
ABSTRACT
Morphological variability in bilingual language production is widely attested. Producing inflected words has been found to be less reliable and consistent in bilinguals than in first-language (functionally monolingual) L1 speakers, even for bilingual speakers at advanced proficiency levels. The sources for these differences are not well understood. The current study presents a detailed investigation of morphological generalization processes in bilingual speakers’ language production. We examined past participle formation of German using an elicited-production experiment containing nonce verbs with varying degrees of similarity to existing verbs testing a large group of bilingual Turkish/German speakers relative to L1 German speakers. We compared similarity-based lexical extensions with generalizations of morphological rules. The results show that rule-based generalizations are used less often and more variably within the bilingual group than within the L1 group. Our results also show a selective effect of age of acquisition on the bilingual speakers’ morphological generalizations.
1. Introduction
It is well known from many previous studies that inflectional morphology can be persistently hard for bilingual speakers, particularly for late second-language (L2) learners who began to learn the L2 after childhood; see White (Citation2003, chapter 6) for a review. Inflectional morphemes may sometimes be present, on occasion omitted, and at times incorrectly used in bilinguals’ language production in the same circumstances in which first-language (L1) speakers of the same language consistently produce these forms; see also Meisel (Citation2011:63ff.). Morphological variability in bilinguals has previously been examined mainly with respect to accuracy rates on existing vocabulary items in spontaneous or elicited production data and in judgment tasks. However, there are methodological concerns with these data types. White (Citation2003:199f.) argued that accuracy rates should not be taken at face value and that even if a particular morpheme yields reduced accuracy scores, this may reflect difficulties in accessing the surface form of this morpheme but not necessarily indicate a lack of grammatical knowledge. Furthermore, it is well known that judgments of acceptability involve subtle and noisy processes, requiring conscious, metalinguistic access. The present study examines a different but crucial property of inflectional processes—that they can be easily applied to nonce or unusual words under appropriate circumstances. Generalization properties provide a crucial diagnostic for determining productivity in morphology. Our focus is on morphological productivity in bilinguals, and we specifically ask whether generalization processes are more variable in bilinguals than in L1 speakers and if so what the source(s) of this additional variability might be.
Morphological productivity has previously mainly been investigated for inflectional processes such as the English past tense (e.g., Bybee & Moder Citation1983; Prasada & Pinker Citation1993). Some inflectional patterns—e.g., -ed affixation—seem to be productively extendable in an unbounded fashion (i.e., even to nonce items that are very dissimilar to existing forms in the language), effectively behaving as a default. Irregular past-tense forms, on the other hand, are lexically conditioned in that they generalize only to nonce items that resemble clusters of existing verbs. The division between lexically conditioned and unbounded generalizations is most explicitly incorporated in dual-morphology models (e.g., Clahsen Citation1999; Pinker Citation1999; Pinker & Ullman Citation2002) that posit two fundamentally different mechanisms for morphological generalization: firstly, a grammatical rule or operation that is lexically unconditioned, e.g., adding the English regular -ed affix to a verbal root; and secondly, analogical extensions through similarity-based associations with existing lexical items, e.g., splang as a past-tense form for the nonce verb to spling in English, in analogy to existing verbs such as sing–sang or ring–rang. As an alternative, a class of single-mechanism accounts proposes that morphological generalization relies on a single mechanism that is sensitive to a nonce word’s overlap with existing lexical items (e.g., Bybee Citation1995; Elman et al. Citation1996; Plunkett & Marchman Citation1996). Under this view, generalizations that appear to be due to a rule-based operation (e.g., -ed generalizations to nonce verbs) are taken to be extensions of the most frequent and phonologically most heterogeneous pattern. Although in English past-tense formation -ed forms are certainly highly frequent and heterogeneous, the question of whether default-like morphological generalization in other inflectional systems and in other languages can be explained in these terms remains controversial (see, e.g., Clahsen Citation1992).
It has been argued that morphological generalization processes in bilinguals, particularly in adult L2 speakers, differ from those in L1 speakers. A prominent account is Ullman’s (Citation2020) proposal of two distinct brain memory systems, a declarative subsystem that is involved in learning and storing lexical items, and a procedural subsystem for learning and processing grammatical rules. Assuming this distinction, Ullman (Citation2020) argued that due to maturational changes, adults invoke their procedural system to a lesser extent for language learning and processing than children. As a result, morphological generalization in a late-learned L2 should rely less on rule-based processes than in an L1 (and more on declarative memory). Empirical evidence for this contrast is currently scarce and mixed, however. For English, neither of the two previous elicited-production studies (Murphy Citation2004; Leung Citation2006) found any reliable L1/L2 between-group differences in past-tense-form generalization to nonce words. Instead, both speaker groups overall preferred -ed (rather than irregularized forms) as the past tense of nonce verbs and exhibited (almost equally) low levels of irregularizations. By contrast, Cuskley et al. (Citation2015) found that nonnative L2 speakers provided significantly fewer -ed past-tense forms for novel verbs (relative to irregular ones) than L1 speakers of English, in line with Ullman’s (Citation2020) conjecture that L2 learners rely less on rule-based processes for morphological generalization than L1 speakers. Morphological generalization processes in bilingual speakers have been studied for many languages other than English (e.g., Hebrew: Farhy Citation2020; Greek: Clahsen, Martzoukou & Stavrakaki Citation2010; Dutch: Rispens & Bree Citation2015; Spanish: Fernández-Dobao & Herschensohn Citation2021; Russian: Gor & Cook Citation2010; Welsh: Thomas et al. Citation2014), but a comprehensive review of this research is beyond the scope of the present study. There are also studies on morphological generalization in German, particularly of past-participle formation. As the current study builds on the findings from these studies, we present a detailed report of these studies in the following section.
2. Previous studies on morphological productivity (with particular reference to German past-participle formation)
Periphrastic constructions consisting of a finite auxiliary (in the present tense) and a nonfinite (past-participle) form are common in German to express past-time events. For instance, ‘Yesterday I bought a book’ typically comes out in German as Gestern habe ich ein Buch gekauft. Past participles consist of the verb stem, the endings -t or -n, and—depending on the verb stem’s stress—the augment ge-. When the main stress is on the first syllable of the verb (which is most commonly the case in German), ge- is added; compare, for example, the following two participle forms, one with and the other without ge- ´übersetzen—´übergesetzt ‘to cross–crossed’ vs. übersétzen–übersétzt ‘to translate–translated.’ All past-participle forms of German carry one of two endings, -t or -n. Although -t participle suffixation is highly productive, which for the most common (so-called weak) verbs is combined with the unmarked base stem, verbs that take -n participles represent a lexically closed class of approximately 170 (so-called strong) verb roots (Grundverben). Furthermore, stem allomorphy among participle forms is largely restricted to -n participles, e.g., gehen–gegangen ‘to go–gone,’ even though many -n participle forms do not exhibit stem changes, e.g., schlafen–geschlafen ‘to sleep–slept.’
Previous research on adult and child L1 speakers of German has revealed different generalization patterns for -t vs. -n participle forms. An elicited nonce verb production experiment with adult L1 speakers of German (Clahsen Citation1997) revealed that although -t participle suffixation was highly productive and readily applied to nonce verbs, even to nonce verbs that are dissimilar to existing German verbs, generalization of -n participle forms was largely restricted to nonce words that are similar to existing ones. A similar contrast was found for children’s overapplication errors. L1 German children commonly overapply -t suffixation to verbs that require -n participle forms (e.g., *gegeht instead of gegangen ‘gone’) in both spontaneous speech and in elicited production, whereas the reverse case, viz. -n forms in cases in which -t is required (e.g., getanzen instead of getanzt ‘danced’), are rare (e.g., Clahsen & Rothweiler Citation1993; Weyerts & Clahsen Citation1994). These findings have been taken to result from different morphological generalization processes (Clahsen Citation1999), unbounded lexically unconditioned generalization of the -t suffixation rule as opposed to associative extension of -n to nonce verbs by analogy to existing participle forms; see, however, the commentaries to Clahsen (Citation1999) for a critique and alternative suggestions.
There are also several studies examining morphological generalization of German participle forms in different groups of bilingual speakers. As many of these studies are only available in German, we present a somewhat more detailed summary here. Three studies tested bilingual children, two using data from spontaneous speech samples—Sterner (Citation2017) from Turkish/German children, Sopata (Citation2013) from Polish/German children—and one study (Clahsen & Jessen Citation2019) using an elicited production task with English/German children. The children tested in these three studies are early bilinguals who started to acquire German from birth or before the age of 6 years. presents the percentages of -t and -n participle overapplications in the bilingual children from Sterner (Citation2017) and Sopata (Citation2013). The percentages show that all children overgeneralized the suffix -t to verbs requiring -n participle forms considerably more often than they overapplied -n to weak verbs that require -t participles. The same contrast was found in Clahsen and Jessen’s (Citation2019) elicited production study conducted with 38 English/German bilingual children of two age groups (19 children, mean age: 9;04, 19 children, mean age: 11;10). Both age groups of children produced more -t than -n overapplications (9-year-olds: 13.5% vs. 8.9%; 11-year-olds: 11.2% vs. 5.7%). These studies show that -t participle forms are preferred over -n forms in bilingual children’s morphological generalizations, parallel to what has been reported for L1 German children and adults.
Table 1. Percentages of -t and -n participle overapplications in bilingual corpus data
A number of studies have examined morphological generalization of participle formation in late bilinguals, i.e., in adults who learned German as an L2. The results are, however, mixed and less clear than those from L1 speakers and early child bilinguals. Some studies found largely parallel rates of -t and -n overapplications in late bilinguals:
Neubauer & Clahsen (Citation2009) performed a judgment task of participle forms of denominal verbs (e.g., ein Brett befliegen ‘to put flies on a board,’ eine Fliege ‘a fly’). While L1 German speakers clearly preferred -t over -n participle forms (with mean ratings of 3.1 for -t vs. 1.7 for -n, out of a maximum of 5), a group of (proficient) L1 Polish speakers of L2 German did not show any preference (2.6 for -t vs. 2.7 for -n) in this task.
Bordag and Sieradz (Citation2012) studied written texts from adult L1 English students of L2 German and obtained almost parallel amounts of -n and -t overapplications (3.1% vs. 4.3%).
Sterner (Citation2017:139) analyzed spontaneous speech samples from two L1 Italian speakers (‘Bruno,’ ‘Giovanni’) from the ZISA data set (Clahsen, Meisel & Pienemann Citation1983) who started learning German as adults in an immersion setting. ‘Bruno’ overapplied -t to 3.2% of the participles that require -n and -n to 1.1% of the participles that require -t. The corresponding figures for ‘Giovanni’ were 6% -t vs. 8.6% -n overapplications.
Mohsenian (Citation2020) replicated the elicited-production task from Clahsen and Jessen’s (Citation2019) study with 30 adult L1 English speakers of L2 German. For the late bilinguals, Mohsenian even found significantly more -n than -t overapplications (10.4% vs. 6.4%), unlike the bilingual children studied by Clahsen and Jessen (Citation2019) in the same task who clearly preferred -t forms for participle generalization.
Attaviriyanupap (Citation2006) analyzing speech samples from 16 L1 Thai speakers of L2 German reported that most participle formation errors were bare unaffixed forms, occasional -n overapplications, and—surprisingly—no single -t overapplication.
Hahne, Mueller & Clahsen (Citation2006) replicated Clahsen’s (Citation1997) nonce-verb elicitation task with (proficient) Russian L1 speakers of L2 German and found a clear preference for -t (relative to -n) overapplications, similarly to what was previously reported for adult L1 speakers of German.
What can we conclude from these studies about morphological generalization of German participle forms in bilingual speakers? The results from early child bilinguals seem to be clear and straightforward. Nonce verb participle formation mainly relies on -t suffixation; overapplications of -n forms are less common, the same generalization pattern that was found for child and adult L1 speakers of German. For late bilinguals, a considerable number of studies reported a reduced rate of -t overapplications (relative to L1 speakers) and no clear preference for either -t or -n overapplication. Assuming that -t suffixation is rule-based and as such engages the procedural system, one may take this contrast between early and late bilinguals to be consistent with Ullman’s (Citation2020) proposal that maturational changes lead to a reduced role of the procedural memory system in late learners. It should be noted, though, that the results of studies with late bilinguals were mixed and that (most of) the reported contrasts between -t and -n overapplications in early bilinguals were not backed up by any statistical analyses. Clearly, further research is required before any safe conclusions on the nature of morphological generalizations in bilinguals can be drawn.
3. The present study
The idea that (unlike in early bilinguals) morphological generalization in late bilinguals does not function in the same way as in L1 speakers, possibly due to maturational changes, has been tested in previous research by comparing different groups and types of individuals, viz. bilingual children vs. bilingual adults and L2 vs. L1 speakers. As these speaker groups differ in multiple ways, it is not always clear what the source of any differences in their generalization behavior might be. The current study pursues a slightly different approach. In addition to a control group of adult L1 speakers of German, we investigated a large group of adult bilingual speakers who acquired Turkish from birth and started to learn German at a range of different ages, from birth to adulthood. At the time of testing, all bilingual participants were adults recruited from the large Turkish/German community residing in Berlin and Potsdam (Germany). Thus, rather than comparing children to adults, the design of our study allows for both (i) comparisons of adult bilingual speakers from roughly the same language environment who differ in their age of acquisition (AoA) of German, and (ii) comparisons of adult bilingual to (functionally monolingual) adult speakers of German. To properly assess the role of AoA, we additionally controlled for L2 proficiency as well as length of exposure to and use of German.
The purpose of the present study is to better understand morphological productivity in the bilingual speaker. Our focus is on the long-term consequences of acquiring an L2 at different ages to the mechanisms speakers employ for generalizing inflectional rules and patterns to nonce words. Following Ullman (Citation2020) and some findings from previous research, we hypothesize that when acquisition occurs relatively late in life, inflectional rules are less robust than in an L1 speaker’s grammar, possibly due to inferior procedural learning, and should consequently be underused for morphological generalization. On the other hand, similarity-based generalizations of lexically conditioned (“irregular”) morphology should be fully functional irrespective of AoA, assuming that these kinds of generalization are based on associatively linked entries in declarative memory, the acquisition of which is not supposed to change with AoA. We tested these predictions using an elicited nonce-verb production task of German participle formation.
4. Methods
4.1. Materials
We created four types of nonce words on the basis of rhyme similarity to existing German verbs. The first type shared the rhyme with strong verbs, the second one with weak verbs, the third type of rhyme was present among both weak and strong verbs, and the last type showed no rhyme similarity to any known German verb. The sample of verb types from which the nonce words were constructed is the set of 1,258 verb roots of German (Grundverben, Ruoff Citation1981), which was chosen because any additional derivational affixes or verb particles do not alter the rhyme of a verb’s basic root. To identify the three rhyme similarity types, we relied on the clusters of vowels and consonants that Köpcke (Citation1998) identified as “prototypical” for German verbs. Köpcke (Citation1998) noted, for example, that a cluster containing a short [ɪ] followed by a velar nasal [ƞ] is prototypical for strong verbs and uncommon for weak verbs (92% vs. 8%), e.g., singen ‘to sing.’ Likewise, the clusters [ɪnd] and [ɛlf] as in finden ‘to find’ and helfen ‘to help’ are typical of strong and uncommon in weak verbs. In the dLex corpus (http://www.dlexdb.de/Qgmilhc), 99.4% of the past-participle forms of verbs (Grundverben) with these clusters are -n participles (29,698/29,863). For the Irregular condition, we constructed nonce verbs from these three clusters. The second type of nonce verb (Irreg/Reg) was constructed from two VC clusters, [ɪm] and [ɛrb], e.g., stimmen ‘to be correct’ and sterben ‘to die,’ which are also more common among strong than weak verb roots but less so than those used for the Irregular condition. In the dLex corpus, 80.3% of the participle forms of verbs (Grundverben) with these two clusters have (irregular) -n participles (4,572/5,695). These two conditions were contrasted with the Regular condition for which nonce verbs were constructed from three VC clusters that are common for regular and uncommon or nonexistent for strong verb roots: [ɔʏ], [a:g], [ax] as in freuen ‘to enjoy,’ fragen ‘to ask,’ and lachen ‘to laugh.’ In the dLex corpus, 88.7% of the participle forms of verbs (Grundverben) with these three clusters are regular -t participles (65,069/73,323). Finally, we chose four VC clusters from the “no-rhyme” items of Weyerts and Clahsen (Citation1994) for our No Similarity condition, [ɔlm], [ɛpf], [a:p], and [ɪrs], and confirmed—using the dLex corpus—that there are no German verbs with any of these rhymes. For each of the four conditions, 24 nonce words were constructed, resulting in 96 nonce words in total, with each cluster equally represented within each condition.
4.2. Participants
We tested 138 individuals in two participant groups, a group of 98 Turkish-German bilinguals (BIL) who had acquired Turkish from birth and German at different ages, and a control group (CTR) of 40 native (L1) speakers of German (33 female), with a mean age of 29.9 (SD: 11.2; range 20–68 years). All participants lived in Germany at the time of testing and received a small fee for taking part in our study.
We deliberately examined a heterogeneous group of bilinguals. One participant from this group had to be excluded due to too many uninterpretable responses in the main experiment. The remaining 97 participants (61 female) had a mean age of 33.0 years (SD: 10.1; range 18–60). The BIL group had a mean age of acquisition (AoA) of German of 10.7 years (SD: 7.7) widely ranging from 0 to 30 years, a mean length of exposure to German of 21.8 years, (SD: 10.8) ranging from 3 to 54 years, and a mean (self-estimated) use of German of 63.7% (SD: 19.1, range 10-90) in a normal week covering reading, writing, speaking, and listening. To measure the BIL group participants’ skills in German, we used the European Language Certificates (telc, Citation2015). The part of the German version of the TELC test we used has a maximum score of 50 points and tests vocabulary and grammar in written cloze texts. The mean TELC score of the BIL group was high, with 43.57 (SD: 5.5), ranging from 30 to 50 points, which places the group at the C1 level according to CEFR (Council of Europe Citation2001). In addition to the TELC test, we also applied the German version of the LexTale vocabulary test to assess our participants’ vocabulary knowledge in German (Lemhöfer & Broersma Citation2012). Our BIL group reached a mean score of 75.5% (SD: 10.1), which reflects performance at the upper end of the B2 level and close to the 80% threshold for C1 (Lemhöfer & Broersma Citation2012, Table 9), again with a wide range from 46.3% to 93.8%.
The CTR group participants reported to have grown up with German only and with (at most) weekly lessons in other languages (mainly English) at school. Although at the time of testing almost all of them were able to speak and understand more than one language, this group of participants may be taken to be functionally monolingual.
4.3. Procedure
The experiment was designed with Google® Forms. The CTR group completed the task remotely via a web link, and the bilinguals were tested in a quiet room, either in a lab or at their homes. It is true that the CTR group was not tested face-to-face (unlike the BIL group), but we note that web-based testing has been found to yield reliable results in many previous psycholinguistic studies (e.g., Enochson & Culbertson Citation2015; Gibson, Piantadosi & Fedorenko Citation2011; Dillon, Clifton & Frazier Citation2014; Wagers & Phillips Citation2014; Lago, Stutter Garcia & Felser Citation2019). Prior to the experiment, the BIL group filled in a demographic questionnaire including questions about their language history and use. They also completed the TELC and the LexTale tests. Prior to the main experiment, participants received instructions about the task and were shown one example trial including a nonce verb and a blank for the corresponding participle form to be filled in. We did not, however, provide the response in this example trial in order not to bias participants toward any specific participle form. In the main experiment, each trial consisted of three lines: the infinitive form of the nonce verb, a sentence containing the nonce verb in either the first-person plural form or the third-person singular form, and finally a sentence with a blank space for participants to supply (in writing) the participle form; see Excerpt 1 for an example with the nonce verb timmen and the nonce noun Kers.
a. TIMMEN
b. Peter timmt täglich seinen Kers.
(‘Peter timms daily his kers.’)
c. Wie jeden Tag hat Peter auch gestern seinen Kers ______.
(‘Just like every day, yesterday Peter ______ his kers.’)
Each trial was presented one by one on separate screens, ensuring that participants could not see any previous or subsequent trials. Experimental sentences also contained nonce words as direct objects to reduce opportunities for semantic associations with existing verbs. Nonce verbs were presented in their infinitive and third-person singular or first-person plural present-tense forms without any stem changes. As some strong verbs include stem changes in their third-person singular present tense forms, e.g., schlafen–schläft ‘to sleep–sleeps,’ a nonce verb introduced without a stem change in its third-person singular present-tense form might have led participants toward conceiving the nonce verb as a weak verb and respond with a regular participle form. To avoid biasing participants, we did not present any such forms with stem changes to participants. Instead, 43% of the nonce verbs (41 out of 96) were presented in their first-person plural present-tense form, which do not have any stem changes (e.g., schlafen–wir schlafen ‘to sleep’–‘we sleep’). Another concern was that in addition to the infinitive ending -(e)n that appeared on all nonce verbs (see 1a), the second form in which the nonce verbs were presented (see 1b), i.e., the first-person plural and the third-person singular, contained affixes that are homophonous to the targeted participle endings -t and -n. To determine whether this influenced participants’ participle responses, we used “Form Presented”—i.e., whether a nonce verb was introduced as a first-person plural or a third-person singular form to the participants—as a covariate in our statistical models of the data.
Each trial was presented separately, and only after filling in the blank could participants continue to the next trial. Responses were not timed, and there was no time pressure for participants. The BIL participants completed the experiment in about 20 to 30 minutes.
4.4. Data analysis
Responses were coded twice according to the different output possibilities (-t vs. -n, with or without stem change), once considering only suffixes (-t = 1, -n = 0) regardless of stem type, and once considering the stems (stem change = 1, no stem change = 0) regardless of suffix type. Responses that were real words or not a possible past-participle form of German or otherwise not interpretable were removed before any further analysis. This resulted in a total of 3.37% responses removed from the BIL group’s and 1.07% from the CTR group’s data sets.
To determine the two participant groups’ participle generalization preferences for the different kinds of nonce verbs presented to them, we used generalized linear mixed-effects regression models (binomial family, with the bobyqa optimizer), with crossed random effects for participants and items (Baayen, Davidson & Bates Citation2008). Four models were fitted, each with Group (BIL, CTR) and Condition (Irreg, Reg, Irreg/Reg, No Sim) as fixed effects. We took No Similarity as the control condition, as the stimuli in this condition were dissimilar to any existing German verb. Differences to the other three conditions were calculated to assess the potential effect of a nonce verb’s similarity to existing German verbs on participle formation. Recall that all irregular (= strong) participle forms in German take -n, some with and others without stem changes, whereas all other verbs take -t participle forms. Thus, the one factor that singles out irregular (= strong) participle forms is the -n ending. Stem changes are an extra exponent of many but not all participle forms of irregular verbs and additionally, of a small group of verbs (the so-called Präteritopresentia) that have stem changes and form their participles with -t, e.g., wissen–gewußt ‘to know.’ Hence the two exponent types are not equivalent, and this is reflected in our analyses, which first examines suffix types and then as a secondary step stem changes. For the first model, responses were coded for -t responses against those with -n responses and for the second one responses with stem changes against those without stem changes. For the latter model, the participle responses produced by the participants were first split up according to their suffix (-t or -n) and then examined with respect to whether or not each of these two types contained stem changes. For main effects, sum-coded contrasts were employed to both factors (i.e., Group and Condition); for single condition comparisons, treatment contrasts were applied.
Two additional analyses were performed. If we recall, the use of grammatical morphemes in bilingual language production has been found to exhibit a large degree of inter-individual variability. This is likely to also affect the way bilinguals generalize grammatical morphemes to nonce words. We therefore assessed the variability of the generalization patterns by determining the individual participants’ difference from the group’s means with respect to -t (vs. -n) suffixation and stem change (vs. no change) for each of the four conditions and the two participant groups. Levene’s tests were used for statistical evaluation. The purpose of the second analysis was to explore potential sources of variability within the BIL group. To this end, we ran additional generalized linear mixed-effects regression models on measures that yielded significantly increased variability for the BIL group (relative to those of the CTR group); these models included a number of potentially relevant participant-level variables from our demographic questionnaires as additional fixed factors (besides the factor Condition), viz. the age of onset of acquisition of German (AoA), the BIL participants’ German language skill (as measured by the TELC test), their amount of usage of German, their length of exposure, and the bilingual participants’ vocabulary scores taken from the LexTale test.
5. Results
The percentages of the four participle response types, -t vs. -n forms with vs. without stem change for the four types of nonce verbs are shown in .
Table 2. Percentages of -t and -n participle responses with and without stem change by Condition and Group
5.1. Between-group analyses
One striking observation from is that -t participle forms are the most common response type throughout, albeit with smaller percentages for the BIL than the CTR group (67.29% for BIL, and 72.84% for CTR) and numerical differences across conditions. To evaluate these observations statistically, the first regression model (see ) compared the percentages of -t participle forms relative to those with -n (irrespective of stem changes). In addition to the aforementioned fixed and random effects, we included Form Presented with two levels (third-person singular vs. first-person plural) as a covariate into the first model, to control for the possibility that the forms in which the nonce words were presented to the participants influenced their participle responses.
Table 3. Fixed effects from the model for -t (vs. -n) participle suffixation
We found a main effect of Group reflecting the fact that the bilingual group produced fewer -t participles across conditions compared to the monolingual one. There were also main effects of Condition for Reg, Irreg, and Irreg/Reg, due to reduced percentages of -t participle forms relative to the No Sim condition. Furthermore, there were significant interactions of Condition by Group for the conditions Irreg and Irreg/Reg (marginally significant for Reg). Follow-up analyses by Condition revealed that these interactions were due to a reduced percentage of -t participles in the No Sim and the Reg conditions for the BIL group relative to the CTR group (No Sim: β = 2.28; SE = 0.6, z = 3.94; Reg: β = 1.58; SE = 0.53, z = 2.97), but no corresponding between-group difference for the Irreg (β = 0.7; SE = 0.6, z = 1.27) and the Irreg/Reg conditions (β = 0.38; SE = 0.6, z = 0.65). These results indicate that -t participle forms are clearly preferred for the Reg and the No Sim conditions, albeit to a lesser extent in the BIL than in the CTR group. Furthermore, the two conditions that include Irreg yielded a reliable increase of the proportion of -n forms for both participant groups.
As regards participle forms with stem changes (17.26% for the BIL and 21.77% for the CTR group), indicates that such forms are commonly produced for the Irreg and the Irreg/Reg condition and only very rarely for the Reg and No Sim condition, for both participant groups. For statistical analysis, the second regression model compared the percentages of participles with stem changes (relative to those without stem changes) in the Irreg, and the Irreg/Reg, as well as the Reg conditions to those in the No Sim control condition.
The model revealed main effects of Condition for Irreg and Irreg/Reg, the latter of which was further modulated by a (marginally significant) interaction with Group (see ). Follow-up analyses showed that this (marginal) interaction was due to fewer stem changes for Irreg/Reg in the BIL group than the CTR group (β = 1.3; SE = 0.6, z = 2.06), and no between-group difference for the No Sim condition (β = –0.4; SE = 0.6, z = –0.7). These results show that the two conditions that include Irreg led to a considerable increase of participle forms with stem changes for both participant groups.
Table 4. Fixed effects from the model for participles with (vs. without) stem changes
To examine the distribution of stem changes within the two suffix types, we analyzed the two sets of -t and -n participles produced by the participants separately. As can be seen from , stem changes were very rarely produced among the -t participle forms for both participant groups and across all conditions, and the corresponding regression model did not yield any significant effects or interactions for either Group or Condition (all zs ≤ 1.6). For -n participles, however, indicates considerably more stem changes, particularly for the CTR group, as well as condition differences with more stem changes for the two conditions that include Irreg compared to Reg and No Sim. We ran a regression model on the proportions of -n participles that contained stem changes (relative to those without stem changes). The model revealed a main effect of Group (β = 6.7, SE = 1.1, z = 6.13) due to an overall lower proportion of -n participles with stem changes in the BIL than the CTR group. This between-group contrast was significant in all four conditions (Irreg: z = 5.35, Irreg/Reg: z = 5.01, Reg: z = 3.72, No Sim: z = 4.2). Furthermore, there were two interactions of Condition and Group, one for Irregular vs. No Sim (β = –2.3, SE = 1.1, z = –2.03) and the other for Irreg/Reg vs. No Sim (β = –4.1, SE = 1.7, z = –2.46). These interactions are due to considerably fewer -n participles with stem changes in the two conditions that include Irreg for the BIL than the CTR group and similarly low proportions of stem changes for both participant groups in the No Sim condition. These results indicate that the BIL participant group dispreferred stem changes for nonce participles, even in conditions in which such forms are relatively common among the CTR group participants.
5.2. Within-group analyses
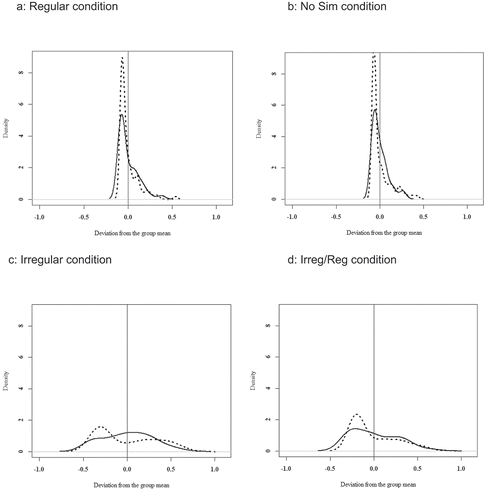
In addition to the previous group-level comparisons, we also examined whether nonce-word generalization patterns are more variable within the bilingual participant group than within the CTR group. To test this, we first calculated—for each individual participant—the proportions of -t (vs. -n) suffixation and of participles with stem change (vs. without stem change) in the four conditions and then subtracted these individual scores from the participant group’s (BIL vs. CTR) mean per condition. This yielded a single measure for participant and condition, which can be either above or below zero depending on whether the individual’s mean was higher or lower than the group’s mean. As illustrated by the density plots in , the BIL group showed more variability for -t participle production than the CTR group but only for two of the four conditions (viz., Reg and No Sim), whereas for Irreg and Irreg/Reg the distribution of the individual scores in the two participant groups was largely parallel; see vs. . To test these observations statistically, we used the Levene’ test of Equality of Variances, which examines the homogeneity of variances within groups based on absolute deviations from a groups’ mean. The test revealed significantly more inter-individual variability within the BIL group’s -t suffixation rates than for the CTR group in the Reg condition (F = 6.90; p = .01) and the No Sim condition (F = 13.79, p < .001) but not for the Irreg (F = 1.73, p = .19) and the Irreg/Reg condition (F = 0.04, p = .85). The density plots () illustrate that this difference is due to a number of bilingual speakers who (unlike the CTR speakers) produced more -t participles than their group’s mean; see the extended dotted lines between 0.3 and 0.5 in . As regards stem changes, indicates a largely similar distribution for the two participant groups. Levene’s tests did not reveal significant between-group differences of the variability scores for three of the four conditions (Reg: F = 0.56, p = .45; No Sim: F = 1.83, p = .18; Irreg/Reg: F = 0.01, p = .9). For the Irreg condition, however, there was a group difference (F = 6.75, p = .01). This might be due to a (small) number of BIL participants that underuse stem changes (relative to their group’s mean); see the small peak for the dotted line at around –0.3 in .
Figure 1. Density plots for -t participles (BIL: dotted line, CTR: straight line)
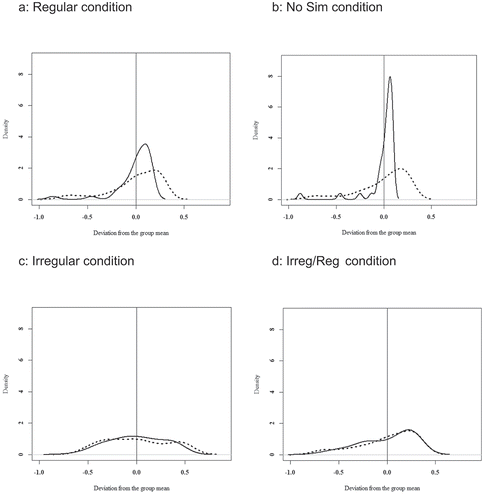
Figure 2. Density plots for participles with stem changes (BIL: dotted line, CTR: straight line)
5.3. Factors affecting variability in the bilingual group
The most striking finding from the previous analyses is that while the BIL participants—taken as one group—produced significantly fewer -t participles across conditions compared to the CTR group, a number of bilingual individuals performed differently in that they produced more -t participles for nonce-verb participles than their group’s mean. This was not the case for the CTR group in which the individuals’ scores centered significantly more closely to the group’s mean. To investigate the sources for the increased variability of the BIL group, additional regression models were fitted with the proportions of -t participles (relative to -n participles) in the BIL group as the dependent variable and as fixed factors Condition and five participant-level variables: (i) the BIL participants’ age of onset of acquisition of German (AoA), (ii) their (TELC test) German language scores, (iii) the amount of usage of German, (iv) their length of exposure to German, and (v) their (LexTale) German vocabulary scores (all numerical predictors were first centered). This overall model did not yield any significant main effects or interactions (with Condition) for any of the five participant-level variables. A likely reason for that is multicollinearity, i.e., the fact these five variables are correlated with each other. For example, an individual’s TELC test score for German is likely to be correlated with this speaker’s LexTale German vocabulary score. Likewise, AoA is obviously related to length of exposure, as those participants who acquired German earlier in life are likely to have been practicing it for a longer time. presents the correlations between the five participant-level variables in our sample.
Table 5. Correlation coefficients (r) between participant-level variables
As can be seen, there are several negative correlations between AoA and the other four variables, reflecting the fact that speakers with relatively high AoA tend to have relatively low Telc and LexTale scores in German as well as fewer years of exposure to German. Furthermore, there was—as expected—a positive correlation between the TELC and the LexTale test scores. Due to this multicollinearities, the likelihood of detecting a unique (uncorrelated) effect of any of the five participant-level variables on the dependent variable (viz., -t participle production) is reduced (Friedman & Wall Citation2005; Wurm & Fisicaro Citation2014), hence the lack of any effect or interaction in the overall model.
As an alternative approach to determining which of the five participant-level variables is the best predictor for -t participle production among the bilingual speakers that avoids the problem of multicollinearity, we employed a backwards stepwise-regression procedure. According to this procedure, potential predictors are sequentially removed from the regression model whenever the removal leads to a model with greater goodness of fit. The latter was assessed by AIC, a measure that penalizes complexity and leads to predictors being kept only when they substantially contribute to explaining variance in the data; see Venables & Ripley (Citation2002). We calculated AIC values for the aforementioned overall model (which contained all five variables) and for models in which each of these predictors was removed. The model with the lower AIC (i.e., better fit) was then selected, and this procedure was sequentially repeated until the removal of predictors did not produce any better model. Application of this procedure led to the following results. The overall model was the worst one (AIC = 7,798.2). Use of German was then removed (AIC = 7,796.5), followed by Length of Exposure (AIC= 7,796.3), Skill in German (AIC =7,796.1), and LexTale score (AIC = 7,795.5). We were then left with a model that (of the five participant-level variables) only contained AoA, in addition to the within-participant factor Condition. If we also removed AoA, we would end up with a worse model (AIC= 8,040.8). As there were no interactions between AoA and the four experimental conditions (Reg, Irreg, Irreg/Reg, No Sim), we employed sum-coded contrasts to the four level factor Condition, which yielded a main effect of AoA on -t participle production (β = –0.08, SE = 0.03, z = –2.51). This effect is due to smaller -t participle production rates with increasing AoA of German.
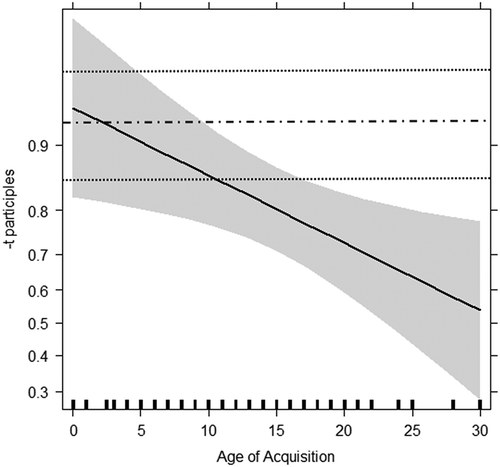
presents the estimates of the best-fit regression model with condition and AoA as fixed factors, controlled for Form Presented. To visualize at which AoA the bilinguals diverge from the CTR group, we added lines with the estimates of a regression model from the CTR group that also included the factor Condition (with sum-coded contrasts) and the covariate Form Presented but not AoA or any of the other participant-level variables. illustrates the decrease of the proportions of -t participle forms among the bilingual participants with increasing AoA of German. An early point of divergence between the BIL participants’ and the CTR group’s mean rates of -t participle production can be identified at approximately an AoA of 3;00; from then on the BIL participants’ rates gradually decrease with increasing AoA of German. We conclude from the results of the stepwise regression analysis that inter-individual variability in the BIL participants’ use of -t participle forms for morphological generalization is best explained by their age at the onset of acquisition of German. As a caveat, we should note, however, that other factors may also be relevant. Our model comparisons just confirm that of the five factors under study, AoA is the best single predictor to explain our data.
Figure 3. AoA by proportion of -t participles in the two participant groups: black straight line = BIL group, gray shadow = confidence intervals BIL; black dash-dotted line = model estimate for CTR group across the four conditions (=0.92), black dotted lines = confidence intervals CTR group (lower = 0.84; upper = 0.96)
6. Discussion
The main findings from the current study can be summarized in three points. First, (regular) -t suffixation is the clearly preferred participle form for nonce verbs of all types, albeit to a lesser extent in the BIL than in the CTR group. Second, the two conditions that include nonce verbs similar to existing German verbs with irregular participle forms yielded a considerable increase of (irregular) responses with -n and of participle forms with stem changes, the latter to a lesser extent in the BIL than in the CTR group. Third, we found more inter-individual variability for -t participle generalizations within the BIL group than among the CTR group participants. Furthermore, we found an AoA effect for the BIL group, viz. a decrease of -t suffixation rates with increasing age of onset of acquisition of German.
Dual-morphology models (e.g., Clahsen Citation1999; Pinker Citation1999; Pinker & Ullman Citation2002) provide a straightforward account for the differences we found between -t and -n generalization in both participant groups. These models posit two different mechanisms for morphological generalization: (i) grammatical operations or rules that may apply to any verb and therefore function as a default allowing for productive unbounded extension to nonce verbs, (ii) more limited generalizations based on similarity-based associations of nonce words with existing words. Our findings that -t participle forms widely generalize to nonce verbs whereas -n generalization rates were modulated by similarity to existing verb forms fit in with the distinction between rule-based and lexically conditioned morphological representations. In single-mechanisms models (e.g., Bybee Citation1995; Elman et al. Citation1996; Plunkett & Marchman Citation1996), the fact that -t participle forms generalize widely across different types of nonce verbs has been attributed to the large number of existing verbs that form their participle with -t relative to the smaller number of verbs that take -n participles. This argument has been disputed, however; see, e.g., Clahsen (Citation1999:1049) and Pinker and Ullman (Citation2002:473) for discussion. First, it is true that in terms of type frequencies of root verbs (Grundverben) -t participles are more common than -n participles (Bybee Citation1995), but in terms of token frequencies this is not the case. To take an example from the CELEX database, of the 14,163 participles in CELEX, 48% (or 6,808 instances) are -n participles, and 52% (or 7,355 instances) are -t forms. Second, even in terms of type-frequency counts, -t participles are only in the majority if one collapses linguistically distinct types of verbs into one category. This includes particle and prefix verbs with noncompositional meanings that orthographically and phonologically behave like single verbs and that in their participle form always appear as a single verb. Unlike in English, for example, these particle and prefix verbs are highly common in German usage. If these verbs are separately included in the frequency counts (rather than collapsed with the Grundverben), -t and -n participles come out with similar (type and token) frequencies (see Clahsen Citation1999). For these reasons, a frequency-based account of morphological generalization seems questionable, at least for German participle formation.
Although the contrasting generalization patterns for -t and -n forms were found for both participant groups, the bilingual speakers’ morphological generalizations exhibited an interesting asymmetry to the patterns seen among the control participants. On the one hand, the BIL group performed like the CTR participants in the two conditions that included Irregular nonce verbs, i.e., nonce verbs that are similar to existing German verbs with irregular participle forms. These conditions yielded a clear increase of the proportion of -n forms for both participant groups and parallel inter-individual variability within the two participant groups. On the other hand, the BIL group produced fewer -t generalizations (relative to the CTR group), particularly for the two conditions Reg and No Sim, and showed more inter-individual variability for -t participle production than the CTR group, again for Reg and No Sim. These results are in line with those from a number of previous studies on other languages (e.g., Cuskley et al. Citation2015; Clahsen, Martzoukou & Stavrakaki Citation2010) and may be taken to indicate that L2 learners rely less on rule-based processes for morphological generalization than L1 speakers (Ullman Citation2020). Additionally, our results revealed that rule-based generalizations are not only used less often but also more variably among the bilingual speaker group than within the L1 control group.
The most interesting novel finding from the current study is the selective AoA effect we discovered for the bilingual speakers’ -t generalizations. Our finding that rule-based morphological generalizations are modulated by AoA also confirms a conjecture that emerged from a number of previous studies investigating bilingual speakers’ morphological generalization patterns. Recall that similarly to child and adult L1 speakers of German, early child bilinguals with an AoA of German of 3 to 4 years or earlier were found to produce more -t (than -n) forms in overapplication errors, whereas for successive and late bilinguals with a higher AoA several (but not all) studies reported a reduced rate of -t forms for nonce verbs (relative to L1 speakers) and no clear preference for either -t or -n overapplications; see . This contrast has been suspected to be due to an early sensitive phase for the acquisition of grammar that ends after about the age of 4 years (Sopata Citation2013; Sterner Citation2017; Meisel Citation2009).
We may speculate that the AoA effect on -t generalizations is a result of maturational constraints on the acquisition of inflectional rules. Ullman (Citation2020) offers a specific account of the nature of these constraints arguing that developmental changes in the declarative/procedural system from child to adulthood are the result of brain maturation and age-related changes of hormone levels. Although we are not necessarily committing ourselves to this specific view, the postulation of maturational changes in language development has a long research history starting with Lenneberg’s (Citation1967) “critical period hypothesis” to many more recent studies (e.g., Bialystok & Hakuta Citation1999; Birdsong Citation1999; DeKeyser Citation2012; Meisel Citation2009; Hartshorne, Tenenbaum & Pinker Citation2018). The current results revealed an AoA effect (possibly indicative of a sensitive period) for rule-based generalization only. This finding provides new evidence that sensitive periods for language and grammar are linguistically selective, a hypothesis that has been put forward in a number of previous studies; see, for example, Granena and Long’s (2012) notion of “windows of opportunity” with specific AoA bands for different linguistic domains, the finding of distinct AoA effects for grammaticality judgment versus spoken production tasks (Huang Citation2014) and for phoneme perception vs. phoneme integration (Werker & Hensch Citation2015). One previous study that is particularly relevant for our findings is Veríssimo et al.’s (Citation2018) investigation of morphological priming patterns in Turkish/German bilinguals. The participants of Veríssimo et al.’s study came from the same cohort as those of the current study, bilinguals who were exposed to Turkish from birth and had varying ages of onset of German acquisition (range: 0 to 38 years). Furthermore, as in the present study, Veríssimo et al. investigated regular -t participle inflection, which they directly compared to -ung nominalizations of German (e.g., geprüft vs. Prüfung ‘checked’ vs. ‘(the) check’). However, although the current study elicited language production data, Veríssimo et al. examined processes involved in word recognition using the masked morphological priming technique. Their results revealed a selective AoA modulation of the magnitudes of inflectional (-t participle) priming that gradually declined with increasing AoA of German, from 5 to 6 years onwards, whereas the magnitudes of derivational priming were not affected by AoA. Veríssimo et al. (Citation2018:324) argued that the selective AoA effect they obtained for -t participle priming is due to paradigm-based learning mechanisms functioning efficiently during early childhood and deteriorating thereafter. As a result, the ability to extract inflectional rules from the input is progressively compromised with later AoAs. If there is indeed a sensitive period for inflectional rules, this should also affect rule-based inflectional generalization processes such as those we examined in the current study. We therefore conclude that the selective AoA effect for -t participle generalization has the same source as the AoA-modulated decline in inflectional priming during word recognition that Veríssimo et al. (Citation2018) reported.
Data availability
Data and materials are available via the Open Science Framework site for this project: https://osf.io/9u3ne/. Learn more about Open Practices from the Center for Open Science at https://www.cos.io/products/osf/.
Acknowledgments
We are grateful to all PRIM team members—particularly Laura Ciaccio, Serkan Uygun, and João Veríssimo—for comments on an earlier version of this manuscript.
Additional information
Funding
References
- Attaviriyanupap, Korakoch. 2006. Der Erwerb der Verbflexion durch thailändische Immigrantinnen in der Schweiz. Eine Bestandaufnahme. Linguistik Online 26. 15–30.
- Baayen, Harald, Doug Davidson & Douglas Bates. 2008. Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language 59. 390–412. https://doi.org/10.1016/j.jml.2007.12.005.
- Bialystok, Ellen & Kenji Hakuta. 1999. Confounded age: Linguistic and cognitive factors in age differences for second language acquisition. In David Birdsong (ed.), Second language acquisition and the critical period hypothesis, 161–181. Mahwah, NJ: Lawrence Erlbaum.
- Birdsong, David. 1999. Introduction: Whys and why nots of the critical period hypothesis for second language acquisition. In David Birdsong (ed.), Second language acquisition and the critical period hypothesis, 1–22. Mahwah, NJ: Lawrence Erlbaum.
- Bordag, Denisa & Magdalena Sieradz. 2012. Learner corpora in second language research: An example study in German as a foreign language. Studies in Applied Linguistics 1. 11–24.
- Bybee, Joan. 1995. Regular morphology and the lexicon. Language and Cognitive Processes 10. 425–455. doi:https://doi.org/10.1080/01690969508407111.
- Bybee, Joan & Carol Moder. 1983. Morphological classes as natural categories. Language 59. 251–270. doi:https://doi.org/10.2307/413574.
- Clahsen, Harald. 1992. Overregularization in the acquisition of inflectional morphology: A comparison of English and German. Monographs of the Society for Research in Child Development 57. 166–178.
- Clahsen, Harald. 1997. The representation of participles in the German mental lexicon: Evidence for the dual-mechanism model. In Geert Booij & Jaap van Marle (eds.), Yearbook of morphology 1996, 73–95. Dordrecht: Kluwer.
- Clahsen, Harald. 1999. Lexical entries and rules of language: A multidisciplinary study of German inflection. Behavioral and Brain Sciences 22. 991–1013. https://doi.org/10.1017/S0140525X9931222X.
- Clahsen, Harald & Anna Jessen. 2019. Do bilingual children lag behind? A study of morphological encoding using ERPs. Journal of Child Language 46. 955–979. https://doi.org/10.1017/S0305000919000321.
- Clahsen, Harald, Maria Martzoukou & Stavroula Stavrakaki. 2010. The perfective past tense in Greek as a second language. Second Language Research 26. 501–525. https://doi.org/10.1177/0267658310373880.
- Clahsen, Harald, Jürgen Meisel & Manfred Pienemann. 1983. Deutsch als Zweitsprache. Tübingen: Narr.
- Clahsen, Harald & Monika Rothweiler. 1993. Inflectional rules in children’s grammars: Evidence from German participles. In Geert Booij & Jaap van Marle (eds.), Yearbook of morphology 1992, 1–34. Dordrecht: Springer. https://doi.org/10.1007/978-94-017-3710-4_1.
- Council of Europe. 2001. Common European framework of reference for languages: Learning, teaching, assessment. Cambridge: Cambridge University Press.
- Cuskley, Christine, Francesca Colaiori, Claudio Castellano, Vittorio Loreto, Martina Pugliese & Francesca Tria. 2015. The adoption of linguistic rules in native and non-native speakers: Evidence from a Wug task. Journal of Memory and Language 84. 205–223. https://doi.org/10.1016/j.jml.2015.06.005
- DeKeyser, Robert. 2012. Interactions between individual differences, treatments, and structures in SLA. Language Learning 62. 189–200. https://doi.org/10.1111/j.1467-9922.2012.00712.x.
- Dillon, Brian, Charles Clifton Jr. & Lyn Frazier. 2014. Pushed aside: Parentheticals, memory and processing. Language, Cognition and Neuroscience 29(4). 483–498.
- Elman, Jeffrey, Elizabeth Bates, Mark Johnson, Annette Karmiloff-Smith, Domenico Parisi & Kim Plunkett. 1996. Rethinking innateness: Connectionism in a developmental framework. Cambridge, MA: MIT Press.
- Enochson, Kelly & Jennifer Culbertson. 2015. Collecting psycholinguistic response time data using Amazon Mechanical Turk. PloS one 10(3). e0116946.
- Farhy, Yael. 2020. Morphological generalization of Hebrew verb classes: An elicited production study in native and non-native speakers. The Mental Lexicon 15(2). 223–257. https://doi.org/10.1075/ml.19001.far
- Fernández-Dobao, Ana & Julia Herschensohn. 2021. Acquisition of Spanish verbal morphology by child bilinguals: Overregularization by heritage speakers and second language learners. Bilingualism: Language and Cognition 24. 56–68. https://doi.org/10.1017/S1366728920000310.
- Friedman, Lynn & Melanie Wall. 2005. Graphical views of suppression and multicollinearity in multiple linear regression. The American Statistician 59. 127–136. https://doi.org/10.1198/000313005X41337.
- Gibson, Edward, Steve Piantadosi & Kristina Fedorenko. 2011. Using Mechanical Turk to obtain and analyze English acceptability judgments. Language and Linguistics Compass 5(8). 509–524.
- Gor, Kira & Svetlana Cook. 2010. Nonnative processing of verbal morphology: In search of regularity. Language Learning 60(1). 88–126.https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1467-9922.2009.00552.x
- Granena, Gisela & Michael Long. 2013. Age of onset, length of residence, language aptitude, and ultimate L2 attainment in three linguistic domains. Second Language Research 29. 311–343. https://doi.org/10.1177/0267658312461497.
- Hahne, Anja, Jutta Mueller & Harald Clahsen. 2006. Morphological processing in a second language: Behavioral and event-related brain potential evidence for storage and decomposition. Journal of Cognitive Neuroscience 18. 121–134. https://doi.org/10.1162/089892906775250067.
- Hartshorne, Joshua, Joshua Tenenbaum & Steven Pinker. 2018. A critical period for second language acquisition: Evidence from 2/3 million English speakers. Cognition 177. 263–277. https://doi.org/10.1016/j.cognition.2018.04.007.
- Huang, Becky. 2014. The effects of age on second language grammar and speech production. Journal of Psycholinguistic Research 43. 397–420. https://doi.org/10.1007/s10936-013-9261-7.
- Köpcke, Klaus-Michael. 1998. Prototypisch starke und schwache Verben der deutschen Gegenwartssprache. Germanistische Linguistik 141. 45–60.
- Lago, Sol, Anna Stutter Garcia & Claudia Felser. 2019. The role of native and non-native grammars in the comprehension of possessive pronouns. Second Language Research 35. 319–349.
- Lemhöfer, Kristin & Mirjam Broersma. 2012. Introducing LexTALE: A quick and valid lexical test for advanced learners of English. Behavior Research Methods 44. 325–343. https://doi.org/10.3758/s13428-011-0146-0.
- Lenneberg, Eric. 1967. Biological foundations of language. New York: Wiley.
- Leung, Yan-kit Ingrid. 2006. Verb morphology in second language versus third language acquisition: The representation of regular and irregular past participles in English-Spanish and Chinese-English-Spanish interlanguages. Eurosla Yearbook 6. 27–56. https://doi.org/10.1075/eurosla.6.05leu.
- Meisel, Jürgen. 2009. Second language acquisition in early childhood. Zeitschrift für Sprachwissenschaft 28. 5–24.
- Meisel, Jürgen. 2011. First and second language acquisition: Parallels and differences. New York: Cambridge University Press.
- Mohsenian, Nazanin. 2020. The production of German participles by L2 speakers: An ERP study. Potsdam: University of Potsdam master’s thesis.
- Murphy, Victoria. 2004. Dissociable systems in second language inflectional morphology. Studies in Second Language Acquisition 26. 433–459. https://doi.org/10.1017/S0272263104263033.
- Neubauer, Kathleen & Harald Clahsen. 2009. Decomposition of inflected words in a second language: An experimental study of German participles. Studies in Second Language Acquisition 31. 403–435. https://doi.org/10.1017/S0272263109090354.
- Pinker, Steven. 1999. Words and rules. New York: Basic Books.
- Pinker, Steven & Michael Ullman. 2002. The past and future of the past tense. Trends in Cognitive Sciences 6. 456–463. https://doi.org/10.1016/S1364-6613(02)01990-3.
- Plunkett, Kim & Virginia Marchman. 1996. Learning from a connectionist model of the acquisition of the English past tense. Cognition 61. 299–308. https://doi.org/10.1016/S0010-0277(96)00721-4.
- Prasada, Sandeeb & Steven Pinker. 1993. Generalisation of regular and irregular morphological patterns. Language and Cognitive Processes 8. 1–56. https://doi.org/10.1080/01690969308406948.
- Rispens, Judith & Elise de Bree. 2015. Bilingual children’s production of regular and irregular past tense morphology. Bilingualism: Language and Cognition 18(2). 290–303. https://doi.org/10.1017/S1366728914000108
- Ruoff, Arno. 1981. Häufigkeitswörterbuch gesprochener Sprache gesondert nach Wortarten. Tübingen: Niemeyer.
- Sopata, Aldona. 2013. Einblick in das mentale Lexikon–Partizipien II im frühen Erwerb des Deutschen. Zeitschrift des Verbandes Polnischer Germanisten/Czasopismo Stowarzyszenia Germanistów Polskich (ZVPG) 2. 151–159.
- Sterner, Franziska. 2017. Sukzessiv-bilinguale Kinder: Der Erwerb von Partizipien in der frühen Zweitsprache Deutsch. Hamburg: University of Hamburg dissertation.
- telc gGmbH (ed.). 2015. Kompetenzcheck Deutsch Beruf A1A2B1B2C1. Frankfurt am Main, 1. Auflage 2015.
- Thomas, Enlli, Nia Williams, Llinos Jones, Susi Davies & Hanna Binks. 2014. Acquiring complex structures under minority language conditions: Bilingual acquisition of plural morphology in Welsh. Bilingualism: Language and Cognition 17(3). 478–494. https://doi.org:10.1017/S1366728913000497
- Ullman, Michael. 2020. The declarative/procedural model. A neurobiologically motivated theory of first and second language. In Bill VanPatten, Gregory Keating & Stefanie Wulff (eds.), Theories in second language acquisition, 128–161. New York: Routledge.
- Venables, William & Brian Ripley. 2002. Modern applied statistics with S, 4th edn. New York: Springer.
- Veríssimo, Joao, Vera Heyer, Gunnar Jacob & Harald Clahsen. 2018. Selective effects of age of acquisition on morphological priming: Evidence for a sensitive period. Language Acquisition 25. 315–326. https://doi.org/10.1080/10489223.2017.1346104.
- Wagers, Matthew & Colin Phillips. 2014. Going the distance: Memory and control processes in active dependency construction. Quarterly Journal of Experimental Psychology 67. 1274–1304.
- Werker, Janet & Takao Hensch. 2015. Critical periods in speech perception: New directions. Annual Review of Psychology 66. 173–196. https://doi.org/10.1146/annurev-psych-010814-015104.
- Weyerts, Helga & Harald Clahsen. 1994. Netzwerke und symbolische Regeln im Spracherwerb: Experimentelle Ergebnisse zur Entwicklung der Flexionsmorphologie. Linguistische Berichte 154. 430–460.
- White, Lydia. 2003. Second language acquisition and universal grammar. Cambridge: Cambridge University Press.
- Wurm, Lee & Sebastiano Fisicaro. 2014. What residualizing predictors in regression analyses does (and what it does not do). Journal of Memory and Language 72. 37–48. https://doi.org/10.1016/j.jml.2013.12.003.