Abstract
Objectives: This study describes the health-related quality of life (HRQOL) of the Portuguese working age population and investigates sociodemographic differences.
Methods: Subjects randomly selected from the working age population (n=2,459) were assessed using the SF-36v2 and converted into the preference-based SF-6D.
Results: The mean SF-6D utility value was 0.70 (range 0.63–0.73). The mean utility value was lower for the lower educational level than for the highest. Women, people living in rural areas and older adults reported lower levels of utility values. Non-parametric tests showed that health utility values were significantly related to employment; unskilled manual workers reported utility values lower than non-manual workers. For different diseases, mean utility values ranged from 0.58 (sexual diseases) to 0.66 (hepatic conditions). Cluster analysis was adopted to classify individuals into three groups according to their answers to the SF-6D dimensions. Multinomial logit regression was used to detect sociodemographic characteristics affecting the probability of following each cluster pattern. This study yielded normative data by age and gender for the SF-6D.
Conclusions: The authors conclude that SF-6D is an effective tool for measuring HRQOL in the community so that different population groups can be compared. The preference-based measure used seems to discriminate adequately across sociodemographic differences. These results allow a better understanding of the impact of sociodemographic variables on the burden of illness perception.
A previous version of this paper was presented at the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) 8th Annual European Congress held at Florence, Italy in November 2005.
Introduction
As health economics, and hence health measurement, have become major issues throughout the world, the need for population reference data for a specific country or region has been increasing. Such normative data can be used as reference data to compare profiles for patients with specific conditions with data for the average person in the general population in a similar age and/or gender groupCitation1. These kinds of comparisons enable identification of the burden of the disease in a particular patient population and can be used to populate economic models.
There is evidence that changes in health status and the magnitude of these changes are useful to quantify outcomes for clinical and economic evaluations, and there is an increasing consensus regarding the centrality of the patient's viewpoint in monitoring medical care outcomesCitation2. The new single index summary preference-based measure of health derived from the SF-36, the SF-6D, has the obvious potential to contribute to that process. Following the growing use of health state values in many European countries (e.g. Belgium, Finland, Germany, Greece, Hungary, The Netherlands, Norway, Slovenia, Slovakia, Spain, Sweden and the UK) and in some non-European countries (e.g. Armenia, Canada, Japan, New Zealand, the US and Zimbabwe), there has been an increasing interest in having normative general population values. Many studies have been published presenting normative values for the general population, with the purpose of using these values in health policiesCitation2–11.
The use of health state values is even more important in a country like Portugal where resources are scarcer than in most developed countries. A study regarding the measurement of Portuguese health state utilities would allow the use of these values in the allocation of resources in the health sector, both at a national and regional level. Currently such values do not exist, so use must be made of values from other countries, but applied to a Portuguese population.
The data reported in this paper show what can be achieved by using a simple instrument for measuring health status. The study obtained norms for the working age Portuguese population and provides estimates that can be used, for example, in economic models that include normal health states by sociodemographic group. It was also the purpose to group the working age Portuguese population by common characteristics in terms of health state utilities. Therefore, cluster analysis was used to classify individuals into different and distinct groups according to their answers to the SF-6D dimensions. The authors then attempted to characterise the clusters by using sociodemographic characteristics, so it would be possible to really know the characteristics of the groups extracted from the working age Portuguese population, since this will allow the health policies to be specifically targeted to them. Multinomial logit regression was used to assign the sociodemographic characteristics that affect the probability of following each cluster pattern.
Methods
Study sample
Portuguese normative data for the fully validated Portuguese version of the SF-36v2Citation12–14 were obtained by personal interview from a random sample (2,459 individuals) of the working age population living in mainland Portugal. The respondents were also asked about their chronic conditions; they were given a list of chronic conditions to choose from. Their characteristics are presented elsewhereCitation14. This sample was collected in 822 households out of a total of 850 randomly chosen households. All adults of working age (18–64 years) from each selected household were interviewed. In the sample design, the main characteristics of the working age adults were taken into account. Collective households (schools, shops etc.) were excluded from the study. All households that refused to participate and all households in which, after a second try, it was not possible to contact anyone were also excluded from the analysis. The non-respondent rate was negligible.
To obtain the health state utilities of the population, the SF-6D algorithm was applied to the SF-36v2 data collected by this sample. These health state utilities allow assessment of the health-related quality of life (HRQOL) of the Portuguese working age population. By legal constraints, ethnicity was not included in the study.
Educational level was classified into four categories: illiterate = without formal education; low level = until 6th grade; middle level = secondary school; and high level = university degree.
SF-6D
The SF-6D is a new single index summary preference-based measure of health derived from 11 items of the SF-36 by a research team at the University of SheffieldCitation15. The items of the SF-36 were converted into a six-dimensional health state classification system, the SF-6D, with four to six levels, allowing for a total of 18,000 distinct health states. These six dimensions are Physical Functioning, Role Limitations, Social Functioning, Pain, Mental Health and Vitality.
A selection of 249 health states defined by the SF-6D have been valued by a representative sample of the UK general population, using the standard gamble (SG) valuation techniqueCitation15. Regression models were then estimated to predict single index scores for health states and the resulting algorithm was used to convert SF-36 data, at the individual level, to a preference-based indexCitation15,Citation16. This algorithm generates health state values ranging from no problems on any of the six dimensions in the SF-6D descriptive system (1.0) to the most impaired level on all six dimensions (0.3)Citation17. For the purposes of this investigation, the SF-6D utility algorithm was applied to the dataset of responses of the Portuguese working age population to generate an SF-6D utility score for each subject. Since there is no Portuguese SG tariff for SF-6D health states, the UK tariff was applied to obtain values for the health states.
In this research, the Portuguese version of the SF-6D was used based on the fully validated Portuguese version of the SF-36v2. Other studies, running in parallel to this one, are mainly concerned with the validation of this measure to Portugal.
Post-stratified estimation
Although the sample was randomly selected, it differed slightly from the whole Portuguese working age population. To overcome this problem, post-stratified estimation methods were used to weight the initial results by gender and age, according to the population values.
The post-stratification consists of stratifying the sample after its collection by using auxiliary information available at the estimation phaseCitation18. The variables that define the post-strata should be highly correlated with the interest variables. For this reason, in this study gender and age groups were chosen to be variables of post-stratification, according to the Portuguese National Statistical InstituteCitation19. The purpose of the post-stratification methods is to adjust the initial weights to allow the weighted sample distribution of certain characteristics of the population to be equivalent to the known distribution of the general population with those characteristics. The use of these post-stratification methods requires knowledge of the population post-stratum dimensionsCitation18.
In this study, the 10 post-stratum classes resulting from the crossing of the 2 variables were known at the population level, 2 for gender and 5 for age. By doing so the estimation problem was reduced to the case of use of a single post-stratification variable, and hence the post-stratification methods could be directly applied. By using post-stratified estimators, the bias caused by sample design problems and by missing data was decreased, improving the estimation precisionCitation20.
Post-stratified estimators from the ‘design-based’ approach were applied. This approach considers that the population characteristics are fixed and that the probabilistic component is introduced when one adopts a particular sample designCitation18. The estimators used are presented below, in an abbreviated form.
With the SF-6D utility score, yhi for the ith individual belonging to the h post-stratum, the post-stratified estimator for the mean is given by the equation:
where N is the population dimension, n is the sample dimension, Nh is the number of individuals from the population that belong to the h post-stratum and nh is the number of individuals from the sample that belong to same post-stratum. From this equation it is possible to conclude that the post-stratified estimator is seen as a weighted mean, where each sampling individual is weighted. That is, the sampling results are adjusted according to the classes defined by the qualitative auxiliary variable weights in the population.
The mean SF-6D utility score for a population subgroup (e.g. women) should be estimated by using a post-stratified estimator for domains. Indeed, a domain is a subpopulation of unknown dimension for which it is intended to estimate parametersCitation21. When it is possible to identify study domains before sampling, the sample design should take into account these planned domains, regarding them as strata. In this case, the sample dimension in each domain should be large enough to produce direct estimations with an acceptable degree of precision. In this study, the sample design did not take into account the definition of these domains (female, male, married, single etc.) as strata. Consequently, they are designated as unplanned domainsCitation21
Similarly, given the observed SF-6D utility score ydhi for the ith individual that belongs to the h post-stratum in the d domain, the post-stratified estimator for the domains mean is given by the equationCitation22:
where Nd is the population dimension in the d domain, nd is the sample dimension in the d domain, Ndh is the number of individuals from the population that belong to the h post-stratum in the d domain and ndh is the number of individuals from the sample that belong to the h post-stratum in the d domain. In the cases in which the domain coincides with the post-stratum, Ndh = Nh and ndh = nh and Equations [1] and [2] are similar.
Statistical analysis
Descriptive statistics were computed to characterise the study sample. Post-stratified estimation methods were applied to weight the initial results by gender and age, according to the population values. Both parametric (t-tests and analysis of variance (ANOVA)) and non-parametric (Kruskal–Wallis) tests were used to investigate for significant differences between sociodemographic groups. These differences were considered statistically significant at p-values <0.05. Non-parametric tests were used owing to the observed heterogeneity of variances in some cases and the non-normality of some dimensions. The amount of missing data was low, and no replacement or imputation was performed on missing response items.
The differences between the total sample and the number of responses presented for some analyses was due to non-completion of some items of the SF-36v2 required to generate the SF-6D utility score. The software used for all the analyses was the Statistical Package for the Social Sciences version 14.0.
Classifying individuals
To classify individuals into homogeneous groups, a cluster analysis was run. To address the issue of ordinality, Kaufman and RousseeuwCitation23 suggested a modification to the calculation of the corresponding dij of the dissimilarity matrix. For an ordinal variable Xk with at most Mk ordered categories, rik,rik = {1, 2,. .., Mk} was transformed to the unit interval by calculating:
The squared Euclidean distance equation or other distance measures can then be applied to replace Xik by Zik. This transformation retains the (ranking) information present in the ordinal variables, but ameliorates some of the problems that otherwise attend clustering of ordinal measures.
In this study, the variables used in the cluster analysis were the SF-6D dimensions. After transformation of the variables, a hierarchical cluster analysis was run, using the Ward's method, the furthest neighbour method, the nearest neighbour method, the between-groups method and the Centroid method as agglomerative methods. The distance measures used were the Euclidean distance and the squared Euclidean distance. Use of all these methods enabled the cluster analysis to be validated relatively. Indeed, the decision on the number of clusters to choose was based on the fusion coefficients and on the cut of the dendrogram.
Modelling cluster pattern probabilities
In seeking to analyse the determinants of cluster patternsCitation24, it was assumed that each individual i in the sample had a probability Pik of following the pattern represented by the subscript k. Modulation of the probability Pik is based on a function of a set of attributes believed to affect the HRQOL of the population. This subscript k denotes a path or shape of adjustment in the HRQOL drawn from a known finite set Ω with three elements. Since the authors intended to model a multilevel outcome variable, the multinomial logit regression (polytomous logistic regression) was used to assign the variables that affect the probability of following each cluster pattern. In this case, assuming three categories (k=3), the outcome Y has three levels, so the basic event under this model is whether the individual i has followed pattern k rather than pattern l, where l and k are any two elements of Ω. The multinomial logit probability of following pattern k is given by:
where Xi is a vector of known explanatory variables and b represents a vector of unknown parameters associated with the pattern. The following equations may be used to estimate the model coefficientsCitation25:
Obviously, the sum of the probabilities for the three outcomes must be equal to 1:
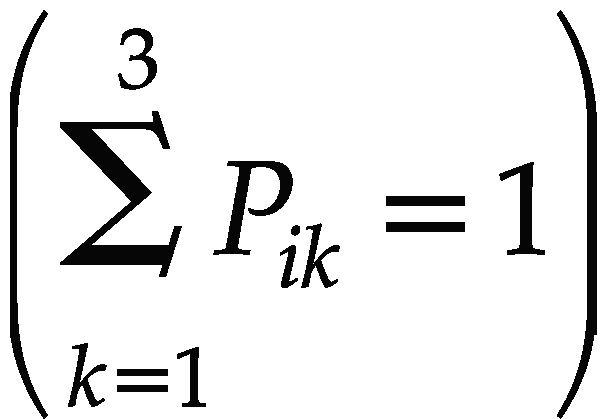 When exp(β)>1, this meansthat a unit change in the underlying X causes an increase in the probability that the outcome changes category (i.e. changes cluster). On the contrary, when exp(b)<1, this means that a unit change in the underlying X causes a decrease in the probability that the outcome changes category.
When exp(β)>1, this meansthat a unit change in the underlying X causes an increase in the probability that the outcome changes category (i.e. changes cluster). On the contrary, when exp(b)<1, this means that a unit change in the underlying X causes a decrease in the probability that the outcome changes category.
The authors hypothesised the existence of differences between sociodemographic groups in terms of health state utilities and that the sociodemographic characteristics of the individuals affect the probability of belonging to a certain group of, for instance, higher levels of health utilities. This knowledge about what can lead to a move from one group to another can be used in health policy to prevent the deterioration of the utility values.
Results
Sample
In total, 2,459 respondents, with a mean age of 37 years (standard deviation (sd) 11 years) completed the SF-36v2. The sample was predominantly female (58.1%), married or living together with someone else (69.5%), with low educational level (46.8%). The respondents were most frequently non-manual workers (41.6%), living in rural areas (63.1%) ().
Table 1. Study sample characteristics.
The sample also reported a considerable number of chronic conditions grouped into categories (), especially musculoskeletal disorders (62.5%), respiratory disorders (36.7%) and hypertension (29.9%). These rates are not statistically different from the prevalence of these conditions in the general population.
Table 2. Chronic conditions of study sample (n=1,853).
Health-related quality of life
The distribution of responses to the SF-6D dimensions is shown in . These results reveal substantial levels of impairment in Role Limitations, Pain, Mental Health and Vitality (more than 56% of individuals chose levels 3–6). In addition, almost 67% of subjects identified some limitations in their Physical Functioning and 54% in their Social Functioning.
Table 3. Distribution of responses to SF-6D dimensions (%).
summarises the mean, sd, and minimum and maximum of each SF-6D dimension. Each dimension value is obtained by adding its correspondent coefficient to 1.00 (perfect health). Vitality presents the highest mean value, and Mental Health the lowest.
Table 4. Descriptive statistics of SF-6D dimensions.
As prevoiusly stated, according to the final model of SF-6D developed by Brazier et al15, the final boundaries of the SF-6D multiattribute utility values are 0.30 and 1.00, where 0.00 represents death and 1.00 is perfect health.
The use of post-stratified estimators enabled the mean utility and the sd of the Portuguese working age population health states to be compared, achieving a value of 0.697 (sd 0.143). The sample based on gender and age was post-stratified. The mean values and sd of the Portuguese working age population health status utilities by gender, age group, marital status and educational level were computed through the post-stratified estimator for domains and the results are presented in
Table 5. Descriptive statistics of SF-6D values by gender, age group, marital status and educational level*.
Although the representativeness of the sample for the whole population is guaranteed by the post-stratification, the real explanation of the figures presented in is dependent on the joint distribution of age/gender. As usual, women have a lower SF-6D score than men and reported significantly more problems in all dimensions than men (t = -10.172; degrees of freedom (df) = 2116; p<0.001). Gender differences were especially large for Pain, Mental Health and Physical Functioning. As was also expected, younger people (18–34 years) reported higher levels of utility values and these differences were significant in all age groups (H = 73.962; df = 4; p<0.001). However, these reported values are not as high as in other populations, perhaps owing to a Portuguese tendency of reporting low scores (seeCitation26–28, for instance).
The mean utility values were 0.13, lower in the lower educational level than in the higher educational level (H = 186.113; df = 3; p<0.001). People living in rural areas reported lower levels of utility values (t = 2.935; df = 2422; p<0.005). Single people and people married or living together reported higher levels of health utilities than widowed and divorced or separated people (H = 65.541; df = 3; p<0.001). Non-parametric tests showed that health utility values were also significantly related to employment (H = 196.456; df = 4; p<0.001): unskilled manual workers (0.68) reported lower utility values than non-manual workers (0.74). For different diseases, mean utility values ranged from 0.58 (sexually transmissible diseases) to 0.66 (hepatitis), as can be seen in .
Table 6. Descriptive statistics of SF-6D values by chronic conditions.
Classifying individuals
Although the between-groups method and the Centroid method of the hierarchical cluster analysis were inconclusive, the other methods (the Ward's, the furthest neighbour and the nearest neighbour) pointed to three clusters. To obtain a better classification, a k-means cluster analysis was used through the centroids of the Ward's method. The solution of this analysis was similar to the previous one, maintaining the three clusters. Three clusters of homogeneous individuals were formed and this solution was validated with the SF-6D utility score (H= 1588.674; df = 2; p<0.001). After the validation, each group was characterised. The results are shown in and .
Table 7. Cluster profiling.
Figure 1. Distribution of SF-6D utility score across the three clusters. SF-6D values based on the Brazier tarifCitation15.
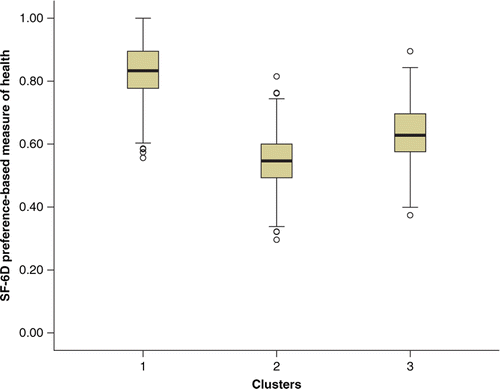
The first group is mainly formed by young males, non-manual workers or unemployed with high educational level, living in urban areas, reporting no chronic diseases and with high levels of health states utilities. On the other extreme, females aged 55–64 years, widowed, illiterate, housewives, living in rural areas, reporting at least one chronic disease and with low levels of health status utilities belong to the second cluster. Finally, the third cluster is mainly formed by slightly younger females, with higher educational level than the previous cluster and unskilled manual workers. The health state utilities of this group of individuals were in between those referred by the other two groups.
Modelling cluster pattern probabilities
Several multinomial logit models were estimated using different combinations of variables. In some cases it was necessary to include interaction variables, to aggregate categories or to transform categorical variables (with more than two outcomes) into dummies. The results presented in were obtained by the preferred maximum likelihood estimated model.
Table 8. Multinomial logit regression model.
The overall measure of the model fitting, the -2log likelihood statistic (which has a χCitation2 distribution under the null hypothesis, assuming that all the explanatory effects in the model are zero), shows a well fitted model (χCitation2 = 347.532; df = 20; p=0.000). Goodness-of-fit statistics (comparing observed with expected frequencies) with all predictors in the model show an excellent fit (χCitation2 = 171.288; df = 178; p=0.627) by the deviance criterion. The likelihood ratio tests used to assess the significance of the independent variables in the model gave an indication of the association between the model improvement and each predictor individually. In this case, the model would be significantly degraded by the removal of any predictor, at a level of 5%. In it is also possible to find the significance levels of the Wald tests (null hypothesis assuming that the coefficients for each explanatory effect are zero) and the odds ratios (exp(b)).
Looking across rows, the odds ratios reveal that, ceteris paribus, males and individuals with no chronic disease have a low probability of belonging to groups 2 or 3, relative to being in group 1. Individuals with low educational level or illiterate individuals have a high probability of becoming a member of groups 2 or 3 compared with individuals with high education. For example, illiterate individuals have approximately 12.8 times more chances of being in group 2 than individuals with high educational level, and are approximately 2.6 times more likely to be in group 3. Older subjects relative to younger subjects are more likely to be in group 3 than in group 1 (exp(![]() = 1.938). When the effects of all other variables are held constant, being a non-manual worker increases the probability of belonging to groups 1 or 3 approximately 2 times relative to group 2. On the other hand, to be an individual aged more than 24 years and not married has a significant positive effect in distinguishing group 2 from the others. Finally, the probability of belonging to group 3 rather than to group 2 is lower for individuals not retired and living in urban areas.
= 1.938). When the effects of all other variables are held constant, being a non-manual worker increases the probability of belonging to groups 1 or 3 approximately 2 times relative to group 2. On the other hand, to be an individual aged more than 24 years and not married has a significant positive effect in distinguishing group 2 from the others. Finally, the probability of belonging to group 3 rather than to group 2 is lower for individuals not retired and living in urban areas.
Discussion
This study described the HRQOL of the Portuguese working age population and investigated sociodemographic differences. Although the sample used was randomly selected, it slightly differed from the whole population. The difference of cell weights ranges from -12.0 to 15.0%, which corresponds to a variation from 0.46 to 5.83 in sample weighting. In order to correct this, post-stratified statistical techniques were used to weight the initial results by gender and age according to the population values.
As expected, the health status values decreased with age and varied significantly with educational level: people with higher educational level had higher levels of health state utilities. Males, single people, non-manual workers and those living in urban areas reported higher health state values. This result suggests that HRQOL is strongly related to gender, age and educational level and varies between manual and non-manual workers as well as between people living in rural or urban areas. The findings generally support the results of Burström et alCitation5, Hoeymans et alCitation6 and Ferreira and SantanaCitation14, who studied, respectively, the Swedish and Dutch population HRQOL and the Portuguese health status perception, using in the first two cases the EQ-5D and in the last case the SF-36. Previous studies conducted in an adult US sampleCitation29, in a Swedish national surveyCitation4 and in a UK national questionnaire surveyCitation2 also reported sociodemographic differences in health status using SF-12 and EQ-5D with regard to age, gender, marital status, social class, educational level, economic status and smoking behaviour. There were also similar results in other countries supporting this result, a promising finding in itself with regard to the validity of the Portuguese version of the SF-6D.
The differences in HRQOL between sociodemographic groups found in this study should be further investigated in terms of health inequalities, since other investigatorsCitation30 concluded that gender, age and educational level explained a great part of health inequalities in 15 countries, with age playing the most important role. A possible line of research could start by conducting a multivariate regression analysis of SF-6D scores in order to compare the impact of each sociodemographic and clinical variable.
This study also demonstrated that it is possible to classify the Portuguese working age population into three clusters. In fact, the application of cluster analysis enabled us to find three different groups. These groups were differentiated in relation to gender, age, marital status, educational level, employment status, living area, absence or existence of at least one chronic disease, and heath state utilities. As expected, urban young males with high educational level, non-manual workers or unemployed persons and with no chronic disease have higher levels of utilities (cluster 1) than middle age women, widowed and illiterate reporting at least one chronic disease (cluster 2).
Cluster patterns can be seen as a range of possible attributes believed to affect the HRQOL of individuals. Each individual has a probability of following a pattern from the group set and ‘chooses’ the pattern with the highest probability given his known personal characteristics. The set of attributes used to explain the probability of belonging to a particular group were gender, absence or existence of at least one chronic disease, educational level, age, employment status and residence area. The most important results on the determinants of modelling cluster pattern probabilities can be summed up as follows. Having low educational level or being illiterate positively affects the probability of becoming a member of groups 2 or 3. Older subjects relative to younger subjects are more likely to be in group 3 than in group 1. Being a non-manual worker increases the probability of belonging to groups 1 or 3 relative to group 2. On the other hand, to be an individual aged more than 24 years and not married has a significant positive effect in distinguishing group 2 from the others. Finally, the probability of belonging to group 3 rather than to group 2 is lower for individuals not retired and living in urban areas.
The authors believe that the methodology presented in this paper can be applied to the general Portuguese population. To their knowledge, there are no published studies using this methodology in the Portuguese population, and certainly none combining the SF-6D, cluster analysis and multinomial logit regression in the Portuguese working age population. This appears to be a fruitful area for further research.
As previously stated, SF-6D is a recent preference-based, indirect utility assessment instrument created by Brazier et alCitation15. Owing to the newness of this utility assessment instrument, there have been few published studies in which it has been utilised. However, with the availability of many SF-36 datasets that could be converted into preference-based measures, it is anticipated that the application of this measure will continue to growCitation31,Citation32.
Owing to the lack of scoring function weights derived for Portugal, this study used weights derived from the general population of the UK. It is unknown whether such weights actually represent the preferences of the Portuguese working age population for SF-6D health states, since valuations of SF-6D health states have not yet been conducted in this country. As there are researchers that support the theory that the valuations for a standard set of health status are broadly similar from country to country and suggest cross-national and cross-cultural applicabilityCitation7,Citation30, the authors decided to use the UK values. Nevertheless, Portuguese people may have different constructs regarding the interrelationship between different dimensions of health, and their health status might differ from the UK valuation. In fact, there is increasing evidence that there are important differences in the SG and the time trade-off valuations emerging between the UK, the US, Japan and other European countriesCitation33. That is the reason why this research team will present, in the near future, the results of a valuation survey that is being conducted in Portugal, in which a re-valuation of the SF-6D is done.
The fact that a floor effect was found, in the sense that more than one-half of the population did report severe health problems, appears to confirm the limitations already assigned to the SF-6D. Moreover, the results stress the existence of a floor effect in the dimensions Physical Functioning and Role Limitations since there were several individuals in the worst levels of those dimensions. Future work needs to be carried out to overcome these problems and to improve the SF-6D. However, despite this, this study shows that the SF-6D was able to discriminate adequately across sociodemographic differences and therefore to distinguish between groups reporting low and high levels of problems in different dimensions, controlling for a particular characteristic such as educational level. Although it is important to take into account the floor effect, this disadvantage is balanced by the instrument's ease of use and the possibility of generating tariffs for use in cost-utility analyses.
Conclusion
As far as the authors know, this is one of the first studies to use the SF-6D to assess the HRQOL of the general population of a country. Furthermore, this is a pioneer study in Portugal, since this is certainly the first study in Portugal to assess the HRQOL of the working age population.
The authors conclude that the SF-6D is an effective and useful tool for measuring HRQOL in the community so that different population groups can be compared. The preference-based HRQOL measure used appears to discriminate adequately across sociodemographic differences, showing that the HRQOL varies greatly among sociodemographic groups. Furthermore, the results show that the HRQOL of the Portuguese working age population is higher in single young males, with high educational level, non-manual workers and living in urban areas. For different diseases, mean utility values were lower in sexually transmissible diseases, cardiovascular disorders and men with prostate problems.
This study was able to achieve normative data by age and gender for the SF-6D; it was the first study to use the SF-6D, a generic multiattribute utility instrument, to assess the health status of that population and to investigate the magnitude of the health state utilities differences between socioeconomic groups of the Portuguese working age population. Further studies should extend this to different patient groups in order to provide estimates from economic models. There also needs to be work to compare the performance of the SF-6D with other preference-based measures in the Portuguese working age population, such as the EQ-5D or the HUI, and to compare utility values provided by SF-6D with those obtained by direct elicitation techniques, such as SG.
Acknowledgements
Declaration of interest: Lara Noronha Ferreira and Luís Nobre Pereira are the beneficiaries of fellowships (SFRH/BD/25697/2005 and SFRH/BD/36764/2007, respectively) of the Foundation for Science and Technology, Portugal.
References
- Oppe M, Charro F. Population norms and their uses. In:. Measuring Self-Reported Population Health: an international perspective based on EQ-5D, Vol. 1., A Szende, A Williams. SpringMed Publishing Ltd., BudapestHungary 2004; 16–22
- Kind P, Dolan P, Gudex C, et al. Variations in population health status: results from a United Kingdom national questionnaire survey. British Medical Journal (Clinical Research ed.) 1998; 16: 736–741.
- Badia X, Schiaffino A, Alonso J, et al. Using the EuroQol 5-D in the Catalan general population: feasibility and construct validity. Quality of Life Research 1998; 7: 311–322
- Brooks R, Jendteg S, Lindgren B, et al. EuroQol: health-related quality of life. Results of the Swedish questionnaire exercise. Health Policy 1991; 18: 37–48.
- Burström K, Johannesson M, Diderichsen F. Swedish population health-related quality of life results using the EQ-5D. Quality of Life Research 2001; 10: 621–635
- Hoeymans N, van Lindert H, Westert G. The health status of the Dutch population as assessed by the EQ-6D. Quality of Life Research 2005; 14: 655–663
- Shaw J, Johnson J, Coons S. US valuation of the EQ-5D health states: development and testing of the D1 model. Medical Care 2005; 43: 203–220
- Nord E. EuroQol: health-related quality of life measurement. Valuation of health states by the general public in Norway. Health Policy 1991; 18: 25–36
- Björk S, Norinder A. The weighting exercise for the Swedish version of the EuroQol. Health Economics 1999; 8: 117–126
- Jelsma J, Hansen K, Weerdt W, et al. How do Zimbabweans value health states?. Population Health Metrics 2003; 7: 11.
- Sleskova M, Salonna F, Geckova A, et al. Health status among young people in Slovakia: comparisons on the basis of age, gender and education. Social Science & Medicine 2005; 61: 2521–2527
- Ferreira PL. [Development of the Portuguese version of MOS SF-36. Part I. Cultural and linguistic adaptation.]. Acta Médica Portuguesa 2000; 13: 55–66, [in Portuguese]
- Ferreira PL. [Development of the Portuguese version of MOS SF-36. Part II. Validation tests.]. Acta Médica Portuguesa 2000; 13: 119–127, [in Portuguese]
- Ferreira P, Santana P. Percepção de estado de saúde e de qualidade de vida da população activa: contributo para a definição de normas portuguesas. Revista Portuguesa de Saúde Pública 2003; 21: 15–30
- Brazier J, Roberts J, Deverill M. The estimation of a preference-based measure of health from the SF-36. Journal of Health Economics 2002; 21: 271–292
- Brazier J, Roberts J, Tsuchiya A, et al. A comparison of the EQ-5D and SF-6D across seven patient groups. Health Economics 2004; 13: 873–884
- Petrou S, Hockley C. An investigation into the empirical validity of the EQ-5D and SF-6D based on hypothetical preferences in a general population. Health Economics 2005; 14: 1169–1189.
- Costa A. Técnicas de Estimação no âmbito da Pós-estratificação. Dissertação de Mestrado, Instituto Superior de Estatística e Gestão de Informação. Universidade Nova de Lisboa, LisbonPortugal 2000
- Instituto Nacional de Estatística. Recenseamento da População e da Habitação (Portugal) Censos 2001. INE, LisbonPortugal 2001
- Lazzeroni L, Little R. Random-effects models for smoothing poststratification weights. Journal of Official Statistics 1998; 14: 61–78
- Pereira L. Estimação em Pequenos Domínios Utilizando Informação Seccional e Cronológica: o caso da estimação do preço médio de transacção da habitação. Dissertação de Mestrado, Instituto Superior de Estatística e Gestão de Informação. Universidade Nova de Lisboa, LisbonPortugal 2005
- Rao J. Small Area Estimation. John Wiley & Sons, HobokenNJ 2003
- Kaufman L, Rousseeuw P. Finding Groups in Data: an introduction to cluster analysis. John Wiley & Sons, New YorkNY 1990
- Menezes R. Work-history patterns. In:. Temas em Métodos Quantitativos 1., E Reis, M Ferreira. Edições Sílabo, LisbonPortugal 2000; 109–145
- Kleinbaum D, Klein M. Logistic Regression: a self-learning text, 2nd edn. Springer, New YorkNY 2002
- Sadana R, Mathers C, Lopez A, et al. Comparative analyses of more than 50 household surveys on health status. In:. Editors. Summary Measures of Population Health—concepts, ethics, measurement and applications., C Murray, J Salomon, C Mathers. World Health Organization, GenevaSwitzerland 2002; 369–386.
- Eurostat. Eurostat Yearbook 2004. The statistical guide to Europe: data 1992–2002. Office for Official, Publication of the European Communities, Luxembourg 2004.
- Eurostat. Self-Reported Health in the European Community: statistics in focus, population and social conditions. Eurostat 1997
- Johnson J, Coons S. Comparison of EQ-5D and SF-12 in an adult US sample. Quality of Life Research 1998; 7: 155–166
- Szende A. Measuring health inequalities. In:. Editors. Measuring Self-Reported Population Health: an international perspective based on EQ-5D, Vol. 1., A Szende, A Williams. SpringMed Publishing Ltd., BudapestHungary 2004; 37–42.
- Kopec J, Willison K. A comparative review of four preference-weighted measures of health-related quality of life. Journal of Clinical Epidemiology 2003; 56: 317–325
- Marra C, Woolcott J, Kopec J, et al. A comparison of generic, indirect utility measures (the HUI2, HUI3, SF-6D, and the EQ-5D) and disease-specific instruments (the RAQoL and the HAQ) in rheumatoid arthritis. Social Science & Medicine 2005; 60: 1571–1582
- Lubetkin E, Jia H, Gold M. Construct validity of the EQ-5D in low-income Chinese American primary care patients. Quality of Life Research 2004; 13: 1459–1468