
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we present a brief survey of reinforcement learning, with particular emphasis on stochastic approximation (SA) as a unifying theme. The scope of the paper includes Markov reward processes, Markov decision processes, SA algorithms, and widely used algorithms such as temporal difference learning and Q-learning.
1. Introduction
In this paper, we present a brief survey of reinforcement learning (RL), with particular emphasis on stochastic approximation (SA) as a unifying theme. The scope of the paper includes Markov reward processes, Markov decision processes (MDPs), SA methods, and widely used algorithms such as temporal difference learning and Q-learning. RL is a vast subject, and this brief survey can barely do justice to the topic. There are several excellent texts on RL, such as Refs. [Citation1–4]. The dynamics of the SA algorithm are analysed in Refs. [Citation5–11]. The interested reader may consult those sources for more information.
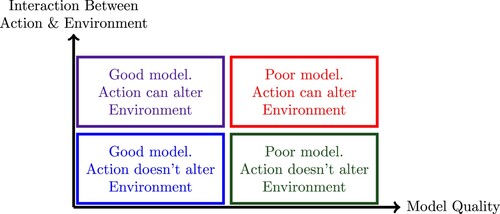
In this survey, we use the phrase “ RL” to refer to decision-making with uncertain models, and in addition, current actions alter the future behaviour of the system. Therefore, if the same action is taken at a future time, the consequences might not be the same. This additional feature distinguishes RL from “mere” decision-making under uncertainty. Figure rather arbitrarily divides decision-making problems into four quadrants. Examples from each quadrant are now briefly described.
Many if not most decision-making problems fall into the lower-left quadrant of “good model, no alteration” (meaning that the control actions do not alter the environment). An example is a fighter aircraft which usually has an excellent model, thanks to aerodynamical modelling and/or wind tunnel tests. In turn this permits the control system designers to formulate and to solve an optimal (or some other form of) control problem.
Controlling a chemical reactor would be an example from the lower-right quadrant. As a traditional control system, it can be assumed that the environment in which the reactor operates does not change as a consequence of the control strategy adopted. However, due to the complexity of a reactor, it is difficult to obtain a very accurate model, in contrast with a fighter aircraft for example. In such a case, one can adopt one of two approaches. The first, which is a traditional approach in control system theory, is to use a nominal model of the system and to treat the deviations from the nominal model as uncertainties in the model. A controller is designed based on the nominal model, and robust control theory would be invoked to ensure that the controller would still perform satisfactorily (though not necessarily optimally) for the actual system. The second, which would move the problem from the lower right to the upper-right quadrant, is to attempt to “learn” the unknown dynamical model by probing its response to various inputs. This approach is suggested in Ref. [Citation4, Example 3.1]. A similar statement can be made about robots, where the geometry determines the form of the dynamical equations describing it, but not the parameters in the equations; see, for example, Ref. [Citation12]. In this case too, it is possible to “learn” the dynamics through experimentation. In practice, such an approach is far slower than the traditional control systems approach of using a nominal model and designing a “robust” controller. However, “learning control” is a popular area in the world of machine learning. One reason is that the initial modelling error is too large, then robust control theory alone would not be sufficient to ensure the stability of the actual system with the designed controller. In contrast (and in principle), a “learning control” approach can withstand larger modelling errors. The widely used model predictive control paradigm can be viewed as an example of a learning-based approach.
A classic example of a problem belonging to the upper-left corner is a MDP, which forms the backbone of one approach to RL. In an MDP, there is a state space
and an action space
The upper-right quadrant is the focus of RL. There are many possible ways to formulate RL problems, each of which leads to its own solution methodologies. A very popular approach to RL is to formulate it as MDPs whose dynamics are unknown. That is the approach adopted in this paper.
Figure 1. The four quadrants of decision-making under uncertainty.
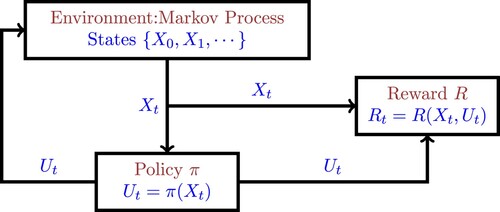
In an MDP, at each time t, the learner (also known as the actor or the agent) measures the state . Based on this measurement, the learner chooses an action
and receives a reward
. Future rewards are discounted by a discount factor
. The rule by which the current action
is chosen as a function of the current state
is known as a policy. With each policy, one can associate the expected value of the total (discounted) reward over time. The problem is to find the best policy. There is a variant called partially observable MDP in which the state
cannot be measured directly; rather, there is an output (or observation)
which is a memoryless function, either deterministic or random, of
. These problems are not studied here; it is always assumed that
can be measured directly. When the parameters of the MDP are known, there are several approaches to determining the optimal policy. RL is distinct from an MDP in that, in RL, the parameters of the underlying MDP are constant but not known to the learner; they must be learnt on the basis of experimentation. Figure depicts the situation.
Figure 2. Depiction of a RL problem.
The remainder of the paper is organized as follows: in Section 2, Markov reward processes are introduced. These are a precursor to MDPs, which are introduced in Section 3. Specifically, in Section 3.1, the relevant problems in the study of MDPs are formulated. In Section 3.2, the solutions to these problems are given in terms of the Bellman value iteration, the action-value function, and the F-iteration to determine the optimal action-value function. In Section 3.3, we study the situation where the dynamics of the MDP under study are not known precisely. Instead, one has access only to a sample path of the Markov process under study. For this situation, we present two standard algorithms, known as temporal difference learning and Q -learning. Starting from Section 4, the paper consists of results due to the author. In Section 4.1, the concept of SA is introduced, and its relevance to RL is outlined in Section 4.2. In Section 4.3, a new theorem on the global asymptotic stability of nonlinear ODEs is stated; this theorem is of independent interest. Some theorems on the convergence of the SA algorithm are presented in Sections 4.4 and 4.5. In Section 5, the results of Section 4 are applied to RL problems. In Section 5.1, a technical result on the sample paths of an irreducible Markov process is stated. Using this result, simplified conditions are given for the convergence of the temporal difference algorithm (Section 5.2) and Q-learning (Section 5.3). A brief set of concluding remarks ends the paper.
2. Markov reward processes
Markov reward processes are standard (stationary) Markov processes where each state has a “reward” associated with it. Markov reward processes are a precursor to MDPs; so we review those in this section. There are several standard texts on Markov processes, one of which is Ref. [Citation14].
Suppose is a finite set of cardinality n, written as
. If
is a stationary Markov process assuming values in
, then the corresponding state transition matrix A is defined by
(1)
(1) Thus the ith row of A is the conditional probability vector of
when
. Clearly the row sums of the matrix A are all equal to one. This can be expressed as
, where
denotes the n-dimensional column vector whose entries all equal to one. Therefore, if we define the induced matrix norm
as
then
equals one, which also equals the spectral radius of A.
Now suppose that there is a “reward” function associated with each state. There is no consensus within the community about whether the reward corresponding to the state
is paid at time t as in Ref. [Citation3] or time t + 1 as in Refs. [Citation2,Citation4]. In this paper, it is assumed that the reward is paid at time t and is denoted by
; the modifications required to handle the other approach are easy and left to the reader. The reward
can either be a deterministic function of
or a random function. If
is a deterministic function of
, then we have that
where R is the reward function mapping
into (a finite subset of)
. Thus, whenever the trajectory
of the Markov process equals some state
, the resulting reward
will always equal
. Thus the reward is captured by an n-dimensional vector
, where
. On the other hand, if
is a random function of
, then one would have to provide the probability distribution of
given
. Since
has only n different values, we would have to provide n different probability distributions. To avoid technical difficulties, it is common to assume that
is a bounded random variable for each index i. Note that because the set
is finite, if the reward function is deterministic, then we have that
In case the reward function R is random, as mentioned above, it is common to assume that
is a bounded random variable for each index
, where the symbol
equals
. With this assumption, it follows that
Two kinds of Markov reward processes are widely studied, namely: discounted reward processes and average reward processes. In this paper, we restrict attention to discounted reward processes. However, we briefly introduce average reward processes. Define (if it exists)
An excellent review of average reward processes can be found in Ref. [Citation15].
In each discounted Markov reward process, there is a “discount factor” . This factor captures the extent to which future rewards are less valuable than immediate rewards. Fix an initial state
. Then the expected discounted future reward
is defined as
(2)
(2) We often just use “discounted reward” instead of the longer phrase. With these assumptions, because
, the above summation converges and is well defined. The quantity
is referred to as the value function associated with
, and the vector
(3)
(3) is referred to as the value vector. Note that, throughout this paper, we view the value as both a function
as well as a vector
. The relationship between the two is given by (Equation3
(3)
(3) ). We shall use whichever interpretation is more convenient in a given context.
This raises the question as to how the value function and/or value vector is to be determined. Define the vector via
(4)
(4) where
if R is a deterministic function, and if
is a random function of
, then
(5)
(5) The next result gives a useful characterization of the value vector.
Theorem 2.1
The vector satisfies the recursive relationship
(6)
(6) or, in expanded form,
(7)
(7)
Proof.
Let be arbitrary. Then by definition we have
(8)
(8) However, if
, then
with probability
. Therefore, we can write
(9)
(9) In the second step we use the fact that the Markov process is stationary. Substituting (Equation9
(9)
(9) ) into (Equation8
(8)
(8) ) gives the recursive relationship (Equation7
(7)
(7) ).
Example 2.2
As an illustration of a Markov reward process, we analyse a toy snakes and ladders game with the transitions shown in Figure . Here W and L denote “win” and “lose,” respectively. The rules of the game are as follows:
Initial state is S.
A four-sided, fair die is thrown at each stage.
Player must land exactly on W to win and exactly on L to lose.
If implementing a move causes crossing of W and L, then the move is not implemented.
Figure 3. A toy snakes and ladders game.
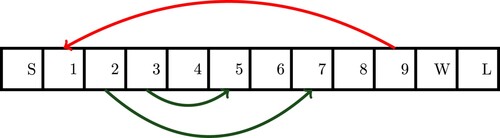
There are 12 possible states in all: S, 1, …, 9, W, and L. However, 2, 3, and 9 can be omitted, leaving nine states, namely S, 1, 4, 5, 6, 7, 8, W, and L. At each step, there are at most four possible outcomes. For example, from the state S, the four outcomes are 1, 7, 5, and 4. From state 6, the four outcomes are 7, 8, 1, and W. From state 7, the four outcomes are 8, 1, W, and 7. From state 8, there four possible outcomes are 1, W, L, and 8 with probability 1/4 each, because if the die comes up with 4, then the move cannot be implemented. It is time-consuming but straight-forward to compute the state transition matrix as
We define a reward function for this problem as follows: we set , where f is defined as follows:
,
, and
for all other states. However, there is an expected reward depending on the state at the next time instant. For example, if
, then the expected value of
is 5/4, whereas if
or
, then the expected value of
is 3/4.
Now let us see how the implicit equation (Equation6(6)
(6) ) can be solved to determine the value vector
. Since the induced matrix norm
and
, it follows that the matrix
is nonsingular. Therefore, for every reward function
, there is a unique
that satisfies (Equation6
(6)
(6) ). In principle, it is possible to deduce from (Equation6
(6)
(6) ) that
(10)
(10) The difficulty with this formula however is that in most actual applications of Markov decision problems, the integer n denoting the size of the state space
is quite large. Moreover, inverting a matrix has cubic complexity in the size of the matrix. Therefore, it may not be practicable to invert the matrix
. So we are forced to look for alternate approaches. A feasible approach is provided by the contraction mapping theorem.
Theorem 2.3
The map is monotone and is a contraction with respect to the
-norm, with contraction constant γ. Therefore, we can choose some vector
arbitrarily, and then define
Then
converges to the value vector
.
Proof.
The first statement is that if componentwise (and note that the vectors
and
need not consist of only positive components), then
. This is obvious from the fact that the matrix A has only nonnegative components, so that
. For the second statement, note that, because the matrix A is row-stochastic, the induced matrix norm
is equal to one. Therefore,
This completes the proof.
There is however a limitation to this approach, namely, that it requires that the state transition matrix A has to be known. In RL, this assumption is often not satisfied. Instead, one has access to a single sample path of a Markov process over
, whose state transition matrix is A. The question therefore arises: How can one compute the value vector
in such a scenario? The answer is provided by the so-called temporal difference algorithm, which is discussed in Section 3.3.
3. MDPs
3.1. Problem formulation
In a Markov reward process, the state evolves on its own, according to a predetermined state transition matrix. In contrast, in a MDP, there is also another variable called the “action” which affects the dynamics. Specifically, in addition to the state space
, there is also a finite set of actions
. Each action
leads to a corresponding state transition matrix
. So at time t, if the state is
and an action
is applied, then
(11)
(11) Obviously, for each fixed
, the corresponding state transition matrix
is row-stochastic. In addition, there is also a “reward” function
. Note that in a Markov reward process, the reward depends only on the current state, whereas in a MDP, the reward depends on both the current state as well as the action taken. As in Markov reward processes, it is possible to permit R to be a random function of
and
as opposed to a deterministic function. Moreover, to be consistent with the earlier convention, it is assumed that the reward
is paid at time t.
The most important aspect of an MDP is the concept of a “policy,” which is just a systematic way of choosing given
. If
is any map, this would be called a deterministic policy, and the set of all deterministic policies is denoted by
. Alternatively, let
denote the set of probability distributions on the finite set
. Then a map
would be called a probabilistic policy, and the set of probabilistic policies is denoted by
. Note that the cardinality of
equals
, while the set
is uncountable.
A vital point about MDPs is this: whenever any policy π, whether deterministic or probabilistic, is implemented, the resulting process is a Markov process with an associated state transition matrix, which is denoted by
. This matrix can be determined as follows: if
, then at time t, if
, then the corresponding action
equals
. Therefore,
(12)
(12) If
and
(13)
(13) where
, then
(14)
(14) In a similar manner, for every policy π, the reward function
can be converted into a reward map
as follows: If
, then
(15)
(15) whereas if
, then
(16)
(16) Thus, given any policy π, whether deterministic or probabilistic, we can associate with it a reward vector
. To summarize, given any MDP, once a policy π is chosen, the resulting process
is a Markov reward process with state transition matrix
and reward vector
.
Example 3.1
To illustrate these ideas, suppose n = 4, m = 2, so that there four states and two actions. Thus, there are two state transition matrices
corresponding to the two actions. (In the interests of clarity, we write
and
instead of
and
.) Suppose
is a deterministic policy, represented as a
matrix (in this case a
matrix), as follows:
This means that if
, or
, then
, while if
, then
. Let us use the notation
to denote the ith row of the matrix
, where k = 1, 2 and
. Then the state transition matrix
is given by
Thus, the first, third, and fourth rows of
come from
, while the second row comes from
.
Next, suppose is a probabilistic policy, represented by the matrix
Thus, if
, then the action
with probability 0.3 and equals
with probability 0.7, and so on. For this policy, the resulting state transition matrix is determined as follows:
For a MDP, one can pose three questions:
Policy evaluation: We have seen already that given a Markov reward process, with a reward vector
Optimal value determination: For each policy π, there is an associated value vector
Optimal policy determination: In (Equation17
3.2. MDPs: solution
In this subsection, we present answers to the three questions above.
3.2.1. Policy evaluation
Suppose a policy π in or
is specified. Then the corresponding state transition matrix
and reward vector
are given by (Equation12
(12)
(12) ) (or (Equation14
(14)
(14) )) and (Equation15
(15)
(15) ), respectively. As pointed out above, once the policy is chosen, the process becomes just a Markov reward process. Then it readily follows from Theorem 2.1 that
satisfies an equation analogous to (Equation6
(6)
(6) ), namely
(19)
(19) As before, it is inadvisable to compute
via
. Instead, one should use value iteration to solve (Equation19
(19)
(19) ). Observe that whatever the policy π might be, the resulting state transition matrix
satisfies
. Therefore, the map
is a contraction with respect to
, with contraction constant γ.
3.2.2. Optimal value determination
Now we introduce one of the key ideas in MDPs. Define the Bellman iteration map via
(20)
(20)
Theorem 3.2
The map B is monotone and a contraction with respect to the -norm. Therefore, the fixed point
of the map B satisfies the relation
(21)
(21)
Note that (Equation21(21)
(21) ) is known as the Bellman optimality equation. Thus, in principle at least, we can choose an arbitrary initial guess
, and repeatedly apply the Bellman iteration. The resulting iterations would converge to the unique fixed point of the operator B, which we denote by
.
The significance of the Bellman iteration is given by the next theorem.
Theorem 3.3
Define to be the unique fixed point of B, and define
to equal
, where
is defined in (Equation17
(17)
(17) ). Then
.
Therefore, the optimal value vector can be computed using the Bellman iteration. However, knowing the optimal value vector does not, by itself, give us an optimal policy.
3.2.3. Optimal policy determination
To solve the problem of optimal policy determination, we introduce another function , known as the action-value function, which is defined as follows:
(22)
(22) This function was first defined in Ref. [Citation16]. Note that
is defined only for deterministic policies. In principle, it is possible to define it for probabilistic policies, but this is not commonly done. In the above definition, the expectation
is with respect to the evolution of the state
under the policy π.
The way in which a MDP is setup is that at time t, the Markov process reaches a state , based on the previous state
and the state transition matrix
corresponding to the policy π. Once
is known, the policy π determines the action
, and then the reward
is generated. In particular, when defining the value function
corresponding to a policy π, we start off the MDP in the initial state
, and choose the action
. However, in defining the action-value function
, we do not feel compelled to set
, and can choose an arbitrary action
. From t = 1 onwards however, the action
is chosen as
. This seemingly small change leads to some simplifications.
Just as we can interpret as an n-dimensional vector, we can interpret
as an nm-dimensional vector, or as a matrix of dimension
. Consequently, the
-vector has higher dimension than the value vector.
Theorem 3.4
For each policy , the function
satisfies the recursive relationship
(23)
(23)
Proof.
Observe that at time t = 0, the state transition matrix is . So, given that
and
, the next state
has the distribution
Moreover,
because the policy π is implemented from time t = 1 onwards. Therefore,
This is the desired conclusion.
Theorem 3.5
The functions and
are related via
(24)
(24)
Proof.
If we choose , then (Equation23
(23)
(23) ) becomes
This is the same as (Equation11
(11)
(11) ) written out componentwise. We know that (Equation11
(11)
(11) ) has a unique solution, namely
. This shows that (Equation24
(24)
(24) ) holds.
The import of Theorem 3.5 is the following: in defining the function for a fixed policy
, we have the freedom to choose the initial action
as any element we wish in the action space
. However, if we choose the initial action
for each state
, then the corresponding action-value function
equals the value function
, for each state
.
In view of (Equation24(24)
(24) ), the recursive equation for
can be rewritten as
(25)
(25) This motivates the next theorem.
Theorem 3.6
Define by
(26)
(26) Then
satisfies the following relationships:
(27)
(27)
(28)
(28) Moreover, every policy
such that
(29)
(29) is optimal.
Proof.
Since is defined by (Equation26
(26)
(26) ), it follows that
This establishes (Equation28
(28)
(28) ) and (Equation29
(29)
(29) ). Substituting (Equation28
(28)
(28) ) into (Equation26
(26)
(26) ) gives (Equation27
(27)
(27) ).
Theorem 3.6 converts the problem of determining an optimal policy into one of solving the implicit equation (Equation27(27)
(27) ). For this purpose, we define an iteration on action-functions that is analogous to (Equation20
(20)
(20) ) for value functions. As with the value function, the action-value function can either be viewed as a map
, or as a vector in
, or as an
matrix. We use whichever interpretation is convenient in the given situation.
Theorem 3.7
Define by
(30)
(30) Then the map F is monotone and is a contraction. Moreover, for all
, the sequence of iterations
converges to
as
.
If we were to rewrite (Equation21(21)
(21) ) and (Equation27
(27)
(27) ) in terms of expected values, the differences between the Q-function and the V-function would become apparent. We can rewrite (Equation21
(21)
(21) ) as
(31)
(31) and (Equation27
(27)
(27) ) as
(32)
(32) Thus in the Bellman formulation and iteration, the maximization occurs outside the expectation, whereas with the Q-formulation and F-iteration, the maximization occurs inside the expectation.
3.3. Iterative algorithms for MDPs with unknown dynamics
In principle, Theorem 2.3 can be used to compute, to arbitrary precision, the value vector of a Markov reward process. Similarly, Theorem 3.7 can be used to compute, to arbitrary precision, the optimal action-value function of a MDP, from which both the optimal value function and the optimal policy can be determined. However, both theorems depend crucially on knowing the dynamics of the underlying process. For instance, if the state transition matrix A is not known, it would not be possible to carry out the iterations
Early researchers in RL were aware of this issue and developed several algorithms that do not require explicit knowledge of the dynamics of the underlying process. Instead, it is assumed that a sample path
of the Markov process, together with the associated reward process, are available for use. With this information, one can think of two distinct approaches. First, one can use the sample path to estimate the state transition matrix, call it
. After a sufficiently long sample path has been observed, the contraction iteration above can be applied with A replaced by
. This would correspond to so-called “indirect adaptive control.” The second approach would be to use the sample path right from time t = 0, and adjust only one component of the estimated value function at each time instant t. This would correspond to so-called “direct adaptive control.” Using a similar approach, it is also possible to estimate the action-value function based on a single sample path. We describe two such algorithms, namely temporal difference learning for estimating the value function of a Markov reward process and Q-learning for estimating the action-value function of a MDP. Within temporal difference, we make a further distinction between estimating the full value vector and estimating a projection of the value vector onto a lower-dimensional subspace.
3.3.1. Temporal difference learning without function approximation
In this subsection and the next, we describe the so-called “temporal difference” family of algorithms, first introduced in Ref. [Citation17]. The objective of the algorithm is to compute the value vector of a Markov reward process. Recall that the value vector of a Markov reward process satisfies (Equation6
(6)
(6) ). In temporal difference approach, it is not assumed that the state transition matrix A is known. Rather, it is assumed that the learner has available a sample path
of the Markov process under study, together with the associated reward at each time. For simplicity, it is assumed that the reward is deterministic and not random. Thus the reward at time t is just
and does not add any information.
There are two variants of the algorithm. In the first, one constructs a sequence of approximations that, one hopes, would converge to the true value vector
as
. In the second, which is used when n is very large, one chooses a “basis representation matrix”
, where
. Then one constructs a sequence of vectors
, such that the corresponding sequence of vectors
forms an approximation to the value vector
. Since there is no a priori reason to believe that
belongs to the range of Ψ, there is also no reason to believe that
would converge to
. The second approach is called temporal difference learning with function approximation. The first is studied in this subsection, while the second is studied in the next subsection.
In principle, by observing the sample path for a sufficiently long duration, it is possible to make a reliable estimate of A. However, a key feature of the temporal difference algorithm is that it is a “direct” method, which works directly with the sample path, without attempting to infer the underlying Markov process. With the sample path of the Markov process, one can associate a corresponding “index process”
taking values in
as follows:
It is obvious that the index process has the same transition matrix A as the process
. The idea is to start with an initial estimate
, and update it at each time t based on the sample path
.
Now we introduce the (Temporal Difference) algorithm studied in this paper. This version of the
algorithm comes from Ref. [Citation18, Equation (4.7)] and is as follows: let
denote the unique solution of the equationFootnote1
At time t, let
denote the current estimate of
. Thus the ith component of
, denoted by
, is the estimate of the reward when the initial state is
. Let
be the index process defined above. Define the “temporal difference”
(33)
(33) where
denotes the
th component of the vector
. Equivalently, if the state at time t is
and the state at the next time t + 1 is
, then
(34)
(34) Next, choose a number
. Define the “eligibility vector”
(35)
(35) where
is a unit vector with a 1 in location
and zeros elsewhere. Since the indicator function in the above summation picks up only those occurrences where
, the vector
can also be expressed as
(36)
(36) Thus the support of the vector
consists of the singleton
. Finally, update the estimate
as
(37)
(37) where
is a sequence of step sizes. Note that, at time t, only the
th component of
is updated, and the rest remain the same.
A sufficient condition for the convergence of the -algorithm is given in Ref. [Citation18].
Theorem 3.8
The sequence converges almost surely to
as
, provided
(38)
(38)
(39)
(39)
3.3.2. TD-learning with function approximation
In this set-up, we again observe a time series . The new feature is that there is a “basis” matrix
, where
. The estimated value vector at time t is given by
, where
is the parameter to be updated. In this representation, it is clear that for any index
, we have that
where
denotes the ith row of the matrix Ψ.
Now we define the learning rule for updating . Let
be the observed sample path. By a slight abuse of notation, define
Thus, if
, then
. The eligibility vector
is defined via
(40)
(40) Note that
satisfies the recursion
Hence it is not necessary to keep track of an ever-growing set of past values of
. In contrast to (Equation35
(35)
(35) ), there is no term of the type
in (Equation40
(40)
(40) ). Thus, unlike the eligibility vector defined in (Equation35
(35)
(35) ), the current vector
can have more than one nonzero component. Next, define the temporal difference
as in (Equation33
(33)
(33) ). Note that if
and
, then
Then the updating rule is
(41)
(41) where
is the step size.
The convergence analysis of (Equation41(41)
(41) ) is carried out in detail in Ref. [Citation19] based on the assumption that the state transition matrix A is irreducible. This is quite reasonable, as it ensures that every state
occurs infinitely often in any sample path, with probability one. Since that convergence analysis does not readily fit into the methods studied in subsequent sections, we state the main results without proof. However, we state and prove various intermediate results that are useful in their own right.
Suppose A is row-stochastic and irreducible, and let denote its stationary distribution. Define
and define a norm
on
by
Then the corresponding distance between two vectors
and
is given by
Then the following result is proved in Ref. [Citation19].
Lemma 3.9
Suppose is row-stochastic and irreducible. Let
be the stationary distribution of A. Then
Consequently, the map
is a contraction with respect to
.
Proof.
We will show that
which is clearly equivalent to the
. Now
However, for each fixed index i, the row
is a probability distribution, and the function
is convex. If we apply Jensen's inequality with
, we see that
Therefore,
where in the last step, we use the fact that
.
To analyse the behaviour of the algorithm with function approximation, the following map
is defined in Ref. [Citation19]:
Note that
can be written explicitly as
Lemma 3.10
The map is a contraction with respect to
, with contraction constant
.
Proof.
Note that the first term on the right side does not depend on . Therefore,
However, it is already known that
By repeatedly applying the above, it follows that
Therefore,
This is the desired bound.
Define a projection by
Then
Thus Π projects the space
onto the image of the matrix Ψ, which is a d-dimensional subspace, if Ψ has full column rank. In other words,
is the closest point to
in the subspace
.
Next, observe that the projection Π is nonexpansive with respect to . As a result, the composite map
is a contraction. Thus there exists a unique
such that
Moreover, the above equation shows that in fact
belongs to the range of Ψ. Thus there exists a
such that
, and
is unique if Ψ has full column rank.
The limit behaviour of the algorithm is given by the next theorem, which is a key result from Ref. [Citation19].
Theorem 3.11
Suppose that Ψ has full column rank and that
Then, the sequence
converges almost surely to
, where
is the unique solution of
Moreover,
Note that since for all
, the best that one can hope for is that
The theorem states that the above identity might not hold and provides an upper bound for the distance between the limit
and the true value vector
. It is bounded by a factor
times this minimum.
Note that . So this is the extent to which the
iterations miss the optimal approximation.
3.3.3. Q-learning
The Q-learning algorithm proposed in Ref. [Citation16] has the characterization (Equation27(27)
(27) ) of
as its starting point. The algorithm is based on the following premise: at time t, the current state
can be observed; call it
. Then the learner is free to choose the action
; call it
. With this choice, the next state
has the probability distribution equal to the ith row of the state transition matrix
. Suppose the observed next stat
is
. With these conventions, the Q-learning algorithm proceeds as follows.
Choose an arbitrary initial guess
At time t, with current state
Repeat.
Theorem 3.12
The Q-learning algorithm converges to the optimal action-value function provided the following conditions are satisfied.
(44)
(44)
(45)
(45)
The main shortcoming of Theorems 3.8 and 3.12 is that the sufficient conditions (Equation38(38)
(38) ), (Equation39
(39)
(39) ), (Equation44
(44)
(44) ), and (Equation45
(45)
(45) ) are probabilistic in nature. Thus it is not clear how they are to be verified in a specific application. Note that in the Q-learning algorithm, there is no guidance on how to choose the next action
. Presumably
is chosen so as to ensure that (Equation44
(44)
(44) ) and (Equation45
(45)
(45) ) are satisfied. In Section 5, we show how these theorems can be proven, and also, how the troublesome probabilistic sufficient conditions can be replaced by purely algebraic conditions.
4. SA algorithms
4.1. SA and relevance to RL
The contents of the previous section make it clear that in MDP theory, a central role is played by the need to solve fixed point problems. Determining the value of a Markov reward problem requires the solution of (Equation6(6)
(6) ). Determining the optimal value of an MDP requires finding the fixed point of the Bellman iteration. Finally, determining the optimal policy for an MDP requires finding the fixed point of the F-iteration. As pointed out in Section 3.3, when the dynamics of an MDP are completely known, these fixed point problems can be solved by repeatedly applying the corresponding contraction mapping. However, when the dynamics of the MDP are not known, and one has access only to a sample path of the MDP, a different approach is required. In Section 3.3, we have presented two such methods, namely the temporal difference algorithm for value determination and the Q-learning algorithm for determining the optimal action-value function. Theorems 3.8 and 3.12, respectively, give sufficient conditions for the convergence of these algorithms. The proofs of these theorems, as given in the original papers, tend to be “one-off,” that is, tailored to the specific algorithm. It is now shown that a probabilistic method known as “SA” can be used to unify these methods in a common format. Moreover, instead of the convergence proofs being “one-off,” the SA algorithm provides a unifying approach.
The applications of SA go beyond these two specific algorithms. There is another area called “ deep RL” for problems in which the size of the state space is very large. Recall that the action-value function can either be viewed as an nm-dimensional vector or an
matrix. In deep RL, one determines (either exactly or approximately) the action-value function
for a small number of pairs
. Using these as a starting point, the overall function Q defined for all pairs
is obtained by training a deep neural network. Training a neural network (in this or any other application) requires the minimization of the average mean-squared error, denoted by
where
denotes the vector of adjustable parameters. In general, the function
is not convex; hence one can at best aspire to find a stationary point of
, i.e. a solution to the equation
. This problem is also amenable to the application of the SA approach.
Now we give a brief introduction to SA. Suppose is some function and d can be any integer. The objective of SA is to find a solution to the equation
, when only noisy measurements of
are available. The SA method was introduced in Ref. [Citation21], where the objective was to find a solution to a scalar equation
, where
. The extension to the case where d>1 was first proposed in Ref. [Citation22]. The problem of finding a fixed point of a map
can be formulated as the above problem with
. If it is desired to find a stationary point of a
function
, then we simply set
. Thus the above problem formulation is quite versatile. More details are given at the start of Section 4.2.
SA is a family of iterative algorithms, in which one begins with an initial guess and derives the next guess
from
. Several variants of SA are possible. In synchronous SA, every component of
is changed to obtain
. This was the original concept of SA. If, at any time t, only one component of
is changed to obtain
, and the others remain unchanged, this is known as ASA . This phrase was apparently first introduced in Ref. [Citation20]. A variant of the approach in Ref. [Citation20] is presented in Ref. [Citation23]. Specifically, in Ref. [Citation23], a distinction is introduced between using a “local clock” versus using a “global clock.” It is also possible to study an intermediate situation where, at each time t, some but not necessarily all components of
are updated. There does not appear to be a common name for this situation. The phrase batch asynchronous stochastic approximation (BASA) is introduced in Ref. [Citation24]. More details about these variations are given below. There is a fourth variant known as two-time scale SA is introduced in Ref. [Citation25]. In this set-up, one attempts to solve two coupled equations of the form
where
, and
. The idea is that one of the iterations (say
) is updated “more slowly” than the other (say
). Due to space limitations, two time-scale SA is not discussed further in this paper. The interested reader is referred to Refs. [Citation25–27] for the theory and to Refs. [Citation28,Citation29] for applications to a specific type of RL, known as actor-critic algorithms.
The relevance of SA to RL arises from the following factors:
Many (though not all) algorithms used in RL can be formulated as some type of SA algorithms.
Examples include temporal difference learning, temporal difference learning with function approximation, Q -learning, deep neural network learning, and actor-critic learning. The first three are discussed in detail in Section 5.
4.2. Problem formulation
There are several equivalent formulations of the basic SA problem.
Finding a zero of a function: Suppose
Finding a fixed point of a mapping: Suppose
Finding a stationary point of a function: Suppose
4.3. A new theorem for global asymptotic stability
In this section, we state a new theorem on the global asymptotic stability of nonlinear ODEs. This theorem is new and is of interest aside from its applications to the convergence of SA algorithms. The contents of this section and the next section are taken from Ref. [Citation30]. To state the result (Theorem 4.3), we introduce a few preliminary concepts from Lyapunov stability theory. The required background can be found in Refs. [Citation31–33].
Definition 4.1
A function is said to belong to class
, denoted by
, if
, and
is strictly increasing. A function
is said to belong to class
, denoted by
, if in addition,
as
. A function
is said to belong to class
, denoted by
, if
, and in addition, for all
, we have that
(50)
(50)
The concepts of functions of class and class
are standard. The concept of a function of class
is new. Note that if
is continuous, then it belongs to class
if and only if
and
for all r>0.
Example 4.2
Observe that every ϕ of class also belongs to class
. However, the converse is not true. Define
Then ϕ belongs to class
. However, since
as
, ϕ cannot be bounded below by any function of class
.
Suppose we wish to find a solution of . The convergence analysis of synchronous SA depends on the stability of an associated ODE
. We now state a new theorem on global asymptotic stability, and then use this to establish the convergence of the synchronous SA algorithm. In order to state this theorem, we first introduce some standing assumptions on
. Note that these assumptions are standard in the literature.
| (F1) | The equation | ||||
| (F2) | The function | ||||
Theorem 4.3
Suppose Assumption (F1) holds, and that there exists a function and functions
such that
(52)
(52)
(53)
(53) Then
is a globally asymptotically stable equilibrium of the ODE
.
This is Ref. [Citation30, Theorem 4], and the proof can be found therein. Well-known classical theorems for global asymptotic stability, such as those found in Refs. [Citation31–33], require the function to belong to class
. Theorem 4.3 is an improvement, in that the function
is required only to belong to the larger class
.
4.4. A convergence theorem for synchronous SA
In this subsection, we present a convergence theorem for synchronous SA. Theorem 4.4 is slightly more general than a corresponding result in Ref. [Citation30]. This theorem is obtained by combining some results from Refs. [Citation24,Citation30]. Other convergence theorems and examples can be found in Ref. [Citation30].
In order to analyse the convergence of the SA algorithm, we need to make some assumptions about the nature of the measurement error sequence . These assumptions are couched in terms of the conditional expectation of a random variable with respect to a σ-algebra. Readers who are unfamiliar with the concept are referred to Ref. [Citation34] for the relevant background.
Let denote the tuple
, and define
analogously; note that there is no
. Let
be any filtration (i.e. increasing sequence of σ-algebras), such that
are measurable with respect to
. For example, one can choose
to be the σ-algebra generated by the tuples
.
| (N1) | There exists a sequence | ||||
| (N2) | There exists a sequence | ||||
Now we can state a theorem about the convergence of synchronous SA.
Theorem 4.4
Suppose , and Assumptions (F1–F2) and (N1–N2) hold. Suppose in addition that there exists a
Lyapunov function
that satisfies the following conditions:
There exist constants a, b>0 such that
There is a finite constant M such that
| (1) | If | ||||
| (2) | Suppose further that there exists a function | ||||
Observe the nice “division of labour” between the two conditions: Equation (Equation58(58)
(58) ) guarantees the almost sure boundedness of the iterations, while the addition of (Equation60
(60)
(60) ) leads to the almost sure convergence of the iterations to the desired limit, namely the solution of
. This division of labour is first found in Ref. [Citation35]. Theorem 4.4 is a substantial improvement on Ref. [Citation36], which were the previously best results. The interested reader is referred to Ref. [Citation30] for further details.
Theorem 4.4 is a slight generalization of Ref. [Citation30, Theorem 5]. In that theorem, it is assumed that for all t, and that the constants
are uniformly bounded by some constant σ. In this case, (Equation58
(58)
(58) ) and (Equation60
(60)
(60) ) become
(61)
(61) These two conditions are usually referred to as the Robbins–Monro conditions.
4.5. Convergence of BASA
Equations (Equation47(47)
(47) ) through (Equation49
(49)
(49) ) represent what might be called synchronous SA, because at each time t, every component of
is updated. Variants of synchronous SA include ASA, where at each time t, exactly one component of
is updated, and BASA, where at each time t, some but not necessarily all components of
are updated. We present the results for BASA, because ASA is a special case of BASA. Moreover, we focus on (Equation48
(48)
(48) ), where the objective is to find a fixed point of a contractive map
. The modifications required for (Equation47
(47)
(47) ) and (Equation49
(49)
(49) ) are straight-forward.
The relevant reference for these results is Ref. [Citation24]. As a slight modification of (Equation46(46)
(46) ), it is assumed that at each time t + 1, there is available a noisy measurement
(62)
(62) We assume that there is a given deterministic sequence of “step sizes”
. In BASA, not every component of
is updated at time t. To determine which components are to be updated, we define d different binary “update processes”
,
. No assumptions are made regarding their independence. At time t, define
(63)
(63) This means that
(64)
(64) In order to define
when
, we make a distinction between two different approaches: global clocks and local clocks. If a global clock is used, then
(65)
(65) If a local clock is used, then we first define the local counter
(66)
(66) which is the total number of occasions when
,
. Equivalently,
is the total number of times up to and including time t when
is updated. With this convention, we define
(67)
(67) The distinction between global clocks and local clocks was apparently introduced in Ref. [Citation23]. Traditional RL algorithms such as
and Q-learning, discussed in detail in Section 3.3 and again in Sections 5.2 and 5.3, use a global clock. That is not surprising because Ref. [Citation23] came after Refs. [Citation16,Citation17]. It is shown in Ref. [Citation24] that the use of local clocks actually simplifies the analysis of these algorithms.
Now we present the BASA updating rules. Let us define the “step size vector” via (Equation65
(65)
(65) ) or (Equation67
(67)
(67) ) as appropriate. Then the update rule is
(68)
(68) where
is defined in (Equation62
(62)
(62) ). Here, the symbol ° denotes the Hadamard product of two vectors of equal dimensions. Thus if
have the same dimensions, then
is defined by
for all i.
Recall that we are given a function , and the objective is to find a solution to the fixed point equation
. Towards this end, we begin by stating the assumptions about the noise sequence.
| (N1′) | There exists a sequence of constants | ||||
| (N2′) | There exists a sequence of constants | ||||
Next we state conditions on the step size sequence, which allow us to state the theorems in a compact manner. Next, we state the assumptions on the step size sequence. Note that if a local clock is used, then can be random even if
is deterministic.
| (S1) | The random step size sequences | ||||
| (S2) | The random step size sequence | ||||
Finally, we state an assumption about the map .
| (G) |
| ||||
Theorem 4.5
Suppose that Assumptions (N1′) and (N2′) about the noise sequence, (S1) about the step size sequence, and (G) about the function hold. Then
almost surely.
Theorem 4.6
Let denote the unique fixed point of
. Suppose that Assumptions (N1′) and (N2′) about the noise sequence, (S1) and (S2) about the step size sequence, and (G) about the function
hold. Then
converges almost surely to
as
.
The proofs of these theorems can be found in Ref. [Citation24].
5. Applications to RL
In this section, we apply the contents of the previous section to derive sufficient conditions for two distinct RL algorithms, namely temporal difference learning (without function approximation) and Q -learning. Previously known results are stated in Section 3.3. So what is the need to re-analyse those algorithms again from the standpoint of SA? There are two reasons for doing so. First, the historical and Q-learning algorithms are stated using a “global clock” as defined in Section 4.5. Subsequently, the concept of a “local clock” is introduced in Ref. [Citation23]. In Ref. [Citation24], the authors build upon this distinction to achieve two objectives. First, when a local clock is used, there are fewer assumptions. Second, by proving a result on the sample paths of an irreducible Markov process (proved in Ref. [Citation24]), probabilistic conditions such as (Equation38
(38)
(38) )–(Equation39
(39)
(39) ) and (Equation44
(44)
(44) )–(Equation45
(45)
(45) ) are replaced by purely algebraic conditions.
5.1. A useful theorem about irreducible Markov processes
Theorem 5.1
Suppose is a Markov process on
with a state transition matrix A that is irreducible. Suppose
is a sequence of real numbers in
such that
for all t, and
(73)
(73) Then
(74)
(74) where I denotes the indicator function.
5.2. TD-learning without function approximation
Recall the algorithm without function approximation, presented in Section 3.3. One observes a time series
where
is a Markov process over
with a (possibly unknown) state transition matrix A, and
is a known reward function. With the sample path
of the Markov process, one can associate a corresponding “index process”
taking values in
as follows:
It is obvious that the index process has the same transition matrix A as the process
. The idea is to start with an initial estimate
and update it at each time t based on the sample path
.
Now we recall the algorithm without function approximation. At time t, let
denote the current estimate of
. Let
be the index process defined above. Define the “temporal difference”
(75)
(75) where
denotes the
th component of the vector
. Equivalently, if the state at time t is
and the state at the next time t + 1 is
, then
(76)
(76) Next, choose a number
. Define the “eligibility vector”
(77)
(77) where
is a unit vector with a 1 in location
and zeros elsewhere. Finally, update the estimate
as
(78)
(78) where
is the step size chosen in accordance with either a global or a local clock. The distinction between the two is described next.
To complete the problem specification, we need to specify how the step size is chosen in (Equation78
(78)
(78) ). The two possibilities studied here are global clocks and local clocks. If a global clock is used, then
, whereas if a local clock is used, then
, where
Note that in the traditional implementation of the
algorithm suggested in Refs. [Citation17–19], a global clock is used. Moreover, the algorithm is shown to converge provided
(79)
(79) As we shall see below, the theorem statements when local clocks are used involve slightly fewer assumptions than when global clocks are used. Moreover, neither involves probabilistic conditions such as (Equation38
(38)
(38) ) and (Equation39
(39)
(39) ), in contrast to Theorem 3.8.
Next we present two theorems regarding the convergence of the algorithm. As the hypotheses are slightly different, they are presented separately. But the proofs are quite similar and can be found in Ref. [Citation24].
Theorem 5.2
Consider the algorithm using a local clock to determine the step size. Suppose that the state transition matrix A is irreducible, and that the deterministic step size sequence
satisfies the Robbins–Monro conditions
Then
almost surely as
.
Theorem 5.3
Consider the algorithm using a global clock to determine the step size. Suppose that the state transition matrix A is irreducible and that the deterministic step size sequence is nonincreasing (i.e.
for all t) and satisfies the Robbins–Monro conditions as described above. Then
almost surely as
.
5.3. Q-learning
The Q-learning algorithm proposed in Ref. [Citation16] is now recalled for the convenience of the reader.
Choose an arbitrary initial guess
At time t, with current state
Repeat.
In earlier work such as Refs. [Citation18,Citation20], it is shown that the Q-learning algorithm converges to the optimal action-value function provided
(82)
(82)
(83)
(83) These conditions are stated here as Theorem 3.12. Similar hypotheses are present in all existing results in ASA. Note that in the Q-learning algorithm, there is no guidance on how to choose the next action
. Presumably
is chosen so as to ensure that (Equation82
(82)
(82) ) and (Equation83
(83)
(83) ) are satisfied. However, we now demonstrate a way to avoid such conditions using Theorem 5.1. We also introduce batch updating and show that it is possible to use a local clock instead of a global clock.
The batch Q-learning algorithm introduced here is as follows:
Choose an arbitrary initial guess
At time t, for each action index
Repeat.
Remark
Note that m different simulations are being run in parallel, and that in the kth simulation, the next action is always chosen as
. Hence, at each instant of time t, exactly m components of
(viewed as an
matrix) are updated, namely the
component, for each
. In typical MDPs, the size of the action space m is much smaller than the size of the state space n. For example, in the Blackjack problem discussed in Ref. [Citation4, Chapter 4],
while m = 2! Therefore the proposed batch Q-learning algorithm is quite efficient in practice.
Now, by fitting this algorithm into the framework of Theorem 5.1, we can prove the following general result. The proof can be found in Ref. [Citation24].
Theorem 5.4
Suppose that each matrix is irreducible, and that the step size sequence
satisfies the Robbins–Monro conditions (Equation61
(61)
(61) ) with
replaced by
. With this assumption, we have the following:
| (1) | If a local clock is used as in (Equation84 | ||||
| (2) | If a global clock is used (i.e. | ||||
Remark
Note that, in the statement of the theorem, it is not assumed that every policy π leads to an irreducible Markov process – only that every action leads to an irreducible Markov process. In other words, the assumption is that the m different matrices correspond to irreducible Markov processes. This is a substantial improvement. It is shown in Ref. [Citation37] that the following problem is NP (Nondeterministic Polynomial)-hard: given an MDP, determine whether every policy π results in a Markov process that is a unichain, that is, consists of a single set of recurrent states with the associated state transition matrix being irreducible, plus possibly some transient states. Our problem is slightly different, because we do not permit any transient states. Nevertheless, this problem is also likely to be very difficult. By not requiring any condition of this sort, and also by dispensing with conditions analogous to (Equation82
(82)
(82) ) and (Equation83
(83)
(83) ), the above theorem statement is more useful.
6. Conclusions and problems for future research
In this brief survey, we have attempted to sketch some of the highlights of RL. Our viewpoint, which is quite mainstream, is to view RL as solving Markov decision problems (MDPs) when the underlying dynamics are unknown. We have used the paradigm of SA as a unifying approach. We have presented convergence theorems for the standard approach, which might be thought of as “synchronous” SA as well as variants such as ASA and BASA. Many of these results are due to the author and his collaborators.
In this survey, due to length limitations, we have not discussed actor-critic algorithms. These can be viewed as applications of the policy gradient theorem [Citation38,Citation39] coupled with SA applied to two-time-scale (i.e. singularly perturbed) systems [Citation25,Citation27]. Some other relevant references are [Citation28,Citation29,Citation40]. Also, the rapidly emerging field of finite-time SA has not been discussed. Finite-Time Stochastic Approximation (FTSA) can lead to estimates of the rate of convergence of various RL algorithms, whereas conventional SA leads to only asymptotic results. Some recent relevant papers include Refs. [Citation41,Citation42].
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Funding
Notes on contributors
Mathukumalli Vidyasagar
Mathukumalli Vidyasagar was born in Guntur, India on September 29, 1947. He received the B.S., M.S. and Ph.D. degrees in electrical engineering from the University of Wisconsin in Madison, in 1965, 1967 and 1969 respectively. Between 1969 and 1989, he was a Professor of Electrical Engineering at Marquette University, Concordia University, and the University of Waterloo. In 1989 he returned to India as the Director of the newly created Centre for Artificial Intelligence and Robotics (CAIR) in Bangalore under the Ministry of Defence, Government of India. In 2000 he moved to the Indian private sector as an Executive Vice President of India's largest software company, Tata Consultancy Services. In 2009 he retired from TCS and joined the Erik Jonsson School of Engineering & Computer Science at the University of Texas at Dallas, as a Cecil & Ida Green Chair in Systems Biology Science. In January 2015 he received the Jawaharlal Nehru Science Fellowship and divided his time between UT Dallas and the Indian Institute of Technology Hyderabad. In January 2018 he stopped teaching at UT Dallas and now resides full-time in Hyderabad. Since March 2020, he is a SERB National Science Chair. His current research is in the area of Reinforcement Learning, with emphasis on using stochastic approximation theory. More broadly, he is interested in machine learning, systems and control theory, and their applications. Vidyasagar has received a number of awards in recognition of his research contributions, including Fellowship in The Royal Society, the world's oldest scientific academy in continuous existence, the IEEE Control Systems (Technical Field) Award, the Rufus Oldenburger Medal of ASME, the John R. Ragazzini Education Award from AACC, and others. He is the author of thirteen books and more than 160 papers in peer-reviewed journals.
Notes
1 For clarity, we have changed the notation so that the value vector is now denoted by instead of
as in (Equation6
(6)
(6) ).
References
- Bertsekas DP, Tsitsiklis JN. Neuro-dynamic programming. Nashua: Athena Scientific; 1996.
- Puterman ML. Markov decision processes: discrete stochastic dynamic programming. Hoboken: John Wiley; 2005.
- Szepesvári C. Algorithms for reinforcement learning. San Rafael: Morgan and Claypool; 2010.
- Sutton RS, Barto AG. Reinforcement learning: an introduction. 2nd ed. Cambridge: MIT Press; 2018.
- Ljung L. Strong convergence of a stochastic approximation algorithm. Ann Stat. 1978;6:680–696.
- Kushner HJ, Clark DS. Stochastic approximation methods for constrained and unconstrained systems. Springer-Verlag; 1978 (Applied mathematical sciences).
- Benveniste A, Metivier M, Priouret P. Adaptive algorithms and stochastic approximation. Springer-Verlag; 1990.
- Kushner HJ, Yin GG. Stochastic approximation and recursive algorithms and applications. Springer-Verlag; 1997.
- Benaim M. Dynamics of stochastic approximation algorithms. Springer Verlag; 1999.
- Borkar VS. Stochastic approximation: a dynamical systems viewpoint. Cambridge University Press; 2008.
- Borkar VS. Stochastic approximation: a dynamical systems viewpoint. 2nd ed. Hindustan Book Agency; 2022.
- Spong MW, Hutchinson SR, Vidyasagar M. Robot modeling and control. 2nd ed. John Wiley; 2020.
- Shannon CE. Programming a computer for playing chess. Philos Mag Ser7. 1950;41(314):1–18.
- Vidyasagar M. Hidden Markov processes: theory and applications to biology. Princeton University Press; 2014.
- Arapostathis A, Borkar VS, Fernández-Gaucherand E, et al. Discrete-time controlled Markov processes with average cost criterion: a survey. SIAM J Control Optim. 1993;31(2):282–344.
- Watkins CJCH, Dayan P. Q-learning. Mach Learn. 1992;8(3–4):279–292.
- Sutton RS. Learning to predict by the method of temporal differences. Mach Learn. 1988;3(1):9–44.
- Jaakkola T, Jordan MI, Singh SP. Convergence of stochastic iterative dynamic programming algorithms. Neural Comput. 1994;6(6):1185–1201.
- Tsitsiklis JN, Roy BV. An analysis of temporal-difference learning with function approximation. IEEE Trans Autom Contr. 1997;42(5):674–690.
- Tsitsiklis JN. Asynchronous stochastic approximation and q-learning. Mach Learn. 1994;16:185–202.
- Robbins H, Monro S. A stochastic approximation method. Ann Math Stat. 1951;22(3):400–407.
- Blum JR. Multivariable stochastic approximation methods. Ann Math Stat. 1954;25(4):737–744.
- Borkar VS. Asynchronous stochastic approximations. SIAM J Control Optim. 1998;36(3):840–851.
- Karandikar RL, Vidyasagar M. Convergence of batch asynchronous stochastic approximation with applications to reinforcement learning [Arxiv:2109.03445v2]; 2022.
- Borkar VS. Stochastic approximation in two time scales. Syst Control Lett. 1997;29(5):291–294.
- Tadić VB. Almost sure convergence of two time-scale stochastic approximation algorithms. In: Proceedings of the American Control Conference, Boston, Vol. 4; 2004. p. 3802–3807.
- Lakshminarayanan C, Bhatnagar S. A stability criterion for two timescale stochastic approximation schemes. Automatica. 2017;79:108–114.
- Konda VR, Borkar VS. Actor-critic learning algorithms for Markov decision processes. SIAM J Control Optim. 1999;38(1):94–123.
- Konda VR, Tsitsiklis JN. Actor-critic algorithms. In: Neural information processing systems (NIPS1999); 1999. p. 1008–1014.
- Vidyasagar M. Convergence of stochastic approximation via martingale and converse Lyapunov methods [Arxiv:2205.01303v1]; 2022.
- Vidyasagar M. Nonlinear systems analysis (SIAM classics series). Soc Ind Appl Math SIAM; 2002;42.
- Hahn W. Stability of motion. Springer-Verlag; 1967.
- Khalil HK. Nonlinear systems. 3rd ed. Prentice Hall; 2002.
- Durrett R. Probability: theory and examples. 5th ed. Cambridge University Press; 2019.
- Gladyshev EG. On stochastic approximation. Theory Probab Appl. 1965;X(2):275–278.
- Borkar VS, Meyn SP. The O.D.E. method for convergence of stochastic approximation and reinforcement learning. SIAM J Control Optim. 2000;38:447–469.
- Tsitsiklis JN. NP-hardness of checking the unichain condition in average cost MDPs. Oper Res Lett. 2007;35:319–323.
- Sutton RS, McAllester D, Singh S, et al. Policy gradient methods for reinforcement learning with function approximation. In: Advances in neural information processing systems 12 (proceedings of the 1999 conference), Denver: MIT Press; 2000. p. 1057–1063.
- Marbach P, Tsitsiklis JN. Simulation-based optimization of Markov reward processes. IEEE Trans Autom Contr. 2001;46(2):191–209.
- Konda V, Tsitsiklis J. On actor-critic algorithms. SIAM J Control Optim. 2003;42(4):1143–1166.
- Chen Z, Maguluri ST, Shakkottai S, et al. Finite-sample analysis of contractive stochastic approximation using smooth convex envelopes [Arxiv:2002.00874v4]; 2020.
- Chen Z, Maguluri ST, Shakkottai S, et al. Finite-sample analysis of off-policy TD-learning via generalized bellman operators [Arxiv:2106.12729v1]; 2021.