Abstract
Background: Evaluation of faculty teaching is critical to improving the educational experience for both students and faculty.
Aim: Our objectives were to implement an evaluation system, using the teaching encounter card, across multiple rotations in the clerkship and determine the feasibility, reliability and validity of this evaluation tool in this expanded setting.
Methods: Students were asked to rate clinical supervisors on nine teaching behaviours using a 6-point rating scale and asked whether they would like to nominate the teacher for a clinical teaching award.
Results: A total of 3971 cards for 587 clinical supervisors across seven clerkship rotations were analyzed. There was an average of 7.3 cards per supervisor (median = 5, range 2–66). There was high internal consistency between items on the card (Cronbach's alpha 0.965). The reliability was fair at 0.63. Seventeen cards per supervisor would be required to achieve a reliability >0.8 (G study). Ratings were higher for encounters that occurred in the operating room and within the anaesthesia rotation. The teachers who had a positive recommendation for teaching award nomination received higher scores than their colleagues.
Conclusion: We successfully implemented a faculty evaluation card across clerkship rotations that was flexible enough to use in multiple learning environments and allowed the identification of outstanding clinical teachers.
Introduction
Quality clinical teaching by enthusiastic and committed faculty is of utmost importance in a medical programme. Evaluation of faculty teaching is critical to improving the educational experience for students and faculty. Evaluation of teaching effectiveness facilitates recognition for excellence in teaching, application for academic promotion, allocation of teaching responsibilities and identification of common weakness to focus on through faculty development programmes (Williams et al. Citation2002). At some universities, results may even translate to financial rewards (Williams et al. Citation2002). Feedback is highly valued by faculty and is identified by community-based faculty as the most important recognition of their commitment and service (Dent et al. Citation2004). Despite the importance of faculty evaluation, it is often difficult to collect and compare across teaching services.
There are many challenges in providing timely, effective faculty evaluation. It is important to balance receiving enough information about specific teaching behaviours to facilitate change without being too lengthy and impacting completion rates. Encounter cards are inexpensive, portable tools that offer the advantage of timely completion following a defined time/event that an evaluation is based on. They provide opportunity to have multiple evaluations within a rotation. Although used in trainee evaluation, they have not been well studied for faculty evaluation (Brennan & Norman Citation1997; Kernan et al. Citation2004; Richards et al. Citation2007). Faculty evaluation has been investigated by others using various methods and tools that vary in length from 54 items to a single global rating scale (Irby et al. Citation1987; Ramsey & Gillmore Citation1988; Ramsbottom-Lucier et al. Citation1994; Litzelman et al. Citation1998a; Copeland & Norman Citation2000; Steiner et al. Citation2000; Williams et al. Citation2002; Kernan et al. Citation2004; Smith et al. Citation2004; Zuberi et al. Citation2007). Timely completion is essential for accuracy, especially for short exposures to faculty. Typically evaluations are completed at the end of clinical rotations, but timing may vary from immediately after a specific patient encounter (Kernan et al. Citation2004), to the end of the academic year (Williams et al. Citation2002). Clinical rotations have inherent differences in the learning setting (e.g. outpatient clinics, operating rooms and inpatient units), number and degree of exposure to faculty, and complexity of patient problems. The majority of studies have considered specific learning settings (e.g. inpatient or ambulatory care) or rotations (e.g. obstetrics, emergency medicine and internal medicine), with few studies examining evaluation across disciplines (Copeland & Hewson Citation2000; Zuberi et al. Citation2007).
Our goal was to standardize faculty evaluation across all clerkship rotations using a practical instrument flexible enough to meet the challenges of faculty evaluation including inherent differences between varied learning environments, unpredictable and varied patient encounters, different length of rotations, and varying number of supervisors encountered. This study expanded the use of a teaching encounter card that was previously piloted in the Department of Obstetrics and Gynaecology (Oppenheimer et al. Citation2006).
Our objectives were to implement an evaluation system, using the teaching encounter card, across multiple rotations in the clerkship and determine the feasibility, reliability and validity of this evaluation tool in this expanded setting.
Methods
Setting
The University of Ottawa Medical School, with 112 anglophone students per year, begins a 48-week clinical clerkship in the third-year of a 4-year programme, using tertiary care and community clinical settings. The core clinical rotations include ambulatory care, anaesthesia, general internal medicine (inpatient units), obstetrics and gynaecology, paediatrics, psychiatry and general surgery. Clinical supervisors include university faculty, community preceptors and residents/fellows.
Instrument refinement
The items of the original faculty evaluation card were generated from review of the literature on ideal clinical teaching, review of other tools including those used in our Emergency Medicine Department and others available in the literature (Irby Citation1986; Irby et al. Citation1987). The original rating scale included 10 key aspects of teaching, rated on a 4-point rating scale anchored by the extent to which the student agreed that the particular teaching behaviour had been provided, and a global item on the value of the educational experience. For construct validation purposes, students were asked whether they would like to recommend this teacher for a clinical teaching award (yes/no).
This faculty evaluation card was pilot-tested on the obstetrics and gynaecology clerkship rotation from March to September 2004 to assess its performance and feasibility (Oppenheimer et al. Citation2006). Our pilot project confirmed the acceptability and the face and content validity of the encounter card (Oppenheimer et al. Citation2006). Despite the encouraging results from the pilot, changes were made to reduce redundancy and to increase the distinction between very good and outstanding teachers (the right-hand side of the scale was expanded from 4 points to 6 points). Other information were added; about the clinical rotation, campus/location of teaching encounter, the learning setting and length of teaching exposure were added. The revised card used is displayed in . Students were not asked to identify themselves to ensure student anonymity. Although this limits the analysis that can be done, student candour is increased if the student cannot be identified (Willet et al. Citation2007).
Figure 1. Teaching encounter card.
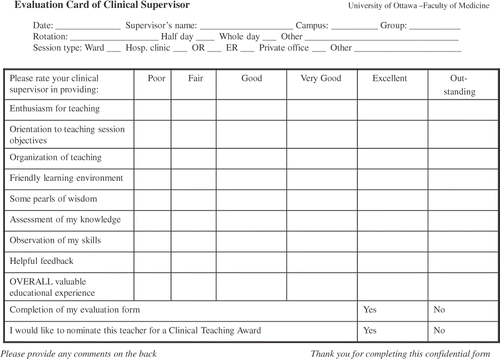
Implementation
From 1 December 2004 to 17 January 2007, all students rotating through clerkship rotations, except for emergency and family medicine (due to unique evaluation already in place) were asked to complete a card on their clinical supervisor at the end of the teaching encounter. Participation was voluntary and anonymous. The cards were deposited in a drop box or given to the administrative rotation coordinator.
Statistical analysis
Before analysis, all evaluation cards were reviewed for completeness of data and for clear identification of the clinical supervisor being evaluated. Incomplete cards were removed from the analysis. In addition, to ensure a balanced design with complete data on all items, only cards with all the rating items completed were included in the analysis. Following these steps, any faculty with less than two evaluation cards were excluded from the analysis.
To study the performance of individual items on the card, descriptive statistics for each item were calculated, as well as item-total correlations. Ratings as a function of learning environment and clerkship rotation were analyzed using analysis of variance (ANOVA). To assess the reliability of reported ratings, two types of reliability coefficients were calculated: internal consistency of items across the instrument was assessed using Cronbach's alpha and a generalizability coefficient was used to assess the reliability of the scale as a whole. For the generalizability analysis, each card was considered as the unit of measurement and was nested within supervisor. Supervisor was treated as a between subject factor and was crossed with items.
Composite scores were analyzed using two factors between subject ANOVA to determine if mean ratings differed depending on whether the students thought their supervisor should be nominated for a teaching award. For construct validation purposes, differences in ratings were compared depending on whether the faculty person was recommended for nomination of a teaching award or not recommended. If the cards are functioning as intended, then it is expected that ratings should be higher for those faculty who are recommended for a nomination than for those who are not.
The analyses including the descriptive statistics and correlations were completed using SPSS 15.0 and G-string (Bloch & Norman Citation2006) with UrGenova (Brennan Citation2001) was used for the generalizability analysis.
Results
We collected a total of 5408 cards. 573 cards were rejected because of failure to clearly identify the faculty person being evaluated. Another 831 cards were flagged for incomplete data on the rating scale items. After removing these cards, a further 33 supervisors were revealed to have only one rating and cards from these supervisors were removed. This left a total of 3971 cards available for 587 clinical supervisors. There was an average of 6.8 cards per supervisor (median = 5, range = 2 to 66 cards per supervisor).
describes the mean scores for each item. For all items, the full spectrum of responses from one to six was used, indicating that students were willing to provide low ratings to some supervisors. The items which were ranked the lowest included orientation to the teaching session, organization of teaching, assessment of knowledge and observation of skills.
Table 1. Scores on individual items
The internal consistency of the items was relatively high at 0.97 suggesting that scores on some of the items may be redundant. This observation is supported by the high item-total correlations of the items displayed in . From the generalizability analysis, the facet accounting for the largest proportion of variance is the rater nested with supervisor facet (r:s) indicating that the ratings for the supervisors varied a great deal between students (64% of the variance). The g-coefficient for the instrument, generalizing over the nine items and with mean of 7.3 cards per supervisor was 0.64. To achieve a g-coefficient of 0.80, which would be required for high stakes decisions, 17 cards/supervisor would be required. Forty-eight of our 587 supervisors had more than 17 cards completed.
To determine if there were differences across learning environments and rotations, a composite total score was created by determining the average of the nine items for each student. displays the mean composite scores for each of the learning environments. There was a significant effect of learning environment (F (5,3243) = 4.08, p < 0.001). The mean composite scores for learning sessions that occurred in the operating room (which includes surgery and anaesthesia encounters) were significantly higher than the mean composite ratings for learning sessions that occurred in the ward (p = 0.001), clinic (p = 0.03) or ER (p = 0.002). displays the mean composite scores for clerkship rotation. There was a significant main effect of the clerkship rotation (F (6,3964) = 11.13, p < 0.001), but post-hoc tests showed that this significant effect occurred because ratings for anaesthesia were higher than ratings for all other rotations (p < 0.001 to p < 0.003).
Table 2. Encounter card results of global score by learning environment
Table 3. Encounter card results of global scale by clerkship rotation
The “nomination for teaching award” item was completed on 2947 (83.7%) of cards of which 33% indicated a positive response for wishing to nominate the faculty for a teaching award. Of the 587 supervisors, 147 (25%) had at least half of their completed cards suggesting nomination; whereas 180 supervisors (31%) did not receive any nominations for a teaching award. There was a significant difference in composite score when there was a positive recommendation for nomination (M = 5.29) versus no recommendation (M = 3.71, F (1,2945 = 1729, p < 0.001). This was consistent across clinical rotations ().
Table 4. Comparison of overall score (mean, SE) and nomination for a teaching award by clinical rotation
Discussion
Standardization of faculty evaluation across disciplines and learning environments using a practical tool is important for faculty wide comparisons and development. Our scale with eight items and a global rating is feasible to format on a card and is easy to distribute, carry and return. Based on the findings, we successfully implemented a revised faculty evaluation card in the clinical clerkship that was flexible enough to use across multiple learning environments. Although use of a rating scale for faculty evaluation is not itself unique, the widespread implementation across varying learning environments and specialties has not previously been reported.
The data collected from teaching encounter cards is twofold. It allows programmes to ensure the quality of teaching being provided, while also providing faculty members with formative feedback. Thus a balance between the purpose of the scale and the measurement properties is needed. Despite the high correlations between scores on some items, we feel that each item represents an important clinical teaching behaviour that may provide supervisors with valuable feedback. Others have shown that feedback to faculty on individual teaching behaviours may result in individual improvement (Maker et al. Citation2004).
The advantage of using a single tool across disciplines is to distinguish excellent teachers within the faculty. The close correlation between the combined score on the rating card and nomination for a teaching award across clinical rotations indicated our teaching encounter card is a valid means of identifying the top and bottom rated teachers. For high stakes decisions, a minimum of 17 evaluations per supervisor is required.
While the majority of studies have used in a single teaching setting, we have looked across learning environments. Those teaching sessions that occurred in the operating room and with anaesthesia faculty in general, were ranked higher than others. Copeland and Norman (Citation2000) implemented a standard faculty evaluation form across departments and all levels of trainees; however, the effect of different learning environments was not considered (Copeland & Norman Citation2000). Focused student–faculty interaction, which occurs in outpatient settings and operating rooms, may positively influence teaching evaluations. A comparison of general internal medicine faculty evaluations between inpatient and outpatient rotations demonstrated lower ratings in the inpatient setting (Ramsbottm-Lucier et al. Citation1994). The perceived higher degree of involvement with the supervisor in the ambulatory setting accounted for a significant amount of the difference between evaluations (Ramsey & Gillmore Citation1988). Further studies are needed to determine the extent to which learning environments might influence the evaluations provided for individual faculty members. For example, are ratings the same for faculty in anaesthesia when the teaching encounter is in the pain or preoperative clinic compared to the operating room?
The limitations of this study include the voluntary and anonymous submission of the teaching encounter cards. Although, it is essential to protect privacy of students for candid completion, there was no way to collect the number of trainees rating each faculty member, and it is possible that some students rated one supervisor more than once. There may be significant differences between those students who chose to complete evaluations and those who did not. The students also selected the supervisors for whom they submitted cards. This selection bias may reduce the likelihood of receiving encounter cards for “middle of the road” teachers i.e. those who do not stand out as excellent or poor.
The variability in number of responses across rotations may reduce the generalizability of our findings to specific rotations, however, all were well represented. We only included clinical clerks and not other levels of trainees. Further studies would need to be done to ensure generalizability across all trainees.
It is important to study now whether the feedback provided by these evaluation cards influences performance of individual teaching faculty, changes to clinical rotations and faculty satisfaction for their teaching efforts. The format that this information is relayed to faculty must be carefully planned and evaluated to encourage improvement and reduce the risk for disengagement of teaching faculty with suboptimal scores (Litzelman et al. Citation1998b).
Conclusion
We successfully implemented an anonymous, standardized faculty evaluation card across a range of clerkship rotations. This evaluation tool allows for individualized feedback to faculty members, comparison across rotations and identification of personal and programme areas of weakness and strength.
Declaration of interest: The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the article.
Additional information
Notes on contributors
Erin Keely
ERIN KEELY, MD FRCPC, is currently Chief, Division of Endocrinology and Metabolism at the Ottawa Hospital. As a clinician-educator, she has developed an interest in ambulatory care teaching.
Lawrence Oppenheimer
LAWRENCE OPPENHEIMER is Division Head of Maternal–Foetal Medicine in the Department of Obstetrics and Gynaecology and Director of the University of Ottawa Clerkship programme.
Timothy Woods
TIMOTHY J. WOOD is currently the Manager, Research and Development for the Medical Council of Canada and is an Adjunct Professor with the Department of Medicine, University of Ottawa. He has a PhD in Cognitive Psychology from McMaster University. His research interests are in evaluation, licensure and expertise.
Meridith Marks
MERIDITH MARKS, MD, MEd, is a clinician educator with a particular interest in faculty development and the assessment of interventions to improve teaching quality.
References
- Bloch R, Norman GR, 2006. G-String II, version 4.2. Available from: www.fhs.mcmaster.ca/perd/download/
- Brennan RL, 2001. Manual for urGenova.Iowa city. Iowa City, IA: Iowa testing programs, University of Iowa
- Brennan BG, Norman GR. Use of encounter cards for evaluation of residents in obstetrics. Acad Med 1997; 72: S43–S44
- Copeland HL, Hewson MG. Developing and testing an instrument to measure the effectiveness of clinical teaching in an academic medical center. Acad Med 2000; 75: 11–16
- Dent MM, Boltri J, Okosun IS. Do volunteer community-based preceptors value students’ feedback?. Acad Med 2004; 79: 1103–1107
- Irby DM. Clinical teaching and the clinical teacher. J Med Educ 1986; 61: 35–45
- Irby DM, Gillmore GM, Ramsey PG. Factors affecting ratings of clinical teachers by medical students and residents. J Med Educ 1987; 62: 1–7
- Kernan WN, Holmboe E, O’Connor PG. Assessing the teaching behaviors of ambulatory care preceptors. Acad Med 2004; 79: 1088–1094
- Litzelman DK, Stratos GA, Marriott DJ, Lazaridis EN, Skeff KM. Beneficial and harmful effects of augmented feedback on physicians’ clinical-teaching performances. Acad Med 1998b; 73: 324–332
- Litzelman DK, Stratos GA, Marriott DJ, Skeff KM. Factorial validation of a widely disseminated educational framework for evaluating clinical teachers. Acad Med 1998a; 73: 688–695
- Maker VK, Curtis KD, Donnelly MB. Faculty evaluations: Diagnostic and therapeutic. Curr Surg 2004; 61: 597–601
- Oppenheimer L, Keely E, Marks M. An encounter card to evaluate teachers in clerkship. Med Educ 2006; 40: 474–475
- Ramsbottom-Lucier MT, Gillmore GM, Irby DM, Ramsey PG. Evaluation of clinical teaching by general internal medicine faculty in outpatient and inpatient settings. Acad Med 1994; 69: 152–154
- Ramsey PG, Gillmore GM, Irby DM. Evaluating clinical teaching in the medicine clerkship: Relationship of instructor experience and training setting to ratings of teaching effectiveness. J Gen Intern Med 1988; 3: 351–355
- Richards ML, Paukert JL, Downing SM, Bordage G. Reliability and usefulness of clinical encounter cards for a third-year surgical clerkship. J Surg Res 2007; 140: 139–148
- Smith CA, Varkey AB, Evans AT, Reilly BM. Evaluating the performance of inpatient attending physicians. A new instrument for today's teaching hospitals. J Gen Intern Med 2004; 19: 766–777
- Steiner IP, Franc-Law J, Kelly KD, Rowe BH. Faculty evaluation by residents in an emergency medicine program: A new evaluation instrument. Acad Emerg Med 2000; 7: 1015–1021
- Willett RM, Lawson SR, Gary JS, Kancitis IA. Medical student evaluation of faculty in student–preceptor pairs. Acad Med 2007; 82(10 Suppl.)S30–S33
- Williams BC, Litzelman DK, Babbott SF, Lubitz RM, Hofer TP. Validation of a global measure of faculty's clinical teaching performance. Acad Med 2002; 77: 177–180
- Zuberi RW, Bordage G, Norman GR. Validation of the SETOC instrument – Student evaluation of teaching in outpatient clinics. Adv Health Sci Educ Theory Pract 2007; 12(1)55–69