Abstract
As epidemiological methods are used increasingly to evaluate the effects of cancer treatment, guidelines for the application of such methods in clinical research settings are necessary. Towards this end, we present a hierarchical step-model for causation of bias, which depicts a real-life study as departing from a perfect setting and proceeding step-wise towards a calculated, often adjusted, effect-parameter. Within this model, a specific error (which influences the effect-measure according to one of four sets of rules) is introduced on one (and only one) of the model's four steps. This hierarchical step-model for causation of bias identifies all sources of bias in a study, each of which depicts one or several errors which can be further categorized into one of the model's four steps. Acceptance of this model has implications for ascertaining the degree to which a study effectively evaluates the effects of cancer treatment (level of scientific evidence).
Validation, the process of using intuition, scientific experience and formal training to judge whether or not scientific conclusions presented are sound and justified by corresponding data, is a routine exercise for those who pursue studies evaluating treatment effects Citation[1–9]. Although epidemiological concepts are often employed in study validation, a coherent theoretical framework for the effective validation of studies documenting wanted and unwanted treatment effects remains to be defined.
Evolution of the randomized clinical trial has elicited a set of guidelines for collecting high-quality data; randomization, sham treatment, triple “blinding” and avoiding attrition are means through which high-quality data can be ensured Citation[10]. When studies have been performed with these means we have confidence in our ability to base administration of treatments on strong scientific evidence of their effects. All real-life studies deviate from the perfect setting put forward by state-of-the-art clinical trials; randomized placebo-controlled clinical trials documenting the effects of pharmaceutical agents perhaps comes closest to the perfect study.
Great measures have been taken to achieve what is conceptualized as the perfect study in the design-phase of contemporary clinical trials aimed at evaluating cancer treatment Citation[11]. Moreover, epidemiologic researchers, often working with far from perfect data sets when investigating the etiological bases of disease, spend a great deal of time wondering whether they have truly learned something from their data. A practice of validation in etiological epidemiological research has therefore evolved and some lessons can be transferred to observational studies evaluating the effect of cancer treatments.
One may consider translation of the concepts developed for validation in etiological epidemiological studies for use in clinical studies an effective solution to the dearth of formalized and coherent validation procedures in the clinical trial context; however, notable challenges complicate such direct translation. Some translation issues can be viewed as purely semantic; while a physician may conceive of an error introduced when physicians select patients with certain conditions to the treatment as selection bias, an epidemiologist would refer to this issue as confounding due to failure to validate the comparison. However, other issues are more challenging, such as those posed by the conceptual inconsistencies between etiologic and treatment effect studies and the consequent reality that those problems that are usually negligible in etiological studies may be a vital pitfall in studies evaluating treatment effects. For example, distinguishing issues contributing to selection-induced bias from those causing confounding may be straightforward in etiological studies but not when evaluating treatment effects. It is the existence of such inconsistencies which highlights the need for conceptual refinement, including development of theory.
Two previous efforts have been made to establish a comprehensive, non-statistical epidemiological theory or model for the causation of bias. One of these calls upon the metaphor of an episcope, a series of lenses lined up between the truth (the true effect-measure in the perfect study) and the conclusions actually drawn at the end of the investigation Citation[5]. The concept founding this model is that each of the lenses introduces new errors that ultimately cloud our ability to view (or achieve) the truth. Alternatively, another model portrays a series of sequential steps between the truth and the conclusions actually drawn after an investigation Citation[4]. The basis of this model is the idea that with each new phase of research, a new step is encountered, each of which introduces novel and exclusive sources of error into the study.
In the subsequent pages we build upon this second theory as we present a refinement of this hierarchical step-model for the causation of bias within studies documenting treatment effects in oncology.
Overview of hierarchical step-model structure
Based on the contemporary foundations of modern epidemiological methods, we recognize that in reality we can never achieve the perfect study in which we know with absolute certainty that our data reflect the true treatment effect Citation[11]. We can, however, theoretically define a setting in which we know that the results would be true; a theoretically perfect situation termed the “counterfactual” Citation[12]. Using such a counterfactual setting as the basis for comparison, we can proceed with validation to determine how closely a study has come to replicating the truth.
There are several ways to conceptualize the counterfactual, or theoretically perfect setting for scientific investigations aimed at learning about reality, i.e. identifying truths Citation[12]. An intuitively appealing way of picturing the counterfactual setting is to imagine a Harry Potterian stroke that duplicates earth; we have two identical and parallel worlds to observe. If we introduce our treatment in but one of these two parallel worlds, we could easily document the true treatment effects. Treatment will be in one world only, thus effects of treatment will be the only difference between the worlds.
Another mind-exercise is to picture a billion subjects randomly allocated to one of two groups, and one group only receiving treatment; this setting would provide valid data. If we want to study whether the surgical treatment procedure, radical cystectomy, influences the risk of developing the outcome, defecation urgency, the perfect setting may be defined as an environment (population) in which: (1) outcome among subjects does not vary unless treatment has been introduced; i.e. achievement of the perfect person-time in that the only exposure contributing to the person-time and the outcome is that introduced by the treatment; (2) observation of treatment and outcome status for all subjects is possible; (3) depiction of the true-rate of outcome in the population is possible and (4) no errors in handling the data from the observation occurred. These conditions could be met if we observe two parallel worlds, or one billion randomly allocated subjects without error. In such a perfect study we would derive incontrovertibly valid data concerning the treatment effects following the introduction of the treatment. We may consider the introduction of treatment into perfect person-time, and observing outcome without error, as the “perfect trial” following on which we would know with certainty whether or not radical cystectomy causes defecation urgency.
From this it follows that decreased validity in a real-life, non-perfect, study can be defined as the difference between the calculated, or adjusted, effect-measure resulting from the analysis and the true effect-measure in perfect person-time given the existence of a perfect trial. As illustrated in the following figure, one can conceptualize a real-life study as departing, step-by-step, from the perfect trial as it approaches the calculated, or adjusted, effect-measure.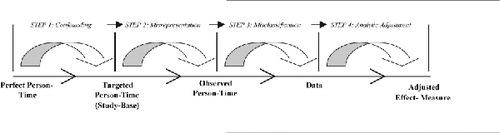
In the first step, investigators identify a targeted person-time and during this process, systematic errors summarized under the epidemiologic heading confounding may evolve. During the second step, portions of the targeted person-time may be lost due to attrition thereby leading to systematic errors characterized as misrepresentation. During the third step, measuring errors resulting during the collection of data, often termed under the heading misclassification, may decrease validity. In the final step, data are summarized into an effect-measure and are commonly statistically adjusted with the aid of covariates. This analytical alteration or adjustment affects the validity of the effect-measure; while the effect is typically an increase in result validity, this is not the assured case.
Following on this brief synopsis is a further dissection of the four sequential steps, and associated errors, contained in our hierarchical step-model for the causation of bias.
Step One: Introduction of bias due to identification of a targeted person-time (study-base) with an invalid comparison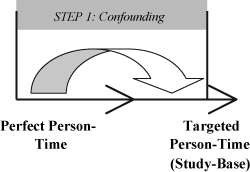
At the outset of treatment-effect studies, investigators work diligently to identify a targeted person-time that will support a valid comparison. Such a valid comparison is achieved when there is: (1) no varying occurrence of factors causally related to the outcome being compared in the two groups or; (2) no erred interpretation of the hazard curves across treatment groups due to failure to consider additional factors, such as onset of observation time in relation to disease onset, which may vary among them. When a valid comparison is not achieved, deviations from the perfect person-time will result and may lead to spurious variations in the incidence of the outcome measure across the treatment groups Citation[13–16].
The first step of the hierarchical model highlights the role of these deviations on the progression from the perfect person-time to the targeted person-time. In clinical terms, errors during this first step may be due to the absence of randomization, lack of sham treatment, failure to analyze according to the intention to treat principle and failure to consistently begin subject observation at the time of randomization or at a certain interval from time of randomization.
Many use the term confounder when referring to the factors which introduce error in this first step of this hierarchical model. However, the errors arising during this first step have been given other designations as well. These include self-selection bias, differential prescriptions bias, healthy-worker bias, healthy-patient effect, lead-time bias and inverse lead-time bias Citation[18–21]. While use and identification of these distinct terms is beneficial in the illustrative sense and meaning each impart, to use only one term for the heading of this category of errors, preferably confounding, would likely enhance our understanding and facilitate our continued recognition that all of these errors are related, if not foundationally identical.
When looking to distinguish between those errors introduced during the first step which influence the effect-measure in a way that can be foreseen (confounding) and those introduced during the second step which more often result in an unpredictable alteration of the effect-measure (misrepresentation), it is essential that one understand the criteria used for the targeted person-time of an investigation; this is perhaps particularly vital for the validation of studies documenting treatment effects. (A special situation occurs if outcome influences the demarcation of the targeted person-time. If so, errors giving an unpredictable alteration of the effect-measure might be integrated into the targeted person-time. Thus, the errors in the confounding category follow the rules of confounding only when the outcome does not influence the demarcation of the targeted person-time Citation[9].
While the magnitude of the effect of a confounder on the outcome measure depends on the strength and shape of the association between the confounder and: 1) the treatment (or exposure) and 2) the outcome being studied, this effect is always smaller than the confounder's independent effect on the outcome. Concurrently, if we know that a potential confounder either increases or decreases the frequency of an outcome, we also know that its error biases the outcome measure correspondingly. If several chains in a causal link are involved in making the errors in this step, just considering one confounder might be misleading Citation[17].
Step Two: Introduction of bias due to misrepresentation of the targeted person-time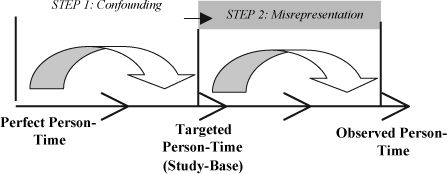
In the second step of the hierarchical model, non-participation, loss of subjects to follow-up, and sampling from the targeted person-time (as done in case-control studies) result in incomplete collection of the information available from the targeted person-time resulting at the culmination of step one. In the model, this second step is illustrated by the progression from the previously targeted person-time to the observed person-time.
Errors in this second step can be regarded as being generated with the separation of a “piece” of the targeted person-time in which the true effect-measure differs from that in the targeted person-time. Examples of such errors in cohort studies include loss of a portion of the planned follow-up period for a specific subject and inappropriate exclusion of subjects (generating the person-time) when researchers fail to perform an intention-to-treat analysis; some use the general term, attrition bias, to describe such alterations in validity that arise due to incomplete follow-up of certain subject Citation[1], Citation[22]. Alternatively, in a case-control setting, an erroneous selection of controls, i.e. selection of controls that do not reflect the distribution of the treatment (exposure) in the targeted person-time, is likely to alter the resulting effect-measure due to misrepresentation of that person-time. Observing but not publishing data from targeted person-time might lead to a misrepresentation of targeted person-time in the literature (“publication bias” Citation[23]).
Each of the aforementioned errors contributes to the loss of a portion of the targeted person-time and thereby misrepresents it. Ultimately, this misrepresentation leads to deviation between the true effect-measure in the observed person-time (now incomplete) and the true effect-measure in the targeted person-time (study-base). Unlike the errors introduced in step one which often cause predictable alterations of the calculated effect-measure, the errors introduced in this step influence the effect-measure in an unpredictable way; the effect-measure can be augmented in any direction and by a large magnitude. One may calculate the maximum possible deviation of the effect-measure from reality by simulating the worst possible scenario for a certain rate of non-participation or loss-to-follow-up however the relevance of external information for understanding the impact of loss of a portion of the targeted person-time is a matter of judgment.
Step Three: Introduction of bias due to measuring errors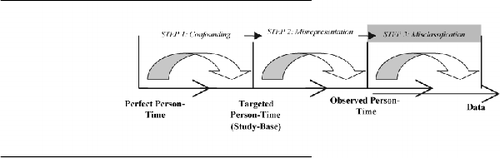 Within research investigations measuring errors occur when the data are collected Citation[24]. According to the hierarchical step-model, the introduction of measurement error in the third step leads to deviations between the calculated effect-measure in the observed person-time and the crude effect-measure inherent in the data.
Within research investigations measuring errors occur when the data are collected Citation[24]. According to the hierarchical step-model, the introduction of measurement error in the third step leads to deviations between the calculated effect-measure in the observed person-time and the crude effect-measure inherent in the data.
A plentitude of terms are used to denote bias caused by measuring errors. These include ascertainment bias, detection bias, diagnostic bias, information bias, performance bias, recall bias, interviewer bias and surveillance bias. For purposes of conceptual understanding and simplification, however, it is appropriate to simplify the terminology and discuss each of the aforementioned biases within the framework of bias caused by measuring errors.
The concepts of sensitivity and specificity, which quantify discrepancies between the data collected and the true status, epidemiological researchers use to characterize measuring errors. While many associate these concepts only with diagnostic tests, they can be readily applied to assess errors in the measurement of treatment and outcome status in studies of treatment effects and etiologic bases of disease. For example, in the setting of a case-control study, recall bias often means that the sensitivity and specificity of the information on exposure differs between cases and controls. In a clinical trial, sensitivity and specificity can vary when an outcome-assessor is aware of the treatment-level or group of individual subjects.
Several rules pertain when assessing the deleterious impact of measuring errors on the validity of a study. Foundationally, the magnitude and direction of the alteration of the effect-measure may or may not be predictable depending on: (1) sensitivity and specificity in measuring the treatment and outcome status of subjects; (2a) whether the error in measuring outcome varies between the treatment (or exposure) groups; (2b) whether the error in measuring treatment (or exposure) varies with the outcome and (3) whether the outcome measure is a ratio or a difference (). If the sensitivity in detecting an outcome is decreased to the same level across all treatment groups, for example, if a radiological examination misses half of the patients with metastatic lesions but the decreased detection is the same across all treatment groups, than this will not affect the validity of the effect-measure—if the effect-measure is a ratio. Alternatively however, as a general rule a measuring error of outcome that varies according to treatment or exposure will always decrease validity and may likely lead to comparisons and analytic results that are misleading Citation[25].
Table I. Misclassification: Predicted alteration of effect-measures by type of measuring error and effect-measure.
Step Four: Analytic alteration of the effect-measure
When going from the data resulting from the studied person-time, to the calculated, often adjusted, effect-measure, analytic alteration alters the validity of the results Citation[26–28]. Typically investigators statistically alter the effect-measure from the crude measure inherent in the data to an adjusted effect-measure in a way that eliminates bias. The statistical techniques commonly employed during such alteration include stratification or modeling with regression analyses while considering covariates or risk factors of the outcome that are potential confounders, as well as the production of hazard curves to depict where on the curves the observations lie or factors correlated with varying misrepresentation or measuring errors. The magnitude and predictability of alternation in the effect-measure induced by analytic alteration depends on the: 1) statistical techniques utilized; 2) whether the covariates used for stratification or modeling are chosen appropriately and 3) whether there are errors in measuring confounders or other variables indicating misrepresentation or misclassification which are used as covariates.
One example of an investigation in which analytic alteration would be appropriate to improve result validity is a study of localized prostate cancer where death is the end point, and cancer stage and grade, as well as level of prostate-specific antigen are potential confounders—they have been seen to predict death from prostate cancer. Given their potential relationship with the outcome, death from prostate cancer, cancer stage, cancer grade and prostate-specific antigen levels would be included as covariates in stratification procedures or a modeling analysis. The outcome of such an analytic alteration would be an adjusted effect-measure which, following controlling for these covariates, more closely depicts the true effect-measure for the association. It is worthy to note here that an additional benefit of this analytic adjustment would be that adjusting the effect-measure for age could diminish bias that had been introduced due to misrepresentation of the targeted person-time if loss to follow-up on outcome varied across age groups. At the same time, this adjustment might also eliminate some of the bias due to measuring errors if the diagnostic sensitivity in measuring the endpoint fluctuated in relation to age.
While the aforementioned text and examples illustrate the many procedures available during the fourth step to increase validity through analytic alteration, it is important to note that like the previous steps in the model, the fourth step is not free of the introduction of additional sources of bias. One such error introduced during this step is that which arises when researchers use statistical models with a poor goodness of fit to assess the effect-measures arising from the collected data.
Remedies
provides an overview of remedies for increasing validity before and during a study, as well as suggestions for validation of a study following its completion.
Table II. Remedies for increasing validity before and during a study, as well as suggestions for validation post-study completion.
Causality assessment
Following from our discussion, the term validation implies: (1) identification of all systematic errors, or potential sources of causation of bias, in a study; (2) an assessment of whether identified errors can be classified as belonging to the first, second, third or fourth step; (3) an estimation of how the magnitude and direction of error alters or biases the effect-measure and (4) a judgment of how the magnitude and direction of the calculated effect-measure deviates from the output of a perfect study based on consideration of the joint bias, or joint effect of all the errors identified. It is only once the investigator has summed up the effect of all of the errors and determined whether treatment truly influences outcome that the validation is complete.
One needs validation theory as well as subject matter knowledge to validate real-life findings. To assess whether lack of sham treatment hinders us from evaluating the effect of cancer surgery on survival, it is helpful to understand factors promoting or hindering tumor growth. To realize whether or not the removed tumor hinders an understanding of whether or not cancer surgery influences symptom occurrence, it is helpful to have knowledge about potential mechanisms for a specific symptom's pathogenesis.
Implications
It follows from both the hierarchical step-model for causation of bias and the “Episcope” theory that variation in validity between studies is one of degree, not kind. We cannot, as is sometimes done, rank completed real-life studies according to validity based on simple design-details, such as randomization.
Studies enrolling a randomized comparison are not categorically different from studies with alternative designs; errors in the second, third and fourth steps are as important to consider as errors in the first (confounding). If large enough, a randomized comparison does not suffer from decreased validity due to unmeasured confounders (first step), an issue for all non-randomized comparisons regardless of population size. Concurrently, a non-randomized quasi-experimental study with good control of potential confounders, small attrition and measuring errors that do not vary between treatment groups may have better validity than a randomized study with large attrition and un-blinded outcome assessment.
Moreover, we do not need a study approaching the perfect study, nor do we need as high degree of evidence as possible. What we need is a study valid enough to answer the scientific questions asked; when the scientific question has been answered ranking on strength of study-design is not necessary. When the scientific question has been answered, ranking according to “degree of scientific evidence” becomes a non-issue.
In studies evaluating treatment effects, errors including: (1) the presence of unknown and undetected confounders; (2) loss of a piece of the targeted person-time; (3) variations in measuring errors across treatment groups and (4) erroneous calculations and adjustments may lead to unpredictable and potentially detrimental alterations of the calculated effect-measure. These four sources of error pose major concerns during the validation process and each should be given equal attention (). Errors can be understood and managed. The hierarchical step-model presented here can be seen as an all-inclusive top-down model for causation of bias; a bottom-up model for causation of bias, built on so-called DAGs others work with Citation[17]. Ultimately, the approaches probably can be fused. Clinical trial researchers have shown us how high-quality data can be collected. Going forward epidemiologists can demonstrate how we can learn about treatment effects in real-life studies that deviate from the perfect study.
Table III. Validity-influencing characteristics of some errors introduced in each of the four steps defined by the hierarchical step model.
We would like to thank Professor Hans-Olov Adami and Professor Howard Scher for their critical reading of early manuscripts. The presented hierarchical model for causation of bias lies inherent in the theoretical work by Staffan Norell, now deceased. The work was supported by grants from the Swedish Cancer Society.
References
- Sackett DL. Bias in analytic research. J Chron Dis 1979; 32: 51–63
- Norell S. A workbook of epidemiology. Oxford University Press, Oxford 1995
- Rothman KJ, Greenland S. Modern Epidemiology2nd ed. Lippincott, Williams & Wilkins, Philadelphia 1998
- Steineck G, Kass P, Ahlbom A. A comprehensive clinical epidemiological theory based on the concept of the source person-time and four distinct study stages. Acta Oncol 1998; 37: 15–23
- Maclure M, Schneeweiss S. Causation of bias: The episcope. Epidemiology 2001; 12: 114–22
- Miettinen OS. Design options in epidemiologic research: An update. Scand J Work Environ Health 1982; 8: 159–68
- Miettinen OS. Theoretical epidemiology: Principles of occurrence research in medicine. John Wiley and Sons, New York 1985
- Hernán MA, Hernandez-Diaz S, Robins JM. A structural approach to selection bias. Epidemiology 2004; 15: 615–25
- Adami HO. What can epidemiological methods mean to surgical research?. Ups J Med Sci 1988; 93: 155–60
- Rothman KJ. Epidemiology in clinical settings. Epidemiology: An introduction, KJ Rothman. Oxford University Press, New York 2002; 211
- Rothman KJ. Measuring disease occurrence and causal effects. Epidemiology: An introduction, KJ Rothman. Oxford University Press, New York 2002; 45–6
- Hernán MA. A definition of causal effect for epidemiological research. J Epidemiol Community Health 2004; 58: 265–71
- Steineck G, Adolfsson J. Bias due to observation of different parts of a hazard curve over time. Urology 1996; 448: 105–9
- Datta M. You cannot exclude the explanation you have not considered. Lancet 1993; 342: 345–7
- Miettinen OS. Efficacy of therapeutic practice: Will epidemiology provide the answers?. Drug therapeutics – concepts for physicians, KL Melmon. Elsevier-North Holland, New York 1980; 201–8
- Norell S. A short course in epidemiology. Raven Press, New York 1992
- Hernán MA. Causal knowledge as a prerequisite for confounding evaluation: An application to birth defects epidemiology. Am J Epidemiol 2002; 155: 176–84
- Holmberg L, Steineck G. Indications for treatment can introduce bias in observational studies of surgical treatment. Eur J Surg Oncol 1993; 19: 223–5
- Hutchinson GB, Shaprio S. Lead time gained by diagnostic screening for breast cancer. J Natl Cancer Inst 1968; 41: 665–81
- Feinleib M, Zelen M. Some pitfalls in the evaluation of screening programs. Arch Environ Health 1969; 19: 412–5
- Leon DA. Failed or misleading adjustment for confounding. Lancet 1993; 342: 479–81
- Feinstein AR. Epidemiologic analyses of causation: The unlearned scientific lessons of randomized trials. J Clin Epidemiol 1989; 42: 481–9
- Gleser LJ, Olkin I. Models for estimating the number of unpublished studies. Stat Med 1996; 15: 2493–507
- Mertens TE. Estimating the effects of misclassification. Lancet 1993; 342: 418–21
- Steineck G, Whitmore WF, Jr, Adolfsson J. “Local recurrence” and “disease-free survival”; doubtful parameters when comparing non-randomized studies of prostate cancer. Scand J Urol Nephrol 1991; 138: 121–6
- Greenland S. Summarization, smoothing, and inference in epidemiologic analyses. Scand J Soc Med 1993; 21: 227–32
- Greenland S. Modeling and variable selection in epidemiologic analyses. Am J Public Health 1989; 79: 340–9
- Greenland S. Concepts of validity in epidemiological research. Oxford Textbook of Public Health Volume 2, Methods of Public Health2nd ed, WW Holland, R Detels, G Knox. Oxford University Press, New York 1991; 253–70