
ABSTRACT
A total 206 samples of green, yellow, white, black, and Oolong teas were utilized to acquire hyperspectral imaging, and five tea categories were identified based on visible and near-infrared (NIR) hyperspectral imaging, combined with classification pattern recognition. The characteristic spectra were extracted from the region of interest (ROI), and the standard normal variate (SNV) method was preprocessed to reduce background noise. Four dominant wavelengths (589, 635, 670, and 783 nm) were selected by principal component analysis (PCA) as spectral features. Textural features were extracted by the Grey-level co-occurrence matrix (GLCM) from images at selected dominant wavelengths. Linear discriminant analysis (LDA), library support vector machine (Lib-SVM), and extreme learning machine (ELM) classification models were established based on full spectra, spectral features, textural features, and data fusion, respectively. Lib-SVM was the best model with the input data fusion, and the correct classification rate (CCR) achieved 98.39%. The results implied that visible and NIR hyperspectral imaging combined with Lib-SVM has the capability of rapidly and non-destructively classifying tea categories.
Introduction
Tea is one of the three most popular non-alcoholic beverages in the world, which contains a number of secondary metabolites, such as polyphenols, caffeine, theanine, and other components beneficial to human health.[Citation1] In China, tea can be classified into six categories: green tea (unfermented), white tea (slightly fermented), yellow tea (partly fermented), Oolong tea (semi-fermented), black tea (fully fermented), and dark tea (post-fermented), according to the degree of fermentation.[Citation2–Citation4]
Tea consumption is expanding all over the world, but a lay man will find it difficult to classify the different categories of teas. Different categories of tea have different qualities and quality standards. The classification of tea categories is important for consumers to purchase tea. Several chemical methods[Citation5–Citation8] were utilized to classify tea categories; however, these methods were time consuming and would destruct tea samples. Recently, green analytical techniques[Citation9] revealed their domination in the classification of tea categories, which were fast, non-destructive, and precise, such as near-infrared (NIR) spectroscopy, computer vision, and electronic nose (E-nose). Chen et al.[Citation10] utilized NIR spectroscopy combined with support vector machine (SVM) as recognition for the fast identification of green, black, and Oolong tea, and the identification accuracies were all above 90%. Wang et al.[Citation11] proposed a computer-vision and machine-learning-based system to identify three tea categories. They used principal component analysis (PCA) to reduce the colour and texture information, which were fed into a fuzzy support vector machine (FSVM) with Winner-take-all (WTA) classifier, and they obtained an overall rate of 97.77%. Chen et al.[Citation12] developed a portable E-nose system based on the door imaging sensor array, and successfully used it for the classification of green tea, black tea, and Oolong tea. However, NIR spectroscopy just obtains single-point information of tea, computer vision only provides tea’s surface information, and E-nose merely captures the volatile organic compounds of tea. Hyperspectral imaging contains both the spectral and spatial information from the analysed sample, which has been recently used as emerging process analytical tool for food-quality control.[Citation13, Citation14] Several researchers attempted to combine the spectral and spatial information, such as for differentiating fresh and frozen-thawed fish fillets,[Citation15] discriminating the varieties of black beans,[Citation16] quantifying the total volatile basic nitrogen content in chicken,[Citation17] and predicting the pH of salted pork[Citation18] wherein the models based on data fusion were better than those based on single variable matrix alone. However, there has been no research on the comprehensive classification of Chinese tea categories utilizing data fusion.
This study focused on the classification of five Chinese tea categories with different fermentation levels based on hyperspectral imaging. Spectral data were extracted within the range of 400–1000 nm wavelength from hyperspectral images of tea samples. Spectral and textural features were extracted and combined by level fusion. Linear discriminant analysis (LDA), library support vector machine (Lib-SVM), and extreme learning machine (ELM) models were developed to discriminate these five Chinese categories of teas.
Materials and methods
Samples preparation
Dark tea was always manufactured into brick, cake, and mushroom forms, which could easily be identified from the other teas. A total of 206 samples were collected from 13 provinces of China. Each tea category contained 44 samples, except yellow tea contained 30 samples. Each tea category had four samples to test the practicability of the final model. The remaining 186 samples were divided into two subsets in the ratio of 2:1, 124 samples were chosen as the calibration set, and the remaining 62 samples made up the prediction set. The calibration set was used to develop the model, while the prediction set was applied to test the robustness of the model.
Hyperspectral image acquisition and processing
The hyperspectral imaging system consisted of a hyperspectral spectrograph (Imspector V10E, Spectral Imaging Ltd., Oulu, Finland), two 150 W tungsten halogen lamps (3900, Illumination Technologies Inc., New York, USA), a moving platform, a dark box, and a computer with image acquisition and analysis software (Spectral Image Software, Isuzu Optics Corp., Taiwan, China). A total of 13 ± 0.5 g of sample was taken, and spread uniformly in the Petri dish (Φ×h: 9 cm × 1 cm). The Petri dish was put onto the moving platform to acquire image at a speed of 1.16 mm/s and the exposure time of the CCD (Charge coupled device) camera (IPX-2M30, Imperx Inc., USA) was set to 8.8 ms. The spectral range was 370–1037 nm with the nominal spectral resolution of 2.73 nm. However, the starting and ending wavelengths in the spectral region had a disturbing noise level; therefore, only the spectral range of 400–1000 nm (with 1107 bands) was chosen and utilized for analysis.[Citation19] To remove the dark current noise in the camera, the acquired hyperspectral images were corrected as the follows:
where Rc is the corrected image, R is the raw hyperspectral image, B is the dark image (approximately 0% reflectance) acquired by covering the camera completely with the lens cover, and W is the white image (approximately 99% reflectance) acquired by a standard white tile (the reference white material).
Selection of important wavelengths
The 200 × 200 pixels region from the centre of the corrected images was selected as the region of interest (ROI). The spectrum of each pixel contained in ROI was extracted and then averaged using ENVI (Version 4.7, ITT Visual Information Solutions, Boulder, USA), which represented the spectral data of the tea sample. The current hyperspectral images have high dimensional data, resulting in increasing computational burden. Besides, the adjacent band images are highly correlated. Therefore, it is necessary to select the dominant wavelengths related to tea categories from the hyperspectral data. PCA is one of the commonly used methods used for the dimension reduction of hyperspectral data.[Citation20] After processing, the hyperspectral image contained low dimension and high signal-to-noise ratio of data. PCA transformed the hyperspectral image into several principal component (PC) images, where each PC image was a linear combination of all of the original images. The first few PC images had a larger variance contribution rate and contained most information of the origin image. The loadings of PCA were the weighting coefficients of each wavelength image at each PC, and they can be used to select the dominant wavelength image. Then, the spectral information at the dominant wavelengths was saved as spectral features. The procedure of PCA was also carried out in ENVI 4.7.
Extraction of textural features
Grey-level co-occurrence matrix (GLCM)[Citation21] was used for extracting the textural feature from the ROI of the images at dominant wavelengths. ROIs were of 900 × 900 pixels from the centre of the images. GLCM is the matrix function obtained by calculating the specified distances and directions from the sample’s adjacent pixels. The distance equals to 1 and the four directions at angles (0°, 45°, 90°, and 135°) were applied to extract four textural features, including contrast, correlation, energy, and homogeneity. The features were calculated using a procedure in Matlab 2014a (The Mathworks Inc., Massachusetts, USA). The textural features were extracted by following Eqs. (2)–(5):
where
p (i, j) is (i, j) th entry of the co-occurrence probability matrix.
Combination of spectral and textural features
Generally, data fusion can be divided into three levels: pixel-level fusion, feature-level fusion, and decision-level fusion.[Citation22] Among these three levels, feature-level fusion is used to extract feature variables from spectra and images and then integrate them together, which can retain most of the original information.[Citation23] To seize as much original information as possible from the hyperspectral images and to enhance the robustness and classification ability of the model, spectral and textural features were combined based on the feature-level fusion. While this fusion level also has the limitation that a small-value parameter would be hidden by the predictability of a larger-value parameter, even though the former may be as important as, or even more important than, the latter.[Citation24] The normalization procedure was used to overcome this drawback of feature-level data fusion.
Classification models
The classification models were developed by LDA, Lib-SVM, and ELM. LDA is a common linear classification algorithm used for pattern recognition to separate the classes of samples or objects. However, if the sample variables are highly correlated, it could affect the discrimination performance, and so PCA is used to reduce the number of variables and extract the effective features as input data to develop the LDA model.[Citation25] Similarly, Lib-SVM is an optimized pattern recognition algorithmic version based on SVMs, which was introduced by Chih-Chung Chang and Chih-Jen Lin.[Citation26] We chose the radial basis function (RBF) as the kernel function, and the parameters (c: cost, g: gamma) of RBF were optimized by the cross-validation process. ELM is proposed for training single-layer feed forward neural network (SLFN). In ELM, only the parameters between the hidden layer and the output layer need to be learned.[Citation27] The models were developed in Matlab 2014a software (The Mathworks Inc., Massachusetts, USA).
Results and discussion
Spectral data analysis
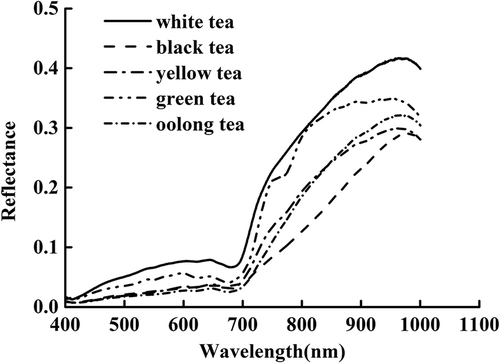
The mean spectral curves of tea samples within the wavelength range of 400–1000 nm are shown in . The general trends of the spectral curves were similar, except for that of green tea, which was a bit different from the other four teas. An absorption peak around 785 nm appeared in the spectral curves of green tea, whereas for all the spectral curves, two main absorption bands appeared at around 670 and 970 nm. According to previous research, an absorption band at 670 nm was associated with chlorophyll.[Citation28] The absorption around 785 nm was due to the fourth overtone of N-H vibration, and near 970 nm it was most related to water.[Citation29]
Figure 1. The mean spectral curves of tea samples in wavelength range of 400–1000 nm.
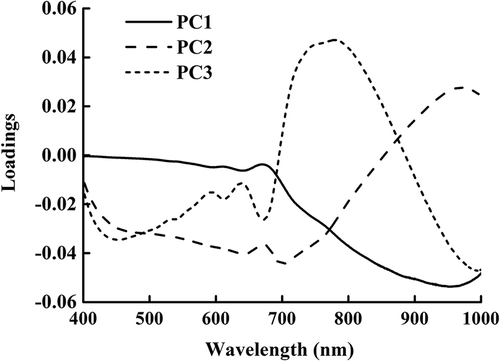
To reduce the spectral dimension, PCA was applied to all hyperspectral images to select the dominant wavelengths and images. The first three PC images provided 99.26% cumulative variance contribution rate. Thus, the dominant wavelength images were selected according to the loadings of the first three PC images in this study. As shown in , the peaks and valleys of the corresponding wavelengths at the first three PC images were selected as the dominant wavelengths. As a result, four dominant wavelengths (589, 635, 670, and 783 nm) were saved as spectral features.
Figure 2. Loadings of all wavelengths for first three principal component images.
Extraction of textural features by GLCM
Textural features were extracted by GLCM from ROI of the images at four dominant wavelengths (589, 635, 670, and 783 nm). The four dominant images at 589, 635, 670, and 783 nm are shown in . The textural features contrast, correlation, energy, and homogeneity were calculated at four directions (0°, 45°, 90°, and 135°). As a result, each tea sample had 64 textural features.
Figure 3. Four important images at 589, 635, 670, and 783 nm.

Classification of tea categories
Before developing the classification models, standard normal variate (SNV) was applied to reduce spectral noise.[Citation22] After spectral processing, LDA, Lib-SVM, and ELM classification models based on full spectra were developed, respectively. The classification results are presented in . Lib-SVM and ELM models achieved a high correct classification rate (CCR). However, the full spectra contained abundant information and the processed data was time consuming and unsuitable for online system. Thus, selection of the spectral features was necessary. Four dominant wavelengths (589, 635, 670, and 783 nm) were selected as spectral features by PCA. As shown in , compared with the LDA, Lib-SVM, and ELM models based on full spectra, the CCR of the spectral features models declined from 83.87% to 70.97%, 98.39% to 75.81%, and 96.77% to 80.65%, respectively. However, the variables of the models were reduced significantly, which improved the data-processing speed.
Table 1. CCR (%) for the calibration set and the prediction set based on different features.
Based on the textural features, LDA, Lib-SVM, and ELM classification models were established, respectively. The LDA and Lib-SVM models obtained the same CCR of 82.26% in the prediction set. The ELM classifier with CCR of 91.94% acquired the best result. Compared to the LDA, Lib-SVM, and ELM models built with spectral features, the models built with textural features had a relatively high performance in either the calibration set or the prediction set. It might be that the textural features were also important for classifying categories.
Based on feature-level data fusion, we combined the spectral and textural features, followed by the normalization procedure to overcome the problem that a large-value parameter would hide the predicted ability of a smaller-value parameter. With the input of data fusion, the LDA, Lib-SVM, and ELM classification models were built. All of the models’ classification results are shown in . Compared to the results of the models developed with spectral or textural features, the three models based on data fusion had higher CCR in both the calibration set and the prediction set. It is might be that the data fusion model combined both the external and internal attributes of tea, which could explain more quality of tea. The Lib-SVM model based on data fusion or full spectra had the highest CCR of 98.39%. However, the variables of the data fusion Lib-SVM model were lesser than the full spectra model. The Lib-SVM model based on data fusion had the best performance and robustness.
Model verification
To test the practicability of the model, each tea category had four samples that were not included in the calibration set and the prediction set, and were utilized for classification based on the data fusion Lib-SVM model. Classification results are illustrated in . The total CCR achieved 95%; only one – Oolong tea – was misclassified as yellow tea. The results revealed that the performance and robustness of the model were at a very high level.
Table 2. Classification results of the data fusion Lib-SVM model in new samples.
Conclusion
The results suggested that visible and NIR hyperspectral imaging combined with data fusion could be used to classify the tea categories. The highest CCR obtained from the Lib-SVM model based on data fusion achieved 98.39%, which were superior to the models based on single features. Future research should focus on data fusion for the classification or prediction of the study object, and optimization of data processing. Furthermore, much more efforts are needed to include more samples to improve the performance of the classifying models, and explore more chemometrics algorithm, such as partial least square discriminant analysis (PLS-DA) and Random forest (RF).
Acknowledgements
This work was supported by the National key Research & Development Plan (2016YFD0200900) and Modern Agriculture (tea) Special System of China (CARS-23). The authors thank Professor Chen for assisting in modification.
Related Research Data
References
- Wang, L.; Gong, L.H.; Chen, C.J.; Han, H.B.; Li, H.H. Column-chromatographic extraction and separation of polyphenols, caffeine and theanine from green tea. Food Chemistry 2012, 131, 1539–1545.
- Chen, L.; Chen, Q.; Zhang, Z.Z.; Wan, X.C. A novel colorimetric determination of free amino acids content in tea infusions with 2,4-dinitrofluorobenzene. Journal of Food Composition and Analysis 2009, 22, 13–141.
- Horžić, D.; Jambrak, A.R.; Belščak-Cvitanović, A.; Komes, D.; Lelas, V. Comparison of conventional and ultrasound assisted extraction techniques of yellow tea and bioactive composition of obtained extracts. Food and Bioprocess Technology 2012, 5, 2858–2870.
- Zhang, L.; Zhang, Z.Z.; Zhou, Y.B.; Ling, T.J.; Wan, X.C. Chinese dark teas: post fermentation, chemistry and biological activities. Food Research International 2013, 53, 600–607.
- Herrador, M.A.; Gonzalez, A.G. Pattern recognition procedures for differentiation of green, black and oolong teas according to their metal content from inductively coupled plasma atomic emission spectrometry. Talanta 2001, 53, 1249–1257.
- Zuo, Y.G.; Chen, H.; Deng, Y.W. Simultaneous determination of catechins, caffeine and gallic acids in green, oolong, black and pu-erh teas using HPLC with a photodiode array detector. Talanta 2002, 57, 307–316.
- Alcázar, A.; Ballesteros, O.; Jurado, J.M.; Pablos, F.; Martín, M.J.; Vilches, J. L.; Navalón, A. Differentiation of green, white, black, Oolong, and Pu-erh teas according to their free amino acids content. Journal of Agricultural and Food Chemistry 2007, 55, 5960–5965.
- Yi, T.; Zhu, L.; Peng, W.L. et al. Comparison of ten major constituents in seven types of processed tea using HPLC-DAD-MS followed by principal component and hierarchical cluster analysis. LWT-Food Science and Technology 2015, 62, 194–201.
- Chen, Q.S.; Zhang, D.L.; Pan, W.X.; Ouyang, Q.; Li, H.H.; Urmila, K.; Zhao, J.W. Recent developments of green analytical techniques in analysis of tea’s quality and nutrition. Trends in Food Science and Technology 2015, 43, 63–82.
- Chen, Q.S.; Zhao, J.W.; Fang, C.H.; Wang, D.M. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochimica Acta Part A 2007, 66(3), 568–574.
- Wang, S.H.; Yang, X.J.; Zhang, Y.D.; Phillips, P.; Yang, J.F.; Yuan, T.F. Identification of green, oolong and black teas in China via wavelet packet entropy and fuzzy support vector machine. Entropy 2015, 17, 6663–6682.
- Chen, Q.S.; Liu, A.P.; Zhao, J.W.; Ouyang, Q. Classification of tea category using a portable electronic nose based on odor imaging sensor array. Journal of Pharmaceutical and Biomedical Analysis 2013, 84, 77–83.
- Gowen, A.A.; O’Donnell, C.P.; Cullen, P.J.; Downey, G.; Frias, J.M. Hyperspectral imaging-an emerging process analytical tool for food quality and safety control. Trends in Food Science and Technology 2007, 18, 590–598.
- Xiong, Z.J.; Sun, D.W.; Zeng, X.A.; Xie, A.G. Recent developments of hyperspectral imaging systems and their applications in detecting quality attributes of red meats: a review. Journal of Food Engineering 2014, 132, 1–13.
- Zhu, F.L.; Zhang, D.R.; He, Y.; Liu, L.; Sun, D.W. Application of visible and near infrared hyperspectral imaging to differentiate between fresh and frozen-thawed fish fillets. Food and Bioprocess Technology 2013, 6(10), 2931–2937.
- Sun, J.; Jiang, S.Y.; Mao, H.P.; Wu, X.H,; Li, Q.L. Classification of black beans using visible and near infrared hyperspectral imaging. International Journal of Food Properties 2016, 19, 1687–1695.
- Khulal, U.; Zhao, J.W.; Hu, W.W.; Chen, Q.S. Nondestructive quantifying total volatile basic nitrogen (TVB-N) content in chicken using hyperspectral imaging (HSI) technique combine with different data dimension reduction algorithms. Food Chemistry 2016, 197, 1191–1199.
- Liu, D.; Pu, H.B.; Sun, D.W.; Wang, L.; Zeng, X.A. Combination of spectra and texture data of hyperspectral imaging for prediction of pH in salted meat. Food Chemistry 2014, 160, 330–337.
- Wei, X.; Liu, F.; Qiu, Z.J.; Shao, Y.N.; He, Y. Ripeness classification of astringent persimmon using hyperspectral imaging technique. Food Bioprocess Technology 2014, 7, 1371–1380.
- Liu, G.S.; He, J.G; Wang, S.L.; Luo, Y.; Wang, W.; Wu, L.G.; Si, Z.H.; He, X.G. Application of near-infrared hyperspectral imaging for detection of external insect infestations on jujube fruit. International Journal of Food Properties 2016, 19, 41–52.
- Haralick, R.M., Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Transactions on Systems, Man, and Cybernetics 1973, 3, 610–621.
- Pohl, C.; Van Genderen, J. Review article multisensor image fusion in remote sensing: concepts, methods and applications. International Journal of Remote Sensing 1998, 19(5), 823–854.
- Huang, L.; Zhao, J.W.; Chen, Q.S.; Zhang, Y.H. Rapid detection of total viable count (TVC) in pork meat by hyperspectral imaging. Food Research International 2013, 54, 821–828.
- Mendoza, F.; Lu, R.F.; Ariana, D.; Cen, H.Y.; Bailey, B. Integrated spectral and image analysis of hyperspectral scattering data for prediction of apple fruit firmness and soluble solids content. Postharvest Biology and Technology 2011, 62(2), 149–160.
- Sádecká, J.; Jakubíková, M.; Májek, P.; Kleinová, A. Classification of plum spirit drinks by synchronous fluorescence spectroscopy. Food Chemistry 2016, 196, 783–790.
- Chang, C.C.; Lin, C.J. LIBSVM: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology 2011, 2(3), 27.
- Huang, G.; Huang, G.B.; Song, S.J.; You, K.Y. Trends in extreme learning machines: A review. Neural Networks 2015, 61, 32–48.
- Cayuela, J.A.; Yousfi, K.; Martínez, M.C.; García, J.M. Rapid Determination of Olive Oil Chlorophylls and Carotenoids by Using Visible Spectroscopy. Journal of the American Oil Chemists Society 2014, 91(10), 1677–1684.
- Pu, H.B.; Kamruzzaman, M.; Sun, D.W. Selection of feature wavelengths for developing multispectral imaging systems for quality, safety and authenticity of muscle foods-a review. Trends in Food Science and Technology 2015, 45, 86–104.