
ABSTRACT
Part 2 of this study investigates the implications of random, small-scale contaminant concentration variability in soil for reliance on discrete soil sample data to guide environmental investigations. Random variability around an individual point limits direct comparison of discrete sample data to risk-based screening levels. “False negatives” can lead to premature termination of an investigation or remedial action. Small-scale distributional heterogeneity of contaminants in soil is expressed as artificial, seemingly isolated “hot spots” and “cold spots” in isoconcentration maps. Surgical removal of hot spots can lead to erroneous conclusions regarding the magnitude of remaining contamination. The field precision of an individual discrete sample data set for estimation of means for a contaminant in a risk assessment is not directly testable. Omission of “outlier” data in order to force data to fit a geostatistical model distorts estimates of mean concentrations and introduces error into a risk assessment. The potential for such errors was pointed out in early USEPA guidance but largely ignored or misunderstood. Decision Unit and Multi Increment sample investigation methods, long known to the agricultural and mining industries, were specifically developed to overcome these inherent shortcomings of discrete sampling methods and provide more reliable and defensible data for environmental investigations.
Introduction
The field study presented in Part 1 of this paper (Brewer et al., Citation2016) was designed to address a basic question: What is the variability of contaminant concentrations in soil around a fixed point at the scale of a typical, discrete soil sample? A significant variability in data for “co-located” or “split” samples as well as data for replicate analyses by the laboratory samples is often simplistically blamed on “laboratory error.” The results of this study document that the error more likely lies in a misunderstanding of the heterogeneous nature of contaminants in particulate media such as soil (HDOH, Citation2015a,b).
The concentration of a chemical in a heterogeneous particulate media such as soil is directly tied to the mass of soil represented by the field sample and subsample tested by the laboratory. As documented in Part 1, discrete sample data provided by the laboratory cannot reliably be assumed to represent the sample submitted, and the sample submitted cannot reliably be assumed to represent the immediate area where the sample was collected. Data reported by a laboratory for a discrete soil sample can only be assumed to be representative of the subsample mass actually extracted and tested. The data for a given sample therefore may or may not have any relevance to the overall objectives of a site investigation.
The area, volume, and total mass of soil for which an average concentration of a chemical is desired are referred to in Sampling Theory as the “Decision Unit” (DU; HDOH, Citation2016; ITRC, Citation2012; see also Minnitt et al., Citation2007; Pitard, Citation1993, Citation2009; Ramsey and Hewitt, Citation2005; USEPA, Citation1999). Note that all data for particulate media such as soil represent an “average” of the particles tested, regardless of how the sample was collected and analyzed. The concept of DUs is well understood in the agriculture, mineral exploration, and food industries, where it is referred to as a “batch” or “lot” (see also AAFCO, Citation2015). The level of available nutrients for a particular field or area of a field might be desired to assist in fertilizer application. Estimation of the mean concentration and ultimately the total mass of gold in a preliminarily identified ore deposit is needed to determine if the deposit is economically viable. In each case, the objective is to determine the concentration of a targeted chemical for the DU volume of media as a whole. Ideally, the entire DU would be submitted to a laboratory for analysis of a single unit. This is not practical in most cases, so a sample of the DU media must be collected.
A well-designed, step-by-step approach to representative sampling based on sampling theory has only recently been utilized for the investigation of potentially contaminated soil in the environmental industry (e.g., HDOH, Citation2016; ITRC, Citation2012). Testing of soil in many cases and many areas is still reliant on discrete sample methods described in Part 1 of this paper. Multiple factors are responsible for the continued use of discrete sampling and subsampling methods in the field and in the laboratory. The number of environmental investigations rose exponentially in the 1980s following passage of federal legislation such as the Resource Conservation and Recovery Act and the publishing of associated regulations and guidance. With little experience to go by, and only marginally aware of the field of Sampling Theory developing in other industries, the authors of early environmental guidance quickly adopted sample collection and testing methods already in place for evaluation of liquid wastes (e.g., USEPA, Citation1985, Citation1986, Citation1989a). Testing of small subsamples from a relatively small number of samples is common practice for these types of media, where the concentration of a contaminant in any given volume/mass of a waste stream can be assumed to be reasonably uniform. Test methods were designed to evaluate temporal rather than spatial variability in contaminant concentrations. The size of the sample collected was largely driven by laboratory needs with respect to the analytical method to be employed and any additional mass required for quality assurance and control measures. Collecting relatively few numbers of discrete samples intended to represent a specific contaminated area also limited costs associated with sample acquisition.
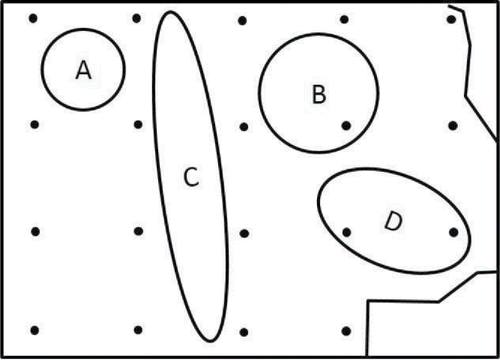
Authors of early soil sampling guidance assumed that a similar approach would be adequate to identify “hot spots” of contaminated soil that could pose a potential risk to human health (USEPA Citation1987; USEPA Citation1989a, Citation1991, Citation1992a; refer to supplement). This is depicted in Figure 1, taken from the USEPA Methods for Evaluating the Attainment of Cleanup Standards guidance (USEPA Citation1989a). The figure is used to illustrate how an excessively large grid spacing might inadvertently miss large “hot spots” that would otherwise be detected with a single discrete soil sample.
Such methods are not, however, effective for heterogeneous particulate media such as soil, where spatial rather than temporal variability of contaminant concentrations is of primary importance. Unlike a liquid, and as demonstrated in Part 1 of this paper, the concentration of a contaminant in small masses of soil can vary dramatically and randomly both within an individual discrete sample and between closely spaced co-located samples. A laboratory will, of course, report a concentration for the mass of soil tested, but the relevance of the resulting data to the objectives of the investigation will be uncertain. Representative testing of contaminants in heterogeneous particulate matter requires much greater attention to the desired resolution of concentration data in terms of the site investigation objectives. This is carried out in the DU designation stage of an investigation (HDOH, Citation2016; ITRC, Citation2012).
Concern regarding potential error associated with reliance on traditional discrete soil sampling methods has been growing for some time (e.g., Hadley and Sedman, Citation1992; Pitard, Citation1993; Ramsey and Hewitt, Citation2005). As stated by Hadley and Petrisor (Citation2013):
It has been clear for some time that the major sources of error in soil sampling for chemical contamination come not from laboratories but from field sampling and subsampling. This situation is—and should be—of concern to environmental forensic scientists. Legal arguments and determinations are based on the prevailing standards of science and practice and often rely on relevant requirements, policies, and guidance from regulatory agencies. Perhaps as a result of deferring to regulatory agencies many of these legal proceedings have focused primarily on the potential for laboratory error rather than on the potential for sampling error. (p. 109)
In this paper, we briefly review the causes of random small-scale variability of contaminant concentrations in soil. We then use data from the field study described in Part 1 as well as other examples to explore the specific types of sampling error likely to be associated with the use and interpretation of discrete sample data in environmental investigations. In the Supporting Information provided with this paper, we also trace the roots of the entrenchment of discrete soil sampling methods in the environmental industry, highlight multiple calls for caution, and emphasize the eventual need for development of robust and reliable investigation methods.
Heterogeneity and hot spots
Distributional heterogeneity
The variability of contaminant concentrations observed between and within discrete soil samples collected during the study is controlled by three factors, each of which is a function of what Sampling Theory (Pitard, Citation1993) refers to as “distributional heterogeneity”: 1) large-scale differences in the amount of the contaminant released in different parts of the study sites; 2) random, small-scale heterogeneity of contaminant distribution in soil at the scale of the sample collected (e.g., five grams to a few hundred grams); and 3) random, small-scale heterogeneity of contaminant distribution within an individual sample at the scale of the mass of soil analyzed by the laboratory (e.g., 0.5 to 30+ g). Large-scale variability is related to the release of greater amounts of a contaminant in one area, typically several hundred to several thousand square feet and a volume of several hundred to several thousand cubic yards of soil (HDOH, Citation2016; ITRC, Citation2012). The identification of such areas and assessment of the potential risk to human health and the environment is the primary objective of most site investigations. The term “small-scale” variability is used in the context of this report to collectively describe random intra-sample and inter-sample variability of contaminant concentrations in discrete samples collected around an individual grid point, typically at the scale of a few grams to a few tens or hundreds of grams (refer to Part 1). While it is important to consider and capture small-scale variability when designing a sampling plan, attempt to characterize a site at the scale or resolution of a discrete sample is neither practical nor necessary in terms of evaluating potential risk to human health and the environment (see HDOH, Citation2016).
The magnitude of random variability increases as the sample mass decreases. Variability in contaminant concentrations within an individual 200-g discrete sample at the scale of a laboratory subsample (e.g., 0.5–30 g) might span one or more orders of magnitude. At some scale, perhaps the scale of an individual particle or even the coating on a particle, the minimum and maximum concentrations of a contaminant in soil will necessarily be 0% and 100%. Attempt to identify the “maximum” concentration of a contaminant in soil at the arbitrary scale of a discrete soil sample or laboratory subsample is both impractical and again irrelevant in terms of evaluating potential risk to human health and the environment. The maximum concentration of a contaminant identified in a small set of discrete samples collected within an area cannot be assumed to represent the maximum concentration of the contaminant present for the tested mass of soil. A relatively small 100 m2 area to a depth of 5 cm will contain, for example, approximately 5,000 kg of soil. Identification of the maximum concentration of a contaminant in any given 0.5 g, 30 g, or even 200 g mass of soil within this area would require an enormous amount of sample collection and provide no added benefit to the objectives of the site investigation.
The cause of random variability of contaminant concentrations in discrete soil samples is straightforward: the mass of the sample and the area over which the sample is collected are too small to overcome random distributional heterogeneity of the contaminant within the soil. This dilemma, well known in the agriculture and mining industry, is identified as “Fundamental Error” in the Gy Sampling Theory (Pitard, Citation1993, Citation2009; see also Minnitt et al., Citation2007; Ramsey and Hewitt, Citation2005; USEPA, Citation1999). Although Fundamental Error can never be completely eliminated, its effect can be minimized by careful sampling design and ensuring that samples are collected, processed, and tested in a representative, unbiased manner (e.g., collection of adequate sample mass from an adequate number of locations with an appropriate collection tool in both the field and the laboratory). Error associated with random distributional variability of a contaminant within a sample, referred to as “intra-sample variability” in Part 1, can in theory be largely eliminated by the use of proper field collection, processing, and laboratory subsampling techniques (Minnitt et al., Citation2007; Pitard, Citation1993, Citation2005, Citation2009). Error associated with random distributional heterogeneity between closely spaced discrete soil samples, referred to as “inter-sample variability” in Part 1, cannot be eliminated, since this is an inherent property of the soil under investigation (Minnitt et al., Citation2007; Pitard, Citation1993, Citation2005, Citation2009). This error can, however, be minimized through the use of Decision Unit and Multi Increment sample (DU-MI) investigation approaches for soil (HDOH, Citation2016), also referred to as Incremental Sampling Methodology or “ISM” (ITRC, Citation2012; The term “Multi Increment®” is trademarked by Charles Ramsey and EnviroStat, Inc.; see Ramsey and Hewitt, Citation2005.)
The potential that discrete soil samples were too small to overcome random variability of contaminant concentrations in soil was not unknown to authors of early USEPA guidance documents. The USEPA guidance document A Rationale for the Assessment of Errors in the Sampling of Soils discussed the need for “representative sampling” (USEPA, Citation1990):
Soils are extremely complex and variable which necessitates a multitude of sampling methods… A soil sample must satisfy the following: 1) Provide an adequate amount of soil to meet analytical requirements and be of sufficiently large volume as to keep short range variability reasonably small… The concentrations measured in an heterogeneous medium such as soil are related to the volume of soil sampled and the orientation of the sample within the volume of earth that is being studied. The term ‘support’ is used to describe this concept. (p. 5)
The same document warned that errors in the collection and representativeness of soil samples were likely to far outweigh errors in analysis of the samples at the laboratory (USEPA, Citation1990):
During the measurement process, random errors will be induced from: sampling; handling, transportation and preparation of the samples for shipment to the laboratory; taking a subsample from the field sample and preparing the subsample for analysis at the laboratory, and analysis of the sample at the laboratory (including data handling errors)… Typically, errors in the taking of field samples are much greater than preparation, handling, analytical, and data analysis errors; yet, most of the resources in sampling studies have been devoted to assessing and mitigating laboratory errors. (p. 3)
Addressing errors in the laboratory was and has continued to be “low-hanging fruit” that received the greatest focus of attenuation over the past 20–30 years (USEPA, Citation1990):
It may be that those errors have traditionally been the easiest to identify, assess and control. This document adopts the approaches used in the laboratory, e.g. the use of duplicate, split, spiked, evaluation and calibration samples, to identify, assess and control the errors in the sampling of soils. (p. 3)
Random small-scale variability of contaminant concentrations in small masses of soil is predicted by sampling theory, but outside of munitions-related sites, had not been widely studied in the field (e.g., see USACE, Citation2009). The effects of random variability of contaminant concentrations within a targeted area at the scale of a discrete sample can lead to significant error in decision-making regarding the extent and magnitude of contamination present. The implications of these factors, once recognized and acknowledged, are likewise significant.
Implications
Comparison of discrete sample data to screening levels
Direct comparison of discrete sample data points to screening levels can lead to significant errors in environmental investigations. Risk-based soil screening levels, including the Regional Screening Levels (RSLs) published by the USEPA (USEPA, Citation2015), are intended for comparison to the concentration of a contaminant within a targeted area of concern or “Decision Unit” as a whole (i.e., the “average”) rather than discrete points within this area. This was made clear in early USEPA soil sampling guidance (USEPA, Citation1989a, emphasis added; see also USEPA, Citation2014 and Supporting Information):
The concentration term in the intake equation is the arithmetic average of the concentration that is contacted over the exposure period. Although this concentration does not reflect the maximum concentration that could be contacted at any one time, it is regarded as a reasonable estimate of the concentration likely to be contacted over time. This is because in most situations, assuming long-term contact with the maximum concentration is not reasonable. (p. 6–19)
Screening levels to assess chronic health risks, for example, are designed to consider regular but random exposure to contaminants in soil within a targeted “exposure area” over many years. Risk is assessed in terms of average daily exposure to contaminants in soil over this time period. The range of contaminant concentrations in soil at the scale of assumed exposure (e.g., 100–200 mg/day) is not important, provided that this is accurately represented in the mean contaminant concentration estimated for the subject area and volume of soil. The USEPA document Guidance on Surface Soil Cleanup at Hazardous Waste Sites (USEPA, Citation2005) notes:
For sampling data to accurately represent the exposure concentration, they should generally be representative of the contaminant populations at the same scales as the remediation decisions and the exposures on which those decisions are based. (p. 5)
Grids of discrete data can sometimes be useful for gross approximation of contaminated versus clean areas (HDOH, Citation2016). The reliability of the data for final decision-making depends in part on the magnitude of small-scale variability of contaminant concentrations in soil with respect to the screening level being used.
Consider, for example, the range of lead concentrations estimated for discrete samples around grid points at Study Site B (refer also to Part 1 supplement). Box plots of total estimated variability depicted in fall both above and below the HDOH residential soil action level for lead of 200 mg/kg (HDOH, Citation2011) at 23 of the 24 grid points. Discrete sample concentrations at 20 of the 24 grid points similarly fall both above and below the USEPA residential soil screening level of 400 mg/kg (USEPA, Citation2015). The wide range of estimated concentrations matches well with the assumed incomplete mixture of lead-contaminated ash and fill soil at the site. Reported concentrations of lead in soil below 100 mg/kg imply that the subsample tested consisted primarily of native fill material, with concentrations approaching natural background (upper threshold limit 73 mg/kg; HDOH, Citation2012). Higher reported concentrations of lead imply a more significant proportion of incinerator ash in the tested soil (typically 1,000–4,000 mg/kg; Shulgin and Duhaas, Citation2008).
Figure 1. Discrete sampling grid designated for a site under investigation overlaid with hypothetical “hot spots” superimposed (USEPA, Citation1989a). Under this approach, an individual discrete soil sample was assumed to be adequate to identify large areas of contamination above potential levels of concern.
Box plots for data from Study Site C depict the extreme variability of total polychlorinated biphenyls (PCBs) concentrations both in subsamples of individual discrete samples as well as in estimated total variability around individual grid points when data for processed samples are considered (). Lines denoting screening levels of 1.1 mg/kg (HDOH residential screening level) and 50 mg/kg are included in the graph. Note the random variability of PCB concentrations both above and below these levels at multiple grid points across the study area. The high small-scale variability highlights an even greater chance for decision error based on comparison of screening levels to individual discrete data. Such comparisons are highly prone to false negatives and early termination of the investigation. As discussed in the "Environmental risk assessment" discussion below, such high variability can also confound estimation of mean PCB concentrations for targeted exposure areas.
The implications are significant. Data for discrete soil samples cannot be reliably assumed to represent either the soil immediately surrounding a sample collection point or the sample submitted to the laboratory for analysis. Direct comparison of data for individual grid points could in theory declare the site to be either completely “clean” (i.e., all discrete samples ≤200 mg/kg lead) or completely “contaminated” (i.e., all discrete samples >200 mg/kg lead) depending on the mass of soil randomly collected for testing around a particular grid point.
Estimation of extent of contamination
The use of discrete sample data to define large-scale contamination patterns of potential interest is highly prone to error. Drawing a line between “contaminated” and “clean” areas of a site for characterization and risk assessment is fundamental to environmental investigations and necessary to design appropriate remedial actions. As is obvious from the previous discussion, random small-scale variability of contaminant concentrations can significantly affect the accuracy of discrete soil sample data to estimate the lateral and vertical extent of larger-scale patterns of interest. Consider the following text from the USEPA document Data Quality Objectives for Remedial Response Activities (USEPA, Citation1987):
The magnitude of the difference in contaminant concentrations in samples separated by a fixed distance is a measure of spatial variability. The level of spatial variability is site and contaminant specific. When spatial variability is high, a single sample is likely to be unrepresentative of the average contaminant concentration in the media surrounding the sample. Although it is important to recognize the nature of spatial variability at all times, it is crucial when the properties observed in a single sample will be extrapolated to the surrounding volume. (p. C-4)
Some guidance documents at the time called for the collection of “co-located” and “replicate” soil samples in order to assess smaller-scale spatial variability and the precision of estimated mean contaminant concentrations within targeted areas (e.g., USEPA, Citation1987, Citation1990, Citation1991). The cost of replicate sample collection and the premature conclusion in USEPA guidance that the variability of contaminant concentrations within an individual sample would be minimal negated serious efforts to evaluate this critical issue in more detail (USEPA, Citation1989a):
When there is little distance between points it is expected that there will be little variability between points. (p. 10-2)
Consider again the example from Study Site B above. The occurrence of “false negatives” and premature termination of an investigation using a progressive, step-out discrete sample collection approach is unavoidable. At some random point, the reported concentration of lead in an individual sample will fall below the target screening level although the concentration of lead for the area as a whole is still well above the screening level. The potential for this type of field error was recognized in early USEPA guidance documents (USEPA, Citation1991):
High coefficients of variation mean that more samples will be required to characterize the exposure pathways of interest. Potential false negatives occur as variability increases and occurrence rates decrease. (p. 40)
Larger scale heterogeneity in the manner in which a contamination was released to the soil can also be expected to confound attempts to determine the extent of contamination based on discrete sample data. Refer, for example, to the pattern of “contamination” in soil caused by an overturned milk truck in . Assume that the milk was present but not visible to field investigators, as is the case for most contaminants. The potential for underestimation of the extent of contamination based on small discrete soil samples would be very high. Accurate estimation of extent of contamination and avoidance of confusion due to false negatives is only possible when the area and volume of the sample collected is large enough to capture and overcome small-scale random variability.
The same potential for error exists in the use of discrete sample data to assess the vertical extent of contamination. Random small-scale variability of contaminant concentrations in soil limits the reliability of interpolation between individual discrete sample points. This is due to the fact that the sample is collected over an area too small to capture smaller scale random heterogeneity within the overall spill area. Such confounding factors are the primary cause of “failed” confirmation samples and of the need for repeated sample collection and over-excavation of contaminated soil with no clear end point in sight.
Interpretation of isoconcentration maps
The problems discussed previously become readily apparent in computer- or hand-generated isoconcentration maps of contaminant distribution. Use of geostatistical methods to interpolate contaminant concentrations between discrete sample data points requires several critical assumptions, including (USEPA, Citation1987): 1) the distributional heterogeneity of contaminant concentrations in soil at the scale represented by individual sample data points is well understood, 2) the trend between points is linear—for example, progressively lower to higher, and 3) any sample located within interpolated isopleth contours will identify the contamination. The first point is especially critical and controls whether the latter two criteria can be met for a given set of data. Trends between data points will only be linear and predictable if the data for an individual point are representative of the large-scale trend of interest. This requires that the sample tested be of sufficient area and volume to capture and overcome random small-scale variability. As demonstrated in the field study presented in Part 1 of this paper, this requirement is unlikely to be met on a point-by-point basis for typical discrete sample data.
summarizes the Relative Standard Deviation (RSD) measured and estimated for discrete samples around individual grid points at each of the study sites (refer to Part 1 Supporting Information). The RSDs estimated for total variability around grid points vary widely between individual grid points both within and between the sites, ranging from 9% to 52% at Study Site A (arsenic), 44% to 139% at Study Site B (lead), and 58% to 336% at Study Site C (total PCBs). Additional sample collection and testing would likely be resulting in a higher RSD. Although larger scale contaminant distribution patterns might indeed be real, small-scale patterns generated by a single point or even a small cluster of points could be random artifacts of small-scale heterogeneity and not reproducible.
Table 1. Range and sum of intra-sample and inter-sample relative standard deviation (RSD) of discrete sample variability around individual grid points (refer to Part 1 Supporting Information).
This has significant implications for attempts to remove apparent isolated “hot spots” in order to reduce the overall mean concentration of a contaminant within a targeted area, referred to as “Iterative Truncation” in some USEPA guidance documents (USEPA, Citation2005; refer to Supporting Information). Consider the removal of a few randomly selected higher concentration sample data represented in the bar graphs for Study Site B depicted in . Removal of such spots cannot be considered to have significantly reduced the mean concentration of the contaminant in soil for the targeted area as a whole. In addition to the likelihood of “failed” confirmation samples following removal, the remaining sample points could no longer be representative of the variability of contaminant concentrations at the scale of a discrete sample. If a new, independent set of samples were to be collected, then a similar random and artificial pattern of isolated “hot spots” and “cold spots” as originally identified would again be generated, but in different locations. The same holds true for selective removal of soil around discrete sample data points at Study Site C, where a concentration of >50 mg/kg PCBs was reported for a discrete sample randomly collected around the point (see ). While they shed some light on the range of contaminant concentrations within the targeted area as a whole, data for any individual point cannot be considered to be representative of the area around that point and, in the absence of other information (e.g., obvious staining or other direct signs of contamination in the field), cannot defensibly be relied upon for design of remedial actions.
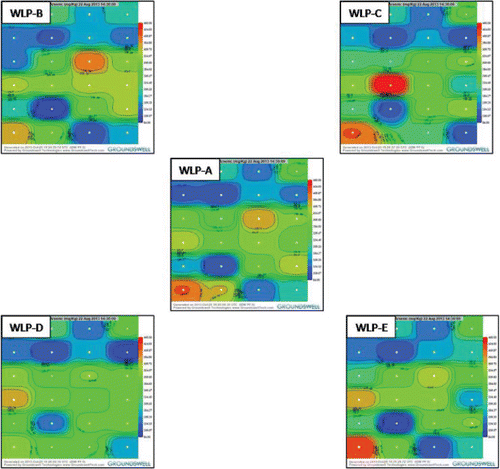
The presence of artificial small-scale patterns of contaminant distribution is exemplified in a series of isoconcentration maps prepared for Study Site A (). The maps depict patterns generated based on separate groupings of data for different groups of processed, discrete samples collected around each of the 24 grid points (samples sets “A,” “B,” “C,” “D,” and “E”; see in Part 1). The maps were generated using software developed by Groundswell Technologies (Groundswell Technologies, Citation2013). A power function of 5 was used to generate the isoconcentration maps in the figure. This is typical for isoconcentration maps for contaminated soil. The center map depicts isoconcentration contours based on use of the “Sample A” data set for each grid point. The upper left hand, upper right, lower left hand, and lower right hand maps depict isoconcentration contours based on use of the “Sample B,” “Sample C,” “Sample D,” and “Sample E” data sets, respectively. Note the changing locations of “hot spots” and “cold spots” within the study area, depending on which data set is used to generate the map. This is again a classic sign of noise in the data due to small-scale heterogeneity. The individual spots are not real in the sense that they represent actual map patterns. They instead reflect small-scale variability inherent to the soil in the study area as a whole. The variability between processed 200-g discrete soil samples is real, but the map patterns generated from the data are not. This is because the concentration of the contaminant in any given 200 g mass of soil from the grid cell area is likely to be random with respect to concentrations in immediately adjacent soil. Collection and testing of an independent set of co-located samples might yield a similar degree of variability, but the apparent distribution of this variability within the grid soil might be very different.
Figure 2. Box plots depicting estimated total variability of lead concentrations in discrete samples within 0.5 m of grid points at Study Site B (lowest to highest median for inter-sample data). Estimated range of lead concentrations falls both above and below HDOH residential soil action level of 200 mg/kg at 23 of 24 grid points and above USEPA residential screening level of 400 mg/kg at 20 of 24 points. HDOH default, upper background lead level of 75 mg/kg indicated for reference with full range of lead concentrations points reflecting the presumed mixture of native fill and lead-contaminated ash.
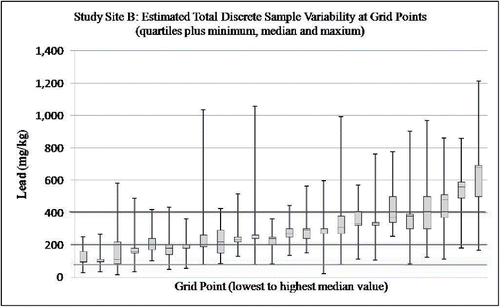
Figure 3. Box plots depicting estimated total variability of total PCB concentrations in discrete samples within 0.5 m of grid points at Study Site C (combined intra- and inter-sample variability; note use of log scale for vertical axis; lowest to highest median values for inter-sample data). Hawaii Department of Health Residential PCB soil screening level of 1.1 mg/kg and USEPA TSCA level of 50 mg/kg noted for reference.
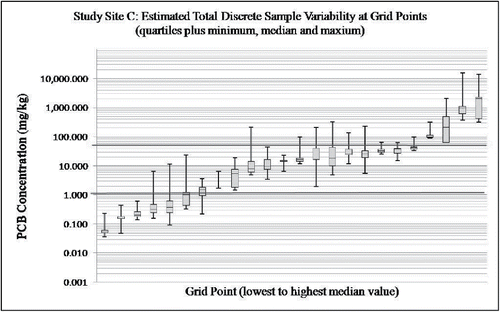
Figure 4. Irregular and disconnected spill patterns on soil made by a release of milk. This might also mimic vertical patterns for subsurface releases of liquids.

Figure 5. Changing locations of isolated “hot spots” and “cold spots” depending on use of arsenic data for “A,” “B,” “C,” “D,” or “E” processed sample sets for Study Site A (Groundswell Technologies, Inverse Distance Weighted Power Function = 5). Red tones represent higher concentrations. Blue tones represent lower concentrations. Individual spots represent approximately 900 ft2 area (refer to Part 1; Grid Point #1 in lower left hand corner). Changing patterns reflect random small-scale variability of arsenic concentrations around individual grid points and use of an unrealistically high isoconcentration mapping power function.
Over-interpretation of individual discrete sample data points can be addressed in part by selection of a mapping option that de-emphasizes data for individual points and instead focuses on apparent larger scale patterns (HDOH, Citation2015b). This is normally accomplished by selection of a lower value “distance decay parameter” value in mapping program. However, most mapping software is still unlikely to be fully able to overcome random small-scale variability of contaminant concentrations around and between individual grid points, and care must be taken in the use of such maps for final decision making purposes.
Small-scale contaminant patterns reflective of random heterogeneity are endemic in computer-generated isoconcentration maps of discrete sample data. Consider, for example, the nine-acre site on the Island of Hawaii depicted in . The site was formerly used to mix and store arsenic-based herbicides and was being considered for residential redevelopment. A tight grid of discrete samples was collected across the site in order to help identify large scale contamination patterns (ERM, Citation2008). The figure depicts an isoconcentration map generated from the discrete data grid points. A background threshold value of 24 mg/kg total arsenic was used to screen the site, with red shades in excess of this level (HDOH, Citation2012).
Figure 6. Isoconcentration map generated from discrete soil sample data collected at a known arsenic-contaminated site on the Island of Hawaii (after ERM, Citation2008). Random small-scale variability of arsenic concentrations in soil at the scale of a discrete sample are expressed in the map as isolated “hot spots” and “cold spots,” particularly within the transitional area (Zone B) that separates areas of consistently low (Zone A) and high (Zone C) arsenic concentrations. Red and green cells in inserts to the right of the map illustrate hypothetical distribution of discrete sample points above (red) and below (green) the target arsenic screening level within each zone.
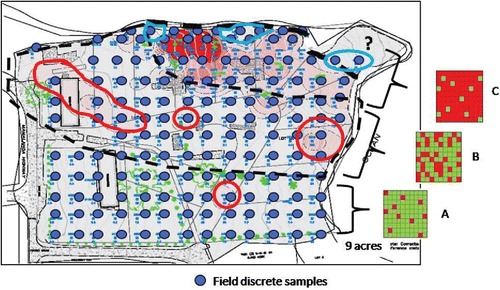
A large area of heavy contamination at the northern edge of the site is clearly apparent from the discrete sample data. Three large-scale zones of arsenic concentrations in soil are apparent on the map. The variability of discrete sample data within each zone is depicted in the boxes to the right of the map in the figure (hypothetical, for illustrative purposes). In “Zone A,” the overwhelming majority of discrete data points fall above the screening level of 24 mg/kg (default upper bound of natural background; HDOH, Citation2011). In “Zone B,” concentrations of arsenic in discrete samples fall both above and below the action level. In “Zone C,” the overwhelming majority of discrete data points are consistently below the screening level. Zone B is best interpreted to reflect the area of the site where the concentration of arsenic in discrete soil samples begins to range both above and below the target screening level. The numerous seemingly isolated “hot spots” and “cold spots” tens of feet across within this zone generated by the software most reasonably reflect random small-scale variability of arsenic concentrations in soil rather than actual large-scale areas of higher or lower concentrations.
Such artificial “Zone B” type patterns are readily apparent in isoconcentration maps used for presentation of contaminant distributions in soil. Examples of large-scale patterns of background metal concentrations in soil reflective of the underlying geology as well as presumed artificial small-scale patterns reflective of random small-scale variability are evident in nationwide isoconcentration maps recently published by the U.S. Geological Survey (USGS, Citation2014). A review of these maps is included in Part 2 of the original report for HDOH field study (HDOH, Citation2015b). In one case, data for a single composite sample collected from a 1-m square area are extrapolated to imply the presence of a 2,400 km2 “hot spot” of arsenic-contaminated soil in a geologic terrane known to be highly heterogeneous. This is almost certainly an artifact of random small-scale heterogeneity that would not be reproducible in the field, and the document appropriately cautions users not to over-interpret data on a point-by-point basis. A more detailed discussion of the use of “inverse distance weighting” methods and “power functions” to help reduce, but not fully eliminate, such inherent errors in isoconcentration maps is also provided (Lu and Wong, Citation2008).
Environmental risk assessment
Estimation of the mean contaminant concentration for a targeted area and volume of soil is a key element of environmental risk assessment (USEPA, Citation1987, Citation1988, Citation1989a,b,c,d, Citation1991, Citation1992a, Citation2011b; see also USEPA, Citation2014). The accuracy of the estimate in terms of bias and precision is a function of multiple factors, including (see Minnitt et al., Citation2007; Pitard, Citation1993, Citation2009): 1) the representativeness of the sample(s) in terms of the targeted area and volume of soil from which it was collected, 2) the representativeness of the subsamples removed for analysis, and 3) the representativeness of data generated by the laboratory analytical method in terms of the subsample mass tested. The effect of each of these factors on the estimated mean is in theory evaluated during the “data validation” stage of a project (USEPA, Citation2002a). In practice, data validation procedures primarily focus on data quality objectives associated with analytical measurements. The precision and reproducibility of the data in terms of field representativeness are rarely if ever directly and adequately assessed.
The USEPA Supplemental Guidance to RAGS: Calculating the Concentration Term (USEPA, Citation1992a) document suggests that a minimum of 20–30 discrete soil samples is required to reliably estimate the mean concentration of a contaminant in soil for a targeted area (USEPA, Citation1992a):
Sampling data from Superfund sites have shown that… data sets with 20–30 samples provide fairly consistent estimates of the mean (i.e., there is a small difference between the sample mean and the 95 percent UCL). (p. 3)
A reference for this conclusion is not provided but appears to be related to an evaluation of coefficients of variation for data collected at Superfund sites in the 1980s (USEPA, Citation1991; refer to Exhibit 23 in document). The manner in which the evaluation was carried out is not discussed in the documents, however. Recommendations for the use of independent replicate sets of discrete sample data to assess field representativeness were recognized to likely be inadequate early on (USEPA, Citation1990, annotations and emphasis added):
Previous EPA guidance for the number of quality assessment samples has been one for every 20 field samples (e.g., USEPA, Citation1987). However, such rules of thumb are oversimplifications and should be treated with great caution… The number of (replicate) samples required to detect random bias will depend on the distribution of the biasing errors, and this distribution will generally be unknown… The importance of pilot studies to the overall monitoring effort cannot be stressed enough. (p. 9)
The “random bias” that the guidance document warns against is the random small-scale variability highlighted in Part 1 of this paper. The document also stressed the need for “pilot studies” to assess the reliability of grid and discrete sample characterization methodologies being proposed and published at that time. To the authors' knowledge, such studies were never carried out to the same level of detail presented in Part 1 of this paper.
The USEPA ProUCL guidance for the statistical evaluation of discrete sample data sets states the size of a discrete sample data set should be based on “appropriate DQOs processes,” with a minimum of ten data points recommended (USEPA, Citation2013). The document is largely referring to data quality objectives (DQOs) for the desired statistical precision of the test used, rather than a more holistic sense of DQOs in terms of both statistical and field precision. Methods are provided to estimate the number of discrete samples required to achieve an acceptable level of precision in the estimate of a mean based on the variance measured for an initial set of samples, but the numbers generated are often well beyond the financial resources available for the project. The authors acknowledge this complication in the document (USEPA, Citation2013, annotations added):
Due to resource constraints, it may not be possible to collect as many samples as determined by using a DQOs based sample size formula… It is suggested to collect at least 10 (discrete samples) before using statistical methods. (p. 24)
The authors are clearly uncomfortable with the use of statistical tests to draw conclusions from what they would consider an inadequately representative set of data (USEPA, Citation2013; annotations added):
Statistics (derived from dataset that does not meet DQO goals) may not be considered representative and reliable enough to make important cleanup and remediation decisions. It is recommended not to use those statistics to draw cleanup and remediation decisions potentially impacting human health and the environment. (p. 24)
In practice, however, investigators are most often left with little other recourse once funds for sample collection and laboratory analysis have been expended, and decisions must be made on how to proceed forward.
Potential problems with the representativeness of discrete sample sets are further recognized, but not fully explored, in more recent USEPA guidance (USEPA, Citation2005, emphasis added):
It is important to note that geostatistical techniques are not a substitute for collecting sample data; the reliability of the results depends on adequate sampling data… Extrapolating the results of a small number of samples to a large area can be misleading unless the contaminant distribution across the large area is uniform… Uncertainty associated with sampling error can be very large, particularly at sites where there is significant spatial heterogeneity in contaminant concentrations. (p. 24)
The effect of field error in estimation of the mean contaminant concentration for a targeted area is highlighted by estimations of means and 95% Upper Confidence Limit (UCL) values for random non-stratified groupings of ten discrete sample data points at Study Site C (HDOH, Citation2015b). The USEPA ProUCL software was then used to generate a 95% UCL of the arithmetic mean for data set (USEPA, Citation2013). Twenty iterations of random data groupings were carried out for each set of study site data. The variance between estimated UCLs for each study site was then used to assess the precision of random sets of discrete soil samples to characterize a site.
The range in estimates of the mean arsenic concentration in soil for the study area again reflects the high combined small- and large-scale variability of total PCB concentrations in the soil identified for the study area in Part 1 (see Part 1 Supporting Information). The variability of estimated means and 95% UCLs for random groupings of ten data points within Study Site C is significantly higher than that calculated for Study Sites A and B. Calculated 95% UCL PCB concentrations range, rather spectacularly, from 9.4 mg/kg to over 1,000,000 mg/kg, with a median of 730 mg/kg and a mean of 52,522 mg/kg. The RSDs for the data point groupings are similarly high, with a range of 124–315%. Individual RSDs suggest a very poor precision in the estimate of mean concentration of PCBs estimated for any given ten-point set of discrete samples and the statistical tests used.
Results for the arsenic and lead study sites were less dramatic but still significant. Calculated 95% UCL arsenic concentrations for random ten-point groupings of discrete sample data range from 403 to 776 mg/kg. RSDs for the groupings range from 34% to 67%. Calculated 95% UCL lead concentrations for the random groupings of discrete sample data at Study Site B ranged from 201 to 439 mg/kg, with a median of 345 mg/kg and a mean of 343 mg/kg, with a corresponding RSD range of 20–86%.
Compare these results to DU-MI triplicate sample data collected for each site (refer to Part 1). A 95% UCL of 259 mg/kg was calculated for arsenic at Study Site A with an RSD of only 6.5%, inferring very good total precision. A 95% UCL of 383 mg/kg was calculated for lead at Study Site B, with a slightly higher but still strong RSD of 20%. A 95% UCL of 346 mg/kg was calculated for PCBs at Study Site C, with the concentration of PCBs in individual MI samples reported at 19, 24, and 270 mg/kg. The replicate data RSD of 138% immediately flagged the data as unreliable due to low field precision, however. Such a test of field precision cannot be carried out on an individual set of discrete sample data, and biases due to field error could go unnoticed. These evaluations are for illustration purposes only. The range of RSDs and estimated means indicates a similarly poor lack of field precision for any given data set. Larger discrete sample databases for each site could be expected to identify even greater variance between random sample sets of data and lower total precision of any given set of data.
Several USEPA guidance documents also discuss the use of discrete soil samples to assess the presence or absence of very small “hot spots” that could pose “acute” toxicity risks (USEPA, Citation1989a, Citation1992b, Citation2005; see also Supporting Information). Data were to be compared to risk-based screening levels for acute toxicity or “not-to-exceed” concentrations. While understandable in concept, this approach suffers from two significant flaws. Acute toxicity factors, reflecting health effects within minutes to a few days following exposure (USEPA, Citation2011a), are not available for direct ingestion for the majority of contaminants assessed as part of a typical environmental investigation. Similarly, “acute” or “not-to-exceed” soil screening levels have never been published by the USEPA, to the authors' knowledge.
None of the documents noted provide either guidance on the calculation of such hypothetical soil screening levels or guidance on sampling methods to establish with any degree of reliability the presence or absence of contaminated soil that could pose such concerns. Assessment of acute toxicity would by necessity need to be tied to a target mass of incidentally ingested soil, such as a default of 10 g assumed to be ingested by a pica child (USEPA, Citation2011b). Each 10-g mass of soil at a site then becomes an individual “Decision Unit.” For comparison, a relatively small 10 m × 10 m exposure area to a depth of just one centimeter contains approximately 1,000 kg of soil, or 100,000 potential 10 g DUs. Were acute toxicity factors and screening levels in fact available, the level of effort to demonstrate with an acceptable level of confidence, if such a level exists for theoretical acute toxicity, would be enormous and not feasible from either a technical or financial standpoint.
Decision-making is instead made based on remediation to meet potential long-term chronic health risk from exposure to much lower concentrations of the contaminant, with a perhaps unspoken assumption that this will also address hypothetical acute risks. The authors are unaware of any cases where such an approach has been demonstrated to be inadequate. If acute health risks are indeed a concern at a site then the area should be remediated (e.g., scraped or capped) and confirmation Multi Increment soil samples collected to evaluate any remaining chronic exposure risk (refer to HDOH, Citation2011 and updates). This might include, for example, concerns regarding the incidental ingestion by children of lead-based paint chips or lead shot randomly scattered in soil. Soil samples could also be ground to help assess the potential presence of large nuggets of targeted contaminants (HDOH, Citation2016; ITRC, Citation2012).
Similar debate and confusion exist in the interpretation and use of apparent “outlier” discrete sample data as part of an environmental investigation. In the mining industry, randomly located “outlier” veins or pockets of target mineral concentrations may make or break the economic viability of an ore deposit. Sampling protocols are therefore carefully designed to capture and represent “outliers” in order to make sound decisions (Pitard, Citation1993). Over-representation can lead to overestimates of the mass of the targeted mineral present and subsequent economic failure of the venture. Under-representation can lead to missed opportunities and shortages of minerals critical for economic development.
The same concepts apply to the investigation of contaminants in soil. The importance of capturing the full distributional heterogeneity of a contaminant in a targeted area and volume of soil is recognized in the USEPA guidance document Methods for Evaluating the Attainment of Cleanup Standards (USEPA, Citation1989a):
This document recommends that all data not known to be in error should be considered valid… High concentrations are of particular concern for their potential health and environmental impact. (p. 2–16)
Such data, however, can cause significant problems with the precision of geostatistical models. Consider, for example, this statement in the USEPA ProUCL document (USEPA, Citation2013):
The inclusion of outliers in the computation of the various decision statistics tends to yield inflated values of those decision statistics, which can lead to incorrect decisions. Often inflated statistics computed using a few outliers tend to represent those outliers rather than representing the main dominant population of interest (e.g., reference area).
Outliers represent observations coming from populations different from the main dominant population represented by the majority of the data set. Outliers distort most statistics (e.g., mean, UCLs, UPLs, test statistics) of interest. Therefore, it is desirable to compute decisions statistics based upon data sets representing the main dominant population and not to compute distorted statistics by accommodating a few low probability outliers (e.g., by using a lognormal distribution). (p. vi)
The suggestion that outliers “distort” estimation of the mean and should therefore not be “accommodated” in geostatistical analysis of a soil sample data set is erroneous for testing of particulate matter such as soil. The objective of any soil investigation is to estimate the mean concentration a contaminant within a designated DU area and volume of soil, regardless of how large or how small the desired DU is. The true mean, for example, of a one cubic-meter volume of soil is a composite of every particle of soil within that volume. Removal of small “outlier hot spots” from the volume prior to testing, such as removing chips of lead-based paint, would yield erroneous data and conclusions. A mineral exploration company certainly would never omit “outlier” concentrations of gold in veins running through an ore body.
This conflict was recognized in earlier USEPA guidance on the estimation of mean contaminant concentrations in exposure areas (USEPA, Citation2002b):
There are a variety of statistical tests for determining whether one or more observations are outliers. These tests should be used judiciously, however. It is common that the distribution of concentration data at a site is strongly skewed so that it contains a few very high values corresponding to local hot spots of contamination. The receptor could be exposed to these hot spots, and to estimate the EPC correctly it is important to take account of these values. Therefore, one should be careful not to exclude values merely because they are large relative to the rest of the data set. (p. 3)
The problem with “outliers” lies not with the statistical test used but with the inappropriately small scale of observation that the sample data represent. The concentration of a chemical in soil at the scale of an individual discrete soil sample or subsample tested by a laboratory has no direct relevance to the assessment of health risk. As somewhat bluntly stated by Pitard (Citation1993):
As samples (i.e., laboratory subsamples) become too small, the probability of having one of these grains present in one selected sample diminishes drastically; furthermore, when one grain is present, the estimator … of the true unknown average… becomes so high that it is often considered as an outlier by the unexperienced (sic) operator. (p. 34)
Pitard repeatedly emphasizes the need for sampling methods that accurately represent all parts of the investigation area (Pitard, Citation2005, annotations and emphasis added):
All the constituents of the lot to be sampled must be given an equal probability… of being selected and preserved as part of the sample (and estimation of the mean). (p. 56)
This includes the need to retain “outlier” data (Pitard, Citation2009, emphasis added):
A common error has been to reject “outliers” that cannot be made to fit the Gaussian model or some modification of it as the popular lognormal model. The tendency, used by some geostatisticians, has been to make the data fit a preconceived model instead of searching for a model that fits the data… It is now apparent that outliers are often the most important data points in a given data set. (p. 5)
Pitard notes that exclusion of “outlier” data can lead to significant error in decision-making (Pitard, Citation1993):
…the above sampling protocol (e.g., discrete samples and improper sample mass, sample collection, sample processing, etc.) introduces an enormous fundamental error (in the data set), resulting in a huge artificial nugget effect that confuses the interpretation of the data, subsequent geostatistical studies, and even the feasibility of the project. (p. 173)
The recommendation in the ProUCL guidance to similarly ignore “non-detect (ND)” results in the statistical evaluation of a data set is likewise inappropriate for soil data (USEPA, Citation2013; see also USEPA, Citation2002b). The document correctly calls out the same problem with the inclusion of ND results in statistical evaluation of data sets, stating that the statistical models employed “…do not perform well even when the percentage of ND observations is low.” This again implies a failure of the approach being used to estimate a mean from both a field and statistical standpoint, rather than an error in the data provided.
Summary and discussion
The results of this field study highlight the need to transition from traditional discrete soil sample investigation methods to more science-based and reproducible Decision Unit and Multi Increment sampling methodologies. The data are irrefutable that the concentration of a contaminant reported by a laboratory for a discrete soil sample cannot reliably be assumed to be representative of the sample provided. A single sample (or even small group of samples) likewise cannot reliably be assumed to be representative of the area from which it was collected or reliably indicative of large-scale trends of potential interest. This can lead to significant but largely hidden errors when discrete sample data are used as a basis for decision-making in environmental investigations. However, false negatives, false positives, confusion over seemingly isolated, and potentially artificial “hot spots” and “cold spots,” inappropriate omission of “outlier” data in environmental risk assessments, and the lack of sufficient replicate data to verify the field precision of data sets are unavoidable. Although useful in some cases for rough approximation of large-scale contaminant patterns, discrete soil sampling methodologies are at best highly inefficient and wasteful of resources, and at worst, highly misleading.
The fact that it has taken over 30 years to begin to address this problem is attributable to multiple factors, including: 1) the lack of training of environmental regulators and consultants in more up-to-date concepts of Sampling Theory for particulate media, 2) the lack of field studies to investigate and quantify potential error in discrete sample data, 3) the mistaken assumption that disparities between replicate data, when collected, were due primarily to laboratory error, and 4) the lack of a final test of data quality comparable to those of the agriculture and mining industry to assess data reproducibility and the corresponding lack of market forces to push controlling regulatory agencies to make the process more efficient and effective. It is hoped that the field study presented in this paper will in part help to address these deficiencies.
The much-needed transition to Decision Unit and Multi Increment sampling methodologies will necessarily be disruptive to regulatory agencies and consultants entrenched in discrete sample investigation methods. The State of Hawaii instituted the change over a period of several years, beginning in 2004 and publishing the first formal guidance in 2008. An estimated 15,000+ MI samples have since been collected. Previously completed investigation and remediation actions were only revisited in a small number of cases, and then usually only as part of a new property redevelopment or transaction. Field data typically indicate that the core of contamination was indeed removed, although the process was highly inefficient in terms of time and cost, and outer areas of moderate contamination were sometimes overlooked. The use of DU-MI methodologies was encouraged but not necessarily required for projects already underway, particularly where work plans for site characterization had already been completed. The collection of DU-MI data to confirm the results of site investigations and remedial actions was especially recommended. Intensive training for regulators and consultants in Sampling Theory and the implementation of DU-MI in the field was carried out during the same period and continues on a regular basis. Experience gained was progressively incorporated into the state's Technical Guidance Manual, which continues to be updated as more efficient and effective investigation methods are developed (HDOH, Citation2016).
The results of this study also have clear implications for reliance on discrete sample data for investigation of contaminated sediment, which requires similar but largely untested assumptions of uniformity at the scale of the samples collected and corresponding predictable trends between individual sample points. A detailed overview of this issue is beyond the scope of this paper, however, and detailed field research is again lacking. The push for change elsewhere will be driven in part by a better understanding of the science of Sampling Theory. The need for change will perhaps be driven even more by responsible parties required to pay for the investigations and the environmental experts who put their credibility at stake each time an investigation is carried out. Additional pushes for change will come from insurers forced to pay for unanticipated cleanup costs, attorneys representing parties involved in property transactions, and the financiers behind these transactions, each of whom could have the most to lose due to faulty data. Not the least, however, is the increased confidence gained in the protection of human health and the environment.
Conflict of interest
The authors declare no conflict of interest.
Part 2: Supplement_Brewer
Download MS Word (59.3 KB)Acknowledgments
The field study carried out by the Hawaii Department of Health was conducted under a grant from the United States Environmental Protection Agency. The authors wish to acknowledge the numerous environmental consultants and regulators who provided input and often lively debate during preparation of this paper. The conclusions expressed in the paper are, however, our own and may not necessarily reflect those of the reviewers.
Funding
Guidance published by the Hawaii Department of Health and referenced in this paper was funded partly through the use of U.S. EPA State Response Program Grant funds. Its contents do not necessarily reflect the policies, actions, or positions of the U.S. Environmental Protection Agency. The Hawaii Department of Health does not speak for or represent the U.S. Environmental Protection Agency.
Related Research Data
References
- Association of American Feed Control Officials (AAFCO). 2015. GOODSamples: Guidance on Obtaining Defensible Samples. Champaign, IL.
- Brewer, R., Peard, J., and Heskett, M. 2016. A critical review of discrete soil sample reliability: Part 1—Field study results. Soil Sediment Cont. Available at: http://dx.doi.org/10.1080/15320383.2017.1244171
- Environmental Resources Management. 2008. Sampling and Analysis Plan Amendment Former Pepe´ekeo Sugar Company property, Hakalau, Hawaii. Prepared for Aloha Green Inc. Hilo, HI,.
- Groundswell Technologies, Inc. 2013. Groundswell Technologies Contouring Web Application and API. Santa Barbara, CA.
- Hadley, P. W. and Petrisor, I. G. 2013. Incremental sampling, challenges and opportunities for environmental forensics. Environ. Forensics 14, 109–120.
- Hadley, P. W. and Sedman, R. M. 1992. How hot is that spot? J. Soil Cont. 3, 217–225.
- Hawaii Department of Health (HDOH), Office of Hazard Evaluation and Emergency Response. 2011. Screening for Environmental Concerns at Sites with Contaminated Soil and Groundwater. Honolulu, HI.
- Hawaii Department of Health (HDOH), Hazard Evaluation and Emergency Response. 2012. Hawaiian Islands Soil Metal Background Evaluation. Honolulu, HI.
- Hawaii Department of Health (HDOH), Hazard Evaluation and Emergency Response. 2015a. Small-Scale Variability of Discrete Soil Sample Data, Part 1: Field Investigation Of Discrete Sample Variability. Honolulu, HI.
- Hawaii Department of Health (HDOH), Hazard Evaluation and Emergency Response. 2015b. Small-Scale Variability of Discrete Soil Sample Data, Part 2: Causes and Implications for Use in Environmental Investigations. Honolulu, HI.
- Hawaii Department of Health (HDOH), Office of Hazard Evaluation and Emergency Response. 2016. Technical Guidance Manual. Honolulu, HI.
- Interstate Technology Regulatory Council (ITRC). 2012. Incremental Sampling Methodology. Washington, DC.
- Lu, G. Y. and Wong, D. W. 2008. An adaptive inverse-distance weighting spatial interpolation technique for computers. Geosciences 34 (9), 1044–1055.
- Minnitt, R. C. A., Rice, P. M. and Spangenberg, C. 2007. Part 1: Understanding the components of the fundamental sampling error: A key to good sampling practice. J. South. Afr. Inst. Min. Metall. 107, 505–511.
- Pitard, F. F. 1993. Pierre Gy's Sampling Theory and Sampling Practice. New York: CRC Press.
- Pitard, F. F. 2005. Sampling correctness—A comprehensive guideline. Proceedings of Sampling and Blending Conference, Sunshine Coast, Queensland, Australia, May 9–12, 2005.
- Pitard, F. F. 2009. Theoretical, practical and economic difficulties in sampling for trace constituents. Proceedings of the 4th World Conference on Sampling and Blending, The Southern African Institute of Mining and Metallurgy, Cape Town, October 19–23, 2009.
- Ramsey, C. A. and Hewitt, A. D. 2005. A methodology for assessing sample representativeness. Environ. Forensics 6, 71–75.
- Shulgin, A. I. and Duhaas, L. 2008. Evaluation of HMA treatment to allow for reuse of waste ash as landfill daily cover. Prepared for H-Power, Inc. Honolulu, HI, October 30, 2008.
- U.S. Army Corps of Engineers (USACE), Environmental and Munitions Center of Expertise. 2009. Interim Guidance 09-02: Implementation of Incremental Sampling (IS) of Soil for the Military Munitions Response Program. Huntsville, AL.
- U.S. Environmental Protection Agency (USEPA), Office of Toxic Substances. 1985. Verification of PCB Spill Cleanup by Sampling and Analysis. Washington, DC ( EPA-560/5-85·026).
- U.S. Environmental Protection Agency (USEPA), Office of Toxic Substances. 1986. Field Manual for Grid Sampling of PCB Spill Sites to Verify Cleanups. Washington, DC ( EPA-560/5-86·017).
- U.S. Environmental Protection Agency (USEPA), Office of Emergency and Remedial Response. 1987. Data Quality Objectives for Remedial Response Activities. Washington, DC ( EPA/540/G-87/003).
- U.S. Environmental Protection Agency (USEPA), Office of Remedial Response. 1988. Superfund Exposure Assessment Manual. Washington, DC ( EPA/540/1-881001).
- U.S. Environmental Protection Agency (USEPA), Office of Policy, Planning, and Evaluation. 1989a. Methods for Evaluating the Attainment of Cleanup Standards, Volume 1: Soils and Solid Media. Washington, DC ( EPA/230/U2-89/042).
- U.S. Environmental Protection Agency (USEPA), Environmental Monitoring Systems Laboratory. 1989b. Soil Sampling Quality Assurance User's Guide. Washington, DC ( EPA/600/8-69/046).
- U.S. Environmental Protection Agency (USEPA), Office of Policy, Planning, and Evaluation. 1989c. Risk Assessment Guidance for Superfund, Volume I, Human Health Evaluation Manual (Part A). Washington, DC ( EPA/540/1-89/002).
- U.S. Environmental Protection Agency (USEPA), Office of Policy, Planning, and Evaluation. 1989d. Risk Assessment Guidance for Superfund, Volume II, Environmental Evaluation Manual. Washington, DC ( EPA/540/1-89/001).
- U.S. Environmental Protection Agency (USEPA), Environmental Monitoring Systems Laboratory. 1990. A Rationale for the Assessment of Errors in the Sampling of Soils. Washington, DC ( EPA/800/4-90/013).
- U.S. Environmental Protection Agency (USEPA), Office of Research and Development. 1991. Guidance for Data Usability in Risk Assessment (Part A). Washington, DC ( EPA/540/R-92/003).
- U.S. Environmental Protection Agency (USEPA), Office of Solid Waste and Emergency Response. 1992a. A Supplemental Guidance to RAGS: Calculating the Concentration Term. Washington, DC ( EPA 9285.7-081).
- U.S. Environmental Protection Agency (USEPA), Office of Research and Development. 1992b. Preparation of Soil Sampling Protocols: Sampling Techniques and Strategies. Washington, DC ( EPA/600/R-92/128).
- U.S. Environmental Protection Agency (USEPA), National Exposure Research Laboratory, Environmental Sciences Division, Technology Support Center. 1999. Correct Sampling Using the Theories of Pierre Gy. Washington, DC ( Fact Sheet 197CMB98.FS-14).
- U.S. Environmental Protection (USEPA), Office of Environmental Information. 2002a. Guidance on Environmental Data Verification and Data Validation. Washington, DC ( EPA/240/R-02/004).
- U.S. Environmental Protection (USEPA), Office of Emergency and Remedial Response. 2002b. Calculating Upper Confidence Limits for Exposure Point Concentrations at Hazardous Waste Sites. Washington, DC ( OSWER 9285.6-10).
- U.S. Environmental Protection Agency (USEPA), Office of Emergency and Remedial Response. 2005. Guidance on Surface Soil Cleanup at Hazardous Waste Sites (peer review draft). Washington, DC ( EPA 9355.0-91).
- U.S. Environmental Protection Agency (USEPA), National Center for Environmental Assessment, Integrated Risk Information System. 2011a. IRIS Glossary. Washington, DC.
- U.S. Environmental Protection Agency (USEPA), National Center for Environmental Assessment, Office of Research and Development. 2011b. Exposure Factors Handbook. Washington, DC ( EPA/600/R-09/052F).
- U.S. Environmental Protection Agency (USEPA), Office of Research and Development. 2013. ProUCL Version 5.0.00, User Guide. Washington, DC ( EPA/600/R-07/041).
- U.S. Environmental Protection Agency (USEPA), Superfund. 2014. Hot Spots: Incremental Sampling Methodology (ISM) FAQs. Washington, DC.
- U.S. Environmental Protection Agency (USEPA), Superfund. 2015. Screening Levels for Chemical Contaminants. Washington, DC.
- U.S. Geological Survey (USGS). 2014. Geochemical and Mineralogical Maps for Soils of the Conterminous United States. Reston, VA ( Open-File Report 2014-1082).