
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper studies the Cramér–Lundberg asymptotics of the ruin probability for a model in which the reserve level process is described by a spectrally-positive light-tailed Markov additive process. By applying a change-of-measure technique in combination with elements from Wiener-Hopf theory, the exact asymptotics of the ruin probability are expressed in terms of the model primitives. In addition a simulation algorithm of generalized Siegmund type is presented, under which the returned estimate of the ruin probability has bounded relative error. Numerical experiments show that, compared to direct estimation, this algorithm greatly reduces the number of runs required to achieve an estimate with a given accuracy. The experiments also reveal that our asymptotic results provide a good approximation of the ruin probability even for relatively small initial surplus levels.
1. Introduction
Primarily motivated by applications in insurance risk, much attention has been directed to evaluating ruin probabilities (Asmussen & Albrecher Citation2010). In this context, one typically assumes that the driving net cumulative claim process is of Lévy type (or a subclass thereof, such as the compound Poisson process). With the insurance firm's initial surplus being u, one is mainly interested in computing the probability
of the surplus level process
dropping below 0. If this is beyond reach, which is often the case, one may settle for the (exact) tail asymptotics, the goal being to identify an explicit function
such that
as
.
Research into such exact asymptotics goes back about a century. In the regime that the driving Lévy process is of compound Poisson type, and in case the claim size distribution is light-tailed, the classical Cramér-Lundberg asymptotics entail that decays, for u large, like
for positive constants α and
(where the decay rate
solves the so-called Lundberg equation). In the analysis one often relies on a duality with the stationary workload in the M/G/1 queue; see e.g. (Asmussen & Albrecher Citation2010, Ch. IV.2) and (Debicki & Mandjes Citation2015). Where in the literature the focus lies on finding the exact tail asymptotics for spectrally-positive (i.e. having only positive jumps) light-tailed Lévy processes, Bertoin & Doney (Citation1994) derive such asymptotics for their spectrally two-sided counterpart (i.e. having jumps in both directions).
A natural extension of the above body of work concerns exact tail asymptotics of ruin probabilities in the context of Markov additive processes (MAPs) (Çinlar Citation1972, Neveu Citation1961). These are essentially Markov modulated Lévy processes with in addition jumps at transition epochs of the modulating process (also often referred to as background process). More explicitly, a MAP behaves as the Lévy process
when its Markovian background chain
(evolving independently of the process
itself) is in state i, and may in addition have a jump at each transition of
. Because of the state changes, MAPs are particularly suitable for modeling real-world processes of which the behavior changes over time.
A main objective of this paper is to establish the exact tail asymptotics of the ruin probability when the driving process is a spectrally-positive light-tailed MAP. We find that these asymptotics are of Cramér-Lundberg type, i.e. they are of the form
for positive α and
. The present paper complements our recent work (van Kreveld et al. Citation2022) and its predecessors, such as D'Auria et al. (Citation2010), Dieker & Mandjes (Citation2011), and Ivanovs (Citation2011), which succeeded in identifying the Laplace transform of
for spectrally one-sided MAPs. With the expressions found there, one could in principle try to perform Laplace inversion in order to obtain numerical values for
, but a complication is that these become inaccurate in the regime that ruin is rare. The findings of the present paper remedy this issue: we provide an asymptotic expansion that becomes increasingly accurate as u grows.
Cramér-Lundberg asymptotics have been studied for various kinds of specific MAPs. Without providing an exhaustive overview, we discuss a few relevant contributions. Siegl & Tichy (Citation1999) consider a compound Poisson process with dividend barrier and two possible claim frequencies governed by a two-state Markov chain. In Jasiulewicz (Citation2001) a model is analyzed with the premium rate depending continuously on the reserve level and the Markov-modulated claim frequency. More general MAPs of compound Poisson type are studied with constant premium rate (Miyazawa Citation2002) or constant claim frequency (Yin et al. Citation2006). The case where all components of the compound Poisson process are allowed to change with the background chain is considered by Zhu & Yang (Citation2009). Typically, for the case that the driving process is of MAP type, the prefactor α is characterized relatively implicitly; see e.g. (Asmussen & Albrecher Citation2010, Theorem VII.3.7), where α is expressed in terms of random quantities at a stopping time under an alternative probability measure. An exception to this is the work of Miyazawa (Citation2004) on the Cramér-Lundberg asymptotics of a Markov-modulated compound Poisson process including jumps at transition epochs. By considering a ladder-height approach, that work determines an explicit expression for the prefactor α for this model.
In detail, the contributions of this paper are the following:
| ° | In the first place, we succeed in establishing exact asymptotics | ||||
| ° | Secondly, we show that the ruin probability | ||||
A crucial idea underlying our analysis is the observation that in order to identify whether the spectrally-positive MAP has crossed level u, it is sufficient to monitor only the maxima of
between every two successive transition epochs of the background process; in other words, it is not needed to monitor
continuously in time. The resulting embedded process turns out to be conceptually substantially simpler than the original one. When deriving the exact asymptotics via the embedded process, two steps play a key role at the technical level. (i) The first concerns the introduction of a specific new probability measure
under which the net cumulative claim process
has a positive drift, so that ruin occurs almost surely; see for instance (Asmussen & Albrecher Citation2010, Ch. VII.3). The main idea is then to write
in terms of the likelihood ratio of a path to ruin under the original measure
, relative to the new measure
. This reasoning leads to an expression for
in terms of the overshoot of
over u under
. (ii) In the second step, which combines application of the Wiener-Hopf decomposition with a result (Ivanovs et al. Citation2010) on the number of zeroes of the matrix-exponent corresponding to the MAP under consideration, this overshoot is analyzed in further detail (in the regime that
).
The outline of this paper is as follows. Section 2 defines our MAP , introduces the ruin probability
, and highlights a number of relevant preliminary results. The change-of-measure argument is carried out in Section 3, which leads, as mentioned above, to an expression for
in terms of the overshoot of
over u under
. As an intermediate step towards the identification of the exact asymptotics of
, the purpose of Section 4 is to find the transform of the overshoot distribution under
. As it turns out, this overshoot transform can be expressed in terms of the solution to a set of linear equations. Combining the above findings, in Section 5 the exact asymptotics of the ruin probability are derived (i.e. the constants α and
in
are identified). A simulation algorithm of generalized Siegmund type, enabling fast estimation of
, is given in Section 6. In addition, we give a proof for its bounded relative error, making the algorithm particularly useful in the rare-event regime. Finally, Section 7 presents the output of simulation experiments that provide an indication of the achievable speedup, as well as of the accuracy of the approximation
.
2. Model and preliminaries
In this section, we first describe in detail the model that we consider in this paper and introduce the corresponding notation. We then discuss the Wiener-Hopf decomposition for spectrally-positive Lévy processes and the result concerning the number of singularities of a spectrally one-sided MAP. Finally, we briefly outline the approach that we will follow in later sections to establish the exact asymptotics. The model, notation and preliminaries strongly resemble those featuring in van Kreveld et al. (Citation2022), save for a few specific aspects (e.g. the restriction to spectrally-positive processes, the background process being irreducible, and a slightly different version of Proposition 2.2).
2.1. Model
We start by defining our model. Let the background process be an irreducible continuous-time Markov chain with state space
for d>1. The corresponding transition rate matrix (or: generator matrix) is given by
, with
, having invariant probability distribution
. Associated with every state i, let
be a spectrally-positive Lévy process, evolving independently of
. Informally, when
, the process
behaves as the Lévy process
. Additionally, the process is allowed to have non-negative jumps at transition epochs of the background process. For that purpose, let
(with
such that
) be a sequence of independent copies of the non-negative random variable
, independent of anything else, representing the jumps at the epochs that
jumps from state i to state j.
The MAP can be formally defined as follows. Let
denote the time of the nth transition of the background chain. If
, we have that
for
, and, if the transition at
is from (say) i to j (where
), then
where
and
. We say that the thus constructed process
is a spectrally-positive Markov additive process (MAP).
2.2. Notation and objective
Each of the spectrally-positive Lévy processes is defined through its Laplace exponent
:
for
, where the corresponding right inverse is denoted by
. In the sequel,
denotes the matrix with entries
(1)
(1)
with
. The matrix exponent
can be seen as the MAP counterpart of the Laplace exponent.
The aim of this paper is to identify the tail asymptotics of the maximum of the MAP conditional on the initial background state being . That is, with
we wish to find an explicit function
such that
as
. We say that
are the exact asymptotics of
. We throughout assume that
has a negative drift, i.e.
(2)
(2)
such that exceeding u is increasingly rare as
; in the actuarial literature, this condition is known as the net profit condition. The focus is on a light-tailed spectrally-positive MAP, under which
decays effectively exponentially. We provide a more precise description of what we mean by the MAP being light-tailed in Section 3.
2.3. Preliminaries
Two important results play a crucial role in the derivation of the exact asymptotics of : the Wiener-Hopf decomposition for spectrally-positive Lévy processes and a fundamental result on the zeroes of
.
The Wiener-Hopf decomposition states that the value of any Lévy process at an exponentially distributed epoch can be written as the difference between two independent non-negative random quantities. In the context of this paper, we specifically consider the case of a spectrally-positive Lévy process with Laplace exponent
and corresponding right inverse
. Denote by
the running maximum process associated with
, and by
the corresponding running minimum process. In the sequel,
is an exponentially distributed random variable with mean
, assumed independent of anything else.
Proposition 2.1
Wiener–Hopf decomposition
Let be a spectrally-positive Lévy process. Then
can be decomposed as the sum of the two independent quantities
and
. Moreover,
has the same distribution as
which is distributed as
. In addition,
For a detailed account, see e.g. Kyprianou (Citation2006, Ch. 6).
The second result concerns a characterization of the zeroes of the determinant of the matrix exponent of a spectrally-positive MAP. In this result an important role is played by the Lévy processes
that are (almost surely) increasing (also referred to as subordinators). Let
denote the set of background states corresponding to these subordinators. The following result is (Ivanovs et al. Citation2010, Theorem 1).
Proposition 2.2
Let be a spectrally-positive MAP, and let the underlying background process
be irreducible. Then the equation
has
solutions in
with positive real part. Additionally, it holds that
.
2.4. Approach
We conclude this section with a short account of the approach followed in the derivation of the exact asymptotics, as covered by Sections 3–5. The MAP itself being a rather involved object, we work with a more manageable embedded version. This embedded process is constructed in such a way that the event of the MAP exceeding u is equivalent to the event of the embedded process exceeding u. More specifically, throughout this paper we restrict ourselves, similar to the approach followed in van Kreveld et al. (Citation2022), to the value of at only three types of time points. In the interval between two transitions of the background process we record the value of
at the start of the interval (right after the jump at transition epoch, that is),
at the epoch that the maximum value (within the interval) is achieved, and
at the end of the interval (right before the jump at transition epoch, that is).
It can be seen that in order to verify whether exceeds u we can restrict ourselves to the values of the MAP at epochs of type (ii). The increments of the MAP between the embedded time points are relatively straightforward to deal with, as a consequence of Proposition 2.1.
In Section 3, we work with the above embedding to find an alternative expression for the ruin probability under an alternative measure . Concretely, we succeed in expressing
in terms of the overshoot of
over level u under
. This overshoot is then analyzed in Section 4, which eventually leads to the exact asymptotics of
in Section 5.
3. Change of measure
In this section, we derive an alternative expression for the ruin probability by applying a change of measure. The derivation consists of the following four steps:
constructing a system of equations for finding the positive solution to the so-called Lundberg equation, providing the candidate for the exponential decay rate
appearing in the exact asymptotics of
defining an embedding of the MAP
defining an alternative probability measure
calculating the likelihood ratio of the actual probability measure
The compact expression for provides us with an explicit (exponentially decaying) bound on
, uniformly in
. More importantly, however, it also eventually allows us to evaluate the exact asymptotics of
, as shown in Sections 4 and 5.
3.1. Step 1: the Lundberg equation
The Lundberg equation, which yields the candidate for the exponential decay rate appearing in the exact asymptotics of
, involves the increment of the MAP between two consecutive epochs that the background state changes to an (arbitrarily chosen) reference state
. The goal of Step 1 is to quantify the moment generating function of this increment, providing the solution to the Lundberg equation.
Denote, for , by
a sequence of independent random variables being distributed as the generic random variable
(in words: the maximum of the spectrally-positive Lévy process
over an exponentially distributed time with mean
). Also, denote by
a sequence of independent random variables distributed as the generic random variable
(in words: minus the minimum of the spectrally-positive Lévy process
over an exponentially distributed time with mean
); recall from Proposition 2.1 that
is exponentially distributed with parameter
. Let the resulting
sequences be independent. Due to Proposition 2.1, the Laplace-Stieltjes transforms of these random variables are given by
with
the density of
and
the density of
(for ease assumed to exist), both under the original measure
. Below, we will use the notation
for the density of
under
.
Now fix a reference state , and define by U the increment of
between two subsequent visits of the background process to this state
. That is, if
and
are two subsequent times that the background chain enters state
, then U is distributed as
. We assume that we are in the light-tailed regime, in the sense that the Lundberg equation
has a positive solution, say
; in the literature,
is referred to as the moment generating function (mgf) of the random variable U.
Four remarks are in place now. In the first place, note that our assumption is similar to that of (Debicki & Mandjes Citation2015, Section 8.1) for the Lévy case (i.e. covering the situation without any background process). In the second place, the fact that the Lundberg equation has a positive solution implies that the jumps have a finite mgf in an open interval around the origin, and that the same holds for the mgfs of the possible upward jumps of the Lévy processes
. It is for this reason that we call the driving MAP
light-tailed. In the third place, since
,
and
, the existence of a positive solution to
excludes cases in which
‘jumps over 1’ at some
. In the fourth place, we note that it may seem that
depends on the reference state
chosen. Below, however, we argue that the choice of
does not affect the value of
.
Next, we show that we can express the root in terms of a generalized eigensystem. Let
, for
, be the moment generating function of the increment of
, with the background process starting in state j, before the background process reaches the reference state
. To derive a system of equations, consider an increment of
in an interval of the type
, that is, an interval between two successive transition epochs of the background process
. By Proposition 2.1, we know that such an increment can be written as the sum of three independent variables: the maximum of the corresponding Lévy process in this interval, the decrease after this maximum, and the jump at the transition epoch. In terms of moment generating functions this leads to the equations
and, for
,
(3)
(3)
Then we equate
to 1, in order to find
. We thus end up with the following system of equations: for
,
(4)
(4)
with
. Note that if
solves this system of equations, then so does
for any c, implying that the solution
does not depend on the reference state
. It also means that
is unique up to a multiplication by a factor, so that ratios of the type
are uniquely determined. Due to the fact that the components of the vector
can be interpreted as moment generating functions, we conclude that
is necessarily componentwise positive. Below we will use the eigenvalue/eigenvector pair
when defining the alternative measure
.
3.2. Step 2: the embedding
The idea is to embed the process into a simpler process that still contains all information based on which it can be determined whether it exceeds level u. To this end, observe that it suffices to consider only the values of
that correspond to maxima between transitions of the background process. This observation is visualized in Figure ; the maxima between transition epochs (i.e. the dots) give all information that is needed to verify whether level u is ever crossed.
Figure 1. Example of a MAP with two background states, with dots representing the embedded process . That is, the dots represent the maxima over the intervals
for
.
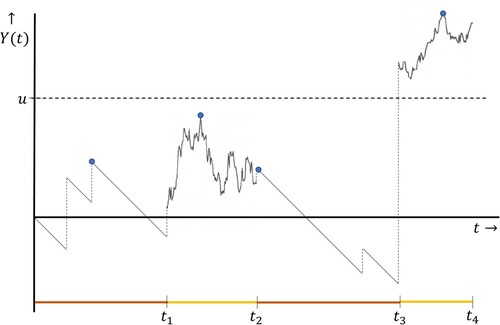
Define the embedded process by
with
and
denoting the state of the background process right after the nth transition of the background process.
As discussed above, and appealing to Proposition 2.1 to justify the independence between the sequences and
, we can rewrite the ruin probability
in terms of the embedded process
, as follows:
3.3. Step 3: construction of the alternative probability measure
To evaluate the ruin probability in the regime that , we work with a change of measure. Particularly, we set up the alternative probability measure
(to be defined below), under which the process is still a MAP, but now has positive drift. The goal is to evaluate
where the path of
is sampled under
. The measure
is an exponentially twisted version of
, in that
(5)
(5)
(where a more descriptive definition will be given below). This change of measure has been employed for the random walk (Asmussen Citation2003, Chapter XIII) and Lévy (Debicki & Mandjes Citation2015, Section VIII.1) cases.
From being convex,
(due to (Equation2
(2)
(2) )) and
, it follows that
, which means that under the new measure
the drift of
has become positive, so that u is eventually exceeded almost surely under
. As an aside, we also note that if state i corresponds to a subordinator process
under
, then the same applies under
(and vice versa).
Let be the appropriate likelihood ratio (or Radon-Nikodym derivative), which records the likelihood of the path of
under
relative to
(until
exceeds u, that is). Then we have the following standard equality translating the likelihood of outcomes under
into those under
:
An important benefit of working with
is that under this measure, the event in the indicator function has probability 1 due to the positive drift, whereas under
the same probability vanishes as u becomes large; as a consequence,
(6)
(6)
It is noted that by many other definitions of
we could have achieved a positive drift, and thus the validity of (Equation6
(6)
(6) ). The crucial feature of our specific alternative measure, as given in (Equation5
(5)
(5) ), however, is that for this
the likelihood ratio ℓ takes a simple form, as we will show below.
The alternative measure , in an abstract sense defined via (Equation5
(5)
(5) ), is concretely described as follows. Under
, the distributions of
and
are characterized through the densities
respectively, for
and x>0. Note that this means that the Laplace-Stieltjes transform of the
under
becomes
and that under
the
are exponentially distributed with parameter
In addition, the
under
have density
where, in the same way as above, the corresponding Laplace-Stieltjes transform can be verified to be
.
Now that we have defined the driving Lévy processes and the jumps at transition epochs under , we conclude by considering the transition rates of the background process under
. For
these become
It is readily verified that this choice implies that the diagonal elements of the transition rate matrix under
are
where the last equality is by virtue of (Equation4
(4)
(4) ).
3.4. Step 4: the likelihood ratio
The next step is to evaluate the likelihood ratio on a path such that
reaches u, which is equal to
by (Equation6
(6)
(6) ). Let
denote the first n for which
(which is under the new measure
finite almost surely). Then
can be written as the product of the following four factors corresponding to the elements of the MAP that change under
: the maxima and minima of the underlying Lévy processes between two transition epochs, the jumps at transition epochs and the transition rates of the background chain.
| ° | In the first place there is the contribution of the ‘in between maxima’ | ||||
| ° | Secondly, there is the contribution of the ‘in between minima’ | ||||
| ° | In the third place, there is the contribution of the jumps at transition epochs of the background process | ||||
| ° | And finally there is the contribution due to the jumps of the background process:
| ||||
It is also noted that, by the definition of the process ,
Multiplying the above four components of the likelihood ratio, the resulting expression greatly simplifies. It means that, upon combining the above, and recalling the identity (Equation6
(6)
(6) ), we have arrived at the following result.
Theorem 3.1
For all and
,
Remark 3.1
To get insight into the expression found in Theorem 3.1, compare it to its counterpart for the maximum of a random walk with independent and identically distributed increments (distributed as the generic random variable X). With
the probability of the random walk exceeding level u, and
denoting the value of this random walk at the moment N that u is crossed, a similar change of measure yields
, with
solving
and the X under
having Laplace-Stieltjes transform
This principle underlies the celebrated Siegmund algorithm for efficiently estimating
; see for a detailed account e.g. (Asmussen & Glynn Citation2007, Equation (2.5)). The additional factors for the MAP case, as appearing in Theorem 3.1, have two reasons. First, the factor
reflects the impact of the initial and eventual background states of the MAP. Secondly, regarding
, one could say that (by definition) the number of ‘steps’ of the embedded process
is odd: in step n there have been n + 1 contributions ‘of the V-type’, and just n contributions ‘of the
-type’, the consequence being that at step N the contribution of the moment generating function of one of the
(namely the last one) has not been neutralized. This results in the additional factor
in the expression for
.
While the focus of the section lies on deriving an alternative expression for , as a by-product we obtain a uniform upper bound on
. To this end, we define
Realizing that by definition
, the following result, which can be seen as the MAP-counterpart of the conventional Lundberg inequality, is an immediate consequence of Theorem 3.1.
Corollary 3.1
For all and
,
Observe that can be decomposed into
, with
denoting the ‘overshoot’ of the embedded process
over level u (i.e.
); we also write
rather than just N to stress the dependence on u. This means that if we manage to compute, for
,
,
then Theorem 3.1 would entail
(7)
(7)
which is the MAP counterpart of the classical Cramér-Lundberg asymptotics that we were aiming at. Therefore, we would be done if we would be able to devise a way to compute the overshoot transform
. As it turns out, this can be done by taking a second transform (with respect to u): note that
where
(8)
(8)
Informally, the object
corresponds to the overshoot over an exponentially distributed threshold with mean
, which grows to ∞ when sending
. In other words: what is left is (i) computing
, and (ii) let
in
. These are the topics of the next two sections.
4. Computing the overshoot transform
In this section, we are interested in evaluating the double transform corresponding to the target level u and the overshoot
, as defined in (Equation8
(8)
(8) ). Recall that i and j respectively represent the initial background state and the state at the time level u is crossed. To find an expression for
, we distinguish three scenarios for the MAP during the first background state i:
Level u has been crossed before the first transition of the background process. This only leads to a contribution if i = j.
Level u has not been crossed before the first transition of the background process, but due to the jump at the transition epoch it crosses level u. This only leads to a contribution if
Level u is not crossed before or at the first transition epoch of the background process (to state k, say), but later it is.
We now split into the components
,
, and
corresponding to the above three scenarios. In the first place, for
we have
(9)
(9)
where
with
and
evaluated below. The first term in the right-hand side of (Equation9
(9)
(9) ) is interpreted as the contribution due to the scenario in which
remains below u, a transition from background state i to background state j is made, and the corresponding jump brings
above u; in this scenario the overshoot includes an extra
(because we consider the embedded process, see Step 2 in Section 3). The second term in the right-hand side of (Equation9
(9)
(9) ) reflects the scenario in which
remains below u, and a transition from background state i to background state
is made such that after the corresponding jump the process
is still below u. The transform
is formally defined by
in which case
, and the transform
by
In the case that i = j we obtain along similar lines
(10)
(10)
with
evaluated below. The first term in the right-hand side of (Equation10
(10)
(10) ) is the contribution due to the scenario in which
exceeds u. In the second term in the right-hand side of (Equation9
(9)
(9) ) we have that
remains below u, and a transition from background state i to background state
is made such that after the corresponding jump
is still below u. The transform
is formally defined by
in which case
.
We now further evaluate the expressions of ,
, and
. First, by conditioning on the value of
, we directly find that
By conditioning on
,
and
, we also have that
Analogously, conditioning on
,
and
,
where
Next, for each of the quantities, we swap the order of the integrals so that the most elementary integration (i.e. the one over u), becomes the innermost integral. Then this integral is computed, and after that the other integrals can be evaluated successively.
Along the lines that we sketched above, we obtain
For
, a similar strategy can be followed. This yields
where
We calculate
in a similar fashion. In addition to the usual rearrangement of the integrals, we perform the change-of-variable y = x−u + v, so as to obtain
We have thus managed to express the entries of the vector
in themselves. We proceed by writing the resulting linear equations in vector/matrix-form. To this end, note that under
the matrix
has entries
For the remainder of this section, the notation
implies that we are working under the measure
. Also, with
we define
It is useful to observe that if background state i corresponds to a non-decreasing subordinator, we have
, so the expression simplifies to
To obtain a system of equations for
, we combine (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ) with the expressions for
,
, and
. When multiplying (Equation9
(9)
(9) ) and (Equation10
(10)
(10) ) by
for each
, it is seen that, for any given α and θ, we obtain the following system of linear equations.
Theorem 4.1
For any and
, and for
,
We would be able to determine the vector from Theorem 4.1, were it not for the fact that for
, the quantities
appearing in
are unknown. Defining
we now turn our attention towards finding
.
Note that, using the linear equations given in Theorem 4.1, one may express the vector by relying on Cramer's rule. More concretely, with the matrix
denoting the matrix
in which the ith column is replaced by the vector
, we have that
(11)
(11)
Since
is finite, any zero of the denominator should be a zero of the numerator. According to Proposition 2.2,
has
zeroes in the right half of the complex plane (recalling that the asymptotic drift is positive under
). For ease of exposition, we let these zeroes have multiplicity 1 (and we call them, say,
). When this multiplicity property does not hold, a reasoning similar to the one below still applies, but one needs to resort to the concept of Jordan chains; we do not discuss this procedure in detail, but instead refer to the in-depth treatment in D'Auria et al. (Citation2010).
Having distinct zeroes guarantees that we have equations to identify the
. That is, for
and
,
(12)
(12)
in other words, the zeroes of
(in the right half of the complex plane, that is) are also zeroes of
, for each
.
By precisely the same argument as the one given in van Kreveld et al. (Citation2022), Equation (Equation12(12)
(12) ) provides the same information for any
, so it suffices to consider just the equation
. With
representing the
matrix which results after deleting the ith column and the kth row from
, this equation can be rewritten as
We thus obtain
equations (one for each
) that are linear in the unknowns
, which can be dealt with in the standard manner, thus yielding a solution for the
. This procedure can be repeated for each eventual state j. Now that the quantities
(for
) are known, Equation (Equation11
(11)
(11) ) expresses
in terms of known quantities.
5. Exact tail asymptotics
As pointed out at the end of Section 3, in order to evaluate , we are interested in
. The purpose of this section is to find an explicit expression for this limit, and consequently determining the exact asymptotics of
by Equation (Equation7
(7)
(7) ). We rely on the fact that from Section 4 we know how
can be evaluated.
It is first observed that as , the denominator
of (Equation11
(11)
(11) ) tends to 0, so that L'Hopital's rule gives
This explains why we first study the behavior of
as
. To this end, we write, taking entry-wise Taylor expansions at
,
where
is given by
Hence, we can express
as the determinant of a sum. In order to work with determinants of sums, we have the following lemma. Let
be the matrix consisting of all columns of C, but with its kth column replaced with the kth column of E.
Lemma 5.1
If C and E are matrices, then, as
,
Proof.
Recall that is the sum of
determinants; one for each possible matrix in which each of the columns equals the corresponding column of C or
. Using this rule, one can write
as a polynomial in
of degree d where the coefficients of the
are sums of
determinants of the above type. The result follows by isolating the terms that do not depend on ϵ and those that are linear in ϵ, and by in addition aggregating all terms that correspond to
.
The idea is now to set ,
and E any finite matrix in the above lemma. It immediately follows that
. We then use the lemma a second time, but now with C = Q,
and E = Z, so as to obtain
Here, in the second equality, we used that Q is the transition rate matrix of a continuous-time Markov chain (also under
), which implies
. Hence, we obtain
We thus conclude that
Combining this with (Equation7
(7)
(7) ), we obtain the main result of the paper: the exact asymptotics for
. As mentioned, this result can be considered the MAP-counterpart of the classical Cramér-Lundberg result.
Theorem 5.1
For any initial state ,
The above theorem provides a possible approximation for the ruin probability in the regime that u is large. Concretely, we propose the approximation
(13)
(13)
In Section 7 the accuracy of (Equation13
(13)
(13) ) is assessed.
6. Efficient simulation
In this section, we point out how to efficiently estimate by simulation, with emphasis on the regime that u is large. The main idea is to rely on importance sampling, using a generalized version of the celebrated Siegmund algorithm. More specifically, we propose to run independent simulations of the MAP under
, and subsequently average the values of
that are sampled in each of the runs. By Theorem 3.1 this results in an unbiased estimator. The main objective of this section is to prove that this estimator has bounded relative error. Its efficiency gain (relative to direct simulation, that is) is demonstrated in Section 7 through a series of numerical experiments.
A pseudo-code corresponding to a single run of this generalized Siegmund algorithm is given by Algorithm 1. Here s records the current value of the embedded MAP and j the current background state. Also, the function ‘sample(X)’ generates and returns a sample of the random variable X, independent of everything what has been sampled before. Finally, the function ‘’ returns a new state of the background chain sampled under
, when the current state is j.
The while loop in Algorithm 1 updates the value of the MAP at maxima between two successive background transition epochs. Lines 3 through 7 respectively correspond to sampling the decrease of the MAP before the next background transition, sampling the next background state, sampling the jump at the transition epoch and sampling the maximum between the current and next background transitions.

An important performance measure of algorithms estimating small probabilities is their relative error, defined by the standard deviation of the estimate divided by the estimated probability. Not only does yield an unbiased estimator of
, the next theorem entails that the relative error is bounded in u. We refer to this property as bounded relative error (Asmussen & Glynn Citation2007, Ch. VI.1).
Theorem 6.1
A sample of as returned by Algorithm 1 has bounded relative error.
Proof.
The proof is closely related to its counterpart for the random walk case (Asmussen & Glynn Citation2007, Ch. VI.2). Denote, in line with the notation that we have previously used, by and
the overshoot and the background state, respectively, at the time that level u is crossed. Now consider the process
, conditional on
. Above, we have computed the transform
, by which we uniquely characterized the limiting distribution of
as
; we let
be distributed as the corresponding limiting random vector.
As a result of the above, the ruin probability (which equals the mean of , as defined above) satisfies the following asymptotics, as
:
We have bounded relative error as the second moment of
vanishes at essentially the same rate as the square of
; to see this, observe that
where it is noted that
due to Jensen's inequality. The variance of a single observation
in our generalized Siegmund algorithm thus satisfies
It now directly follows that for u large the relative error tends to
(14)
(14)
We observe that apparently the relative error loses its dependence on u as u grows, and that it is bounded by a constant.
7. Numerical experiments
In this section, we numerically study the asymptotic behavior of , measuring in particular the efficiency of the generalized Siegmund algorithm compared to direct estimation. We in addition include an experiment that studies the impact of the background process on the ruin probability.
To obtain a direct estimation of the ruin probability , one may simulate the model at hand say n times under the original measure
, and then determine the fraction of runs in which the process exceeds level u. This leads to an unbiased estimator, with the relative error equaling
In order to achieve a relative error of at most ϵ, one thus requires roughly
runs. The particularly worrisome element in this quantity is the
in the denominator, being very small when u is large. Concretely, with
decaying roughly as
and
, we conclude that n blows up like
as u grows.
The generalized Siegmund algorithm, in which the process is simulated under , on the other hand has bounded relative error. With c given in (Equation14
(14)
(14) ), and again aiming for a relative error ϵ, this algorithm thus requires roughly
runs for large u. As a result, the generalized Siegmund algorithm gives an accurate estimation for any u, in that for large u the number of runs required becomes independent of u. This in particular means that this number of runs does not blow up as
.
In the remainder of this section we discuss experiments in which we apply our generalized Siegmund algorithm. It should be noted that executing this algorithm requires being able to sample random variables , while only their respective Laplace-Stieltjes transforms are known (see Proposition 2.1). To this end we first apply numerical inversion to obtain a discretization of the distribution function of each of the
. In our numerics we have used the intensively tested and frequently cited algorithm that was developed in Abate & Whitt (Citation2006); in the experiments reported in this section, we use
mass points. With this approximate distribution function at our disposal, we can use the inverse distribution function method to sample a random variable distributed according to
. Three remarks are in place here.
| ° | First observe that, for any k, the Laplace inversion has to be performed just once (say, in the pre-processing phase); once the approximate distribution function of | ||||
| ° | Secondly, the simulation of the embedded process under the original measure | ||||
| ° | The fact that we propose to use numerical Laplace inversion to run our generalized Siegmund algorithm, triggers the question why we do not simply numerically invert the transform of | ||||
We now describe the specific MAP we use in our experiments. It consists of two background states, the first and second corresponding respectively to a standard Brownian motion with drift
, and a compound Poisson process
with drift
and jumps of
size arriving at rate
. Note that we constructed this instance such that
, allowing for better comparison between the impacts of both processes on the ruin probability. To make our model as elementary as possible, our setup does not contain jumps at transition epochs; we stress however that adding those does not lead to any conceptual complications.
Experiment 7.1
In the first experiment we vary the value of the exceedance level (or, in risk applications, the initial reserve) u, so as to provide empirical backing for the claims of Theorems 5.1 and 6.1. In addition, we obtain insight into the accuracy of the approximation (Equation13(13)
(13) ).
We consider the instance , and we vary u (with steps of 10) from 10 to 80, see Table . Two approximations of the ruin probability are presented: the second column shows estimates of
that are generated by
runs of Algorithm 1, and the third column presents the approximation
of (Equation13
(13)
(13) ) (with
and
). The approximations of both methods differ around
, even for small values of u. This indicates, for our specific MAP, fast convergence of the expression in Theorem 5.1.
Table 1. Ruin probabilities as a function of u, and the relative error per run under and
.
In addition, Table shows the average relative error of a single run under (Algorithm 1), based on the sample (fourth column). This is compared to the same error when one would estimate the ruin probability directly under
(fifth column). Where the relative error of Algorithm 1 is fairly constant, the same error under direct estimation shows exponential increase in u, as anticipated. If, say, one is interested in an estimate for
with relative error at most
, the instances u = 10, 40, 80 respectively require approximately
,
, and
runs. The number of runs required under
, on the other hand, is around 250 for any value of u.
Experiment 7.2
In the second experiment the background chain transition rates and
are varied, and with them the proportion of time spent in each of the two background states. For each combination of these parameter values we run Algorithm 1 with u = 40 a total of
times. The output consists of the estimated ruin probability and the relative error per run based on the sample. The results are shown in Table .
Table 2. Ruin probabilities as a function of the fraction of time spent in each of the two background states.
As we can see, the ruin probability heavily depends on the transition rates of the background chain. The larger the proportion of time spent in the compound Poisson state (state 2), the larger the ruin probability, and the larger the proportion of time spent in the Brownian state (state 1), the smaller the ruin probability. It is also reassuring to see that, for this MAP, the (bounded) relative error per run is rather low. With runs this results in a relative error in the order of
.
When , one expects that the net cumulative claim process effectively coincides with a compound Poisson process, which has a ruin probability that asymptotically decays as
. Substituting u = 40 gives
, close to the values of
in the top rows. Conversely, when
, the net cumulative claim process should be close to a Brownian motion, which has a ruin probability
. Substituting u = 40 gives
, in line with the values of
in the bottom rows.
8. Discussion and concluding remarks
In this paper we have considered a ruin model driven by a light-tailed spectrally-positive Markov additive process. We first identified the exact asymptotics of the ruin probability, and then devised an efficient simulation algorithm. Since previous literature restricts to MAPs with specific underlying Lévy processes, our results narrow the gap in the understanding of these asymptotics for arbitrary MAPs. Nevertheless, various directions for further research are possible, of which we list a few.
When the net cumulative claim process is a spectrally-negative MAP (i.e. having jumps in the downward direction only), the all-time maximum has a phase-type distribution (van Kreveld et al. Citation2022). This means that in that case the exact asymptotics of the ruin probability can be dealt with relatively easily. Considerably more challenging, however, is the case of a MAP with jumps in both directions; this would extend the result for the Lévy case that was established in Bertoin & Doney (Citation1994). A possible first step in this direction could be to assume that the jumps in one of the directions are of phase-type (cf. Jacobsen Citation2005 for instance).
A second interesting extension would concern the inclusion of heavy-tailed jump size distributions, applying to jumps of the Lévy processes and/or jumps at transition epochs. Such distributions deny the existence of a positive solution to the Lundberg equation, thus invalidating our change-of-measure approach. Instead, we suggest to build upon the results of Foss et al. (Citation2007), in which the ‘principle of a single big jump’ is exploited.
In our paper we used an embedded process to simplify the analysis while maintaining all information on the ruin probability over level u. For this embedded process, we in particular identified the transform of the overshoot over level u. However, it is clear that the overshoot over level u of the embedded process can be substantially different from its counterpart for the original MAP. This leaves open the problem of characterizing the distribution of the overshoot for our MAP. Extensions in this direction would be valuable additions to the literature on first passage times.
Finally, it may be interesting to explore which results can be obtained if one drops the assumption that the background chain is irreducible, but still assumes that the asymptotic drift in the recurrent classes is negative. In this setting we think it is wise to condition on the joint distribution of the recurrent class that is reached and the value of the MAP at the time this class is reached. We conjecture that, out of the reachable recurrent classes from the initial state, only the class with the lowest exponential decay rate (i.e. with the heaviest tail) impacts the ruin probability in the limit.
Acknowledgments
The authors thank Onno Boxma (Eindhoven University of Technology), Masakiyo Miyazawa (Tokyo University of Science), and Peter Spreij (University of Amsterdam) for useful remarks.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abate J. & Whitt W. (2006). A unified framework for numerically inverting Laplace transforms. INFORMS Journal on Computing 18(4), 408–421.
- Asmussen S. (2003). Applied probability and queues, 2nd ed. New York: Springer.
- Asmussen S. & Albrecher H. (2010). Ruin probabilities. Singapore: World Scientific.
- Asmussen S. & Glynn P. (2007). Stochastic simulation: algorithms and analysis. New York: Springer.
- Bertoin J. & Doney R. (1994). Cramér's estimate for Lévy processes. Statistics & Probability Letters 21(5), 363–365.
- Çinlar E. (1972). Markov additive processes. I. Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete 24(2), 85–93.
- D'Auria B., Ivanovs J., Kella O. & Mandjes M. (2010). First passage of a Markov additive process and generalized Jordan chains. Journal of Applied Probability 47(4), 1048–1057.
- Debicki K. & Mandjes M. (2015). Queues and Lévy fluctuation theory. New York: Springer.
- Dieker A. B. & Mandjes M. (2011). Extremes of Markov-additive processes with one-sided jumps, with queueing applications. Methodology and Computing in Applied Probability 13(2), 221–267.
- Foss S., Konstantopoulos T. & Zachary S. (2007). Discrete and continuous time modulated random walks with heavy-tailed increments. Journal of Theoretical Probability 20(3), 581–612.
- Ivanovs J. (2011). One-sided Markov additive processes and related exit problems [Ph.D. thesis]. University of Amsterdam. Available at: https://pure.uva.nl/ws/files/1408093/94456_0_Thesis.pdf
- Ivanovs J., Boxma O. & Mandjes M. (2010). Singularities of the matrix exponent of a Markov additive process with one-sided jumps. Stochastic Processes and Their Applications 120(9), 1776–1794.
- Jacobsen M. (2005). The time to ruin for a class of Markov additive risk process with two-sided jumps. Advances in Applied Probability 37(4), 963–992.
- Jasiulewicz H. (2001). Probability of ruin with variable premium rate in a Markovian environment. Insurance: Mathematics and Economics 29(2), 291–296.
- Kyprianou A. (2006). Introductory lectures on fluctuations of Lévy processes with applications. New York: Springer.
- Miyazawa M. (2002). A Markov renewal approach to the asymptotic decay of the tail probabilities in risk and queuing processes. Probability in the Engineering and Informational Sciences 16(2), 139–150.
- Miyazawa M. (2004). Hitting probabilities in a Markov additive process with linear movements and upward jumps: applications to risk and queueing processes. The Annals of Applied Probability 14(2), 1029–1054.
- Neveu J. (1961). Une généralisation des processus à accroissements positifs indépendents. Abhandlungen aus dem Mathematischen Seminar der Universität Hamburg 25(1-2), 36–61.
- Siegl T. & Tichy R. F. (1999). A process with stochastic claim frequency and a linear dividend barrier. Insurance: Mathematics and Economics 24(1-2), 51–65.
- van Kreveld L., Mandjes M. & Dorsman J. (2022). Extreme value analysis for a Markov additive process driven by a nonirreducible background chain. Stochastic Systems 12(3), 293–317.
- Yin G., Liu Y. J. & Yang H. (2006). Bounds of ruin probability for regime-switching models using time scale separation. Scandinavian Actuarial Journal 2006(2), 111–127.
- Zhu J. & Yang H. (2009). On differentiability of ruin functions under Markov-modulated models. Stochastic Processes and Their Applications 119(5), 1673–1695.