Abstract
Long-term immunity, evaluated by the persistence of antibody titers, is important to assess duration of protection induced by vaccination. This paper aims at drawing awareness on the risk of misinterpreting persistence results in absence of adjustment for missing or left-censored data. Using simulations, the paper shows that repeated measurement models are an appropriate alternative to control the bias associated to unadjusted persistence results.
1. Introduction
Many vaccine clinical studies are set up for assessing the duration of protection induced by vaccination. These studies typically collect repeated measurements of immunogenicity over years. However several factors can lead to missing data such as subjects withdrawing from the study, blood sample results not available, unevaluability of the results due to natural disease exposure or revaccination. In addition, immunogenicity, measured by antibody titer, decreases over time and may become unmeasurable as soon as passing below the cut-off of an assay quantification. In these cases the titer is left-censored as its exact value is only known to be below the cut-off. Unfortunately the amount of missing and left-censored values increases over time.
Despite various publications on the risk of misinterpretation in presence of missing/incomplete data,Citation1-Citation3 many researchers keep publishing persistence studies by providing summary at each persistence time point, without taking into account missing or left-censored data and without accounting for the repeated nature of the results over time.
In this paper we examine the bias generated by an analysis unadjusted for missing and left-censored data and we show how this can be corrected by repeated measurement models. We introduce the terminology in section 2. section 3 presents the different approaches for analyses. The performance of these approaches is examined using simulations in section 4. The application of the methods to a persistence clinical study is presented in section 5. Concluding remarks follow.
2. Terminology
2.1. Missingness
Missing data are one of the many issues in clinical trials. Missingness may happen due to various factors such as a subject skipping a follow-up visit or a subject dropping out of the study due to various reasons such as treatment failure or when the subject moves to another area. The reasons could thus be anything which is beyond the control of investigator or sponsor. A proper analysis should account for potential bias associated to missing observations.
There are three classifications of missing dataCitation1,Citation2,:
1. Missing Completely At Random (MCAR)
If the probability of an observation being missing does not depend on observed or unobserved measurements then the missing observation is classified as MCAR. For example, a subject has moved to another city for non-study reasons, then the subject would be considered as drop-out of a study. This subject’s data may be considered as MCAR because dropout was not in any way related to the endpoint of interest.
2. Missing At Random (MAR)
MAR corresponds to the situation where the missingness depends on the observed outcomes. In this case, whether or not a result is missing has nothing to do with the missing value itself but this is related to the values of observed results. An example of MAR data could be an instance in which a subject had low antibody titer at a previous visit which led to revaccination (rescue vaccination). Thereafter the subject dropped out as the subject could not contribute to persistence of initial vaccination. In this case, missing data at future visits depends on the results observed previously.
3. Missing Not At Random (MNAR)
The last scenario covers all other situations in which the missingness also depends on the unobserved outcomes. An example of MNAR data could be a subject for which the observed immunological results were indicative of protection up to the occurrence of the illness of interest (vaccine failure). Thereafter the subject dropped out as the subject could not contribute to persistence of initial vaccination. In this case, missing data at future visits depend on an unobserved titer that was too low to protect the subject.
Frequently, missingness is related to the outcome of interest, and thus the data are not MCAR.Citation4 The MAR assumption is much more plausible than the MCAR assumptionCitation4,Citation5 because the observed data explain much of the missingness in many scenarios.
2.2. Left-censoring
Left-censoring is also common in persistence clinical studies. Censoring occurs when the value of a measurement or observation is only partially known. Left-censoring occurs when a value is known to be below a certain value but the actual value is unknown. This is typically the case for seronegative results where titers are known to be below the assay cut-off. As titer decreases with time since vaccination, the amount of left-censored data in persistence studies increases over time. The common way to deal with left-censored data has been to impute an arbitrary value that is below the assay cut-off.
The bias induced by left-censored data has been studied in different contexts.Citation6,Citation7 The next section will illustrate the bias specific to persistence clinical studies.
3. Statistical Methods
3.1. The unadjusted approach
Most of persistence studies are currently analyzed by providing point estimate and 95% confidence intervals (CIs) for the percentage of subjects with titer above a given threshold(s) and for the geometric mean titer using results available at each persistence time point. For each time point, analysis is done independently without considering available results at other time points. In other words, for a specific persistence time point, a subject without available result at that time point is not accounted for even if the subject has results at previous or subsequent timepoints.
To deal with left-censoring, geometric mean titer computation considers that the left-censored titer is equal to an arbitrary value, often chosen as half the cut-off. As a result, geometric mean converges toward the arbitrary value as the number of subjects with titer below the cut-off increases.
The repeated measurements models presented below are possible alternatives to adjust for missing and left-censored data.
3.2. Repeated measurement models
Let Yit be the measurement for subject i at time t. The repeated data are then modeled according to a function of time. For the sake of simplification, we limit this paper to a linear model in which the repeated data from a subject evolved linearly over time with different intercepts αi per subject and common slope β between subjects i.e.
Yit = αi + β•timeit + εit i=1,..., N and t=1,..., K
where timeit represents the duration between the blood sample at time t and the last vaccine dose for subject i, αi and εit represent independent normally distributed observation with α and 0 as mean and with σ2 and ψ2 as variance, respectively. The parameters αi are technically called random intercepts and εit are called residual errors.
Note that normality of error distribution may require data trasofrmation. For antibody titers, log-transformation of antibody titers is often used as Yit .
Although this is a simple model the conclusions presented in this paper are valid for more complex models.
3.2.1. Mixed models imputing left-censored data (MM)
When Yit is exactly measurable (i.e not left-censored), the estimation of the parameters (α,β,σ2,ψ2) can be obtained using linear mixed model theory.Citation4
This approach allows the contribution of subjects with missing measurements at some time points and is available in many statistical softwares such as SAS.
To handle left-censored titers, we investigated 3 different imputation strategies as follow: (a) imputation to half of the cut-off (MM imputation of cut-off/2) (b) imputation to the cut-off itself (MM imputation of cut-off) (c) imputation to missing value (MM imputation to missing value).
In most of the vaccine clinical studies, the imputation (a) is used.
3.2.2. Mixed models without imputation of left-censored data (MMW)
It is also possible to use the left-censored data without imputationCitation8 or with multiple imputation.Citation9 In the former approach, the left-censored titers contribute to the likelihood function accounting for the probability that Yit is below the assay cut-off. In the latter approach, the left censored titers are imputed multiple values according to the truncated distribution of εit
4. Simulations
Simulations were performed in order to evaluate the impact of the left-censoring or missing values in the estimation using the different methods. Simulations are a good way to explore the performance of these methods.
4.1. Simulation plan
The simulations were performed by generating data for 200 subjects measured at 4 equidistant time points (time = 0, 1, 2, 3) and assuming true values of α, β, σ and, ψ equal to -0.05, -0.2, 0.2, and 0.5 respectively. The choice of (α, β, σ, ψ) was supported by our experience in previous long-term vaccine trials.
The percentage of left-censored data was controlled by the value of the cut-off used in different simulations. We used cut-off values of 0.1, 0.2, 0.3, 0.4, 0.5 and 0.6 respectively. shows the percentage of censored data associated to the choice of the cut-off according to the time-point.
Table 1. Percentage of left censoring according to the cut-off
The next subsections summarize the two different scenarios used in the simulations.
4.1.1. Scenario 1—No missing data
A simulated measurement was used as such when this was above the cut-off. A simulated measurement below the cut-off was considered left-censored at the cut-off. This scenario allowed measuring the impact of left-censoring in absence of missing data.
4.1.2. Scenario 2—Missing at random data
In this second scenario, missingness was added to the scenario 1. Results after observing a left-censored measurement were considered missing. This second scenario is reflecting what occurs in many vaccine studies where a subject with a measurement below the protective cut-off is revaccinated and withdrawn from further persistence follow-up. illustrates both scenarios.
Figure 1. Simulated and derived measurable results for one subject.
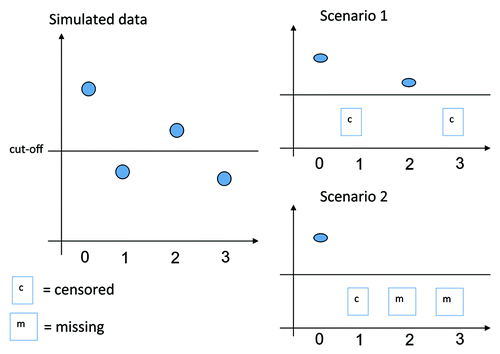
4.1.3. Assessment under the different scenarios
The performance of each of the 3 imputation strategies (the unadjusted approach, the linear mixed model (MM) or the mixed model without imputation (MMW)) was assessed by simulating 1,000 data sets and quantifying:
The bias in estimating the expected titer at the first (time 0) and last (time 3) timepoint by computing the mean of the estimate obtained from each method over the 1,000 simulated data sets
The accuracy in estimating the expected titer by computing the mean of standard deviation associated to the estimate .
The true coverage of the 95% CI, measured as the percentage of simulated data sets that led to 95% CI covering the true value expected at the first and last timepoint.
4.2. Simulation results
In this section the results obtained from the simulations are summarized. shows the results of scenario 1 according to the cut-off (reflecting the amount of left-censored measurements, see ). As a reminder, there are no missing data in this scenario.
Figure 2. Results of simulations— scenario 1—No missing data.
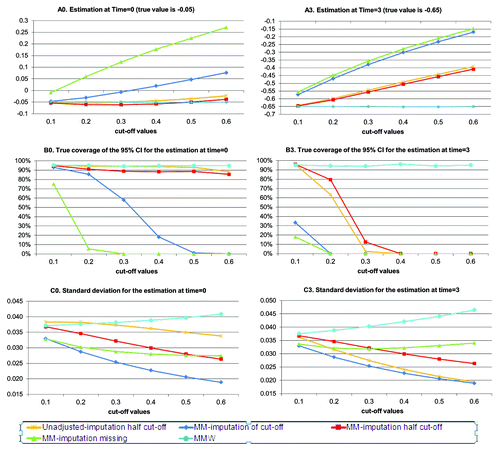
A shows that the methods diverge with the cut off used ie to the amount of left-censored data. The estimated values for unadjusted or mixed model using imputation (MM approach) become biased as the amount of left-censored data increases. On the other hand the MMW estimates are unbiased. The show that imputation approaches are associated to lower standard deviation as compared with the MMW approach, which is expected since left-censored data are imputed to a same value and imputating to missing data corresponds to removing the distribution tail. All together the 95% CIs associated to the estimated values based on imputed approaches have a poor coverage as the amount of left-censored data increases (see ). Contrarily the 95% CIs associated to the MMW estimated values appear reliable as the coverage rate is practically 95%.
Figurs shows the results of scenario 2 where data are missing at random after left-censoring. In this context the unadjusted approach with imputation to half the cut-off provides estimates that are close to the mixed model approach (MM) with imputation to missing. Namely overestimation is seen with the amount of left-censored data since the left-censored data are practically ignored for obtaining the estimates. The mixed model (MM) approach with imputation to half the cut-off appears to behave well in these simulations but as shown in scenario 1 this is not always the case. The MMW estimates continue to show convergence to true value and to provide CI with reliable coverage.
Figure 3. Results of simulations—scenario 2— Missing at random .
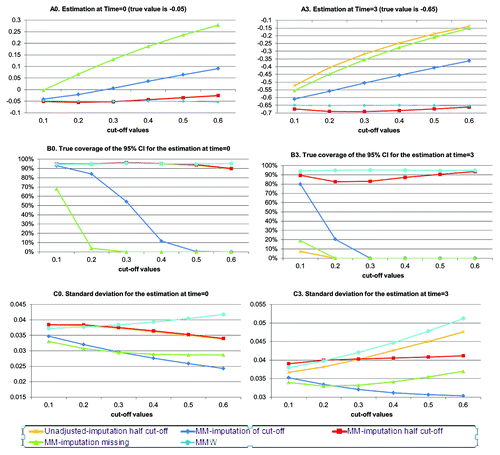
5. Illustrative Example
A Phase III clinical trial, open, multicenter study, assessing the long-term persistence of three vaccines given to 14-mo-old subjects, was used to illustrate the different approaches.Citation10 Serum samples were taken at 18, 30, 42 and 54 mo after vaccination. At each time-point, samples were tested for rSBA-MenC antibodies using a bactericidal assay. The cut-off for the assay was 1:8.
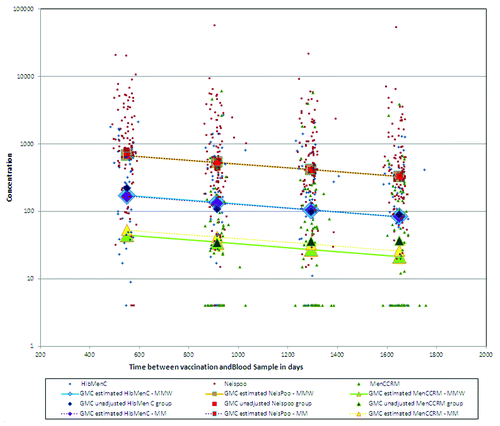
The estimates using the unadjusted approach as well as the estimates using the adjusted approaches are presented in . In this case antibody titers below the cut-off were given the arbitrary value of half the cut-off for computing geometric means. The individual data and estimated geometric means are also presented graphically in . This figure contains also the estimates from the repeated models introduced in Section 3.2. It can be seen from the figure that for the two groups called HibMenC and NeisPoo, where a small number of subjects have left-censored data, the unadjusted estimates at month 54 are in the same range as the estimates from the two repeated measurement models. For the MenCCRM group, where a larger proportion of subjects have left-censored titers, the unadjusted mean estimate at month 54 is higher than the adjusted estimates and seem to be over-estimated. Moreover, both repeated models give different results. Based on the simulation results presented in section 5 the MMW model is the most reliable.
Table 2. GMTs for rSBA-MenC antibodies estimated by the unadjusted approach and the repeated measurement approaches
Figure 4. Unadjusted and estimated rSBA-MenC GMTs.
Conclusion
This paper demonstrates that unreliable results can be obtained (1) when, in presence of left-censored data (scenario 1), inference is based on single imputation of left censored data and (2) when, in presence of data missing at random (scenario 2), inference at a time point does not account for results available at previous time points. Using a repeated measurement model accounting for left-censored data are therefore a more appropriate method.
Authors Contributions
B.C. led the project of simulations and has coordinated the paper writing. Other authors have contributed to the simulations, case study analysis and paper writing. All authors have critically reviewed the draft manuscript at various stages and have approved the final version of the manuscript.
Conflict of Interest
All authors are employed by the GlaxoSmithKline group of companies.
Role of funding source
GlaxoSmithKline Biologicals SA took in charge all costs associated with the development and publication of this manuscript.
7. References
- Carpenter JR, Kenward MG. Missing data in clinical trials—a practical guide. Available at: http://www.hta.ac.uk/nihrmethodology/reports/1589.pdf (accessed 23 Aug 2011).
- Molenberghs G, Kenward MG. Missing Data in Clinical Studies. Chichester: Wiley; 2010.
- CHMP Guideline on Missing Data in Confirmatory Clinical Trials, EMA/CPMP/EWP/1776/99, 2010.
- Verbeke G, Molenberghs G. Linear mixed models for longitudinal data. New York: Springer; 2000.
- Little RJA, Rubin DB. Statistical Analysis with Missing Data. New York: J. Wiley & Sons; 1987.
- Cain KC, Harlow SD, Little RJ, Nan B, Yosef M, Taffe JR, et al. Bias due to left truncation and left censoring in longitudinal and disease processes. Am J Epidemiol 2011; 173:1078 - 84; http://dx.doi.org/10.1093/aje/kwq481; PMID: 21422059
- Helsel DR. Fabricating data: how substituting values for nondetects can ruin results, and what can be done about it. Chemosphere 2006; 65:2434 - 9; http://dx.doi.org/10.1016/j.chemosphere.2006.04.051; PMID: 16737727
- Thiébaut R, Jacqmin-Gadda H. Mixed models for longitudinal left-censored repeated measures. Comput Methods Programs Biomed 2004; 74:255 - 60; http://dx.doi.org/10.1016/j.cmpb.2003.08.004; PMID: 15135576
- Rubin DB. Multiple Imputation for Nonresponse in Surveys, J. Wiley & Sons, New York, 1987.
- Menitorix product name, Study 106672, http://www.gsk-clinicalstudyregister.com.