
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
To test whether error-driven implicit learning can explain cross-language structural priming, we implemented three different models of bilingual sentence production: Spanish-English, verb-final Dutch-English, and verb-medial Dutch-English. With these models, we conducted simulation experiments that all revealed clear and strong cross-language priming effects. One of these experiments included structures with different word order between the two languages. This enabled us to distinguish between the error-driven learning account of structural priming and an alternative hybrid account which predicts that identical word order is required for cross-language priming. Cross-language priming did occur in our model between structures with different word order. This is in line with results from behavioural experiments. The results of the three experiments reveal varying degrees of evidence for stronger within-language priming than cross-language priming. This is consistent with results from behavioural studies. Overall, our findings support the viability of error-driven implicit learning as an account of cross-language structural priming.
1. Introduction
1.1. Structural priming
Structural priming is the tendency of speakers to reuse syntactic structures that they have previously encountered. In the study by Bock (Citation1986) that introduced structural priming as an experimental paradigm, participants were more likely to use a passive target sentence (e.g. “The church is being struck by lightning”) after repeating a passive sentence (“The referee was punched by one of the fans”) than after repeating an active prime sentence (“One of the fans punched the referee”). If one sentence primes another, even without lexical overlap between the two sentences, then these sentences share some structural aspect of their mental representation.
Structural priming is not only a real-life discourse phenomenon that speakers use to adapt to their dialogue partners linguistically but also forms a research tool: Careful investigation of the structural relations between sentences that prime each other has provided insight into syntactic representations without relying on speakers' explicit notions of grammaticality (Branigan & Pickering, Citation2017). Structural priming also occurs between different languages (Hartsuiker et al., Citation2004; Huttenlocher et al., Citation2004; Meijer & Fox Tree, Citation2003). Investigating these cross-language priming effects can give insight into how syntactic representations in different languages relate to each other in multilingual speakers.
Error-driven implicit learning is one of the proposed accounts of within-language structural priming. This account has been implemented in the Dual-path model of sentence production (see Section 1.2) (Chang et al., Citation2006). To verify whether error-driven implicit learning can also account for cross-language priming, we implement three different bilingual Dual-path models, and we test whether these models can simulate results from behavioural priming experiments.
1.1.1. Error-driven implicit learning accounts of structural priming
According to an implicit learning account of structural priming (Chang et al., Citation2006, Citation2000), error-driven learning causes changes in the extent to which different syntactic structures are expected to occur. In this account, upcoming words are predicted during sentence comprehension. When a word is predicted incorrectly during the processing of a prime sentence, prediction error is used to strengthen the connections associated with the prime's syntactic structure, which makes that structure's occurrence more expected. This learning mechanism affects the production of the target sentence as it increases the likelihood of producing the same structure. In this account, structural priming is, therefore, regarded as a long-lasting and cumulative effect. The same error-driven learning mechanism that is responsible for syntax acquisition is also responsible for structural priming in this account.
Support for this view on structural priming has been provided in a large number of studies that have demonstrated that this type of priming can last over time and persists over the processing of other sentences, both in within-language priming (Bock & Griffin, Citation2000; Boyland & Anderson, Citation1998; Branigan et al., Citation2000; Hartsuiker & Kolk, Citation1998; Huttenlocher et al., Citation2004; Saffran & Martin, Citation1997) and in cross-language priming (Kootstra & Doedens, Citation2016).
Support for the error-driven learning mechanism as an account of the acquisition of syntax comes from a behavioural study by Peter et al. (Citation2015) on how children develop knowledge of verb argument structure, and from a priming study by Fazekas et al. (Citation2020) which demonstrated that exposure to the same syntactic structure leads to faster learning in children if this structure was presented in a surprising context rather than a predictable context.
1.1.2. Activation-based accounts of structural priming
An alternative to the error-driven implicit learning account explains structural priming as the result of residual activation. In the verbal model introduced by Pickering and Branigan (Citation1998), the residual activation of syntactic representations and combinatorial nodes makes these representations and nodes easier to access and thus leads to repeated use of particular syntactic representations. In activation-based accounts such as this, priming is regarded as a short-term effect that is not cumulative and that does not last across different experimental trials.
A bilingual version of the residual activation account was proposed by Hartsuiker et al. (Citation2004). According to this account, syntactic representations can be fully shared between languages. Findings of equally strong cross-language and within-language priming have been interpreted as strong support for this shared syntax account (Kantola & van Gompel, Citation2011). In other respects, the current verbal, activation-based models are unfortunately under-specified. For example, whether identical word order in prime and target sentences in different languages is necessary for priming (Bernolet et al., Citation2007), depends on the exact architecture of an activation-based account of structural priming. This illustrates a limitation in the usefulness of verbal models as opposed to implemented models. Verbal models allow for a high level of vagueness that is often not immediately apparent. As a consequence, fewer experimental findings can potentially contradict these theoretical accounts. In contrast, the computational implementation of a model forces the researcher to make choices regarding the specifics of the architecture that underlies a theoretical account.
Reitter et al. (Citation2011) implemented a hybrid model that provides an activation-based account of structural priming but also includes learning-based long-term linguistic adaptation. In this model, the abstract hierarchical order of phrases and the surface order in which phrases appear are computed in a single step. For this reason, the model does not predict priming between sentences with different constituent orders, such as prepositional object constructions with the prepositional phrase placed sentence final (e.g. “The driver showed the problem to the mechanic.”) or directly after the verb (“The driver showed the mechanic the problem.”). Since the model does not allow for within-language structural priming between structures with different word orders, it must also predict that such priming does not occur between languages, although the model has never been applied in a bilingual setting.
1.2. The dual-path model
Other, connectionist, cognitive models of monolingual structural priming have been introduced by Chang et al. (Citation2000) and Malhotra (Citation2009). The initial model introduced by Chang et al. (Citation2000) implemented an error-driven implicit learning account of structural priming that was based on the Simple Recurrent Network (SRN; Elman, Citation1990) architecture. Unlike Dual-path, this initial model specifically aimed to model structural priming rather than sentence production in general. As is the case for other purely SRN-based models, it lacked the ability to accurately produce novel sentences. The first version of the Dual-path model (Chang, Citation2002) addressed this limitation. Its architecture enabled the model to acquire syntactic abstractions that gave it the ability to generalise in a symbolic fashion.
Dual-path is a connectionist model that implements an error-driven account of how sentence production is learned implicitly. The first of its two paths is the sequencing system, which is based on the SRN architecture. It learns how words are ordered in a sentence. This is done by predicting the next word in sentences, one word at a time, and adjusting connection weights through back-propagation of error. The second pathway extends the SRN by adding the meaning that is conveyed by a sentence. This pathway allows the model to acquire meaning-to-word-form mappings using the same error-driven learning mechanism.
1.2.1. Applications of dual-path
Dual-path has been used to investigate monolingual structural priming for transitives, datives, and for the theme-locative alternation (e.g. “The man sprayed water on the wall.” vs. “The man sprayed the wall with water.”) in English (Chang et al., Citation2006) and for datives in German (Chang et al., Citation2015). Both of these studies demonstrated structural priming in the model, and thus provide evidence for the viability of error-driven implicit learning as an account of structural priming in the monolingual case. In addition, Dual-path has been used to successfully simulate a large variety of experimental and corpus-based findings. In a study by Chang (Citation2009), a learning-based account of word order phenomena such as heavy noun phrase (NP) shift was established by comparing how word order is learned in models of monolingual speakers of Japanese or English.
Fitz et al. (Citation2011) have also used Dual-path to provide a learning-based account of the acquisition and processing patterns of different types of relative clauses in English. Furthermore, Dual-path was part of a distributional learning account of the acquisition of the theme-locative alternation proposed by Twomey et al. (Citation2013). A model based on Dual-path then showed how children could recover from early overgeneralisation through distributional learning of verb classes. In the context of the debate on which aspects of our linguistic knowledge are learned from experience and which are innate, Fitz and Chang (Citation2017) used Dual-path to simulate how the rule is acquired that derives yes-no questions (e.g. “Is the boy that is jumping happy?”) from complex declarative sentences (e.g. “The boy that is jumping is happy.”). Most recently, the Dual-path model has been used to simulate experimental data from several studies on event-related potentials (ERPs), namely the N400 and the P600, that have been linked to language processing (Fitz & Chang, Citation2019). The study provides support for an account of ERPs as a reflection of a learning process that is based on the propagation of prediction error.
Taken together, the work on Dual-path shows that an error-driven implicit learning model can bring together language acquisition and sentence processing in one coherent account.
1.2.2. Bilingual dual-path models
The Dual-path model has also demonstrated the potential to account for experimental data from various second-language (L2) acquisition and production studies. A Korean-English bilingual Dual-path model was used to examine the interaction between the effect of the age of acquisition (AoA) and input factors, such as length of exposure, on second-language sentence production (Janciauskas & Chang, Citation2018). The model reproduced human L2 acquisition patterns in showing a negative effect of AoA on L2 learning.
Tsoukala et al. (Citation2017) investigated errors made by Spanish learners of English in the use of the pronouns “he” and “she” (e.g. “He's pregnant.”). The modelling results showed that these errors could occur because Spanish, unlike English, is a pro-drop language, in which pronouns in subject position are often omitted.
Tsoukala et al. (Citation2021) demonstrated that the model could produce code-switches (e.g. “the short boy shows a libro a un hermano.”), even in the absence of code-switching in the training input to the model. In addition, the model reproduced a particular code-switching pattern that has been observed among Spanish-English bilinguals (Tsoukala et al., Citation2021).
These studies show that the Dual-path model can account for a range of phenomena in bilingual language production. So far, however, no studies have demonstrated cross-language structural priming in the model, or in any other implemented model.
1.3. Cross-language structural priming
Over 15 years ago, a number of studies showed that structural priming can occur between two different languages (Hartsuiker et al., Citation2004; Loebell & Bock, Citation2003; Meijer & Fox Tree, Citation2003). These findings provide evidence that syntactic representations can be shared between languages, and they thus increase support for the abstract nature of those representations.
Cross-language structural priming effects have been observed in adults from a wide age range (e.g. Loebell & Bock, Citation2003), in adolescents (e.g. Favier et al., Citation2019; Kutasi et al., Citation2018), and in children (e.g. Hsin et al., Citation2013; Vasilyeva et al., Citation2010). Most of the experiments in cross-language priming include English as the prime and/or target language. The only exceptions to this are, to the best of our knowledge, the study by Cai et al. (Citation2011) that involved Mandarin-Cantonese bilinguals, the study by Kootstra and Şahin (Citation2018) that involved Papiamento-Dutch bilinguals, and the study by Mercan and Simonsen (Citation2019) that included Norwegian-Turkish bilinguals. Nevertheless, a wide variety of other languages has been studied in cross-language syntactic priming experiments, including German (e.g. Loebell & Bock, Citation2003), Spanish (e.g. Bock, Citation1986), Dutch (e.g. Desmet & Declercq, Citation2006), Greek (e.g. Salamoura & Williams, Citation2007), Korean (e.g. Shin & Christianson, Citation2009), Polish (Fleischer et al., Citation2012), Irish (Favier et al., Citation2019), Scottish Gaelic (Kutasi et al., Citation2018), and Swedish (Kantola & van Gompel, Citation2011). So far only Hartsuiker et al. (Citation2016) and Huang et al. (Citation2019) have studied cross-language priming in trilinguals (L1 Dutch – L2s English and either French or German; and L1 Mandarin – L2s Cantonese and English, respectively).
The most common syntactic constructions under investigation in cross-language priming studies are datives (e.g. “The woman handed the screaming baby to her husband.” / “The woman handed her husband the screaming baby.”) (e.g. Loebell & Bock, Citation2003; Meijer & Fox Tree, Citation2003) and transitives (e.g. “Many people attended the concert.” / “The concert was attended by many people.”) (e.g. Hartsuiker et al., Citation2004; Loebell & Bock, Citation2003). Other structures that have been investigated are relative clauses (e.g. “someone shot the servants of the actress who was / were on the balcony”) (e.g. Desmet & Declercq, Citation2006; Kidd et al., Citation2015), genitives (e.g. “the shirt of the boy” / “the boy's shirt”) (Bernolet et al., Citation2013), noun phrases (e.g. “the red shark” / “the shark that is red”) (Bernolet et al., Citation2007; Hsin et al., Citation2013), and subject-to-object raising constructions (e.g. “Mary believes Jerry to be trustworthy” / “Mary believes that Jerry is trustworthy”) (Song & Do, Citation2018). While most of these studies investigate structural priming in sentence production, several studies have also demonstrated such cross-language priming effects in sentence comprehension (Kidd et al., Citation2015; Weber & Indefrey, Citation2009). The majority of the work on structural priming between languages has tested priming in spoken language. Nevertheless, similar priming effects have also been demonstrated in experiments where participants produced written language (Desmet & Declercq, Citation2006; Favier et al., Citation2019; Hartsuiker et al., Citation2016; Kantola & van Gompel, Citation2011).
A considerable body of work on cross-language structural priming confirms that syntax can be shared between languages. Nonetheless, conflicting results on a number of issues remain to be fully explained. Two of these issues relate to the way in which syntactic structures are shared between languages: the relative strength of within-language and cross-language structural priming and the dependency of cross-language structural priming on identical word order between languages.
1.3.1. Are within-language and cross-language structural priming equally strong?
Several studies have found no significant difference between the strength of within-language and cross-language structural priming (Hartsuiker et al., Citation2016; Kantola & van Gompel, Citation2011; Schoonbaert et al., Citation2007). In contrast, Cai et al. (Citation2011) and Bernolet et al. (Citation2013) have provided experimental evidence for a stronger within-language than cross-language structural priming effect. Travis et al. (Citation2017) found a similar difference in a corpus study, where the within-language priming effect was not only stronger but also longer-lived than the cross-language effect.
The quantitative difference in the experimental findings was accounted for by Bernolet et al. (Citation2013) under the assumption that less proficient speakers of the second language (L2) have not yet developed syntactic representations that are shared across languages, or at least not for the syntactic structure under investigation. This would suggest that a prerequisite for equally strong within- and cross-language structural priming is that speakers are highly proficient in both languages.
1.3.2. Does cross-language structural priming require structures that have identical word order?
Conflicting results have been reported on the possibility of cross-language priming between structures that have different word order. Priming was shown to occur between verb-final passives in Dutch (e.g. “De duiker werd door de piraat opgetild.”; literally: “The diver was by the pirate lifted.”) and verb-medial passives in English (e.g. “The boxer was chased by the nun.”) (Bernolet et al., Citation2009). Priming has also been demonstrated between transitives in Chinese and English (Chen et al., Citation2013), between object–verb–subject order sentences in Polish and passives in English (Fleischer et al., Citation2012), and between datives in Korean and English (Shin & Christianson, Citation2009), even though syntactic structures involved in these alternations do not have identical word order between the prime and target languages. On the other hand, no such priming effects were found between transitives in German and English (Loebell & Bock, Citation2003), between datives in German and English (Jacob et al., Citation2017), and between relative clauses in Dutch and English (Bernolet et al., Citation2007), where word order is also different between languages.
While the contrasting findings on the difference between cross-language and within-language structural priming seem to be explainable by taking into account proficiency and language dominance, no such overall explanation has been offered for the different results on the dependency of cross-language structural priming on shared word order.
1.4. The present work
In the present work, we investigate whether implicit learning can account for cross-language priming. We combine the monolingual account of structural priming with the implemented bilingual Dual-Path model of sentence production. We train instances of the model which we then use as participants in simulated experiments. Our simulated participants differ from each other because they all have different random initial weights and their own unique language input. This language input also has a small variation in the balance between the two languages. In addition, we create differences between simulated participants by varying model parameters such as the number of units in some of the layers.
In our first simulation experiment, we determine whether structural priming can occur in the model between transitives in artificial versions of Spanish and English. In the second experiment, we investigate whether cross-language structural priming in the model is dependent on identical word order in the syntactic structures in question. We do this by ascertaining whether priming occurs between Dutch with verb-final passives and English with verb-medial passives and comparing its strength to that of priming between Dutch and English that both have verb-medial passives.
We find that priming does indeed occur between all language pairs, and we show that priming tends to be stronger within than between languages.
2. General method
In this section, we describe the aspects of the method that apply to all the experiments on which we report.
2.1. Artificial languages
All artificial languages that we used comprised the same nine sentence types: Animate intransitive, Animate with-intransitive, Inanimate intransitive, Locative, Transitive (in active or passive form), Cause-motion, Benefactive transitive, State-change, and Locative alternation (in location-theme (LT) or theme-location (TL) form). These are the same sentence types that were used by Chang et al. (Citation2006), with two exceptions: Chang et al. (Citation2006) also included Transfer datives and Benefactive datives.
In the model input, sentences were paired with messages that consist of three parts that represent the conceptual structure of the target sentence. The first part is made up of thematic roles that are linked to concepts. The second part of the message contains event semantic information. The third part of the message contains information about the target language for the sentence.
The thematic roles used in the messages follow the so-called XYZ role encoding scheme introduced by Chang (Citation2002). In terms of traditional thematic roles, the X role is assigned to agents, causes, and stimuli, the Y role maps to patients, themes and experiencers, and the Z role to goals, locations, recipients, and benefactors. However, the XYZ format differs from conventional thematic role assignments in that the Y role is used for both intransitive agents as well as transitive patients.
The message for Example 1 (see below), for example, links the thematic role X to the noun concept FATHER, the thematic role ACTION-LINKING to the verb concept BREAK, and the thematic role Y to the noun concept BOTTLE. The event semantic part of the message sets the tense as PAST and the aspect as SIMPLE and also lists the required roles for the message as X, Y, and ACTION-LINKING. Finally, the third part of the message sets the target language to Spanish. Noun concepts are accompanied by attributes that determine how the noun is realised as a noun phrase. Nouns can be expressed as pronouns and can have a definite or indefinite article. In the example, “a bottle” is therefore encoded in the message as “Y = indef, BOTTLE”, while “the father” is encoded as “X = def, FATHER”. In addition, a noun phrase can contain an adjective. The noun phrase “a big bottle”, for instance, could be encoded as “Y = indef, BOTTLE; Y-MOD = BIG”.
| (1) | Spanish Active: el padre romper -pas una botella.
| ||||
| (2) | English Active: the father break -pst a bottle.
| ||||
| (3) | Spanish Passive: una botella fue romper -prf por el padre.
| ||||
| (4) | English Passive: a bottle was break -par by the father.
| ||||
Messages that can be expressed using two different syntactic structures were given a strong bias towards one of those structures. This was achieved by creating differences in activation based on how each structure emphasises thematic roles in the sentence. Biasing towards an active sentence (Examples 1 and 2 above), for example, was done by giving the agent a higher activation (X:1) than the patient (Y:0.5 or Y:0.75). In the same way, a bias towards a passive sentence (Examples 3 and 4 above) was achieved with a higher activation for the patient (Y:1), than for the agent (X:0.5 or X:0.75).
In our message semantics, only singular entities, properties, and actions (that are expressed by (pro)nouns, adjectives, and verbs, respectively) were used. Actions and entities were always in third person form. Because of this, our artificial languages did not have any markers for number, in contrast with the artificial English used by Chang et al. (Citation2006), which had a plural noun marker and a singular verb marker.
2.2. Model
visualises the overall architecture of the model. The two pathways in the model meet at the hidden layer and at the output layer, where the information from both pathways is integrated. The model produces the word that has the highest activation in the output layer and this word then becomes input for the prediction of the next word in the sentence (see the dotted line in ). The model learns to convert a message into a sentence in the artificial language by predicting the sentence word by word. This learning is done by means of the error-driven implicit learning mechanism as described in Sections 1.1.1 and 1.2.
Figure 1. Bilingual Dual-path, the model used in our Spanish-English priming experiment. The model is an SRN-based model (the lower path, via the “compress” layers) that is augmented with a semantic stream (upper path) that contains information about concepts, thematic roles, event semantics, and the target language. The number of units per layer for the model used in Experiment 1 is shown in parentheses. The numbers of units for the hidden and compress layers vary across simulations.
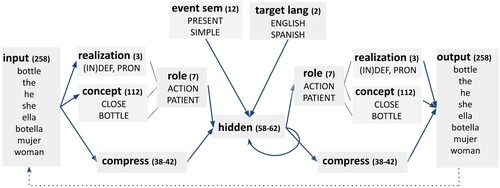
A difference between the Dual-path architecture and other Recurrent Neural Networks is that the network has connections with fixed weights between concepts and roles of the message to be expressed (represented by lines instead of arrows in ). This allows dynamic binding between roles and concepts and thus enables the model to generalise and to produce words in novel roles (Chang, Citation2002).
To simulate participants in a cross-language priming experiment, we trained the Bilingual version of the Dual-path model (Tsoukala et al., Citation2017)Footnote1 to simulate simultaneous Spanish-English or Dutch-English bilinguals, who start acquiring both languages from infancy.
The Bilingual Dual-path model is a modified version of the original Dual-path model (Chang, Citation2002; Chang et al., Citation2006). The model was made bilingual by exposing it to two languages and by adding a target language layer in the meaning path that determines the intended output language. Apart from this, there are a number of minor architectural differences between the original Dual-path model and the bilingual version that we used. As is shown in , the implementation used in our experiments had a realisation layer with separate units for realising a noun phrase with a pronoun, a definite article, or an indefinite article. The original Dual-path model, in contrast, had a single unit with different levels of activation for the each of the three possible realisations of a noun phrase (Chang et al., Citation2006). The two implementations of the model also differ slightly in the activation functions that are used. The original model used the tanh activation function for all layers, except for the output and comprehended role layers, which used softmax. The implementation by Tsoukala et al. (Citation2017), however, also used softmax activation for the predicted role layer. This helped the model to overcome a difficulty it had with learning the correct gender and definiteness for articles (e.g. “a” vs. “the”). Finally, unlike the original Dual-path model, our implementation did not have a layer that enhances the model's memory for the roles it has produced by keeping a running average of those activations.
Our models had a number of hidden layer units that were sampled from a uniform distribution between 58 and 62, and a number of compress layer units sampled from a uniform distribution between 38 and 42. The fixed weight value for concept–role connections was sampled from a uniform distribution between 13 and 17. The sentences were approximately equally divided over the two languages, where the language percentage of English was sampled from a uniform distribution between 48 to 52% and the rest was Spanish. Other than this, we used the model's default settings.
2.3. Training and testing input
For each simulated participant, a set of 8,000 unique message-sentence pairs was randomly generated and different random initial weights were used. 80% of these sentences were used for training, while 20% were set aside for testing the accuracy of the model. This means that there was no overlap between the training and test sets. This contrasts with accuracy testing in Chang et al. (Citation2006), where the same test set was used for all trained models, and there was a small overlap (less than 1%) between training and test. We did follow Chang et al. (Citation2006) in excluding the message from 25% of training pairs. This increases the syntactic nature of the representations that the model learns (Chang et al., Citation2015). The models iterated over their training sets 16 times. After each of these 16 epochs, model accuracy was tested using the test set. The order of the training set was randomised at the beginning of each epoch. We modelled balanced bilingual speakers by training the model on both languages from the beginning and on approximately equal numbers of sentences in each language.
Because our aim was to verify the possibility of structural priming between different languages, we designed the training input to maximise the likelihood of revealing an effect. If a structure is produced very frequently irrespective of priming, ceiling effects might cause the priming effect to become smaller and therefore harder to detect. We addressed this issue by using balanced frequencies of the structures under investigation. This means that actives and passives occurred with the same frequency in the training input we provided the model.
2.4. Priming experiment
Independent of the training and test sets, a single set of experimental trials was generated that was used to perform the priming experiment on all of the simulated participants. Each trial consisted of a combination of a unique prime sentence and a unique target message that did not have any semantic overlap in terms of their verb, agent, and patient. Whereas the messages in the training data had activations of 0.5 or 0.75 for the de-emphasised role, we gave the target messages in the priming experiment only the weaker bias, by always giving the de-emphasised roles an activation of 0.75. In this way, we follow Chang et al. (Citation2006) in simulating that stimuli in structural priming experiments generally do not have a strong bias towards one syntactic structure over another.
With two Language Combination conditions (Cross-language and Within-language) and two Prime Language conditions, we had four possible combinations of prime and target language, for example: English-English, Spanish-Spanish, Spanish-English, and English-Spanish. We had equal numbers of each of these four language combinations, which in turn means that there were equal numbers of within- and cross-language trials. We also had equal numbers of trials with active and passive primes, and equal numbers of trials with active- and passive-bias target messages. The two levels for Prime Structure, Language Combination, Prime Language, and Target-message Bias combine for a total of 16 different conditions. We had 50 prime-target combinations that all occurred as each of the 16 different conditions. This means that each experiment consisted of 800 trials.
The priming experiment was performed on the models after 16 training epochs. As was done in Chang et al. (Citation2006) and Chang et al. (Citation2015), we presented the models with prime sentences without a message, and with learning turned on in the model. After each prime, a response was elicited from the model by presenting it with a target message.
We used a learning rate of 0.2 during the priming experiment, which was slightly higher than the learning rate of 0.15 used by Chang et al. (Citation2006) but considerably lower than the learning rate of 0.6 used by Chang et al. (Citation2015). According to Chang et al. (Citation2015), prediction error in an artificial language is smaller than in natural language because of its smaller size and complexity. This reduced prediction error can lead to smaller priming effects. Because our artificial languages have fewer syntactic structures than those of Chang et al. (Citation2006) but many more structures than Chang et al. (Citation2015), we used a learning rate that was closer to Chang et al. (Citation2006).
After each trial, the connection weights were reset to the values they had before starting the priming experiment. The state in which the model encountered each trial was thus the same for all of the trials. Hence, there was no between-trial priming or any other learning effects during the experiment. This means that the order of the trials did not need to be (pseudo-)randomised across simulated participants.
3. Spanish – English (Experiment 1)
3.1. Research questions
We perform a computational modelling experiment to further test the viability of error-driven implicit learning as an account of structural priming in general and of cross-language structural priming specifically. We simulate cross- and within-language priming of actives and passives, using artificial versions of Spanish and English. Furthermore, we investigate if cross-language priming differs quantitatively from within-language priming in the model.
We expect cross-language structural priming to occur because it has been demonstrated in adults by Hartsuiker et al. (Citation2004), and in children by Vasilyeva et al. (Citation2010), for the languages and the syntactic structures used in the present experiment. Additionally, as mentioned above, Chang et al. (Citation2006) have shown that within-language priming of English transitives (and other syntactic structures) occurs in the model. The analyses in that study revealed that the model builds syntactic representations that largely abstract away from lexical items. The model does this in a way that is mostly consistent with results from behavioural studies. We expect that the model's syntactic representations will similarly abstract away from the target language and will, therefore, enable cross-language structural priming in the model in line with findings from behavioural studies. Finally, a bilingual version of the Dual-path model has demonstrated the ability to code-switch (Tsoukala et al., Citation2021), and code-switching has been interpreted as an indication that syntax is shared between languages (Kootstra et al., Citation2010; Loebell & Bock, Citation2003). This notion of shared syntactic representations is also what should make cross-language structural priming possible.
Assuming the model does display cross-language structural priming, we have no strong expectation of whether or not it will differ in strength from within-language priming, for two reasons. Firstly, as mentioned in the Introduction, an error-driven implicit learning account does not make any prediction about a difference in the strength of cross-language versus within-language priming. Secondly, as was also described in the Introduction, some behavioural experiments reveal that within-language priming is significantly stronger than cross-language priming, while others do not find a significant difference between the two types of priming. While we do not have a clear expectation, we aim to meet the proficiency prerequisite for equivalent within- and cross-language priming prerequisite that was suggested by Bernolet et al. (Citation2013) by simulating balanced bilingual speakers, who are equally proficient in both languages. If our results do reveal a difference, we expect within-language priming to be stronger than cross-language priming.
3.2. Method
3.2.1. Artificial languages
gives examples of each of the sentence types that were used in Experiment 1Footnote2.
Table 1. Sentence types in the artificial language input for the Spanish-English model.
The two languages together have 258 unique lexical items. In addition to nouns, verbs, adjectives, determiners, and prepositions, these lexical items include inflectional morphemes such as a past tense marker (Spanish: “-pas”; English: “-pst”) and a past participle marker (Spanish: “-prf”; English: “-par”). Spanish has 135 items while English has 126. These include one item that occurred in both languages: the period “.”. Each of the two languages has 44 nouns, 4 pronouns, 51 verbs, 12 prepositions, and 3 inflectional morphemes. English had 2 determiners, 6 adjectives, and 3 auxiliary verbs, while Spanish had 4 determinersFootnote3, 11 adjectives, and 5 auxiliary verbs.
3.2.2. Simulated participants
There was considerable variability in how successfully the simulated participants learned the artificial languages. We, therefore, trained 120 models and selected the 80 simulated participants with the highest meaning accuracy (i.e. percentage of grammatically correct sentences that convey the target message without any additions, over all test sentences). The accuracy scores for these models varied from 73.30% to 91.55%, with a mean of 77.72%. The percentage of grammatically correct sentences for these simulated participants varied from 95.10% to 100.00%, with a mean of 99.42%. Supplementary analyses of the experiments in the present work include all 120 simulated participants (see Appendix A in the online version of this document). The supplementary analyses reveal the same patterns of results as the analyses in the main article.
3.3. Results
Our analysis only included those responses that correctly conveyed the target message, either with an active or a passive structure. However, we disregarded errors involving definiteness of articles or missing periods. We included 72.82% of the responses on cross-language trials and 68.78% of responses on within-language trials.
3.3.1. Descriptive statistics
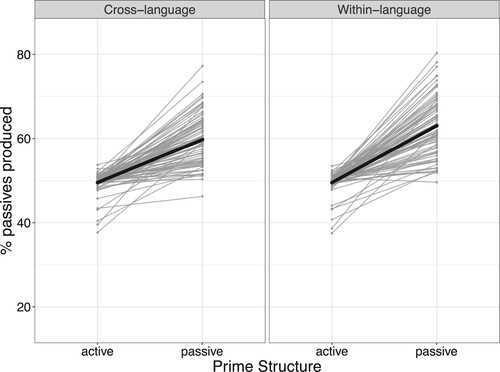
On cross-language trials, 59.75% of sentences that simulated participants produced were passives after a passive prime, while 49.57% of sentences were passives after an active prime. On within-language trials, 63.07% of the produced sentences were passives after a passive prime, whereas 49.55% of sentences were passives after an active prime. visualises the priming effect, in that there were more passive responses after passive primes than after active primes, for both Language Combination conditions. The plot also shows that the effect was similar for cross-language and within-language priming, with a somewhat stronger effect for within-language trials.
Figure 2. Percentage of responses in Experiment 1 (Spanish-English) that had a passive structure after either an active prime or a passive prime, for cross-language trials (on the left) or within-language trials (on the right). The thick black lines visualise the priming effect across all analysed trials by connecting the percentage of passive responses after active primes to the percentage of passive responses after passive primes. The thin grey lines show the same for each individual simulated participant.
3.3.2. Pre-registered analysis
As pre-registeredFootnote4, we analysedFootnote5 the data from our experiment with a Bayesian logistic mixed-effects model, with a logit link function, using the function brm from the package brms (version 2.12.0; Bürkner, Citation2017, Citation2018) in R (version 3.5.1; R Core Team, Citation2018). The model predicts a binary dependent variable, Is Passive, that indicates whether the sentence structure that the model produced was passive (1), or active (0). The predictors of interest were Language Combination (Cross-language = 0, Within-language = 1), Prime Structure (Active , Passive = 0.5), and their interaction. In addition, the model includes two other contrast-coded predictors: Target-message Bias (Active
, Passive
) and Prime Language (English
, Spanish = 0.5). Because our main interest is in cross-language priming, Language Combination was dummy-coded with Cross-language as the reference level. The inclusion of the interaction between Language Combination and Prime Structure means that we can then interpret the estimate of the Prime Structure predictor at that reference level of Language Combination. The other predictors were contrast-coded since they lacked a meaningful reference level in the context of our research questions. We fit random intercepts for items and simulated participants, as well as by-participant random slopes for Language Combination, Prime Structure, and their interactionFootnote6. We did not include correlations between random effects.
Regularising priors were used in all our models, which give a minimal amount of information with the objective of yielding stable inferences. Prior means were 0, and did thus not bias towards specific effects. The only exception to this was the Target-message Bias predictor for which we used a prior with a Gamma distribution to exclude negative values. The standard deviations for the priors that we used for the predictors are based on the effect sizes that resulted from an earlier version of the experiment.
The regression analysis results are summarised in . The positive estimate for the Prime Structure predictor (Estimate of the log-odds ratio = 3.08, 95% CrI = [2.65, 3.50]) indicates that more passives were produced when the Prime Structure was passive than when it was active. The estimate has a credible interval far from zero. This means that there was a clear priming effect at the reference level (i.e. cross-language) of the Language Combination predictor. We interpret this as strong evidence for cross-language priming in the Dual-path model. The top panel of shows the posterior distribution of the estimate for the Prime Structure predictor.
Figure 3. Posterior distributions of the estimate for the Prime Structure predictor (top) and of the estimate for the interaction between Language Combination and Prime Structure (bottom) in Experiment 1 (Spanish-English).
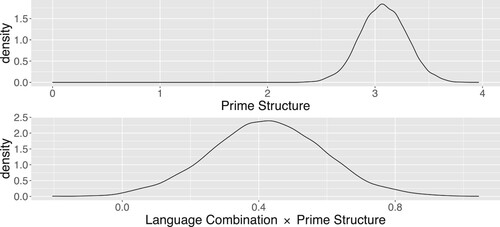
Table 2. Summary of the fixed effects in the Bayesian logistic mixed-effects model () for Experiment 1.
The estimate for the interaction between Language Combination and Prime Structure (Estimate of the ratio of log-odds ratios = 0.42, 95% CrI = [0.09, 0.76]) with a credible interval that only includes positive values, provides strong evidence for a difference between within-language and cross-language priming. This is visualised in the bottom panel of , which shows the posterior distribution of the interaction. The positive value of the estimate indicates that the priming effect was stronger for within-language than for cross-language trials since the log-odds ratio that compares the production of passives after passive or active primes on within-language trails was larger than the log-odds ratio that compares the production of passives after passive or active primes on cross-language trials.
3.4. Discussion
The results of Experiment 1 reveal a clear and strong cross-language structural priming effect. We thus provide evidence for the viability of implicit learning as an account of cross-language structural priming. In turn, our finding provides support for the implicit learning model implemented in Dual-path, as an account of structural priming in general. We should note, however, that this finding does not provide evidence against other implemented models of structural priming. The hybrid model introduced by Reitter et al. (Citation2011), for example, also predicts cross-language structural priming to occur. Fortunately, a way to empirically distinguish between this hybrid account and the Dual-path account is available. As explained in Section 1.1.2, the hybrid account predicts that priming will not occur between structures in different languages that do not have the same word order (Reitter et al., Citation2011). The Dual-path account, on the other hand, does not rule out such a priming effect. In our next experiment, we investigate if structural priming in our model requires identical word order by testing whether priming can occur between Dutch verb-final passives and English verb-medial passives.
4. Verb-final Dutch – English (Experiment 2a) and verb-medial Dutch – English (Experiment 2b).
4.1. Introduction
In Experiment 1, we demonstrated that priming of transitives occurs between Spanish and English. Both actives and passives have the same word order between these languages. This is not the case for the combination of Dutch and English. While actives always have identical word order across these two languages, passives do not, because Dutch has more flexible word order than English. In passive sentences, the participle verb can be placed either before (1) or after (2) the agent noun. While priming between these Dutch passives and passives in English has been demonstrated experimentally, it remains controversial how structural priming depends overall on surface word order.
| (1) | De kerk wordt getroffen door de bliksem. (The church is struck by lightning) | ||||
| (2) | De kerk wordt door de bliksem getroffen. (The church is by lightning struck) | ||||
4.1.1. Evidence for cross-language structural priming between sentences with different word order
Several studies have provided evidence for priming between different languages for syntactic structures without identical word order. Bernolet et al. (Citation2009) have shown that priming occurs between Dutch and English, not only for those passive constructions that are the same between the two languages (1) but also for those that differ in terms of word order (2). Their study, however, did reveal the former effect to be stronger than the latter. According to the authors, this indicates that priming is a phenomenon that not only occurs at the level of syntactic structure but also at the level of information structure.
Further evidence for structural priming of transitives without identical word order comes from Chen et al. (Citation2013), who demonstrated that priming occurs between verb-final passives in Chinese (e.g. “杯子被小猫打破了” (“the cup beiFootnote7 the cat break-perfective”)) and verb-medial passives in English (e.g. “The cup was broken by the cat.”). Similar priming effects for a different syntactic construction have been presented by Shin and Christianson (Citation2009). Their results revealed priming of datives with prepositional phrase – noun phrase – verb (PP-NP-V) order in Korean, and datives with noun phrase – prepositional phrase – verb (NP-PP-V) order in English. Finally, priming of English passives was found by Fleischer et al. (Citation2012) from Polish object–verb–subject order sentences (e.g. “Kowboja budzi baletnica.” (“The cowboy [object] wake the ballet dancer [subject].”)).
4.1.2. Evidence against cross-language structural priming between sentences with different word order
Contrasting findings can also be found in the literature. The earliest cross-language priming study to include prime-target pairs that had different word order was performed by Loebell and Bock (Citation2003). They investigated priming between German and English for datives and transitives. Their results show priming effects between the two languages for datives, which have identical word order. However, no such effect was found for transitives, which are verb-final for German but verb-medial for English (e.g. German: “Die Böden werden täglich von dem Hausmeister gereinigt.”; English: “The floors are cleaned daily by the janitor.”). For active primes, there was a non-significantly increased production of active targets after active primes. Surprisingly, there was a (non-significant) decrease in the production of passive sentences after passive primes.
Additionally, Jacob et al. (Citation2017) did not find evidence for cross-language priming of datives between verb-final subordinate clauses in German and verb-medial subordinate clauses in English (e.g. German: “Kristin dachte, dass der Rechtsanwalt den Vertrag an den Klienten schickte.”; English: “Kristin thought that the lawyer sent the contract to the client.”).
Bernolet et al. (Citation2007) also did not find priming of relative clauses between Dutch and English (e.g. Dutch: “de pan die blauw is”; English: “the pan that is blue”), which don't share relative clause word order, while they did find a priming effect for these relative clauses between Dutch and German (e.g. Dutch: “de haai die rood is”; German: “der Hai der rot ist”), which do share relative clause word order.
4.1.3. Interpretation of the available experimental evidence
We interpret the findings of priming between structures with different word order in different languages as convincing evidence for the existence of such an effect. The reports of the absence of these types of effects in other studies provide comparatively weaker evidence to the contrary, since the absence of a significant effect is not proof that an effect does not exist (Vasishth & Nicenboim, Citation2016). Based on the available behavioural results, we therefore conclude that cross-language structural priming can occur in multilingual speakers for structures that do not have identical word order. Nonetheless, the conflicting findings remain to be fully explained. It is therefore unclear under which circumstances cross-language priming for structures with different word order does or does not occur.
4.2. Research questions
We perform a pair of experiments to answer the question whether cross-language priming in an error-driven implicit learning account of structural priming depends on identical word order between languages. We answer this question by determining if cross-language priming can occur between Dutch and English passives in the bilingual Dual-path model. In the first of the two experiments, Experiment 2a, we use a version of Dutch that has verb-final passives, which have a different word order than English passives. In the second experiment, Experiment 2b, we use a version of Dutch that has verb-medial passives, which have a the same word order as English passives. These experiments will also answer the question whether the results of our first experiment generalise to a different language pair. Furthermore, if a priming effect between English and both versions of Dutch is found, our results will give some indication of whether the strength of the priming effect decreases when word order similarity decreases.
According to Reitter et al. (Citation2011), the hybrid account of structural priming that they implemented predicts that cross-language priming is only possible when linear word order is shared between structures. On the other hand, it is not clear what an error-driven implicit learning account predicts for structures that don't share word order. However, in performing our experiment we can establish a prediction on this issue. If our model, as an implementation of the error-driven learning account of structural priming, displays priming between structures with different word order, this would imply that the error-driven learning account (unlike the hybrid account) predicts such priming. In this way, our results might contribute to distinguishing between the two implemented accounts of structural priming.
4.3. Method
4.3.1. Artificial languages
The version of English that we used for Experiment 2a and 2b was the same as for Experiment 1. The artificial versions of Dutch only differ from each other in that all passive Transitive and passive Theme-experiencer sentences, as well as sentences that have progressive or perfect aspect, are verb-final in Experiment 2a (e.g. “de fles wordt door de vader breken -vdw.” (“The bottle is by the father broken.”)) and verb-medial in Experiment 2b (e.g. “de fles wordt breken -vdw door de vader.” (“The bottle is broken by the father.”)).Footnote8.
One of the main differences between Dutch and the languages of Experiment 1 is its gender system. We implement the Dutch syntactic gender system as having two values: common (definite article: “de”) or neuter (definite article: “het”). In contrast with Spanish, syntactic gender in this system does not largely agree with semantic gender. Animate nouns, for example, almost always have common gender, independent of whether they are semantically male (e.g. “de man” (“the man”)) or female (e.g. “de vrouw” (“the woman”)), with only a few exceptions that have neuter gender (e.g. “het meisje” (“the girl”)). It is likely that this makes the Dutch gender system harder to learn for the model than the Spanish gender system. In Spanish, there are three consistent sources of information on the gender of an animate noun. The first two sources are the agreement with determiners and with adjectives based on the syntactic gender of these nouns. The third source is the semantic gender that determines by which pronoun an animate noun is expressed. These sources of information never conflict in the version of Spanish we use. The animate nouns “niña” (“girl”) and “señora” (“lady”), for example should both be accompanied by the female form of determiners and adjectives and are also both expressed by the pronoun “ella” (“she”). In Dutch on the other hand, there are only two sources of information that, in addition, do not always coincide. For example, the animate nouns “meisje” (“girl”) and “vrouw” (“woman”) should be expressed by the same pronoun “zij” (“she”), because they have the same semantic gender but they should be accompanied by different determiners, since they have different syntactic gender.
gives an overview of all the sentence types that occur in the artificial languages we use in the Dutch-English experiments. We included all the sentence types that were used in Experiment 1. The lexicon of the two languages together consisted of 254 unique lexical items. Dutch had 129 items while English had 126. These include the period (“.”) that occurred in both languages. Each language had 44 nouns, 51 verbs, 4 pronouns, 12 prepositions, 6 adjectives, and 3 inflectional morphemes. English had 2 determiners and 3 auxiliary verbs, while Dutch had 3 determiners and 4 auxiliary verbs.
Table 3. Sentence types in the artificial language input for the Dutch-English models.
4.3.2. Simulated participants
As was the case for Experiment 1, there was considerable variability in how successfully the simulated participants learned the artificial languages. Therefore, we again selected the 80 simulated participants with the highest meaning accuracy out of the 120 models that we trained. The accuracy scores for the models in Experiment 2a varied from 64.55% to 94.25%, with a mean of 76.23%, while for the models in Experiment 2b they varied from 76.10% to 98.70%, with a mean of 86.33%. The percentage of grammatically correct sentences varied from 93.50% to 100.00%, with a mean of 98.52% for Experiment 2a, and varied from 94.80% to 100.00%, with a mean of 98.93% for Experiment 2b.
4.4. Results
4.4.1. Descriptive statistics
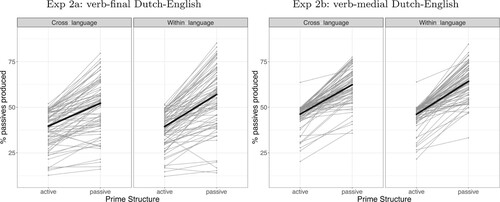
The same exclusion criteria that were used for Experiment 1, were applied to the data from Experiments 2a and 2b. That is, responses that did not correctly convey the target message were excluded from the analysis. Only errors involving definiteness of articles and missing periods were ignored. Based on these exclusion rules, we analysed 69% of the responses on cross-language trials, and 64% of responses on within-language trials from Experiment 2a and 83.20% of the responses on cross-language trials, and 79.85% of responses on within-language trials from Experiment 2b. For cross-language trials in Experiment 2a, 52.25% of sentences that simulated participants produced were passives after a passive prime, while 39.69% of sentences were passives after an active prime. On within-language trials in this experiment, 57.04% of the produced sentences were passives after a passive prime, whereas 39.48% of sentences were passives after an active prime. For cross-language trials in Experiment 2b, 62.41% of sentences that simulated participants produced were passives after a passive prime, while 46.27% of sentences were passives after an active prime. On within-language trials in this experiment, 64.28% of the produced sentences were passives after a passive prime, whereas 46.20% of sentences were passives after an active prime. visualises the overall priming effects in each experiment for both Language Combination conditions, and it shows that the effects were similar across conditions but slightly larger for within-language trials than for cross-language trials.
Figure 4. Percentage of responses in Experiment 2a (verb-final Dutch-English, left panel) and Experiment 2b (verb-medial Dutch-English, right panel) that had a passive structure after either an active or a passive prime, split by within- or cross-language trials. The thick black lines visualises the priming effect across all analysed trials by connecting the percentage of passives responses after active primes to the percentage of passive responses after passive primes. The thin grey lines show the same for each individual simulated participant.
4.4.2. Pre-registered analyses
We performed pre-registered analysesFootnote9 for Experiment 2a and 2b that were based on the analysis that we performed for Experiment 1. Additionally, we analysed the cross-language trials from both experiments together. The results of the regression analyses are summarised in for Experiment 2a, in for Experiment 2b, and in for the combined analysis of cross-language trials from both experiments.
Table 4. Summary of the fixed effects in the Bayesian logistic mixed-effects model () for Experiment 2a (verb-final Dutch-English).
Table 5. Summary of the fixed effects in the Bayesian logistic mixed-effects model () for Experiment 2b (verb-medial Dutch-English).
Table 6. Summary of the fixed effects in the Bayesian logistic mixed-effects model () for the combined analysis of the cross-language trials from Experiment 2a and 2b (verb-final and verb-medial Dutch-English).
Experiment 2a For Experiment 2a (verb-final Dutch-English), the positive estimate for the Prime Structure predictor (Estimate of the log-odds ratio = 2.37, 95% CrI = [2.00, 2.74]) reveals that more passives were produced when the Prime Structure was passive than when it was active. The estimate has a credible interval far from zero. This indicates a clear priming effect at the reference level (i.e. cross-language) of the Language Combination predictor. We interpret this as clear evidence for cross-language priming in the Dual-path model for structures with different word order. The estimate for the interaction between Language Combination and Prime Structure (Estimate of the ratio of log-odds ratios = 0.53, 95% CrI = [0.30, 0.77]) with a credible interval that only includes positive values, indicates that within-language priming was stronger than cross-language priming. The solid lines in visualise the priming effect (top panel) and the interaction (bottom panel). The positive value of the estimate indicates that the priming effect was stronger for within-language than for cross-language trials since the log-odds ratio that compares production of passives after passive or active primes on within-language trails was larger than the log-odds ratio that compares the production of passives after passive or active primes on cross-language trials.
Figure 5. Posterior distributions of the estimates for the Prime Structure predictors (top) and of the interaction between Language Combination and Prime Structure (bottom) for Experiment 2a (verb-final Dutch-English, solid line) and Experiment 2b (verb-medial Dutch-English, dashed line).
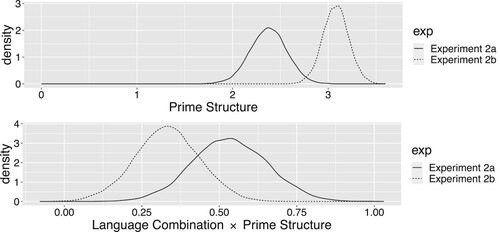
Experiment 2b For Experiment 2a (verb-final Dutch-English), the positive estimate for the Prime Structure predictor (Estimate of the log-odds ratio = 3.08, 95% CrI = [2.81, 3.34]) also reveals that more passives were produced when the Prime Structure was passive than when it was active. The estimate has a credible interval far from zero. This indicates a clear priming effect at the reference level (i.e. cross-language) of the Language Combination predictor. As was the case for Experiment 2a, the estimate for the interaction between Language Combination and Prime Structure (Estimate of the ratio of log-odds ratios = 0.33, 95% CrI = [0.12, 0.54]) with a credible interval that only includes positive values, indicates that within-language priming was stronger than cross-language priming. The dashed lines in visualise the priming effect (top panel) and the interaction (bottom panel). The positive value of the estimate indicates that the priming effect was stronger for within-language than for cross-language trials, since the log-odds ratio that compares production of passives after passive or active primes on within-language trails was larger than the log-odds ratio that compares the production of passives after passive or active primes on cross-language trials.
Combined analysis of cross-language trials This combined analysis differs from the analyses for Experiment 1, 2a and 2b in only three respects. Firstly, the analysis has no Language Combination predictor (and therefore no interaction between that predictor and Prime Structure) because it only includes cross-language trials. Secondly, it includes a Dutch Passive Structure (Verb-final , Verb-medial
) predictor, and its interaction with Prime Structure. Thirdly, there are by-item random slopes for Prime Structure but not for the interaction between Prime Structure and Dutch Passive Structure, since simulated participants learned and produced only one of the two passive structures.
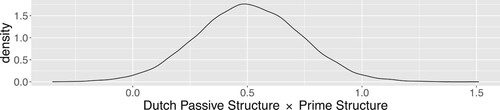
For the analysis of all the cross-language trials from both Experiments 2a and 2b, the 95% credible interval for the estimate of the interaction between Dutch Passive Structure and Prime Structure only includes positive values (Estimate of the ratio of log-odds ratios = 0.51, 95% CrI = [0.06, 0.95]). The positive value of the estimate means that the cross-language priming effect was weaker when passives had a different word order (Experiment 2a with verb-final Dutch passives) than when word order was the same (Experiment 2b with verb-medial Dutch passives), since the log-odds ratio that compares the production of passives after either a passive or an active prime on cross-language trials in Experiment 2a was smaller than the log-odds ratio that compares the production of passives after either a passive or an active prime on cross-language trials in Experiment 2b. The posterior probability of the interaction being positive given the data, confirms this, which is visualised in .
Figure 6. Posterior distribution of the estimate for the interaction between Dutch Passive Structure and Prime Structure.
4.5. Discussion
The results of our pair of priming experiments using Dutch-English models show a clear and strong priming effect between verb-medial English transitives and both verb-final and verb-medial Dutch transitives. We therefore provide support for the viability of implicit learning as an account of experimental findings of cross-language structural priming between structures with different word order. Furthermore, our combined analysis suggests that the priming effect was stronger for structures that share word order (verb-medial Dutch-English), than for structures that do not (verb-final Dutch-English). This is in line with behavioural results reported by Chen et al. (Citation2013).
How can our finding of cross-language priming without identical word order be explained? We speculate that this is possible for the structures under investigation because Dual-path predicts sentences word by word. Connection weights are therefore adjusted after a word is predicted wrongly rather than after an entire sentence is predicted wrongly. If the prime sentence, for example, is a passive sentence that starts with the patient role: “a bottle is broken by the father / een fles wordt door de vader gebroken (a bottle is by the father broken)”, and the model would wrongly predict an active sentence: “the father breaks a bottle / de vader breekt een fles”, then error would occur when the model predicts the noun phrase that expresses the agent role “the father / de vader”. Since learning is turned on in the model during processing of the prime sentence, the connection weights that bias towards a passive sentence would then be strengthened. This, in turn, would make the production of both English and Dutch passives more likely, because both those passives start with a noun phrase that expresses the patient role. Only after that noun phrase does word order differ in verb-medial English and verb-final Dutch passives. Of course, this account of what occurs in the model needs to be verified by inspecting the connection weights in the model.
Our results contribute to distinguishing between the error-driven implicit learning account of priming that is implemented in the Dual-path model and the hybrid account implemented in the model by Reitter et al. (Citation2011). Our model shows priming to occur between transitives with different word order, while their model, in contrast, predicts identical word order to be a requirement for cross-language structural priming.
5. General discussion
Across the three experiments, we see clear and strong within-language priming effects, which confirm earlier findings, and similarly clear and strong cross-language priming effects, that provide further support for error-driven implicit learning as a viable underlying mechanism of structural priming. The finding is consistent with our expectation that the model would learn syntactic representations that abstract away from the target language sufficiently to enable cross-language structural priming.
Experiment 2a revealed priming between structures that do not share word order. This is in line with a number of results from behavioural experiments, and it sets the implicit learning account apart from the hybrid account proposed by Reitter et al. (Citation2011), which predicts that identical word order is a requirement for structural priming.
The analyses of the three experiments also provide support for within-language priming being stronger than cross-language priming. Unsurprisingly, the largest difference is found in Experiment 2a, where the Dutch and English passives did not share word order. This led to a slightly weaker priming effect than in Experiment 2b. A combined analysis of the cross-language trials from these two experiments confirmed this small difference in the strength of the cross-language priming effect between the two Dutch-English experiments. The evidence we find for stronger within-language than cross-language priming is consistent with the results of behavioural studies that also report evidence for such a difference (Bernolet et al., Citation2013; Cai et al., Citation2011). Other studies, however, report results in which the difference is not significant (Hartsuiker et al., Citation2016; Kantola & van Gompel, Citation2011; Schoonbaert et al., Citation2007).
The pattern of results across our three simulated experiments shows that priming can occur for syntactic structures that differ in their target language as well as for those that differ in a part of their word order. In these cases of partial overlap between the syntactic representations involved, priming is weaker compared to cases where syntactic representations are more similar. Note that these results were not explicitly hypothesised and therefore still require further confirmation.
5.1. Limitations and further work
5.1.1. Frequency of actives and passives in the language input
The language input that we used in the present work had balanced numbers of actives and passives. This, of course, is not how these structures are distributed in natural language. However, we think it is unlikely that using unbalanced frequencies of transitives would have led to a different pattern of results in the experiments on which we report here. One of the distinguishing properties of an error-driven account of structural priming is that it predicts an inverse frequency effect (Chang et al., Citation2006). This means that a prime structure that is less frequent results in more prediction error and therefore a stronger priming effect. At the same time, a prime structure that is more frequent results in a weaker priming effect. With equal numbers of active and passive prime sentences in the experiment, we would expect these effects to cancel each other out if transitives had been unbalanced in the language input. That is, a stronger priming effect for infrequent passives and a weaker priming effect for frequent actives would result in approximately the same average effect as was obtained for balanced transitives.
In follow-up experiments, we have addressed this limitation by using a larger number of actives than passives. Preliminary results from these experiments do indeed suggest that similar cross-language structural priming effects occur in the model when transitives are not balanced in the language input.
5.1.2. Is the strength of the priming effect different for different prime structures?
and show that the production of actives after an active prime was approximately at chance level in Experiment 1 and Experiment 2b. Since actives and passives were balanced in the input, this might give the impression that priming did not occur after active primes but only after passive primes. Unfortunately, our experiments were not designed to determine whether this was the case or not. This determination would have been feasible if we had included a baseline condition in our experiments. In their study on cross-language priming of transitives between Dutch and English, Bernolet et al. (Citation2009) used prime sentences consisting of two conjoined noun phrases without a verb as a baseline. It might be interesting to add such a baseline condition to future experiments. We should note, however, that this would not be a straightforward change. Firstly, the use of a baseline is not standard in behavioural research on structural priming, and different baselines are used. This would of course make it difficult to relate our modelling findings to the literature. Secondly, a baseline that is used in a behavioural experiment might not be suitable for our simulated experiments. The artificial languages that we used have far fewer sentence types than natural language. Due to this difference, it is imaginable that a sentence type that does not bias towards either actives or passives in natural language could bias towards one of those structures in the model. Despite these two issues, we think it is worthwhile to investigate the use of a baseline in our simulated experiments.
5.1.3. The influence of proficiency on cross-language structural priming
The next step in our research will be to investigate how proficiency influences the strength of the cross-language priming effect. A proficiency-based account has been proposed to explain the contradicting experimental findings on the difference between cross-language and within-language priming (Bernolet et al., Citation2013; Hartsuiker & Bernolet, Citation2017). Behavioural results suggest that relative proficiency in the two languages involved in cross-language structural priming can influence the strength of the priming effect (Bernolet et al., Citation2013; Kootstra & Doedens, Citation2016). Now that we have established that cross-language priming occurs in the Dual-path model, a fruitful direction for future research will be to explore the relationship between second language proficiency and structural priming between languages in the model. By varying the amount of input that models receive in their two languages or the moment when the L2 input starts (Tsoukala et al., Citation2021), we can simulate different levels of L2 proficiency in the simulated participants. In this way, we can investigate the influence that L2 proficiency might have on the strength of cross-language priming and therefore on the difference between cross-language and within-language priming.
5.1.4. Cumulative and long-lasting effects
One of the main differences between a learning-based and an activation-based account of structural priming is whether the effect is long-lasting or short-lived. Now that we have shown that error-driven learning can account for cross-language structural priming, we can investigate whether this effect in the model is cumulative and long-lasting in the same way as in behavioural results. Such cumulative effects, as reported by Kootstra and Doedens (Citation2016), included self-priming within blocks of experimental trials and priming between blocks of trials.
5.1.5. Other syntactic alternations
As argued by, for example, Bernolet et al. (Citation2009), structural priming could be a phenomenon that takes place at different levels (e.g. information structure and syntactic structure), and syntactic alternations differ in the extent to which these levels play a role. Our finding of cross-language priming between structures with different word order suggests that this might also be the case in the Dual-path model. To reach a deeper understanding of structural priming, it is therefore important to extend our modelling to further syntactic alternations, such as datives and genitives. In addition, our model can be extended to produce relative clauses. Monolingual versions of Dual-path have already been implemented that produce complex sentences (Fitz et al., Citation2011). Extending the bilingual model in this way would create the possibility to simulate results from cross-language priming experiments that specifically investigate priming in relative clause attachment (Desmet & Declercq, Citation2006; Hartsuiker et al., Citation2016).
6. Conclusion
We performed structural priming experiments with three different bilingual models: Spanish-English (Exp. 1), verb-final Dutch-English (Exp. 2a), and verb-medial Dutch-English (Exp. 2b). The results of all these three experiments reveal that the Dual-path model can simulate a clear and strong cross-language structural priming effect. We have thus presented the first implemented models of this phenomenon. This finding provides support for the viability of error-driven implicit learning as an account of structural priming between languages specifically, and of structural priming in general.
In addition, the results from the verb-final Dutch-English model show that cross-language priming can occur in the model between structures with different word order. This is in line with results from behavioural experiments conducted by Bernolet et al. (Citation2009), Chen et al. (Citation2013), Fleischer et al. (Citation2012), and Shin and Christianson (Citation2009). Importantly, it allows us to distinguish between our error-driven learning account of structural priming and the hybrid account proposed by Reitter et al. (Citation2011), which predicts that cross-language priming requires structures with identical word order.
Finally, the analyses of the three experiments provide varying degrees of evidence for a difference between cross-language and within-language priming, where within-language priming is always stronger. This is in line with results from behavioural experiments, where within-language priming is also generally stronger but not always significantly so.
Supplemental Appendix
Download PDF (143.6 KB)Acknowledgments
An earlier version of the first experiment of this article was presented at the 18th International Conference on Cognitive Modeling (ICCM 2020) and published in its proceedings (Khoe et al., Citation2020).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 The Bilingual Dual-path model can be downloaded from: https://github.com/xtsoukala/dual_path. It includes the code to run a cross-language priming experiment.
2 The files that the model requires to generate the artificial language input and the input for the priming experiment can be found here: https://github.com/khoe-yh/cross-lang-struct-priming
3 For Spanish, the lexical item “la” is both a determiner and a pronoun.
4 The pre-registration can be accessed here: https://aspredicted.org/xf4yh.pdf
5 Our analysis scripts can be found here: https://github.com/khoe-yh/cross-lang-struct-priming
6 We did not fit by-item random slopes, because an earlier version of our analysis, that did include them, did not result in valid and reliable parameter estimates. This was apparent from the large number of divergent transitions after warmup, and the low Bulk and Tail Effective Sample Sizes (ESS) (https://mc-stan.org/misc/warnings.html). Analysis of the output of the earlier regression model revealed that the ESS values were specifically related to the estimates of the by-item random slopes for Language Combination. In addition, the credible interval (CrI) for these estimates were consistently close to zero across different numbers of iterations and chains, and different values for the adapt_delta parameter.
7 bei is a passive marker in Chinese
8 The files that the models require to generate the artificial language input, and the input for the priming experiments can be downloaded from GitHub: https://github.com/khoe-yh/cross-lang-struct-priming
9 The pre-registration for Experiment 2a and 2b can be accessed here: https://aspredicted.org/3xu25.pdf and the pre-registration for the combined analysis can be accessed here: https://aspredicted.org/qn4qy.pdf
References
- Bernolet, S., Hartsuiker, R. J., & Pickering, M. J. (2007). Shared syntactic representations in bilinguals: Evidence for the role of word-order repetition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(5), 931. https://doi.org/10.1037/0278-7393.33.5.931
- Bernolet, S., Hartsuiker, R. J., & Pickering, M. J. (2009). Persistence of emphasis in language production: A cross-linguistic approach. Cognition, 112(2), 300–317. https://doi.org/10.1016/j.cognition.2009.05.013
- Bernolet, S., Hartsuiker, R. J., & Pickering, M. J. (2013). From language-specific to shared syntactic representations: The influence of second language proficiency on syntactic sharing in bilinguals. Cognition, 127(3), 287–306. https://doi.org/10.1016/j.cognition.2013.02.005
- Bock, K. (1986). Syntactic persistence in language production. Cognitive Psychology, 18(3), 355–387. https://doi.org/10.1016/0010-0285(86)90004-6
- Bock, K., & Griffin, Z. M. (2000). The persistence of structural priming: transient activation or implicit learning? Journal of Experimental Psychology: General, 129(2), 177. https://doi.org/10.1037/0096-3445.129.2.177
- Boyland, J. T., & Anderson, J. R. (1998). Evidence that syntactic priming is long-lasting. In Proceedings of the 20th Annual Conference of the Cognitive Science Society (Vol. 1205). Erlbaum.
- Branigan, H. P., & Pickering, M. J. (2017). An experimental approach to linguistic representation. Behavioral and Brain Sciences, 40, e282. https://doi.org/10.1017/S0140525X16002028
- Branigan, H. P., Pickering, M. J., Stewart, A. J., & McLean, J. F. (2000). Syntactic priming in spoken production: Linguistic and temporal interference. Memory & Cognition, 28(8), 1297–1302. https://doi.org/10.3758/BF03211830
- Bürkner, P. C. (2017). Brms: An R package for Bayesian multilevel models using stan. Journal of Statistical Software, 80(1), 1–28. https://doi.org/10.18637/jss.v080.i01
- Bürkner, P. C. (2018). Advanced Bayesian multilevel modeling with the R package brms. The R Journal, 10(1), 395–411. https://doi.org/10.32614/RJ-2018-017
- Cai, Z. G., Pickering, M. J., Yan, H., & Branigan, H. P. (2011). Lexical and syntactic representations in closely related languages: Evidence from Cantonese–Mandarin bilinguals. Journal of Memory and Language, 65(4), 431–445. https://doi.org/10.1016/j.jml.2011.05.003
- Chang, F. (2002). Symbolically speaking: A connectionist model of sentence production. Cognitive Science, 26(5), 609–651. https://doi.org/10.1207/s15516709cog2605_3
- Chang, F. (2009). Learning to order words: A connectionist model of heavy NP shift and accessibility effects in Japanese and English. Journal of Memory and Language, 61(3), 374–397. https://doi.org/10.1016/j.jml.2009.07.006
- Chang, F., Baumann, M., Pappert, S., & Fitz, H. (2015). Do lemmas speak German? A verb position effect in German structural priming. Cognitive Science, 39(5), 1113–1130. https://doi.org/10.1111/cogs.2015.39.issue-5
- Chang, F., Dell, G. S., & Bock, K. (2006). Becoming syntactic. Psychological Review, 113(2), 234. https://doi.org/10.1037/0033-295X.113.2.234
- Chang, F., Dell, G. S., Bock, K., & Z. M. Griffin (2000). Structural priming as implicit learning: A comparison of models of sentence production. Journal of Psycholinguistic Research, 29(2), 217–230. https://doi.org/10.1023/A:1005101313330
- Chen, B., Jia, Y., Wang, Z., Dunlap, S., & Shin, J. A. (2013). Is word-order similarity necessary for cross-linguistic structural priming? Second Language Research, 29(4), 375–389. https://doi.org/10.1177/0267658313491962
- Desmet, T., & Declercq, M. (2006). Cross-linguistic priming of syntactic hierarchical configuration information. Journal of Memory and Language, 54(4), 610–632. https://doi.org/10.1016/j.jml.2005.12.007
- Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179–211. https://doi.org/10.1207/s15516709cog1402_1
- Favier, S., Wright, A., Meyer, A., & Huettig, F. (2019). Proficiency modulates between- but not within-language structural priming. Journal of Cultural Cognitive Science, 3(1), 105–124. https://doi.org/10.1007/s41809-019-00029-1
- Fazekas, J., Jessop, A., Pine, J., & Rowland, C. (2020). Do children learn from their prediction mistakes? A registered report evaluating error-based theories of language acquisition. Royal Society Open Science, 7(11), 180877. https://doi.org/10.1098/rsos.180877
- Fitz, H., & Chang, F. (2017). Meaningful questions: the acquisition of auxiliary inversion in a connectionist model of sentence production. Cognition, 166, 225–250. https://doi.org/10.1016/j.cognition.2017.05.008
- Fitz, H., & Chang, F. (2019). Language ERPs reflect learning through prediction error propagation. Cognitive Psychology, 111, 15–52. https://doi.org/10.1016/j.cogpsych.2019.03.002
- Fitz, H., Chang, F., & Christiansen, M. H. (2011). A connectionist account of the acquisition and processing of relative clauses. The Acquisition of Relative Clauses, 8, 39–60. https://doi.org/10.1075/tilar
- Fleischer, Z., Pickering, M. J., & McLean, J. F. (2012). Shared information structure: Evidence from cross-linguistic priming. Bilingualism: Language and Cognition, 15(3), 568–579. https://doi.org/10.1017/S1366728911000551
- Hartsuiker, R. J., Beerts, S., Loncke, M., Desmet, T., & Bernolet, S. (2016). Cross-linguistic structural priming in multilinguals: Further evidence for shared syntax. Journal of Memory and Language, 90, 14–30. https://doi.org/10.1016/j.jml.2016.03.003
- Hartsuiker, R. J., & Bernolet, S. (2017). The development of shared syntax in second language learning. Bilingualism: Language and Cognition, 20(2), 219. https://doi.org/10.1017/S1366728915000164
- Hartsuiker, R. J., & Kolk, H. H. (1998). Syntactic persistence in Dutch. Language and Speech, 41(2), 143–184. https://doi.org/10.1177/002383099804100202
- Hartsuiker, R. J., Pickering, M. J., & Veltkamp, E. (2004). Is syntax separate or shared between languages? Cross-linguistic syntactic priming in Spanish-English bilinguals. Psychological Science, 15(6), 409–414. https://doi.org/10.1111/j.0956-7976.2004.00693.x
- Hsin, L., Legendre, G., & Omaki, A. (2013). Priming cross-linguistic interference in Spanish–English bilingual children. In Proceedings of the 37th Annual Boston University Conference on Language Development (pp. 165–77). Cascadilla Press.
- Huang, J., Pickering, M. J., Chen, X., Cai, Z., Wang, S., & Branigan, H. P. (2019). Does language similarity affect representational integration? Cognition, 185, 83–90. https://doi.org/10.1016/j.cognition.2019.01.005
- Huttenlocher, J., Vasilyeva, M., & Shimpi, P. (2004). Syntactic priming in young children. Journal of Memory and Language, 50(2), 182–195. https://doi.org/10.1016/j.jml.2003.09.003
- Jacob, G., Katsika, K., Family, N., & Allen, S. E. (2017). The role of constituent order and level of embedding in cross-linguistic structural priming. Bilingualism: Language and Cognition, 20(2), 269–282. https://doi.org/10.1017/S1366728916000717
- Janciauskas, M., & Chang, F. (2018). Input and age-dependent variation in second language learning: A connectionist account. Cognitive Science, 42, 519–554. https://doi.org/10.1111/cogs.2018.42.issue-S2
- Kantola, L., & van Gompel, R. P. (2011). Between-and within-language priming is the same: Evidence for shared bilingual syntactic representations. Memory & Cognition, 39(2), 276–290. https://doi.org/10.3758/s13421-010-0016-5
- Khoe, Y. H., Tsoukala, C., Kootstra, G. J., & Frank, S. L. (2020). Modeling cross-language structural priming in sentence production. In Proceedings of the 18th International Conference on Cognitive Modeling (ICCM 2020). Applied Cognitive Science Lab, Penn State.
- Kidd, E., Tennant, E., & Nitschke, S. (2015). Shared abstract representation of linguistic structure in bilingual sentence comprehension. Psychonomic Bulletin & Review, 22(4), 1062–1067. https://doi.org/10.3758/s13423-014-0775-2
- Kootstra, G. J., & Doedens, W. J. (2016). How multiple sources of experience influence bilingual syntactic choice: Immediate and cumulative cross-language effects of structural priming, verb bias, and language dominance. Bilingualism: Language and Cognition, 19(4), 710. https://doi.org/10.1017/S1366728916000420
- Kootstra, G. J., & Şahin, H. (2018). Crosslinguistic structural priming as a mechanism of contact-induced language change: Evidence from Papiamento-Dutch bilinguals in Aruba and the Netherlands. Language, 94(4), 902–930. https://doi.org/10.1353/lan.2018.0050
- Kootstra, G. J., Van Hell, J. G., & Dijkstra, T. (2010). Syntactic alignment and shared word order in code-switched sentence production: Evidence from bilingual monologue and dialogue. Journal of Memory and Language, 63(2), 210–231. https://doi.org/10.1016/j.jml.2010.03.006
- Kutasi, T., Suffill, E., Gibb, C. L., Sorace, A., Pickering, M. J., & Branigan, H. P. (2018). Shared representation of passives across Scottish Gaelic and English: Evidence from structural priming. Journal of Cultural Cognitive Science, 2(1-2), 1–8. https://doi.org/10.1007/s41809-018-0012-z
- Loebell, H., & Bock, K. (2003). Structural priming across languages. Linguistics, 41(5), 791–824. https://doi.org/10.1515/ling.2003.026
- Malhotra, G. (2009). Dynamics of structural priming (Unpublished doctoral dissertation). University of Edinburgh.
- Meijer, P. J., & Fox Tree, J. E. (2003). Building syntactic structures in speaking: A bilingual exploration. Experimental Psychology, 50(3), 184. https://doi.org/10.1026//1617-3169.50.3.184
- Mercan, G., & Simonsen, H. G. (2019). The production of passives by English-Norwegian and Turkish-Norwegian bilinguals: A preliminary investigation using a cross-linguistic structural priming manipulation. Journal of Cultural Cognitive Science, 3(1), 89–104. https://doi.org/10.1007/s41809-019-00040-6
- Peter, M., Chang, F., Pine, J. M., Blything, R., & Rowland, C. F. (2015). When and how do children develop knowledge of verb argument structure? Evidence from verb bias effects in a structural priming task. Journal of Memory and Language, 81, 1–15. https://doi.org/10.1016/j.jml.2014.12.002
- Pickering, M. J., & Branigan, H. P. (1998). The representation of verbs: Evidence from syntactic priming in language production. Journal of Memory and Language, 39(4), 633–651. https://doi.org/10.1006/jmla.1998.2592
- R Core Team (2018). R: A language and environment for statistical computing [Computer software manual]. Vienna, Austria. https://www.R-project.org.
- Reitter, D., Keller, F., & Moore, J. D. (2011). A computational cognitive model of syntactic priming. Cognitive Science, 35(4), 587–637. https://doi.org/10.1111/cogs.2011.35.issue-4
- Saffran, E. M., & Martin, N. (1997). Effects of structural priming on sentence production in aphasics. Language and Cognitive Processes, 12(5–6), 877–882. https://doi.org/10.1080/016909697386772
- Salamoura, A., & Williams, J. N. (2007). Processing verb argument structure across languages: Evidence for shared representations in the bilingual lexicon. Applied Psycholinguistics, 28(4), 627–660. https://doi.org/10.1017/S0142716407070348
- Schoonbaert, S., Hartsuiker, R. J., & Pickering, M. J. (2007). The representation of lexical and syntactic information in bilinguals: Evidence from syntactic priming. Journal of Memory and Language, 56(2), 153–171. https://doi.org/10.1016/j.jml.2006.10.002
- Shin, J. A., & Christianson, K. (2009). Syntactic processing in Korean–English bilingual production: Evidence from cross-linguistic structural priming. Cognition, 112(1), 175–180. https://doi.org/10.1016/j.cognition.2009.03.011
- Song, Y., & Do, Y. (2018). Cross-linguistic structural priming in bilinguals: Priming of the subject-to-object raising construction between English and Korean. Bilingualism: Language and Cognition, 21(1), 47–62. https://doi.org/10.1017/S1366728916001152
- Travis, C. E., Cacoullos, R. T., & Kidd, E. (2017). Cross-language priming: A view from bilingual speech. Bilingualism: Language and Cognition, 20(2), 283–298. https://doi.org/10.1017/S1366728915000127
- Tsoukala, C., Broersma, M., Van Den Bosch, A., & Frank, S. L. (2021). Simulating code-switching using a neural network model of bilingual sentence production. Computational Brain & Behavior, 4, 87–100. https://doi.org/10.1007/s42113-020-00088-6
- Tsoukala, C., Frank, S. L., & Broersma, M. (2017). “He's pregnant”: simulating the confusing case of gender pronoun errors in L2 English. In G. Gunzelmann, A. Howes, T. Tenbrink, and E. Davelaar (Eds.), Proceedings of the 39th Annual Conference of the Cognitive Science Society (pp. 3392–3397). Cognitive Science Society.
- Tsoukala, C., Frank, S. L., Van Den Bosch, A., Valdés Kroff, J., & Broersma, M. (2021). Modeling the auxiliary phrase asymmetry in code-switched Spanish–English. Bilingualism: Language and Cognition, 24, 271–280. https://doi.org/10.1017/S1366728920000449
- Twomey, K., Chang, F., & Ambridge, B. (2013). A distributional learning account of the acquisition of the locative alternation: corpus analysis and modeling. In Proceedings of the 35th Annual Meeting of the Cognitive Science Society (pp. 1498–1503). Cognitive Science Society.
- Vasilyeva, M., Waterfall, H., Gámez, P. B., Gómez, L. E., Bowers, E., & Shimpi, P. (2010). Cross-linguistic syntactic priming in bilingual children. Journal of Child Language, 37(5), 1047–1064. https://doi.org/10.1017/S0305000909990213
- Vasishth, S., & Nicenboim, B. (2016). Statistical methods for linguistic research: foundational ideas–Part I. Language and Linguistics Compass, 10(8), 349–369. https://doi.org/10.1111/lnc3.12201
- Weber, K., & Indefrey, P. (2009). Syntactic priming in German–English bilinguals during sentence comprehension. NeuroImage, 46(4), 1164–1172. https://doi.org/10.1016/j.neuroimage.2009.03.040