
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this contribution, a new framework for -optimal reduction is presented, motivated by the local nature of both (tangential) interpolation and
-optimal approximations. The main advantage is given by a decoupling of the cost of reduction from the cost of optimization, resulting in a significant speedup in
-optimal reduction. In addition, a middle-sized surrogate model is produced at no additional cost and can be used e.g. for error estimation. Numerical examples illustrate the new framework, showing its effectiveness in producing
-optimal reduced models at a far lower cost than conventional algorithms. Detailed discussions and optimality proofs are presented for applying this framework to the reduction of multiple-input, multiple-output linear dynamical systems. The paper ends with a brief discussion on how this framework could be extended to other system classes, thus indicating how this truly is a general framework for interpolatory
reduction.
1. Introduction
Recent advances in the development of complex technical systems are partly driven by the advent of software tools that allow their computerized modelling and analysis, drastically reducing the resources required during development. Using information about the system’s geometry, material properties and boundary conditions, a dynamical model can be derived in an almost automated way, allowing for design optimization and verifications using a virtual prototype. Depending on the complexity of the model at hand and the required accuracy during investigation, such models quite easily reach a high complexity. As a consequence, simulations and design optimizations may require excessive computational resources or even become unfeasible. In addition, in some applications the models are required to be evaluated in real-time, e.g. in embedded controllers or digital twins. In this latter case, the computational resources available are particularly limited.
Model reduction is an active field of research aimed at finding numerically efficient algorithms to construct low-order, high-fidelity approximations to the high-order models . Amongst all, the most prominent and numerically tractable methods for linear systems include approximate balanced truncation [Citation1-Citation3] and rational interpolation [Citation4,Citation5]. As these methods generally require only the solution of large sparse systems of equations, they can be applied efficiently even to models of very high order. In a context where the admissible model order is low, e.g. in real-time applications, it is of particular interest to find the best possible approximation for a given order. This problem has been addressed in terms of different error norms (see [Citation6] for Hankel norm, [Citation7] for norm), but only for the case of
-optimal approximations there exist algorithms [Citation8–Citation11] that are both numerically tractable and satisfy optimality conditions.
-optimal reduction methods are iterative, therefore their numerical efficiency is diminished at slow convergence.
In this contribution, we describe a new reduction framework to increase the numerical efficiency of -optimal reduction methods. In this framework, firstly introduced in [Citation12] and further developed in [Citation13] for single-input, single-output (SISO) linear time-invariant (LTI) models,
-driven optimization is performed in a reduced subspace, lowering the cost with respect to conventional methods. Through the update of this subspace, optimality of the resulting reduced-order model can be established. In this paper we generalize the framework, proving its validity for linear time-invariant system with multiple-inputs and multiple-outputs (MIMO) and indicating possible extensions to further system classes. By applying this framework for
-optimal reduction, substantial speedup can be achieved. In addition, this framework bears the advantage of producing a Model Function, i.e. a middle-sized surrogate model, at no additional cost. We will give first indications on how to exploit this Model Function in further applications and outline current research endeavours towards this direction.
The remainder of the paper is structured as follows: Section 2 briefly revises -optimal reduction for MIMO LTI systems, whereas in Section 3 we analyse the computational cost tied to these methods. Section 4 presents the main result of this contribution, i.e. a new framework for
-optimal reduction. Section 5 will compare conventional
-optimal reduction to the new framework in numerical examples and show the potential for significant speedup in reduction time. In Section 6, we indicate how to apply this framework to
-optimal approaches for different system classes, motivating its general nature. Finally, Section 7 will summarize and conclude the discussion.
2. Preliminaries
2.1. Model reduction by tangential interpolation
Linear dynamical systems are often described by state-space models of the form
where is the regular descriptor matrix,
is the system matrix and
,
,
(
) represent the state, input and output of the system, respectively.
denotes the system (1) by its state-space representation. The input-output behaviour of a linear system (1) can be characterized in the frequency domain by
, with the rational transfer function matrix
The construction of a reduced-order model (ROM) from the full-order model (FOM) (1) can be obtained by means of a Petrov-Galerkin projection
with projection matrices and reduced state vector
. We will use the shorthand notation
to specify the projection matrices used.
The primary goal of model reduction in the following will be the approximation of the output for all admissible inputs
. This is equivalent to approximating the transfer function
. To achieve this goal, the appropriate design of projection matrices V,W becomes the primary task of model reduction. In this contribution, we will choose projection matrices that achieve bitangential Hermite interpolation according to following result.
Theorem 2.1 (Bitangential Hermite Interpolation [Citation5,Citation14]) Consider a full-order model as in (1) with transfer function
and let scalar frequencies
and vectors
,
be given such that
is nonsingular for
. Consider a reduced-order model
as in (3) with transfer function
, obtained through projection
. Let
denote the range of the matrix
.
(1) If
then .
(2) If
then .
(3) If both (4) and (5) hold, then
where denotes the first derivative with respect to
.
In addition, note that it is possible to tangentially interpolate higher order derivatives at frequencies
by spanning appropriate Krylov subspaces [Citation4,Citation14]. In general, Krylov subspaces are defined through a matrix
, a vector
and a scalar
as follows:
Theorem 2.2 (Tangential Moment Matching [Citation4,Citation14]) Consider a full-order model as in (1) with transfer function
and let a scalar frequency
and nonzero vectors
,
be given, such that
is nonsingular. Consider a reduced-order model
as in (3) with transfer function
, obtained through the projection
.
(1) If
then for
.
(2) If
then for
.
(3) If both (8) and (9) hold, then
Any bases V and W satisfying (4) and (5) are valid; for theoretical considerations, primitive bases are of particular interest, as defined in the following.
Definition 2.3 (Primitive bases) Consider a full-order model as in (1). Let interpolation frequencies
and tangential directions
and
be given such that
is invertible for all
. Then the primitive projection bases
,
are defined as
From a numerical standpoint, and
are preferably (bi-)orthogonal, real bases, improving the conditioning and resulting in a
with real matrices. Finally, note that the primitive bases (11) can be defined as solutions of particular generalized dense-sparse Sylvester equations.
Lemma 2.4 ([Citation14,Citation15]) Consider a full-order model as in (1). Let interpolation frequencies
and tangential directions
be given such that
is invertible for all
. Define matrices
,
. Then the primitive basis
satisfying (11a) solves the generalized sparse-dense Sylvester equation
This relationship is particularly useful for theoretical considerations and will be exploited in Section 4 in the proofs. A dual result for holds as well.
Lemma 2.5 Consider a full-order model as in (1). Let interpolation frequencies
and tangential directions
be given such that
is invertible for all
. Define matrices
,
. Then the primitive basis
satisfying (11b) solves the generalized sparse-dense Sylvester equation
2.2.  -optimal reduction
-optimal reduction
For the design of V and W as of Section 2.1, an appropriate choice for the interpolation frequencies and tangential directions
,
needs to be made. This is a non-trivial task, as the inspection of the FOM is a computationally challenging task in the large-scale setting. For this reason, an automatic selection of reduction parameters minimizing the approximation error
for some chosen norm is highly desirable.
In this contribution, we address the problem of finding an optimal ROM of prescribed order that minimizes the error measured in the
norm, i.e.
where the norm is defined as [Citation16]
Note that there exists a direct relation between the approximation error in the frequency domain in terms of the norm and a bound for the
norm of the output error in the time domain, according to [Citation17]
The optimization problem (14) is non-convex, therefore in general only local optima can be found. Necessary conditions for local -optimality in terms of bitangential Hermite interpolation are available.
Theorem 2.6 ([Citation8,Citation9,Citation18]) Consider a full-order model (1) with transfer function . Consider a reduced-order model with transfer function
with reduced poles
and input resp. output residue directions
,
.
If satisfies (14) locally, then
for .
Theorem 2.1 indicates how to construct bitangential Hermite interpolants for given interpolation data. However, in general, the eigenvalues and residue direction of the reduced-order model are not known a priori. For this reason, an iterative scheme known as Iterative Rational Krylov Algorithm (IRKA) has been developed [Citation8,Citation9] to iteratively adapt the interpolation data until the conditions (17) are satisfied. A sketch is given in Algorithm 1.
Algorithm 1 MIMO -Optimal Tangential Interpolation (IRKA)
Input: FOM ; Initial interpolation data
,
,
Output:locally -optimal reduced model
1:while not converged do
2: //projection matrix (11a)
3: //projection matrix (11b)
4: ;
//compute orthonormal bases
5: //compute reduced model by projection
6: [] = eig(
) //eigendecomposition
7: //update interpolation data
8: end while
Note that the primitive bases in lines 2 and 3 are not computed solving Sylvester equations but rather the sparse linear systems in (11). The equivalent representation using Sylvester equations (cf. Theorem 2.4) is used for brevity.
Finally, note that Algorithm 1 is not the only -optimal method for linear systems present in literature, but is certainly best known due to its simplicity and effectiveness. Other approaches worth mentioning include the trust-region algorithms in [Citation10] and [Citation11]. In addition [Citation19], derives a residue correction algorithm to optimize the tangential directions for fixed poles, speeding up convergence for models with many inputs and outputs. Even though for brevity we will not treat all these algorithms individually, the proofs of Section 4 will make evident that the new framework presented in this paper applies to these algorithms as well, as all methods are targeted at satisfying the optimality conditions (17).
3. The cost of -optimal reduction
The computational cost of model reduction by IRKA (cf. Algorithm 1) is dominated by the large-scale linear systems of equations (LSE) involved in computing ,
according to
In fact, the orthogonalization, the matrix-matrix multiplications involved in the projection , and the low-dimensional eigenvalue decomposition are in general of subordinated importanceFootnote1. As the matrix
of large-scale systems is generally sparse [Citation20], the actual cost involved in solving one LSE depends on a series of factors (including sparsity pattern, number of nonzero elements, conditioning …) as well as the effective exploitation of available hardware resources. It is therefore not possible (or even meaningful) to perform asymptotic operation counts as in the dense case. Nonetheless, to demonstrate that the reduction cost is indeed dominated by the solution of the sparse LSE in (18), compares the average execution times for the different computation steps of Algorithm 1 using MATLAB® R2016b on an Intel® Core™ i7-2640 CPU @ 2.80 GHz computer with 8GB RAM.
Figure 1. Cumulated execution times involved in each step of algorithm 1 for different benchmark models ().
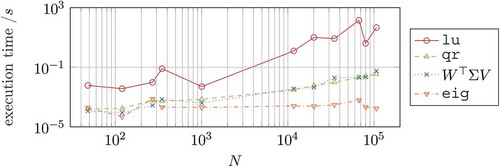
The comparison includes the sparse lu decomposition of the matrix , the economy-sized qr decomposition of the projection matrix
, the matrix products involved in
as well as the small dimensional generalized eig decompositions. The reduced order is set to n = 10 for all cases, while the original model order is given on the x-axis. The times given are averaged amongst several executions and cumulated for each IRKA step: At each iteration of IRKA, n lu decompositions, two qr decompositions, one projection
and one eig decomposition are performed. The models used are taken from the benchmark collections [Citation21,Citation22].
As it can be seen, the execution time for the sparse lu decompositions grows more and more dominant as the problem size increases. This becomes even more evident in , where the execution times are given as percentage of the total time for one IRKA iteration. The two models shown represent the extreme cases of , i.e. where the execution time for the lu decompositions has the smallest and largest share.
Figure 2. Cumulated execution times as total share of each step of Algorithm 1.
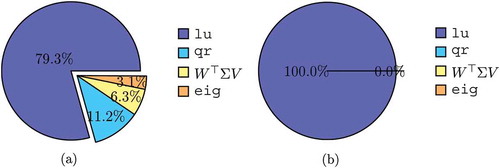
IRKA (and alternative reduction methods) require the repeated reduction of an Nth-order model until, after
steps, a set of
-optimal parameters
,
, and
is found. Following the results of and , its cost can be approximated by
where the cost of a -dimensional LSE
depends on, amongst others, the model at hand, as well as the chosen LSE solverFootnote2. While the second factor in (19) represents the cost of a single reduction, the factor
represents the cost introduced by the optimization. From this representation, it becomes evident that the cost of optimization is tied to – in fact weighted with – the cost of a full reduction. The efficiency of
-optimal reduction methods can hence be significantly deteriorated by bad convergence, which can be a result of a bad initialization or the selection of an unsuitable reduced order. A very similar discussion applies to trust-region-based
-optimal reduction methods [Citation10,Citation11], where the evaluation of gradient and Hessian in each step also involves a full reduction.
Clearly, a more desirable setting would be to obtain -optimal reduction parameters at a far lower cost than the cost of reduction, having to reduce the full-order model only once. In the following, we introduce a new framework that effectively decouples the cost of reduction from the cost of finding
-optimal reduction parameters without compromising optimality.
4. A new framework for -optimal reduction
The framework discussed in this section was first introduced in [Citation12, p. 83] for SISO models, under the name of model function, a heuristic to reduce the cost of -optimal reduction within the SPARK algorithm. This heuristic was later applied to IRKA and proved in [Citation13] to yield
-optimal reduced-order models under certain update conditions. In this contribution, we give a more extensive discussion of the framework, extending its validity to MIMO models. In Section 6, we will indicate how to apply this framework also to further system classes for which
approximation algorithms are available. The main motivation for the new framework arises from simple considerations on the locality of
-optimal model reduction by tangential interpolation. In fact,
tangential interpolation only guarantees to yield a good approximation locally around the frequencies
as
This can be exploited during reduction as follows: Suppose a full-order model and initial tangential interpolation data
,
, and
are given. Conventional
reduction approaches would initialize e.g. IRKA and run for
steps until convergence. In contrast, as our goal is to find a local optimum close to the initialization, then optimization with respect to a surrogate model – a good local approximation with respect to the initial interpolation data – may suffice. For this reason, the new framework starts by building an intermediate model
– in the following denoted as Model Function, in accordance to its first introduction in [Citation12] – of order
, with
.
Definition 4.1 Consider a full-order model as in (1). Let interpolation data
,
,
,
, be given and define the matrices
,
,
. Then the Model Function
is defined as
where solve the Sylvester equations
From Theorem 4.1 and the results of Theorem 2.4, Theorem 2.5, and Theorem 2.1 it follows that is a bitangential Hermite interpolant of
with interpolation frequencies and tangential directions specified in
,
and
.
4.1. The Model Function framework
Step 1: Initialization of The goal of the Model Function
is to be a good approximation of
, locally with respect to the initial interpolation data
,
, and
, for it to be used as a surrogate of
during the
optimization. For obvious reasons, it must hold
, making it not possible to choose
,
, and
. In the following, we introduce two possible alternatives:
I.1 Include the initial interpolation data with additional interpolation of
and its first
derivatives at the frequency
for a sum of all input and output channels. This can be achieved through
where is a Jordan block of size
with eigenvalue
and
of appropriate dimensions. In this case, the choice of
is free. Due to Theorem 2.2, we expect the approximation quality of
to improve locally around
as
grows.
1.2 Tangentially interpolate higher-order derivatives with respect to the data . This can be achieved through
(cf. Theorem 2.2). In this case and we expect the approximation quality of
to increase locally around the frequencies
with respect to the tangential directions
and
.
Many more choices for ,
, and
are conceivable and valid. Nonetheless, the approaches presented above bear the advantage of minimizing the additional cost tied to the initialization of
. In fact, note that for every value
, the LSEs in (18) share the same left-hand side, allowing e.g. the recycling of LU decompositions or pre-conditioners. That said, one may choose to use the additional degrees of freedom to enforce tangential interpolation with respect to different data. As there is no rigorous rule for this – just like there is no rigorous rule on how to initialize
-optimal reduction – our philosophy is to minimize the initialization cost and let the optimizer choose new frequencies of interest. Finally, note that the specific choice of initialization may affect both the speed of convergence and resulting approximation quality.
Step 2: 2 optimization with respect to
As the Model Function
is a good approximation of
locally with respect to the initial interpolation data, we can run the
optimization with respect to
with initialization
,
,
. The optimal interpolation data found at convergence is denoted by
,
, and
. As typically
, we are expecting the cost of this optimization to be significantly lower than a full optimization over
. As we assume the validity of the resulting reduced-order model
to be confined locally to the frequency region defined by
, we call the combination of IRKA with this Model Function framework Confined IRKA (CIRKA).
In fact, by approximating through
, we have lost any optimality condition between
and
. Whether
is an acceptable approximation of
highly depends on the approximation quality of
itself. This loss of connection between
and
is a typical drawback of so-called two-step model reduction approaches. Nonetheless, by means of surrogate optimization, a new set of interpolation data
,
,
has been found in a cost-effective way. At this point, an update of
with local information about these frequencies is required.
Step 3: Update of and fixed-point iteration To restore the relationship between
and
, the Model Function
from the current step
can be updated to a new
by enforcing tangential interpolation with respect to the optimal data
,
,
. This can be achieved by updating the projection matrices
with new directions and
. As for the initialization of
, several strategies are possible. In the following, we present only a few most relevant ones:
U.1 Update with tangential interpolation with respect to all optimal frequencies and tangential directions
,
,
. This implies that
increases by n in every step and that higher-order derivatives are tangentially interpolated in case specific combinations of optimal frequencies and tangential directions are repeated. In this approach, we expect the approximation quality of
to increase around all optimal frequencies
, with respect to the tangential directions
and
.
U.2 Update only with tangential interpolation with respect to new interpolation data. This implies that the order of the Model Function increases by at most
in every step. In this approach, we expect the approximation quality of
to increase only around new optimal frequencies
with respect to the respective tangential directions
and
, for
, where
denotes the number of new frequencies.
U.3 Reinitialize by including ‘only’ tangential interpolation about the new optimal data. In this approach, we expect the approximation quality of
to increase in the regions around the new optimal frequencies
, with respect to the tangential directions
and
, but potentially decrease around previous interpolation data. However, the order
can be kept constant through iterations using this method, reducing the cost of
optimization. As
, similar considerations apply as for the Initialization in Step 1.
The updated Model Function can be used again to perform a low-dimensional
optimization and potentially improve the optimal frequencies and directions
,
and
, which in general may differ from those of the previous step. This leads to a fixed-point iteration, until, after
steps, an update of
does not result in new optimal interpolation data.
The overall procedure is summarized in Algorithm 2 for the case where optimization is performed with IRKA. Note however that Line 6 can be replaced by any
-optimal reduction method, leading to the more general Model Function framework. Also note that Line 5 covers both the initialization and the update of the Model Function. For brevity, details on the implementation are omitted at this point. MATLAB® code for the proposed algorithms is provided with this paper as functions of the sssMOR toolbox [Citation24].
Algorithm 2 Confined IRKA (CIRKA)
Input: FOM ; Initial interpolation data
,
,
Output: reduced model , Model Function
, error estimation
1: ;
empty; //Initialization
2: ,
,
;
3: while not converged do
4:
5: updateModelFunction
6: IRKA
7: blkdiag
;
;
8: end while
9:
10: norm
4.2. An illustrative example
To make the explanation of the framework clearer, we include a simple numerical example to accompany the discussion. As a test model we consider the benchmark model beam [Citation21] of order with
. Our aim is to find a model of reduced order
satisfying
-optimality conditions. We assume that no previous information about the relevant frequency region is given, hence the initialization is chosen with interpolation frequencies
, corresponding to
. As the model is SISO, there is no need to specify tangential directions.
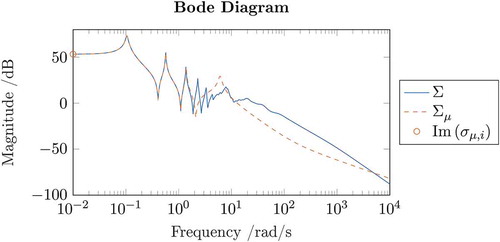
Step 1: Initialization of As initial order for the Model Function we select
. In this particular case, both initializations I.1 and I.2 of
coincide. shows the Bode plot of
and the resulting
Footnote3. The orange circles indicate the imaginary part of the frequencies used to initialize the Model Function.
Figure 3. Illustrative Bode plot of and its Model Function
.
Step 2: 2 optimization with respect to
shows the reduced-order model
resulting from the optimization with respect to
.
Figure 4. Comparison of ,
and
after
optimization.
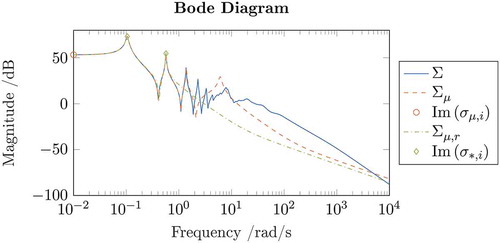
In this example, IRKA converged in steps at optimal frequencies
, whose imaginary parts are depicted in by green diamonds. In this case, by inspection of the Bode plot, we see that
appears to be an acceptable approximation also of the original model
for the given order
. This is a result of
being a valid approximation of
also locally around the new frequency region represented by
. However, this need not hold true in general. For this reason, an update of the Model Function is performed.
Step 3: Update of and fixed-point iteration Using
, we update
to
by including interpolation of the full-order model
with respect to the frequencies in
. As all optimal frequencies differ from those used for initialization of
, update strategies U.1 and U.2 coincide in this case. shows the updated Model Function
of order
for the beam example, as well as the reduced-order model
and new optimal frequencies
resulting from IRKA on
.
Figure 5. Comparison of ,
and
after repeated
optimization.
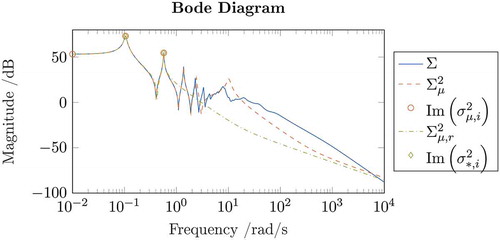
In this example, IRKA converges (within some tolerance) to the same optimal frequencies and hence the whole framework required
iterations until convergence. The fact that an update of the Model Function does not yield a new optimum indicates that the Model Function
was already accurate enough in the region around
.
Finally, note that while this framework has required 3 full-sized LU decompositions to generate and update the Model Function, a direct application of IRKA to requires
full-sized LU decompositions, i.e. more than double the amount. A deeper discussion and comparison of the complexities will be given in Section 4.5 and Section 5. It is also worth noting that both CIRKA and IRKA converge to the same local optimum.
4.3. Optimality of the new framework
So far, the new framework has been presented as a heuristic to perform surrogate optimization and – hopefully – reduce the overall reduction cost. The update of
has been introduced to increase the accuracy of the surrogate model in the frequency regions the optimizer seemed to deem as important. However our original intent was to obtain a reduced model
satisfying the
-optimality conditions (17). The question still remains as to whether this goal has been achieved. In this section, we prove that the update of
is sufficient to satisfy the optimality conditions (17) at convergence.
Theorem 4.2. Consider a full-order model as in (1) with transfer function
. Let
satisfy
with matrices ,
,
and
,
,
. Consider the Model Function
with transfer function
. Let
satify
with matrices ,
,
and
,
,
. Consider the reduced Model Function
with transfer function
. Further, assume that for every
, the triplets
satisfy
where
is the pole/residue representation of the reduced Model Function.
If, for every , there exists a
, such that
then satisfies the first-order
optimality conditions
for all
Proof. By Theorem 2.1 and Theorem 2.4, construction of with the projection matrices satisfying (26) results in a reduced model that is a bitangential Hermite interpolant of the Model Function
with respect to the interpolation data
,
, and
. In combination with the assumption
, this yields the relationship
for all . In addition, from (27) and (25) follows
for all . Equating (29) and (30) completes the proof. ◸
All assumptions of Theorem 4.2 are satisfied if results from an
-optimal reduction of
and the Model Function
is properly updated during algorithm 2. In fact, the assumption (27) can be seen as an update condition for the Model Function
. Theorem 4.2 proves that the new framework results – at convergence – in a reduced model
locally satisfying the optimality conditions (17) and hence effectively solves the
-optimal reduction problem (14). In addition, it is possible to show that the reduced model
has the same state-space realization as one obtained through direct projection of the full model
.
Corollary 4.3. Consider a full-order model as in (1). Let all assumptions of Theorem 4.2 hold. Further, let
be projection matrices satisfying Sylvester equations of the form
Consider the reduced model resulting from the projection
. Then it holds
Proof. The proof amounts to showing that the projection matrices used to obtain and
from projection of
are equal, hence
Consider the Sylvester equation (26a), for which holds
Obviously, by comparing this equation to (31a), the relation (33a) is sufficient to show that (34) is satisfied. In order to show that (33a) is also necessary, we assume that the term in the brackets does not vanish. By defining , the product (34) can be rewritten as
which needs to hold true for all and
. Due to the update condition (27), for every
there exists a
such that
. For all such
combinations, we can hence consider the inner product between the jth row of
and the ith column in the bracket
where is a vector with 1 on the ith entry and otherwise 0. Since (36) needs to hold true for all possible
, it finally follows that
which by Theorem 2.4 and (31a) corresponds exactly to . As (37) holds true for all columns
, we finally obtain
. The proof for
is analogous. □
The results of Theorem 4.3 require all projection matrices to be primitive bases (cf. Theorem 2.3). In practical applications, this is not the case. In general, the realizations and
will be restricted system equivalent, i.e. sharing the same order and transfer function.
4.4. Interpretations of the new framework
The new framework introduced in this section, which we refer to as the Model Function framework in general or Confined IRKA (CIRKA) when applied to IRKA, can be given different interpretations. On the one hand, it is a form of surrogate optimization [Citation25] in that the optimization is not conducted on the actual cost function
but on an approximation
. In fact, the framework itself is an application of reduced-model based optimization [Citation26]. On the other hand, the framework can be seen as
optimization in a subspace, defined by the matrices
and
, that is updated at every iteration. In fact, this technique could be interpreted as a subspace acceleration method [Citation27] to recycle information obtained in a previous optimization step. Traditionally, subspace acceleration methods in numerics are used to ameliorate the convergence of iterative methods. In our setting, this becomes the convergence to a set of optimal reduction parameters. Finally, one may think of it as a restarted
optimization, where e.g. IRKA is restarted in a higher-dimensional subspace after convergence.
4.5. The cost of the new framework
The discussion so far has shown how the reduced-order model , resulting from the Model Function framework, indeed satisfies
-optimality conditions. What still remains to be discussed is whether we can expect this framework to be computationally less demanding than simply applying
-optimal reduction to the full-order model. To address this question, we compare the cost of IRKA, estimated in (19), to the cost of CIRKA. Following similar considerations as in Section 3, we obtain the relationship
where is the number of iterations of the new framework,
indicates the size of the Model Function update in each step, and
is the number of IRKA iterations in each step of the new framework. The first summand represents the cost of updating the Model Function with information of the full-order model and could be interpreted as the cost of reduction. The second summand adds up the cost of IRKA in each iteration and depends on the number of optimization steps in IRKA
, as well as
-dimensional LSEs. As it can be seen from (38), the cost involved in finding optimal parameters is in some sense decoupled from the cost of reduction, although a link through
still remains. Obviously, as
increases, we expect
. Hence the dominant cost is represented by the cost of reduction, whereas the number of optimization steps
plays no role. Therefore, comparing (19) and (38) we expect the new framework to be cost effective as long as
where in this case represents the number of iterations required by IRKA to directly reduce the full order model. In Section 5, numerical results will illustrate the substantial speedup that can be achieved by using this framework.
It becomes apparent from (39) that the number of iterations of the new framework may have an impact on its performance. Unfortunately, to date there are no results on the convergence speed or even a guarantee of convergence for the new framework. In practice, we observe that its convergence is affected by the convergence behaviour of the
optimization itself. Whenever IRKA has difficulties in converging, e.g. due to inconvenient initialization or choice of reduced order, then the frequencies and tangential directions returned after the maximum number of iterations is reached are likely to change after every iteration. In this respect, the new framework offers new opportunities to deal with IRKA convergence issues, in allowing a high number of maximum iterations at a low cost, with the possibly of reinitializing IRKA with different parameters if no convergence is reached. Conversely, for
descent methods as [Citation11], no convergence issues have been observed.
4.6. Further advantages of the new framework
We conclude this section by addressing another advantage of this framework, compared to conventional optimization. In fact, in the process of generating an
-optimal reduced-order model
, we naturally obtain an intermediate reduced-order model
at no additional cost. This Model Function has a reduced order
and is – though not being
-optimal – in general a better approximation to
than
. This is especially true if update strategies U.1 or U.2 are used. For this reason, by assuming
, we can estimate the relative reduction error
through
Obviously, the validity of the estimation (40) highly depends on the approximation quality of . Nonetheless, as rigorous error estimation is still a big open challenge in model reduction by tangential interpolation, this type of indicator may be of interest, even though no claim about its rigorosity can be made. Note that this error estimation is very similar to the one in [Citation7], where data-driven approaches are used to generate a surrogate model from data acquired during IRKA. As reduced models obtained by projection can become unstable, in general it is necessary to take the stable part of
after convergence to be able to evaluate (40). As
is small, this can be easily computed, for example in MATLAB using the stabsep command. Note that even though in theory no claim can be made about the stability of reduced-order models obtained by IRKA, in practice more often then not the resulting reduced models are stable. We make the same observation for CIRKA. Finally, by making the cost of optimization negligible, the new framework allows to introduce globalized local optimization approaches [Citation28], where local reduction is performed from different start points, increasing the chance of finding the global minimum [Citation29].
5. Numerical results
In this section, we compare IRKA and CIRKA in the reduction of a benchmark model taken from the collection [Citation22]. The model (gyro) represents a micro-electro mechanical butterfly gyroscope [Citation30] and has a full order of ,
input and
outputs. The computations were conducted on an Intel® Xeon® CPU @ 2.27 GHz computer with four cores and 48 GB RAM.
-optimal reduced models for the reduced orders
are constructed using both IRKA and CIRKA, run using the sssMOR toolbox implementations. The execution parameters were set to default, in particular the chosen convergence tolerance was set to Opts.tol = 1e-3 and the convergence was determined by inspection of the optimal frequencies
(Opts.stopCrit = ‘s0ʹ) in IRKA and optimal frequencies
and tangential directions
,
(Opts.stopCrit = ‘s0+tanDir’) in CIRKA. The initial frequencies in
were all set to
, whereas all initial tangential directions in
and
were set to
of appropriate dimensions. In CIRKA, strategies I.2 for initialization and U.2 for Model Function updates were used. The results are summarized in .
Table 1. Reduction results for the gyro model using zero initialization.
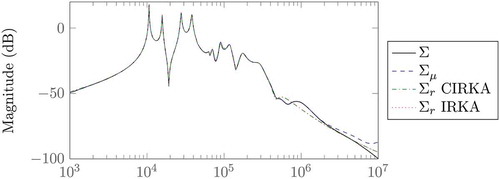
For all three cases considered, CIRKA required significantly less full-dimensional LU decompositions compared to IRKA. This is reflected also in the significant speedup in reduction time, ranging from four to over 20 times faster than IRKA. Note that for the case , IRKA did not converge within the maximum number of steps. On the other hand, CIRKA converges to a local optimum, hence reaching a lower relative approximation error. As the model represents an oscillatory system with weakly damped eigenfrequencies and many outputs, it is hard to approximate well with a low reduced order, as the relative approximation errors in reflect. Nevertheless, a comparison of the reduced models in a Bode diagram shows a good approximation, as it is depicted in exemplary for the case
and the 9th output.
Figure 6. Reduction of the gyro model using CIRKA and IRKA (, 9th output).
To analyse the dependency of the results in from the initialization, summarizes the results for initial frequencies and tangential directions corresponding to the mirrored eigenvalues with smallest magnitude and respective input/output residues of the full model . This choice of initial parameters is known to be advantageous [Citation31,Citation32], its computation can be performed efficiently for large-scale sparse models using iterative methods (cf. e.g. the MATLAB command eigs).
Table 2. Reduction results for the gyro model using eigs initialization.
Interestingly, for the case , IRKA converged to the default tolerance in one step, requiring only 5 LU decompositions. As CIRKA required two iterations until convergence, the number of full-dimensional LU decomposition required were 6. In this special case, IRKA was faster than CIRKA. In addition, comparison of the relative
error indicates that IRKA converged to a better local minimum. A comparison with the respective result of demonstrates that initialization of
-optimal reduction can have a large impact on the optimization and the results. For the other two cases, the pattern is similar to what discussed so far. In particular, the speedup obtained through CIRKA is significant.
Comparing the values of in and , we see that the value for CIRKA may be below, above, or the same as the one for IRKA. In general, it is not possible to say which method is expected to yield a better approximation quality. Given identical initializations, often times IRKA and CIRKA will converge to the same local optimum, especially in the case of small number of inputs and outputs. However, as the optimization in CIRKA is based on a surrogate of the actual cost function, it may converge to a different (better or worse) local optimum. Note that neither in IRKA, nor in CIRKA, we have control over which local optimum will be found – we only hope to find a local optimum. This is why in [Citation29], an approach to find the global optimum exploiting the Model Function framework is presented.
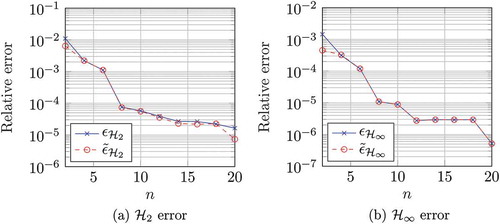
Finally, note that even when IRKA converges in few steps (e.g. 9) a reduction using CIRKA can already result in a significant speedup. Also note that the relative error estimation tends to underestimate the approximation error, which has been observed especially for models with high dynamics. In general, it is not possible to state how far the estimate is from the real error. Nonetheless, given that no rigorous error bounds or estimators are yet available for
-optimal reduction of general systems, we believe a non rigorous estimate at basically no additional cost may be of interest. To further investigate the validity of the error estimation based on the Model Function, Figure 11 compares the error estimations to the true error after reduction with CIRKA for the benchmark model CDplayer [Citation21] and different reduced orders. ) shows the estimation of the
error as defined in (40), whereas in ) an analogous estimation of the
error is given.
Figure 7. Comparison of relative error and its estimation for the CDplayer model.
6. Application to different system classes
The discussion of this contribution has been limited to the model reduction of linear time-invariant systems as in (1) with regular matrix. However,
approximation approaches exist for other system classes as well, including systems of Differential Algebraic Equations (DAEs) [Citation33], systems for which only transfer function evaluations or measurements are available [Citation19], linear systems with time delays [Citation34], linear systems in port-Hamilton form [Citation35], as well as non-linear systems in bilinear [Citation36,Citation37] or quadratic-bilinear form [Citation38]. Obviously, going into the details of all approximation methods above would exceed the scope of this paper. Nonetheless, as we feel that
algorithms for different system classes could also benefit from the framework presented in this contribution, we will give brief indications of what steps and considerations are required to extend this framework. Generally speaking, the idea of surrogate optimization is certainly not new. However, as most methods above are based on interpolation, an update of the surrogate model as presented here can ensure interpolation of the full model with respect to optimal interpolation data, which would be otherwise lost. Once more, we emphasize that the idea presented in this contribution truly is a general framework and not just an additional reduction algorithm by the name of CIRKA. In the following, we briefly indicate for some system classes, how the principle of this new framework could be applied. The goal is to reduce the computational cost while still satisfying the same conditions as the original algorithms. Due to the brevity of the following subsections, readers who are not familiar with the system classes mentioned might prefer to skip these discussions.
6.1. DAE systems
DAE systems are state-space representations as in (1) having a singular matrix . Their transfer function can be generally decomposed into the sum of a strictly proper part
, satisfying
, and a polynomial part
, a polynomial in
of order at most
, the so called index of the DAE [Citation39]. Due to this polynomial contribution, approximation by tangential interpolation is not sufficient to prevent the reduction error to become unbounded, which is a result of a mismatch in the polynomial part. For this reason, in the reduction the polynomial part needs to be matched exactly, while the strictly proper part can be approximated through tangential interpolation. To achieve tangential interpolation of the strictly proper part while preserving the polynomial part, the subspace conditions in (4), (5) can be adapted by including spectral projectors onto deflating subspaces [Citation33, Theorem 3.1]. Based on this, Gugercin, Stykel and Wyatt show in [Citation33, Theorem 4.1] that interpolatory
-optimal reduction of DAEs can be performed by using the modified subspace conditions to find an
approximation to the strictly proper part
.
For this system class, an extension of the Model Function framework is quite straightforward: By computing a Model Function following the modified interpolatory subspace conditions of [Citation33, Theorem 3.1], optimization can be performed on the surrogate instead of on the original DAE. An update of the Model Function finally leads to a reduced-order model that tangentially interpolates the strictly proper part of the original DAE at the optimal frequencies, along the optimal right and left tangential directions.
6.2. Port-Hamiltonian systems
Port-Hamiltonian (pH) formulations of linear dynamical systems are a very effective way to model systems that result from the interconnection of different subsystems, especially in a multi-physics domain. Their representation is similar to (1), where the system matrices have the special structures ,
, and
,
being a skew-symmetric interconnection matrix,
a positive semi-definite dissipation matrix and
a positive definite energy matrix [Citation40]. Models in pH form bear several advantages, such as passivity, and it is therefore of great relevance to preserve the pH structure after reduction. In a setting of tangential interpolation, this can be achieved by computing a projection matrix V according to (4) and choosing
in order to retain the pH structure (cf [Citation35,Citation41].).
Gugercin, Polyuga, Beattie and van der Schaft present in [Citation35] an iterative algorithm by the name of IRKA-PH, that adaptively chooses interpolation frequencies and input tangential directions, inspired by the IRKA iteration. In general, the resulting reduced model will not satisfy the first-order optimality conditions (17), as is not chosen to enforce bitangential Hermite interpolation but rather structure preservation. Nonetheless, the algorithm has shown to produce good approximations in practice.
To reduce the cost involved in repeatedly computing the projection matrices (4) in IRKA-PH, a Model Function in pH form could be introduced and updated. At convergence, the reduced model satisfies the condition (18) while being of pH-form as in the IRKA-PH case. In addition, the resulting Model Function (also in pH form) could be used e.g. for error estimation.
6.3. TF-IRKA
Gugercin and Beattie demonstrate in [Citation19] how to construct a reduced-order model satisfying first-order
optimality conditions (17) only from evaluations of the transfer function
. The algorithm by the name of TF-IRKA exploits the Loewner-Framework, a data-driven approximation approach by Mayo and Antoulas [Citation42] that produces a reduced model that tangentially interpolates the transfer function of a given system, whose transfer behaviour can be measured or evaluated at selected frequencies. Therefore, this algorithm can be used to obtain a reduced-order model satisfying optimality conditions for irrational, infinite dimensional dynamical systems for which an expression for
can be obtained by direct Laplace transformation of the partial differential equation, i.e. without prior discretization. In addition, it can be used for optimal approximation of systems where no model is available but the transfer behaviour
can be measured in experiments. Similar approaches have been derived to obtain reduced-order models for systems with delays [Citation43].
The cost of TF-IRKA is dominated by the evaluation of the transfer function . In general, if an analytic expression is given, this cost is minimal compared to evaluating a discretized high-order model. However, if the evaluation is obtained through costly measurements, an approach to reduce the number of evaluations would be highly beneficial. In [Citation44], Beattie, Drma
, and Gugercin introduce a quadrature-based version of TF-IRKA for SISO models, called Q-IRKA, that only requires the evaluation of
once for some frequencies (quadrature nodes) and returns a reduced-order model that satisfies the optimality conditions (17) within the quadrature error. In [Citation45], the same authors propose a similar approach by the name of QuadVF, based on vector fitting rational approximations using frequency sampling points.
By exploiting the new framework presented in this paper, it is possible to reduce the number of evaluations of and satisfy the optimality conditions (17) exactly. By creating a surrogate using the Loewner-Framework, standard IRKA can be applied to obtain a new set of frequencies and tangential directions. Evaluating (or measuring)
for the new optimal frequencies allows to update the surrogate and repeat the process. Compared to Q-IRKA, this approach bears the additional advantage of automatically finding the amount and position of suitable frequencies for evaluating
. In contrast, Q-IRKA and QuadVF require the initial evaluation of
at some pre-specified quadrature nodes. While a judicious spacing of the sampling frequencies in QuadVF was presented in [Citation45], the frequency range and number of sampling points remains a tunable parameter within this approach.
6.4. Nonlinear systems
Model reduction approaches for general non-linear systems typically differ from what discussed in this contribution. However, in the case of weak nonlinearities, a bilinear formulation can be obtained by means of Carleman Bilinearization [Citation46]. For this class of non-linear systems, the dynamic equations are similar to (1) and are complemented by an additional term that sums the weighted product between the state and the inputs. Recently, Benner and Breiten have presented in [Citation36] a Bilinear IRKA (B-IRKA) algorithm that produces a reduced bilinear model satisfying, at convergence, first-order optimality conditions with respect to the bilinear norm for the approximation error. This algorithm requires the repeated solution of two bilinear Sylvester equations, which can be obtained either by vectorization, solving linear systems of the dimension
, or, equivalently, computing the limit to an infinite series of linear Sylvester equations. Flagg and Gugercin have demonstrated in [Citation37,Citation47] for SISO models that the optimality conditions in [Citation36] can be interpreted as interpolatory conditions of the underlying Volterra series ([Citation37, Theorem 4.2]). In addition, they present an algorithm to construct reduced bilinear models that achieve multipoint Volterra series interpolation by construction (cf. [Citation37, Theorem 3.1]), requiring the solution of two bilinear Sylvester equations. Exploiting the often fast convergence of the Volterra integrals, they propose a Truncated B-IRKA (TB-IRKA) that satisfies the first-order optimality conditions asymptotically as the truncation index tends to infinity. Note that extensions to bilinear DAEs were presented by Benner and Goyal in [Citation48].
The interpolatory nature of this approach makes it possible to extend the new framework presented in this paper to bilinear systems, hopefully speeding up the reduction with B-IRKA significantly. In fact, given a set of initial frequencies, a bilinear Model Function can be constructed that interpolates the Volterra series at these frequencies. This would require the solution of the full bilinear Sylvester equations for a few selected frequencies. Using this bilinear surrogate model, B-IRKA can be run efficiently on a lower dimension to find a new set of optimal frequencies and update the Model Function. Note that the cost of solving a full-dimensional bilinear Sylvester equation plays the same role in the complexity of B-IRKA as the cost of a full-dimensional LU decomposition for linear systems. Assuming the convergence behaviour of the new framework is similar to the linear case, this could lead to an algorithm that produces reduced bilinear models that satisfy the
optimality conditions exactly – i.e. without truncation error – at a far lower cost.
In presence of strong nonlinearities, the dynamics can be captured exactly in a quadratic bilinear model where, in addition, a quadratic term in the state variable is present. An approach for this system class has been recently presented by Benner, Goyal and Gugercin in [Citation38] and it is not evident at this point, how the new framework could be applied to this system class while preserving rigor of the results.
7. Conclusions and outlook
In this paper, we have presented a new general framework for -optimal reduction, based on the local nature of (tangential) interpolation and
optimality. The motivation to develop this framework, which can be interpreted e.g. as a surrogate optimization or subspace acceleration approach, has resulted from theoretical and numerical considerations on the cost of
-optimal reduction. By means of updated surrogate optimization, the cost of reduction can be decoupled from the cost of optimization. Through a numerical example, we have illustrated the effectiveness of the new framework in reducing the cost of
-optimal reduction. Theoretical considerations have demonstrated how the reduced-order models resulting from this new framework still satisfy first-order optimality conditions at convergence. The system class discussed in detail in this contribution has been MIMO LTI models. In addition, first indications have been given on how to extend this new framework for
reduction of different system classes, e.g. DAEs and bilinear systems. The new framework not only produces optimal reduced models at a far lower cost than conventional methods, but also provides – at no additional cost – a middle-sized surrogate model that can be used e.g. for error estimation, as demonstrated in numerical examples.
Recent research endeavours exploit the new framework to obtain the global optimum amongst all local optimal reduced models of prescribed order [Citation29]. In current research, the Model Function is used for error estimation in the cumulative reduction framework CURE by Panzer, Wolf and Lohmann [Citation11,Citation12,Citation49] to adaptively chose the reduced order. Finally, the Model Function framework is currently being used in parametric model reduction to recycle the Model Function from one parameter sample point to another and reduce the cost tied to the repeated reduction at several points in the parameter space. Preliminary work is available in [Citation50]. These advances will be topics of future investigations and publications.
Supplementary_materials_MATLAB_toolboxes_sss___sssMOR.zip
Download Zip (647 KB)Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1. For dense matrices, this can be motivated by simple asymptotic operation counts. The QR decomposition of a matrix via Householder requires
flops and is hence linear in
. The flops involved in the product
are
for a dense
and hence quadratic in
. Note however that for a diagonal
matrix – an ideally sparse invertible matrix – the flops become at most
, hence being linear in
[Citation23].
2. For the results of this contribution, we have used sparse LU decompositions, which are still feasible for models of relative large size even on standard machines (cf. ). This approach bears the advantage of allowing the recycling of LU factors, e.g. to solve LSEs with same left-hand sides. If other methods are used instead, some of the values and statements in this contribution may vary. Note, in addition, that complex conjugated pairs of shifts yield complex conjugated directions
. Therefore, the actual number of LSE to be solved may actually vary, making
a worst-case estimate.
3. All numerical examples presented in this contribution were generated using the sss and sssMOR toolboxes in MATLAB® [Citation24].
Related Research Data
References
- T. Penzl, A cyclic low-rank Smith method for large sparse Lyapunov equations, SIAM J. Sci. Comput. 21 (4) (2000), pp. 1401–1418. doi:10.1137/S1064827598347666
- V. Druskin, V. Simoncini, and M. Zaslavsky, Adaptive tangential interpolation in rational Krylov subspaces for MIMO dynamical systems, SIAM J. Matrix Anal. Appl. 35 (2) (2014), pp. 476–498. doi:10.1137/120898784
- P. Kürschner, Efficient low-rank solution of large-scale matrix equations, Ph.D. thesis, Max Planck Institute for Dynamics of Complex Technical Systems, 2016.
- E.J. Grimme, Krylov projection methods for model reduction, Ph.D. Thesis, University of Illinois at Urbana-Champaign, USA, 1997.
- C.A. Beattie and S. Gugercin, Model reduction by rational interpolation, in Model Reduction and Approximation: Theory and Algorithms, P. Benner, A.M. Cohen, M. Ohlberger, eds., et al., math.NA. SIAM, Sep. 2017, Available at http://arxiv.org/abs/1409.2140v1.
- K. Glover, All optimal Hankel-norm approximations of linear multivariable systems and their L∞-error norms, Int. J. Control 39 (6) (1984), pp. 1115–1193. doi:10.1080/00207178408933239
- A. Castagnotto, C.A. Beattie, and S. Gugercin, Interpolatory methods for H2∞ model reduction of multi-input/multi-output systems, in Model Reduction of Parametrized Systems, P. Benner, M. Ohlberger, A. Patera, eds., et al., Vol. 17, Modeling, Simulation & Applications, Springer, Cham, 2017, Chap. 22, pp. 349–365. doi:10.1007/978-3-319-58786-8_22
- S. Gugercin, A.C. Antoulas, and C.A. Beattie, H2 model reduction for largescale dynamical systems, SIAM J. Matrix Anal. Appl. 30 (2) (2008), pp. 609–638. doi:10.1137/060666123
- P. Van Dooren, K. Gallivan, and P.-A. Absil, H2-optimal model reduction of MIMO systems, Appl. Math. Lett. 21 (2008), pp. 1267–1273. doi:10.1016/j.aml.2007.09.015
- C.A. Beattie and S. Gugercin, A trust region method for optimal H2 model reduction, in IEEE Conference on Decision and Control, IEEE, 2009, pp. 5370–5375. doi:10.1109/CDC.2009.5400605
- H.K.F. Panzer, S. Jaensch, T. Wolf, et al. A Greedy Rational Krylov Method for H2-pseudooptimal model order reduction with preservation of stability, in Proceedings of the American Control Conference, 2013, pp. 5512–5517.
- H.K.F. Panzer, Model order reduction by Krylov subspace methods with global error bounds and automatic choice of parameters, Ph.D. thesis, Technische Universität München, 2014.
- A. Castagnotto, H.K.F. Panzer, and B. Lohmann, Fast H2-optimal model order reduction exploiting the local nature of Krylov-subspace methods, in European Control Conference 2016, Aalborg, Denmark, 2016, pp. 1958–1963. doi:10.1109/ECC.2016.7810578
- K. Gallivan, A. Vandendorpe, and P. Van Dooren, Model reduction of MIMO systems via tangential interpolation, SIAM J. Matrix Anal. Appl. 26 (2) (2004), pp. 328–349. doi:10.1137/S0895479803423925
- K. Gallivan, A. Vandendorpe, and P. Van Dooren, Sylvester equations and projection-based model reduction, J. Comput. Appl. Math. 162 (1) (2004), pp. 213–229. doi:10.1016/j.cam.2003.08.026
- A.C. Antoulas, Approximation of Large-Scale Dynamical Systems, Vol. 6, Advances in Design and Control, SIAM Publications, Philadelphia, PA, 2005, ISBN 9780898715293. doi:10.1137/1.9780898718713
- A.C. Antoulas, C.A. Beattie, and S. Gugercin, Interpolatory model reduction of large-scale dynamical systems, in Efficient Modeling and Control of Large-Scale Systems, Springer US, 2010, pp. 3–58. doi:10.1007/978-1-4419-57573_1
- L. Meier and D.G. Luenberger, Approximation of linear constant systems, IEEE Trans. Autom. Control 12 (5) (Oct., 1967), pp. 585–588. doi:10.1109/TAC.1967.1098680
- C.A. Beattie and S. Gugercin, Realization-independent H22-approximation, in 51st IEEE Conference on Decision and Control, IEEE, 2012, pp. 4953–4958. doi:10.1109/CDC.2012.6426344
- Y. Saad, Iterative Methods for Sparse Linear Systems, SIAM, 2003.
- Y. Chahlaoui and P. Van Dooren, A collection of benchmark examples for model reduction of linear time invariant dynamical systems, Tech. rep. 2002-2, SLICOT Working Note, 2002. Available at www.slicot.org.
- J.G. Korvink and E.B. Rudnyi, Oberwolfach benchmark collection, in Dimension Reduction of Large-Scale Systems, P. Benner, D.C. Sorensen, and V. Mehrmann, eds., Vol. 45, Lecture Notes in Computational Science and Engineering, Springer Berlin Heidelberg, 2005, pp. 311–315. doi:10.1007/3-54027909-1_11
- G.H. Golub and C.F. Van Loan, Matrix Computations, Johns Hopkins University Press, Baltimore, 1996.
- A. Castagnotto, M. Cruz Varona, and L. Jeschek, sss & sssMOR: analysis and reduction of large-scale dynamic systems in MATLAB, atAutomatisierungstechnik, 65 (2) (2017), pp. 134–150. doi:10.1515/auto-20160137
- N.V. Queipo, R.T. Haftka, W. Shyy, T. Goel, R. Vaidyanathan, and P. Kevin Tucker, Surrogate-based analysis and optimization, Prog. Aerosp. Sci. 41 (1) (2005), pp. 1–28. doi:10.1016/j.paerosci.2005.02.001
- P. Benner, Z. Tomljanović, and N. Truhar, Optimal damping of selected eigenfrequencies using dimension reduction, Numer. Lin. Alg. Appl. 20 (1) (2013), pp. 1–17, ISSN . doi:10.1002/nla.833
- J. Rommes and N. Martins, Effcient computation of transfer function dominant poles using subspace acceleration, IEEE Trans. Power Syst. 21 (4) (2006), pp. 1218–1226. doi:10.1109/TPWRS.2006.876671
- J.D. Pintér, Global Optimization in Action: Continuous and Lipschitz Optimization: Algorithms, Implementations and Applications, Vol. 6, Springer Science & Business Media, 2013.
- A. Castagnotto, S. Hu, and B. Lohmann, An approach for globalized H2-optimal model reduction, in Proceedings of the 9th Vienna International Conference on Mathematical Modelling, 2018.
- J. Lienemann, D. Billger, E.B. Rudnyi, et al., MEMS compact modeling meets model order reduction: Examples of the application of Arnoldi methods to microsystem devices, in The Technical Proceedings of the 2004 Nanotechnology Conference and Trade Show, Nanotech, Vol. 4, 2004.
- S. Gugercin, Projection methods for model reduction of large-scale dynamical systems, Ph.D. thesis, Rice University, 2003. Available at http://hdl.%20handle.%20net/1911/18536.
- S. Gugercin and A.C. Antoulas, An H2 error expression for the Lanczos procedure, in 42nd IEEE Conference on Decision and Control, Vol. 2, IEEE, 2003, pp. 1869–1872.
- S. Gugercin, T. Stykel, and S. Wyatt, Model reduction of descriptor systems by interpolatory projection methods, SIAM J. Sci. Comput. 35 (5) (2013), pp. B1010–B1033. doi:10.1137/130906635
- I. Pontes Duff, S. Gugercin, C. Beattie, C. Poussot-Vassal, and C. Seren, H2-optimality conditions for reduced time-delay systems of dimension one, IFAC Pap. OnLine 49 (10) (2016), 13th IFAC Workshop on Time Delay Systems TDS 2016, pp. 7–12. doi:10.1016/j.ifacol.2016.07.464
- S. Gugercin, R.V. Polyuga, C. Beattie, and A. van der Schaft, Structure-preserving tangential interpolation for model reduction of port-Hamiltonian systems, Autom. 48 (9) (2012), pp. 1963–1974. doi:10.1016/j.automatica.2012.05.052.
- P. Benner and T. Breiten, Interpolation-based H2-model reduction of bilinear control systems, SIAM J. Matrix Anal. Appl. 33 (3) (2012), pp. 859–885. doi:10.1137/110836742
- G.M. Flagg and S. Gugercin, Multipoint volterra series interpolation and H2Optimal model reduction of bilinear systems, SIAM J. Numer. Anal. 36 (2) (2015), pp. 549–579. doi:10.1137/130947830
- P. Benner, P. Goyal, and S. Gugercin, H2-quasi-optimal model order reduction for quadratic-bilinear control systems, arXiv Preprint arXiv:1610.03279 (2016).
- P. Benner and T. Stykel, Model Order Reduction for Differential-Algebraic Equations: A Survey, Springer, 2017, pp. 107–160.
- A. van der Schaft, L2-Gain and Passivity Techniques in Nonlinear Control, 3rd ed., Springer, 2017.
- T. Wolf, B. Lohmann, R. Eid, and P. Kotyczka, Passivity and structure preserving order reduction of linear port-Hamiltonian systems using Krylov subspaces, Eur. J. Control 16 (4) (2010), pp. 401–406. doi:10.3166/ejc.16.401-406
- A.J. Mayo and A.C. Antoulas, A framework for the solution of the generalized realization problem, Linear Algebra Appl. 425 (2–3) (2007), Special Issue in honor of P. A. Fuhrmann, Edited by A. C. Antoulas, U. Helmke, J. Rosenthal, V. Vinnikov, and E. Zerz, pp. 634–662, ISSN: . doi:10.1016/j.laa.2007.03.008
- I. Pontes Duff, C. Poussot-Vassal, and C. Seren, Realization independent single time-delay dynamical model interpolation and H2-optimal approximation, in 2015 54th IEEE Conference on Decision and Control (CDC), Dec. 2015, pp. 4662–4667. doi:10.1109/CDC.2015.7402946
- C. Beattie, Z. Drmač, and S. Gugercin, Quadrature-based IRKA for optimal H2 model reduction, IFAC Pap. OnLine 48 (1) (2015), 8th Vienna International Conferenceon Mathematical Modelling, pp. 5–6. doi:10.1016/j.ifacol.2015.05.196.
- Z. Drmač, S. Gugercin, and C. Beattie, Quadrature-based vector fitting for discretized H2 approximation, SIAM J. Sci. Comput. 37 (2) (2015), pp. A625–A652. doi:10.1137/140961511
- W.J. Rugh, Nonlinear System Theory, Johns Hopkins University Press Baltimore, 1981.
- G.M. Flagg, Interpolation methods for the model reduction of bilinear systems, Ph.D. Thesis, Virginia Polytechnic Institute and State University, Blacksburg, Virginia, Apr. 2012.
- P. Benner and P. Goyal, Multipoint interpolation of volterra series and H2Model reduction for a family of bilinear descriptor systems, Syst. Control Lett. 97 (2016), pp. 1–11. doi:10.1016/j.sysconle.2016.08.008
- T. Wolf, Pseudo-optimal model order reduction, Dissertation, Technische Universität München, Munich, Germany, 2015.
- J. Peters, Parametrische modellordnungsreduktion mit dem H2-optimalen Modellfunktions-Framework, Bachelor Thesis, Technical University of Munich, Oct. 2017.