approaches, including MIST-VR and ICSAD, where no attempt is made to identify gestures. In terms of a sequence-modeling paradigm, this is analogous to modeling utterances in terms of a vocabulary of words in automatic speech recognition. In this work, we have developed automatic techniques for detecting and segmenting surgical gestures, which we term surgemes.
Materials and methods
Assessing surgical skill is a complex task, regardless of the experience or status of the evaluator. As an initial step, we attempt to understand the problem of recognizing simple elementary motions in a basic surgical task: suturing. This task is frequently performed and is sufficiently complex to provide significant variations. Surgeons with two levels of experience – expert and intermediate – performed multiple trials of the suturing task on the da Vinci system to provide realistic data with significant intra-user variations. In this section, we describe the data acquisition procedure, the paradigm for training and testing, and a solution for the motion recognition problem.
The robot used in our study is the da Vinci Surgical System (Intuitive Surgical, Sunnyvale, CA). The da Vinci is typically used in minimally invasive surgery to provide enhanced dexterity, precision and control for the surgeon. It has two master console manipulators and two patient-side manipulators. The device has seven degrees of freedom and 90 degrees of articulation. It also has a high-quality stereo-vision system that is fully controlled by the surgeon. However, from a surgical modeling point of view, its appeal lies in the wealth of kinematics data output by the application programming interface (API). The da Vinci outputs 192 data points ten times per second: these data points comprise Cartesian positions and velocities, rotation matrices, joint positions and velocities, servo times and the status of various console buttons.
For our method, we use a 72-data-point subset of the 192-data-point API at each time unit during task performance. Of these, the 22 data points from each of the two master console manipulators comprise 6 Cartesian velocities, 8 joint positions (7 joints plus gripper), and 7 joint velocities (7 joints plus gripper), while the 14 data points from each of the two patient-side manipulators comprise 7 joint positions (6 joints plus gripper) and 7 joint velocities (6 joints plus gripper) (). The 6 Cartesian positions were not included because of their noticeable relationship to the present surgeme. A 4-throw suturing task on simulated skin (leatherette) was selected as the basic surgical task to be analyzed. A senior cardiac surgeon suggested eight rudimentary surgemes common in such a task, which formed the vocabulary of the task. These eight surgemes are shown in . They can occur in order in a trial and some may even be absent in a given trial.
Figure 1. The eight rudimentary surgical gestures, or surgemes, common in a four-throw suturing task, as defined by a senior cardiac surgeon. 1) Reach for needle. 2) Position needle. 3) Insert and push needle through tissue. 4) Move to middle with needle (left hand). 5) Move to middle with needle (right hand). 6) Pull suture with left hand. 7) Pull suture with right hand. 8) Orient needle with both hands. [Color version available online.]
![Figure 1. The eight rudimentary surgical gestures, or surgemes, common in a four-throw suturing task, as defined by a senior cardiac surgeon. 1) Reach for needle. 2) Position needle. 3) Insert and push needle through tissue. 4) Move to middle with needle (left hand). 5) Move to middle with needle (right hand). 6) Pull suture with left hand. 7) Pull suture with right hand. 8) Orient needle with both hands. [Color version available online.]](/cms/asset/c509d97b-83f0-4a0e-9ada-f5d07d47d84f/icsu_a_198819_f0001_b.jpg)
Table I. The 72-data-point subset used in the study. The full 192-data-point da Vinci API also contains Cartesian positions, rotation matrices and other data.
Recognizing surgical motion
The task of recognizing elementary surgemes can be perceived as a mapping of temporal signals to a sequence of category labels. In this study, the set of temporal signals, X, are k real-valued stochastic variables obtained directly from the data values of the da Vinci API. The set of n finite category labels, C, correlates to the set of surgemes in the motion vocabulary. Thus, the task is to mapThe function F is derived and learned from the trials data. The method we propose adopts a statistical framework that simplifies the task of learning F by projecting X(k) into a feature space where the categories are well separated and the within-category variance is low.
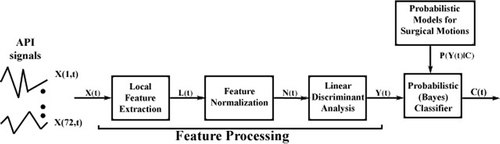
Our sequence of operations contains three major components: signal acquisition, feature processing, and a Bayes classifier (). The signal acquisition is the streaming 72 data-points per time unit output by the da Vinci API. The feature processing comprises three subparts: local feature extraction, feature normalization, and linear discriminant analysis (LDA); local feature extraction takes advantage of temporal information, feature normalization normalizes the input data, and linear discriminant analysis projects the data to a lower dimension. The Bayes classifier decides the most likely surgeme present based on learned probabilities from training labeled data sets. Each functional block will now be described in detail.
Figure 2. Functional block diagram of the system used to recognize elementary surgical motions in this study.
Local temporal features
A simple Cartesian position plot () of a surgeon performing the suturing task shows that surgical motion seldom changes abruptly from one surgeme to another. This is most evident in those surgemes associated with the actual throws (surgemes 5 and 6). This observation suggests that information from adjacent input samples can be useful in improving the accuracy and robustness of surgical motion recognition. Thus, for each time unit t, the |X(kt)|-feature vector can be concatenated with m preceding feature vectors and m subsequent feature vectors, subsampled at a rate of s, to form a new super feature vector (). For the time units at the beginning and end of a trial, where there are less than sm previous or subsequent time units, we pad the data with average values for the first 20 time units or the last 20 time units in the trial. This allows us to use all the trials in their entirety. The resulting super-vector L(t) has a length of (2m + 1)|X(kt)|. Since subsequent feature vectors are used in our calculation, the current method is not done in real time but in post-analysis.
Figure 3. Creating a super feature vector that encapsulated temporal information from neighboring data samples. This example assumes a subsampling granularity of s = 2. [Color version available online.]
![Figure 3. Creating a super feature vector that encapsulated temporal information from neighboring data samples. This example assumes a subsampling granularity of s = 2. [Color version available online.]](/cms/asset/22560205-e5c8-43ef-9af3-df57d98f9ab3/icsu_a_198819_f0003_b.jpg)
Figure 4. Cartesian position plots of the da Vinci left master manipulator, identified by motion class, during performance of a 4-throw suturing class. The left plot (a) depicts the data for the expert surgeon while the right (b) represents the intermediate surgeon. [Color version available online.]
![Figure 4. Cartesian position plots of the da Vinci left master manipulator, identified by motion class, during performance of a 4-throw suturing class. The left plot (a) depicts the data for the expert surgeon while the right (b) represents the intermediate surgeon. [Color version available online.]](/cms/asset/5220dc4a-7b90-4cfb-b6f7-358cb71f2484/icsu_a_198819_f0004_b.jpg)
Feature normalization
To be able to compare or manipulate high-dimensional data, it is important to ensure that the units of measurement in our super-vector are normalized so as to ensure that the range of data values is not significantly different. In the case of the da Vinci API, where the units of measurement for positions and velocities are different, the difference in dynamic range of the data points can hurt the performance of the classifier or recognition system. Thus, a mean and variance normalization is applied to each dimension of our data. This simple normalizing transformation iswhere
and
The resulting normalized vector, Ni(k), has the same length as Li(k).
Linear discriminant analysis
We can now apply general statistical methods to our normalized super-vectors. When the features corresponding to different surgical motions are well separated, the accuracy of the recognizer can be considerably improved. The transformation in this study focuses on linear discriminant analysis (LDA) Citation[20]. LDA attempts to project high-dimensional feature vectors into a lower-dimensional space while preserving as much of the class discriminatory information as possible. In our method, given a normalized super-vector N(k), we calculate a linear transformation matrix W such that the product of the two is a vector Y(k) that exists in a lower-dimensional space:The linear transformation matrix W is estimated by maximizing the Fisher discriminant, which is the ratio of variance between the classes to the variance within the classes. One can view this as a measure of the signal-to-noise ratio for the class labels. The transformation that maximizes the ratio gives us the optimum Y(k). The resulting vector Y(k) has a length equivalent to the lower-dimensional space. Since the class means and covariances are not known beforehand, we can estimate them from the training set using the maximum likelihood estimate. The estimates do not guarantee the best possible average test errors, even if the classes are normally distributed.
Bayes classifier
We can now created a Bayes classifier to compare results on the trained LDA data with the manually segmented data. The discriminant function, F, could be of several forms. When equal weight is given to all errors, the optimal discriminant function is given by the Bayes decision rule. Thus, given a lower-dimensioned feature vector, Y(1:k), we want the surgeme, C(1:n), that is most likely occurring at that point. In other words, the sequence whose posterior probability, P(C(1:n) | Y(1:k)), is maximum would be the optimal decision. The Bayes chain rule allows us to rewrite it as the product of prior probability of the class sequence, P(C(1:n)), and the generative probability for the class sequence, P(Y(1:k) | C(1:n)).For this study, we make the simplifying assumption that the conditional probability is independent at each time frame, Πi = 1kP(C(i)|Y(i)). Thus, the decision is made at each frame independently.
Cross-validation paradigm
The data in this study consisted of 15 expert trials and 12 intermediate trials Citation[20]. A senior cardiac surgeon with extensive experience using the da Vinci in cardiac surgery performed the expert trials. Another cardiac surgeon with limited experience using the da Vinci in cardiac surgery performed the intermediate trials. Each trial contains a sequential log of the kinematics data (192 data points per time unit) of the respective surgeon performing the four-throw suturing task. Not all trials were required to use all eight surgemes in the motion vocabulary. To improve the statistical significance of the results, a 15-fold cross validation and a 12-fold cross validation were performed on the expert and intermediate data, respectively. For the expert data, the machine learning algorithm was evaluated by performing 15 different tests. In each test, 13 of the 15 expert trials were used in the training of the statistical model and the remaining two trials were held out for testing. The average across the 15 such tests was used to measure the performance of various parameter settings. The same validation method was used on the 12 intermediate trials, and for our preliminary skill-independent test on all 27 trials.
Results
Our study was composed of running experiments performed on the two varying levels of surgical skill. We applied the recognition and segmentation techniques first to the expert data and then to the intermediate data. A preliminary test was then run on the entire data set, both expert and intermediate. On looking at a Cartesian position plot of a sample expert and intermediate trial (), it will be apparent why Cartesian positions of the tool tip are not included in our study. In a number of cases, they can clearly differentiate between surgical skill levels simply by the efficient use of space and structure.
A preliminary review of the data suggested that a few preprocessing steps were required before modeling the surgical motions. Of the eight surgemes defined in our motion vocabulary, the expert surgeon did not use surgemes 5 and 7, and the intermediate surgeon used surgeme 4 only sparingly. Thus, we collapsed the eight surgemes into a smaller number of motion classes ( and ). For example, a possible set of motion classes for the expert experiments would collapse the eight surgemes into 6 motion classes, with surgemes 5 and 6 in class 5 and surgemes 7 and 8 in class 6. We examined the effect of varying the number of motion classes to compare performances. shows the average recognition rates of motion class 11234455 to be higher than those for the other three motion classes in the expert data across all three LDA dimensions (90.9%, 91.2%, 91.3% respectively). shows the average recognition rates of motion class 12344567 to be higher than those for the other five motion classes in the intermediate data for dimensions 4 and 5 (92.46%, 92.81% respectively), while motion class 12233456 had the highest recognition rate for dimension 3 (92.02%). Unlike in the expert data, the dimensional results within a class had more variance in the intermediate data.
Figure 5. Recognition rates of the four motion class definitions for the expert surgeon across all 14 temporality sizes with window removal sizes of w = (3, 5, 7). Motion class 11234455 had the highest average recognition rate across all 3 dimensions. [Color version available online.]
![Figure 5. Recognition rates of the four motion class definitions for the expert surgeon across all 14 temporality sizes with window removal sizes of w = (3, 5, 7). Motion class 11234455 had the highest average recognition rate across all 3 dimensions. [Color version available online.]](/cms/asset/271fca1d-d848-4283-a793-408ba9a23bf0/icsu_a_198819_f0005_b.jpg)
Figure 6. Recognition rates of the six motion class definitions for the intermediate surgeon across all 14 temporality sizes with window removal sizes of w = (3, 5, 7). Motion class 12344567 had the highest average recognition rate across dimensions 4 and 5, while 12233456 had the highest rate for dimension 3. [Color version available online.]
![Figure 6. Recognition rates of the six motion class definitions for the intermediate surgeon across all 14 temporality sizes with window removal sizes of w = (3, 5, 7). Motion class 12344567 had the highest average recognition rate across dimensions 4 and 5, while 12233456 had the highest rate for dimension 3. [Color version available online.]](/cms/asset/5dd2ae0b-9dca-4271-9eda-568c409afc90/icsu_a_198819_f0006_b.jpg)
Table II. The four motion classes used for the expert data. Each motion class defines the mapping from the surgeme in the vocabulary to the corresponding motion in the class.
Table III. The six motion classes used for the intermediate data. Each motion class defines the mapping from the surgeme in the vocabulary to the corresponding motion in the class.
Local temporal features
The lengths of the neighboring feature vectors, m, and the subsampling rate, s, were varied to determine the optimal length and granularity of motion to be considered (). The results showed that, as expected, understating the temporal length results in the disappearance of any advantage of temporality, while overstating the temporal length increases the probability of blurring the transition between neighboring surgemes. shows the results of varying the temporal length, m, and subsampling granularity, s, for the expert data. We concluded that m = 8 and s = 2 provided the best length and rate of temporality (91.4%). For the intermediate results (), we concluded that m = 16 and s = 2 had the highest recognition rate at 93.99%.
Figure 7. Having a temporal length m = 8 and a subsampling granularity of s = 2 resulted in the highest average recognition rate. Each pair was tested across all 4 motion classes, all 3 dimensions, and on transition removal sizes of 3, 5 and 7. Note that not using any temporal information resulted in the lowest average recognition rates.
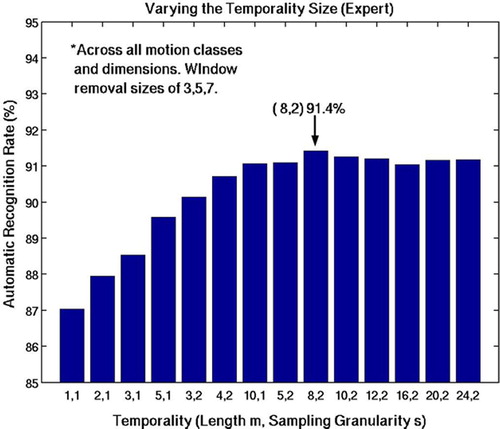
Figure 8. Having a temporal length m = 16 and a subsampling granularity of s = 2 resulted in the highest average recognition rate. Each pair was tested across all 6 motion classes, all 3 dimensions, and on transition removal sizes of 3, 5 and 7. Note that not using any temporal information resulted in the lowest average recognition rates.
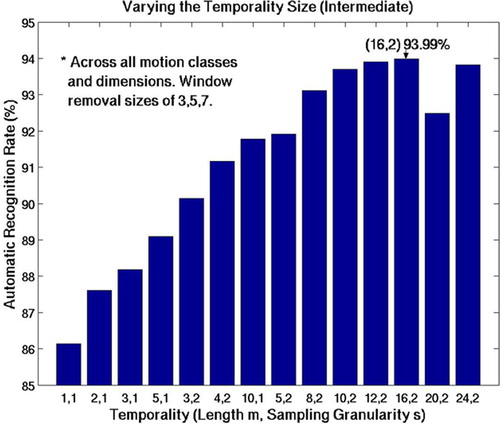
Table IV. The various combinations of temporal region m and subsampling rate s. The ordering is based on increasing temporal window size (sm + 1).
Linear discriminant analysis
shows the reliability of LDA in separating motion data into 6 distinct regions in a 3D projection space. Although not always the case, it is more commonly found that the intermediate surgeon's motions tend not to separate as well, indicating less consistent motions (, right). These experiments validated the hypothesis that LDA could be used to project the original data into a simpler, low-dimensional data set. We also varied the dimensionality of the projection, d = {3, 4, 5} to examine if there was any correlation to the recognition rate. Looking at and again, it can be seen that d = {4, 5} have comparable recognition rates, but d = 3 has consistently lower rates across all motion classes, temporality sizes, and window removal sizes.
Figure 9. The result of LDA reduction with m = 6 and d = 3. The motions of the expert surgeon (left) separate more distinctly than those of the intermediate surgeon (right). [Color version available online.]
![Figure 9. The result of LDA reduction with m = 6 and d = 3. The motions of the expert surgeon (left) separate more distinctly than those of the intermediate surgeon (right). [Color version available online.]](/cms/asset/937dd318-0e6e-4fe6-b2cc-0126b7c6fb43/icsu_a_198819_f0009_b.jpg)
Having fine-tuned the classifier for surgical motion, we then applied the algorithm to produce segmentations. shows a comparison of a segmentation by a human and the surgeme sequence generated by the algorithm for a randomly chosen trial performed by the expert surgeon.
Figure 10. Comparison of automatic segmentation of robot-assisted surgical motion with manual segmentations. Note that most errors occur at the transitions. [Color version available online.]
![Figure 10. Comparison of automatic segmentation of robot-assisted surgical motion with manual segmentations. Note that most errors occur at the transitions. [Color version available online.]](/cms/asset/c15ba6b0-1493-4ecc-922e-29e596016ba6/icsu_a_198819_f0010_b.jpg)
Even though the model only incorporates weak temporal constraints, the resulting recognition rates are surprisingly good. Most of the errors in the expert data occur at the transitions. This can be explained by the smooth transition from one surgeme to another. Thus, it is difficult, even for a human, to mark a sharp transition boundary. Consequently, we removed a small window size at each boundary, so as to avoid confidence issues in the manual segmentation. shows the expert results of varying the window removal sizes, w = {0, 1, 3, 5, 7} across all motion classes with dimension 4. Window sizes of 5 and 7 time units (0.5 and 0.7 seconds) result in the best recognition rates. shows the intermediate results of varying the same window sizes across all motion classes with dimension 5. Similarly, window sizes of 5 and 7 result in the best recognition rates. The window sizes are statistically insignificant because an average surgical motion lasts over 3 seconds. However, we choose window size of 5 as our optimum choice because we want the highest recognition rate without compromising data loss. It was noticed that window sizes larger than 5 do not significantly improve recognition rates, and thus do not outweigh the loss of data.
Figure 11. Results of varying window removal size across all temporality sizes and motion classes, and with LDA dimension 4 for the expert data. Removal of a window size of 5 or 7 returned the highest recognition rates. [Color version available online.]
![Figure 11. Results of varying window removal size across all temporality sizes and motion classes, and with LDA dimension 4 for the expert data. Removal of a window size of 5 or 7 returned the highest recognition rates. [Color version available online.]](/cms/asset/0a2901e1-5819-42ed-a7c5-14e3699b8674/icsu_a_198819_f0011_b.jpg)
Figure 12. Results of varying window removal size across all temporality sizes and motion classes, and with LDA dimension 5 for the intermediate data. Removal of a window size of 5 or 7 returned the highest recognition rates. [Color version available online.]
![Figure 12. Results of varying window removal size across all temporality sizes and motion classes, and with LDA dimension 5 for the intermediate data. Removal of a window size of 5 or 7 returned the highest recognition rates. [Color version available online.]](/cms/asset/ee390c35-fc72-4552-b1fb-5f75a96daec1/icsu_a_198819_f0012_b.jpg)
Training on combined data sets
To better understand the robustness of our techniques, we trained our system on the combined 27 datasets. A motion class definition of 12344455 was used, which is a rough combination of the two best motion classes that worked for each skill level. We set our temporal size to m = 8 and our subsampling rate to s = 2 and projected onto a dimension of 5. The result is shown in .
Table V. Results of training on both the expert and intermediate data sets, which barely decreased the recognition rates of the classifier. A motion class definition of 12344455, with temporal size of m = 8 and s = 2 and LDA dimension of 5 was used. The comparison parameters for the standalone are expert = {11234455, m = 8, s = 2, d = 5} and intermediate = {12344567, m = 16, s = 2, d = 5}.
Discussion
We have shown that carefully tailored feature processing can simplify the task of classification considerably, requiring only a Bayesian classifier to provide accuracies above 90%.
Expert
The results obtained on the expert data showed that a motion class mapping of 11234455 consistently had the highest recognition rates. As mentioned previously, surgemes 5 and 7 are not used by the expert surgeon. We can also hypothesize why putting surgemes 1 and 2 together would increase accuracy. Since surgeme 2 (position needle) must come after 1 (reach for needle), grouping them together is akin to simply creating a new gesture of 1 + 2. However, grouping surgemes 2 (position needle) and 3 (insert and push needle through tissue) does not necessarily result in higher recognition rates, because 3 does not have to come after 2 except in the first throw. As for the temporality of m = 8 and subsampling granularity of s = 2 having the highest recognition rates, we can conclude that this is the right mix of taking advantage of temporal information but not impinging on the next motion. It can be seen from that the increasing temporality size graph takes on a bell-shaped curve, confirming our hypothesis. Based on our experiments, we conclude that, for the expert data, the motion class definition of 11234455, with a temporality of (8, 2) and a reduced LDA dimension of d = 5 results in the most optimal recognition rates: the average recognition rate was 92.21%, with a high of 97.79%.
Intermediate
The results obtained on the intermediate data showed that a motion class mapping of 12344567 had the highest recognition rates for dimensions 4 and 5. As mentioned previously, surgeme 4 is only sparsely used and it seems logical to group it with surgeme 5. We are unsure why projecting the intermediate data onto a 3D space produced markedly lower recognition rates than for the other two higher dimensions. Unlike the expert data, dimension 5 clearly had higher recognition rates than dimension 4 for all motion classes. As for the temporality of m = 16 and subsampling granularity of s = 2 having the highest recognition rates, we can conclude that this is the right mix of taking advantage of temporal information but not impinging on the next motion. However, the intermediate data does not take on a strong bell-shaped curve like that observed with the expert data. We believe that the errors in the intermediate were not just limited to the transitions, but were also present while the surgeme was occurring. Thus, a larger temporality size of (m = 16, s = 2) would better capture the current surgeme. In the test using a mapping of 12344567, temporality of (16, 2), reduced LDA dimension d = 5 and a window removal size w = 7; the average recognition rate was 95.26%, with a high of 97.69%.
Combined datasets
Training on the expert and intermediate data simultaneously was important because it allowed us to examine the strength of our technique and observe how the gesture recognition portion performs regardless of skill level. Since the recognition rates were still mostly above 90%, this supports our hypothesis that there exist inherent structures in surgical motion.
Conclusion
This paper addresses the problem of segmenting surgical trails using the API signals from the da Vinci system. A feature-processing pipeline has been proposed which reduces the highly redundant and correlated features into a low-dimensional discriminative space. The resulting feature space is highly separable and simple classifiers can provide very high accuracy. The preliminary experiments reported here demonstrate the robustness of the segmentation algorithm to expert and intermediate skill levels, achieving accuracies above 91% in both cases. Given these high-quality segmentations, it should now be possible to extract features specific to each gesture and design general-purpose surgical skill evaluators.
Acknowledgments
This research was supported by the National Science Foundation and the Division of Cardiac Surgery at the Johns Hopkins Medical Institutions. The authors thank Todd E. Murphy for the datasets used in this study and the work from his Master's thesis, and Dr. Allison M. Okamura for her input and advice. The authors would also like to thank Dr. Randy Brown, Sue Eller, and the staff at the Minimally Invasive Surgical Training Center at Johns Hopkins Medical Institutions for access to the da Vinci system, and Intuitive Surgical, Inc., for use of the da Vinci API.
References
- King R. T. New keyhole heart surgery arrived with fanfare, but was it premature?. Wall Street Journal May 5, 1999
- Haddad M., Zelikovski A., Gutman H., Haddad E., Reiss T. Assessment of surgical residents’ competence based on postoperative complications. Int Surg 1987; 72(4)230–232
- Darzi A., Smith S., Taffinder N. Assessing operative skill needs to become more objective. BMJ 1999; 318: 887–888
- Barnes R. W. But can s/he operate?: Teaching and learning surgical skills. Current Surgery 1994; 51(4)256–258
- Cuschieri A., Francis N., Crosby J., Hanna G. What do master surgeons think of surgical competence and revalidation?. Am J Surg 2001; 182(2)110–116
- Moorthy K., Munz Y., Sarker S., Darzi A. Objective assessment of technical skills in surgery. BMJ 2003; 327: 1032–1037
- Scott D., Valentine J., Bergen P., Rege R., Laycock R., Tesfay S., Jones D. Evaluating surgical competency with the American Board of Surgery in-training examination, skill testing, and intraoperative assessment. Surgery 2000; 128(4)613–622
- Zhan C., Miller M. Excess length of stay, charges, and mortality attributable to medical injuries during hospitalization. JAMA 2003; 290(14)1868–1874
- Darzi A., Mackay S. Skills assessment of surgeons. Surgery 2002; 131(2)121–124
- Wilhelm D. M., Ogan K., Roehrborn C. G., Cadeddu J. A., Pearle M. S. Assessment of basic endoscopic performance using a virtual reality simulator. J Am Coll Surg 2002; 195(5)675–681
- Cowan C., Lazenby H., Martin A., et al. National health care expenditures. Health Care Finance Rev 1999 1998; 21: 165–210
- Acosta E., Temkin B. Dynamic generation of surgery specific simulators – a feasibility study. Stud Health Technology Inform 2005; 111: 1–7
- McIntyre R., Driver C. P., Miller S. S. The anterior abdominal wall in laparoscopic procedures and limitations of laparoscopic simulators. Surg Endosc 1996; 10(4)411–413
- Rosen J., Hannaford B., Richards C. G., Sinanan M. N. Markov modeling of minimally invasive surgery based on tool/tissue interaction and force/torque signatures for evaluating surgical skills. IEEE Trans Biomed Eng 2001; 48(5)579–591
- Rosen J., Solazzo M., Hannaford B., Sinanan M. Task decomposition of laparoscopic surgery for objective evaluation of surgical residents’ learning curve using Hidden Markov Model. Comput Aided Surg 2002; 7(1)49–61
- Richards C., Rosen J., Hannaford B., Pellegrini C., Sinanan M. Skills evaluation in minimally invasive surgery using force/torque signatures. Surgical Endoscopy 2000; 14: 791–798
- Datta V., Mackay S., Mandalia M., Darzi A. The use of electromagnetic motion tracking analysis to objectively measure open surgical skill in laboratory-based model. J Am Coll Surg 2001; 193: 479–485
- Datta V., Mandalia M., Mackay S., Chang A., Cheshire N., Darzi A. Relationship between skill and outcome in the laboratory-based model. Surgery 2001; 131(3)318–323
- Verner L., Oleynikov D., Holtman S., Haider H., Zhukov L. Measurements of the level of expertise using flight path analysis from da Vinci robotic surgical system. R. Phillips, J. D. Westwood, R. A. Robb, D. Stredney, H. M. Hoffman, G. T. Mogel. IOS Press, Amsterdam 2003; 94, Medicine Meets Virtual Reality 11. Studies in Health Technology and Informatics
- Murphy T. Towards objective surgical skill evaluation with Hidden Markov Model-based motion recognition. Department of Mechanical Engineering, The Johns Hopkins University. August, 2004, M.S. Thesis