
ABSTRACT
Computational techniques are becoming more common in persona development. However, users of personas may question the information in persona profiles because they are unsure of how it was created. This problem is especially vexing for data-driven personas because their creation is an opaque algorithmic process. In this research, we analyze the effect of increased transparency – i.e., explanations of how the information in data-driven personas was produced – on user perceptions. We find that higher transparency through these explanations increases the perceived completeness and clarity of the personas. Contrary to our hypothesis, the perceived credibility of the personas decreases with the increased transparency, possibly due to the technical complexity of the persona profiles disrupting the facade of the personas being real people. This finding suggests that explaining the algorithmic process of data-driven persona creation involves a “transparency trade-off”. We also find that the gender of the persona affects the perceptions, with transparency increasing perceived completeness and empathy of the female persona, but not for the male persona. Therefore, transparency may specifically assist in the acceptance of female personas. We provide practical implication for persona creators regarding transparency in persona profiles.
1. Introduction
Computational techniques are rapidly taking a powerful role in the field of digital user analytics, where tools, techniques, and platforms that provide user and customer insights are being automated at an increasing pace (An, Kwak, Jung, Salminen, & Jansen, Citation2018; An, Kwak, Salminen, Jung, & Jansen, Citation2018; Salminen et al., Citation2018) for a variety of purposes (Khashe, Lucas, Becerik-Gerber, & Gratch, Citation2019; Mahmut, Citation2016). For example, Google Analytics automatically provides recommendations to improve website performance (Salminen & Jansen, Citation2018). Still, end users of automatically generated customer insights may question the insights, especially when their generation process is not transparent, self-explanatory, or questions arise from the reliability of data (Salminen et al., Citation2018). In other words, the trustworthiness and credibility of the underlying data and algorithms are essential for the use of automated analytics systems for many uses, such as data-driven marketing (Driscoll & Walker, Citation2014). This is also the case for data-driven personas, which are fictitious people describing core users or customers of a software system, product, or service (Cooper, Citation1999; Pruitt & Adlin, Citation2006; Pruitt & Grudin, Citation2003). A persona profile typically includes a name, a picture, and a description detailing the attitudes and behaviors of the persona in question (Nielsen, Hansen, Stage, & Billestrup, Citation2015). Personas have repeatedly been used in a variety of fields, including software development (Dantin, Citation2005), design (Nielsen, Citation2013), marketing (Salminen, Jansen, Kwak, & Jung, Citation2018), and health informatics (LeRouge, Jiao, Sneha, & Tolle, Citation2013; Liu et al., Citation2016). A persona simplifies numerical data into an easy-to-understand representation – another human being (Cooper, Citation1999). Personas facilitate the communication of data within an organization, so that content, product, or other decisions can always be made while keeping the end user in mind (Nielsen & Hansen, Citation2014). From the analytics perspective, personas aggregate similar users under one shared representation, thereby facilitating the understanding of users’ needs and wants in a design or development process (Nielsen & Hansen, Citation2014) and communicating these needs and wants to others in the team and organization producing outputs for users (Blomquist & Arvola, Citation2002). Conversely, as “imaginary people,” the credibility of personas has been questioned (Chapman & Milham, Citation2006; Salminen et al., Citation2018), especially relating to personas created using qualitative methods that may reflect their creators’ biases (Marsden & Haag, Citation2016) and to lack true representativeness of the underlying population (Chapman, Love, Milham, ElRif, & Alford, Citation2008).
To address the issue of human bias and limited data of qualitative persona generation, researchers have introduced approaches for quantitative data-driven persona creation (An et al., Citation2018; McGinn & Kotamraju, Citation2008; Zhang, Brown, & Shankar, Citation2016). Such personas are created using quantitative user data and computational techniques, involving a higher degree of precision and accuracy compared to manually created personas (An, Kwak, & Jansen, Citation2017; Kwak, An, & Jansen, Citation2017; Salminen et al., Citation2018), but, at the same time, the creation mechanisms of data-driven personas are complicated to understand by persona end users. Moreover, if the end users only see the persona profiles without any explanations, they may still consider data-driven personas as untrustworthy because they may be unsure how the information in the persona profiles was inferred (Chapman & Milham, Citation2006; Salminen et al., Citation2018). A potential solution to these issues is providing explanations in the persona profile about how the information was produced.
Transparency has been suggested as a solution to trust concerns regarding data use and algorithmic decision-making (Ananny & Crawford, Citation2018; Diakopoulos & Koliska, Citation2017). It is postulated that by understanding how systems and algorithms work, end users of those systems or algorithms will feel more comfortable and trusting (Kizilcec, Citation2016) with the results. Unfortunately, there is no extant research on the impact of increased transparency on user perceptions of personas, especially those created using computational techniques. The issue is important because credibility has been observed to be a key antecedent to the use and acceptance of personas in real organizations and scenarios (Chapman & Milham, Citation2006; Rönkkö, Hellman, Kilander, & Dittrich, Citation2004). Therefore, research into transparency could significantly advance persona development and design.
In this research, we analyze the effect of increased transparency, defined as explanations of how the information within a persona profile is created, on end users’ persona perceptions. Building from prior research, we presume that the lack of transparency in persona profiles might result in several adversities, including fear that persona profiles are biased (Hill, Haag, & Oleson et al., Citation2017), lack of perceived representativeness and completeness of persona information (Chapman et al., Citation2008), lack of credibility of persona generation process (Salminen et al., Citation2018), and lack of perceived usefulness of the personas (Matthews, Judge, & Whittaker, Citation2012; Rönkkö et al., Citation2004). Moreover, since explanations are not typically part of persona profiles shown to end users (Nielsen et al., Citation2015), it is possible that they will influence the perceived clarity of the persona profile. To investigate these effects on persona perceptions, we pose the following research question:
How does the increased level of transparency affect the persona perceptions of credibility, completeness, clarity, empathy, and usefulness?
The constructs of the research are based on prior work reported in (Salminen et al., Citation2018) and are explained in the Section 2.3. In the following section, we review the related literature. After that, we explain the methodology, including data collection and analysis methods. The results of the data analysis are presented, which is followed by conclusions and discussion over the implications for research and practice.
2. Related literature
2.1. Data-driven personas and the problem of transparency
Personas, defined as fictitious people describing an underlying user base, have been suggested as a format for representing customer insights in a manner that supports end users’ sense-making about the customers in the design, software development, and marketing (Cooper, Citation1999; Jenkinson, Citation1994; Nielsen & Hansen, Citation2014). In persona profiles, customer attributes are displayed as ‘people characteristics’ that describe the core users or customers of the organization (Pruitt & Adlin, Citation2006). Showing human attributes instead of numbers, makes analytics data more approachable than numbers, especially for decision makers with limited analytics experience (An, Kwak, & Jansen, Citation2016).
To curb the effect of bias on persona creation, researchers have proposed personas based on large-scale quantitative data (Chen, Wang, Xie, & Quan, Citation2018; Jerison, Citation1959; An et al., Citation2017; Kizilcec, Citation2016; Salminen et al., Citation2018; Thelwall & Stuart, Citation2019). Overall, personas can be classified into three categories according to their usage of data: (a) personas based solely on data, (b) personas based on data but with considerable fictive elements, and (c) entirely fictive personas created without data (Matthews et al., Citation2012). When qualitative data is used, personas are typically developed using ethnographic fieldwork and/or user interviews (Goodwin, Citation2009; Pruitt & Grudin, Citation2003). A major critique of personas created manually is that they are often based on a small volume of user data, not enough to apply quantitative methods (Chapman & Milham, Citation2006). Computational techniques provide four key advantages for data-driven personas (An et al., Citation2017): (1) time-savings from data collected via application programming interfaces (APIs), (2) availability of behavioral data, (3) scalability, and (4) real-time access to the data, enabling personas to change as the underlying user behavior changes.
Despite the advantages and potential of data-driven personas in capturing and presenting key customer insights, there are also challenges. Most notably, when personas are applied in real use cases, there has been a lack of perceived credibility (Chapman & Milham, Citation2006; Rönkkö et al., Citation2004). For example, a user study on data-driven personas (Salminen et al., Citation2018) showed that users expressed doubts about the origin of the information shown to them. Therefore, trust issues can be considered as real concerns for data-driven personas. Research in other contexts (Kizilcec, Citation2016; Stoyanovich, Abiteboul, & Miklau, Citation2016) suggests that these issues could be mitigated by providing additional transparency of how the personas are created and how the information is inferred.
2.2. Algorithmic transparency
Most algorithmic decision-making systems do not communicate their inner workings to their users (Pasquale, Citation2015). This can result in information asymmetry, which is the disparity in what information is visible to different parties of a system (Nissenbaum, Citation2009) that might erode users’ trust in a system (Kizilcec, Citation2016), cause misperceptions (Eslami, Rickman, & Vaccaro et al., Citation2015), may result in inaccurate folk theories of how algorithms work (Blase, Leon, Cranor, Shay, & Wang, Citation2012; Rader, Citation2014; Stevenson, Citation2016; Yao, Re, & Wang, Citation2017), and mislead users through biased algorithm outputs (Eslami, Vaccaro, Karahalios, & Hamilton, Citation2017). To mitigate these issues, researchers suggest algorithmic transparency in opaque algorithmic systems such as personalized news feeds (Eslami et al., Citation2015), team formation tools (Jahanbakhsh, Wai-Tat, Karahalios, Marinov, & Bailey, Citation2017), online behavioral advertising (Eslami, Kumaran, Sandvig, & Karahalios, Citation2018), and algorithmic journalism (Diakopoulos & Koliska, Citation2017). Still, transparency in algorithmic systems can pose both advantages and disadvantages, which we discuss below.
Transparency in opaque algorithmic systems can improve user interaction with the system. For example, adding explanations to recommender systems increases users’ trust in and acceptance of recommendations (Herlocker, Konstan, & Riedl, Citation2000). Increased algorithm awareness has also led users to a higher level of engagement with their algorithmically curated social feeds (Eslami et al., Citation2015). In online behavioral advertising, adding interpretable explanations to how an ad is algorithmically targeted to a user increases users’ trust in advertisers (Eslami et al., Citation2018). On the other hand, even though algorithmic transparency can be beneficial to user interaction, it can also have detrimental effects (Ananny & Crawford, Citation2018). The complex and unpredictable nature of algorithms makes it almost impossible to disclose the complete functionality of an algorithm. Even if possible, such disclosure would make user interaction with the system complicated, effortful, or even impossible (Seaver, Citation2013). Assuming these issues could be resolved, providing users with the wrong level of algorithmic transparency can still ruin user interaction with the system. For example, in previous work, providing a high level of transparency of a grading algorithmic caused confusion, expectation violation, and trust erosion among students (Kizilcec, Citation2016). In another example, Eslami et al. (Eslami et al., Citation2018) found that too much specificity can make an explanation of an ad algorithm suspicious, causing dissatisfaction among users. Also, when users were asked to design the desired explanation for their personalized ads, many argued that they do not need full transparency to be satisfied with an explanation (Eslami et al., Citation2018).
These research findings illustrate that determining the right level of transparency in opaque algorithmic systems is challenging. Algorithmically generated personas, in particular, are one of the opaque algorithmic processes where finding the right level of transparency can be challenging, mainly due to the complexity of the information and computational methods that are used in creating these personas.
We define transparency in the context of data-driven personas as follows: Transparency is providing user with clearly understandable explanations on how the information in the persona profiles is generated, including what tools, methods, and techniques are used.
2.3. Research gap and hypotheses
Overall, the transparency literature shows that lack of transparency can have several adverse effects on user experience, including fears of biased algorithms, mistrust or disbelief of algorithmic decision making, and lack of credibility of the results given by systems. In this research, we aim to analyze how explanations of this information and computational techniques applied to data-driven personas influence individuals’ perceptions of those personas. Because personas, in general, are reported to suffer from problems of trust and credibility (Chapman & Milham, Citation2006; Matthews et al., Citation2012) and there are reports of mistrust relating to transparency of algorithms in various domains (Diakopoulos & Koliska, Citation2017; Kizilcec, Citation2016; Pasquale, Citation2015), investigating how increased transparency in the context of data-driven personas influences perceptions is an important undertaking. To this end, we formulate the hypotheses in .
Table 1. Research hypotheses and rationales for each
Credibility, or lack of it, has been noted as one of the most notable challenges for persona adoption. If individuals do not find the personas credible, they are unlikely to believe in the information and take the personas seriously (Chapman & Milham, Citation2006; Matthews et al., Citation2012). We expect that providing explanations of the information in the persona profiles enhances the sense of credibility of the persona, because the persona user can better understand how the persona profile is created.
Completeness is a central characteristic of a whole or “rounded” persona, in the sense that the individual using the persona feels that the persona contains the necessary information to understand the users that the persona portrays (Nielsen, Citation2019). We expect that the explanations are considered as additional persona-related information that enhances the general satisfaction of the persona user’s information needs, thereby resulting in a higher perceived completeness of the persona profile.
Clarity has been found to be a persistent issue especially for data-driven personas, as their information can be confusing or unclear to persona users (Salminen, Jansen, Jung, Nielsen, & Kwak, Citation2018; Salminen et al., Citation2019). As explanations clarify the specific information pieces shown in the persona profile, their introduction is expected to increase the perceived clarity.
Empathy is core benefit and advantage of deploying personas for decision making, as the persona format is seen enhancing the decision makers’ understanding of the users as people with goals, needs, and wants (Nielsen, Citation2019), rather than anonymous numbers (Salminen et al., Citation2018). However, we expect this perceptual dimension to decrease with the introduction of explanations, as the explanations emphasize that the persona is not “real” but actually constructed using algorithmic processes.
Finally, usefulness is critical in the sense that a “good” persona is engaging and encourages the persona user to learn more about it (Blomquist & Arvola, Citation2002; Chapman & Milham, Citation2006; LeRouge et al., Citation2013). The lack of such willingness is seen detrimental for deployment of personas in real decision-making situations (Rönkkö et al., Citation2004). We expect that the usefulness of transparent persona profiles is higher, because the explanations make the persona user interested in knowing more about the persona.
Overall, study focuses on perceptual constructs that are relevant for persona theory and practice. The operational definitions and measurement items of the constructs are presented in Section 3.4.
3. Methodology
3.1. Persona creation
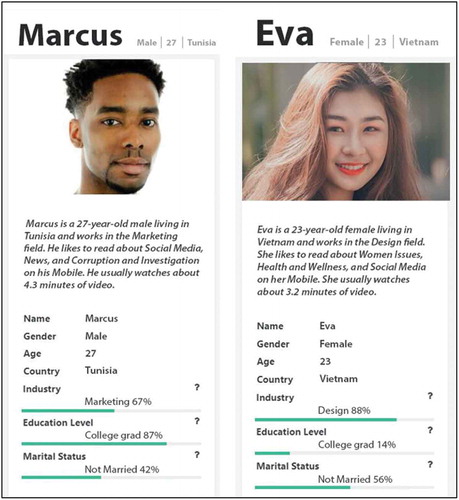
We created two personas from the collected, “Eva” (E) and “Marcus” (M), and two versions of each: Transparent (T) and nontransparent (N). The personas were created using real data from an actual organization, a large international news and media company (i.e., the aggregated YouTube audience statistics of the said organization). We used the collected data to generate a set of ten personas and chose two personas from this set for the transparency experiment (one male, one female). The personas were further modified before they were shown to the participants using an image-editing software to add the explanations into the transparency versions. An example is shown in (E-T).
Figure 1. Transparent persona “Eva”. The participants were provided a full-sized image that shows each section of the persona profile and the accompanying explanations clearly. Another persona, “Marcus”, was created that only differed by demographic attributes and picture. The explanations were detailed considering the space limitations of the persona profile
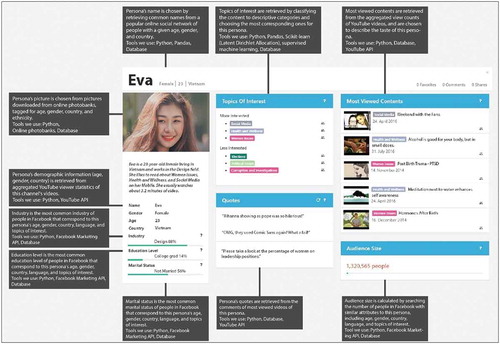
In the transparent versions of the persona profiles, we added informative text boxes that explain to the persona users how each section of the persona profiles is generated (see for the explanations). Transparency was, therefore, achieved by adding explanations for each central information piece in the persona profile. As seen from , the explanations contain both a generic explanation of how the information is generated (e.g., “Persona’s picture is chosen from pictures downloaded from online photobanks, tagged for age, gender, country, and ethnicity”), as well as a description of the tools used (“Tools we use: Python, Online photobanks, Database”).
Table 2. Explanations provided to participants for the attributes of the persona profiles
The explanations are reasonably brief and concise (196 characters on average), and they were created with the goal of balancing technicality and understandability. The first version of the explanations was created by one of the researchers with intimate knowledge about the data-driven persona generation process; after this, other researchers commented on the language, content and understandability of the explanations and they were edited accordingly. After having been accepted by all the researchers, the explanations were added into the generated persona profiles.
3.2. Technical description of the persona creation
The persona creation followed the data-driven persona generation methodology developed by An et al. (An et al., Citation2018, Citation2018), in which aggregated user statistics are collected from online analytics platforms and processed automatically using computational methods. This approach involves the following steps:
Step 1: Create an interaction matrix by assigning content (videos) as columns, demographic user groups as rows, and view count of each group for each video as elements of the matrix
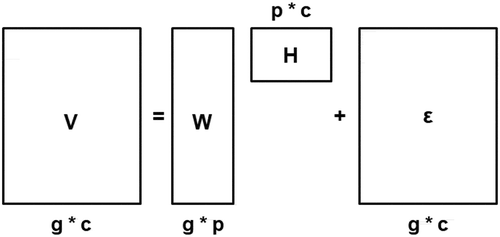
Step 2: Apply non-negative matrix factorization (NMF) (Lee & Sebastian Seung, Citation1999) to the interaction matrix to discern p latent video viewing behaviors (where p is a hyper-parameter set by us). illustrates the matrix decomposition process of NMF; the resulting patterns inferred from the matrix discriminate the user groups based on the variation of their content viewing patterns.
Step 3: Choose the representative demographic attributes for each behavior by using weights from the NMF computation
Step 4: Create the personas by enriching the representative demographic groups for each p personas with extra information, including name, picture, topics of interest, etc.
Figure 2. Matrix decomposition carried out using NMF. Matrix V is decomposed into W and H. g denotes demographic groups in the dataset, c denotes content (e.g., videos), and p is the number of latent interaction patterns that are used to create the personas
For this research, the personas were generated from 206,591,656 video views from 13,251 videos published between January 1, 2016 and September 30, 2018 on the YouTube channel of Al Jazeera Media Network (AJ+Footnote1). For the data collection, we used the YouTube Analytics APIFootnote2 with the channel owner’s permission. The dataset includes all the channel’s view counts divided by demographic groups (age group x gender x country), of which there are 1631 with at least one view during the collection period. For further technical reference, we refer the reader to An et al. (An et al., Citation2018, Citation2018), as this research focused on reporting the effects of adding transparency to the data-driven personas.
3.3. Experiment set-up
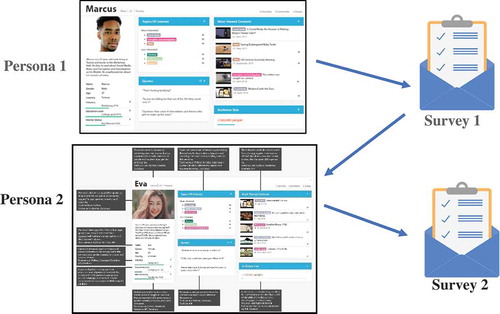
The experiment design is a controlled within-subjects experiment. We created four sequences to counterbalance possible ordering and learning effects (Jerison, Citation1959): [MarcusN→EvaT]; [MarcusT→EvaN]; [EvaN→MarcusT]; and [EvaT→MarcusN]. Each participant is, therefore, shown two personas, one transparent and one nontransparent. For example, [MarcusN→EvaT] shows the participant first the nontransparent version of Marcus and then the transparent version of Eva. In this process, each participant is randomly assigned to a given setting (i.e., they choose a survey to fill and are excluded from the other surveys). illustrates the sequences.
Figure 3. Flow 1. Two personas were shown to participants, such that the participants were randomly assigned to counter-balanced flows (Flow 1: Showing Male persona first, then Female persona; Flow 2: vice versa). Either of the personas always had explanations enabled
3.4. Survey creation
To address the research question, we created a questionnaire using the items of as statements shown to participants, utilizing a 7-point Likert scale, options ranging from ‘Strongly disagree’ to ‘Strongly agree’. We utilized the constructs and items from the Persona Perception Scale (Salminen et al., Citation2018). From this instrument, we investigate eight constructs that correspond with our hypotheses, shown in along with their internal consistency scores (Cronbach’s alpha).
Table 3. Constructs and items. These are based on prior work reported in Salminen et al. (Citation2018) that also addressed scale reliability and validity. α = Cronbach’s alpha
3.5. Data collection
3.5.1. Recruitment of participants
The participant data was collected via the online survey platform Prolific,Footnote3 used for crowdsourcing behavioral research (Palan & Schitter, Citation2018; Peer, Brandimarte, Samat, & Acquisti, Citation2017). Prolific provides a large pool of participants and includes built-in quality management tools (Palan & Schitter, Citation2018). We sample the Prolific pool of participants using the following criteria:
Minimum Age: 23, Maximum Age: 50 (inclusive)
Four English-speaking countries: United States, United Kingdom, Canada, Australia
Student status: No
Highest education level: Undergraduate (BA/BSc/other), Graduate (MA/MSc/MPhil/other), or Doctorate (Ph.D./MD/other) degree
Applying these sampling criteria yielded 7,275 suitable candidates from a Prolific pool of 59,325 available participants. We provided compensation of 1.50 British pounds per response, equal to 9–10£ effective hourly work rate. From the pool of eligible participants (i.e., matching the criteria above), the participants self-selected their participation, as is customary in crowdsourcing platforms (Hauser & Schwarz, Citation2016).
3.5.2. Instructing the participants
The participants were asked to tell what they think about two personas, without mentioning that one contains explanations, and the other one does not. The concept of persona was defined (“A persona is a fictive person describing a customer group.”), and it was explained that the purpose of the study is to understand better how individuals perceive personas. The participants were encouraged to review the information carefully and give their honest opinions. Also, we gave the participants a scenario that corresponds to a real use case of personas (Salminen et al., Citation2018) to facilitate answering. Deploying a realistic scenario was considered necessary as the use of personas is tied to a specific use case (Cooper, Citation1999). The task was as followsFootnote4:
Imagine you are given a task of creating a YouTube video for the persona you will be shown next. Keeping this task in mind, please carefully review the information in the persona profile to understand who the persona is. After reviewing the persona profile, you will be presented with a series of statements asking your opinion on a scale from “Strongly disagree” to “Strongly agree”.
Although it was not explicitly ensured that the participants had experience in online content creation, nearly every online user has created some type of content on social media. Furthermore, we received no questions or feedback that would indicate that the participants had not understood the task in a way where it was intended. We have previously deployed similar tasks for persona perception experiments, and they have been found to work in practice (Salminen et al., Citation2018).
3.5.3. Validating the quality of the responses
To maintain the quality of the collected data, participants that had answered one survey were excluded from answering the other surveys by using the custom blacklist function of Prolific to avoid repetitive responses by the same participants. Also, we applied an attention check question (“Your attention is important for collecting valid answers. Please choose ‘I disagree’ to answer this question”) to verify that the participants pay proper attention to the survey (Hauser & Schwarz, Citation2016). The collected responses were manually evaluated, and we found all participants passing the attention check.
Moreover, we paid attention to the survey completion time. Initially, we excluded responses that were under 6 minutes long, as this number seemed reasonable minimum time for filling in the survey based on our trials. We abandoned this strategy after most of these participants personally contacted us and explained that they had taken enough time to answer truthfully. As they were, in many cases, able to recall precise details about the personas, we kept these answers.
Note also that the platform applies sophisticated mechanisms for bot detection, including IP filtering, monitoring of unusual usage patterns, and so onFootnote5. Thus, none of the data was removed after evaluation, yielding a total of 412 responses (103 per sequence).
3.5.4. Description of the participants
summarizes information about the participants. The average age of the participants was 33.5 years (min = 23, max = 50). 63% of the sample were females, 37% were males. The participants were generally well-educated, with 67% having an undergraduate degree, 29% graduate degree, and 4% doctoral degree. The nationalities of the participants consist of four English-speaking countries: United Kingdom (63%), United States (31%), Canada (5%), and Australia (1%). Regarding the participants’ experience with personas, 69% of the participants had no prior experience with personas and 31% had prior experience with using personas. Note that we provided all the participants with a definition of what a persona is. In addition, we conduct a separate analysis including only participants with previous experience with personas in Section 4.4.
Table 4. Descriptive information about the participants
4. Results
4.1. Data processing and analysis procedure
The obtained responses were grouped in four distinct conditions, depending on which persona was presented first (either the male one, “Marcus”, or the female one, “Eva”), and which persona was transparent. We also included Persona Gender and Participant Gender as control variables, because previous research has shown that both the gender of the persona user and the persona itself can have effects on how the persona is perceived (Hill et al., Citation2017; Marsden & Haag, Citation2016). Before conducting the analysis, the data was re-arranged to disentangle the transparency variable (so it could be used as a within-subjects factor) and the Persona Gender variable (to be used as a between-subjects factor and control variable). This resulted in having, for each participant, (a) a set of Non-transparency measurements and a set of Transparency measurements, as well as (b) a Transparency-Gender variable that indicated whether the transparency measurement was male or female.
The Participant Gender was also included as a control variable. This allowed the usage of a repeated-measures mixed MANOVA (Hair, Black, Babin, & Anderson, Citation2009; Maroco, Citation2003) that allowed determining whether the Transparency measurements were significantly different from the Non-transparency condition and whether the differences were influenced by the persona’s gender. The MANOVA also has the benefit of accounting for the observed degree of interdependence that exists between the dependent variables (correlations ranging from 0.114 to 0.535).
4.2. Findings
For the within-subject effects, we observe a significant effect in the transparency condition (Pillai’s Trace = 0.136, F(8, 430) = 8.484, η2p = .136, p < .001), which indicates that at least one measurement was significantly different between the Transparency and Non-transparency conditions. Further investigation reveals significant differences in several variables, which are summarized in .
Table 5. Univariate tests for within-subjects effects of nontransparent and transparent persona profiles (df(error) = 1 (439))
First, regarding Completeness, the Transparency condition has significantly higher scores. Clarity also exhibits significant differences, with Transparency scoring higher. The results for Credibility are significantly different across conditions, but with Non-transparency scoring higher. Therefore, Transparency significantly affects user perceptions of Completeness, Clarity, and Credibility. The transparent condition increases Completeness and Clarity but decreases Credibility. In contrast, transparency has no significant effect on Usefulness and Empathy.
4.3. Gender effects
For Transparency-Gender, we observe a significant effect (Pillai’s Trace = 0.052, F(8, 430) = 2.965, η2p = .052, p < .01), indicating that at least one of the dependent variables differed across Transparency-Gender groups. When controlling the persona’s gender, we find a significant effect for several variables, including Completeness, Usefulness, Clarity, and Empathy (see ).
Table 6. Univariate tests for between-subjects effects of nontransparent and transparent persona profiles controlling for the gender of the persona (df(error) = 1 (439))
Moreover, there is a significant interaction effect between Transparency and Transparency-Gender (Pillai’s Trace = 0.041, F(8, 430) = 2.299, η2p = .041, p < .05), which indicates that at least one of the measurement differences is significantly influenced by the persona’s gender. Note that the Participant Gender exhibited no significant effects (Pillai’s Trace = 0.050, F(8, 430) = 1.395, η2p = .025, p = .136), but was maintained in the model for control purposes.
shows an interaction effect between Transparency and persona Gender, with this interaction influencing Completeness, Credibility, and Empathy. For Completeness, only marginal differences are observed across conditions for the male persona. For the female persona, the differences across conditions are much more substantial, with the Transparent version of Eva scoring higher for Completeness than the nontransparent version. Regarding Credibility, Transparency lowers this score for both Marcus and Eva, but the effect is slightly more pronounced on Marcus. Moreover, Transparency lowers Empathy for the male persona but increases it for the female persona.
Table 7. Univariate tests for within-subjects effects of nontransparent and transparent persona profiles (df(error) = 1 (439))
Overall, these results imply that gender of the persona is impactful for the participant perceptions, which we will address in the discussion.
4.4. Summary of results
summarizes the results of the hypothesis testing along with providing brief explanations. We further elaborate these interpretations in the Discussion section. Regarding the reliability of the findings, we note that for all scales and across transparency conditions, skewness for all scales is < |3| and kurtosis is < |10|, indicative of satisfactory multivariate normality for assumption purposes (Kline, Citation2015).
Table 8. Hypothesis results. Positive support is denoted with (✓) and lack of support with (-)
4.5. Subsample analysis
For additional robustness, we re-ran the analysis using only participants who had previous experience with personas, i.e., leaving out participants who reported no experience with personas, as, in some sense, the answers from these participants can be considered as more “valid” due to their greater understanding of personas in general. This sample comprised of 128 participants. For the sake of parsimony, this section will focus merely on results which differ from the global sample analysis.
For within-subject effects, the results for this sub-sample largely match the findings from the global sample analysis. The exception is Clarity, which is no longer exhibits significant differences across transparency conditions (F(1, 131) = 2.487, η2p = .019, p = .117). The Transparency * Transparency-Gender interaction ceases to be significant entirely (Pillai’s Trace = 0.098, F(8, 124) = 1.688, η2p = .098, p = .108), indicating that the persona’s gender does not affect the nature of the differences across conditions for those experienced with personas. This is further corroborated that, for the between-subjects effects, there are no differences for any of the measures regarding the gender of the persona, unlike what occurred in the global sample (Pillai’s Trace = 0.037, F(16, 124) = 0.590, η2p = .037, p = .785).
5. Discussion
5.1. Positive effects of added transparency in data-driven personas
This research shows interesting results on the effects of persona transparency on user perceptions, most notably, that Transparency (a) increases Completeness and Clarity of personas, and (b) decreases Credibility of the personas. We explain the impact of transparency on Completeness and Clarity such that the explanations facilitate understanding of the personas. In brief, persona information is easier to understand when explanations are provided. This interpretation is in line with prior research of transparency in other application contexts when dealing with algorithmic opaqueness (Kizilcec, Citation2016).
The fact that Completeness increases with the addition of explanations suggest that explanations are treated as additional information that enhances the completeness of the persona, resulting in more “rounded” personas (the term from (Nielsen, Citation2019)). This proposition is highly interesting, since the extant persona literature has only considered the persona attributes as important information for end users (Nielsen, Citation2013; Nielsen & Hansen, Citation2014), while providing persona users with explanations as to how and why the persona is created has largely been neglected in previous research.
Our findings suggest that explanations have informative power that enhances the sense of fulfillment in terms of individuals’ information needs for a user-related task. Moreover, since both empathy (Nielsen, Citation2019; Norman, Citation2004) and usefulness (Rönkkö et al., Citation2004) are considered as key perceptions of personas, the fact that transparency does not decrease these perceptions is a desirable outcome for transparency efforts in the persona context. Based on our findings, added explanations do not appear to make the personas less “human-like” or less useful.
5.2. Negative effects of added transparency in data-driven personas
The discovered negative impact on Credibility extends the previous works on adverse effects of transparency in other contexts where algorithmic systems have been explained to end users (Ananny & Crawford, Citation2018; Seaver, Citation2013). This findings proposes a trade-off between increasing transparency and retaining human-like characteristics of the persona. To us, it was surprising that Credibility decreased with the additional explanations, as we hypothesized the opposite effect. We speculate that either the explanations were not adequately implemented, or individuals found them to make the persona less believable as a human being. The former explanation is in line with previous literature that mentions the challenge of actually implementing transparency in real systems (Kizilcec, Citation2016), which often has unintended consequences for user experience, while the latter explanation suggests that care should be taken when increasing the transparency of personas, so that the perceived credibility of the persona is not compromised. In particular, the added explanations may raise further questions about the persona, especially if the information provided is not comprehensive or clear for the persona users.
5.3. Gender effects
The univariate tests for between-subject effects reveal that the gender of the persona affects the way it is perceived by the participants. The gender of the persona significantly affected scores for several variables, including Completeness, Usefulness, Clarity, and Empathy. Moreover, increased transparency of the female persona has a notable positive effect on Completeness and Empathy (). Conversely, increased transparency of the male persona has a negative effect on several constructs. Therefore, it appears that there is some gender stereotyping taking place among the participants (both males and females).
Figure 4. Eve Persona Profile without explanations. The use of more detailed explanations in the profile of Eve had a positive effect on Completeness and Empathy of the female persona
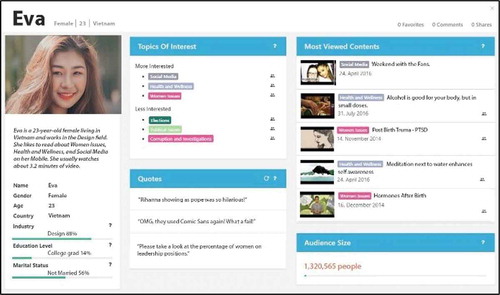
These findings extend and in some ways challenge the prior work of stereotypes in personas (Hill et al., Citation2017; Marsden & Haag, Citation2016; Salminen et al., Citation2018), and they provide grounds to presume that male and female personas are perceived differently by at least some end users. Hill et al. (Hill et al., Citation2017) argue that personas are known to promote gender stereotyping, although their study focuses on showing multiple persona pictures with different genders as a way of increasing inclusivity, rather than analyzing the gender stereotyping per se. Our results provide empirical evidence that the gender of the persona interacts with several persona perceptions that are considered important for application of personas. Even though these gender effects require further investigation, we note that there are indications from prior work in other domains (Thelwall & Stuart, Citation2019) that the quantity and type of information provided can affect how females are perceived (Bradley, Roberts, & Bradley, Citation2019). This additionally may impact how male/female personas (and the audiences they represent) are understood within organizations. As such, this is an interesting area for future research, with implications for better understanding users with personas.
5.4. Limitations and future work
Like most research, ours comes with limitations. First, regarding our results, there is a potential issue of representativeness of the experimental sample concerning the actual population of persona end users. 31% of the participants indicated that they were at least slightly experienced with the use of personas, whereas the remaining 69% had no prior experience on the use of personas. Thus, instead of claiming generalizability on persona users, our results are to be taken as individuals’ general perceptions of personas. Although we provided both a clear definition of what personas are and a straightforward task that required no particular skills or sophistication, it is always possible that the end users of personas in another context would react to the persona profiles differently. To investigate whether the difference in experience level matters, we conducted the sub-sample analysis. The analysis showed that most results were consistent between the global sample and the subsample of more experienced participants, apart from the Clarity construct and the impact of gender. To further substantiate our findings, therefore, repetitive experiments are needed.
Second, the persona treatments themselves were subject to limitations. We chose two young personas that, albeit being truthful to the underlying data, might arouse specific stereotypes in the participants’ thinking (e.g., regarding race, gender), as image processing is a complex cognitive task (Chen et al., Citation2018). On the other hand, previous research quite strongly postulates that there is no known method to avoid bias in the interpretation of personas (Hill et al., Citation2017; Salminen et al., Citation2018) and that stereotyping is an essential part of the subjective persona experience (Marsden & Haag, Citation2016). Thus, the only way to account for the bias is to increase the number of personas that are being compared for each condition to account for differences in racial, cultural, gender, and other demographic aspects that can be inferred from a persona. For example, the race of the persona, as shown in , is a potential confounding factor that we did not control. Moreover, the similarity between the participants and the deployed personas (in terms of age, gender, ethnicity) could impact end-user perceptions, and its investigation could particularly shed more light on the observed gender effect. Related to this, given that gender identity is fluid, it would be interesting investigate other gender identifications to see the possible reactions to the transparency of personas. These confounding factors should, therefore, be included as variables in future studies on persona transparency.
Figure 5. The racial difference between the personas may be a confounding factor in the analysis of the persona’s gender and effect on perceptions, with Marcus being black and Eva being Asian. This is an area for future research
5.5. Takeaways for practitioners
Overall, determining the “right” level of transparency in data-driven personas is challenging, mainly due to the complexity of the information and computational methods that are used in creating these personas. Too technical explanations are likely to be non-useful; but too simplistic explanations undermine the complexities involved in data-driven persona creation. For design practices, it is important to test alternative ways to introduce transparency and visual clues (Jiang, Guo, Yaping, & Shiting, Citation2019), both in terms of user interface (e.g., pop ups, additional boxes, explainer videos, etc.). Due to research limitations, we could implement the explanations only in one specific way; however, it is apparent that the way algorithmic transparency is implemented can itself have an impact on user perceptions. Therefore, future research should test ways of implementing transparency while tackling the observed “transparency trade-off,” so that the credibility of the persona is not compromised.
In brief, we summarize the persona design implications as follows:
The positive impact on Completeness and Clarity implies that explanations are useful for the end users of personas and should be made available to them. However, this does seem to come at the cost of reduced Credibility of the persona.
Implementing algorithmic transparency involves design choices when developing persona profiles. Devising ways of displaying explanations may be as central as the content of the explanations themselves. Persona creators are encouraged to test the impact of explanations on the perceptions of their end users before implementing them to final personas, paying careful attention that the explanations do not harm the credibility of the persona.
Because transparency seems to have a more pronounced effect on female personas, for organizations employing female personas, increased transparency may help in alleviating negative stereotyping by end users and result in higher acceptance of these personas.
Transparency is beneficial but becomes less so as decision makers become more experienced with personas. Therefore, for organizations employing personas, increased transparency is especially important for those who are novices with the use of personas.
6. Conclusion
Personas are a widely used technique in design and marketing, and computational techniques along with new data sources centered on social media and online analytics provide innovative opportunities for data-driven persona generation. However, making these techniques and the resulting persona representations understandable and credible for end users is a key ambition. Our findings show that transparency in persona profiles increases the perceived completeness and clarity of personas but decreases their credibility. Perceived empathy and usefulness have no significant change. More experimental work is needed to find optimal ways of introducing transparency for personas.
Additional information
Notes on contributors
Joni Salminen
Joni Salminen is a postdoctoral researcher at Qatar Computing Research Institute, HBKU; and at Turku School of Economics. His current research interests include automatic persona generation from social media and online analytics data, the societal impact of machine decision-making (#algoritmitutkimus), and related social computing topics.
Joao M. Santos
Joao M. Santos is a researcher based at the Lisbon University Institute (ISCTE-IUL) in Portugal. João collaborates regularly with other higher education institutions such as Instituto Superior Técnico (IST) in Portugal and the University of Hong Kong, and also provides consultancy for governments, trans-national organizations, and private businesses.
Soon-Gyo Jung
Soon-gyo Jung is a software engineer focused on news/data analytics and implementing related systems at Qatar Computing Research Institute. He received a B.E. degree in computer software from the Kwangwoon University, Seoul, Korea, in 2014, and an M.S. degree in electrical and computer engineering from the Sungkyunkwan University, Suwon, Korea, in 2016.
Motahhare Eslami
Motahhare Eslami is a PhD candidate at University of Illinois at Urbana-Champaign. She is working in Social Spaces Group with Karrie Karahalios. She will start at the Computer Science department of CMU in Fall 2020 as an assistant professor.
Bernard J. Jansen
Bernard J. Jansen is a Principal Scientist in the social computing group of the Qatar Computing Research Institute. He is a graduate of West Point and has a Ph.D. in computer science from Texas A&M University. Professor Jansen is editor-in-chief of the journal, Information Processing & Management (Elsevier).
Notes
4. Note: this was a fictitious task, and the participants did not actually create videos.
References
- Ananny, M., & Crawford, K. (2018). Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media & Society, 20(3), 973–989. doi:https://doi.org/10.1177/1461444816676645
- An, J., Kwak, H., & Jansen, B. J. (2016). Towards automatic Persona generation using social media. Proceedings of Third International Symposium on Social Networks Analysis, Management and Security (SNAMS 2016), The 4th International Conference on Future Internet of Things and Cloud, IEEE, Vienna, Austria. 22–24 August.
- An, J., Kwak, H., & Jansen, B. J. (2017). Personas for content creators via decomposed aggregate audience statistics. Proceedings of advances in social network analysis and mining (ASONAM 2017). Presented at the Advances in Social Network Analysis and Mining (ASONAM 2017), July 31, Sydney, Australia.
- An, J., Kwak, H., Jung, S.-G., Salminen, J., & Jansen, B. J. (2018). Customer segmentation using online platforms: Isolating behavioral and demographic segments for persona creation via aggregated user data. Social Network Analysis and Mining, 8, 1.
- An, J., Kwak, H., Salminen, J., Jung, S.-G., & Jansen, B. J. (2018). Imaginary people representing real numbers: Generating personas from online social media data. ACM Transactions on the Web (TWEB), 12, 3.
- Blase, U., Leon, P. G., Cranor, L. F., Shay, R., & Wang, Y. (2012). Smart, useful, scary, creepy: Perceptions of online behavioral advertising. Proceedings of the eighth symposium on usable privacy and security (p. 4). ACM, Washington, DC. doi:https://doi.org/10.1094/PDIS-11-11-0999-PDN
- Blomquist, A., & Arvola, M. (2002). Personas in action: Ethnography in an interaction design team. Proceedings of the second Nordic conference on Human-computer interaction (pp. 197–200). ACM, Aarhus, Denmark.
- Bradley, S. W., Roberts, J. A., & Bradley, P. W. (2019). Experimental evidence of observed social media status cues on perceived likability. Psychology of Popular Media Culture, 8(1), 41–51. doi:https://doi.org/10.1037/ppm0000164
- Chapman, C. N., Love, E., Milham, R. P., ElRif, P., & Alford, J. L. (2008). Quantitative evaluation of Personas as information. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 52(16), 1107–1111. doi:https://doi.org/10.1177/154193120805201602
- Chapman, C. N., & Milham, R. P. (2006). The Personas’ new clothes: Methodological and practical arguments against a popular method. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 50(5), 634–636. doi:https://doi.org/10.1177/154193120605000503
- Chen, J., Wang, D., Xie, I., & Quan, L. (2018). Image annotation tactics: Transitions, strategies and efficiency. Information Processing & Management, 54(6), 985–1001. doi:https://doi.org/10.1016/j.ipm.2018.06.009
- Cooper, A. (1999). The Inmates Are Running the Asylum: Why high tech products drive us crazy and how to restore the sanity. Indianapolis, IN: Sams - Pearson Education.
- Dantin, U. (2005). Application of personas in user interface design for educational software. Proceedings of the 7th Australasian conference on Computing education-Volume 42 (pp. 239–247). Australian Computer Society, Inc., Newcastle, New South Wales, Australia. doi:https://doi.org/10.1007/s11171-005-0029-1
- Diakopoulos, N., & Koliska, M. (2017). Algorithmic transparency in the news media. Digital Journalism, 5(7), 809–828. doi:https://doi.org/10.1080/21670811.2016.1208053
- Driscoll, K., & Walker, S. (2014). Big data, big questions| working within a black box: Transparency in the collection and production of big Twitter data. International Journal of Communication, 8, 20.
- Eslami, M., Rickman, A., Vaccaro, K., Aleyasen A., Vuong A., George Karahalios K., ..., Sandvig C. (2015). “I always assumed that I wasn’T really that close to [Her]”: Reasoning about invisible algorithms in news feeds. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (pp. 153–162). ACM, Seoul, Republic of Korea.
- Eslami, M., Vaccaro, K., Karahalios, K., & Hamilton, K. (2017). “Be careful; Things can be worse than they appear”: Understanding biased algorithms and users’ behavior around them in rating platforms. Proceedings of the 11th International AAAI Conference on Web and Social Media (ICWSM) (pp. 62–71). Montréal, Canada.
- Eslami, M., Krishna Kumaran, S. R., Sandvig, C., & Karahalios, K. (2018). Communicating algorithmic process in online behavioral advertising. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, ACM, (pp.432), ACM, Montréal, Canada.
- Goodwin, K. (2009). Designing for the digital age: How to create human-centered products and services. Indianapolis, IN: Wiley.
- Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2009). Multivariate data analysis. Upper Saddle River, NJ: Pearson.
- Hauser, D. J., & Schwarz, N. (2016). Attentive Turkers: MTurk participants perform better on online attention checks than do subject pool participants. Behavior Research Methods, 48(1), 400–407. doi:https://doi.org/10.3758/s13428-015-0578-z
- Herlocker, J. L., Konstan, J. A., & Riedl, J. (2000). Explaining collaborative filtering recommendations. Proceedings of the 2000 ACM conference on Computer supported cooperative work (pp. 241–250). ACM, Philadelphia, PA.
- Hill, C. G., Haag, M., Oleson, A., Mendez, C., Marsden, N., Sarma, A., & Burnett, M. (2017). Gender-Inclusiveness Personas vs. Stereotyping: Can we have it both ways? Proceedings of the 2017 CHI Conference (pp. 6658–6671). ACM Press, Denver, CO.
- Jahanbakhsh, F., Wai-Tat, F., Karahalios, K., Marinov, D., & Bailey, B. (2017). You want me to work with who?: Stakeholder perceptions of automated team formation in project-based courses. Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (pp. 3201–3212). ACM, Denver, CO.
- Jenkinson, A. (1994). Beyond segmentation. Journal of Targeting, Measurement and Analysis for Marketing, 3(1), 60–72.
- Jerison, H. J. (1959). Effects of noise on human performance. Journal of Applied Psychology, 43(2), 96. doi:https://doi.org/10.1037/h0042914
- Jiang, T., Guo, Q., Yaping, X., & Shiting, F. (2019). A diary study of information encountering triggered by visual stimuli on micro-blogging services. Information Processing & Management, 56(1), 29–42. doi:https://doi.org/10.1016/j.ipm.2018.08.005
- Khashe, S., Lucas, G., Becerik-Gerber, B., & Gratch, J. (2019). Establishing social dialog between buildings and their users. International Journal of Human–Computer Interaction, 35(17), 1–12.
- Kizilcec, R. F. (2016). How much information?: Effects of transparency on trust in an algorithmic interface. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 2390–2395). ACM, San Jose, CA.
- Kline, R. B. (2015). Principles and practice of structural equation modeling. New York, NY: Guilford publications.
- Kwak, H., An, J., & Jansen, B. J. (2017). Automatic generation of Personas using Youtube social media data. Proceedins of the Hawaii International Conference on System Sciences (HICSS-50) (pp. 833–842), Waikoloa, HI.
- Lee, D. D., & Sebastian Seung, H. (1999). Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755), 788–791. doi:https://doi.org/10.1038/44565
- LeRouge, C., Jiao, M., Sneha, S., & Tolle, K. (2013). User profiles and personas in the design and development of consumer health technologies. International Journal of Medical Informatics, 82(11), e251–e268. doi:https://doi.org/10.1016/j.ijmedinf.2011.03.006
- Liu, T., Du, J., Cai, H., Farmer, R., Jiang, L., & Fenglin, B. (2016). Personas in O2O mobile healthcare: A method for identifying and creating user groups. e-Business Engineering (ICEBE), 2016 IEEE 13th International Conference on, IEEE (pp. 100–107), Macau, China.
- Mahmut, E. (2016). User experience design of a prototype Kiosk: A case for the Istanbul public transportation system. International Journal of Human–Computer Interaction, 32(10), 802–813. doi:https://doi.org/10.1080/10447318.2016.1199179
- Maroco, J. (2003). Análise estatística com utilização do SPSS. Lisboa, Portugal: Silabo.
- Marsden, N., & Haag, M. (2016). Stereotypes and politics: Reflections on personas. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 4017–4031). ACM, San Jose, CA.
- Matthews, T., Judge, T., & Whittaker, S. (2012). How do designers and user experience professionals actually perceive and use personas? Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 1219–1228). ACM, Austin, TX.
- McGinn, J. J., & Kotamraju, N. (2008). Data-driven persona development. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 1521–1524). ACM, Florence, Italy.
- Nielsen, L. (2013). Personas - user focused design. London, UK: Springer Science & Business Media.
- Nielsen, L. (2019). Personas - user focused design. New York, NY: Springer.
- Nielsen, L., & Hansen, K. S. (2014). Personas is applicable: A study on the use of personas in Denmark. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp.1665–1674). ACM, Toronto, ON.
- Nielsen, L., Hansen, K. S., Stage, J., & Billestrup, J. (2015). A template for design Personas: Analysis of 47 Persona descriptions from Danish industries and organizations. International Journal of Sociotechnology and Knowledge Development, 7(1), 45–61. doi:https://doi.org/10.4018/IJSKD
- Nissenbaum, H. (2009). Privacy in context: Technology, policy, and the integrity of social life. Palo Alto, CA: Stanford University Press.
- Norman, D. A. (2004). Ad-Hoc Personas & empathetic focus [Personal website] Retrieved November 4, 2019, from Jnd.org website: http://www.jnd.org/dn.mss/personas_empath.html.
- Palan, S., & Schitter, C. (2018). Prolific. ac—A subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17, 22–27. doi:https://doi.org/10.1016/j.jbef.2017.12.004
- Pasquale, F. (2015). The black box society: The secret algorithms that control money and information. Cambridge, MA, USA: Harvard University Press.
- Peer, E., Brandimarte, L., Samat, S., & Acquisti, A. (2017). Beyond the Turk: Alternative platforms for crowdsourcing behavioral research. Journal of Experimental Social Psychology, 70, 153–163. doi:https://doi.org/10.1016/j.jesp.2017.01.006
- Pruitt, J., & Adlin, T. (2006). The Persona lifecycle: Keeping people in mind throughout product design. Boston, MA: Morgan Kaufmann.
- Pruitt, J., & Grudin, J. (2003). Personas: Practice and theory. Proceedings of the 2003 Conference on Designing for User Experiences (pp. 1–15). ACM, San Francisco, CA.
- Rader, E. J. (2014). Awareness of behavioral tracking and information privacy concern in Facebook and Google. SOUPS. (pp.51–67).
- Rönkkö, K., Hellman, M., Kilander, B., & Dittrich, Y. (2004). Personas is not applicable: Local remedies interpreted in a wider context. Proceedings of the Eighth Conference on Participatory Design: Artful Integration: Interweaving Media, Materials and Practices - Volume 1 (pp. 112–120). ACM.
- Salminen, J., Jansen, B. J., An, J., Kwak, H., Jung, S.-G. (2018). Are personas done? Evaluating their usefulness in the age of digital analytics. Persona Studies, 4(2), 47–65. doi:https://doi.org/10.21153/psj2018vol4no2art737
- Salminen, J., & Jansen, B. J. (2018). Use cases and outlooks for automatic analytics. arXiv:1810.00358 [cs]. Toronto, ON.
- Salminen, J., Jung, S.-G., An, J., Kwak, H., Nielsen, L., & Jansen, B. J. (2019). Confusion and information triggered by photos in persona profiles. International Journal of Human-computer Studies, 129, 1–14.
- Salminen, J., Kwak, H., Santos, J. M., Jung, S.-G., An, J., & Jansen, B. J. (2018). Persona perception scale: Developing and validating an instrument for human-like representations of data. CHI’18 Extended Abstracts: CHI Conference on Human Factors in Computing Systems Extended Abstracts Proceedings, Montréal, Canada.
- Salminen, J., Nielsen, L., Jung, S.-G., An, J., Kwak, H., & Jansen, B. J. (2018). “Is more better?”: Impact of multiple photos on perception of persona profiles. Proceedings of ACM CHI Conference on Human Factors in Computing Systems (CHI2018), Montréal, Canada.
- Salminen, J., Şengün, S., Kwak, H., Jansen, B. J., An, J., Jung, S.-G., & Harrell, D. F. (2018). From 2,772 segments to five personas: Summarizing a diverse online audience by generating culturally adapted personas. First Monday, 23, 6. doi:https://doi.org/10.5210/fm.v23i6.8415
- Salminen, J., Jansen, B. J., An, J., Jung, S., Nielsen, L., & Kwak, H. (2018). Fixation and confusion – investigating eye-tracking participants’ Exposure to information in personas. Proceedings of The ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR 2018), 110–119.
- Seaver, N. (2013). Knowing algorithms. Media in Transition 8. Cambridge, MA: April.
- Stevenson, D. M. (2016). Data, trust, and transparency in personalized advertising (PhD Thesis). University of Michigan. Retrieved from https://deepblue.lib.umich.edu/handle/2027.42/133246?show=full
- Stoyanovich, J., Abiteboul, S., & Miklau, G. (2016). Data, responsibly: Fairness, neutrality and transparency in data analysis. International Conference on Extending Database Technology, Bordeaux, France.
- Thelwall, M., & Stuart, E. (2019). She’s Reddit: A source of statistically significant gendered interest information? Information Processing & Management, 56(4), 1543–1558. doi:https://doi.org/10.1016/j.ipm.2018.10.007
- Yao, Y., Re, D. L., & Wang, Y. (2017). Folk Models of online behavioral advertising. Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (CSCW’17), 1957–1969. Portland, Oregon.
- Zhang, X., Brown, H.-F., & Shankar, A. (2016). Data-driven personas: Constructing archetypal users with Clickstreams and user telemetry. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 5350–5359). ACM, San Jose, CA.