
Abstract
The inter-rater reliability of university students’ evaluations of teaching quality was examined with cross-classified multilevel models. Students (N = 480) evaluated lectures and seminars over three years with a standardised evaluation questionnaire, yielding 4224 data points. The total variance of these student evaluations was separated into the variance components of courses, teachers, students and the student/teacher interaction. The substantial variance components of teachers and courses suggest reliability. However, a similar proportion of variance was due to students, and the interaction of students and teachers was the strongest source of variance. Students’ individual perceptions of teaching and the fit of these perceptions with the particular teacher greatly influence their evaluations. This casts some doubt on the validity of student evaluations as indicators of teaching quality and suggests that aggregated evaluation scores should be used with caution.
Teaching quality is an important criterion to assess in higher education, for example, to identify improvement needs or to justify tuition costs. Students and their parents demand high-quality teaching, and teachers and department heads need good measures of teaching quality. Its importance begs the question of whether current teaching assessments provide reliable data on teaching effectiveness. This study examines the ratings of students on the quality of single courses, also referred to as teaching effectiveness (e.g. Gillmore, Kane, and Naccarato Citation1978; Marsh Citation1984, Citation2007). The construct of teaching effectiveness comprises several facets of good teaching, including how teachers perform in communicating with students, organising a course and its contents, stimulating interest, and behaving in a friendly and tolerant fashion (Hattie and Marsh Citation1996).
Teaching quality can be measured in different ways and by tapping different sources. The most common way to measure teaching quality in higher education is through student evaluations of teachers (e.g. Marsh Citation1984; Spooren Citation2010; Rantanen Citation2013). In most cases, student evaluations of teaching quality are obtained via evaluation questionnaires (e.g. Student Evaluation of Educational Quality, Marsh Citation1982; Marsh et al. Citation2009; Student Course Experience Questionaire; Ginns, Prosser, and Barrie Citation2007; FEVOR/FESEM (Fragebogen zur Evaluation von universitären Lehrveranstaltungen durch Studierende [Students Course Assessment Questionnaire for Evaluation of University Courses]), Staufenbiel Citation2000). All of these questionnaires mirror the multidimensionality of teaching quality by differentiated scales.
This study focuses on the inter-rater reliability of student’s evaluations of teaching quality (e.g. Marsh Citation1984, 2007; Rantanen Citation2013). Reliability is a fundamental criterion of student evaluations of teaching and a necessary (though not sufficient) precondition for their validity as indicators of teaching quality. The most common measure of inter-rater reliability for interval-scaled ratings is the intra-class correlation (ICC; Shrout and Fleiss Citation1979). The ICC for teaching evaluations is defined as the correlation between assessments of randomly determined pairs of students evaluating the same course or teacher. It may also be regarded as the proportion of the total variance of student evaluations that can be explained by courses and teachers. In terms of Kenny’s (Citation1994) social relations modelling, the variance components of courses and teachers can be seen as target variance, that is, the degree to which different perceivers (students) rate the target (the course or the teacher) in the same way. Reliability is maximised by maximising the proportion of target variance.
Marsh (Citation1982) and Rindermann and Schofield (Citation2001) addressed the issue of inter-rater reliability by comparing different combinations of teachers and courses. For example, they compared one teacher giving several courses with one course taught by different teachers. An evaluation questionnaire was deemed as more reliable (and also more valid) when there was a higher effect of teachers in parallel courses with the same content compared to courses covering different content. They inferred from correlational analyses that teachers have a high impact on teaching evaluations. Gillmore, Kane, and Naccarato (Citation1978) estimated variance components via an analysis of variance with random factors. They found that the variance explained by courses (6%) was much smaller than that explained by teachers (40%). Moreover, they found a substantial effect of the interaction of teachers and courses. In most studies, the ICC for student evaluations of courses or teachers is about .20 (e.g. Marsh Citation1984; Solomon et al. Citation1997). An ICC in this order of magnitude indicates a modest reliability of individual evaluations but corresponds to an acceptable or even high reliability when means of evaluations from a considerable number of students are considered (e.g. .90 for 25 students Marsh and Roche Citation1997).
The reviewed studies did not examine the influence of students on course evaluations and compare this influence with those of teachers or courses. The modern analytical approach of multilevel analysis (linear mixed models) can address this question in a straightforward way (Raudenbush and Bryk Citation2006; Richter Citation2006). Multilevel analyses can account for the multilevel structure of evaluation data. Typically, students evaluate several courses and teachers, teachers teach several courses, and the same courses are taught by different teachers, yielding an imperfect hierarchy or cross-classified data structure. Such data structures call for models with crossed random effects (Baayen, Davidson, and Bates Citation2008), also known as cross-classified or non-hierarchical multilevel models (Rasbash and Browne Citation2008). These models estimate the effect sizes of teachers, courses and students, and also their interactions, provided that a sufficient number of different combinations of units from different levels are obtained. From the estimates of the variance components, the ICCs (variance proportions) can be calculated for student evaluations of courses or teachers and for all other sources of variance included in the model (such as students or interactions of students and teachers).
Several authors (Spooren Citation2010; Rantanen Citation2013; Staufenbiel, Seppelfricke, and Rickers Citation2016) have already adopted the approach of estimating hierarchical or cross-classified multilevel analyses. Despite methodological differences (such as different questionnaires used), these studies yielded estimates of variance components for students, courses and teachers of similar magnitude. They found nearly one quarter at the student level and one quarter at the teacher and course level, whereas about 50% of the variance remained unexplained. More details are available in Figure .
Figure 1. Estimates of variance components estimated in previous studies. The study by Rantanen (Citation2013) included the interaction of teachers and courses. The study by Spooren (Citation2010) did not distinguish between teachers and courses as sources of variance.
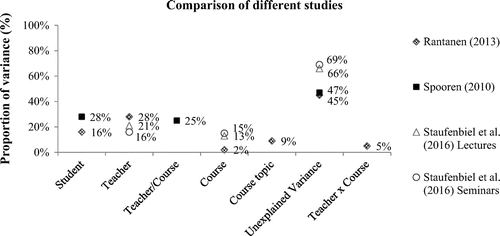
All the previous studies focused on only one dependent variable. Staufenbiel, Seppelfricke, and Rickers (Citation2016) used an average score of three scales capturing three different facets of teaching effectiveness (planning and presentation, interaction with students, and interestingness and relevance). Rantanen (Citation2013) used a mean score based on five items (teacher’s expertise in the subject, teaching skills, visual aids, interaction with the students and learning assignments). Spooren (Citation2010) calculated a rescaled global factor of seven factors (e.g. clarity of course objectives and value of subject-matter). Yet, to our knowledge, no study decomposing the total variance of student evaluations in its different components (teachers, courses and students) has taken multiple dimensions of teaching effectiveness into account.
Rationale of the present study
The present study was based on a psychometrically sound questionnaire that is used in German-speaking countries for student evaluations of teaching in higher education (Staufenbiel Citation2000; Staufenbiel, Seppelfricke, and Rickers Citation2016). The questionnaire assesses four different aspects of teaching quality (planning and presentation, interaction with students, interestingness and relevance, difficulty and complexity), and contains two global ratings of the quality of the entire course and the teacher. We analysed the data using a cross-classified multilevel analysis (mixed models with crossed random effects: Baayen, Davidson, and Bates Citation2008), including random effects of all three possible sources of variance: teachers, courses and students. Moreover, we ran separate analyses for lectures and seminars because of the didactical and organisational differences of the two course formats (cf. Staufenbiel, Seppelfricke, and Rickers Citation2016). Our aim was to provide an in-depth analysis of the inter-rater reliability of the different scales and the global ratings included in the questionnaire by Staufenbiel (Citation2000), and to compare the variance components that contribute to a high reliability (teachers and courses) with variance components that are due to students and the interaction of students and teachers.
This analysis tackled three novel research questions. First, we examined whether the variance components of teachers, courses and students would differ systematically between different aspects of teaching quality. Conceptually, the evaluations regarding planning and presentation of the course contents might be influenced more strongly by teacher behaviour than evaluations regarding the aspects of interaction with students, interestingness and relevance, and difficulty and complexity. For the assessment of the latter three aspects, students’ behaviour, interests and abilities are also likely to play a major role. For example, a student with strong prior knowledge might find the same course easier than a student with weak prior knowledge. Likewise, students might find courses interesting and relevant that match their personal interests, which can differ between students. Second, we investigated potential differences in the variance components in models for lectures and seminars. Lectures are a much more teacher-centred course format than seminars, which include active contributions from students in the form of class-room presentations and discussions, implying that teachers should be a stronger source of variance in lectures. Third, we extended previous multilevel studies by including the interaction of students and teachers as an additional random effect in the model. By including this interaction, we were able to account for the possibility that student evaluations of teaching might depend systematically on whether student characteristics (such as their expectations, abilities and interests) match characteristics of the teacher giving the course (such as their expectations, teaching styles or level of difficulty). Our expectation was that including this interaction, as another source of systematic variance in the model, would considerably reduce the large amount of unexplained variance found in previous studies (typically around 50%).
Method
Sample
The present study used a data-set of 4224 evaluations (questionnaire data) of psychology courses held between the winter semester 2011 and the summer semester 2014 at the University of Kassel, Germany. During this period, courses were taught by 53 different teachers (30 women). Sixty lectures were given by 18 different teachers and 115 seminars were held by 49 different teachers. Of the 53 teachers, 19 teachers (36%) were professors on the associate/full professor level (tenured or visiting), 13 (24%) were assistant professors or post-doctoral lecturers and 21 (40%) were doctoral students holding a position as researcher or lecturer. The evaluations were provided by 480 students (73% women) who attended the courses. The students remained anonymous but evaluations provided by the same student could be identified by an individual code. On average, each student evaluated seven courses (lectures: Median = 4, Range = 1–18, seminars: Median = 4, Range = 1–17). The sample of courses comprised courses on research methods such as statistics, and content courses like educational, cognitive, social or clinical psychology. Of all courses, 145 (83%) were bachelor-level courses (BSc programme in Psychology) and 30 (17%) were master-level courses (MSc programmes in Psychology).
Procedure
The questionnaires were administered in the last third of each semester (in the second half of January in winter semesters and the second half of June in summer semesters). The teachers handed out the questionnaires. The students were given 5–10 min to complete the questionnaires. Data were scanned with the programme Remark Office OMR 8. Accuracy of data scanning was controlled by a student research assistant. Each teacher received elaborated reports for their courses to discuss with the students in the last session of the semester.
Measures
The study was based on a standardised questionnaire that is widely used in Germany for the evaluation of university courses (FEVOR/FESEM, Staufenbiel Citation2000; Staufenbiel, Seppelfricke, and Rickers Citation2016). There are different versions of the questionnaire for different course types. The version for lectures contains 31 items and the version for seminars 34 items. Apart from 26 parallel items, eight seminar items on discussions and presentations held by students and four lecture items on the presentation style were included. In the header of the questionnaire, students provided an individual alphanumerical code that allowed assigning different questionnaires to one student while protecting students’ anonymity. The questionnaire assesses students’ evaluations of university courses on three psychometrically distinct unipolar scales that are based on Likert-scaled items (ranging from 1 = strongly agree to 5 = strongly disagree, and ‘not applicable’ as an additional response option). On the bipolar difficulty and complexity scale the response options range from 1 = much too low to 5 = much too high.
Planning and presentation
The scale assesses the extent to which students perceive a course to be well prepared and structured, and the extent to which the contents are presented in a meaningful way. It contains items such as ‘The seminar provides a good overview of the subject area’ and ‘The lecture is clearly structured’. The scale consists of eight items in the version for seminars (M = 4.13, SD = .63, Cronbach’s α = .78) and five items in the version for lectures (M = 4.13, SD = .70, Cronbach’s α = .90).
Interaction with students
This scale assesses the perceived respect and concern that teachers show to their students. It contains items such as ‘There is a good working climate in the seminar’ and ‘The lecturer seems to care about the students’ learning success’. The scale consists of four items in the version for seminars (M = 4.35, SD = .63, Cronbach’s α = .79) and three items in the version for lectures (M = 4.38, SD = .66, Cronbach’s α = .77).
Interestingness and relevance
This scale measures how useful students perceive the contents of the course for other contexts and how interesting they find the content. The scale consists of items such as ‘The lecturer encourages my interest in the subject area’ and ‘The lecturer makes the lecture interesting’. The scale consists of four items in the version for seminars (M = 3.94, SD = .76, Cronbach’s α = .85) and lectures (M = 4.03, SD = .73, Cronbach’s α = .80).
Difficulty and complexity
This scale measures the perceived difficulty, scope and pace of the course. The scale consists of items such as ‘The pace of the seminar is …’; M = 3.17, SD = .42, Cronbach’s α = .74 for seminars and M = 3.29, SD = .51, Cronbach’s α = .77 for lectures.
Ratings of teacher and course
Respondents also rated the teacher’s overall performance and the quality of the course on a general level. Ratings were provided according to the German grading system that ranges from 1 = very good to 5 = poor (teachers: M = 1.88, SD = .82 for seminars, M = 1.81, SD = .80 for lectures; course: M = 2.11, SD = .79 for seminars; M = 2.06, SD = .76 for lectures).
Results
Analyses were performed with cross-classified linear mixed-effects models (Baayen, Davidson, and Bates Citation2008) that allowed separation of the variance components of teachers, courses and students. These three sources of variances were included as random effects in the analysis. Separate models were estimated for the four scales and the two overall ratings of the evaluation questionnaire by Staufenbiel (Citation2000). The models were estimated with the statistical software R Version 3.2.2 (R Core Team Citation2015) and the full maximum likelihood estimation procedure built-in the function lmer of the R-package lme4 (Bates et al. Citation2015). The significance of each random effect was tested with the function called ANOVA of the R-package stats that compares the fit of models that differ in their random effects structure (R Core Team Citation2015). Data were analysed separately for lectures and seminars because of the heterogeneous course format and the differences in course sizes.
Based on the random effects models, ICCs were computed that reflect the proportions of variance due to students, teachers and courses. The ICCs for teachers and courses may be interpreted as measures of inter-rater reliability (absolute agreement between students) of the evaluations of teachers and courses. For example, the proportion of variance due to teachers reflects how reliably students were able to assess teachers with regard to a certain criterion (e.g. an overall rating or score on one of the four evaluation scales):(1)
High values of ICC (i.e. values close to 1) indicate that students strongly agreed in their assessments of the teachers and that different courses given by the same teacher were judged similarly. Low values of this ICC (i.e. values close to 0) indicate that students, classes or both differed in their evaluations, implying that the evaluations are not reliable assessments of teachers.
Figure illustrates the structure of the cross-classified multilevel models. The first model (Model 1) included for all four scales and two ratings random effects (random intercepts) of students and courses:(2)
Figure 2. Random effects included in the three models estimated for student evaluations of teaching.
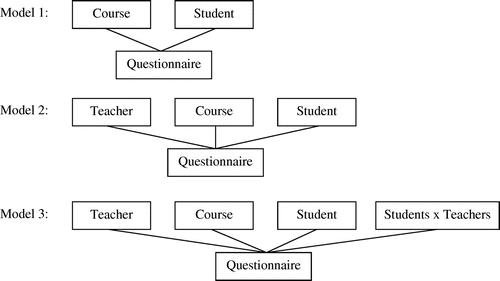
In this model, Ysc represents the evaluation score of student s in courses c. The intercept θ0 represents the grand mean of this score across all students and courses. The term h0s captures the individual deviation of student s from θ0, that is, the contribution of this student across all courses. Likewise, i0c represents the deviation of course c, that is, its contribution across all students. The individual deviations of students and courses are conceptualised as random effects that follow a normal distribution with a mean of 0 and the variances τs0 and τc0. Finally, the model includes the error term esc that captures unsystematic errors in the evaluation scores that remain after the random effects of students and courses have been taken into account. These unsystematic errors are also assumed to be normally distributed with mean 0 and variance σ² (Raudenbush and Bryk Citation2006).
Model 1 allows estimating the inter-rater reliability for course evaluations by separating the systematic variance due to courses from the systematic variance due to students (e.g. Spooren Citation2010), plus a component of unsystematic error variance. However, courses are confounded with teachers, who may be regarded as a separate source of variance. Thus, we estimated a second model (Model 2) that disentangles the contributions of teachers and courses to the total variance. This model included random effects (random intercepts) of students, teachers and courses.(3)
In addition to the effects contained in Model 1, this model includes the term j00t that represents the deviation of teacher t from the grand mean, that is, his or her contribution to the evaluations across all courses and students taught by this teacher. Again, the effects of teachers are assumed to be random effects that are normally distributed with mean 0 and variances τs00, τc00, and τt00.
Finally, differences in course evaluations might depend systematically on who evaluates whom, that is, on an interaction of students and teachers. Therefore, we estimated a third model (Model 3) that included another random effect reflecting the interaction of students and teachers:(4)
In this model, k00st represents the random deviations of specific student–teacher combinations st from the grand mean; all other terms are the same as in Model 2 (Equation (3)). The variance of these deviations, assumed to be normally distributed with a mean 0 and variances τs00, τc00, τt00, and τst0, captures the variance due to the two-way interaction effect of students and teachers.
In principle, including interactions of students and courses or interactions of courses and teachers would also be possible. However, such interactions could not be estimated with the present data-set, because the frequencies of different student–course combinations and teacher–course combinations were too small. For example, there was mostly only one evaluation per course and student.
Tables 1-3 display the variance components, variance proportions, and model fit for the models estimated for seminars and lectures. In Tables and display the four scales, and Table displays the overall ratings of course and teacher.
Table 1. Estimates for the cross-classified linear mixed effect models (random intercepts) for the scales planning and presentation and interactions with students.
Table 2. Estimates for the cross-classified linear mixed effect models (random intercepts) for the scales interestingness and relevance and difficulty and complexity.
Table 3. Estimates for the cross-classified linear mixed effect models for the global ratings of courses and teachers.
Planning and presentation
The estimates for Models 1–3 with the scale planning and presentation as criterion variable are displayed in Table (upper half). For this scale, the proportion of variance due to courses, 22% for seminars and 33% for lectures, estimated in Model 1 nearly equalled the sum of the variance components of teachers and courses in Model 2. Thus, taking the confounding of teachers and courses into account did not reduce the unexplained variance. It also did not change the proportion of variance due to students, which was 15% in seminars and 21% in lectures. The proportion of variance explained by teachers was 27% in lectures but only 6% in seminars (Model 2), reflecting the different role of teachers in seminars and lectures. Model 3, which additionally included the interaction of students and teachers, strongly increased variance explained. The proportion of variance explained by this interaction was 20% in seminars and 29% in lectures (Model 3). Thus, the fit of the individual students with the individual teachers determined the student’s evaluations on this scale to a considerable extent. Overall, we obtained a large proportion of variance due to students and a large proportion of variance that remained unexplained in evaluations of seminars. These problems were less aggravated in the evaluation of lectures, with only 23% unexplained variance and a relatively low proportion of variance due to students (15%).
Interaction with students
The estimates for the models with the scale interaction with students as criterion variable are displayed in Table (lower half). Generally, the results for this scale are similar to the results for planning and presentation. Model 1 revealed a considerable proportion of variance due to students (17% for seminars and 18% for lectures) but a much higher proportion of variance due to courses (35% for seminars and 27% for lectures). Model 2 decomposed the latter variance component further in similarly large proportions due to courses and teachers. Including the interaction of students and teachers in Model 3 provided a large increment in variance explained (26% in seminars and 32% in lectures), reducing the proportion of unexplained variance to only 24% in seminars and 27% in lectures.
Interestingness and relevance
The estimates for the models with the scale interestingness and relevance as criterion variable are displayed in Table (upper half). For seminars, Model 1 revealed a considerable proportion of variance due to students (17%) and a much higher proportion of variance due to courses (31%). For lectures, there was also a considerable proportion of variance due to students, which was of a similar magnitude to the variance due to courses (20%). Including the interaction of students and teachers in Model 3 led to a considerable increase of variance explained (18% in seminars and 26% in lectures). Nevertheless, relatively large proportions of variance remained unexplained even in Model 3 (35% in seminars and 37% in lectures).
Difficulty and complexity
The estimates for the models with the scale difficulty and complexity as criterion variable are displayed in Table (lower half). Similar to the scales planning and presentation and interactions with students, Model 1 revealed a considerable proportion of variance due to students (15% for seminars and 20% for lectures) but a higher proportion of variance due to courses (26% for seminars and 29% for lectures). However, the decomposition of this variance component in Model 2 suggests that the variance explained by teachers (17% for seminars and 19% for lectures) was higher than the variance explained by courses (8 and 11%). Compared to the other three scales, including the interaction of students and teachers in Model 3 led to a relatively small increase of variance explained (8% in seminars and 13% in lectures). Consequently, relatively large proportions of variance remained unexplained even in Model 3 (54% in seminars and 38% in lectures).
Overall rating of course
Table (upper half) provides the estimates for the models with the overall rating of course quality as criterion variable. Model 1 showed that the proportion of variance due to students (11% for seminars and 16% for lectures) was substantial but still markedly smaller than the proportion of variance due to courses (33% for seminars and 27% for lectures). Despite course quality being the focus of this rating, Model 2 suggests that teachers were a similarly strong source of variance (10% in seminars and 9% in lectures) as were courses (14% in seminars and 7% in lectures). Finally, Model 3 revealed a strong increment of the interaction of students and teachers (17% variance explained in seminars and 25% in lectures). Nevertheless, even in Model 3 large proportions of variance remained unexplained (48% in seminars and 45% in lectures).
Overall rating of teacher
Table (lower half) provides the estimates for the models with the overall rating of teacher performance as criterion variable. The results resemble those obtained for the overall rating of the course (which is not surprising given the strong correlation of the two ratings: see Table ). In Model 1, students were a significant source of variance (11% for seminars and 12% for lectures). However, their contribution was much smaller than the proportion of variance due to courses (33% for seminars and 27% for lectures). Despite teacher performance being the focus of this rating, Model 2 suggests that courses were a similarly strong source of variance (16% in seminars and 14% in lectures) as teachers (17% in seminars and 14% in lectures). Thus, students were influenced by (teacher-independent) characteristics of the courses when rating teacher performance. Finally, Model 3 revealed a particularly strong increment of the interaction of students and teachers (24% variance explained in seminars and 32% in lectures). Thus, similar to most of the other evaluation measures, the fit of students and teachers had a strong and systematic effect on the overall rating of the teacher. In Model 3, about one-third of the overall ratings variance remained unexplained (33% in seminars and 32% in lectures).
Table 4. Correlations between criterion variables for seminars and lectures.
Discussion
The present study examined the reliability of student evaluations of teaching quality. Our results showed that teachers and courses were essential sources of variance for all four facets of teaching quality examined in this study and also for the overall ratings of courses and teachers. A considerable proportion of variance, mostly around one-fifth of the total variance in these measures, was also explained by students. However, in five of the six measures, the proportions of variance explained by teachers and courses together was nearly twice the proportion of variance explained by students. Dissociating the confound of teachers and courses did not reduce the unexplained variance but offered a more detailed picture by showing that both courses and teachers have an impact on how students evaluate teaching quality. Not surprisingly, the effects of teachers were larger in lectures compared to seminars. The most striking result was the finding that the interaction of students and teachers introduced in Model 3 was the strongest source of variance in most of the models. Including this interaction substantially reduced the unexplained variance.
The proportion of variance which is due to courses and teachers may, in principle, be interpreted as inter-rater reliability. This proportion ranged between 16 and 35% (median = 27%) in our study and was in most cases above the normative cut-off value offered by Marsh and Roche (Citation1997) for single assessments. This finding is in line with those of other studies (Spooren Citation2010; Rantanen Citation2013; Staufenbiel, Seppelfricke, and Rickers Citation2016). However, to achieve an acceptable reliability that can serve as the basis for reasonable and fair instructional and administrational decisions, average ratings based on the evaluations of several students must be used instead of individual ratings. These individual ratings differ considerably, are affected by individual student characteristics and are therefore subject to a huge measurement error. The required number of evaluations can be estimated by the Spearman–Brown Formula (Brown Citation1910; Spearman Citation1910). Given the average inter-rater reliability of 27% found in this study, one would need a sample of 24 students to evaluate a course to achieve an inter-rater reliability of 90%. This number is comparable to the 25 students that Marsh and Roche (Citation1997) suggested for courses with a single-rater reliability of 20%. In sum, teaching quality can be assessed reliably by student evaluations, provided that average evaluations are used that are based on a sufficient sample size.
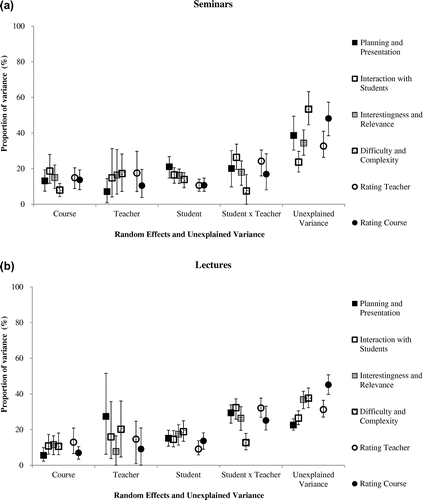
Our data, however, also suggest four important qualifications and differentiations of this optimistic conclusion. First, the variance component of courses and teachers and the amount of measurement error vary considerably between different scales, and also between lectures and seminars (as illustrated in Figure ). For example, student evaluations of the difficulty and complexity, but also the planning and presentation, in seminars seem to be particularly unreliable, whereas the same evaluations with regard to lectures achieve a better inter-rater reliability. Overall, student evaluations of teaching quality seem to be more reliable in lectures than in seminars. This makes sense in so far as the instructional design of lectures (one teacher, teacher-centred instruction, and little variation in teaching methods) presumably yields a higher stability of teaching quality throughout the semester than is the case with seminars, in which student presentations of varying quality alternate with other forms of instruction. In contrast to the discrepancies between lectures and seminars, the discrepancies between different scales are more difficult to interpret. At this point, a replication of these differences seems to be required before any attempt at a substantial interpretation is made. Nevertheless, it is important to note that these discrepancies exist, and that researchers and practitioners using student evaluations are aware that their reliability might depend on the exact content of the evaluations.
Figure 3. Proportions of variance explained by course, teacher, student, the students × teachers interaction and unexplained variance for the four scales of the evaluation questionnaire by Staufenbiel (Citation2000) and the two overall ratings for seminars (a) and lectures (b). Error bars represent 95% confidence intervals.
Second, this study aimed at dissociating the variance components of teachers and courses, which were confounded in previous studies. The separation of both sources of variance sources allowed a more detailed picture of student evaluations. For example, the results show that, in lectures with their teacher-centred format of instruction, the relative effect of teachers compared to courses was stronger than in seminars. Overall, course characteristics were a major source of variance apart from the teacher. These findings have important implications for practical applications of student evaluations of teaching. Factors affecting the variance component of teachers can often be controlled by the teacher, with the exception of teachers’ personality characteristics (e.g. Clayson and Sheffet Citation2006) or possible bias variables such as gender or attractiveness (Campbell, Gerdes, and Steiner Citation2005; Basow, Codos, and Martin Citation2013; Wolbring and Riordan Citation2016). Factors that can be influenced include those central for teaching quality, such as teaching style, teaching method or the way that discussions in class are organised. In contrast, this is often not the case with factors that contribute to the variance component of courses. For example, teachers often have little influence on environmental conditions such as room size, room location, the topic of the course, the required workload and the number of students and their composition in a course. These factors are likely to affect student evaluations but are not (or only indirectly) related to teaching quality.
Third, the large proportion of systematic variance in the evaluations (between 11 and 21%) due to students was remarkable. The variance component of students was only slightly lower than the average proportions of variance explained by courses and teachers (27%). This finding has implications that go beyond reliability and touch upon the construct validity of student evaluations. Apparently, the systematic influences of student characteristics were almost as strong as the effects of course or teacher characteristics, suggesting that student evaluations cannot be regarded as pure measures of teaching quality, but also capture (hitherto largely unknown) student characteristics to a considerable degree. Possibly, for example, students’ personality traits (Patrick Citation2011), their competence level (Spooren Citation2010) or general response biases (Dommeyer, Baum, and Hanna Citation2002; Sax, Gilmartin, and Bryant Citation2003) systematically affect their evaluations of teaching quality. Future research should clarify the extent to that the variance component of students can be explained further by these different types of student characteristics.
Fourth, the total variance explained improved markedly by including the interaction of students and teachers in the model. The proportion of variance explained by this interaction ranged between 8 and 32% (for similar results obtained with factor analyses, see Leamon and Fields Citation2005). Thus, the interaction was in the same order of magnitude as the variance components (i.e. main effects) of teachers and courses together. This finding has important implications for the interpretation of student evaluations of teaching. Apparently, different students evaluate the same teachers’ performance in a (systematically) different way. Some students evaluate particular teachers consistently positively, whereas other students evaluate the same teachers consistently negatively. Thus, how a student evaluates teaching quality seems to depend to a large extent on the fit of an individual student with individual teachers. The common practice of averaging across evaluations to derive one score that describes the teacher essentially neglects the student–teacher interaction, and can therefore be misleading to some degree.
Our results provide an initial contribution to learning more about what exactly affects the degree of fit between students and teachers that leads to more positive or negative evaluations. Future research could examine this topic in different ways. According to Kenny (Citation1994), heterogeneity in student assessments can be due to three factors: (1) different information is used for the assessment, (2) students refer to the same behaviours in their evaluation but interpret them differently (3) or different kinds of non-behavioural information are used such as sympathy for their assessment. All three factors could play a role in the student–teacher interaction, but the effects of these factors could not be analysed in our data. Future multilevel studies should include potentially relevant teacher and student characteristics, and their interactions as fixed effects, to elucidate the factors that determine the fit of students and teachers that lead to more positive student evaluations of teaching. Another approach would be to examine whether the interaction itself is moderated by the expertise of the teacher (e.g. Tigelaar et al. Citation2004). Expert teachers might be better able to adapt their teaching style to special characteristics of the students such as prior knowledge (e.g. Thompson and Zamboanga Citation2003). This could result in a generally more positive evaluation by all students.
Despite its informative results, this study suffers from a number of limitations. One limitation is that the study was based on data from university courses in just one academic subject (psychology) at one particular university in Germany in a limited number of student cohorts. Although we included students, teachers and courses as random effects in our models to account for their being drawn from larger populations, the extent that the results can be generalised is unclear. This problem is complicated by the students voluntarily taking part in the evaluations, and only students who were present in the course when the evaluation was conducted could take part in the study. In other words, this study was based on a convenience sample (a weakness, though, that is shared by virtually all studies in the field). Nevertheless, the variance components estimated in this study lie in a range that is comparable to other studies (e.g. Spooren Citation2010; Rantanen Citation2013; Staufenbiel, Seppelfricke, and Rickers Citation2016), which provides some confidence that our results can be generalised to some extent. Cross-validations of the results, in particular of the novel finding of a strong interaction of students and teachers, with different subjects, universities and university systems would be very useful. Given the important practical implications of the variance components approach, these additional analyses would certainly be worthwhile.
In sum, our results suggest that student evaluations of teaching can be reliable assessments of the course and the teacher when aggregated evaluations based on a sufficient number of students are used (Marsh and Roche Citation1997). However, the inter-rater reliability of student evaluations of teaching varies between different measures and course types (seminar and lecture). Moreover, these evaluations depend to a large extent on the students that provide the evaluations, implying that student characteristics can affect the evaluations and biases can occur through selection effects. These effects need to be taken into account when student evaluations of teaching are collected in university courses. It may also be regarded as a general problem for the validity of these evaluations, because data are almost as informative with regard to the students that provide the evaluations as they are with regard to the courses or teachers that are the actual focus of the evaluations. Finally, the large interaction effect of teachers and students that fundamentally reduced the amount of unexplained variance advances the findings from previous studies. This finding suggests that the fit of the individual students with their teachers plays an important role for student evaluations of teaching, a phenomenon of high practical relevance that requires clarification in future research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes on contributors
Daniela Feistauer is a research associate at the University of Kassel. Her research interests are quality criteria of student evaluation.
Tobias Richter, PhD, is a professor of Psychology at the University of Würzburg. His research interests are language and text comprehension, language skills, cognitive aspects of learning, research methods and assessment.
References
- Baayen, R. H., D. J. Davidson, and D. M. Bates. 2008. “Mixed Effects Modeling with Crossed Random Effects for Subjects and Items.” Journal of Memory and Language 59: 390–412.10.1016/j.jml.2007.12.005
- Basow, S. A., S. Codos, and J. L. Martin. 2013. “The Effects of Professors’ Race and Gender on Student Evaluations and Performance.” College Student 47: 352–363.
- Bates, D., M. Maechler, B. Bolker, and S. Walker. 2015. “Fitting Linear Mixed-effects Models Using lme4.” Journal of Statistical Software 67: 1–48.
- Brown, W. 1910. “Some Experimental Results in the Correlation of Mental Abilities.” British Journal of Psychology 2: 296–322.
- Campbell, H., K. Gerdes, and S. Steiner. 2005. “What’s Looks Got to Do with It? Instructor Appearance and Student Evaluations of Teaching.” Journal of Policy Analysis and Management 24: 611–620.10.1002/(ISSN)1520-6688
- Clayson, D. E., and M. J. Sheffet. 2006. “Personality and the Student Evaluation of Teaching.” Journal of Marketing Education 28: 149–160.10.1177/0273475306288402
- Dommeyer, C. J., P. Baum, and R. W. Hanna. 2002. “College Students’ Attitudes toward Methods of Collecting Teaching Evaluations: In-class versus On-line.” Journal of Education for Business 78: 11–15.10.1080/08832320209599691
- Gillmore, G. M., M. T. Kane, and R. W. Naccarato. 1978. “The Generalizability of Student Ratings of Instruction: Estimation of the Teacher and Course Components.” Journal of Educational Measurement 15: 1–13.10.1111/jedm.1978.15.issue-1
- Ginns, P., M. Prosser, and S. Barrie. 2007. “Students’ Perceptions of Teaching Quality in Higher Education: The Perspective of Currently Enrolled Students.” Studies in Higher Education 32: 603–615.10.1080/03075070701573773
- Hattie, J., and H. W. Marsh. 1996. “The Relationship between Research and Teaching: A Meta-analysis.” Review of Educational Research 66: 507–542.10.3102/00346543066004507
- Kenny, D. A. 1994. Interpersonal Perception: A Social Relations Analysis. New York: Guilford Press.
- Leamon, M. H., and L. Fields. 2005. “Measuring Teaching Effectiveness in a Pre-clinical Multi-instructor Course: A Case Study in the Development and Application of a Brief Instructor Rating Scale.” Teaching and Learning in Medicine 17: 119–129.10.1207/s15328015tlm1702_5
- Marsh, H. W. 1982. “The Use of Path Analysis to Estimate Teacher and Course Effects in Student Ratings of Instructional Effectiveness.” Applied Psychological Measurement 6: 47–59.10.1177/014662168200600106
- Marsh, H. W. 1984. “Students’ Evaluations of University Teaching: Dimensionality, Reliability, Validity, Potential Biases, and Utility.” Journal of Educational Psychology 76: 707–754.10.1037/0022-0663.76.5.707
- Marsh, H. W. 2007. “Students’ Evaluations of University Teaching: Dimensionality, Reliability, Validity, Potential Biases and Usefulness.” In The Scholarship of Teaching and Learning in Higher Education: An Evidence-based Perspective, edited by R. P. Perry and J. C. Smart, 319–383. Dordrecht: Springer.10.1007/1-4020-5742-3
- Marsh, H. W., B. Muthén, T. Asparouhov, O. Lüdtke, A. Robitzsch, Alexandre J. S. Morin, and U. Trautwein. 2009. “Exploratory Structural Equation Modeling, Integrating CFA and EFA: Application to Students’ Evaluations of University Teaching.” Structural Equation Modeling: A Multidisciplinary Journal 16: 439–476.10.1080/10705510903008220
- Marsh, H. W., and L. A. Roche. 1997. “Making Students’ Evaluations of Teaching Effectiveness Effective: The Critical Issues of Validity, Bias, and Utility.” American Psychologist 52: 1187–1197.10.1037/0003-066X.52.11.1187
- Patrick, C. L. 2011. “Student Evaluations of Teaching: Effects of the Big Five Personality Traits, Grades and the Validity Hypothesis.” Assessment & Evaluation in Higher Education 36: 239–249.10.1080/02602930903308258
- Rantanen, P. 2013. “The Number of Feedbacks Needed for Reliable Evaluation: A Multilevel Analysis of the Reliability, Stability and Generalisability of Students’ Evaluation of Teaching.” Assessment & Evaluation in Higher Education 38: 224–239.10.1080/02602938.2011.625471
- Rasbash, J., and W. J. Browne. 2008. “Non-hierarchical Multilevel Models.” In Handbook of Multilevel Analysis, edited by J. de Leeuw and E. Meijer, 301–334. New York: Springer.10.1007/978-0-387-73186-5
- Raudenbush, S. W., and A. S. Bryk. 2006. Hierarchical Linear Models Applications and Data Analysis Methods: Applications and Data Analysis Methods. 2nd ed. Thousand Oaks, CA: Sage.
- R Core Team. 2015. R: A Language and Environment for Statistical Computing [ Computer program]. Vienna: R Foundation for Statistical Computing. https://www.R-project.org/.
- Richter, T. 2006. “What is Wrong with ANOVA and Multiple Regression? Analyzing Sentence Reading Times with Hierarchical Linear Models.” Discourse Processes 41: 221–250.10.1207/s15326950dp4103_1
- Rindermann, H., and N. Schofield. 2001. “Generalizability of Multidimensional Student Ratings of University Instruction across Courses and Teachers.” Research in Higher Education 42: 377–399.10.1023/A:1011050724796
- Sax, L. J., S. K. Gilmartin, and A. N. Bryant. 2003. “Assessing Response Rates and Non-Response Bias in Web and Paper Surveys.” Research in Higher Education 44: 409–432.10.1023/A:1024232915870
- Shrout, P. E., and J. L. Fleiss. 1979. “Intraclass Correlations: Uses in Assessing Rater Reliability.” Psychological Bulletin 86: 420–428.10.1037/0033-2909.86.2.420
- Solomon, D. J., A. J. Speer, C. J. Rosebraugh, and D. J. DiPette. 1997. “The Reliability of Medical Student Ratings of Clinical Teaching.” Evaluation & the Health Professions 20: 343–352.10.1177/016327879702000306
- Spearman, C. 1910. “Correlation Calculated from Faulty Data.” British Journal of Psychology 3: 271–295.
- Spooren, P. 2010. “On the Credibility of the Judge: A Cross-classified Multilevel Analysis on Students’ Evaluation of Teaching.” Studies in Educational Evaluation 36: 121–131.10.1016/j.stueduc.2011.02.001
- Staufenbiel, T. 2000. “Fragebogen zur Evaluation von universitären Lehrveranstaltungen durch Studierende und Lehrende.” [Students Course Assessment Questionnaire for Evaluation of University Courses.] Diagnostica 46: 169–181.10.1026//0012-1924.46.4.169
- Staufenbiel, T., T. Seppelfricke, and J. Rickers. 2016. “Prädiktoren studentischer Lehrveranstaltungsevaluationen.” [Predictors of Student Evaluations of Teaching.] Diagnostica 62: 44–59.10.1026/0012-1924/a000142
- Thompson, R. A., and B. L. Zamboanga. 2003. “Prior Knowledge and its Relevance to Student Achievement in Introduction to Psychology.” Teaching of Psychology 30: 96–101.10.1207/S15328023TOP3002_02
- Tigelaar, D. E., D. H. Dolmans, I. H. Wolfhagen, and C. P. M. van der Vleuten. 2004. “The Development and Validation of a Framework for Teaching Competencies in Higher Education.” Higher Education 48: 253–268.10.1023/B:HIGH.0000034318.74275.e4
- Wolbring, T., and P. Riordan. 2016. “How Beauty Works: Theoretical Mechanisms and Two Empirical Applications on Students’ Evaluation of Teaching.” Social Science Research 57: 253–272.10.1016/j.ssresearch.2015.12.009