Abstract
This AMEE Guide offers an introduction to the use of databases in medical education research. It is intended for those who are contemplating conducting research in medical education but are new to the field. The Guide is structured around the process of planning your research so that data collection, management and analysis are appropriate for the research question. Throughout we consider contextual possibilities and constraints to educational research using databases, such as the resources available, and provide concrete examples of medical education research to illustrate many points. The first section of the Guide explains the difference between different types of data and classifying data, and addresses the rationale for research using databases in medical education. We explain the difference between qualitative research and qualitative data, the difference between categorical and quantitative data, and the difference types of data which fall into these categories. The Guide reviews the strengths and weaknesses of qualitative and quantitative research. The next section is structured around how to work with quantitative and qualitative databases and provides guidance on the many practicalities of setting up a database. This includes how to organise your database, including anonymising data and coding, as well as preparing and describing your data so it is ready for analysis. The critical matter of the ethics of using databases in medical educational research, including using routinely collected data versus data collected for research purposes, and issues of confidentiality, is discussed. Core to the Guide is drawing out the similarities and differences in working with different types of data and different types of databases. Future AMEE Guides in the research series will address statistical analysis of data in more detail.
Introduction
We are surrounded by data (facts) wherever we go. In our lives we constantly take in data from our environment, interpret and make sense of this and store relevant pieces of information for the future. Too much data can, however, lead to information overload and there is a limit to how much useful information an individual can effectively store and retrieve. This means that data need to be recorded more permanently for future reference. This is not new. Five thousand years ago as more complex societies developed, the need for accurate bureaucratic records led to an organised system of records on clay tablets. Other societies recorded information using stone, papyrus, paper or even knotted string and many employed scribes to record and interpret important data.
Such stored information is only useful if organised in such a way that it can be retrieved quickly. A database is just an organised collection of data for storing, managing and retrieving information. The term originates from the development of computing in the 1960s, but a database does not necessarily need to be in digital form. A filing cabinet or card box to store records in alphabetical order could be considered a database, as it is simply a means of storing data and is designed to enable fast access to such information (see for an example of a paper-based database).
Picture 1. A paper-based database.

An electronic database can be even more powerful than a paper-based database – not only can it store large amount of data, it can also sort and order data in convenient ways and establish connections and patterns between related records. For example, using a paper database you cannot quickly sort records by age, find the oldest or youngest person or find everyone born on a particular day. Using an electronic database this information is readily available at the touch of a key.
Databases abound in everyday life now. When you go online to look for a cheap flight, the branded systems you use are sophisticated databases, organised in such a way that you can find the information you need. Similarly, online supermarket shopping is commonplace – when you go to the site of your favourite retailer to select the items you wish to buy and pay for them, you are using a database. When you search social media such as ‘Facebook’ ™ to find an old friend, you are again using a database. These public access databases are well planned to make them as ‘user-friendly’ as possible.
Organisations and companies, from small to large, heavily depend on databases for operations such as payroll, contact details for their employees and suppliers, ordering materials and so on. You probably also depend on your bank's database to keep track of your money and financial dealings.
The aims of this Guide are multiple. First, the focus is on setting up and using databases for medical education research purposes. We then introduce the different types of data – quantitative and categorical – and how to classify them. Related to this, we explain the difference between qualitative research and qualitative data. We present different types of database and data management software, for managing quantitative and categorical data. We then introduce how to work with quantitative and qualitative databases and some of the many practicalities of setting up a database so that it is usable for research. This includes: cases and variables, displaying data, variable names and value labels, unique identifiers, data entry, form design, dealing with missing data and ‘handy hints’. Statistical analysis of data is beyond the scope of this Guide, but we provide guidance on how to organise your database and prepare your data so it is ready for analysis (such as ‘eyeballing’ and describing your data). The ethics of using databases in medical educational research, including using routinely collected data versus data collected for research purposes, are then discussed. Furthermore, the purpose of this guide is not to examine technical aspects of a database such as design, construction and maintenance, as these may require specialist programming skills. Rather, we focus on how to best use databases for medical educational research projects, such as identifying patterns of performance, which students struggle with communication skills, where your students go after graduation, and who interacts most with students on the wards and so on, and use examples to illustrate various points.
Different types of data
When dealing with data and databases, it is fundamental to understand the differences between the different types of data. Understanding the type or classification of your data is important for both how you enter it into a database and how you then analyse the data. One crucial basic point to consider is the difference between data and information. Data are a representation of information – words, numbers, dates, images, sounds, etc., without context. For example, here is a list of data items:
Fail
MCQ
100
Part 2
Pre-clinical
60
Data items need to be part of a structure, such as in a sentence, in order to give them meaning. Information is a collection of words, numbers, dates, images, sounds, etc., put into context to give them meaning. While you will probably have spotted that these data relate to assessment in medicine, they do not gain true meaning until used in a sentence:
The Year 1 (pre-clinical year) MCQ examination has 100 questions in its Part Two, of which students must pass 60 or they fail the course and must repeat the year.
In other words, data can be thought of as raw material, while information is data that have been processed in such a way as to be meaningful. Databases are not, however, written in sentences to help you process the information they contain. Rather you need to use a structure in order for data to become information. In the second and third columns contain either ‘Yes’ or ‘No’, but without headings there is no meaning.
Table 1. The difference between information and data
This information, held in the database, can be used to determine which students are prone to not attending ward rounds without pre-authorising their absence. This knowledge then highlights which students need to be contacted by Faculty to discuss the reasons for their poor attendance at ward rounds. Knowledge is the ability to understand information and to then form judgements and opinions and to make decisions based on that understanding.
Classifying data types
Understanding how to classify data types is essential for both data analysis and for setting up a database. However, it can be a confusing topic as a number of different terminologies are used. Perhaps the most useful distinction that can be made is to divide data into two broad categories: quantitative or categorical (‘qualitative’). Note that quantitative and ‘qualitative’ refer here to types of data, not to different types of research paradigm (see later). Just to confuse matters even further, quantitative data may also be referred to as numeric or scale data, while categorical data may be called qualitative or attribute data.
We will refer to qualitative data as categorical data from now on, to limit potential confusion between qualitative/categorical data and qualitative research (see later).
Categorical data is the measurement expressed not in terms of numbers on a linear scale, but rather by means of natural language description (e.g. eye colour = blue, height = short). A set of data is said to be categorical if the values or observations belonging to it can be sorted according to category. Each value is chosen from a set of mutually-exclusive categories (i.e. a subject can be in one group only). For example, people have the characteristic of ‘gender' with categories ‘male’ and ‘female’, and they can be either ‘male’ or ‘female’, but not both. Similarly, people can be a member of just one age group or attend just one medical school.
Categorical data comprise either ordered or unordered categories. Unordered categories are where there is no natural ordering of categories, so they are nominally labelled (hence why unordered categorical data is also referred to as nominal data). Examples of unordered category data include marital status (e.g. single, married, widowed or separated), or different sports (e.g. baseball, basketball, football).
Ordered categorical data, or ordinal data, are defined by categories with a specific rank or ordering. For example, a question about student satisfaction with the following response options will collect ordinal data: unsatisfied, expectations met, exceeded expectations and significantly exceeded expectations. Categorical variables that judge size (small, medium, large, etc.) and attitudes (strongly disagree, disagree, neutral, agree, strongly agree) are also ordinal variables. A common example of ordinal categorical data is an asymmetric Likert scale, often used in questionnaire surveys. For example, you might be asked if you send emails to the student population every day, once a week, once a month, once a year, or never. (Note that the distances between points are not equal in this example, but symmetric Likert scales, with equal distances between points, are also commonly used).
Categorical data also encompass a third type of data: binary data – where there are only two categories (see for examples of the different types of categorical data).
Table 2. Different types of categorical data
Quantitative data, on the other hand are numerical data. As this implies, this is measurement in terms of numbers. Usually, quantitative or numerical data are associated with a scale measure where the distance between categories is the same (e.g., the difference between 1 and 2 is the same as the difference between 2 and 3), unlike categorical data. Furthermore, quantitative data can be discrete or continuous. Discrete data are whole numbers (e.g. the number of complete years a student has been studying). Continuous data can take any value within a certain range (e.g. height, age, blood pressure). Discrete data have finite values – you can count them (e.g. number of days spent in hospital). Continuous data technically have an infinite number of steps, which form a continuum. The number of questions correct in a test is discrete, as there are a finite and countable number of questions. On the other hand, the time taken to complete a task is continuous, since time forms an interval from 0 to infinity.
See for a pictorial representation of these relationships between quantitative and categorical data and for examples.
Figure 1. Different types of data.
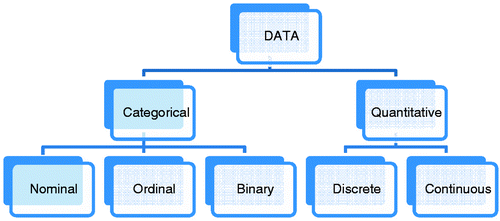
Table 3. Examples of quantitative data and categorical data
As another example, we can describe what we know about JC (one of the authors).
Categorical She has green eyes (nominal data).
She is in her 40 s (ordinal data).
She is female (binary data).
Quantitative She has two legs (discrete data).
She has one brother and two sisters (discrete data)
She weighs 60 kg (continuous data).
She is 165 cm tall (continuous data)
Discriminating between qualitative research and qualitative data
The examples of ‘qualitative’ or categorical data given above might seem a little confusing – surely ‘qualitative’ data is text, graphics, document or visual data from interviews, observations, recordings, focus groups and so on? What is the relationship between qualitative research and ‘qualitative’/categorical data? It is important to outline the difference here.
Fundamentally, what distinguishes the data in a qualitatively-designed study from ‘qualitative’ or categorical data is the set of assumptions and principles underlying the research (see for an overview of research paradigms).
Box 1 Research paradigms
In short, quantitative and qualitative research methods are based on different paradigms which make different assumptions about the world (Guba Citation1978), about how science should be conducted (e.g. because of the type of research questions under investigation in qualitative research studies, sample sizes are usually quite small, but selected because they have certain characteristics – whereas quantitative research studies usually require quite large samples in order to provide statistical power) and about what constitutes legitimate problems, solutions and criteria of ‘proof’ (Kuhn Citation1970).
Both approaches have their strengths and weaknesses (), and it is important to select the approach which is appropriate for the research question, or a combination of approaches which together provide complementary information.
Table 4. An overview of some of the strengths and weaknesses of quantitative and qualitative research methods
An increasing recognition of how both paradigms can be applied successfully to medical education scholarship, if done so guided by theory and reflection, is now apparent in the medical education literature (e.g. Ringsted et al. Citation2011).
Coming back to the main focus of this Guide, note that different research paradigms generate different types of data. Usually, data from qualitative studies using data collection methods such as interviews, focus groups, video diaries and so on cannot be reduced into very simple numerical form for analysis whereas categorical or qualitative data from a quantitative study can be. For example, if a respondent on a survey is asked for their dietary preference, and answers ‘vegetarian’, this is can legitimately be coded into a number (e.g. where 0 indicates non-vegetarian and 1 indicates vegetarian) and subjected to statistical analysis without losing meaning. Trying to squeeze narratives into boxes may, however, result in the loss of contextualisation and narrative layering. Qualitative researchers think that to do so sublimates the very qualities that make qualitative data distinctive whereas other researchers think presenting qualitative data within a scientific construct facilitates accessibility. Unsurprisingly, it is the quantitative researchers, those working within a scientific model, who support the latter approach.
There are many books, research papers and AMEE guides available that help determine whether or not your research question is best answered by qualitative or quantitative research paradigms and methods, or if a combination of these approaches (a mixed method study) is appropriate, and how to plan your research accordingly. To find out more about qualitative and quantitative paradigms, their differences, strengths and weaknesses, the following classic texts are helpful: Firestone (Citation1987), Bryman (Citation1984), Norman & Streiner (Citation2000) or Denzin & Lincolm (Citation2001). More recently, Ringsted et al. (Citation2011) provide a useful Guide for choosing a research approach that is appropriate to the purpose of the study while considering the individual researcher's preferences and the contextual possibilities and constraints. Cook (Citation2012) provides a very accessible overview of randomized controlled trials and meta-analyses, and their role in medical education research. Patricio & Vaz Carneiro (Citation2012) compare the evidence produced by systematic reviews of evidence in medical education (BEME Reviews) and clinical medicine (Cochrane Reviews). Other authors demonstrate the use of different qualitative methodologies in medical education research (e.g. Carroll et al., Citation2008; Cleland et al., 2008; Todres et al., Citation2012). This list is not meant to be exhaustive but these books and papers introduce some different methodologies for you to consider.
In conclusion, deciding the nature of your research and understanding the nature of your data are crucial when it comes to considering how to manage and analyse your data. Some types of data are appropriate for some types of analysis, others are not. For example, it does not make sense to compute the average (or mean) of nominal data; imagine computing the mean of gender! After introducing different types of database and what you may wish to consider when deciding which to use, we go on to talk about preparing the data in your database for analysis.
Types of databases
In this section, we introduce different types of databases and discuss their pros and cons for research purposes.
What is the difference between a database and a spreadsheet? Why can’t I just use a spreadsheet for my research project? Do I need a statistical or qualitative software package? These are very common questions, which apply equally to quantitative and qualitative research, causing a lot of researchers to scratch their heads. To help, this section weighs up the pros and cons of different types of software: spreadsheet, database, statistical and qualitative software packages.
Spreadsheet software
Many people will already be familiar with spreadsheet packages such as Microsoft Excel™. These feature individual cells defined by a set of rows and columns that can be used to enter data and have useful features such as the ability to quickly take the sum or average of a set of numbers. They are often able to produce graphs very quickly and are also great for rough working and for ‘what-if’ scenarios – how does changing one cell affect a whole system.
However, spreadsheets are not necessarily useful for a large research project. There are several reasons for this. Firstly, a spreadsheet usually consists of just one table whereas a database (see later) may contain a number of related tables which are integrated. It is also extremely easy to enter data in a format that is then difficult to analyse. For example, if there is a specific reason why a particular numeric value is unavailable, it may be tempting to write a comment in that cell of the spreadsheet. If, on the other hand, rather than a spreadsheet you use a statistical software package (see later), it will require you to keep text and numeric data separate, which means fewer hitches when you come to the analysis stage. Although some spreadsheets offer statistical functions, these are not generally adequate for most research project analyses (spreadsheets are not designed to do complex statistical analysis) and instead data should be imported into a statistical software package. However, you can also use spreadsheets when dealing with qualitative data, especially when using a framework approach where you want to be able to arrange, display and map out the data into a more easily digestible format (e.g. Miles & Huberman Citation1994).
Database software
Specific database software (such as Microsoft Access™) has many advantages for data entry, data checking, display of data and the ability to store data in complex formats. Some database software incorporates automatic data checks, e.g. they can be set up so that it is impossible to enter values that are out of a sensible range, such as ‘alien’ when the only two possible values should be ‘male’ or ‘female’, or 200 for someone's age.
Database software packages are powerful and can allow complex data that are hierarchical (one to many), for example, when each student has marks in more than one subject and each student has taken a variable number of tests or exams in each subject.
Database software also organises information on a particular subject for retrieval. Data can be retrieved through methods such as asking questions of the data (querying), sorting or filtering, and pulling information into a formatted report that can be printed. Databases also check certain fields, when instructed, to prevent unique identifiers such as patient numbers from being duplicated. This duplication check is not available in spreadsheet software.
Databases are actually much more powerful than spreadsheets in the way users are able to manipulate data. Here are just a few of the actions that can be performed on a database that would be difficult, if not impossible, to perform on a spreadsheet:
Retrieve all records that match certain criteria
Update records in bulk
Cross-reference records in different tables
Perform complex aggregate calculations
For these reasons, databases may be most useful when handling large amounts of information.
The main disadvantage of using database software for a research project is that it is optimised for data entry and routine data management and not for statistical analysis. For most research projects this means that data will need to be exported to another software package, specifically developed for analysis. However, data may not come through in an optimal format. Often variable and value labels may not be transferred correctly. For example, you might enter your data into Package A, and then try to convert it to Package B and find out that you used the latest version of Package A, but your version of Package B has trouble reading the latest Package A files.
Statistical and qualitative data management and analysis software
Statistical software
If you are working with quantitative (numerical) data and need to perform statistical analysis there is a third option: statistical software. The main advantage of entering data directly into a statistical package is that it removes the need to transfer the data for your analysis. As previously stated, transferring data from one package to another can be difficult. In addition, some data, such as dates, are notoriously difficult to transfer. Setting up data entry in a statistical package also forces you to think about how the data will be analysed from the outset. Often too many unnecessary data items are collected for a research project, or they are obtained in a format that is subsequently difficult to analyse.
In short, if the project involves statistical analysis, enter data directly into a statistical package from the start, don’t use spreadsheet or database software. This will force you to think about the types of data you are using (see earlier) and will save time in the long run.
Qualitative software
But what if you are working with qualitative (word or visual image) data? If your data takes the form of ‘words’ and text, or documents and video clips, there are specific qualitative research software packages available to facilitate data management and analysis.
Qualitative research databases facilitate the interpretation of qualitative data through the coding of themes, concepts, processes, contexts, etc., in order to build explanations, theories or to test or enlarge on a theory. Qualitative software packages are useful for managing large amounts of qualitative data and can save time in terms of manual sorting and organising data. You can usually do the following with a qualitative database: colour your written text or highlight text segments using a marker; use drag and drop coding; get an overview of various object types like primary documents, quotations (i.e. coded segments), codes, memos and saved network views; get a full overview of all codes or memos at any time; manage (sort, rename, merge, delete) codes conveniently; always see your coding; label fine-grained units of analysis (e.g. text characters, image pixels); use colour-coded and grouped codes and so on. Qualitative databases make managing and analysis a large amount of text and/or visual data much, much easier.
However, a word of caution: if you are not familiar with these packages, they can take a while to learn (this is no different from a quantitative database). For smaller qualitative studies (e.g. small pilot study with up to ten interviews) you might wish to consider working with a more manual approach using a spreadsheet to help organise and display your data. A combined approach of Excel™ and Word™, rather than a specific qualitative software package, can work well if your study is relatively small.
Choosing a database
There are a number of considerations when choosing a database (). Possible users of a database could be researchers, students, educators, administrators, statisticians (if a numerical database) or those entering the data. They could have no experience using databases, some experience of using different software or some experience using databases in the chosen software. For large complex projects it may be advisable to include an experienced database designer as part of the research team.
Box 2 Choosing a database
Box 3 Handy hints
The length of time that this database will be in use, and the importance of the data [that will be contained within the database], must be fully accounted for when deciding how many resources to set aside for buying or creating the database. If a database will only be used for one week to analyse results from a pilot formative test, then a very simple database may suffice. Conversely, a database designed to contain course evaluation data for the next 20 years will need to be carefully designed, with thought given to possible future requirements. Changing the design of a database once it is in use is possible, but not always easy to do and may cause inconsistencies as the data are collected over time.
You might be wondering how software can code and analyse data from, for example, interview or focus group transcriptions – it may be easier to see how statistical software can carry out computations on numerical data. The bottom line is that both statistical and qualitative research software packages are designed brilliantly – to do what you tell them to do (not necessarily what you want them to do)! The manuals and websites of software packages provide much invaluable information to help you in this, but do seek out other people in your institution who have used the package before, and ask them for any handy hints or advice they can provide.
As before, it is best to start as you mean to go on. For a large project, specific database software offers many advantages. If you intend to carry out statistical or qualitative analysis on your data, use the appropriate specialist research software package from the start. Basically, if you are working with numbers, or data which can be sensibly coded into numerical form (see later), you need a database that is designed to store and analyse numerical data. On the other hand, if your study design is qualitative and hence your data takes the form of ‘words’ and text, or images and visual material, you may want to use a specialist qualitative database to facilitate data management and analysis.
We cannot recommend specific databases, but many are available commercially and are used widely by universities. The use of a commercial database requires a licence, which has a cost attached. The choice of database may be dictated by the resources of your institution, your personal preference and/or what support is available locally.
Working with research databases
Quantitative research data
As discussed previously, in quantitative research, databases hold quantitative or categorical data that has usually been translated into numerical form for the purposes of storage in a database and for statistical analysis. The data may have been collected via a questionnaire survey of, for example, course evaluation, where students may have answered on a 1–5 scale where one is very poor and 5 is very good. A clinical example would be patient responses on a scale of never, once a year, once a month, once a week, every day. In this section, we explain some of the fundamental steps in setting up your database and entering your data so it is ready for analysis.
Cases and variables
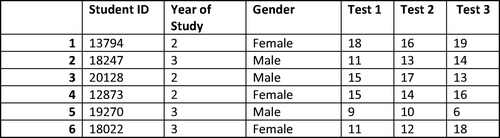
First we introduce two fundamental concepts: records/cases and variables. Usually a case or record is signified by a row in your database, while a variable is a column. We have provided an illustrative example (). In this example the rows (the ‘cases’) represent students, while the columns represent ‘variables’, i.e. attributes of the students such as their ID number, their gender or their test results.
Figure 2. Example of records/cases and variables.
A ‘record’ or ‘case’ can be thought of as a form divided up into areas into which are placed specific types of information. There can be any number of records/cases in a database. Each could typically correspond to a person (as in student records), but equally can correspond to an ‘individual case’ of a chunk of information such as a response to one interview question or an episode from a transcript. A range of operations can be performed on a set of such records, a process resembling filling in, shuffling and sorting a set of file cards. These operations include sorting cases/records, finding records of a given type, classifying and coding the information in a given field, finding instances of a given type of information, counting instances and so on. In this way, an electronic database can display information in whatever way one chooses, limited mainly by practical considerations.
A variable, on the other hand, is a symbolic name representing some attribute of the case (a piece of data that may vary from person to person, record to record). For example, a variable might be: score on the Year 1 OSCE exam, age, gender, score on a written exam or attendance on the wards.
Sometimes multiple variables are required to measure one aspect – for example, if students receive a series of tests on the same subject, a separate variable is required for each test. You may have a choice between setting up your data using different formats (). In long format, each row (or case) represents the result of a particular test, in a particular subject, for a particular student. For example, in the first (top) format presented in , in the first row of data, we see that student 1 received a score of 16, for test one, in mathematics. In an intermediate format, each row represents the results of multiple tests, in a particular subject, for a particular student. For example, in the second (bottom) format presented in , in the first row of data, we see the scores that student 1 received for tests one to four, in mathematics. There is also wide format (not pictured) where each row represents the result of multiple tests, in multiple subjects, for a particular student. For example, in the row of data, you would see the scores that student 1 received for four tests in mathematics and another four tests in english.
Figure 3. Two ways of displaying the same data: long format (top) or intermediate format (bottom).
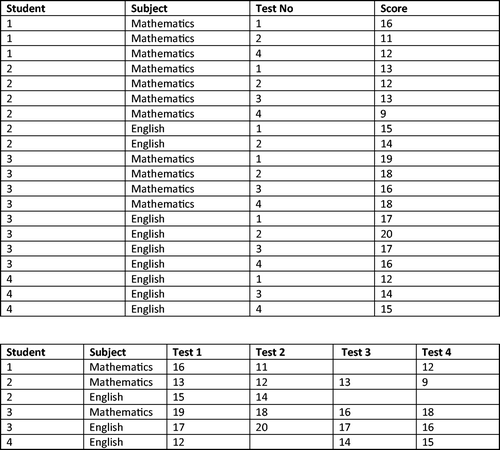
In questionnaire design, a situation occurs that often catches people out. Frequently, there is a mixture of types of questions, some with the instruction ‘tick one box’ and others ‘tick all that apply’. When setting up a database for this type of questionnaire, it is easy to forget that those of the latter type require a separate variable for each possible response option, whereas for the ‘tick one box’ variety, only one variable is needed. It is important to consider how the database may be set up as you design your instrument (i.e. survey) for these reasons!
Variable names and value labels
As discussed earlier, in most systems the columns of the matrix will represent variables (e.g. student names or the marks in a particular exam) and the rows will represent cases (e.g. individual students). Labelling your variables clearly is critical – someone else might take over the project and need to make sense of your labels or you yourself may have a period of time away from the project, and not understand your own labels when you get back to it (believe us, this happens more often than you might think!). The same considerations apply to value labels - numeric codes for categorical variables, e.g., 0 for male, 1 for female. It is very important to document exactly what the codes stand for, as these can easily be forgotten. See for some ‘handy hints’ for variable and values labelling.
How variables are named is very important. They should be kept relatively short, for ease of use. On the other hand, they also need to be informative. A variable containing the grade for an English course might be called ‘GradeEnglish’ to help distinguish it from the variable for a mathematics course, ‘GradeMaths’. This tells a user of the database more information, and will lead to less confusion, than simply calling the variables ‘Grade1’ and ‘Grade2’. However, note that in the past, some software packages limited variable names to no more than eight characters and even today it is usually not possible to include spaces or special characters as part of a variable name.
To work around these problems, some software packages allow both a variable name and a variable label, which may be longer, allow spaces and special characters and which provides a more exact description of what the variable represents.
This advice may seem trivial and unnecessary. Nevertheless, several different people may use this database, with varying levels of familiarity of its design. What may seem obvious to one person may not be to another. In addition, a database may not be used for a while, before it is required again. Individuals may forget what piece of information is contained within a variable.
It is recommended that variables be named consistently. For example, the variable for question 1, part 1 may be called ‘Q1P1’. The variable for question 2, part 2 should then be called ‘Q1P2’ and not ‘P2Q1’, say.
To avoid any confusion, ensure the meaning of variables and value codes are made explicit in a formal coding sheet or data dictionary that lists the exact meaning of every variable and code number used (). If your software allows this, it may be acceptable to document this within the program itself, but be aware that value and variable labels may be lost when the data are transferred to another package.
Figure 4. Example of a coding sheet (data dictionary).

Unique identifiers
Often a database is used by many different people, for a variety of reasons. Access to all the data contained within the database may need to be restricted. Even if this is not the case, it is still good practice to keep confidential information, such as students’ names and addresses, separate from other data. An effective way to ensure confidentiality is to create two databases: one for confidential data, the other for non-confidential data.
The database containing all the confidential data should contain a unique identifier (ID) for each record. This same unique ID should also be used in the database containing the rest of the information for that record. This will allow for the data kept in both databases to be linked, if necessary. For example, the names and salaries of staff members could be kept in one database, while the number of students and hours each staff members teaches could be kept in another database, and the two databases could be linked using staff ID numbers. Access to the confidential information should be restricted, either using a password protected database or a secure file location.
This ID should be an alphanumeric variable and it should be something that cannot be linked back to the individual (see the section on Ethics). To illustrate, each record could simply be numbered 1, 2 and so on. Or perhaps S1, A1, S2, A2, could be used to identify the first student on the science course, the first student on arts course, the second student on the science course, the second student on the arts course, and so forth ().
Box 4 Handy hint: Never mix text and numeric data
This unique ID will prove invaluable when checking the data contained in the database for odd or inconsistent values. Without it, several pieces of information, such as a student's name, date of birth and so on, may be required to check copies of records for data entry errors. With one, it may be simpler to compare electronic and hard copies of the same information. The use of a unique identifier is also recommended in terms of confidentiality.
In addition, this ID can be used to link data from different sources together. If a student's personal information, courses taken, and exam results are all kept separately, the ID unique to each student can be used to combine all of their details together into one dataset.
Data entry
Data entry is an area which attracts little attention in the research arena. Data can be entered into a database in different ways. In the early days of computing, data were sometimes entered by a manual system of reading punched pieces of cardboard. Later data had to be input using command syntax. Nowadays, some specialist statistical packages require data in a particular format such as a text file with data separated by commas or spaces, but most data can now be entered using a spreadsheet format by typing data into cells of a matrix. ‘Raw’ data can sometimes be imported directly, such as saving an interview transcript into a qualitative data analysis (QDA) software package. For some research projects optical scanners can be used to read data directly from questionnaires. If carrying out an online survey, you may be able to set up the survey so that completed questionnaires are entered automatically into a database, depending on the precise combinations of survey package and database software used.
However, depending on the nature of your project and the resources available to you, you may have to manually enter data from paper questionnaires or exam papers into a database, a tedious and time-consuming task. It is often assumed that this ‘comes naturally’, but our experience is that some personalities are better suited to meticulous data entry than others. So, when planning your project, consider how will the data be entered? If manually, who will enter the data? Would two heads be better than one (one reading out the data, one entering it)? What skills and experience do they have? Who is going to check the data entry?
Manual data entry is a tedious task and errors are commonplace (). As a result, it is important to check the quality and accuracy of the data entry prior to the data analysis stage (discussed later).
Box 5 ‘Rubbish in, rubbish out’ (RIRO)
The gold standard method for data validation would be duplicate data entry, where all records are entered twice and then compared in order to identify any discrepancies between the two versions. However, duplicate data entry is time-consuming and costly; so many projects use a check of a certain percentage of the data entry as a quality assurance method. A variety of percentages, e.g. 5% 10%, 20% checks have been used – the proportion to be checked needs to be decided based on the total number of records and the amount of resources that can be allocated. For many projects, there may not be the resources available for these kinds of data checks, but it is still very important to carry out range and consistency checks, as outlined later.
Form design
Often the design of a database follows on directly from the design of a form or questionnaire. It is often possible to include code numbers on a questionnaire, which can be used for data entry. Using database software, it may also be possible to set up data entry so that the format of the data entry screen is exactly the same as the format of the questionnaire itself (see, e.g. ). As discussed earlier, typically, only one line or record of data will be entered for each person (e.g. lecturer) or item (e.g. assignment) of interest.
Figure 5. Example of a questionnaire format incorporating coding that can be used for data entry.

Note that it is usually better to make things as easy as possible for data entry. If questions need to be reverse scored, this can be done at the analysis stage.
How to designate missing data?
Missing data are, unfortunately, a common occurrence when working with research databases – however hard you try, it is likely that some information will remain unknown and this could be for a variety of reasons.
When setting up a database you need to consider how missing data will be recorded. The most common situation is just to leave missing values blank and not to enter anything into a cell. It is also possible to assign specific codes, typically 9 or 99 to indicate missing values. If doing so, however, you need to be careful to ensure that actual values of 9 or 99 are not possible for this particular variable and to account for the coding at the analysis stage – e.g. taking an average of a set of numbers that includes values of 99 could give you very misleading results.
Checking data
This section introduces some basic descriptive statistics which are useful for describing your data, to ensure that what has been entered into the database is correct. It is very tempting to jump straight in and start to analyse your data, but this is not recommended. First, you need to clean your data and check for possible errors.
Visual inspection of data is a common method of initial quality control, although this should be no substitute for formal data checks. This is often called the ‘eyeball technique’ or ‘eyeball method’ of data assessment ().
Box 6 Eyeballing your data
In addition to be detecting visible differences between groups, it may enable you to spot many other things (drift over time, obvious outliers/typos in your data set). It acts as a sense check for your data, but it is no substitute for formal data checks, especially when the size of the dataset is large. There are two further types of checks that can be made to ensure clean and valid data: range checks and consistency checks.
Range checks ensure data are within a sensible range, for example, if someone's age had been entered as 200 then it would have to be an error. Consistency checks ensure that pairs of variable are consistent. For example, if someone replies that they are a non-smoker in one question but later admit to smoking 20 cigarettes a day, this would also be a mistake of some kind.
Range checks can be performed by obtaining the maximum and minimum values or histograms (for quantitative variables) or frequency tables (for categorical variables). Consistency checks may be performed using scatter plots or using cross-tabulation tables.
Both these types of checks are just common sense but are often forgotten, leading to potentially misleading results. There is also an advantage if these checks are performed automatically as part of the database structure. Packages such as Microsoft Access™ may be set up so that it is impossible to enter an age below zero or above, say, 120 at the data entry stage. This may reduce the number of errors in the data. It may also, however, be time consuming to set up and it may be difficult to know at the outset what ranges are sensible. Returning to the example on age, it would be clearly impossible for anyone to be aged -1 but it is not possible to set a firm upper limit on this variable. Another option within some databases would be to set up queries to highlight those records with out of range values. Getting into a routine of running these daily, or at the end of a batch of entries, means that errors or inconsistencies can be investigated whilst you still have the source data there. Otherwise, if you do find possible errors or inconsistencies, you will need to go back to the source of the data and check this. This may mean checking paper records or going back to the person who supplied you with the data. Such data checks cannot pick up all possible data entry errors, but they should pick up the majority and are recommended before starting your data analysis to ensure high data quality.
Describing data
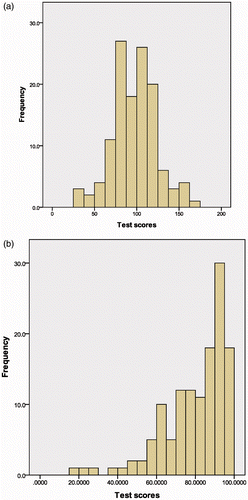
Graphs are a very clear and effective way of presenting your data. The best way to describe your data will depend on the data type: for categorical data you can display your results using a bar chart. When you have quantitative data you should first graph your data using a histogram: this will show you the overall shape or distribution of your data (). For a discussion on the difference between a bar chart and a histogram, see ).
Figure 6. The results of two student tests. (a) The best data descriptors will be mean and standard deviation as the distribution is symmetrical; (b) use median and range as the distribution is skewed.
Box 7 The difference between a bar chart and a histogram
It is often useful to describe your data using appropriate summary statistics – once again this will depend on the type of data that you have. For quantitative data, however, there is a further consideration – the shape or distribution of the data. What this means is that it is usually best to start by plotting a histogram to help you decide which summaries to present.
Provided that you have roughly symmetrical data, the mean (the simple average) will be the best single-figure summary of your data. To indicate the spread or dispersion of your data you should use the standard deviation – this is useful because most data values will fall within two standard deviations of the mean.
If your data have a skewed distribution, the mean and standard deviation will often not be sensible summaries of your data as they will be highly influenced by extreme data values – instead you should use the median (the middle value when your data are arranged in ascending order) as the main summary measure. To describe the spread of your data, you can use the interquartile range or the range (the maximum minus the minimum value). In fact, examining the maximum and minimum values is often the quickest way to evaluate if you have any problem values in your dataset.
If you have categorical data you should instead describe your data using frequencies and percentages.
You are now ready to carry out statistical analysis on the quantitative data held in your numerical database! To do so successfully, you need clear research questions, knowledge of statistical analysis and – ideally – the support of a statistician. It is beyond the scope of this Guide to discuss data analysis methods but many useful introductory texts are available (Altman Citation1991; Bland Citation2000; Bowling Citation1997; Norman & Streiner Citation2000; Petrie & Sabin Citation2005). We have provided an example of a study using a numerical database, quantitative methods and statistical analysis, where the role of the statistician was central ().
Table 5. Common uses for databases in undergraduate medical education
Box 8 Example of a quantitative research study (Cleland et al., 2008a)
Qualitative research data
Qualitative research methods tend to generate language or image data. This could be field notes, narratives or other forms of written text such as audio recordings which are then transcribed into written text. Other forms of media such as video recordings, images/photographs and documents (reports, meeting minutes, e-mails) can all be used. The three main types of data in qualitative research are:
Ethnographic field notes – written observations of the field setting that record what is seen, heard or observed.
Interviews designed to elicit stories and accounts, views and attitudes from respondents. Usually interviews are recorded and transcribed, generating large numbers of words. When carefully recorded and transcribed the questions and answers become the data elements.
Focus groups where, usually, three to 10 persons, are asked to address a group of questions for which they have the expertise to provide illuminating information.
The most common forms of qualitative data in medical education research are what people have said during interviews or focus groups. Usually, with appropriate consent from the participants (see later), interviews or focus group interviews are recorded for later transcription and analysis. This can be done using tape recorders with cassettes or digital voice recorders (DVR), which provide better sound quality and recording accuracy, and allow you to download the electrical digital file directly onto a computer, but are often more expensive than tape recorders.
Recording interviews and focus groups is good research practice for a number of reasons. For example:
If you are taking copious notes, you cannot truly focus in on what is being said in such a way as to manage the interview well.
Recordings allow you to follow the narrative of an interview, for example, in a group interview who said what, how did people respond to a comment from another participant or from the interviewer. This can be worthy of analysis in itself.
You can get an impression not just of what participants said (the content of the interview) but also how they said it (in anger, timidly, in a questioning tone of voice and so on).
Your notes may mean little to you a few weeks later, whereas a recording holds all the information
A handy hint, no matter which recording device you use, is to have a remote microphone directed at the respondent, and sit near the recording device when asking questions.
Transcribing this data means typing out the text (from interviews, observational notes, memos, etc.) into word processing documents. It is the data from these transcriptions that are managed and later analyzed (most people find it easier to manage data in which has been transcribed rather than working solely from recordings). See for an example of transcribed data (from Cleland et al., Citation2008b).
Box 9 An example of transcribed data (from Cleland et al., Citation2008b)
There is no doubt that recording interviews or focus groups creates a lot of data to manage! If you have collected data from more than a small number of interviews or focus groups, you may want to use a qualitative database (software packages specifically developed for qualitative research) to facilitate this data management and analysis. These are often referred to as Computer-Assisted Qualitative Data Analysis Software (CAQDAS; Fielding & Lee Citation1991). Before we talk more about CAQDAS, it is worth illustrating that many of the issues discussed in the section on numerical or categorical data are also pertinent to managing qualitative research data.
Data entry
As is the case with a numerical database, attention paid to this early stage will greatly help later analysis and interpretation of qualitative research data. Questions you need to consider are – if audio recordings are to be transcribed, who is going to transcribe them? Who is going to check the transcription for quality? What level of detail do you need for your transcriptions, e.g. just spoken word, or do you need to include ‘uhms, ahs’ or sighs, laughs, etc. For focus group transcriptions, have individual participants been differentiated correctly?
Data checking
If using audio or digital recordings which are then transcribed, whether you carry out the transcription or it is done by a third party, it is extremely important to check your transcripts against the original recordings to check accuracy. If transcription is carried out by a third party, there may be errors in terminology if your topic is quite specialist/specialty orientated. There may also be errors in place and people names (we have had some very funny/strange transcription errors in terms of Scottish town/hospital names). Even if you are transcribing yourself, or someone locally if doing it for you, you must check the transcripts against the recordings as it is very easy to drop a ‘not’ from a sentence by accident which can then totally change the meaning. The term ‘Rubbish In – Rubbish Out’ () also applies here.
Unique identifiers
Each participant should have a unique identifier (ID). This ID should be an alphanumeric variable as pseudonyms might be considered a form of symbolic violence over the participants (Bourdieu Citation1991) and it should be something that cannot be linked back to the individual (see earlier and the section on Ethics). Details which could identify the speaker must also be stripped out from the database. For example, in a recent study carried out in Aberdeen, we interviewed physiotherapy, occupational therapy and diagnostic radiography educators about their experiences of assessing students on clinical placement. We realised when looking at the participant background information sheets that all data had to be reported by number (e.g. participant 1, focus group1) only as adding in details such as locality of workplace or gender would have facilitated identification of individuals.
As before, the database containing all the confidential data should be linked to participant background details using only a unique ID and access to the qualitative research database should be restricted.
Data description
Qualitative data analysis (QDA) is the range of processes and procedures whereby we move from the qualitative data that have been collected into some form of explanation, understanding or interpretation of the people and situations under investigation. The idea is to examine the meaningful and symbolic content of qualitative data.
Data describing and analysis in qualitative research tend to overlap. While the purpose of this Guide is not to introduce qualitative research data analysis in depth, it is important to give an overview of the first steps, those akin to describing your data when working with numerical data.
The process of QDA usually involves two things; coding (the identification of themes) and writing. We describe coding here as it most closely resembles data description – writing tends to be more analytic and interpretative and hence beyond the scope of this guide.
Coding
On any given topic and in answers to interviewers’ questions, respondent stories may be highly differentiated and varied in content. The researcher must read through much textual data trying to locate and understand different themes or uniformity that emerge from respondent stories. This includes identifying textual material (appropriate quotes) that exemplify the themes (or categories) relevant for the written report. The analyst needs to define categories for the different themes and may assign some code or value to each category. If and when a coding scheme has been generated, the researcher(s) can encode each respondent's answer according to those themes. In other words, coding is the identification of passages of text (or other meaningful phenomena, such as parts of images) and applying labels to them that indicate they are examples of some thematic idea.
At its simplest, this labelling or coding process enables researchers quickly to retrieve and collect together all the text and other data that they have associated with some thematic idea so that they can be examined together and different cases can be compared in that respect. Coding the data makes it easier to search the data, to make comparisons and to identify any patterns that require further investigation.
Codes can be based on:
Themes, Topics
Ideas, Concepts
Terms, Phrases
Keywords
As you read through your data set the number of codes will evolve and grow as more topics or themes become apparent. The list of codes thus will help to identify the issues contained in the data set.
During coding, you must keep a master list (i.e. a list of all the descriptors or codes that are developed and used in the research study). Then, the codes are reapplied to new segments of data each time an appropriate segment is encountered. It is surprising how the meanings of codes/themes can evolve during analysis. Therefore, keeping a current description of the code/theme will improve consistency over the whole dataset.
Thus, whereas in a quantitative database you ‘code’ information in terms of values and variable names, coding in qualitative research means something a little different but similar in that coding is a way of pulling out information for analysis. CAQDAS packages involve tools which can mark and retrieve data through coding the text, such as interview transcripts, field notes, transcribed recordings, documents. Coding involves marking the text in order to tag particular chunks or segments of that text. Codes are thus attached to discrete stretches of data. (How you code the data is up to you and may be influenced by your conceptual or theoretical framework.)
In we present a snapshot of a page of codings from one of our exploratory studies, which looked at identifying communication skills training needs in primary care (Moffat et al. Citation2007).
Figure 7. An example of a coding page (Moffat et al. Citation2007).
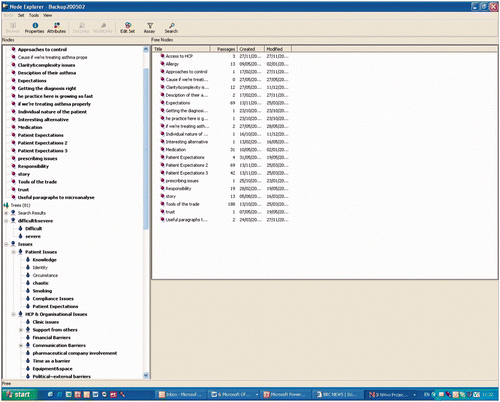
Qualitative database software facilitates the attachment of these codes to data; it also allows the researcher to retrieve all instances in the data that share a code. The underlying logic of coding and searching for coded segments differs little, if at all, from that of manual techniques to do the same thing. There is no great conceptual advance over the indexing of typed or even manuscript notes and transcripts, or of marking them physically with code-words, coloured inks and the like. However, using a computer database enables fast and comprehensive searches that can use more than one codeword simultaneously, to facilitate complex searches. The co-occurrence of codings can be an important issue; finding them can be a useful tool. Since the software can handle very large numbers of codings and code words, in purely mechanical terms the computer can help with more comprehensive and more complex code-and-retrieve tasks than can be achieved by manual techniques. Many of the packages also allow the researcher to add notes to the text, which facilitates analysis.
Thematic or conceptual coding is one way of categorising data, but some packages provide alternative means of working with qualitative data. One example of this is the use of linking tools to track non-linear associations, which can be particularly useful for narrative-based approaches (see Silver & Fielding Citation2008 and Silver & Patashnick Citation2011 for more discussion on this). CAQDAS packages also provide tools that allow textual data to be explored according to content, i.e. to consider the context within which keywords or phrases are used, which can be useful for approaches interested in the use of language.
The fact that qualitative databases allow for coding alongside the data is hugely helpful in terms of data management, particularly if you have a lot of data to manage. We provide an example of a qualitative research project which used a database to aid data analysis in .
Box 10 Example of a qualitative research study (Cleland et al., 2008b)
We cannot provide a full description to qualitative data management and analysis in this Guide, so we direct you to the many textbooks and online resources available to help with this aspect of qualitative data management (e.g. Ryan & Bernard (Citation2003) or Strauss & Corbin (Citation1998)).
Ethics and confidentiality
Any medical education research study involving data collection must follow ethical procedures. These differ by country. For example, the Netherlands does not have rule-based ethics review for education projects. In the UK, however, most medical schools and universities have internal ethics review committees for research involving students or staff – these are different from those committees which review research studies involving patients. In countries without separate review boards for educational projects, the mainstream review boards and ethics committees frequently find it difficult to handle requests for review from the medical education community. On the other hand, medical education journals (the journals you are likely to want to publish your study in!) each have a philosophy-based approach to ethical conduct which requires that authors show how they addressed the spirit of protecting subjects and how they articulated any issues of risk. The journals do not define or police ethical standards but, rather, are clear on what statement is required from the authors about ethical requirements in their country of origin. In other words, they encourage authors to be transparent about issues of research ethics (Brice et al. Citation2009).
Our advice is to follow good research practice no matter what the procedures of your country or institution. Broadly speaking, this means:
Taking necessary steps to ensure that all participants in the research understand the process in which they are to be engaged, including why their participation is necessary, how it will be used and how and to whom it will be reported. This is usually achieved by using a ‘participant information sheet’ (PIS) outlining the nature of the project and what is involved in taking part. It should be made clear on the PIS that a participant can withdraw from the research for any or no reason, and at any time, without recourse.
Ensuring potential participants understand and agree to their participation without any duress (i.e. taking part in any research project must be voluntary). Agreeing to participate and knowing what one is agreeing to, can be implied by, for example, questionnaire completion, but often participants are required to sign a separate ‘consent form’.
If you have the funds to use incentives to encourage participation, these should be commensurate with the effort involved in taking part (e.g. providing a sandwich lunch and travel expenses for people taking part in a focus group is reasonable, paying them more than a small sum of money is not). Remember that if you are using incentives, this can influence the research in terms of a bias in sampling or in participant responses.
The secure, confidential and anonymous treatment of participants’ data is considered the norm for the conduct of research. To aid in this, it is desirable to ask the researchers to sign a code of conduct or equivalent, to agree to maintain confidentiality and security. The database should be password protected or held on a [desk-top or] computer which remains within the institution – laptops are often stolen! Any database or data file which has student/doctor identifiable details on it should not be transferred between computers on a memory stick or disk, unless this is encrypted. It is good practice to keep confidential information, such as students’ names and addresses, separate from other data.
You must never send identifiable data outside your institution electronically (unless encrypted) or in paper format. If you are doing a two-centre or multi-centre study where the database has to be sent elsewhere, or you are receiving data from another institution to merge with a database you are holding, the project must be organised so that shared data does not contain student/doctor identifying details. This is good research practice and pertains to any data sharing, not just that held in a database.
Once the project is finished, the database should be locked and stored (archived) as per institutional guide lines.
Similarly, researchers must ensure that the form of any publication does not directly or indirectly lead to a breach of agreed confidentiality and anonymity.
And, particularly relevant to education research, researchers must comply with the legal requirements of their county in relation to the storage and use of personal data. People are entitled to know how and why their personal data is being stored, to what uses it is being put and to whom it may be made available (this information should be included in your PIS).
As discussed earlier, often a database is used by many different people, for a variety of reasons. Access to all the data contained within the database may need to be restricted. Even if this is not the case, access to the confidential information should be restricted. This is usually via password protected files and computers. In addition, the database containing these data should be kept in a secure location.
Using routinely collected data for research purposes
Much data are collected about medical students and doctors that does not relate to specific research projects planned in advance. This concerns data that are routinely collected by medical schools for other purposes ().
You may want to apply a research question to a database held by the medical school for administrative purposes. If analysis of a routine database will address your research question, as a very rough guide, and bearing in mind the data protection legislation and principles for your country, you are likely to be able to access routine medical education data legitimately if you are a contracted Faculty member (but check the specific rules and regulations of your institution!). If you are using a researcher for data checking and analysis, it is desirable to ask the researcher to sign a code of conduct or equivalent. Alternatively, you could ensure that all person identifying details are removed from the routine database before it is used for research purposes.
This information is invariably collected on a non-consented basis and, as such, there may be ethical issues in using it for research purposes. In other words, an existing database will not have been set up originally for research purposes but will hold routine data – admissions or assessment data for example. In this case, your use of the database is secondary to its main purpose.
There have been long-standing debates as to whether or not use of routine databases in medical education constitutes research or evaluation (see McLachlan and McHarg Citation2005, for an overview of this debate). Top of page Abstract
Morrison and Prideaux (Citation2001) proposed that research is ‘aimed at producing generalisable results to be published in the refereed literature’. Research is intended to benefit a general, non-specified audience, while evaluation is addressed to a particular (and specified) constituency or constituencies. In contrast, evaluation tends to be for local purposes – is our teaching acceptable to students, how does one examination compare to another in terms of difficulty, etc.? However, data gathered for evaluation or other purposes may subsequently be appreciated as generalisable (e.g. Cleland et al. Citation2008a). The lack of necessity for formal ethical permission from a local research ethics board (REB), including informed consent, for evaluation means that data that are subsequently reclassified as of research interest ‘lie in ethical limbo’ (McLachlan & McHarg Citation2005). (Where you are creating a database purely for research purposes, as part of a planned study, the situation is less disputable: you must follow the ethics procedures of your country/institution for educational research.)
While some medical educators feel that subjecting education research to the level of scrutiny of a REB is akin to ‘using a sledgehammer to crack a nut’ due to the comparatively low risk involved for participants in education studies (Pugsley & Dornan Citation2007), our view is that it is unethical not to do so. Our own experiences are very positive and often a simple, pre-application query is enough for the Chairman of a REB to give a view as to whether or not a full application is required. Many medical school and universities now have an internal ethics Board or Committee, established to deal with ‘low risk’ studies and populations, where the procedures are more straightforward (reflecting the low risk of this type of study and the fact that the populations under study tend not to be vulnerable). Furthermore, to publish your work, you may be required to provide evidence that you sought ethical permission (Brice et al. Citation2009).
We have tried to give some broad guidance on the ethical issues involved in educational research and use of routine databases in educational research. Further reading on this topic includes the following. A useful guide for seeking ethical approval for education research is ‘Twelve tips for ethical approval for research in health professions education’ by Egan-Lee et al. (Citation2011). A recent editorial in the journal Medical Education (Eikelboom et al. Citation2012) presents a framework for the ethics review of education research and see also Kanter (Citation2009) for the journal Academic Medicine's policy on studies involving human participants. Ten Cate (Citation2009) provides a useful editorial on why the ethics of medical education differ from those of medical research (see also Eva Citation2009) and the American Educational Research Association (AERA) provides a Code of Ethics for educational research (Citation2011).
Conclusion
This AMEE Guide is intended as an introduction to research using databases in medical education. In addition to outlining many basic principles of research using databases, from setting up to describing your data, it presents an overview of the variety of research data and methodological approaches which are suitable for database research. We have tried to explain the various steps in planning and setting up a well-designed research database and how ethical and careful planning can greatly assist in achieving and providing accurate data management, ready for analysis, whether you are using qualitative or quantitative database software, whichever is appropriate for your research question. We have supported the content with a combination of ‘seminal’ and more recent references. We have aimed for a Guide which is useful to all researchers, not just those with (relatively) plentiful resources. We hope readers have gained insight into how different types of data can be used in furthering the goal of extending the knowledge and understanding of medical education. Future AMEE Guides will address the next step of data analysis in considerably greater detail.
Acknowledgements
Our thanks to Dr Lorna Aucott and Katie Wilde, University of Aberdeen, Professor Trevor Gibbs and the reviewers for their helpful comments on the manuscript. We also thank Professor Trevor Gibbs for his support in bringing this Guide to fruition.
Declaration of interest: The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the paper.
References
- Altman DG. Practical statistics for medical research. Chapman & Hall, London 1991
- American Educational Research Association. Code of ethics, american educational research association and Australian council for educational research. Educ Res 2011; 40: 145–156
- Bland M. An introduction to medical statistics. Oxford University Press, Oxford 2000
- Bourdieu P. Language and symbolic power. Harvard University Press, Boston 1991
- Bowling A. Research methods in health. Open University Press, Buckingham 1997
- Brice J, Bligh J, Bordage G, Colliver J, Cook D, Eva KW, Harden R, Kanter SL, Norman GR. Publishing ethics in medical education journals. Acad Med 2009; 84: S132–S134
- Bryman A. The debate about quantitative and qualitative research: A question of method or epistemology?. Brit J Sociol 1984; 35: 75–92
- Carroll K, Iedema R, Kerridge R. Reshaping ICU ward round practices using video-reflexive ethnography. Qual Health Res 2008; 18: 380–390
- Cleland JA, Milne A, Sinclair HK, Lee AJ. Predicting performance cohort study: Is performance on early MBChB assessments predictive of later undergraduate grades?. Med Educ 2008a; 42: 676–683
- Cleland JA, Knight L, Rees C, Tracey S, Bond CB. ‘Is it me or is it them?’ Factors influencing assessors’ failure to report underperformance in medical students. Med Educ 2008b; 42: 800–809
- Cook D. Randomized controlled trials and meta-analysis in medical education: What role do they play?. Med Teach 2012; 34: 468–447
- Denzin NR, Lincolm YS. The SAGE handbook of qualitative research4th. Sage, Thousand Oaks, CA 2001
- Egan-Lee E, Frietag S, LeBlanc V, Baker L, Reeves S. Twelve tips for ethical approval for research in health professions education. Med Teach 2011; 33: 268–272
- Eikelboom JI, ten Cate OTJ, Jaarsma D, Raat JAN, Schuwirth L, van Delden JM. A framework for the ethics review of education research. Med Educ 2012; 46: 728–737
- Eva K. Research ethics requirements for medical education. Med Educ 2009; 43: 194–195
- Fielding N, Lee R. Using computers in qualitative research. Sage, London 1991
- Firestone WA. Meaning in method: The rhetoric of quantitative and qualitative research. Educ Res 1987; 16: 16–21
- Gage NL. The paradigm wars and their aftermath. Educ Res 1989; 18: 4–10
- Guba EG. Towards a methodology of naturalistic inquiry in educational evaluation. Centre for the Study of Evaluation, Los Angeles, CA 1978
- Kanter S. Ethical approval for studies involving human participants: Academic Medicine's new policy. Acad Med 2009; 84: 149–150
- Kuhn TS. The structure of scientific revolutions2nd. University of Chicago Press, Chicago 1970
- McLachlan JC, McHarg J. Ethical permission for the publication of routinely collected data. Med Educ 2005; 39: 944–948
- Miles MB, Huberman AM. Qualitative data analysis: An expanded sourcebook. Sage, London 1994
- Moffat M, Cleland J, van der Molen T, Price D. Poor communication may impair optimal asthma care: A qualitative study. Fam Pract 2007; 24: 65–70.
- Morrison J, Prideaux D. Ethics approval for research in medical education. Med Educ 2001; 35: 1008
- Norman GR, Streiner DL. Biostatistics – The bare essentials2nd. BC Decker, Hamilton 2000
- Patricio M, Vaz Carneiro A. Systematic reviews of evidence in medical education (BEME Reviews) and clinical medicine (Cochrane Reviews): Is the nature of evidence similar?. Med Teach 2012; 34: 474–482
- Petrie A, Sabin C. Medical statistics at a glance2nd. Blackwell Publishing, Malden, MA 2005
- Pugsley L, Dornan T. Using a sledgehammer to crack a nut: Clinical ethics review and medical education research projects. Med Educ 2007; 41: 726–728
- Ringsted C, Hodges B, Scherpier A. AMEE Guide 56 research in medical education. ‘The research compass’: An introduction to research in medical education. AMEE. Med Teach 2011; 33: 695–709
- Ryan GW, Bernard HR. ‘Techniques to identify themes. Field Methods 2003; 15(1)85–109
- Silver C, Fielding N. Using computer packages in qualitative research. The Sage handbook of qualitative research in psychology, C Willig, W Stainton-Rogers. Sage Publications, London 2008; 334–351
- Silver C, Patashnick P, 2011. ‘Finding fidelity: Advancing audiovisual analysis using software’. The KWALON Experiment: Discussions on Qualitative Data Analysis Software by Developers and Users, FQS, Vol 12, No 1. pp. 334–351
- Strauss A, Corbin J. Basics of qualitative research. Grounded theory procedures and techniques2nd. Sage, Newbury Park, CA 1998
- ten Cate O. Why the ethics of medical education differ from those of medical research. Med Educ 2009; 43: 608–610
- Todres M, Tsimtsiou Z, Sidhu K, Stephenson A, Jones R. Medical students’ perceptions of the factors influencing their academic performance: An exploratory interview study with high-achieving and re-sitting medical students. Med Teach 2012; 34: e325–e331