
Abstract
Objective: The current update of the Ease of Language Understanding (ELU) model evaluates the predictive and postdictive aspects of speech understanding and communication.
Design: The aspects scrutinised concern: (1) Signal distortion and working memory capacity (WMC), (2) WMC and early attention mechanisms, (3) WMC and use of phonological and semantic information, (4) hearing loss, WMC and long-term memory (LTM), (5) WMC and effort, and (6) the ELU model and sign language.
Study Samples: Relevant literature based on own or others’ data was used.
Results: Expectations 1–4 are supported whereas 5–6 are constrained by conceptual issues and empirical data. Further strands of research were addressed, focussing on WMC and contextual use, and on WMC deployment in relation to hearing status. A wider discussion of task demands, concerning, for example, inference-making and priming, is also introduced and related to the overarching ELU functions of prediction and postdiction. Finally, some new concepts and models that have been inspired by the ELU-framework are presented and discussed.
Conclusions: The ELU model has been productive in generating empirical predictions/expectations, the majority of which have been confirmed. Nevertheless, new insights and boundary conditions need to be experimentally tested to further shape the model.
Background
Over the last decade and a half the research community has increasingly acknowledged that successful rehabilitation of persons with hearing loss must be individualised and based on assessment of the impairment at all levels of the auditory system. Studying the system means taking into account impairments from cochlea to cortex, and combining this with details of individual differences in the cognitive capacities pertinent to language understanding. Several views on and models of this top-down–bottom-up interaction have been formulated (e.g. Holmer, Heimann, and Rudner Citation2016; Luce and Pisoni Citation1998; Marslen-Wilson and Tyler Citation1980; Pichora-Fuller et al. Citation2016; Signoret et al. Citation2018; Stenfelt and Rönnberg Citation2009; Wingfield, Amichetti, and Lash Citation2015).
The ELU model (Rönnberg Citation2003; Rönnberg et al. Citation2008, Citation2010, Citation2013, Citation2016) represents one such attempt. It provides a comprehensive account of mechanisms contributing to ease of language understanding. It has a focus on the everyday listening conditions that sometimes push the cognitive processing system to the limit and thus may reduce ease of language understanding (cf. Mattys et al. Citation2012; Wingfield, Amichetti, and Lash Citation2015). As such, it is intimately connected with the field of Cognitive Hearing Science (CHS), which studies the cognitive mechanisms that come into play when we listen to impoverished input signals, or when speech is masked by background noise, or some combination of the two. Other factors of interest are familiarity of accent and language, speed and flow of conversation as well as the phonological, semantic and grammatical coherence of the speech. The characteristics of the listener in terms of sensory and cognitive status are also important, along with his/her linguistic and semantic knowledge and access to social and technical support. Furthermore, in a recent account of listening effort (i.e. the Framework for Understanding Effortful Listening, FUEL), Pichora-Fuller et al. (Citation2016) show that it is also heuristically useful and important to consider an individual’s intention and drive to take part in listening activities to reach listener goals, in combination with demands on (perceptual and cognitive) capacity. In the ELU account, the first step has been to address some of the cognitive mechanisms that contribute to the ease with which we understand language.
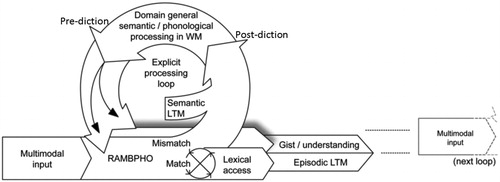
Cognitive functions that have been discussed and researched in relation to ease of language understanding are primarily working memory (WM) and executive functions such as inhibition and updating (e.g. Mishra et al. Citation2013a, Citation2013b; Rönnberg et al. Citation2013). According to the ELU model, WM and executive functions come into play in language understanding when there is a mismatch between input and stored representations (Rönnberg Citation2003), i.e. when the input signal does not automatically resonate with phonological/lexical representations in semantic Long-Term Memory (LTM) during language processing. Mismatch is mediated in the RAMBPHO buffer whose task is the Rapid, Automatic, Multimodal Binding of PHOnology. When mismatch occurs, the success of language understanding becomes dependent on WM and executive functions. However, it is also important to note that when mismatch is extreme, cognitive resources and drive to reach goals may not be sufficient to ultimately achieve understanding (Ohlenforst et al. Citation2017).
In some more detail, the RAMBPHO component is assumed to be an efficient phonological buffer that binds representations based on the integration of multimodal information (typically audiovisual) relating to syllables. These representations feed forward in rapid succession to semantic LTM (see ). If the RAMBPHO-delivered sub-lexical information matches a corresponding syllabic phonological representation in semantic LTM, then lexical access will be successful and understanding ensured. Conversely, lexical activation may be unsuccessful or inappropriate if there is a mismatch between the output of RAMBPHO and representations in semantic LTM. In this case, understanding is likely to be compromised unless sufficient context is available to allow disambiguation.
Figure 1. The Rönnberg et al. (2018) version of the ELU-model, based on Rönnberg et al. (Citation2013) in Frontiers in Systems Neuroscience.
The original observations made by Lunner (Citation2003), Lunner and Sundewall-Thorén (Citation2007) and Rudner et al. (Citation2008, Citation2009) showed that familiarisation during 9 weeks to a certain kind of signal processing (i.e. fast or slow wide dynamic range compression in this case), reduced dependence on WMC of speech recognition in noise with the same kind of signal processing. When speech-recognition-in-noise testing was done with the non-familiarized signal processing mode, however, dependence on WMC was substantial and significant. The interpretation given was in terms of phonological mismatch (Rudner et al. Citation2008, Citation2009). We have later generalised the mismatch notion to also include semantic attributes (due to joint storage functions), although we still assume that the bottle-neck of lexical retrieval depends on phonological attributes (Rönnberg et al. Citation2013). However, it should be noted that these results were found for matrix sentences.
Matrix sentences are based on a grammar which is simple and predictable but where the actual lexical name of e.g. an object can only be guessed if it has not been heard. For example: The Hagerman (Citation1982) (Hagerman and Kinnefors, Citation1995) and Dantale2 (Hernvig and Olsen, Citation2005) materials consist of five-word sentences comprising a proper noun, verb, numeral, adjective, and noun, presented in that order. Thus, they are similar as regards both form and to some extent the content. Similar grammatical structures apply e.g. the Oldenburg matrix test (Wagener, Brand, and Kollmeier Citation1999), and have been adopted in many other languages including English and Russian.
However, other kinds of sentence materials higher on contextual support (e.g. the Swedish Hint sentences, Hällgren, Larsby, and Arlinger Citation2006) or high on predictability (e.g. SPIN sentences, Wilson et al. Citation2012), deliver an initial support in sentence beginnings that facilitate predictions of final words. We have been able to show that the dependence on WMC decreases rather than increases in such a case (Rönnberg et al. Citation2016). With high lexical predictability and a tight context, the reliance on cognitive “repair” functions such as WM is reduced. In other words, intelligent guesswork and inference-making does not seem to be needed to the same extent as for matrix sentences (e.g. Rudner et al. Citation2009). The data in those studies show that the correlation with WMC was practically nil, regardless of familiarisation procedures (Rudner et al. Citation2009). This pattern of results was recently replicated in a large sample drawn from the so called the n200 data-base (Rönnberg et al. Citation2016). The pattern is further corroborated in gating studies from our lab, where we have compared gating of final words in predictable vs. less predictable sentences (for details see Moradi, Lidestam, Rönnberg Citation2013, Citation2016; Moradi, Lidestam, Saremi, et al. Citation2014; Moradi, Lidestam, Hällgren Citation2014). Again, the dependence on WMC is lower with predictable sentences.
Details regarding the number of phonological/semantic attributes needed for a successful match—i.e. the threshold at which the degree of overlap of attributes triggers lexical activation (Rönnberg et al. Citation2013)—is left open and can only be addressed by studies using well-controlled linguistic materials. In general, when the threshold(s) for triggering lexical access are not achieved, the basic prediction is that explicit, elaborative and relatively slower WM-based inference-making processes are invoked to aid the reconstruction of what was said but not heard. Also, at the general level, mismatches may be due to one or more variables, including but not limited to hearing status, hearing aid fittings, energetic and informational masking and speech rate (Rönnberg et al. Citation2013, Citation2016).
The collective evidence of the predicted association between speech recognition in noise performance under mismatching conditions and WMC has been obtained in a number of studies investigating speech recognition in noise in individuals with hearing loss (in our studies, Lunner Citation2003; Foo et al. Citation2007; Rudner et al. Citation2009; Rudner, Rönnberg, and Lunner Citation2011, as well as in other labs, Arehart et al. Citation2013, Citation2015; Souza and Arehart Citation2015; Souza and Sirow Citation2014; Souza et al. Citation2015) and this work has been seminal in the development of the field of Cognitive Hearing Science (CHS). Akeroyd (Citation2008) reviewed work showing an association between speech recognition in noise and cognition and reached the conclusion that WMC is a key predictor. Besser et al. (Citation2013) performed a more extensive review of the burgeoning body of work, showing that although WMC seems to be a consistent predictor of speech recognition in various listening conditions for individuals with hearing loss, other groups only show associations under certain conditions. And recently, an experimental study corroborated correlational findings by showing that simultaneous cognitive load interferes with speech recognition in noise (Hunter and Pisoni Citation2018, see also Gennari et al. Citation2018, for neural correlates of cognitive load on speech perception).
And, even more recent evidence by Michalek, Ash, and Schwartz (Citation2018) supports the view that systematic manipulation of the signal-to-noise ratio in babble noise backgrounds show increased dependence on WMC with more challenging SNRs, even for normal hearing individuals. It could be the case that for babble noise there is a more general group-independent role for WMC (Ng and Rönnberg Citation2018). It seems that this issue is forcing a more nuanced view of WMC-dependence.
There is also evidence that degradation of the language signal per se increases cognitive load, and hence, the probability of mismatch. Individuals with normal hearing show greater pupil dilation (Zekveld et al. Citation2018) and increasing alpha power (Obleser et al. Citation2012), both established indices of cognitive load, with increasing degradation of the speech signal. Individuals with hearing loss show a similar effect but when impairment was most severe and the task hardest, alpha power dropped, indicating a breakdown in the recruitment of task-related neural processes (Petersen et al. Citation2015).
Thus, there is evidence to suggest that explicit cognitive processing occurs in participants with both normal hearing and impaired hearing under challenging listening conditions. Below, we address the dual role played by WMC in speech understanding.
Prediction and postdiction
Rönnberg et al. (Citation2013) distinguished between two aspects of the role played by WMC under the ELU framework, viz. prediction and postdiction (see ). The postdictive role refers to the cognitive mechanism which is thought to pertain post factum when mismatch has already occurred. As a matter of fact, Rönnberg (Citation2003) postulated that the actual mismatch triggers a signal which in turn invokes explicit processing resources of WM. This signal is in principle produced every time the ratio of explicit over implicit processing is larger than 1 (standardized variables). The assumption of a match-mismatch mechanism was supported by the experimental data in the Foo et al. (Citation2007) study. Given a certain kind of signal processing (FAST or SLOW compression) that was applied in experimental hearing aids for an intervention and acclimatisation period of 9 weeks, and then testing in the other phonologically mismatching condition (e.g. SLOW-FAST) caused a higher dependence on WM than e.g. in the FAST-FAST matching condition.
Hence, observed correlations between measures of WM and speech recognition in noise are assumed to reflect triggering of explicit WM functions by a certain degree of phonological mismatch. WM is the mental resource where fragmentary information can be explicitly manipulated, pieced together and used for making inferences and decisions. This is important for postdiction purposes, where the individual may need to combine contextual information with clarification from the interlocutor to be able to reconstruct what was said but not heard to access meaning and continue with the dialogue. This postdictive function is assumed to be relatively slow and deliberate and operates on a scale of seconds (Stenfelt and Rönnberg Citation2009).
The predictive role of WM, on the other hand, is assumed to involve priming and pre-tuning of RAMBPHO as well as focussing of attention in goal pursuit. In contrast to the postdictive aspect of WM, the prediction function is fast, in many instances implicit and automatic, and presumably operates on a scale of tenths of seconds (Stenfelt and Rönnberg Citation2009). Both phonological and semantic information can be used for predictive purposes (Rönnberg et al. Citation2013; Signoret et al., Citation2018; Signoret & Rudner, Citation2018). Behavioural work provides evidence that the ability to use information predictively to perceive speech is related to WMC when the speech is degraded but not when it is clear (Hunter and Pisoni Citation2018; Zekveld, Kramer, and Festen Citation2011; Zekveld et al. Citation2012). Evidence of the role of WMC in prediction is also based on the findings that WMC and WM load are related to early attention processes in the brainstem (cf. Sörqvist, Stenfelt, and Rönnberg Citation2012; Anderson et al. Citation2013; Kraus, Parbery-Clark, and Strait Citation2012; cf. the early filter model by Marsh and Campbell Citation2016). This kind of WMC-modulated attention process seems also to propagate to the cortical level. At the cortical level, when attention is e.g. deployed to a visual WM task, the brain will (cross-modally) attenuate the temporal cortex responses involved in sound processing (Molloy et al. Citation2015; Sörqvist et al. Citation2016; Wild et al. Citation2012).
In general, postdiction and prediction are dynamically related on-line processes and presumably feed into one another during the course of a dialogue. Prediction—which is fast and implicit—is assumed to be nested under the relatively slower postdiction process, i.e. several predictions may occur before explicit inference-making takes place (Rönnberg et al. Citation2013; cf. Poeppel, Idsardi, and van Wassenhove Citation2008). Related to predictive and postdictive functions of WM, we (Rönnberg et al. Citation2013) offered a set of expectations, which we use as points of departure for some more detail on recent research related to the ELU-model (see ).
Follow-up on the Rönnberg et al. (Citation2013) summary expectations
First, based on the ELU model it is expected that if RAMBPHO output is of low quality the probability of achieving a match with phonological-lexical representations in semantic memory will also be low and WM resources will have to be deployed to achieve understanding during speech processing. This expectation can be tested with different manipulations of both the speech signal and the background noise, applies primarily to participants with hearing impairment, and is related to the postdictive function of the model.
One type of study that has addressed the quality of RAMBPHO output has dealt with different kinds of signal processing in hearing instruments (e.g. Arehart et al. Citation2013). Hearing aid signal processing is intended to simplify speech processing for persons with hearing impairment, but sometimes it also causes unwanted alterations or artefacts that distort the percept in a manner that is cognitively demanding. Souza et al. (Citation2015) reviewed studies which had examined the effects of signal processing and WMC. Three types were considered: fast-acting wide dynamic range compression (WDRC), digital noise reduction, and frequency compression. Souza et al. (Citation2015) found that for fast-acting WDRC, the evidence suggests that WMC (especially tapped by the reading span task) is important for speech in noise performance. The data they reviewed also suggest that persons with low WMC may not tolerate such fast signal alterations and may benefit from slower compression times (e.g. data from our own lab Foo et al. Citation2007; Lunner and Sundewall-Thorén Citation2007; Ohlenforst et al. Citation2017; Rudner et al. Citation2009; Rudner, Rönnberg, and Lunner Citation2011). The general conclusion drawn by Souza et al. (Citation2015) was that the dependence on WMC is high for individuals with hearing impairment when listening to speech-in-noise processed by fast-acting WDRC.
The effect of hearing aid signal processing interacts with both the nature of the target speech and the type of degradation (Lunner, Rudner, and Rönnberg Citation2009; see review by Rönnberg et al. Citation2010). Rudner, Rönnberg, and Lunner (Citation2011) showed that for individuals with mild to moderate sensorineural hearing loss who were experienced hearing aid users, speech recognition in noise with fast-acting WDRC was dependent on WMC in high levels of modulated noise but only when the speech materials were lexically unpredictable, i.e. for matrix-type sentences (Hagerman and Kinnefors Citation1995). WMC dependency was not found for the more ecologically valid Hearing in Noise Test (HINT) sentences, where the sentential context aids speech processing (Hällgren et al. Citation2006; see also Rönnberg et al. Citation2016). Note that there is always going to be a dynamic ratio between implicit and explicit processes (see original mathematical formulations in Rönnberg Citation2003), depending on the current conditions. When explicit processes dominate over implicit processes, then a mismatch signal is assumed to be triggered.
Other very recent data from the n200 study (Ng and Rönnberg Citation2018; Rönnberg et al. Citation2016), also using matrix-type sentences, suggest that the type of background noise is important, across different kinds of signal processing conditions. The name n200 refers to the number of participants in one group with HL who use hearing aids in daily life (age range: 37–77 years, Rönnberg et al. Citation2016). Ng and Rönnberg (Citation2018) compared 4-talker babble and stationary noise and found for the 180 hearing aid users included in that sub-study that the dependence on WMC was significantly higher for 4-talker babble than for stationary noise. This also holds true for another n200 study by Yumba (Citation2017), where babble noise seemed to draw on WMC, irrespective of signal processing conditions. In addition, the study by Ng and Rönnberg (Citation2018) demonstrates that dependence on WMC may persist for much longer periods of time (2 to 5 years) than expected on the basis of our previous work, i.e. Ng et al. (Citation2014; 6 months) and Rudner et al. (Citation2009; 9 weeks).
For other types of hearing aid signal processing such as noise reduction and frequency compression, WMC dependence is not as clear as for WDRC (Souza et al. Citation2015, but see Yumba Citation2017). However, there are certain kinds of exceptions. In the studies by Ng et al. (Citation2013, Citation2015) it was shown that implementation of binary masking noise reduction can lead to improved memory for HINT materials for experienced hearing aid users with mild to moderate hearing loss. This improvement was found even though there was no perceptual improvement at the favourable signal-to-noise ratios (SNRs) that characterise everyday listening situations. This shows an ecologically important aspect of postdiction that targets memory for spoken sentences and not only what can be directly perceived and understood.
Finally, we want to acknowledge the pioneering work by Gatehouse, Naylor, and Elberling (Citation2003, Citation2006), who demonstrated that there were important associations between cognitive function (i.e. the letter/digit monitoring test) and benefit obtained from fast WRDC. We can now summarise and conclude that these initial observations have been generalised in many subsequent cognitive studies involving the use of other WM tests such as the reading span test (Daneman & Merikle Citation1996).
In this follow-up, we have also seen that the degree of hearing loss plays a role as well as type of background noise, but the ELU prediction is most clearly borne out for fast WRDC of the signal processing algorithms investigated, while the evidence is mixed for other kinds of signal processing. Presumably, the ELU-model needs to be further developed with respect to which signal-noise processing combinations tend to mismatch more than others and why.
It should be noted that the studies reviewed concern hearing-impaired participants. Nevertheless, we know that also for normal hearing participants WMC dependence may increase when cognitive load is high or grammatical or sentence complexity is high (see under Task demands in speech processing: more on postdiction and prediction for a fuller discussion).
The second expectation is about how WMC actively modulates early attention mechanisms. As such, this expectation is related to the overall priming and prediction mechanism of the ELU model. More precisely, this expectation was based on a study by Sörqvist, Stenfelt, and Rönnberg (Citation2012) which showed that the auditory brain stem responses (ABR) of young individuals with normal hearing were dampened (linearly), as the working memory load in a concurrent visual task increased. This effect was modulated by individual differences in WMC such that in persons with higher WMC, the ABR was dampened even further. Sörqvist et al. (Citation2016) followed up the ABR study with an fMRI study with exactly the same paradigm and found that under high WM load critical auditory cortical areas responded less than under no concurrent visual WM load while the WMC-related attention system responded more. These results are in line with other work (Molloy et al. Citation2015; Wild et al. Citation2012) and show rapid and flexible allocation of neurocognitive resources between tasks.
The interpretation put forward in the Sörqvist et al. article (2016) was that WM plays a crucial role when the brain needs to concentrate on one thing at the time. In a similar vein, we also found that the amygdala reduced its activity during the high WM-load conditions (Sörqvist et al. Citation2016), which could be a means of lowering inner distractions. This reduction may prove to be an important prediction aspect of WM and crucial for persons who want to stay involved in communicative tasks without losing focus.
Third, in the ELU model WMC is assumed to mediate the use of phonological and semantic cues. Earlier work suggests that high WMC may help compensate for phonological imprecision in semantic LTM in persons with hearing impairment during visual rhyme judgment, especially when there is a conflict between orthography and phonology. The mechanism involved is a higher ability to keep items in mind to enable double-checking of spelling and sound (Classon, Rudner, and Rönnberg Citation2013). WMC is also related to the ability to use semantic cues during speech recognition in noise for young individuals with normal hearing (Zekveld, Kramer, and Festen Citation2011; Zekveld et al. Citation2012). In addition, it is related to the increase in perceptual clarity obtained from phonological and semantic cues when young individuals with normal hearing listen to degraded sentences (Signoret et al. Citation2018). However, although WMC has been shown to be related to the ability to resist the maladaptive priming offered by mismatching cues during speech recognition in noise in low intelligibility conditions by young individuals with normal hearing, it was not found to be related to the ability to resist maladaptive priming during verification of non-degraded auditory sentences, the so-called auditory semantic illusion effect (Rudner, Jönsson, et al. Citation2016). In addition, WMC predicts facilitation of encoding operations (and subsequent episodic LTM) in conditions of speech-in-speech maskers (Sörqvist and Rönnberg Citation2012). In Zekveld et al. (Citation2013) two effects were demonstrated related to WMC. First, it was shown that for speech maskers, high WMC was important for cue-benefit in terms of intelligibility gain. Second, word cues also enhanced delayed sentence recognition.
In short, participants with high WMC are expected to adapt better to different task demands than participants with low WMC, and hence are more versatile in their use of semantic and phonological coding and re-coding after mismatch.
Fourth, LTM but not WM (or STM) is assumed to be negatively affected by hearing loss. Rönnberg et al. (Citation2011) showed that while poorer hearing was associated with poorer LTM, no such association was found with WMC. The explanation for this finding was that of relative disuse between memory systems; when mismatches occur, fewer encodings into and therefore subsequent retrievals from episodic LTM will occur than when language understanding is rapid and automatic. Then, the episodic memory system is activated all the time. In particular, over the course of a day we expect that several hundreds of mismatches will occur, especially for individuals with hearing loss, and hence, that executive WM functions will be activated to process fragments of speech in relation to the contents of semantic LTM. However, in many cases, mismatch will not be satisfactorily resolved and thus, lexical access will not be achieved (i.e. disuse), leading to weakened encoding and fewer retrievals from episodic LTM. Relative disuse will then reduce the amount of practice that the episodic memory system gets. Therefore, episodic LTM will start to deteriorate, and presumably the quality of episodic representations as well. WM, on the other hand is fully occupied with resolving mismatches much of the time, and so this memory system will get sufficient practice to maintain its function.
Another interesting aspect that emerged from those data (Rönnberg et al. 2011) was that poorer episodic memory LTM function was observed despite the fact that all persons in the study were hearing aid users. Further, the decline in LTM was generalisable to non-auditory encoding of memory materials. As a matter of fact, in the best-fit Structural Equation Model (SEM), free verbal recall of Subject Performed Tasks (i.e. motor-encoded imperatives like “comb your hair”) loaded the highest among cognitive tasks on the episodic LTM construct. Hence, the potential argument that poorer episodic LTM performance with poorer hearing status was due to resource-demanding auditory encoding must be deemed as less likely. Instead it seemed that the effect of hearing loss struck at the memory system level and the ability to form episodic memories rather than being tightly coupled to a specific encoding modality.
In the follow-up study by Rönnberg, Hygge, Keidser and Rudner (Citation2014), we showed a similar pattern of data, viz that the association between poorer episodic LTM and functional hearing loss was stronger than the association between poorer visuospatial WM and hearing loss. Visual acuity did not add to the explanation. Recently, the pervasiveness of effects of untreated hearing loss on memory function was investigated by Jayakody et al. (Citation2018). They found significant negative effects with hearing thresholds for a WM test as well. This suggests that when mismatches occur too frequently or are too great, then there are too few perceived fragments to work with in WM. Hence, our additional hypothesis is that WM will also suffer from relative disuse to a larger extent for persons with untreated hearing loss than for persons with treated age-related hearing loss.
So, the new and general insight from these studies is that hearing loss has a negative effect on multi-modal memory systems, especially episodic LTM, but may be manifest also for other memory systems such as semantic memory and WM (Jayakody et al. Citation2018).There may also be neural correlates to these effects. There is evidence to indicate a loss of grey matter volume in the auditory cortex as a consequence of hearing loss (see review by Peelle and Wingfield Citation2016). These morphological changes may be related to right-hemisphere dependence of episodic retrieval (Habib, Nyberg, and Tulving Citation2003) and age-related episodic memory decline (Nyberg et al. Citation2012). In a recent study by Rudner et al. (Citation2018) based on imaging data from 8701 participants in the UK Biobank Resource, we revealed an association between poorer functional hearing and lower brain volume in auditory regions as well as cognitive processing regions used for understanding speech in challenging conditions (see Peelle and Wingfield Citation2016).
Furthermore, these morphological changes may be part of a mechanism explaining the association between hearing loss and dementia. In particular, recent evidence suggests such a link between hearing loss and the incidence of dementia (Lin et al. Citation2011, Citation2014). This notion chimes in with the general memory literature which shows that episodic LTM is typically more sensitive to aging and brain damage than semantic and procedural memory (e.g. Vargha-Khadem et al. Citation1997). The observed association between episodic LTM and hearing loss has opened up a whole new field of research (e.g. Hewitt Citation2017).
Fifth, based on the ELU model, we expect that the degree of explicit processing needed for speech understanding is positively related to effort. Since WM is one of the main cognitive functions that becomes involved when the demands on explicit processing is involved, we suggest that WMC also plays a role in the perception of effort during speech processing (Rönnberg, Rudner, and Lunner Citation2014).
One indication of this is that experienced hearing aid users’ higher WMC is associated with less listening effort (measured using ratings on a visual analogue scale) in both steady state noise and modulated noise (Rudner et al. Citation2012). McGarrigle et al. (Citation2014) wrote a “white paper” on effort and fatigue in persons with hearing impairment, wherein they used a dictionary definition of listening effort, as follows: “the mental exertion required to attend to, and understand, an auditory message”. In an invited reply to the McGarrigle et al. (Citation2014) article, we (Rönnberg, Rudner, and Lunner Citation2014) argued that the concept of effort must be related to a model of the underlying mechanisms rather than to dictionary definitions. One such mechanism is the degree to which a person must deploy explicit processing, e.g. in terms of use of WMC and executive functions (Rönnberg et al. Citation2013). Thus, the degree to which explicit processes are engaged, is generally assumed to reflect the amount of effort invested in the task. Persons with high WMC presumably have a larger spare capacity to deal with the communicative task at hand, resulting in less effortful WM processing. These notions are incorporated in the FUEL (Pichora-Fuller et al. Citation2016), which defines listening effort as “the deliberate allocation of mental resources to overcome obstacles in goal pursuit when carrying out a listening task”.
As commented on in the “white paper” (McGarrigle et al. Citation2014) pupil dilation has typically been accepted to index cognitive load and associated effort. Larger pupil dilation, indicating greater cognitive load, is found with lower speech intelligibility (Koelewijn, Zekveld, Festen, et al. Citation2012) and for single-talker compared to fluctuating or steady state maskers (Koelewijn Zekveld, Festen et al. Citation2012; Koelewijn, Zekveld, Rönnberg et al. Citation2012; Zekveld et al. Citation2018). However, pupil dilation amplitude is generally lower in older individuals (Zekveld, Kramer, and Festen Citation2011), making it a less sensitive load metric for this group. Interestingly, Koelewijn, Zekveld, Rönnberg et al. (Citation2012) found that a larger Size Comparison span (SiC span), which is a measure of WM with an inhibitory processing component (Sörqvist and Rönnberg Citation2012), was associated not only with higher speech recognition performance in a single-talker babble condition, but also with a larger pupil dilation. This pattern of findings was suggested to show that individuals with higher WMC invest more effort in listening (cf. Rönnberg, Rudner, and Lunner Citation2014; Zekveld, Kramer, and Festen Citation2011), which may seem contradictory to the above findings. However, the increase in pupil size may also reflect a more extensive/intensive use of brain networks (Koelewijn, Zekveld, Rönnberg, et al. Citation2012; see Grady Citation2012) rather than an increase in the actual load (cf. the FUEL, Pichora-Fuller et al. Citation2016). At the same time, there are other studies showing a larger pupil dilation in individuals with low WMC when performing the reading span task (e.g. Heitz et al. Citation2008), suggesting that the same cognitive task makes higher cognitive demands on low capacity individuals.
One solution to these conflicting interpretations could be that investing effort in performing a reading span task may in itself be qualitatively different from investing effort in understanding speech in adverse listening conditions (Mishra et al. Citation2013a, Citation2013b). Although a person with high WMC may show smaller pupil dilation than a person with low WMC during a WM task, the person with high WMC may show larger pupil dilation during a task that requires communication under adverse conditions, even if memory load is comparable, simply because WM resources can be more usefully deployed. This may be because there is no obvious upper limit to how adverse listening conditions can get before speech understanding breaks down. The brain probably makes the most of its available resources to understand speech (cf. Reuter-Lorenz and Cappell Citation2008). Nevertheless, recent data seems to suggest an inverted U-shaped brain function that defines the SNRs that generate maximum pupil size, given a certain intelligibility criterion (Ohlenforst et al. Citation2017). We have also shown in a recent study that concurrent memory load is more decisive than auditory characteristics of the signal in generating pupil dilation (Zekveld et al. Citation2018).
In all, the conceptual issue of what pupil size actually measures in different contexts makes the ELU expectation in terms of degree of explicit involvement (and concomitant WM processing) only an approximation of what might be a true effort-related mechanism. In addition, it seems to be hard to cross-validate effort by other physiological measures (McMahon et al. Citation2016), and certainly, other dimensions—such as task difficulty and motivation to participate in conversation—play a role as well (Pichora-Fuller et al. Citation2016).
Sixth, expectations relating to ease of language understanding are assumed to hold true for both sign and speech-based communication. One of the key features of the ELU model is its claim to multimodality. Already in RAMBPHO stage of processing, multimodal features of phonology are assumed to be bound together (Rönnberg et al. Citation2008). However, earlier work showed that there are modality-specific differences in WM for sign and speech that seem to be related to explicit processing (e.g. in bilateral parietal regions, Rönnberg, Rudner, and Ingvar Citation2004; Rudner et al. Citation2007, 2009; Rudner and Rönnberg Citation2008) and this was reflected in an early version of the ELU model (Rönnberg et al. Citation2008).
Sign languages are natural languages in the visuospatial domain and thus well suited to testing the modality generality of ELU predictions. In recent work, we have investigated how sign-related phonological and semantic representations that may be available to sign language users, but not non-signers, influence sign language processing (for a review, see Rudner Citation2018). We found no evidence that existing semantic representations influence the neural networks supporting either phoneme monitoring (Cardin et al. Citation2016) or WM (Cardin et al. Citation2017) even though we did find independent behavioural evidence that existing semantic representations do enhance WM for sign language (Rudner, Orfanidou, et al. Citation2016; see e.g. Hulme, Maughan, and Brown (Citation1991), for a similar effect for spoken language). Further, we found no effect of existing phonological representations on WM for sign language (Rudner et al. Citation2016). This was all the more intriguing as we established in a separate study that the brains of both signers and non-signers distinguished between phonologically legal signs and phonologically illegal non-signs (Cardin et al. Citation2016). However, deaf signers do have better sign-based WM performance than hearing non-signers, probably because of expertise developed through early engagement of visually based linguistic activity (Rudner and Holmer Citation2016), a notion which also explains better visuospatial WM in deaf than hearing individuals (Rudner et al. Citation2016). Furthermore, during WM processing deaf signers recruit superior temporal regions that in hearing individuals are reserved for auditory processing (Cardin et al. Citation2017; Ding et al. Citation2015).
Together, these results show, in line with other work (Andin et al. Citation2013) that although sign-based phonological information is perceptually available, even to non-signers, it does not seem to be capitalised on during WM processing. What does seem to be important in WM for sign language is modality-specific expertise supported by cross-modal plasticity. In terms of the ELU model, work relating to sign language demonstrates that phonology must be treated as a modality-specific phenomenon. This puts a spot-light on the importance of modality-specific expertise. While deaf individuals have visuospatial expertise that can be deployed during sign language processing, musical training may afford auditory expertise that can be deployed during speech processing (Good et al. Citation2017; Strait and Kraus Citation2014). Future work should continue to examine the role of modality-specific expertise on ease of language understanding.
We have started to investigate the effect of visual noise on sign language processing. Initial results show that for hearing non-signers (i.e. individuals with no existing sign-based representations) decreasing visual resolution of signed stimuli decreases WM performance and that this effect is greater when WM load is higher (Rudner et al. Citation2015). Future work should focus on visual noise manipulations and on semantic maskers to assess the role of WMC in understanding sign language under challenging conditions (Cardin et al. Citation2013; Rönnberg, Rudner, and Ingvar Citation2004; Rudner et al. Citation2007). By testing whether WMC is also invoked in conditions with visual noise, the analogous mechanism to mismatch in the spoken modality could be evaluated.
Summary of results related to the Rönnberg et al. (Citation2013) expectations
All six predictions have generated new research and new insights, which further shapes the ELU-model. With respect to the first prediction, not all kinds of hearing aid signal processing induce a dependence of WMC, but there is substantial evidence in favour of the “mismatch” assumption with respect to fast WDRC for low context speech materials. This is a postdictive aspect of the model.
Secondly, WMC also plays predictive roles, and our work on early effects on attention has proven to be robust at the cortical as well as the subcortical levels.
Third, the versatility in the use of phonological and semantic codes, has by now been investigated with several paradigms, and is the hallmark of high WMC for spoken stimuli, which may be less pronounced for phonological aspects of signed language.
Fourth, the effects of hearing loss on memory systems, especially episodic LTM, seem to be multi-modal in nature. This means that the effect of hearing loss is relatively independent of encoding and test modality. Furthermore, episodic memory decline due to hearing loss may prove to be an important link to an increased risk of dementia.
Fifth, WMC is part of the explicit function of the ELU-model, which means that explicit involvement of cognitive functions in language processing is related to subjectively experienced and objectively measured effort. We have also seen that physiological indices of effort partially measure different dimensions of effort. For pupil size, our claim is that high WMC involves an efficient brain that also coordinates and integrates several brain functions, presumably a higher intensity of brain work that also is reflected in larger pupil dilations.
Sixth and finally, sign language research has taught us several things. One aspect is that there is some modality specificity in representations of signs in the brain, which was made clear as an assumption in the Rönnberg et al (Citation2008) version of the model and important for formulating the developmental D-ELU model, with its implications for a learning mechanism (Holmer, Heimann, and Rudner 2016, see further under “Development of representations”) .
Task demands in speech processing: more on postdiction and prediction
Listening may involve a range of perceptual and cognitive demands irrespective of hearing status. There are several levels of perception and comprehension (Edwards Citation2016; Rönnberg et al. Citation2016). One key difference between perception and comprehension is that the latter, but not necessarily the former, involves explicitly inferring what a particular sentence means in the light of preceding sentences or other cues. Both functions are vital to conversation and turn-taking, especially under everyday communication conditions. Although not made explicit in previous publications on the ELU-model, the connection to task demands for prediction and postdiction processes is that prediction typically involves recall or recognition of heard items as such, while postdiction by its very nature implies additional inference-making and reconstruction of missing or misperceived information. Prediction processing that is facilitated by hypotheses or prior cues held in WM is by its implicit mechanism assumed to be direct and rapid, improving the phonological/semantic recognition of targets. Indirect, postdictive processing may involve piecing together or inferring new information that was not present during encoding, or that was sufficiently mismatching to trigger explicit WM-processing. Speech processing tasks may vary on a continuum from being very direct (template matching) to very indirect (generation of completely new information).
Postdiction
Related to the reasoning above, Hannon and Daneman (Citation2001) developed test materials to assess complex text-based, inference-making functions that are dependent on WMC. They showed that the ability to make inferences about new information, combined with the ability to integrate accessed knowledge with the new information, was dependent on WMC. It seems likely that versatility in deploying different kinds of inference-making will support continued listening under the most adverse listening conditions; the listener may e.g. have to rely on subtle ways of recombining information and may sometimes settle for getting the gist only. An analogous measure of inference-making ability, implemented for auditory conditions is now part of a more comprehensive test battery for testing both hard-of-hearing and normal hearing participants (see Rönnberg et al. Citation2016). These latter functions definitively represent a level of complexity beyond that of merely repeating or recalling words. This complexity is a prominent aspect of conversations in everyday life and calls for postdiction in all listeners, irrespective of hearing status.
Few studies in the area of speech understanding have addressed the complexity of the inference-making involved in postdiction. However, some studies have begun to take some first steps toward this angle to speech understanding. Keidser et al. (Citation2015) used an ecological version of a speech understanding test. Normal hearing participants listened to passages of text (2–4 min) and received 10 questions per passage. Here it was shown that WMC (measured by reading span) played a crucial role for task completion and for keeping things in mind while answering questions about the contents of the passage.
In another postdiction study, Sörqvist and Rönnberg (Citation2012) were able to show that episodic LTM for prose, encoded in competition with a background speech masker compared to a masker of rotated speech, was related to performance on a complex WM test called SiC span. In this task, the participant is asked to compare the size of objects (“is a dog larger than an elephant?”), after which an additional word from the same semantic category appears on the screen (the actual to-be remembered word). The SiC span test especially emphasises the participants’ ability to inhibit semantic intrusions from previous comparison items when recalling each list of to-be-remembered words. Translated to the episodic LTM task, this aspect of storage of target speech and inhibition of distracter speech, processed in WM, was thus predictive of episodic recall of facts in each story. An example of a question that had to be inferred rather than explicitly recalled verbatim was: “Why was the king angry with the messenger?” Typically, the answers were contained within a single sentence (e.g. “He refused to bow”) and were scored as correct if they contained a specific key word (e.g. “refused/bow”) or described the accurate meaning of the key words (e.g. “He did not want to bow”).
Moreover, Lin and Carlile (Citation2015) found that cognitive costs are associated with following a target conversation that shifts from one spatial location to another (in a multi-talker environment). In particular, recall of the final three words in any given sentence and comprehension of the conversation (multiple choice questions) both declined. Switching costs were significant for complex questions requiring multiple cognitive operations. Reading span scores were positively correlated with total words recalled, and negatively correlated with switching costs and word omissions. Thus, WM seems to be important for maintaining and keeping track of meaning during conversations in complex and dynamic multi-talker environments.
Independent but related work suggests that the plausibility of sentences is an important factor for postdiction. For example, Amichetti, White, and Wingfield (Citation2016) showed a stronger association between the ability to recognise spoken sentences in noise and reading span performance when the sentences were less plausible. Observe that in the reading span test, semantic plausibility judgements of “absurdity”, “abnormality” or “plausibility” of the to-be-recalled sentences (initial or final words) have been used in many studies (examples:” The train sang a song”, or the more plausible sentence, “The girl brushed her teeth”). The common denominator is a kind of semantic judgement that demands more explicit semantic processing and effort to be comprehended. As a hypothesis, the kind of semantic judgement involved in reading span is also involved in postdiction.
Generally, then, WMC is important for postdiction in speech understanding tasks that require recall and semantic processing, in particular inference-making. Since the reading span task has been designed to tap into recall and semantic processing, it is reasonable that it is positively associated with postdictive performance under these task demands (Daneman and Merikle Citation1996). The advantage of using the reading span and SiC span tasks is that their inherent complexity sometimes leads to stronger empirical associations than tasks like digit span which tap one component only (see e.g. Hannon and Daneman Citation2001). Therefore, it seems that the generality and usability of such tests outweighs “process-pure” tests in applications to real-life conversation.
Prediction
If postdiction is mainly concerned with filling-in, piecing together, or inferring what has been misperceived, prediction is more concerned with preparing the participant via prior cues or primes for what kind of materials to expect. Common to prediction studies is that semantically associated or phonologically related primes have a fast, direct and implicit framing effect on speech understanding. In one semantic priming study by Zekveld et al. (Citation2013), participants used prior word cues that were related (or not) to each sentence to-be-perceived in noise. Compared to a control condition with no cues provided, WMC was strongly correlated with cue benefit at SRT50% (in dB SNR) with a single talker distractor. Thus, in this case WMC presumably served a predictive and integrative function, whereby semantic cues were used to distinguish the semantically related linguistic content of the target voice from the unrelated content of the distracter voice. More precisely, fast priming (via cues or context held in WM) affects RAMBPHO and constrains phonological combinations (as in sentence gating), and in that sense lowers the probability of mismatch. However, given a mismatch, the explicit processes feedback to (“primes”) RAMBPHO, and onwards.
In a prediction task like final word-gating in sentences (i.e. where participants have listened to a sentence and are to guess the final word from a successively larger (gated) portion of the word, it is reasonable to assume that a predictive, semantic context unloads WM (Moradi, Lidestam, Hällgren, et al. Citation2014; Moradi, Lidestam, Saremi, et al. Citation2014; Wingfield, Amichetti, and Lash Citation2015). In the extremely predictable case (for example, “Lisa went to the library to borrow a book” compared to a low predictable sentence, for example, “In the suburb there is a fantastic valley”), we only have to rely to a small extent on the signal to achieve sentence completion and comprehension (Moradi, Lidestam, Saremi, et al. Citation2014; Moradi, Lidestam, Hällgren, et al. Citation2014).
In a recent experimental study (Signoret et al. Citation2018) we showed that predictive effects of both plausibility and text primes on the perceptual clarity of noise-vocoded speech were to some extent dependent on WMC, although at low sound quality levels the predictive effect of text primes persisted even when individual differences in WMC were controlled for. This suggests that text primes have a useful role to play even for individuals with low WMC.
Still other work on prediction, using eye movements and the visual-world paradigm (Hadar et al. Citation2016), show that WM is involved. The task in that study consists of a voice saying “point at that xxx”, and the participant has to point at one of four depicted objects on a screen (unrelated or phonologically related to the target). Eye movements toward the target object are co-registered. Hadar et al. (Citation2016) were able to show that increasing the WM load by a four-digit load delayed the time point of visual discrimination between the spoken target word and its phonological competitor. This is just another example where WMC proves to be important for ideal listening conditions even for normal hearing individuals, and is contrary to claims from the correlational review study by Füllgrabe and Rosen (Citation2016).
In all, WMC serves both predictive and postdictive purposes (cf. Rönnberg et al. Citation2013). Predictive aspects are represented by mechanisms associated with inhibition of distracting semantic information and pre-processing of facilitating semantic information (e.g. cues). When sentence predictability is high, WM is less important. However, even if a sentence is perceived and understood, the postdictive dependence on WMC may still be of a reconstructive character, demanding WMC for recall of sentences or for more complex inference-making and comprehension (see Rönnberg et al. Citation2016 test battery).
In real-life turn-taking in conversation, prediction and postdiction feed into each other. However, we offer as a speculation that the degree to which prediction/postdiction functions dominate may also be part of the motivation by an individual to engage in certain types of conversations (cf. Pichora-Fuller et al. Citation2016). Turn-taking may for example be much more effortful in a context that demands more explicit inference-making and postdiction. On the other hand, predictive expectations of a delightful conversation may either make listening less effortful or spur the listener to devote the effort necessary to achieve successful listening.
In sum, we submit that WMC plays an attention-steering and priming role for prediction by means of “zooming” in on or preloading relevant phonological/lexical representations in LTM. For postdiction, high WMC is important for inference-making in the absence of context. Prediction is dependent on storage of information necessary for priming, whereas postdictive processes are dependent on both storage and processing functions.
Recent ELU-model definitions and issues
Stream segregation
There have been several recent attempts at refining the component concepts of the ELU-model. The ELU-model has generated several important predictions and ways of investigating and testing them. In an interesting article by Edwards (Citation2016), he suggests that just before RAMBPHPO processing takes place, a process is needed that accomplishes early perceptual segregation of the auditory object from the background, so called Auditory Scene Analysis (ASA, Dolležal et al. Citation2014). His discussion is based on the Rönnberg et al. (Citation2008) version of the ELU model, where RAMBPHO processing focuses on how different streams of sensory information are integrated and bound into a phonological representation (see also Stenfelt and Rönnberg Citation2009).
However, closer scrutiny of the Rönnberg et al. (Citation2013) version reveals a mechanism that allows for such ASA processes to occur as well. In the explicit processing loop there is (1) room for explicit feedback to lower levels of e.g. syllabic processing in RAMBPHO, and (2) attentional steering and priming of RAMBPHO to earlier levels of feature extraction (cf. Marsh and Campbell Citation2016; Sörqvist, Stenfelt, and Rönnberg Citation2012; Sörqvist et al. Citation2016). Both these processes (i.e. postdiction and prediction, respectively) are mediated by WM and executive functions. Thus, a separate ASA component in the Rönnberg et al. (Citation2013) version of the ELU model is only needed when task demands do not gear explicit attention and prediction mechanisms toward early features of the auditory stream. Even simple stream segregation between tones presented in an ABA format appears to be driven by predictability (Dolležal et al. Citation2014). This implies that even at very early levels of the auditory system, there is an element of prediction that affects stream segregation, and hence, the formation of auditory and linguistic objects in RAMBPHO. It is likely that stream predictability is reduced when the signal is degraded or the listener is hard of hearing, resulting in poorer stream segregation and thus poorer quality input to RAMBPHO. This is what the ELU model is about. The additional preattentive or automatic ASA processing component suggested by Edwards (Citation2016) may therefore not be key to the ELU model and the proposed function of such a component is at least partially accounted for by Rönnberg et al. (Citation2013). Functions for coping with ambiguity and mismatch (i.e. postdiction processes) are crucial features of the model. These postdictive processes provide explicit feedback from WMC and WMC-related mechanisms, which in turn feed into RAMBPHO, continuously and dynamically, during the course of a dialogue.
Development of representations
Sign language may be able to shed light on the way in which the representations that are the key to ease of language understanding come to be established. We have shown that deaf and hard of hearing (DHH) signing children are more precise than hearing non-signing children in imitating manual gestures, but only after having had the opportunity to practice imitation and thus establish item-specific representations (Holmer, Heimann, and Rudner 2016, cf. Mann et al. Citation2010). For both groups, precision of imitation after practice was related to language comprehension skill, but in the DHH group, language modality specific phonological skill was also implicated (Holmer Heimann, and Rudner 2016). This suggests that for the establishment of functional representations, both domain general, likely to involve semantically mediated postdictive processes, and language-modality specific processing are required, and this has led to the proposal of a Developmental ELU model (D-ELU, Holmer Heimann, and Rudner 2016. This notion is corroborated by work showing that it is the reduced language experience sometimes experienced by DHH children rather than auditory deprivation as such that may compromise the development of WM (Marshall et al. Citation2015; Rudner and Holmer Citation2016). Further, studies on word learning in hearing children (e.g. Hoover, Storkel, and Hogan Citation2010) and adults (e.g. Storkel , Ambrüster, and Hogan Citation2006 ) reveal an important role of LTM representations in development. Investigating interactions between WMC and LTM representations in developing ease of language understanding, both during “noisy” and normal conditions, will be an important future task in relation to the general ELU framework.
RAMBPHO and LTM
RAMBPHO processing is also important for the build-up of phonological and semantic representations in LTM. This is in line with an exemplar-based model view of word encoding and learning (e.g. Schmidtke Citation2016), which assumes that every encounter with a word leaves a memory trace which strengthens the connection(s) to the representation of the meaning of the word. Individual vocabulary size is the number of encountered words (including phonological neighbors/variants) encoded in LTM. Speed of access to lower frequency words (Brysbaert et al. Citation2016; Goh et al. Citation2009) is likely to be slower if this account is correct (Caroll et al. Citation2016). According to Schmidtke (Citation2016), because bilinguals are exposed to each of their two languages less often than monolinguals are exposed to their single language, they also encounter each individual word less frequently. This may lead to poorer phonetic representations of all words compared to monolinguals (Schmidtke Citation2016).
If input to the RAMBPHO mechanism is compromised due to hearing impairment, then phonological representations may become more fuzzy. According to the D-ELU model (Holmer, Heimann, and Rudner 2016), a mismatch condition that is not solved by postdictive processes (i.e. the output of RAMBPHO cannot find an exact match to a stored representation) pushes the system towards change, i.e. restructuring of existing or adding novel phonological representations. If hearing impairment is progressive and not compensated for, the change to the system at time n might not help at time n + 1 since the input to RAMBPHO is continuously changing, over time and across context. Phonological exemplars in LTM will morph but might not become fixed as exemplars that can be used for efficient processing, i.e. the summation over many attempted word encoding events during the course of days and months results in less distinct LTM representations (Classon, Rudner, and Rönnberg Citation2013). Fitting of hearing aids might interfere with this process, and help the system to develop useful representations after acclimatisation (Ng and Rönnberg Citation2018). However, it seems to be a matter of 2–5 years rather than the usual recommendations for acclimatisation to hearing aids (Ng and Rönnberg Citation2018). Many assembled fuzzy traces may even obscure the phonemic contrasts that support LTM representation of word meaning. This can be a reason why hearing impairment has such a decisive effect on the match/mismatch function, which reflects the relationship between language understanding and WMC (Füllgrabe and Rosen Citation2016; Rönnberg et al. Citation2016). With less distinct or fuzzy LTM representations, the probability of mismatch during listening in everyday conditions will increase, and with it dependence on WMC. Empirically, additional predictors of ease of language understanding for hearing-impaired participants are the degree of preservation of hearing sensitivity and temporal fine structure (Rönnberg et al. Citation2016). This applies especially when contextual support is low and explicit processing becomes more prominent.
Temporal fine structure information is important for pitch perception and for the ability to perceive speech in the dips of fluctuating background noise (Moore Citation2008; Qin and Oxenham Citation2003). Perceiving speech in fluctuating noise is also being modulated by WMC (e.g. Lunner and Sundewall-Thorén Citation2007; Rönnberg et al. Citation2010; Füllgrabe, Moore, and Stone Citation2015). Thus, one important role of preserved temporal fine structure may according to the ELU model be accomplished by the fast, implicit and predictive processes of WM—from the brainstem (Sörqvist, Stenfelt, and Rönnberg Citation2012) and upwards to the cortical level—where hippocampus serves a binding function in the evolution of auditory scenes as well as for WM (i.e. Yonelinas Citation2013). Recent evidence also suggest that it is possible to dissociate the effects of age and hearing impairment on neural processing of temporal fine structure (Vercammen et al. Citation2018). For a fuller discussion on the topic of WM and temporal fine structure, see Rönnberg et al. (Citation2016, pp. 14–15.)
The multimodality aspect
The talker’s face provides information that is supplementary to the auditory signal. Thus, it is not surprising that it enhances speech perception, especially when the auditory signal is degraded. A set of interesting gating studies by Moradi et al. (Citation2013, 2014a, Citation2014b, Citation2016) supports two major conclusions: (1) that seeing the talker’s face reduces dependence on WMC during perception of gated phonemes and words, and (2) that individuals who perform an audiovisual gating task subsequently show improved auditory speech recognition immediately and after 1 month, an effect not found with audio-only gating. We have named this latter phenomenon, perceptual “doping”(see Moradi et al. in press; Moradi et al., Citation2017).
With respect to the phenomenon, some of the important details were: The participants underwent gated speech identification tasks comprising Swedish consonants and words presented at 65 dB sound pressure level with a 0 dB signal-to-noise ratio, in audiovisual or auditory-only training conditions. A Swedish HINT test was employed to measure the participants’ sentence comprehension in noise before and after training. The results show that audiovisual gating training confers a benefit not seen after auditory only gating training such that auditory HINT performance improved, even at follow-up a month later. The interpretation of this finding is based on a change of the cortical maps/representations. These representations are more accessible (doped or enriched maps) and are maintained after the (gated) audiovisual speech training, which subsequently facilitates auditory route mapping to those phonological and lexical representations in the mental lexicon. It is probably the case that the specific task demands of the gating task reinforces the fine-grained phonological analysis which we know is facilitated by the visual component of speech (Moradi et al. Citation2013). Another way of phrasing this effect is to state that the visual component helps RAMBPHO processing, which also is a reason why the first version of the ELU model (Rönnberg Citation2003) stressed the multimodality aspect of speech and the fact that phonological information comes in different modes in the natural communication situation.
Although seeing the talker’s face generally enhances speech perception in adverse conditions, we showed in a set of studies (Mishra et al. Citation2014) that it does not always enhance higher level processing of speech. Indeed, in two separate studies (Mishra et al. Citation2013a, Citation2013b), we showed that the presence of congruent visual information actually reduced the ability of young adult participants with normal hearing to perform a cognitive spare capacity task (CSCT). In the CSCT, series of spoken digits are presented either audiovisually or in the auditory mode only, and the participant is instructed to retain the two digits that meet certain criteria (e.g. highest value spoken by each of two speakers). This task requires memory (retention of two digits) and executive function (updating in the given example). We reasoned that when the auditory signal is fully intelligible, the visual component provides no additional information to support cognitive processing and instead acts as a distractor. However, for older adults with hearing impairment, seeing the talker’s face did provide a benefit in terms of CSCT performance (where executive functioning rather than maintenance per se is a key, Mishra et al. Citation2014) but not in terms of immediate recall (where it is maintenance per se rather than executive functioning that is the key, Rudner, Mishra et al. Citation2016b). We explained this discrepancy in terms of differences in task demands and their interaction with, on the one hand, different aspects of audiovisual integration and, on the other hand, individual differences in executive skills. Consequently, we propose that the benefit of seeing the talker’s face during speech processing is contingent on the specific cognitive demands of the task as well as the cognitive abilities of the listener and the quality of the signal. It could even be the case that non-linguistic social functions are triggered by the face, which in turn might modulate the executive function processes. Most importantly, there is no straightforward explanation of the role of visual information in ease of language understanding.
Hearing status
One important aspect of the ELU-model and moreover one of the driving forces behind its inception in Rönnberg (Citation2003) is that the probability of mismatches increases with severity of hearing impairment. For normal hearing listeners, it seems less likely that postdictive functions need to be invoked as a function of mismatch. However, depending on the difficulty and context of the speech understanding task, predictive and postdictive functions may still be important for persons with normal hearing. Nonetheless, one potentially important constraint on the ELU model is hearing status.
This constraint has been addressed by Füllgrabe and Rosen (Citation2016) in a meta-analysis of their own and some other correlational studies in the area. In particular, they focussed on the role played by WM and they found for the studies—where data had been shared—that in normal hearing listeners only a few percent of the variance in the speech understanding/recognition criterion is accounted for by WMC. Other independent published data support the ELU prediction that WMC is important for listeners with hearing impairment, especially those who are older (e.g. Füllgrabe and Rosen Citation2016; Rönnberg et al. Citation2016; Smith and Pichora-Fuller Citation2015). This is in keeping with the original intentions, but was (perhaps prematurely) generalised to the case of all participants, as long as adversity was severe enough (Rönnberg et al. Citation2013).
Nevertheless, in a recent article by Gordon-Salant and Cole (Citation2016), convincing evidence has been adduced regarding the importance of WMC—even for participants with age-appropriate hearing—concerning speech perception in noise. Obtained correlations between WMC and speech in noise thresholds (at 50%) are very similar to those obtained in work by e.g. Foo et al. (Citation2007) and Lunner (2003), using hearing-impaired participants. Gordon-Salant and Cole (Citation2016) also subdivided their normal hearing participants into high and low WMC subgroups, holding age constant between the two subgroups for each of two general age groups (older listeners =68 years vs. younger listeners =20 years). Both age and WMC caused main effects for perception of context-free, single word tests in noise, whereas there was an additional and interesting interaction between the two variables for sentence materials (with limited context) in noise (e.g. “The birch canoe slid on the smooth planks”), revealing that high WMC facilitated efficient use of sentence cues more for older than for younger participants (Gordon-Salant and Cole Citation2016).
WMC and context interactions
Although the ELU model has been less specific about the more precise role of context (Wingfield, Amichetti, and Lash Citation2015), the model can account for data patterns (e.g. Gordon-Salant and Cole Citation2016; Rönnberg et al. Citation2013), showing that a noisy speech signal accompanied by semantic cues is easier to resolve for a person with higher WMC. This phenomenon is likely to be especially prominent in older listeners who often have preserved semantic memory despite declining episodic LTM and executive skills (see Gordon-Salant and Fitzgibbons Citation1997; Peelle and Wingfield Citation2016; Sheldon, Pichora-Fuller, and Schneider Citation2008), but it has also been observed for participants with normal hearing (Michalek, Ash, and Schwartz Citation2018; Signoret et al. Citation2018).
Focusing on contextual demands rather on hearing status, we (Rönnberg et al. Citation2016) predicted and found a data pattern analogous to the pattern reported by Gordon-Salant and Cole (Citation2016). Based on the n200 data-base, we (Rönnberg et al. Citation2016) have now documented in exploratory factor analyses—for 200 participants with an average age of 61 and mild to moderate hearing loss—that WMC (with a high loading on a cognition factor, statistically derived from a set of cognitive tests)—is substantially associated with outcome conditions in which context plays a lesser role (i.e. the no context factor constituted by e.g. Hagerman matrix sentences, Hagerman and Kinnefors Citation1995). This replicates earlier studies from our lab (Foo et al. Citation2007; Rudner et al. Citation2011), which suggest a dissociation in the dependence on WMC: no context outcomes depend on WMC, whereas context outcome conditions (e.g. Swedish HINT sentences with naturalistic context, example: “She got shampoo in her eyes”, Hällgren, Larsby, and Arlinger Citation2006) depend less on WMC.
Context presumably helps the listener unload WM, as predictions are facilitated by the context of the sentence. This may at first glance, seem contradictory to the Gordon-Salant and Cole (Citation2016) data, but the similarity lies in the fact that the no context conditions in Rönnberg et al. (Citation2016) were primarily based on the Hagerman matrix sentences (i.e. Hagerman and Kinnefors Citation1995), which consists of stereotypical sentences (e.g. “Ann had five red boxes”). Albeit being different in terms of surface structure, the Hagerman and the Gordon-Salant and Cole sentences share the property of low redundancy, which means there is relatively little help in terms of prediction of sentence content.
Thus, we argue that the results in relation to context or no context in the Gordon-Salant and Cole (Citation2016)/Rönnberg et al. (Citation2016) studies are not necessarily conflicting. It seems mainly to be a matter of labelling of tests (and their contrasting relations to other tests in the respective test batteries) rather than a difference in actual task demands. Generally speaking, both sentence types depend on the internal sentence context (if any), which is why we argue here that the observed correlations replicate each other, across participant populations, keeping the type of outcome test and contextual support constant. Based on this reasoning, a case can be made for a further, seventh ELU–prediction about contextual use by WM.
Further support for this reasoning comes from a recent study by Meister et al. (Citation2016), who used low context matrix sentences (Oldenburg sentence materials, OLSA) to test speech perception in noise in participants with hearing impairment. A post hoc subdivision of participants into high and low WMC shows exactly the predicted pattern indicated above: high WMC participants could compensate for their hearing loss in low context conditions (Meister et al. Citation2016, see also Amichetti, White, and Wingfield Citation2016, for plausibility).
In the Rönnberg et al. (Citation2016) study, the context outcome factor tests that loaded the highest were the Swedish HINT (Hällgren, Larsby, and Arlinger Citation2006) and the Samuelsson and Rönnberg sentences (1993). The HINT sentences are naturalistic sentences and the Samuelsson and Rönnberg sentences have previously been used for lip-reading research. Lip-reading is hard without contextual cues. Participants listened to the sentences in noise with contextual cues selected from common everyday scripts and provided before the actual sentence (e.g. being at a “restaurant”, “Can we pay for our dinner with a credit card?”). For these kinds of speech-in-noise sentences, the Rönnberg et al. (Citation2016) study thus concludes that the correlation with WM is reduced relative to perception of Hagerman matrix sentences (but still significant, even after partialling out for age) because predictability is higher.
Likewise, in the case of auditory gating studies from our laboratory, highly predictive sentences do not necessitate the explicit involvement of WM, i.e. showing a lack of correlation between WMC and the amount of time required for the correct identification of sentence-final words. This result holds true for both hearing-impaired (Moradi et al. Citation2014a) and normal hearing participants (Moradi et al. Citation2014b). However, when it comes to gating of consonants and words, no supportive sentence context is present, and in this case, WMC comes into play for both participant groups. In a very recent study based on the n200 sample, Moradi et al. (Citation2017) replicated the gating results for consonants and vowels, showing significant correlations with WMC in those stimulus conditions. Finally, if we accept the data pattern concerning contextual variability and associated deployment of WMC, the key challenge seems to be how to conceptualise the mechanism of exact interplay between the two, given that e.g. sensitivity and temporal fine structure in part account for aging and hearing impairment effects (e.g. Gordon-Salant and Cole Citation2016; Rönnberg et al. Citation2016).
In summarising the argument for a seventh prediction by the ELU model, we use the original ELU formulation (Rönnberg Citation2003) as one point of departure to generally characterise the conditions under which WMC plays a role. In that theoretical article it was argued that for intermediate levels of phonological precision and lexical access speed (depending on the actual perceptual input or the phonological/lexical abilities of the listener), there is supposedly a larger opportunity for contextual use due to WMC. Thus, with either a precise perceptual and contextual input, or with a very poor input, the modulation by means of WMC was not assumed to be critical: in the former case the perceptual platform is sufficiently stable and precise, and hence, there is no additional explicit processing necessary; in the latter case, the input is too poor to instigate meaningful processing, leaving the cognitive machinery without input.
Concluding discussion
The role of WMC in language understanding under everyday conditions is well-established by data relating to speech processing. Related to expectation six, there was reason to believe that the theoretical arguments would largely apply to sign language. However, few of the predictions set out from the ELU model have thus far been empirically tested for sign language, and the results are not unequivocal. WM has been shown to support both prediction and postdiction during speech understanding, especially for older hearing-impaired participants. In terms of prediction, the storage aspect of complex WM provides maintenance of information (context, cues, or primes) available before the language signal has been sensed. While such information potentially narrows down the form and content of the attended signal, there may still be room for misperception. This can be explained by the notion that RAMBPHO primarily is about phonology, it has developed to deal with phonology, and semantic constraints work only rapidly in terms of pre-existing associations with semantic LTM or by means of semantic implications due to particular RAMBPHO combinations. RAMBPHO processing is implicit and modular, interacts with WM and LTM, but it is not part of either system as such. However, in terms of postdiction, WM provides a mechanism for disambiguation of a suboptimal language signal after sensing. This mechanism relies heavily on inference-making on the basis of context and prior knowledge, and on both the semantic processing and storage aspects of a complex WM function. In everyday life, prediction and postdiction go hand in hand, and the ratio between these implicit and explicit functions varies momentarily during discourse due to the signal quality, sensory ability and the ease with which predictive and postdictive functions can be performed.
Disclosure statement
The authors have no conflicts of interest to declare.
The research was supported by a Linnaeus Centre HEAD excellence centre grant [349-2007-8654] from the Swedish Research Council and by a programme grant from FORTE [2012–1693], awarded to the first author, as well as by a new grant from the Swedish Research Council (2017-06092), awarded to Anders Fridberger.
Additional information
Funding
References
- Akeroyd, M. A. 2008. “Are Individual Differences in Speech Reception Related to Individual Differences in Cognitive Ability? A Survey of Twenty Experimental Studies with Normal and Hearing-impaired Adults.” International Journal of Audiology 47 (Suppl 2): S53–S71. doi:10.1080/14992020802301142.
- Amichetti, N. M., A. G. White, and A. Wingfield. 2016. “Multiple Solutions to the Same Problem: Utilization of Plausibility and Syntax in Sentence Comprehension by Older Adults with Impaired Hearing.” Frontiers in Psychology 7: 789. doi:10.3389/fpsyg.2016.00789
- Anderson, S., T. White-Schwoch, A. Parbery-Clark, and N. Kraus. 2013. “A Dynamic Auditory-cognitive System Supports Speech-in-noise Perception in Older Adults.” Hearing Research 300:18–32. doi:10.1016/j.heares.2013.03.006.
- Andin, J., E. Orfanidou, V. Cardin, E. Holmer, C. M. Capek, B. Woll, J. Rönnberg and M. Rudner. 2013. “Similar Digit-Based Working Memory in Deaf Signers and Hearing Non-signers despite Digit Span Differences.” Frontiers in Psychology 4: 942. doi:10.3389/fpsyg.2013.00942
- Arehart, K. H., P. Souza, R. Baca, and J. M. Kates. 2013. “Working Memory, Age, and Hearing Loss: Susceptibility to Hearing Aid Distortion.” Ear and Hearing 34 (3): 251–260. doi:10.1097/AUD.0b013e318271aa5e.
- Arehart, K., P. Souza, J. Kates, T. Lunner, and M. S. Pedersen. 2015. “Relationship among Signal Fidelity, Hearing Loss, and Working Memory for Digital Noise Suppression.” Ear and Hearing 36 (5): 505–16. doi:10.1097/AUD.0000000000000173.
- Besser, J., T. Koelewijn, A. A. Zekveld, S. E. Kramer, and J. M. Festen. 2013. “How Linguistic Closure and Verbal Working Memory Relate to Speech Recognition in Noise–A Review.” Trends in Amplification 17 (2): 75–93. doi:10.1177/1084713813495459.
- Brysbaert, M., M. Stevens, P. Mandera, and E. Keuleers. 2016. “The Impact of Word Prevalence on Lexical Decision Times: Evidence from the Dutch Lexicon Project 2.” Journal of Experimental Psychology: Human Perception and Performance 42 (3): 441–458. doi:10.1037/xhp0000159.
- Cardin, V., E. Orfanidou, L. Kästner, J. Rönnberg, B. Woll, C. M. Capek, and M. Rudner. 2016. “Monitoring Different Phonological Parameters of Sign Language Engages the Same Cortical Language Network but Distinctive Perceptual Ones.” Journal of Cognitive Neuroscience 28 (1): 20–40. doi:10.1162/jocn_a_00872.
- Cardin, V., E. Orfanidou, J. Rönnberg, C. M. Capek, M. Rudner, and B. Woll. 2013. “Dissociating Cognitive and Sensory Neural Plasticity in Human Superior Temporal Cortex.” Nature Communications 4: 1473. doi:10.1038/ncomms2463.
- Cardin, V., M. Rudner, D. Oliveira, J. Andin, M. Su, L. Beese, B. Woll, J. Rönnberg. 2017. “The Organization of Working Memory Networks Is Shaped by Early Sensory Experience.” Cerebral Cortex 30: 1–15. doi:10.1093/cercor/bhx222.
- Caroll, R., A. Warzybok, B. Kollmeier, and E. Ruigendijk. 2016. “Age-Related Differences in Lexical Access Relate to Speech Recognition in Noise.” Frontiers in Psychology 7: 990. doi:10.3389/fpsyg.2016.00990
- Classon, E., M. Rudner, and J. Rönnberg. 2013. “Working Memory Compensates for Hearing Related Phonological Processing Deficit.” Journal of Communication Disorders 46 (1): 17–29. doi:10.1016/j.jcomdis.2012.10.001.
- Daneman, M., and P. M. Merikle. 1996. “Working Memory and Language Comprehension: A Meta-Analysis.” Psychonomic Bulletin and Review 3 (4): 422–433. doi:10.3758/BF03214546.
- Ding, H., W. Qin, M. Liang, D. Ming, B. Wan, Q. Li, and C. Yu. 2015. “Cross-modal Activation of Auditory Regions during Visuo-Spatial Working Memory in Early Deafness.” Brain 138 (9): 2750–2765. doi:10.1093/brain/awv165.
- Dolležal, L.-V., A. Brechmann, G. M. Klump, and S. Deike. 2014. “Evaluating Auditory Stream Segregation of SAM Tone Sequences by Subjective and Objective Psychoacoustical Tasks, and Brain Activity.” Frontiers in Neuroscience 8: 119. doi:10.3389/fnins. 2014.00119
- Edwards, B. 2016. “A Model of Auditory-Cognitive Processing and Relevance to Clinical Applicability.” Ear and Hearing 37 (Suppl 1): 85S–91S. doi:10.1097/AUD.0000000000000308.
- Foo, C., M. Rudner, J. Rönnberg, and T. Lunner. 2007. “Recognition of Speech in Noise with New Hearing Instrument Compression Release Settings Requires Explicit Cognitive Storage and Processing Capacity.” Journal of the American Academy of Audiology 18: 553–566.
- Füllgrabe, C., and S. Rosen. 2016. “On the (un)importance of Working Memory in Speech-in-noise Processing for Listeners with Normal Hearing Thresholds.” Frontiers in Psychology 7: 1268. doi:10.3389/fpsyg.2016.01268
- Füllgrabe, C., B.C. Moore, and M. A. Stone. 2015. “Age-group Differences in Speech Identification despite Matched Audiometrically Normal Hearing: Contributions from Auditory Temporal Processing and Cognition.” Frontiers in Aging Neuroscience 6: 347. doi:10.3389/fnagi.2014.00347
- Gatehouse, S., G. Naylor, and C. Elberling. 2003. “Benefits from Hearing Aids in Relation to the Interaction between the User and the Environment.” International Journal of Audiology 42 (Suppl 1): S77–S85. doi:10.3109/14992020309074627.
- Gatehouse, S., G. Naylor, and C. Elberling. 2006. “Linear and Nonlinear Hearing Aid Fittings–1: Patterns of Benefit.” International Journal of Audiology 45 (3): 130–152. doi:10.1080/14992020500429518.
- Gennari, S. P., R. Millman, M. Hymers, and S. L. Mattys. 2018. “Anterior Paracingulate and Cingulate Cortex Mediates the Effects of Cognitive Load on Speech Sound Discrimination.” NeuroImage 178: 735–743. doi:10.1016/j.neuroimage.2018.06.035.
- Goh, W. D., S. Lidia, M. J. Yap, and S. Hui Tan. 2009. “Distributional Analyses in Auditory Lexical Decision: Neighborhood Density and Word-frequency Effects.” Psychonomic Bulletin and Review 16 (5): 882–887. doi:10.3758/PBR.16.5.882.
- Good, A., K. A. Gordon, B. C. Papsin, G. Nespoli, T. Hopyan, I. Peretz, and F. A. Russo. 2017. “Benefits of Music Training for Perception of Emotional Speech Prosody in Deaf Children with Cochlear Implants.” Ear and Hearing 38 (4): 455–464. doi:10.1097/AUD.0000000000000402.
- Gordon-Salant, S., and P. J. Fitzgibbons. 1997. “Selected Cognitive Factors and Speech Recognition Performance among Young and Elderly Listeners.” Journal of Speech, Language, and Hearing Research 40 (2):423–431.
- Gordon-Salant, S., and S. S. Cole. 2016. “Effects of Age and Working Memory Capacity on Speech Recognition Performance in Noise among Listeners with Normal Hearing.” Ear and Hearing 37 (5): 593–602. doi:10.1097/AUD.0000000000000316.
- Grady, C. 2012. “The Cognitive Neuroscience of Ageing.” Nature Reviews Neuroscience 13 (7): 491–505. doi:10.1038/nrn3256.
- Habib, R., L. Nyberg, and E. Tulving. 2003. “Hemispheric Asymmetries of Memory: The HERA Model Revisited.” Trends in Cognitive Sciences 7 (6): 241–245. doi:10.1016/S1364-6613(03)00110-4.
- Hadar, B., J. E. Skrzypek, A. Wingfield, and B. M. Ben-David. 2016. “Working Memory Load Affects Processing Time in Spoken Word Recognition: Evidence from Eye-Movements.” Frontiers in Neuroscience 10: 221. doi:10.3389/fnins.2016.00221
- Hagerman, B. 1982. “Sentences for Testing Speech Intelligibility in Noise.” Scandinavian Audiology 11 (2): 79–78. doi:10.3109/01050398209076203.1
- Hagerman, B., and C. Kinnefors. 1995. “Efficient Adaptive Methods for Measuring Speech Reception Threshold in Quiet and in Noise.” International Journal of Audiology 24 (1): 71–77. doi:10.3109/14992029509042213.
- Hannon, B., and M. Daneman. 2001. “A New Tool for Measuring and Understanding Individual Differences in the Component Processes of Reading Comprehension.” Journal of Educational Psychology 93 (1): 103–128. doi:10.1037/0022-0663.93.1.103.
- Heitz, R. P., J. C. Schrock, T. W. Payne, and R. W. Engle. 2008. “Effects of Incentive on Working Memory Capacity: Behavioral and Pupillometric Data.” Psychophysiology 45 (1): 119–129. doi:10.1111/j.1469-8986.2007.00605.x
- Hernvig, L. H., and S. Ø. Olsen. 2005. “Learning Effect When Using the Danish Hagerman Sentences (Dantale II) to Determine Speech Reception Threshold.” International Journal of Audiology 44 (9): 509–512. doi:10.1080/14992020500189997.
- Hewitt, D. 2017. “Age-Related Hearing Loss and Cognitive Decline: You Haven't Heard the Half of It.” Frontiers in Aging Neuroscience 9: 112. doi:https://doi.org/10.3389/fnagi.2017.00112
- Hulme, C., S. Maughan, and G. D. A. Brown. 1991. “Memory for Familiar and Unfamiliar Words: Evidence for a Long-term Memory Contribution to Short-term Memory Span.” Journal of Memory and Language 30 (6): 685–701. doi:10.1016/0749-596X(91)90032-F.
- Holmer, E., M., Heimann, and M. Rudner. 2016. “Imitation, sign Language Skill and the Developmental Ease of Language Understanding (D-ELU) Model.” Frontiers in Psychology 7: 107. doi:10.3389/fpsyg.2016.00107.
- Hunter, C. R., and D. B. Pisoni. 2018. “Extrinsic Cognitive Load Impairs Spoken Word Recognitionin High- and Low-Predictability Sentences.” Ear and Hearing 39 (2): 378–389. doi:10.1097/AUD.0000000000000493.
- Hällgren, M., B. Larsby, and S. Arlinger. 2006. “A Swedish Version of the Hearing in Noise Test (HINT) for Measurement of Speech recognition.” International Journal of Audiology 45 (4): 227–237. doi:10.1080/1499202050042
- Hoover, J. R., H. L. Storkel, and T. P. Hogan (2010). A cross-sectional comparison of the effects of phonotactic probability and neighborhood density on word learning by preschool children. Journal of Memory and Language, 63(1), 100–116. doi:10.1016/j.jml.2010.02.003
- Jayakody, D. M. P., P. L. Friedland, R. H. Eikelboom, R. N. Martins, and H. R. Sohrabi. 2018. “A Novel Study on Association between Untreated Hearing Loss and Cognitive Functions of Older Adults: Baseline Non-verbal Cognitive Assessment Results.” Clinical Otolaryngology 43 (1): 182–191. doi:10.1111/coa.12937.
- Keidser, G., Best, V. Freeston, K. and A. Boyce. 2015. “Cognitive Spare Capacity: evaluation Data and Its Association with Comprehension of Dynamic Conversations.” Frontiers in Psychology 6: 597. doi:https://doi.org/10.3389/fpsyg.2015.00597
- Koelewijn, T., A. A. Zekveld, J. M. Festen, and S. E. Kramer. 2012. “Pupil Dilation Uncovers Extra Listening Effort in the Presence of a Single-talker Masker.” Ear and Hearing 32 (2): 291–300. doi:10.1097/AUD.0b013e3182310019.
- Koelewijn, T., A. A. Zekveld, J. Rönnberg, J. Festen, and S. E. Kramer. 2012. Processing Load Induced by Informational Masking Is Related to Linguistic Abilities.” International Journal of Otolaryngology 2012: 1–11. doi:10.1155/2012/865731.
- Kraus, N., A. Parbery-Clark, D. L. Strait, 2012. “Cognitive Factors Shape Brain Networks for Auditory Skills: spotlight on Auditory Working Memory.” Annals of the New York Academy of Sciences 1252 (1): 100–107. doi:10.1111/j.1749-6632.2012.06463.x.
- Luce, P. A., and D. B. Pisoni. 1998. “Recognizing Spoken Words: The Neighborhood Activation Model.” Ear and Hearing 19 (1): 1–36.
- Lin, F. R., L. Ferrucci, Y. An, J. O. Goh, J. Doshi, E. J. Metter, C. Davatzikos, M. A. Kraut, and S. M. Resnick. 2014. “Association of Hearing Impairment with Brain Volume Changes in Older Adults.” Neuroimage 90: 84–92. doi:10.1016/j.neuroimage.2013.12.059.
- Lin, F. R., E. J. Metter, R. J. O'Brien, S. M. Resnick, A. B. Zonderman, and L. Ferrucci. 2011. “Hearing Loss and Incident Dementia.” Archives of Neurology 68 (2): 214–220. doi:10.1001/archneurol.2010.362
- Lin, G., and S. Carlile. 2015. “Costs of Switching Auditory Spatial Attention in following Conversational Turn-Taking.” Frontiers in Neuroscience 9: 124. doi:10.3389/fnins.2015.00124
- Lunner, T. 2003. “Cognitive Function in Relation to Hearing Aid Use.” International Journal of Audiology 42 (Suppl 1): 49–58. doi:10.3109/14992020309074624.
- Lunner, T., and E. Sundewall-Thorén. 2007. “Interactions between Cognition, compression, and Listening Conditions: effects on Speech-in-noise Performance in a 2-channel Hearing Aid.” Journal of the American Academy of Audiology 18 (7): 604–617. doi:10.3766/jaaa.18.7.7.
- Lunner, T., M. Rudner, and J. Rönnberg. 2009. “Cognition and Hearing Aids.” Scandinavian Journal of Psychology 50 (5): 395–403. doi:10.1111/j.1467-9450.2009.00742.x.
- Mann, W., C. R. Marshall, K. Mason, and G. Morgan. 2010. “The Acquisition of Sign Language: The Impact of Phonetic Complexity on Phonology.” Language Learning and Development 6 (1): 60–86. doi:10.1080/15475440903245951.
- Marslen-Wilson, W. D., and L. K. Tyler. 1980. “The Temporal Structure of Spoken Language Understanding.” Cognition 8 (1): 1–71. doi:10.1016/0010-0277(80)90015-3.
- Marsh, J. E., and T. A. Campbell. 2016. “Processing Complex Sounds Passing through the Rostral Brain Stem: The New Early Filter Model.” Frontiers in Neuroscience 10: 136. doi:10.3.89/fnins.2016.00136
- Marshall, C., A. Jones, T. Denmark, K. Mason, J. Atkinson, and N. Botting. 2015. “Deaf Children's Non-verbal Working Memory Is Impacted by Their Language Experience.” Frontiers in Psychology 6: 527. doi:10.3389/fpsyg.2015.00527
- Mattys, S. L., M. H. Davis, A. R. Bradlow, and S. Scott. 2012. “Speech Recognition in Adverse Conditions: A Review.” Language and Cognitive Processes 27 (7–8): 953–978. doi:10.1080/01690965.2012.705006.
- McGarrigle, R., K. J. Munro, P. Dawes, A. J. Stewart, D. R. Moore, J. G. Barry, and S. Amitay. 2014. “Listening Effort and Fatigue: What Exactly Are we Measuring? A British Society of Audiology Cognition in Hearing Special Interest Group ‘white Paper’.” International Journal of Audiology 53 (7): 433–440. doi:10.3109/14992027.2014.890296.
- McMahon, C. M., I. Boisvert, D P. Lissa, L. Granger, R. Ibrahim, and C. Y. Lo. 2016. “Monitoring Alpha Oscillations and Pupil Dilation across a Performance-intensity Function.” Frontiers in Psychology 7: 745. doi:10.3389/fpsyg.2016.00745
- Meister, H., S. Schreitmüller, M. Ortmann, S. Rählmann, and M. Walger. 2016. “Effects of Hearing Loss and Cognitive Load on Speech Recognition with Competing Talkers.” Frontiers in Psychology 7: 301. doi:10.3389/fpsyg.2016.00301
- Michalek, A. M. P., I. Ash, and K. Schwartz. 2018. “The Independence of Working Memory Capacity and Audiovisual Cues When Listening in Noise.” Scandinavian Journal of Psychology 59 (6): 578–585. doi:10.1111/sjop.12480
- Mishra, S., T. Lunner, S. Stenfelt, J. Rönnberg, and M. Rudner. 2013a. “Seeing the Talker’s Face Supports Executive Processing of Speech in Steady State Noise.” Frontiers in Systems Neuroscience 7: 96. doi:10.3389/fnsys.2013.000961
- Mishra, S., T. Lunner, S. Stenfelt, J. Rönnberg, and M. Rudner. 2013b. “Visual Information Can Hinder Working Memory Processing of speech.” Journal of Speech, Language, and Hearing Research 56 (4): 1120–1132. doi:10.1044/1092-4388(2012/12-0033
- Mishra, S., S. Stenfelt, T. Lunner, J. Rönnberg, and M. Rudner. 2014. “Cognitive Spare Capacity in Older Adults with Hearing Loss.” Frontiers in Aging Neuroscience 6: 96. doi:10.3389/fnagi.2014.00096
- Moradi, S., B. Lidesam, H. Ng. Danielsson, and J. Rönnberg. 2017. Visual cues contribute differentially in audiovisual perception of consonants and vowels in improving recognition and reducing cognitive demands. Journal of Speech, Language, and Hearing Research, 60, 2687–2703. doi:10.1044/2016_JSLHR-H-16-0160.
- Molloy, K., T. D. Griffiths, M. Chait, and N. Lavie. 2015. “Inattentional Deafness: Visual Load Leads to Time-specific Suppression of Auditory Evoked Responses.” Journal of Neuroscience 35 (49): 16046–16054. doi:10.1523/JNEUROSCI.2931-15.2015.
- Moore, B. C. J. 2008. “The Role of Temporal Fine Structure Processing in Pitch Perception, masking, and Speech Perception for Normal-hearing and Hearing-impaired People.” Journal of the Association for Research in Otolaryngology 9 (4): 399–406. doi:10.1007/s10162-008-0143-x.
- Moradi, S., B. Lidestam, H. Danielsson, E. H. N. Ng, and J. Rönnberg. (in press). Audiovisual perceptual doping: A multisensory facilitation effect on auditory speech perception, from phonetic feature extraction to sentence identification in noise in aided hearing-impaired listeners. Ear & Hearing.
- Moradi, S., B. Lidestam, and J. Rönnberg. 2013. “Gated Audiovisual Speech Identification in Silence vs. noise: effects on Time and Accuracy.” Frontiers in Psychology 4: 359. doi:10.3389/fpsyg.2013.00359
- Moradi, S., B. Lidestam, and J. Rönnberg, 2016. “Comparison of Gated Audiovisual Speech Identification in Elderly Hearing Aid Users and Elderly Normal-hearing Individuals: Effects of Adding Visual Cues to Auditory Speech Stimuli.” Trends in Hearing 20: 1–15. doi:10.1177/2331216516653355
- Moradi, S., B. Lidestam, A. Saremi, and J. Rönnberg. 2014a. “Gated Auditory Speech Perception: effects of Listening Conditions and Cognitive Capacity.” Frontiers in Psychology 5: 532. doi:10.3389/fpsyg.2014.00531
- Moradi, S., B. Lidestam, M. Hällgren, and J. Rönnberg. 2014b. “Gated Auditory Speech Perception in Elderly Hearing Aid Users and Elderly Normal Hearing Individuals: Effects of Hearing Impairment and Cognitive Capacity.” Trends Hearing 18. doi:10.1177/2331216514545406
- Moradi, S., A. Whalin, M. Hällgren, J. Rönnberg, and B. Lidestam. 2017. The efficacy of a short-term audiovisual training on speech-in-noise identification in elderly hearing-aid users. Frontiers in Psychology: Auditory Cognitive Neuroscience, 8: 368, doi:10.3389/fpsyg.2017.00368.
- Ng, E. H. N., E. Classon, B. Larsby, S. Arlinger, T. Lunner, M. Rudner., et al. 2014. “Dynamic Relation between Working Memory Capacity and Speech Recognition in Noise during the First Six Months of Hearing Aid Use.” Trends in Hearing 18. doi:10.1177/2331216514558688
- Ng, E. H. N., M. Rudner, T. Lunner, M. S. Pedersen, and J. Rönnberg. 2013. “Effects of Noise and Working Memory Capacity on Memory Processing of Speech for Hearing-aid Users.” International Journal of Audiology 52 (7): 433–441. doi:10.3109/14992027.2013.776181.
- Ng, E. H. N., M. Rudner, T. Lunner, and J. Rönnberg. 2015. “Noise Reduction Improves Memory for Target Language Speech in Competing Native but Not Foreign Language Speech.” Ear and Hearing 36 (1): 82–91. doi:10.1097/AUD.0000000000000080.
- Ng, E. H. N., and J. Rönnberg. 2018. “Hearing Aid Experience and Background Noise Affect the Robust Relationship Between Working Memory and Speech Reception in Noise.” Paper presented at IHCON, Lake Tahoe, USA.
- Nyberg, L., M. Lövdén, K. Riklund, U. Lindenberger, and L. Bäckman. 2012. “Memory Aging and Brain Maintenance.” Trends in Cognitive Sciences 16 (5): 292–305. doi:10.1016/j.tics.2012.04.005.
- Obleser, J., M. Wöstmann, N. Hellbernd, A. Wilsch, and B. Maess. 2012. “Adverse Listening Conditions and Memory Load Drive a Common α oscillatory Network.” Journal of Neuroscience 32 (36): 12376–12383. doi:10.1523/JNEUROSCI.4908-11.2012 .
- Ohlenforst, B., A. A. Zekveld, T. Lunner, D. Wendt, G. Naylor, Y. Wang, N. J. Versfeld., et al. 2017. “Impact of Stimulus-related Factors and Hearing Impairment on Listening Effort as Indicated by Pupil Dilation.” Hearing Research 351: 68–79. doi:10.1016/j.heares.2017.05.012.
- Peelle, J. E., and A. Wingfield. 2016. “The Neural Consequences of Age-related Hearing Loss.” Trends in Neuroscience 39 (7): 486–497. doi:10.1016/j.tins.2016.05.001.
- Petersen, E. B., M. Wöstmann, J. Obleser, S. Stenfelt, and T. Lunner. 2015. “Hearing Loss Impacts Neural Alpha Oscillations under Adverse Listening Conditions.” Frontiers in Psychology 6: 177. doi:10.3389/fpsyg.2015.00177
- Pichora-Fuller, M. K., S. E. Kramer, M. A. Eckert, B. Edwards, B. W. Y. Hornsby, L. E. Humes, U. Lemke., et al. 2016. “Hearing Impairment and Cognitive Energy: The Framework for Understanding Effortful Listening (FUEL).” Ear and Hearing 37 (Suppl 1): 5S–27S. doi:10.1097/AUD.0000000000000312.
- Poeppel, D., W. J. Idsardi, and V. van Wassenhove. 2008. “Speech Perception at the Interface of Neurobiology and Linguistics.” Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences 363 (1493): 1071–1086. doi:10.1098/rstb.2007.2160.
- Qin, M. K., and A. J. Oxenham. 2003. “Effects of Simulated Cochlear-implant Processing on Speech Reception in Fluctuating Maskers.” Journal of the Acoustical Society of America 114 (1): 446–454. doi:10.1121/1.1579009.
- Reuter-Lorenz, P. A., and K. A. Cappell. 2008. “Neurocognitive Aging and the Compensation Hypothesis.” Current Directions in Psychological Science 17 (3): 177–182. doi:10.1111/j.1467-8721.2008.00570.x.
- Rönnberg, J. 2003. “Cognition in the Hearing Impaired and Deaf as a Bridge between Signal and Dialogue: A Framework and a Model.” International Journal of Audiology 42 (Suppl 1): S68–S76. doi:10.3109/14992020309074626.
- Rönnberg, J., H. Danielsson, M. Rudner, S. Arlinger, O. Sternäng, Å. Wahlin, and L-G. Nilsson (2011). Hearing loss is negatively related to episodic and semantic long-term memory but not to short-term memory. Journal of Speech, Language, and Hearing Research, 54, 705–726. doi:10.1044/1092-4388(2010/09-0088.
- Rönnberg, J., S. Hygge, G. Keidser, and M. Rudner. 2014. “The Effect of Functional Hearing Loss and Age on Long- and Short-Term Visuospatial Memory: Evidence from the UK Biobank Resource.” Frontiers in Aging Neuroscience 6: 326. doi:10.3389/fnagi.2014.00326
- Rönnberg, J., T. Lunner, A. A. Zekveld, P. Sörqvist, H. Danielsson, B. Lyxell., et al. 2013. “The Ease of Language Understanding (ELU) Model: Theoretical, Empirical, and Clinical Advances.” Frontiers in Systems Neuroscience 7: 31. doi:10.3389/fnsys.2013.00031.
- Rönnberg, J., M. Rudner, and M. Ingvar. 2004. “Neural Correlates of Working Memory for Sign Language.” Cognitive Brain Research 20 (2): 165–182. doi:10.1016/j.cogbrainres.2004.03.002.
- Rönnberg, J., M. Rudner, and T. Lunner. 2014. “Commentary on McGarrigle et al. Listening Effort and Fatigue: What Exactly Are we Measuring? A British Society of Audiology Cognition in Hearing Special Interest Group ‘white Paper.” International Journal of Audiology 53 (7): 441–442.
- Rönnberg, J., M. Rudner, C. Foo, and T. Lunner. 2008. “Cognition Counts: A Working Memory System for Ease of Language Understanding (ELU).” International Journal of Audiology 47 (Suppl 2): S99–S105. doi:10.1080/14992020802301167.
- Rönnberg, J., M. Rudner, T. Lunner, and A. A. Zekveld. 2010. “When Cognition Kicks in: Working Memory and Speech Understanding in Noise.” Noise and Health 12 (49): 263–269.
- Rönnberg, J., T. Lunner, E. H. N. Ng, B. Lidestam, A. A. Zekveld, P. Sörqvist, B. Lyxell., et al. 2016. “Hearing Impairment, cognition and Speech Understanding: Exploratory Factor Analyses of a Comprehensive Test Battery for a Group of Hearing Aid Users, the n200 Study.” International Journal of Audiology 55 (11): 623–642. doi:10.1080/14992027.2016.1219775.
- Rudner, M. 2016. “Cognitive Spare Capacity as an Index of Listening Effort.” Ear and Hearing 37: 69S–76S. doi:10.1097/AUD.0000000000000302.
- Rudner, M. 2018. “Working Memory for Linguistic and Non-linguistic Manual Gestures: Evidence, Theory, and Application.” Frontiers in Psychology 9:679. doi:10.3389/fpsyg.2018.00679
- Rudner, M., J. Andin, and J. Rönnberg. 2009. “Working Memory, deafness and Sign Language.” Scandinavian Journal of Psychology 50 (5): 495–505. doi:10.1111/j.1467-9450.2009.00744.x.
- Rudner, M., C. Foo, J. Rönnberg, and T. Lunner. 2009. “Cognition and Aided Speech Recognition in Noise: specific Role for Cognitive Factors following Nine-week Experience with Adjusted Compression Settings in Hearing Aids.” Scandinavian Journal of Psychology 50 (5): 405–418. doi:10.1111/j.1467-9450.2009.00745.x.
- Rudner, M., C. Foo, E. Sundewall Thorén, T. Lunner, and J. Rönnberg. 2008. “Phonological Mismatch and Explicit Cognitive Processing in a Sample of 102 Hearing Aid Users.” International Journal of Audiology 47 (Suppl. 2): S163–S170.
- Rudner, M., and E. Holmer. 2016. “Working Memory in Deaf Children Is Explained by the Developmental Ease of Language Understanding (D-ELU) Model.” Frontiers in Psychology 7: 1047. doi:10.3389/fpsyg.2016.01047
- Rudner, M., M. Jönsson, S. Szadlo, and E. Holmer. 2016. “Hearing is Believing: Semantic Illusions in the Auditory Modality.” Paper presented at the 2nd Workshop on Psycholinguistic Approaches to Speech Recognition in Adverse Conditions, Nijmegen, The Netherlands, October 31, 2016–November 1, 2016.
- Rudner, M., S. Mishra, S. Stenfelt, T. Lunner, and J. Rönnberg. 2016. “Seeing the Talker’s Face Improves Free Recall of Speech for Young Adults with Normal Hearing but Not Older Adults with Hearing Loss.” Journal of Speech Language and Hearing Research 59 (3): 590–599. doi:10.1044/2015_JSLHR-H-15-0014.
- Rudner, M., E. Orfanidou, V. Cardin, C. M. Capek, B. Woll, and J. Rönnberg. 2016. “Pre-existing Semantic Representation Improves Working Memory Performance in the Visuospatial Domain.” Memory and Cognition 44 (4): 608–620. doi:10.3758/s13421-016-0585-z.
- Rudner, M., P. Fransson, M. Ingvar, L. Nyberg, and J. Rönnberg (2007). Neural representation of binding lexical signs and words in the episodic buffer of working memory. Neuropsychologia, 45(10), 2258–2276. doi:10.1016/j.neuropsychologia.2007.02.017.
- Rudner, M., and J. Rönnberg. 2008. “The Role of the Episodic Buffer in Working Memory for Language Processing.” Cognitive Processing 9 (1): 19–28. doi:10.1007/s10339-007-0183-x.
- Rudner, M., J. Rönnberg, and T. Lunner. 2011. “Working Memory Supports Listening in Noise for Persons with Hearing Impairment.” Journal of the American Academy of Audiology 22 (3): 156–167. doi:10.3766/jaaa.22.3.4.
- Rudner, M., T. Lunner, T. Behrens, E. Sundewall-Thorén, and J. Rönnberg. 2012. “Working Memory Capacity May Influence Perceived Effort during Aided Speech Recognition in Noise.” Journal of the American Academy of Audiology 23 (8): 577–589. doi:10.3766/jaaa.23.7.7.
- Rudner, M., M. Seeto, G. Keidser, B. Johnson, and J. Rönnberg. 2018. “Poorer Speech Reception Threshold in Noise is Associated with Reduced Brain Volume in Auditory and Cognitive Processing Regions.”
- Rudner, M., E. Toscano, and E. Holmer (2015). Load and distinctness interact in working memory for lexical manual gestures. Frontiers in Psychology 6:1147. doi:10.3389/fpsyg.2015.01147.
- Rudner M., E. Orfanidou, V. Cardin, C. M., Capek, B. Woll, and J. Rönnberg 2016. Preexisting semantic representation improves working memory performance in the visuospatial domain. Memory & Cognition, 44 (4): 608–620. doi:10.3758/s13421-016-0585-z.
- Samuelsson, S., and J. Rönnberg. 1993. “Implicit and Explicit Use of Scripted Constraints in Lipreading.” European Journal of Cognitive Psychology 5 (2): 201–233. doi:10.1080/09541449308520116.
- Schmidtke, J. 2016. “The Bilingual Disadvantage in Speech Understanding in Noise Is Likely a Frequency Effect Related to Reduced Language Exposure.” Frontiers in Psychology 7: 678. doi:10.3389/fpsyg.2016.00678
- Sheldon, S., M. K. Pichora-Fuller, and B. A. Schneider. 2008. “Priming and Sentence Context Support Listening to Noise-vocoded Speech by Younger and Older Adults.” Journal of the Acoustical Society of America 123 (1): 489. doi:10.1121/1.2783762
- Signoret, C., I. Johnsrude, E. Classon, and M. Rudner. 2018. “Combined Effects of Form- and Meaning-based Predictability on Perceived Clarity of Speech.” Journal of Experimental Psychology: Human Perception and Performance 44 (2): 277–285. doi:10.1037/xhp0000442.
- Signoret, C., and M. Rudner. 2016. “The Interplay of Phonological and Semantic Knowledge during Perception of Degraded Speech.” Paper presented at the WCA2016: 33rd World Congress of Audiology 2016, September 18–21, Vancouver, Canada.
- Signoret, C., and M. Rudner. 2018. “Hearing impairment and perceived clarity of predictable speech.” Ear & Hearing. doi:10.1097/AUD.0000000000000689
- Smith, S. L., and M. K. Pichora-Fuller. 2015. “Associations between Speech Understanding and Auditory and Visual Tests of Verbal Working Memory: Effects of Linguistic Complexity, task, age, and Hearing Loss.” Frontiers in Psychology 6: 1394. doi:10.3389/fpsyg.2015.01394
- Souza, P., and K. H. Arehart. 2015. “Robust Relationship between Reading Span and Speech Recognition in Noise.” International Journal of Audiology 54 (10): 705–713. doi:10.3109/14992027.2015.1043062.
- Souza, P., K. H. Arehart, J. Shen, M. Anderson, and J. M. Kates. 2015. “Working Memory and Intelligibility of Hearing-aid Processed Speech.” Frontiers in Psychology 6: 526. doi:10.3389/fpsyg.2015.00526
- Souza, P., and L. Sirow. 2014. “Relating Working Memory to Compression Parameters in Clinically Fit Hearing Aids.” American Journal of Audiology 23 (4): 394–401. doi:10.1044/2014_AJA-14-0006.
- Sörqvist, P., S. Stenfelt, and J. Rönnberg. 2012. “Working Memory Capacity and Visual-verbal Cognitive Load Modulate Auditory-sensory Gating in the Brainstem: Toward a Unified View of Attention.” Journal of Cognitive Neuroscience 24 (11): 2147–2154. doi:10.1162/jocn_a_00275.
- Sörqvist, P., and J. Rönnberg. 2012. “Episodic Long-term Memory of Spoken Discourse Masked by Speech: What is the Role for Working Memory Capacity?” Journal of Speech, Language, and Hearing Research 55 (1): 210–218. doi:10.1044/1092-4388(2011/10-0353)
- Sörqvist, P., Ö. Dahlström, T. Karlsson, and J. Rönnberg. 2016. “Concentration: The Neural Underpinnings of How Cognitive Load Shields against Distraction.” Frontiers in Human Neuroscience 10: 221. doi:10.3389/fnhum.2016.0022
- Stenfelt, S., and J. Rönnberg. 2009. “The Signal-cognition Interface: interactions between Degraded Auditory Signals and Cognitive Processes.” Scandinavian Journal of Psychology 50 (5): 385–393. doi:10.1111/j.1467-9450.2009.00748.x.
- Storkel, H. L., J. Armbrüster, and T. P. Hogan (2006). Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech, Language, and Hearing Research, 49, 1175–1192. doi:10.1044/1092-4388(2006/085).
- Strait, D. L., and N. Kraus. 2014. “Biological Impact of Auditory Expertise across the Life Span: musicians as a Model of Auditory Learning.” Hearing Research 308: 109–121. doi:10.1016/j.heares.2013.08.004.
- Vargha-Khadem, F., D. G. Gadian, K. E. Watkins, A. Connely, W. Van Paesschen, and M. Mishkin. 1997. “Differential Effects of Early Hippocampal Pathology on Episodic and Semantic Memory.” Science 277 (5324): 376–380. doi:10.1126/science.277.5324.376.
- Wagener, K. C., T. Brand, and B. Kollmeier. 1999. “Entwicklung Und Evaluation Eines Satztests Für Die Deutsche Sprache Teil III: Evaluation Des Oldenburger Satztests.” Zeitschrift für Audiologie 38 (3): 86–95.
- Vercammen, C., Goossens, T. Undurraga, J. A. Wieringen. V, A. and. 2018. “Electrophysiological and Behavioral Evidence of Reduced Binaural Temporal Processing in the Aging and Hearing Impaired Human Auditory System.” Trends in Hearing 22 (3): 1–12. doi:10.1177/2331216518785733
- Wild, C. J., A. Yusuf, E. Wilson, J. P. Peelle, M. H. Davis, and I. S. Johnsrude. 2012. “Effortful Listening: The Processing of Degraded Speech Depends Critically on Attention.” Journal of Neuroscience 32 (40): 14010–14021. doi:10.1523/JNEUROSCI.1528-12.2012.
- Wilson, R. H., R. McArdle, K. L. Watts, and S. L. Smith. 2012. “The Revised Speech Perception in Noise Test (R-SPIN) in a Multiple Signal-to-noise Ratio Paradigm.” Journal of the American Academy of Audiology 23 (8): 590–605. doi:10.3766/jaaa.23.7.9.
- Wingfield, A., N. M. Amichetti, and A. Lash. 2015. “Cognitive Aging and Hearing Acuity: modeling Spoken Language Comprehension.” Frontiers in Psychology 6: 684. doi:10.3389/fpsyg.2015.006841
- Yonelinas, A. P. 2013. “The Hippocampus Supports High-resolution Binding in the Service of Perception, Working Memory and Long-Term Memory.” Behavioural Brain Research 254: 34–44. doi:10.1016/j.bbr.2013.05.030.
- Yumba, W. 2017. “Cognitive Processing Speed, Working Memory, and the Intelligibility of Hearing Aid-Processed Speech in Persons with Hearing Impairment.” Frontiers in Psychology 8: 1308. doi:10.3389/fpsyg.2017.01308
- Zekveld, A. A., S. E. Kramer, and J. M. Festen. 2011. “Cognitive Load during Speech Perception in Noise: The Influence of Age, hearing Loss, and Cognition on the Pupil Response.” Ear and Hearing 32 (4): 498–510. doi:10.1097/AUD.0b013e31820512bb.
- Zekveld, A. A., S. E. Kramer, J. Rönnberg, and M. Rudner. 2018. “In a Concurrent Memory and Auditory Perception Task, the Pupil Dilation Response Is More Sensitive to Memory Load than to Auditory Stimulus Characteristics.” Ear and Hearing. doi:10.1097/AUD.0000000000000612.
- Zekveld, A. A., M. Rudner, I. S. Johnsrude, J. M. Festen, J. H. M. van Beek, and J. Rönnberg. 2011. “The Influence of Semantically Related and Unrelated Text Cues on the Intelligibility of Sentences in Noise.” Ear and Hearing 32 (6): e16–e25. doi:0196/0202/11/3206-00e16/0
- Zekveld, A. A., M. Rudner, I. S. Johnsrude, D. Heslenfeld, and J. Rönnberg. 2012. “Behavioural and fMRI Evidence That Cognitive Ability Modulates the Effect of Semantic Context on Speech Intelligibility.” Brain and Language 122 (2): 103–113. doi:10.1016/j.bandl.2012.05.006.
- Zekveld, A. A., M. Rudner, I. Johnsrude, and J. Rönnberg. 2013. “The Effects of Working Memory Capacity and Semantic Cues on the Intelligibility of Speech in Noise.” Journal of the Acoustical Society of America 134 (3):2225–2234. doi:10.1121/1.4817926