Abstract
Areal interpolation is used to transfer attribute data between geographically incongruous zonal systems. Remotely sensed land cover data are widely used in intelligent areal interpolation methods to solve this problem. This article examines the usefulness of different publicly available remotely sensed land cover data sets as ancillary data used in conjunction with different areal interpolation methods. Two land cover data sets were compiled at the national scale; one by the Multi-Resolution Land Characteristics Consortium (the National Land Cover Dataset or NLCD) and one by the Coastal Change Analysis Program. A third land cover data set was compiled at a regional scale for the state of Connecticut by the Center for Land Use Education and Research. Results show that for areal interpolation, greater detail in the classification of developed areas was important whether the data were developed for use at a national or a regional scale. Even more important is the further enhancement of remotely sensed land use categories by incorporating local road or parcel data layers. The worst performing interpolation method using enhanced remote sensing-derived land cover data produced more accurate results than the best performing method using only the original land cover data. The results also show that parcels produce better enhancements than road buffers because they remove the areas of the roads themselves from population consideration.
1. Introduction
Areal interpolation techniques have been developed to enable data collected for one areal delineation of geographic space to be transferred to a different delineation of geographic space (Lam Citation1983). This is a type of “change of support” problem, in which the set of regions with known attribute values are identified as source zones, and the set of regions needing estimated values are target zones (Goodchild and Lam Citation1980). Fotheringham and Rogerson (Citation1993) categorized and discussed four general issues and problems associated with spatial analysis: the modifiable areal unit problem (MAUP), the boundary problem, the spatial sampling problem, and the spatial autocorrelation problem. Areal interpolation is especially associated with the MAUP, which includes the sensitivity of spatial analysis results to the zoning system used to aggregate spatial data (Openshaw and Taylor Citation1981). Many spatial data sets are aggregated into zones because of privacy issues and storage efficiency, but the diversity of applications, variations in geographic scale, and the spatial distributions of the phenomena under investigation have worked against the unification of areal units into a single standardized system (Visvalingam Citation1991). Areal interpolation can be used to estimate missing data layers, transfer data from one geography to another, and estimate attribute values for new polygonal units resulting from GIS overlay operations (Mrozinski and Cromley Citation1999). Thus, areal interpolation can be used to rectify disparate spatially aggregated data layers into a common scale with common boundary delineations before proceeding with further spatial analysis. In addition, the areal interpolation of population is needed in many other applications (Qiu, Zhang, and Zhou Citation2012).
Overtime, different methods have been developed to improve the efficiency and accuracy of areal interpolators. Different ways for classifying these procedures can be found in the literature, based on differences in model assumptions and data types. Each method makes an assumption regarding the distribution of data within the spatial units that can result in different levels of interpolation accuracy. Methods that use ancillary data have been found to improve the results of the interpolation (Langford Citation2007). This is because the ancillary data used are often spatially correlated with the phenomenon under investigation in the source zone. Having a better understanding of the distribution of the data in the source zone can improve the inherent disaggregation of the data during the areal interpolation process. The most widely used classification scheme divides areal interpolation methods into two categories: simple methods, which assume data are uniformly distributed within source zones, and intelligent areal interpolation methods, which use ancillary data to infer a spatial distribution of the data of interest (Okabe and Sadahiro Citation1997; Langford, Maguire, and Unwin Citation1991; Langford Citation2006). Intelligent methods are further subdivided into those based on dasymetric mapping (Wright Citation1936) and those based on a statistical method such as regression.
Another classification is based on the underlying data model used during the interpolation procedure. For a vector-based model, the spatial data used for areal interpolation, including source zones, target zones, ancillary zones, if necessary, and all other spatial zoning systems used in the intermediary steps, are all vector data. However, if raster data are included in any step in the interpolation procedure, the method can be considered as raster-based, even though the source layer is usually in a vector format. If the target layer is in a vector format, a raster-based model would use vector-to-raster and raster-to-vector operations as intermediary steps and the interpolation itself is calculated over a grid. The values for the target zones are simply the aggregation of grid values within each areal unit. If the target layer is a raster, then only an initial vector-to-raster conversion of the source layer is necessary as an intermediate step and the interpolation is performed over a grid. Using remotely sensed data as an ancillary layer in the interpolation process also necessitates certain vector/raster conversions.
The purpose of this analysis is to investigate how useful publicly available remotely sensed land cover data sets are with respect to the process of areal interpolation. The next section reviews different areal interpolation procedures including those used in the analysis.
2. Areal interpolation methods
The original vector-based areal interpolation method is areal weighting, which is based on the geometric overlay of the source and target zones (Goodchild and Lam Citation1980; Lam Citation1983). It assumes a uniform density of data values within each source zone. Values are estimated as averages that are proportionally weighted by the ratio of the area of each intersection polygon to the area of the source polygon that contains it. Areal weighting is the most widely used method among all other methods because of its intuitively simple theory, low data and computation requirements, and easily implementation in GIS software (Xie Citation1995). This method is not used in this study because it does not use any ancillary data.
The binary dasymetric method (BDAS) (Fisher and Langford Citation1996) is a direct extension of areal weighting in which an ancillary data layer containing a single-valued correlate variable is used. BDAS can also be easily implemented in GIS, which can readily integrate various spatial ancillary data (Wu, Qiu, and Wang Citation2005). In this method, the area of the correlated variable within the source zones is used, rather than the total area of the source zone, to determine the weighted proportions. A spatially correlated variable that is often used is land cover. In a land cover data set derived from remotely sensed images, a single category such as “developed” is used. All land cover categories that might be associated with population would be compressed into a single category. Target zone population is estimated as:
A slightly different method is intelligent dasymetric mapping (IDM) (Mennis and Hultgren Citation2006), which allows multiple classes in the ancillary layer. Although this method uses land cover data, it first converts the data to a vector format before the interpolation step. The method then overlays the source layer and the ancillary layer and the resulting intersection zones are used as the target zone. Only one ancillary class is associated with each target zone. The estimated population for the target zone is:
IDM incorporates the estimated density of each ancillary class in calculating the proportion of counts in a target zone from that in the source zone. The value of can be specified by the analyst who has some prior knowledge of the density of the ancillary class. Noting that this specification is subjective on the part of the analyst, three objective methods are further proposed to calculate
: containment, centroid, and percent cover. All source zones that are completely contained within each individual ancillary class are selected as a sample to calculate the density for that class in the containment method. In the centroid method (IDMC), source zones that have their centroid within each individual ancillary class are selected as the sample to calculate the density for that class. For the percentage method, source zones with areas occupied by a single ancillary class equal or exceeding a threshold percentage, subjectively assigned by the analyst, are selected to calculate the density for that class. Calculating density for each ancillary class for all three sampling methods is:
Noting that the densities for each of the ancillary data are globally derived by the ratio of the sum of the counts for all selected source zones to the sum of the areas for all those zones, the authors further described a more local model in which the study area is divided into several regions to account for spatial variation in the relationship between density and ancillary class, with density calculated separately in each individual region. The possibility exists that no source zone is selected for a particular ancillary class. In the containment method, for example, no source zone was fully contained within one particular ancillary class; thus, the density for this class cannot be calculated using the method described above. In this case, they proposed first calculating the raw estimated count for the target zone containing an ancillary class with unknown density using the previously estimated densities of other ancillary classes that are in the same source zone as this particular class:
Note that is not the final estimated count for the target zone, rather it is used to calculate the density of the ancillary class with unknown density as follows:
Then, the estimated density for this particular ancillary class is used along with EquationEquation (2)(2) to calculate the final count for those target zones associated with this particular ancillary class. Other dasymetric methods using multiple classes have been developed by Eicher and Brewer (Citation2001) and Langford (Citation2006), but are not used in this analysis.
In the statistical approach to areal interpolation, different regression models have been applied to estimate population density values for each class of the correlated variables. Langford, Maguire, and Unwin (Citation1991) used ordinary least squares (OLS) regression with population count as the dependent variable and pixel counts of individual land cover classes as independent variables to model the relationship between population density and land cover classes. Noting the possibility of negative counts using OLS, Flowerdew and Green (Citation1989) suggested that Poisson regression is theoretically preferable for modeling counts, as negative population estimation could be avoided. They proposed a Poisson model to interpolate count variables using ancillary binary data for target zones. Furthermore, with the existing target zone information, Flowerdew and Green (Citation1991) improved their Poisson model by synthesizing the expectation and maximum likelihood (EM) algorithm, which was originally developed by Dempster, Laird, and Rubin (Citation1977) to solve problems of missing data. Flowerdew and Green (Citation1994) then extended this EM method to handle continuous variables having a normal distribution.
However, the early regression models generally underperformed in comparison with a simple binary dasymetric model (Fisher and Langford Citation1995). Population density varied more among different places than among different ancillary classes. To make the relationship between population and an ancillary class in a regression model not only vary over ancillary classes but also over space, Yuan, Smith, and Limp (Citation1997) developed a regional model that regressed population on land cover types in each county of their study area. However, Langford (Citation2006) argued that their method for dividing the study area into sub-regions to fit the local regression model is not based on the distribution of population. The counties used by Yuan, Smith, and Limp (Citation1997) are administrative areas where there is little basis for determining the underlying distribution of population. Furthermore, the variation of local model parameters among counties indicates that some degree of spatial variation exists in the relationship between population density and land cover type. Langford (Citation2006) inferred that the spatial variation in the relationship between population density and land cover type is likely to be continuous, because variation is likely within regions if it exists between regions.
To overcome this problem, Lin, Cromley, and Zhang (Citation2011) proposed using geographically weighted regression (GWR) (Charlton and Fotheringham Citation2009) for modeling the spatial variation in the relationship between population density and land cover type. Different GWR models were proposed to investigate the influence of bandwidths and the number of classes in the estimation of population density. Because there is usually a residual associated with each source observation when applying GWR (or OLS regression) to areal interpolation, so the population estimates are not volume-preserving. Thus, a scaling step is required to preserve the original population size in the source zone. With scaling, the GWR interpolator outperformed areal weighting, binary dasymetric, and a corresponding global regression interpolator. Also fewer, more relevant classes were found to be more accurate than including a large number of categories.
Another local statistical interpolation model using quantile regression (QR) (Koenker and Bassett Citation1978) was developed recently by Cromley, Hanink, and Bentley (Citation2012). Theoretically, two advantages were identified for a QR-based interpolator compared with other regression interpolators. One is that every observation can perfectly fit the local regression hyperplane associated with the observation's quantile level; thus, QR-based areal interpolation is inherently volume-preserving and does not require a scaling step. The other is that the estimated coefficients found by QR can easily be constrained to be non-negative and the intercept term can be set to zero; thus, the estimated coefficients can be directly interpolated as a population density for each ancillary class at a specific location. Although the authors did not compare it with GWR, they found that the QR interpolator outperformed areal weighting, binary dasymetric, OLS regression, and a spatial error model-based interpolator (Anselin Citation2003).
Most of the existing literature compares different areal interpolation methods using a single ancillary data layer such as land cover, parcel data, a road network, or other physical or socio-economic characteristics. Fisher and Langford (Citation2006) also examined the effect of the errors in a classified Landsat image on the areal interpolation of population counts. In their research, the classification errors were simulated by assigning any pixel in a classified satellite image to an alternative random cover type between 0% and 100% at 10% increments. The simulation was further divided into constrained and unconstrained, mainly based on whether the original proportions of the different land cover types were preserved during the simulating process. They concluded that dasymetric method, which is their main test method, is robust against classification errors in satellite imagery.
Instead of testing the simulated errors in classified satellite imagery, this article focuses more on examining the utility of different publicly available preclassified remotely sensed land cover data sets with respect to different areal interpolation methods. Until recently, most of the publicly available preclassified land cover data sets provided only an Anderson Level I-like classification, which distinguishes only among the broadest land cover types: developed agriculture, forest, water, wetland, etc. (Anderson et al. Citation1976). However, the Anderson Level II classification further divides developed areas into residential, commercial, and industrial areas. Falcone and Homer (Citation2012) noted that derivation of the Anderson Level II classification, based on the spectral information in remotely sensed imagery, can be enhanced by using additional socio-economic data layers. In their research, they further classified the developed pixels in the National Land Cover Database 2006 (NLCD 2006) into very low density residential, low density residential, medium density residential, high density residential, commercial-industrial with low-medium density, commercial-industrial with high density, institutions, transportation, and open space. The main enhancement data they used in their research is the Homeland Security Infrastructure Program (HSIP) HSIP-Gold 2010 data set (http://www.hifldwg.org/), which provides the locations and shapes of institutions, transportation networks, recreation, commercial, and industrial places. The second enhancement data are vector data obtained from ESRI (http://www.esri.com/) containing primarily institutional and recreational features. The third enhancement data set is a historical land-use data set from the Geographic Information Retrieval and Analysis System (Price et al. Citation2006) and NLCD1992 (Vogelmann et al. Citation2001). Both data sets delineate several Level II land use classes.
Similar data layers have been used in areal interpolation as alternatives to remotely sensed data. Road buffers (Mrozinski and Cromley Citation1999), road length (Xie Citation1995), and parcel data (Maantay, Maroko, and Herrmann Citation2007; Tapp Citation2010) have all been used as ancillary data. Other data layers are rarely used in conjunction with remotely sensed data to improve interpolation accuracy. This research not only compares the publicly available preclassified land cover data sets for different areal interpolation methods, but it also examines different enhancements of the land cover data sets for improving the accuracy of these areal interpolation methods.
3. Study area and data
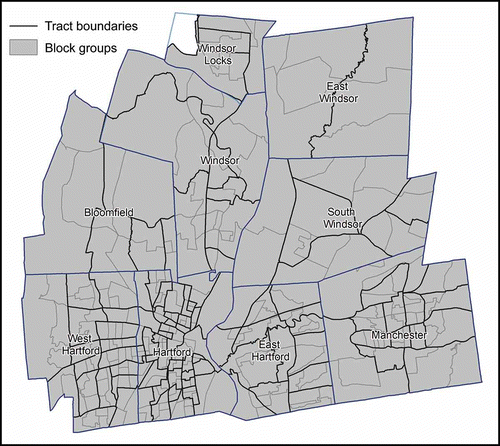
The study area consists of a nine-town region in Hartford County, Connecticut (). In the 2010 census, the nine-town study area had a total population of 396,435. These towns have been chosen as the study area because this region is characterized by various types of land use, including residential areas with different housing densities and socio-economic structures, commercial and industrial areas, and open space. In addition, this region contains a variety of population densities, from dense urban centers such as Hartford to sparsely populated rural forested areas. Census tract and block group boundaries data, for the source zones and target zones, respectively, were downloaded from the US Census Bureau's 2010 Topologically Integrated Geographic Encoding and Reference (TIGER/Line) Shapefiles Main Page (http://www.census.gov/geo/www/tiger/tgrshp2010/tgrshp2010.html). shows the study area overlaid with the target and source zones. The population data were extracted from 2010 Census Summary File 1 (SF1) Table P1, and downloaded through the US Census Bureau's web data retrieval interface, American FactFinder (http://factfinder2.census.gov). The geography boundary files and the demographic data were then joined in ArcGIS 10.1.
Figure 1. The nine-town region overlaid with the source and target zones. The nine towns are Bloomfield, East Hartford, East Windsor, Hartford, Manchester, South Windsor, West Hartford, Windsor, and Windsor Locks. One tract in Winsor Locks was not included in the study region because it is Bradley International Airport.
The first public land use/land cover (LULC) data set used as thematic ancillary data was compiled nationally and was based primarily on the unsupervised classification of Landsat 7 Enhanced Thematic Mapper+ (ETM+) satellite imagery acquired in 2006 with a 30 × 30 meters spatial resolution (Fry et al. Citation2011). This data set is available from the NLCD 2006 from the Multi-Resolution Land Characteristics Consortium (MRLC) (http://www.mrlc.gov/). The NLCD 2006 was created on a Landsat WRS Path-Row basis and mosaicked to create a seamless national product. The land cover classification was performed on an individual path/row basis to make it more local (Xian, Homer, and Fry Citation2009). The study area is located in Path 13 Row 31, which includes most of Connecticut. The second public LULC data set, which was also derived at the national level, is primarily based on Landsat 5 Thematic Mapper scenes and produced by the Coastal Change Analysis Program (C-CAP). The data set was downloaded from the National Oceanic and Atmospheric Administration (NOAA) coastal service center (http://www.csc.noaa.gov). The third LULC data set, which was derived for use at the state level, is mainly based on Landsat Thematic Mapper satellite imagery and was produced by the Center for Land Use Education and Research (CLEAR) at the University of Connecticut. The data were acquired from CLEAR's website (http://clear.uconn.edu).
Since the satellite imagery, providing the foundation for land cover classification for the three preclassified land cover data sets, was acquired circa 2006, there is a temporal discrepancy between the thematic LULC ancillary data (dated 2006) and the population data (dated 2010). Although there is a discrepancy between the three LULC data sets and the population data, this discrepancy is the same for each LULC data set. All three preclassified LULC data sets were clipped to the study area and registered to the Connecticut State Plane Coordinate System (NAD83) at a 30 × 30 meters spatial resolution.
It is apparent that most of the population is concentrated in the developed area and that some categories of the land cover in the original LULC data set may not be clearly related to the population distribution. As has been noted, having more categories does not necessarily lead to improved results (Lin, Cromley, and Zhang Citation2011). Only categories related to developed land in the three LULC data sets were used as ancillary data in the analysis. There are three different developed types in NLCD 2006 and C-CAP data sets: low-, medium-, and high-intensity developed. However, there is only a single developed category in the CLEAR data set.
The road networks were downloaded from the US Census Bureau's 2010 TIGER/Line Shapefiles Main Page (http://www.census.gov/cgi-bin/geo/shapefiles2010/main) and clipped to the study area. Finally, parcel data were obtained from the Connecticut Capitol Region Council of Governments (CRCOG). This data layer was first clipped to the study area, and then single-family features, two-family features, and multiple-family features were extracted as residential parcels. The CRCOG parcel data contains 80,022 single-family parcels, 6036 two-family parcels, and 8177 multiple-family parcels in the study area.
4. Research design
The basic problem is to use population counts given for source zones at the census tract level to estimate population counts at the larger scale of block groups. There are broadly four types of areal interpolation methods included in this study: BDAS, IDM, GWR, and QR. Two IDM sub-models with different population density calculation procedures were tested: one calculated population density for each land cover type based on the source zones that had their centroids located in that land use area (IDMC) and the other calculated population density for each land use type based on the source zones where land use appears most frequently (IDMM). The GWR interpolator also had two sub-models with different methods for the scaling procedure. The first scaled the population calculated from the raw estimated coefficient to preserve source zone counts, which is termed GWR with scaled population (GWRSP). The other made all estimated coefficients non-negative first and then scaled the estimated population to preserve source counts; this is termed GWR with scaled coefficients (GWRSC). The QR model had three sub-models. The first two initially permitted negative coefficients as in GWR; the original coefficients were then scaled in a manner similar to GWRSP (QRSP), and the other used the scaling procedure similar to GWRSC (QRSC). The third followed the procedure outline by Cromley, Hanink, and Bentley (Citation2012) by solving the QR with non-negative coefficients in a linear programming model without the need for a scaling step. This is termed the QR with non-negative coefficients (QRNC).
The global accuracy of each interpolation method was evaluated using the root mean square error (RMSE), the adjusted root mean square error (adj-RMSE), the mean absolute error (MAE), and the adjusted absolute error (adj-MAE). They were calculated as follows:
Where = the interpolated population for the ith target zone;
= the actual population for the ith target zone; n = the number of observations in the target zones.
RMSE is based on the variance of the estimator; RMSE will increase as the variance of error magnitudes increases (Res, Willmott, and Matsuura Citation2005). Since the errors are squared before they are averaged, the RMSE assigns relatively high weights to large errors and relatively low weights to small errors. Therefore, the adj-RMSE measure was developed (Gregory Citation2000) to adjust error magnitudes by the size of the population counts. However, Qiu, Woller, and Briggs (Citation2003) argued that the scaling procedure by population counts for each observation would be more likely to exaggerate the errors for the observations with small population counts and depreciate the errors for the observations with large population counts. MAE is based on the average absolute value of the errors. Res, Willmott, and Matsuura (Citation2005) preferred MAE over RMSE in describing average model-performance error. The adjusted MAE score was also included to reduce the impact of larger population counts.
In the first stage of the analysis, the interpolations used only the extracted land cover categories as ancillary data. Population was assumed to be located within these land cover areas. In the second stage, the land cover categories were enhanced before being used in the interpolation. One enhancement was associated with a 100 feet buffer of only secondary roads (MTFCC S1200), local neighborhood roads, rural roads, and city streets (MTFCC S1400). These roads were selected from the original road network, because certain features such as primary highways, their ramps, and parking lot roads are not likely to have population living alongside. All populations are assumed to reside only within the extracted land cover pixels that fall within this road buffer. The buffer enhancement was performed for all the three original LULC data sets. The second enhancement intersected the single-family, two-family, and multiple-family parcel layer with the three LULC data sets, respectively, to select only those developed pixels within each type of residential parcels.
5. Results and discussion
provides the global accuracy of each areal interpolation method using the three different LULC data sets without any enhancement. There is only one developed type in the CLEAR data set, and as shown by Cromley, Hanink, and Bentley (Citation2012), any interpolator based on regression with only one independent variable and no intercept with a scaling step will produce results identical to the binary dasymetric interpolator. All RMSE, adj-RMSE, MAE, and adj-MAE values for GWR- and QR-based interpolators are the same as those for BDAS interpolator under the CLEAR category. IDMC and IDMM also have the same global accuracy because source zones that have their centroids in developed land are identical to those with developed land having the most area within them. For the BDAS method, the C-CAP data produced the best results, followed by the NLCD data, and then the CLEAR data. For the two IDM-based methods, C-CAP is the best ancillary data for the IDMC interpolator; CLEAR data has the lowest RMSE values for the IDMM interpolator, while NLCD data has the best results in terms of adj-RMSE, MAE, and adj-MAE. For the two GWR-based methods, either of which is usually the best among all methods, C-CAP results are the best among all LULC data sets for the GWRSC interpolator, while results based on the NLCD data are best for the GWRSP interpolator. For the three QR-based interpolators, C-CAP is the best ancillary data for the QRNC interpolator; however, the best data set varies with respect to the measurement scores for the other two QR-based estimators.
Table 1. Overall areal interpolation results derived from LULC data sets without enhancement
shows the global areal interpolation results derived from road buffer-enhanced LULC data sets. All the RMSE, adj-RMSE, MAE, and adj-MAE values presented in are less than their corresponding values in . The reason that all GWR- and QR-based interpolators have the same results in this table is the same as that described for . The QRSP interpolator with C-CAP thematic ancillary data has the greatest absolute decrease of RMSE and MAE values, while the IDMM interpolator with C-CAP ancillary data has the greatest decrease in adj-RMSE values. IDMC with NLCD ancillary data has the greatest decrease of adj-MAE values. GWRSP using NLCD as ancillary data has the greatest decrease of RMSE and adj-RMSE values; QRSC with NLCD ancillary data has the least decrease of MAE values; and QRNC with C-CAP ancillary data has the least decrease of adj-MAE values.
Table 2. Overall areal interpolation results derived from LULC data sets enhanced by road buffer
Finally, shows the global areal interpolation results derived from parcel-enhanced LULC data sets. As expected, the overall error values in this table are the smallest compared to their corresponding values in the previous two tables. The GWRSC interpolator with the CLEAR ancillary data has the greatest decrease of RMSE, adj-RMSE, and MAE values, while the QRSP interpolator with the C-CAP ancillary data has the greatest decrease of adj-MAE values. IDMC with the NLCD ancillary data has the least decrease of RMSE, MAE, and adj-MAE values, while GWRSP with NLCD ancillary data has the least decrease in adj-RMSE values.
Table 3. Overall areal interpolation results derived from LULC data sets enhanced by parcel data
The local evaluation of areal interpolation results was done by mapping the spatial distributions of absolute deviation errors for each target zone. compares the spatial distributions of the absolute errors of the areal interpolation results. The three maps in the first row of are the results derived from the three different remotely sensed data sets without any enhancement. The areal interpolation method with the lowest MAE value for each LULC data set in was selected for mapping. The three maps in the second row are the results derived from road buffer-enhanced remotely sensed data. Again the areal interpolation methods for display were selected based on the same rule for values given in . Finally, the three maps in the last row compare the results derived from parcel-enhanced remotely sensed data. The selected criterion is also the smallest MAE value under each LULC data set. A four class, equal interval classification was used for each map. The visual complexity of each map in is very similar but the number of darker tones decreases from first row to last row.
Figure 2. The spatial distributions of absolute errors for areal interpolation results: (A) IDMC with CLEAR as ancillary data; (B) GWRSC with C-CAP as ancillary data; (C) GWRSP with NLCD as ancillary data; (D) BDAS with road buffer-enhanced CLEAR as ancillary data; (E) GWRSC with road buffer-enhanced C-CAP as ancillary data; (F) GWRSP with road buffer-enhanced NLCD as ancillary data; (G) GWRSC with parcel-enhanced CLEAR as ancillary data; (H) QRSC with parcel-enhanced C-CAP as ancillary data; (I) GWRSC with parcel-enhanced NLCD as ancillary data.
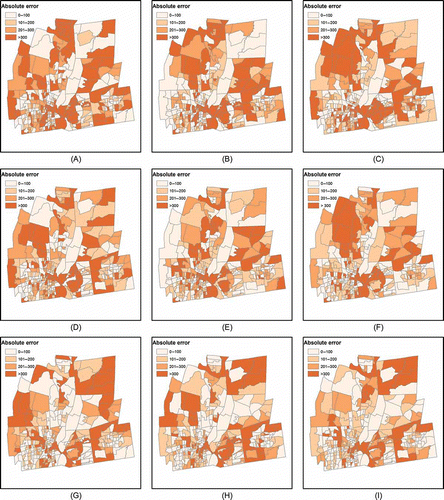
This visual result is verified by examining the statistical distributions of errors in each map class interval across all interpolators. – present the statistical distributions of errors in each interval, and over- and under-predictions are further separated resulting in eight classes. shows the statistical distributions of interpolation errors derived from remotely sensed data without any enhancement. shows the statistical distributions of errors derived from road buffer-enhanced remotely sensed data. The general trend is that the observations move from tail intervals to the center intervals by applying the road buffer to CLEAR, C-CAP, and NLCD data. The results for the parcel-enhanced data sets remove even more observations from the classes at the tails. This helps to explain the greater reduction in RMSE values with enhancement than for the MAE values in –.
Table 4. The number of observations in each break interval of error maps derived from three different remotely sensed data sets
Table 5. The number of observations in each break interval of error maps derived from three different remotely sensed data sets enhanced by road buffer
Table 6. The number of observations in each break interval of error maps derived from three different remotely sensed data sets enhanced by parcel.
As for the results derived from these three data sets, most numbers under the two tail break intervals in are larger than the corresponding ones in , while most numbers under the two center break intervals in are less than the corresponding ones in . However, this trend does not occur when applying the road buffer to the C-CAP data. Although the observations in the two tail intervals decrease, the observations within the two center intervals also decrease when applying the road buffer to the C-CAP data. In terms of the statistical distributions of interpolated population errors, the road buffer enhancement has a greater effect on CLEAR and NLCD data than on C-CAP data.
6. Conclusions
Enormous effort and cost is spent compiling publicly available LULC data set from remotely sensed imagery. When deciding on which categories to include in the classification, it is important to anticipate the uses of these data sets in further analysis. Areal interpolation is a widely used method for rectifying disparate data sets in GIS. This article evaluates the effect of three publicly available land cover data sets on intelligent areal interpolation results and, at the same time, evaluates the effects of two enhancements on areal interpolation results by applying them to remotely sensed land cover data. Results show that national and regional data sets can be of greater use in areal interpolation if more attention is given to the division of developed urban land into finer categories versus a single broad category.
Based solely on the original classified data sets, NLCD and C-CAP produced better results than CLEAR because CLEAR did not provide any sub-categorization of developed urban land. However, the advantage of C-CAP and NLCD data over CLEAR data becomes less obvious if these data sets were enhanced using additional information. The enhancement of CLEAR data with a parcel layer improved CLEAR results, making it better than C-CAP for six of the eight methods and better than NLCD for four of the eight methods with respect to RMSE. CLEAR is only better than the national data set for three methods based on MAE.
Overall, using parcels appears to be a better spatial enhancement than a road buffer. One reason is that road buffer enhancement constrains only the developed land spatially, while the parcel enhancement not only constrains the developed land spatially, but also expands the developed land into more categories. The developed land category in CLEAR, for example, was further divided into single-family developed, two-family developed, and multiple-family developed. Another reason for parcel data being a better enhancer of remotely sensed land cover data is that the developed land within the road buffer area might not contain only residential land along the road, but also the road itself.
Ancillary data are critical to improving areal interpolation results and are as important as the actual interpolation method used. In this study, overall weaker methods, such as BDAS, the two IDM methods, and QRSP outperformed the overall stronger methods when the original remotely sensed data were enhanced by road buffers or parcel data layers. For areal interpolation, having ancillary data that are spatially correlated variables is very important. More effort is needed to improve the spatial detail among developed urban categories. Parcel data provide a better enhancement than road buffers because the parcels remove the areas of the roads themselves. Land cover data sets based on the broadest Anderson Level I classification such as the CLEAR data set in this study are insufficient for use as ancillary data to estimate population distributions. Enhancement before using imagery data in an areal interpolation analysis, which can be implemented easily in a GIS, is a solution to this problem.
Related Research Data
References
- Anderson , J. R. , Hardy , E. E. , Roach , J. T. and Witmer , R. E. 1976 . “ A Land Use and Land Cover Classification System for Use with Remote Sensor Data ” . In U.S. Geological Survey Professional Paper, 964 , Washington , DC : United States Government Printing Office .
- Anselin , L. 2003 . Spatial Externalities, Spatial Multipliers and Spatial Econometrics . International Regional Science Review , 26 : 153 – 166 .
- Charlton, M. E., and A. S. Fotheringham. 2009. “Geographically Weighted Regression White Paper.” http://ncg.nuim.ie/ncg/gwr/GWR_WhitePaper.pdf (http://ncg.nuim.ie/ncg/gwr/GWR_WhitePaper.pdf) (Accessed: February 2013 ).
- Cromley , R. G. , Hanink , D. M. and Bentley , G. C. 2012 . A Quantile Regression Approach to Areal Interpolation . Annals of the Association of American Geographers , 102 ( 4 ) : 763 – 777 .
- Dempster , A. , Laird , N. and Rubin , D. 1977 . Maximum Likelihood From Incomplete Data via the EM Algorithm.” . Journal of the Royal Statistical Society. Series B (Methodological) , 39 ( 1 ) : 1 – 38 .
- Eicher , C. L. and Brewer , C. A. 2001 . Dasymetric Mapping and Areal Interpolation: Implementation and Evaluation.” . Cartography and Geographic Information Science , 28 ( 2 ) : 125 – 138 .
- Falcone , J. A. and Homer , C. G. 2012 . Generation of a U.S. National Urban Land-Use Product . Photogrammetric Engineering and Remote Sensing , 78 ( 10 ) : 1057 – 1068 .
- Fisher , P. and Langford , M. 1995 . Modeling the Errors in Areal Interpolation Between Zonal Systems by Monte Carlo Simulation . Environment and Planning A , 27 : 211 – 224 .
- Fisher , P. F. and Langford , M. 1996 . Modeling Sensitivity to Accuracy in Classified Imagery: A Study of Areal Interpolation by Dasymetric Mapping.” . The Professional Geographer , 48 ( 3 ) : 299 – 309 .
- Flowerdew , R. and Green , M. 1989 . “ Statistical Methods for Inference Between Incompatible Zonal Systems ” . In The Accuracy of Spatial Databases , Edited by: Goodchild , M. F. and Gopal , S. 239 – 247 . London : Taylor and Francis .
- Flowerdew , R. and Green , M. 1991 . “ Data Integration: Statistical Methods for Transferring Data Between Zonal Systems ” . In Handling Geographical Information , Edited by: Masser , I. and Blakemore , M. 38 – 54 . London : Longman .
- Flowerdew , R. and Green , M. 1994 . “ Areal Interpolation and Types of Data ” . In Spatial Analysis and GIS , Edited by: Fotheringham , S. and Rogerson , P. 121 – 145 . London : Taylor and Francis .
- Fotheringham , A. and Rogerson , P. 1993 . GIS and Spatial Analytical Problems.” . International Journal of Geographical Information Systems , 7 ( 1 ) : 3 – 19 .
- Fry , J. , Xian , G. , Jin , S. , Dewitz , J. , Homer , C. , Yang , L. , Barnes , C. , Herold , N. and Wickham , J. 2011 . Completion of the 2006 National Land Cover Database for the Conterminous United States.” . Photogrammetric Engineering and Remote Sensing , 77 ( 9 ) : 858 – 864 .
- Goodchild , M. F. and Lam , N. S.-N. 1980 . Area Interpolation: A Variant of the Tradiational Spatial Problem . Geo-Processing , 1 : 297 – 312 .
- Gregory , I. N. August 23–25 2000 . “ An Evaluation of the Accuracy of the Areal Interpolation of Data for the Analysis of Longterm Change in England and Wales ” . In Proceedings of the 5th International Conference on GeoComputation , August 23–25 , Kent : University of Greenwich .
- Koenker , R. and Bassett , G. 1978 . Regression Quantile.” . Econometrica , 46 ( 1 ) : 33 – 50 .
- Lam , N. S.-N. 1983 . Spatial Interpolation Methods: A Review.” . Cartography and Geographic Information Science , 10 ( 2 ) : 129 – 150 .
- Langford , M. 2006 . Obtaining Population Estimates in Non-Census Reporting Zones: An Evaluation of the 3-Class Dasymetric Method.” . Computers, Environment and Urban Systems , 30 ( 2 ) : 161 – 180 .
- Langford , M. 2007 . Rapid Facilitation of Dasymetric-Based Population Interpolation By Means of Raster Pixel Maps.” . Computers, Environment and Urban Systems , 31 ( 1 ) : 19 – 32 .
- Langford , M. , Maguire , D. and Unwin , D. 1991 . “ The Areal Interpolation Problem: Estimating Population Using Remote Sensing in a GIS Framework ” . In Handling Geographic Information: Methodology and Potential Applications , Edited by: Masser , I. and Blakemore , M. 55 – 77 . London : Longman .
- Lin , J. , Cromley , R. G. and Zhang , C. 2011 . Using Geographically Weighted Regression to Solve the Areal Interpolation Problem.” . Annals of GIS , 17 ( 1 ) : 1 – 14 .
- Maantay , J. A. , Maroko , A. R. and Herrmann , C. 2007 . Mapping Population Distribution in the Urban Environment: The Cadastral-Based Expert Dasymetric System (CEDS).” . Cartography and Geographic Information Science , 34 ( 2 ) : 77 – 102 .
- Mennis , J. and Hultgren , T. 2006 . Intelligent Dasymetric Mapping and Its Application to Areal Interpolation.” . Cartography and Geographic Information Science , 33 ( 3 ) : 179 – 194 .
- Mrozinski , R. D. and Cromley , R. G. 1999 . Singly- and Doubly-Constrained Methods of Areal Interpolation for Vector-Based GIS.” . Transactions in GIS , 3 ( 3 ) : 285 – 301 .
- Okabe , A. and Sadahiro , Y. 1997 . Variation in Count Data Transferred From a Set of Irregular Zones to a Set of Regular Zones Through the Point-in-Polygon Method.” . International Journal of Geographical Information Science , 11 ( 1 ) : 93 – 106 .
- Openshaw , S. and Taylor , P. J. 1981 . “ The Modifiable Areal Unit Problem ” . In Quantitative Geography: A British View , Edited by: Wrigley , N. and Bennett , R. 60 – 69 . London : Routledge and Kegan Paul .
- Price, C. V., N. Nakagaki, K. J. Hitt, and R. M. Clawges. 2006. “Enhanced Historical Land-use and Land-cover Data Sets of the U.S. Geological Survey.” U.S. Geological Survey Data Series 2006-240. http://pubs.usgs.gov/ds/2006/240/ (http://pubs.usgs.gov/ds/2006/240/) (Accessed: February 2013 ).
- Qiu , F. , Woller , K. and Briggs , R. 2003 . Modeling Urban Population Growth From Remotely Sensed Imagery and TIGER GIS Road Data.” . Photogrammetric Engineering and Remote Sensing , 69 ( 9 ) : 1031 – 1042 .
- Qiu , F. , Zhang , C. and Zhou , Y. 2012 . The Development of an Areal Interpolation ArcGIS Extension and a Comparative Study.” . GIScience and Remote Sensing , 49 ( 5 ) : 644 – 663 .
- Res , C. , Willmott , C. J. and Matsuura , K. 2005 . Advantages of the Mean Absolute Error (MAE) Over the Root Mean Square Error (RMSE) in Assessing Average Model Performance . Climate Research , 30 : 79 – 82 .
- Tapp , A. 2010 . Areal Interpolation and Dasymetric Mapping Methods Using Local Ancillary Data Sources.” . Cartography and Geographic Information Science , 37 ( 3 ) : 215 – 228 .
- Visvalingam , M. 1991 . “ Areal Units and the Linking of Data ” . In Spatial Analysis and Spatial Policy Using Geographic Information Systems , Edited by: Worrall , L. 12 – 37 . London : Belhaven Press .
- Vogelmann , J. E. , Howard , S. M. , Yang , L. , Larson , C. R. , Wylie , B. K. and Van Driel , N. 2001 . Completion of the 1990’s National Land Cover Data Set for the Conterminous United States From Landsat Thematic Mapper Data and Ancillary Data Sources.” . Photogrammetric Engineering and Remote Sensing , 67 ( 6 ) : 650 – 662 .
- Wright , J. K. 1936 . A Method of Mapping Densities of Population: With Cape Cod as an Example.” . Geographical Review , 26 ( 1 ) : 103 – 110 .
- Wu , S. , Qiu , L. and Wang , L. 2005 . Population Estimation Methods in GIS and Remote Sensing: A Review.” . GIScience and Remote Sensing , 42 ( 1 ) : 80 – 96 .
- Xian , G. , Homer , C. and Fry , J. 2009 . Updating the 2001 National Land Cover Database Land Cover Classification to 2006 by Using Landsat Imagery Change Detection Methods.” . Remote Sensing of Environment , 113 ( 6 ) : 1133 – 1147 .
- Xie , Y. 1995 . The Overlaid Network Algorithms for Areal Interpolation Problem.” . Computers, Environment and Urban Systems , 19 ( 4 ) : 287 – 306 .
- Yuan , Y. , Smith , R. M. and Limp , W. F. 1997 . Remodeling Census Population with Spatial Information From Landsat TM Imagery.” . Computers, Environment and Urban Systems , 21 ( 3 ) : 245 – 258 .