

ABSTRACT
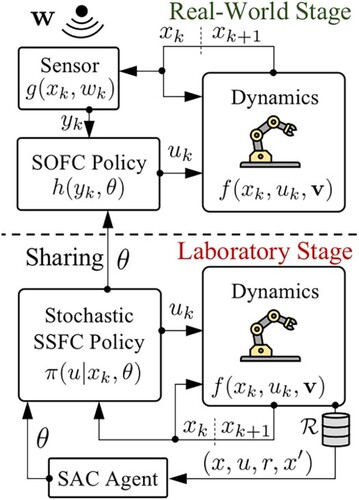
The state-of-the-art deep reinforcement learning (DRL) methods, including Deep Deterministic Policy Gradient (DDPG), Twin Delayed DDPG (TD3), Proximal Policy Optimization (PPO), Soft Actor-Critic (SAC), among others, demonstrate significant capability in solving the optimal static state feedback control (SSFC) problem. This problem can be modeled as a fully observed Markov decision process (MDP). However, the optimal static output feedback control (SOFC) problem with measurement noise is a typical partially observable MDP (POMDP), which is difficult to solve, especially for the continuous state-action-observation space with high dimensions. This paper proposes a two-stage framework to address this challenge. In the laboratory stage, both the states and the noisy outputs are observable; the SOFC policy is converted to a constrained stochastic SSFC policy, of which the probability density function is generally not analytical. To this end, a density estimation based SAC algorithm is proposed to explore the optimal SOFC policy by learning the optimal constrained stochastic SSFC. Consequently, in the real-world stage, only the noisy outputs and the learned SOFC policy are required to solve the optimal SOFC problem. Numerical simulations and the corresponding experiments with robotic arms are provided to illustrate the effectiveness of our method. The code is available at https://github.com/RanKyoto/DE-SAC.
GRAPHICAL ABSTRACT
Disclosure statement
No potential conflict of interest was reported by theauthor(s).
Notes
2 dlqe and dlqr
are the solvers of a linear-quadratic state estimator (LQE) and a linear-quadratic regulator (LQR) for discrete-time linear control systems, respectively. They can be found in Matlab or Python Control Systems Library.
Additional information
Funding
Notes on contributors
Ran Wang
Ran Wang received the B.E. degree in Automation and the M.E. degree in Control Theory and Control Engineering from Dalian University of Technology, Dalian, China, in 2016 and 2019, respectively. He is currently pursuing the Ph.D. degree with Kyoto University, Kyoto, Japan. His research interests include reinforcement learning and self-triggered control.
Ye Tian
Ye Tian received his B.S. degree in applied mathematics from Ningxia University, Yinchuan, China, in 2014, and the Ph.D. degree in control theory and control engineering from Xidian University, Xi'an, China, in 2021. From 2017 to 2019, he was a visiting student at the Center for Control, Dynamical-systems and Computation, University of California, Santa Barbara, CA, USA. He is currently a Postdoctoral Fellow with the Graduate School of Informatics, Kyoto University, Kyoto, Japan. His research interests include multi-agent systems, game theory, and social networks.
Kenji Kashima
Kenji Kashima received his Doctoral degree in Informatics from Kyoto University in 2005. He was with Tokyo Institute of Technology, Universität Stuttgart, Osaka University, before he joined Kyoto University in 2013, where he is currently an Associate Professor. His research interests include control and learning theory for complex (large scale, stochastic, networked) dynamical systems, as well as its interdisciplinary applications. He received Humboldt Research Fellowship (Germany), IEEE CSS Roberto Tempo Best CDC Paper Award, Pioneer Award of SICE Control Division, and so on. He is an Associate Editor of IEEE Transactions of Automatic Control ( 2017–), the IEEE CSS Conference Editorial Board ( 2011–) and Asian Journal of Control ( 2014–).