
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The empirically robust phenomenon of impaired verbal short-term memory due to task-irrelevant background speech is known as the Irrelevant Sound Effect (ISE). Yet, the underlying cognitive mechanisms are still not fully resolved, like whether phonology-based interference contributes to the disruptive effect of speech on verbal serial recall. Thus, we tested the ISE for such a speech-specific aspect by varying the phonological content of the irrelevant speech and the verbal nature of the task. Furthermore, we also varied the changing-state characteristic of irrelevant speech. Therefore, visual-verbal and visual-spatial serial recall of 70 participants each was measured during silence and syllable series varying in phonological (unaltered speech vs. sinewave speech) and in changing-state content (one repeatedly presented vs. successively changing syllables). Both phonology and changing-state characteristic had significant and independent impacts on each of the two serial recall tasks, and both effects were unrelated to participants’ working memory capacity. Changing-state sequences were more disturbing than steady-state sounds for both serial recall tasks, but the effect of phonological content was not in the same direction for the two tasks. Whereas unaltered speech sounds impaired verbal serial recall more than their phonologically reduced sinewave versions, this was the opposite for visual-spatial serial recall. In the latter task, however, only changing-state sinewave speech reduced performance significantly compared to silence condition. In summary, our results indicate that there is a speech-specific, disruptive effect of phonological content, which is an attention-independent interference effect and presumably restricted to verbal short-term memory.
Introduction
Background speech reduces cognitive performance in certain tasks, even if it is irrelevant to the task at hand or the performer of the task knows it should be ignored. This diminishing effect of irrelevant speech and certain non-speech sounds – known as the Irrelevant Sound Effect (ISE) – has been investigated in a multitude of studies (e.g., Jones et al., Citation2010; Page & Norris, Citation2003; for an overview see Schlittmeier et al., Citation2012). However, from a cognitive psychological perspective, it is not yet completely understood which characteristics of background speech are decisive for a specific cognitive function or process to be impaired. Thus, it is still an open question whether the ISE is driven by speech-specific characteristics, such as the phonology of the background speech or the short-term recall of verbal, rather than visual-spatial content, for example. The present study tests these two aspects: the background speech’s phonology and the verbal nature of the serial recall task.
Research on the detrimental effect of irrelevant speech on verbal short-term memory dates back to a study by Colle and Welsh (Citation1976). The authors used the visual-verbal serial recall task, which is the standard task to measure verbal short-term memory capacity. In this study, eight consonants were presented visually one after the other and had to be written down in the same order immediately after presentation. When foreign speech was played to the participants during this task, there was a 12% decrease in serial recall performance compared to the quiet control condition. The insight from this study was repeatedly confirmed empirically in later studies: background speech impairs verbal serial recall even if its semantic content is not accessible for the listener (e.g., Martin et al., Citation1988; Sörqvist et al., Citation2012). Thus, the decisive factor for the background speech’s disturbance impact cannot be its semantic content.
In fact, since the 1980s, a large number of studies have shown that the disturbance impact is not limited to irrelevant speech but can be caused by non-speech sounds too: by music (e.g., Salamé & Baddeley, Citation1989; Schlittmeier et al., Citation2008) or by sequences of different tones (e.g., Jones & Macken, Citation1993; Macken et al., Citation2003). In order to elicit a disturbance impact, it has been shown to be crucial that the irrelevant sound is composed of distinct auditory-perceptual tokens that vary consecutively. An example would be a sequence of consecutively varying speech syllables (e.g., /de/ /ka/ /ef/ /te/ …). These are known as changing-state sounds and reduce visual-verbal short-term memory significantly more than steady-state sounds; an example of the latter would be one repeatedly presented speech token (e.g., /de /de /de/ …). Relevant studies here include those by Jones et al. (Citation1992) and Jones et al. (Citation1995).
The first explanation of this changing-state effect was the Object-Oriented Episodic Record (O-OER) model by Jones and coauthors (Jones, Citation1993; Jones et al., Citation1996; W. Macken et al., Citation1999). Here, the successively varying auditory-perceptive tokens of changing-state sounds are assumed to be encoded in short-term memory in terms of automatically lined-up objects. Performing a serial recall task necessitates the encoding of a further object-sequence for the memory items. Since the presence of order information in short-term memory results in the loss of other order information, serial recall performance is reduced during irrelevant changing-state sound. In contrast to changing-state sounds, steady-state sounds are encoded as a single object with only self-referential, and thus barely concurrent, order information. The detrimental impact of changing-state sounds – whether or not of speech origin – on verbal serial recall is thus attributed to interferences between seriation information. These interference processes, however, are specific neither to background speech, like phonology or semantics, nor to the verbal origin of the retention material: since the O-OER model represents an amodal conception of short-term memory that assumes functional equivalence between, for example, verbal, visual, spatial codes (Jones et al., Citation1996), irrelevant speech that exhibits a changing-state characteristic should not only impair the serial recall of verbal material but also affect visual-spatial serial recall. In line with this, Jones et al. (Citation1995) reported one experiment in which changing-state speech disturbed verbal as well as visual-spatial serial recall (Exp. 4).
This finding, and the conception of short-term memory that it supports, stands in sharp contrast to the considerations proposed some years earlier by Salamé and Baddeley (Citation1987, Citation1989) to explain the ISE. They localized the disturbance effect of irrelevant speech on verbal serial recall in the phonological loop, which is the short-term memory module for verbal material in Baddeley’s highly influential Working Memory model (Baddeley, Citation1986, Citation2000). However, processing and serial recall of visual-spatial items (like a series of positions) is assumed to be achieved by the visual-spatial sketchpad, which is the second short-term storage system within the Working Memory model. Since background speech is not encoded there, it should not reduce visual-spatial serial recall. Indeed, no direct replication has been reported so far for the finding by Jones et al. (Citation1995, Exp. 4) of irrelevant speech impairing visual-spatial serial recall; instead, subsequent studies were not able to verify the detrimental impact of changing-state speech on visual-spatial serial recall (Bergström et al., Citation2012; Kvetnaya, Citation2018; Marsh et al., revision under review).
Beyond that, the assumption of an acoustic-phonological processing format of the phonological loop is per se speech-specific. Phonology is the study of the structure of speech sounds; it refers to the sound patterns of a given language and legal combinations of these to form words. In English, for example, /br/ as in /bread/ or /brew/ is a legal phoneme connection at the beginning of a word, while /bt/ is not. Phonological content is inherent in speech sound articulation. Acoustic resonances of the human vocal tract result in broad spectral maxima that are referred to as formants (Peterson & Barney, Citation1952). The first two formants are critical for vowel identification (Peterson, Citation1952). These formants are associated with movements of the oral cavity. For example, higher frequency of the first formant is associated with higher opening of the mouth necessary for the /a/ in German, whereas higher frequency of the second formant reflects higher arching of the tongue, e.g., used to build a German /i/ (Slawson, Citation1968).
The loop’s acoustic-phonological processing format suggests that the phonology of the background speech underlies its disturbance impact or at least contributes to it. Although not further specified in the conception of the phonological loop, assuming a phonology-related interference mechanism seems reasonable – and still needs empirical testing. It could be considered that the involvement of phonological interference processes in the disturbance impact of irrelevant speech has already been refuted by studies showing the ISE to be independent of any phonological similarity between the irrelevant sound and the items to be retained (e.g., Jones & Macken, Citation1995; Larsen et al., Citation2000; LeCompte & Shaibe, Citation1997). However, these findings on irrelevance of the so-called the (phonological) between-stream similarity should not be overestimated in terms of their argumentative strength against the role of phonology in ISE evocation. First, the mathematically formulated Primacy Model, which is based on the phonological loop's conception, can simulate the ISE independently of the phonological similarity between irrelevant sound and items to be retained (see, Page & Norris, Citation2003, p. 1297). We will return to this model in the discussion. Second, interference mechanisms do not need to be content-based. Rather, the Duplex-Mechanism Account of Auditory Distraction (DMAAD; Hughes et al., Citation2013; Hughes, Vachon et al., Citation2007) assumes interferences to occur when volitional task processing and obligatory, pre-attentive processing of the irrelevant sound “match” in terms of engaging the same cognitive processes (interference-by-process principle; Marsh et al., Citation2009). Thus, in case of process-based interference relying on phonological processing of both irrelevant speech and verbal items to be remembered, it is expected that irrelevant speech is less disruptive when its phonological content is reduced.
One way to reduce the phonological content of a background speech signal is by sinewave synthesis (Remez & Rubin, Citation1990; Remez et al., Citation1981). Here, the main frequency spectra (formants) of natural speech are replaced by sinusoidal tones. Although this kind of signal processing preserves the clear temporal structure and certain spectral regularities of natural speech, it reduces the spectral complexity and the temporal-spectral fine structure our speech production system generates. Since certain information-bearing aspects of the speech signal are still preserved after sinewave synthesis (see, Rosen & Hui, Citation2015), sinewave speech (SWS) can actually be intelligible for some listeners ad-hoc and for most after training. Nonetheless, it is uncontroversial to state that the phonological content of the speech signal is reduced.
In agreement with the assumption of phonological interference, SWS results in distinctly less disruption than natural speech (Tremblay et al., Citation2000), whereas foreign language and reversed speech are nearly as disturbing as their corresponding original speech sounds (Jones et al., Citation1990; Ueda et al., Citation2019). However, it could also be argued that SWS decreased the background sound’s acoustical complexity, and with this its changing-state content, thus causing less interference by seriation to occur.
Thus, the question arises whether there is a phonology-based disruptive effect that can be distinguished from the detrimental impact of the changing-state. If this is so, there is a further question of whether the performance-reducing impact of background speech is fed by these two interference effects of phonology and seriation changing-state features). There is scarce empirical support for the argument that phonological interference is independent of a sound's changing-state characteristic. Cautious conclusions can perhaps be drawn from a study by Viswanathan et al. (Citation2014) in which the authors presented participants with background speech conditions that differed in phonological content by comparing unaltered speech with SWS versions, with all being characterized by changing-state features. They found evidence for an independent effect of phonology, but this conclusion should be tested with an empirical study that includes both changing-state and steady-state versions of speech conditions that vary in phonological content.
Research Intent
In our present study, we disentangled disturbance effects due to either phonology or the changing-state characteristic on verbal serial recall by presenting changing-state and steady-state speech as both unaltered speech and SWS in a within-subject design. We hypothesize that both phonological and seriation interferences, the latter driven by a sound's changing-state characteristic, occur in verbal short-term memory. Thus, we expect SWS with either changing- or steady-state characteristics to reduce performance in verbal serial recall less than the corresponding unaltered speech sounds. Since we assume that an independent changing-state effect is involved, both unaltered speech and SWS with a changing-state characteristic should be more disruptive than their respective steady-state counterparts.
As a further touchstone for differentiating interference related to phonology from that related to the changing-state characteristic, we also employed a visual-spatial serial recall task in the present study. Since neither the encoding nor the serial recall of visual-spatial material encompasses a phonological processing component in the first place, any phonology-based interference mechanism should not be at work. Moreover, previous evidence on the impact of irrelevant speech in this task is very sparse and at the same time controversial (see, Jones et al., Citation1995, opposed to Bergström et al., Citation2012; Kvetnaya, Citation2018; and Marsh et al., revision under review).
Finally, the individual working memory capacity (WMC) of the participants was also measured to test whether any effects found vary with WMC. This was done to have a checkpoint for discriminating interference effects from attentional capture. These two mechanisms of action of irrelevant sound on cognitive performance can be distinguished according to the DMAAD (Hughes et al., Citation2007; Hughes et al., Citation2013). While interferences are assumed to be task-specific (interference-by-process principle; Marsh et al., Citation2009), attentional capture is assumed to vary with the individual’s degree of cognitive control, which can be operationalized via the WMC (Engle, Citation2002). In fact, there is a group of attentional accounts of the ISE (Bell et al., Citation2019; Cowan, Citation1995; Röer et al., Citation2015) which attribute any disruptive effect of background sound to attentional distraction while interference mechanisms are considered to be dispensable in explaining the ISE.
Materials and Methods
Participants
We took two independent samples, each with 70 native German-speaking participants: one for the verbal and one for the visual-spatial short-term memory task. The sample for the verbal short-term memory task ranged in age between 17 and 40 years (median = 21 years; 44 women). For the visual-spatial short-term memory task, age ranged from 18 to 40 years (median = 21 years; 44 women). However, while completing with 70 participants for each of the two tasks, one participant in the verbal and four participants in the visual-spatial short-term memory task had to be left out as they could recall only 20% or less of the items correctly in at least one of the sound conditions (i.e., made 80% errors). Since we assume limited task understanding here, we excluded these participants.
All participants responded to an e-mail seeking participants inside and outside of RWTH Aachen University and were randomly assigned to one of the two samples. Participants received credit points or 8€/hour for participating in the experiment. Written informed consent was obtained from all participants. All participants reported normal hearing and normal or corrected to normal vision.
Apparatus
All tasks were programmed in PsychoPy v3.1.3 (Peirce, Citation2007) and presented on a 15.6-inch laptop. Headphones (Sennheiser HD 650) were connected to the notebook indirectly via a Focusrite Scarlett 2i2 audio interface. The study was conducted in a soundproof booth (Studiobox Premium) at the Institute of Psychology of the RWTH Aachen University.
Stimuli
Sound Conditions
In addition to silence, four irrelevant sound conditions were presented, namely changing-state and steady-state sequences each in unaltered speech and SWS. Irrelevant unaltered changing-state speech consisted of a fixed sequence of 31 varying syllables (/be/, /ti/, /pe/, /bu/, /to/, …; approx. 450–600 ms duration) spoken by a female voice and presented with a 200 ms interstimulus interval. The unaltered irrelevant steady-state speech was spoken by the same female voice and consisted of the syllable “bah” (450 ms duration), which was a taken from the changing-state syllables and repeated 33 times with a 200 ms interstimulus interval. All used syllables consisted of phoneme combinations that are legal in German. Auditory material was recorded using an artificial head (HRS II.2, HEAD Acoustics GmbH) via Digital Audio Tape (DAT; 44,100 Hz sampling rate and 16 bit resolution). The sounds were edited with the software SoundEdit 16 (Macromedia, Inc.).
All recorded unaltered speech syllables were then processed in the phonetic software Praat (Boersma & Weenink, Citation2005) by sinewave synthesis in order to reduce the phonological content of the syllables. Specifically, the first three formants of the original unaltered speech syllables were replaced by time-varying sinusoidal tones tracking the speech signals' frequency and amplitude curves (cf, Remez et al., Citation1981). The changing-state and steady-state SWS sequences were then composed analogously to the unaltered speech sequences.
The loudness of the unaltered speech sounds was measured binaurally via an artificial head (HRS II.2, HEAD Acoustics GmbH) with a Sound Analyzer Type 110 in LAeq over 30 minutes. The changing-state speech sound reached LAeq = 57 dB(A), whereas steady-state speech reached LAeq = 60 dB(A). The sound files of the SWS sounds were calibrated with the sound analyzer via ITA-Toolbox (Dietrich et al., Citation2012) in MATLAB R2019b (MATLAB, Citation1984) to the same psychoacoustical loudness (DIN 45631, Citation1991) of their respective unaltered speech sound counterparts, namely N= 8.8 sone for both changing-state sounds and N= 8.0 sones for both steady-state sounds. However, despite having the same psychoacoustical loudness to the unaltered speech files, changing-state and steady-state SWS were a little louder reaching 58 dB(A) and 62 dB(A), respectively. When no irrelevant sound was played, the sound level was LAeq = 28 dB(A).
Verbal Short-Term Memory
Verbal short-term memory was assessed with a visual-verbal serial recall task. Here, 16 monosyllabic and phonologically dissimilar German nouns (e.g., Pilz (mushroom), Mond (moon), Eis (ice)) were represented by simple pictorial representations in a rectangular black frame (102 × 73 mm) in the center of a white screen. A pretest ensured that these were easily and unambiguously nameable. We used pictorial representation instead of written words so that the setup can also be used for child samples of different ages in the context of developmental studies of the ISE (see, Klatte et al., Citation2010; CitationLeist et al., in prepaccepted for publication). A trial consisted of eight visual stimuli shown one after the other, for 1500 ms with a 500 ms interstimulus interval, at the center of the screen. The 16 visual stimuli were equally divided on all trials by quasi-randomization: each sound condition received the same number of any visual stimuli. It was not possible for the same visual stimulus to be shown twice within a trial.
Visual-Spatial Short-Term Memory
In a trial of the visual-spatial serial recall task, a total of seven black dots with 10 mm diameter appeared for 1500 ms with 500 ms interstimulus interval successively in different spatial positions on a white screen (304 × 183 mm surrounded by a black frame) in each trial. The screen allowed a total of 80 different dot positions (formed invisibly by 8 rows and 10 columns). The task difficulty can be held constant between all trials by a balanced complexity of the paths formed by the successive dots (Parmentier et al., Citation2005). Thus, the order of the dot positions for one block (12 trials for one sound condition) was mirrored either horizontally or vertically for each of two other sound condition, respectively, and shuffled within each mirrored position block again for another two sound conditions, to generate further lists with relatively equal task difficulty.
Working Memory Capacity
A version of the Operation Span (OSPAN) Task (Unsworth et al., Citation2005; first introduced by Turner & Engle, Citation1989) was used as a measure of WMC (Conway et al., Citation2005) in line with other studies on the ISE (e.g., Beaman, Citation2004; Elliott et al., Citation2020; Sörqvist, Citation2010b). In the OSPAN task, the participant has to maintain an increasing sequence of consonants (e.g., F, H, J) while judging mathematical equations (e.g., “3/3 + 2 = 1”) as being true or false between each consonant. Here, responses were given by pressing as fast as possible the corresponding key (“M” and “X” were used, on a computer keyboard with a German layout). In one trial, the presentation of one consonant (shown for 800 ms) and a mathematical equation (time limit of 10,000 ms to solve) alternated until the last consonant was shown. In the recall phase, the previously shown consonants needed to be typed in using the computer keyboard, in the same order in which they were presented before. Here, the OSPAN task consisted of three trials for each sequence length of consonants ranging from three up to seven consonants, respectively.
Procedure
Participants were tested individually. First, participants performed the 15 trials of the OSPAN task. Then they put on the headphones for the respective serial recall task that was either the verbal or the visual-spatial version. This was accompanied by five sound conditions altogether: changing-state unaltered speech, steady-state unaltered speech, changing-state SWS, steady-state SWS, and silence. The participants were made familiar with all five sounds by listening to them one after the other for 4000 ms each before starting the trials. Sound conditions varied trial to trial in quasi-randomized order. After all sound conditions were presented in random order, they were randomized again. Each sound condition was tested in 12 out of a total of 60 trials. The participants were told to ignore the sounds. The irrelevant sounds were presented during the item presentation phase and in a 5000 ms retention interval between list presentation and recall phase. A random interval of sound presentation between 1200 and 1800 ms was introduced before the first list item appeared in the presentation phase. No sound was presented during the recall phase. In the verbal serial recall task, either the 31 changing-state syllables or 33 “bah” syllables occurred per trial for the changing-state or steady-state conditions, respectively. The same happened for the visual-spatial serial recall task but with three syllables less per sound condition due to the shorter trial length.
In the recall phase, all of the stimuli to be remembered were presented at the same time and the participant had to mouse-click all pictures/dots in the correct order as previously shown. Clicking an item changed its shading, indicating that it had been selected. There was no time limit in the recall phase. It was not possible to skip or choose a stimulus once more, or to correct errors by unclicking a stimulus. A visual cue appeared after the selection of the final item indicating the participant should proceed with the next trial by pressing the space bar. Practice trials were given to familiarize participants with the task before the respective testing trials started (OSPAN: two practice trials; verbal serial recall: five practice trials; visual-spatial serial recall task: three practice trials). The whole experiment took about 40 minutes to complete.
Statistical Analysis
For the serial recall tasks, each memory item (picture/dot) correctly recalled on its previously presented serial position was scored as a correct response. Repeated measures ANOVAs were conducted to test the disturbance impact of the different sound conditions in both serial recall tasks. We analyzed the sound effects on serial recall in three steps. First, we included the entire data set and thus all five sound conditions. Here, we checked the comparability of task difficulty of the two serial recall tasks and whether the different sound conditions had any effect at all compared to the silence condition since the latter is the standard baseline condition in ISE research. In the second step, we removed the silence condition from the data set and examined the effects of task, changing-state characteristic and phonological content according to the study’s factorial design. Finally, as a third step to test our ad hoc hypotheses, we examined the effects of phonological content and changing-state characteristics for each task separately.
The performance in WMC was assessed by the so-called all-or-nothing load scoring of the OSPAN values. For any trial, all consonants needed to be recalled in the correct order to get scoring points depending on the number of consonants, i.e., five correctly assigned consonants in a trial with five consonants resulted in 5 points, whereas less than five correctly assigned consonants resulted in 0 points. All points were summed up and divided again by the number of all consonants to get the individual overall mean score value (Conway et al., Citation2005; Hughes et al., Citation2013). At least 85% of the equations needed to be judged correctly to justify the ability to remember consonants as being a valid measurement of WMC. This criterion was fulfilled by all participants.
To test whether participants’ WMC contributed to the disturbance effects of phonological content and/or changing-state characteristic, we performed correlations following Sörqvist (Citation2010a). Correlations were tested between OSPAN scores and difference scores of either unaltered speech and SWS or between changing-state and steady-state sound. The difference scores representing an effect of a sound’s phonological content were calculated by subtracting for each participant the mean correct percentage of the two unaltered speech conditions from the corresponding mean of the two SWS conditions. The difference scores representing an effect of changing-state characteristic were obtained in a similar way by subtracting the mean percentage of the correct responses of the two changing-state speech conditions from the corresponding mean of the two steady-state conditions. The correlations were first tested irrespectively of the serial recall task and then for each of the two serial recall tasks separately.
Results
Sound Effects on Verbal and Visual-Spatial Short-Term Memory
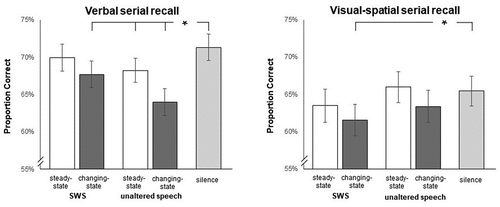
The proportions of correctly recalled items during the different sound conditions are depicted in for each of the two tasks. To start with, we performed a 2 × 5 ANOVA with the between-subjects factor task (verbal vs. visual-spatial) and the within-subject factor sound condition (changing-state speech, steady-state speech, changing-state SWS, steady-state SWS, silence). Due to non-sphericity of the variance-covariance matrix for this ANOVA, Greenhouse–Geisser corrections were applied to significant effects. The interaction of the two factors sound condition and task reached statistical significance, F(3.75, 517.84) = 5.03, p = .001, partial η2 = .04, indicating that the sound conditions affected performance differently in verbal and visual-spatial serial recall. The main effect of task was not significant, F(1, 138) = 2.85, p = .09, partial η2 = .02, indicating comparable overall task difficulty by appropriate item numbers for each task, i.e., 8 items in verbal serial recall and 7 items in visual-spatial serial recall. However, concerning baseline task difficulty, i.e., between both silence conditions, performance was significantly lower in visual-spatial than in verbal serial recall, t(138) = 2.21, p = .03, Cohen’s d = 0.37. The main effect of sound condition was significant, F(3.75, 517.84) = 10.33, p < .001, partial η2 = .07. It was further analyzed separately for verbal and visual-spatial serial recall because of the significant two-way interaction. Testing was limited to comparing the different irrelevant sounds with performance in silence as a standard baseline condition for the ISE. T-tests revealed that verbal serial recall was significantly reduced by the two changing-state sounds, i.e., unaltered speech, t(69) = 6.58, p < .001, Cohen’s d = 0.79, and SWS, t(69) = 3.59, p = .001, Cohen’s d = 0.43, and by the steady-state version of unaltered speech, t(69) = 2.61, p = .01, Cohen’s d = 0.31 (see, , left panel). In contrast, visual-spatial serial recall was exclusively affected by changing-state SWS, t(69) = 3.03, p = .003, Cohen’s d = 0.36 (see, , right panel). All other comparisons did not reach significance, t(69) 0.42, p’s ≥ .68.
Figure 1. Percentages of correctly recalled items in the verbal (left panel) and visual-spatial (right panel) serial recall task as a function of the type of sound condition. SWS = sinewave speech. Error bars indicate the standard error of the mean. Effect indicators represent the irrelevant sound effect by comparison of all respective sound conditions with silence. *p < .01.
To examine the differential effects of phonological and changing-state content on the two serial recall tasks, a 2 × 2 × 2 ANOVA was conducted considering the between-subjects factor task (verbal vs. visual-spatial) and the two within-subject factors phonology (unaltered speech, SWS) and state (changing-state sequence, steady-state sequence). The three-way interaction of task, phonology, and state was not significant, F(1, 138) = 0.34, p = .56, partial η2 = .002. Neither were the two-way interactions of state with either task, F(1, 138) = 0.95, p= .33, partial η2 = .007, or phonology, F(1, 138) = 1.41, p = .24, partial η2 = .01. These results show that, when considering both tasks simultaneously, the impact of changing-state and steady-state sounds did not vary with either the phonological content of the sound or the task type. However, the effect of irrelevant sound on verbal and visual-spatial serial recall depended on its phonological content: this is shown by the significant interaction of phonology and task, F(1, 138) = 13.88, p < .001, partial η2 = .09. The main effect for state, F(1, 138) = 29.52, p < .001, partial η2 = .18, but not the main effects for task, F(1, 138) = 2.26, p = .14, partial η2 = .02, or phonology, F(1, 138) = 0.18, p = .67, partial η2 = .001, reached statistical significance.
Because of a significant interaction with task as one factor being involved, and to test our hypotheses formulated specifically for verbal serial recall, we now consider each of the two experimental groups on its own. For that purpose, we performed a 2 × 2 ANOVA separately for verbal and visual-spatial serial recall, each with the two within-subject factors phonology (unaltered speech, SWS) and state (changing-state sequence, steady-state sequence).
For verbal serial recall, the 2 × 2 ANOVA indicated no interaction between phonology and state, F(1, 69) = 1.59, p = .21, partial η2 = .02, but significant main effects of phonology, F(1, 69) = 9.52, p = .003, partial η2 = .12, and state, F(1, 69) = 29.22, p < .001, partial η2 = .30. Thus, phonology and state affected verbal serial recall independently of each other: regardless of phonological content, changing-state sounds (M= 65.85%, SD = 14.27%) were more disruptive than steady-state sounds (M= 69.10%, SD = 13.58%), and regardless of the changing-state characteristic, unaltered speech (M= 66.12%, SD = 13.99%) was more disruptive than SWS (M= 68.83%, SD = 14.38%) (see, , left panel). Thus, as specifically hypothesized in our research intent, we see that changing- and steady-state SWS reduced performance in verbal serial recall less than their corresponding unaltered speech sounds.
For the visual-spatial serial recall task, there was also no interaction between phonology and state, F(1, 69) = 0.18, p = .67, partial η2 = .003, as indicated by the corresponding 2 × 2 ANOVA. And the main effect of phonology, F(1, 69) = 4.97, p = .03, partial η2 = .07, as well as the main effect of state were also significant, F(1, 69) = 7.66, p = .01, partial η2 = .10. Looking further at the two main effects that lack interaction, we find that the main effect of state was significant because changing-state sounds (M= 62.46%, SD = 16.87%) were more disruptive than steady-state sounds (M= 64.72%, SD = 17.28%), regardless of phonological content. However, and most surprisingly, the main effect of phonology was due to the fact that SWS speech (M= 62.51%, SD = 17.43%) was more disruptive than unaltered speech (M= 64.67%, SD = 16.99%) (see, , right panel), regardless of the changing-state characteristic. However, as revealed at the very beginning of our data analyses, changing-state SWS was the only irrelevant sound in the visual-spatial serial recall task that differed significantly from performance during silence.
Sound Effects and Working Memory Capacity
Finally, we tested whether participants’ WMC, as indicated by performance in the OSPAN task, was related to the disturbance effects of phonological content and/or changing-state characteristic. The overall mean OSPAN score of both experimental groups was M = .58 (SD = .21), ranging from .00 to 1.00. The overall mean difference score between performance during unaltered speech and SWS sounds irrespective of serial recall task was M = 0.28% (SD = 8.09%); the mean difference between steady-state and changing-state sound conditions reached M = 2.76% (SD = 6.00%). There were no significant correlations with the OSPAN scores, neither with the phonological difference scores, r(138) = .04, p = .61, nor with the state difference scores, r(138) = .01, p = .89.
Considering the two experimental groups separately, the participants specifically working on verbal serial recall reached for the OSPAN scores a mean performance value of M = .60 (SD = .20), ranging from .12 to 1.00 (see, , left panels). The mean difference score of performance between unaltered speech and SWS was 2.72% (SD = 7.36%), as it was in turn 3.25% (SD = 5.03%) for the difference between steady- and changing-state conditions. Neither the phonology difference scores, r(68) = −.02, p = .88, nor the state difference scores, r(68) = .09, p = .48, correlated with the OSPAN scores.
Figure 2. Scatter plot for OSPAN score and the amount of disruption by phonological/changing-state content measured by difference scores with SWS minus unaltered speech (phonological effect; upper panels) and with steady-state minus changing-state sound conditions (changing-state effect; lower panels) for both verbal and visual-spatial serial recall.
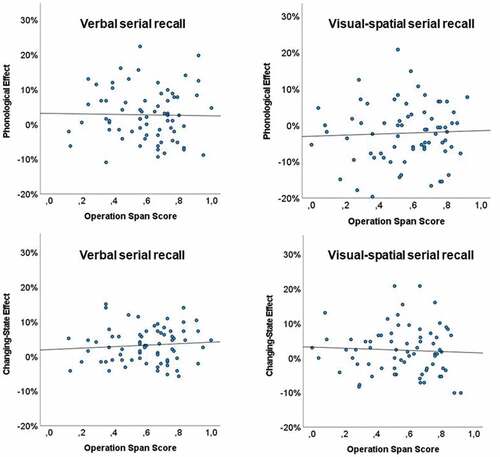
For the participants working on the visual-spatial serial recall task, the mean value for the OSPAN score was M = .56 (SD = .22), ranging from .00 to .92 (see, , right panels). The mean difference score of performance between unaltered speech and SWS, and between steady- and changing-state conditions reached M = −2.16% (SD = 8.11%) and M = 2.26% (SD = 6.84%), respectively. In this experimental group, too, there were no significant correlations of OSPAN scores either with phonology difference scores, r(68) = .04, p = .73, or with the state difference scores, r(68) = −.05, p = .67.
In total, these results indicate that WMC had no differential contribution to the effects of an irrelevant sound’s phonological content or changing-state characteristic on either verbal or visual-spatial serial recall.
Discussion
In our study, we examined visual-verbal and visual-spatial short-term memory during background speech by varying the speech’s phonological content and its changing-state characteristic. Foremost, we wanted to test whether phonology-based interference contributes to the disruptive effect of speech on verbal serial recall. The phonological effect was examined by comparing the unaltered versions of the syllable sequences with their phonologically reduced SWS versions, while in turn for the changing-state effect, the steady-state versions of the syllable sequences were compared with their changing-state versions in a within-subject design. As we consider an effect of phonological content to be independent of the changing-state effect, it should occur for changing-state as well as for steady-state sequences. To further elucidate the mechanisms of action on which a potentially given detrimental sound effect is based, we pursued two further experimental strategies. On the one hand, we explored the impact of the same irrelevant sounds also in a visual-spatial serial recall task lacking any phonological processing component to test in particular for phonology-based interference processes. On the other hand, the individual WMC of the participants as a measure for cognitive control was tested for its potential involvement in any given sound effect. Such a correspondence would point to attentional capture being involved instead of interference mechanisms.
According to our main research interest, we start by considering the empirical results in the verbal serial recall task. Here, the present study verified detrimental effects of both phonological and changing-state content. In fact, unaltered speech impaired verbal serial recall significantly more than SWS (effect of phonological content). Furthermore, the changing-state sequences diminished verbal serial recall to a greater extent than the steady-state sequence (effect of changing-state content). Moreover, these two effects were independent of each other. Thus, phonological content and changing-state characteristic contributed individually – if inherent in the background sound’s characteristics – to a given performance reduction in verbal serial recall. According to the rationale put forward by Sternberg (Citation1969), such an additivity of two effects indicates that they are underpinned by different mechanisms.
Please note, that this finding is not blurred by the fact that performance under silence was significantly higher in the verbal than in visual-spatial serial recall task. The absolute difference between the two baseline conditions (71% vs. 65%) can be considered to be practically irrelevant since for such performance baselines, the performance impairments caused by irrelevant sound are hardly masked by floor or ceiling effects. Furthermore, it is difficult to match performance baselines even better in different serial recall tasks because the task can only be varied in integer steps with respect to the number of items.
Our finding of a special role for phonology as a speech-specific sound feature is in line with a previous study by Dorsi et al. (Citation2018). The authors tested whether irrelevant speech’s fidelity (i.e., speech-likeness) and/or signal complexity (i.e., changing-state characteristic) contribute to its disturbance impact on visual-verbal serial recall. Signal complexity was varied by using noise-vocoded speech and varying the number of vocoding channels. Additionally, speech fidelity of the resulting speech signals was varied by time-reversing a selected subset of channels. In this way, the typical signal-based regularities of irrelevant speech, due to the co-vocalization of speech sounds and biological restrictions on voice production, were reduced. Dorsi et al. (Citation2018) found speech fidelity – and thus speech alikeness in a signal-oriented view – to be relevant for the speech signal’s disturbance impact besides signal complexity and thus changing-state content. However, by maintaining changing words as irrelevant speech in all tested sound conditions, Dorsi et al. (Citation2018) actually did not use a definite steady-state sound version to ultimately compare with separated changing-state quality (see, also Viswanathan et al., Citation2014). In the present study, however, a steady-state sound was realized through a repetitively presented syllable next to successively changing syllables as a changing-state sound. This is a common approach in studies on the ISE to generate irrelevant speech sounds systematically varied by changing-state and steady-state characteristics (e.g., by using words: Campbell et al., Citation2002; Neely & LeCompte, Citation1999; Salamé & Baddeley, Citation1982; Tremblay et al., Citation2000; by using syllables: Hughes, Tremblay et al., Citation2005; Jones et al., Citation1992; Jones & Macken, Citation1993; LeCompte, Citation1995).
To validate the found disturbance impacts of changing-state characteristic and phonological content as being assignable to interference mechanisms only, and that attentional capture by the irrelevant sound is not involved here, we tested the participants’ individual WMC for correlation with the difference scores between the different sound conditions. Such a correlation would suggest that individual attentional control underlies a given detrimental sound effect – or is at least involved in its evocation (cf. the DMAAD; Hughes et al., Citation2007, Hughes et al., Citation2013). Nevertheless, we found no association of WMC either with the disturbance impact of phonological content or with that of a sound’s changing-state characteristic. Regarding the changing-state effect, these results are in line with prior studies that found WMC to be unrelated to an irrelevant changing-state sound’s disturbance impact on visual-verbal serial recall (Beaman, Citation2004; Körner et al., Citation2017; Sörqvist, Citation2010a, Citation2010b; for a meta-analysis cf, Sörqvist et al., Citation2013). Our study expands this finding to the detrimental impact induced by irrelevant speech’s phonological content. Thus, our findings argue that the detrimental impact of both a sound’s changing-state characteristic and its phonological content are specific and independent interference processes instead of the more general mechanism of attentional capture.
Further clarification of the two interference mechanisms was made by also testing the given sound effects in visual-spatial serial recall as a task with no phonological processing components. Here, there were significant effects of both phonological and changing-state content, too, but for phonology, it was the opposite direction, with SWS being more disruptive than phonologically unaltered speech. One could hypothesize that these SWS sounds were very unusual, even irritating, as reported by participants from both serial recall tasks, and, in contrast to the other sounds, led to a distraction of attention in the visual-spatial serial recall. In verbal serial recall, on the other hand, this type of distraction of attention by these “alien” sounds could have been “masked” by the interference effects of phonological and changing-state content that actually occur there. However, this consideration of irritation or attentional distraction is contradicted by the fact that even in visual-spatial serial recall, individual WMC showed no correlation with individual performance differences between SWS and unaltered speech on the one hand, or changing-state and steady-state sounds on the other. Finally, we would like to address a speculative idea related to the visual-spatial aspects of this serial memory task. It might be that natural speech is more associated with a specific spatial position, namely the position of the talker, while SWS, which is usually not identified as speech, might not appear comparably locally bound. Therefore, SWS might be more challenging for visual-spatial short-term memory than unaltered speech. Whether spatial uncertainty or even changing spatial positions of the sound source (e.g., the talker’s location changing after each syllable) affects visual-spatial serial recall more than serial recall without a spatial component could be the subject of future investigation.
As far as we know, this is the first published study examining the possible disturbance of phonological content of background speech on visual-spatial short-term memory. As we have found no such impairment here, we suppose that phonological content may be exclusively disturbing for verbal short-term memory. Our findings support the Working Memory model (Baddeley, Citation1986, Citation2000) which assumes irrelevant speech to be exclusively processed in the phonological loop as one short-term store for verbal material, while it gains no access to the visual-spatial sketchpad as the other separated short-term store in this model. Consequently, the model correctly predicts that irrelevant speech is disruptive to short-term recall of visual-verbal but not visual-spatial items. Furthermore, the phonological loop is assumed to operate on an acoustic-phonological processing format which makes it reasonable to assume that phonological content of the background speech is also relevant for its disturbance impact. The latter, however, does not apply to the O-OER model (Jones, Citation1993; Jones et al., Citation1996; Macken et al., Citation1999), which considers exclusively the changing-state characteristic of an irrelevant sound as decisive for its disturbance impact on serial recall. Our findings contradict this assumption of the O-OER model.
However, our study seems to be one of the rare published studies replicating the changing-state effect of Jones et al. (Citation1995, Exp. 4) in visual-spatial serial recall, namely reduced performance during irrelevant changing-state sound than during corresponding steady-state sound. Thus, it contrasts with extant studies of other authors who found no changing-state effect in visual-spatial serial recall (Bergström et al., Citation2012; Kvetnaya, Citation2018; Marsh et al., revision under review). Yet our study results also present themselves as less straightforward when considering that only one of the two changing-state conditions disrupted serial recall performance compared with the silence condition, i.e., elicited an ISE at all. Although our results seem to be more in line with the O-OER model that expects that irrelevant changing-state sounds equally affect serial recall independent of modality (e.g., verbal information, spatial information) due to functional equivalence of verbal and non-verbal material in an amodal conception of short-term memory (Jones, Citation1993; Jones et al., Citation1996; W. Macken et al., Citation1999), further studies are needed in this perspective.
Although the interference mechanisms imposed by irrelevant speech are not further detailed within the Working Memory model (Baddeley, Citation1986, Citation2000), they are specified in the Primacy Model proposed by Page and Norris (Citation1998). This model is based on the phonological loop’s architecture and thus takes the “speech is special” view, but it is able to account for the changing-state effect at the same time. The primacy model assumes that performing a serial recall task during irrelevant sound results in the encoding of order information for the to-be-remembered item sequence as well as for the background sound, analogous to the O-OER model. During changing-state sounds, however, higher order information is encoded than during steady-state sounds. The changing-state effect is due to the boosted encoding of order information during changing-state sound that consumes more cognitive resources and additionally leads to more noise among the order information encoded for the item sequence (cf, Page & Norris, Citation2003, p. 1297, as well; Norris et al., Citation2004). Because the phonological content of the background sound does not play a role here, the primacy model can correctly model the irrelevance of the (phonological) between-stream similarity (see Introduction), while at the same time it must be assumed that this model cannot cover the phonological interference effect found for verbal serial recall in the present study.
It should be noted that we varied the two sound characteristics of changing-state and phonological content in two rather extreme levels, possibly suggesting a dichotomy of these sound characteristics. However, it can be assumed that these two sound characteristics – and thus possibly also their disturbance impact on verbal serial recall – actually have a dimensional character. Several empirical studies manipulated the irrelevant speech signal in several steps, with corresponding gradual variations of its disturbance impact on verbal serial recall being observed. A reduction in the impact of irrelevant speech has been found when the extent of low-pass filtering (Jones et al., Citation2000) or the level of continuous noise used for superimposition was increased (Ellermeier & Hellbrück, Citation1998). Both manipulations, however, not only reduced the acoustic mismatch between successive auditory-perceptive tokens of the irrelevant speech signal, and with this, its changing-state characteristic, but also affected its phonological content. We like to believe that in our study, we managed to vary changing-state and phonological content largely independently of each other. This is supported by the fact that the fluctuation strengths of the two changing-state sounds were very similar to each other (speech: 1.22 vacil; SWS: 1.11 vacil; measured by the sound and vibration analysis software ArtemiS SUITE, HEAD Acoustics GmbH) as to be considered negligibly different for the magnitude of the interference effect in an ISE modeling study (cf, Schlittmeier et al., Citation2012). The hearing sensation fluctuation strength describes the percept of fluctuations when listening to slowly modulated sounds (fmod [modulation frequency] <20 Hz) like, for example, narration. It has been found to be an instrumental measure to estimate the disturbance impact of most irrelevant speech and non-speech sounds on visual-verbal serial recall (Schlittmeier et al., Citation2012). Therefore, fluctuation strength has been said to capture the changing-state content of an irrelevant sound, as it indicates the temporal structure and the prominence of variations in the frequency spectrum, rather than the properties that are exclusive to speech like, e.g., phonology. However, in the aforementioned modeling study with 70 behavioral measurements of visual-verbal serial recall on over 40 irrelevant sounds, it was noticed that the sounds with the highest disruptive effect – and thus the strongest ISE – were almost exclusively speech sounds (Schlittmeier et al., Citation2012). Our findings contribute to the perspective that this may be the case because speech signals best fulfill the criteria for irrelevant sounds to gain automatic and obligatory access to short-term memory or, in the perspective of the DMAAD (Hughes et al., Citation2005, Hughes et al., Citation2013), automatic processing of speech interfere to the highest extent with cognitive processes involved in verbal serial recall. Such criteria might include clear temporal structures and significant changes in spectrum (i.e., changing-state characteristic), but also the presence of phonology, as our results suggest.
In summary, our findings argue for the irrelevant speech effect being driven by certain speech-specific characteristics, such as the phonology and changing-state character of the speech sound. They are also informative for weighing the various proposed conceptions of short-term memory. Even though performance under silence was significantly higher in verbal than in visual-spatial short-term memory, we consider the absolute difference between the two baseline conditions (71% vs. 65%) to be practically irrelevant. First, because for such performance baselines, the performance impairments caused by irrelevant sound are hardly masked by floor or ceiling effects. Second, it should be noted that it is difficult to match performance baselines even better in different serial recall tasks because the task can only be varied in integer steps with respect to the number of items. Nonetheless, the independent role of phonology-based interference processes in the presence of irrelevant speech certainly requires further empirical clarification, for example, through the use of phonology-based short-term memory tasks that do not require serial processing.
Acknowledgments
The authors thank Plamenna Koleva, Jian Pan, Jonathan Plaß, Ann-Sophie Schenk, and Wiebke Stöver for data collection and for preparing the datasets.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Baddeley, A. (1986). Working memory. Oxford University Press.
- Baddeley, A. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4(11), 417–423. https://doi.org/10.1016/S1364-6613(00)01538-2
- Beaman, C. P. (2004). The irrelevant sound effect revisited: What role for working memory capacity? Journal of Experimental Psychology: Learning, Memory, and Cognition, 30(5), 1106–1118. https://doi.org/10.1037/0278-7393.30.5.1106
- Bell, R., Röer, J. P., Lang, A.-G., & Buchner, A. (2019). Reassessing the token set size effect on serial recall: Implications for theories of auditory distraction. Journal of Experimental Psychology: Learning, Memory, & Cognition, 45(8), 1432–1440 doi:10.1037/xlm0000658.
- Bergström, K., Lachmann, T., & Klatte, M. (2012). Wann stört Lärm das geistige Arbeiten? Einfluss von Aufgaben- und Geräuschcharakteristiken bei der Wirkung moderaten Lärms auf Arbeitsgedächtnisleistungen [proceeding]. Jahrestagung für Akustik (DAGA), Vol. 38, Darmstadt, Germany: Deutsche Gesellschaft für Akustik. https://pub.dega-akustik.de/DAGA_2012/data/articles/000316.pdf
- Boersma, P., & Weenink, K. (2005). Praat: Doing phonetics by computer. (https://www.fon.hum.uva.nl/praat)
- Campbell, T., Beaman, C. P., & Berry, D. C. (2002). Auditory memory and the irrelevant sound effect: Further evidence for changing-state disruption. Memory, 10(3), 199–214. https://doi.org/10.1080/09658210143000335
- Colle, H. A., & Welsh, A. (1976). Acoustic masking in primary memory. Journal of Verbal Learning and Verbal Behavior, 15(1), 17–32. https://doi.org/10.1016/S0022-5371(76)90003-7
- Conway, A. R., Kane, M. J., Bunting, M. F., Hambrick, D. Z., Wilhelm, O., & Negle, R. W. (2005). Working memory span tasks: A methodological review and user’s guide. Psychonomic Bulletin & Review, 12(5), 769–786. https://doi.org/10.3758/BF03196772
- Cowan, N. (1995). Oxford psychology series, No. 26. Attention and memory: An integrated framework. Oxford University Press.
- Dietrich, P., Guski, M., Pollow, M., Müller-Trapet, M., Masiero, B., Scharrer, R., & Vorländer, M. (2012). ITA-Toolbox – An open source MATLAB toolbox for acousticians [proceeding]. Jahrestagung für Akustik (DAGA), Vol. 38, Darmstadt, Germany: Deutsche Gesellschaft für Akustik. https://pub.dega-akustik.de/DAGA_2012/data/index.html
- DIN 45631. (1991). Berechnung des Lautstärkepegels und der Lautheit aus dem Geräuschspektrum – Verfahren nach E. Zwicker (Berlin: Beuth).
- Dorsi, J., Viswanathan, N., Rosenblum, L. D., & Dias, J. W. (2018). The role of speech fidelity in the irrelevant sound effect: Insights from noise-vocoded speech backgrounds. Quarterly Journal of Experimental Psychology, 71(10), 2152–2161. https://doi.org/10.1177/1747021817739257
- Ellermeier, W., & Hellbrück, J. (1998). Is level irrelevant in ‘Irrelevant speech’? Effects of loudness, signal-to-noise ratio, and binaural unmasking. Journal of Experimental Psychology: Human Perception & Performance, 24(5), 1406–1414 doi:10.1037//0096-1523.24.5.1406.
- Elliott, E. M., Marsh, J. E., Zeringue, J., & McGill, C. I. (2020). Are individual differences in auditory processing related to auditory distraction by irrelevant sound? A replication study. Memory & Cognition, 48(2), 145–157. https://doi.org/10.3758/s13421-019-00968-8
- Engle, R. (2002). Working memory capacity as executive attention. Current Directions in Psychological Science, 11(1), 19–23. https://doi.org/10.1111/1467-8721.00160
- Hughes, R. W., Hurlstone, M. J., Marsh, J. E., Vachon, F., & Jones, D. M. (2013). Cognitive control auf auditory distraction: Impact of task difficulty, foreknowledge, and working memory capacity supports duplex-mechanism account. Journal of Experimental Psychology: Human Perception and Performance, 39(2), 539–553. https://doi.org/10.1037/a0029064
- Hughes, R. W., Tremblay, S., & Jones, D. M. (2005). Disruption by speech of serial short-term memory: The role of changing-state vowels. Psychonomic Bulletin and Review, 12(5), 886–890. https://doi.org/10.3758/BF03196781
- Hughes, R. W., Vachon, F., & Jones, D. M. (2005). Auditory attentional capture during serial recall: Violations at encoding of an algorithm-based neural model? Journal of Experimental Psychology; Learning, Memory, and Cognition, 31(4), 736–749. https://doi.org/10.1037/0278-7393.31.4.736
- Hughes, R. W., Vachon, F., & Jones, D. M. (2007). Disruption of short-term memory by changing and deviant sounds: Support for a duplex-mechanism account of auditory distraction. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(6), 1050–1061. https://doi.org/10.1037/0278-7393.33.6.1050
- Jones, D. M. (1993). Objects, streams and threads of auditory attention. In A. D. Baddeley & L. Weiskrantz (Eds.), Attention, awareness, and control. Oxford University Press, 87–104.
- Jones, D. M., Alford, D., Macken, W. J., Banbury, S., & Tremblay, S. (2000). Interference from degraded auditory stimuli: Linear effects of changing-state in the irrelevant sequence. The Journal of the Acoustical Society of America, 108(3), 1082–1088. https://doi.org/10.1121/1.1288412
- Jones, D. M., Beaman, P., & Macken, W. J. (1996). The object-oriented episodic record model. In S. E. Gathercole (Ed.), Models of short-term memory (pp. 209–238). Psychology Press.
- Jones, D. M., Farrand, P., Stuart, G., & Morris, N. (1995). Functional equivalence of verbal and spatial information in serial short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(4), 1008–1018. https://doi.org/10.1037//0278-7393.21.4.1008
- Jones, D. M., Hughes, R. W., & Macken, W. J. (2010). Auditory distraction and serial memory: The avoidable and the ineluctable. Noise & Health, 12(49), 201–209. https://doi.org/10.4103/1463-1741.70497
- Jones, D. M., & Macken, W. J. (1993). Irrelevant tones produce an irrelevant speech effect: Implications for phonological coding in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(2), 369–381 doi:10.1037/0278-7393.19.2.369.
- Jones, D. M., & Macken, W. J. (1995). Phonological similarity in the irrelevant speech effect: Within- or between-stream similarity? Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(1), 103–115 doi:10.1037/0278-7393.21.1.103.
- Jones, D. M., Madden, C., & Miles, C. (1992). Privileged access by irrelevant speech to short-term memory: The role of changing state. Quarterly Journal of Experimental Psychology, 44(4), 645–669. https://doi.org/10.1080/14640749208401304
- Jones, D. M., Miles, C., & Page, J. (1990). Disruption of proof-reading by irrelevant speech: Effects of attention, arousal or memory? Applied Cognitive Psychology, 4(2), 89–108. https://doi.org/10.1002/acp.2350040203
- Klatte, M., Lachmann, T., Schlittmeier, S. J., & Hellbrück, J. (2010). The irrelevant sound effect in short-term memory: Is there developmental change? European Journal of Cognitive Psychology, 22(8), 1168–1191. https://doi.org/10.1080/09541440903378250
- Körner, U., Röer, J. P., Buchner, A., & Bell, R. (2017). Working memory capacity is equally unrelated to auditory distraction by changing-state and deviant sounds. Journal of Memory and Language, 96(1), 122–137. https://doi.org/10.1016/j.jml.2017.05.005
- Kvetnaya, T. (2018). Registered replication report: Testing disruptive effects of irrelevant speech on visual-spatial working memory. Journal of European Psychology Students, 9(1), 10–15. https://doi.org/10.5334/jeps.450
- Larsen, J. D., Baddeley, A., & Andrade, J. (2000). Phonological similarity and the irrelevant speech effect: Implications for models of short-term verbal memory. Memory, 8(3), 145–157. https://doi.org/10.1080/096582100387579
- LeCompte, D. C. (1995). An irrelevant speech effect with repeated and continuous background speech. Psychonomic Bulletin & Review, 2(3), 391–397. https://doi.org/10.3758/BF03210978
- LeCompte, D. C., & Shaibe, D. M. (1997). On the irrelevance of phonological similarity to the irrelevant speech effect. The Quarterly Journal of Experimental Psychology Section A: Human Experimental Psychology, 50(1), 100–118. https://doi.org/10.1080/027249897392242
- Leist, L., Lachmann, T., Schlittmeier, S. J., Georgi, M., & Klatte, M. (accepted for publication). Effects of irrelevant speech on serial recall of verbal and spatial materials in children and adults, Memory & Cognition.
- Macken, W., Tremblay, S., Alford, D., & Jones, D. M. (1999). Attentional selectivity in short-term memory: Similarity of process, not similarity of content, determines disruption. International Journal of Psychology, 34(5/6), 322–327. https://doi.org/10.1080/002075999399639
- Macken, W. J., Tremblay, S., Houghton, R. H., Nicholls, A. P., & Jones, D. M. (2003). Does auditory streaming require attention? Evidence from attentional selectivity in short-term memory. Journal of Experimental Psychology: Human Perception & Performance, 29(1), 43–51. doi:10.1037/0096-1523.29.1.43.
- Marsh, J. E., Hughes, R. W., & Jones, D. M. (2009). Interference by process, not content, determines semantic auditory distraction. Cognition, 110(1), 23–38. https://doi.org/10.1016/j.cognition.2008.08.003
- Marsh, J. E., Hurlstone, M. J., Marois, A., Ball, L. J., Moore, S. B., Vachon, F., Schlittmeier, S. J., Röer, J. P., Buchner, A., & Bell, R. (revision under review). Changing-state irrelevant speech disrupts visual-verbal but not visual-spatial serial recall, Journal of Experimental Psychology: Leaning, Memory and Cognition.
- Martin, R. C., Wogalter, M. S., & Forlano, J. G. (1988). Reading comprehension in the presence of unattended speech and music. Journal of Memory and Language, 27(4), 382–398. https://doi.org/10.1016/0749-596X(88)90063-0
- MATLAB. (1984). MATLAB. The MathWorks Inc.
- Neely, C. B., & LeCompte, D. C. (1999). The importance of semantic similarity to the irrelevant speech effect. Memory & Cognition, 27(1), 37–44. https://doi.org/10.3758/BF03201211
- Norris, D., Baddeley, A. D., & Page, M. P. A. (2004). Retroactive effects of irrelevant speech on serial recall from short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30(5), 1093–1105. https://doi.org/10.1037/0278-7393.30.5.1093
- Page, M. P. A., & Norris, D. G. (1998). Modeling immediate serial recall with a localist implementation of the primacy model. In J. Grainger & A. M. Jacobs (Eds.), Localist connectionist approaches to human cognition (pp. 227–255). Erlbaum.
- Page, M. P. A., & Norris, D. G. (2003). The irrelevant sound effect: What needs modelling, and a tentative model. The Quarterly Journal of Experimental Psychology, 56(8), 1289–1300. https://doi.org/10.1080/02724980343000233
- Parmentier, F. B. R., Elford, G., & Maybery, M. (2005). Transitional information in spatial serial memory: Path characteristics affect recall performance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(3), 412–427. https://doi.org/10.1037/0278-7393.31.3.412
- Peirce, J. W. (2007). PsychoPy – psychophysics software in python. Journal of Neuroscience Methods, 162(1–2), 8–13. https://doi.org/10.1016/j.jneumeth.2006.11.017
- Peterson, G. E. (1952). The information-bearing elements of speech. The Journal of the Acoustical Society of America, 24(6), 629–637. https://doi.org/10.1121/1.1906945
- Peterson, G. E., & Barney, H. L. (1952). Control methods used in a study of the vowels. The Journal of the Acoustical Society of America, 24(2), 175–184. https://doi.org/10.1121/1.1906875
- Remez, R. E., & Rubin, P. E. (1990). On the perception of speech from time-varying acoustic information: Contributions of amplitude variation. Perception & Psychophysics, 48(4), 313–325. https://doi.org/10.3758/BF03206682
- Remez, R. E., Rubin, P. E., Pisoni, D. B., & Carell, T. D. (1981). Speech perception without traditional speech cues. Science, 212(4497), 947–949. https://doi.org/10.1126/science.7233191
- Röer, J. P., Bell, R., & Buchner, A. (2015). Specific foreknowledge reduces auditory distraction by irrelevant speech. Journal of Experimental Psychology: Human Perception & Performance, 41(3), 692–702 doi:10.1037/xhp0000028.
- Rosen, S., & Hui, S. N. (2015). Sine-wave and noise-vocoded sine-wave speech in a tone language: Acoustic details matter. The Journal of the Acoustical Society of America, 138(6), 3698–3702. https://doi.org/10.1121/1.4937605
- Salamé, P., & Baddeley, A. D. (1982). Disruption of short-term memory by unattended speech: Implications for the structure of working memory. Journal of Verbal Learning and Verbal Behavior, 21(2), 150–164. https://doi.org/10.1016/S0022-5371(82)90521-7
- Salamé, P., & Baddeley, A. D. (1987). Noise, unattended speech and short-term memory. Ergonomics, 30(8), 1185–1193. https://doi.org/10.1080/00140138708966007
- Salamé, P., & Baddeley, A. (1989). Effects of background music on phonological short-term memory. The Quarterly Journal of Experimental Psychology, 41(1), 107–122. https://doi.org/10.1080/14640748908402355
- Schlittmeier, S. J., Hellbrück, J., & Klatte, M. (2008). Can the irrelevant speech effect turn into a stimulus suffix effect? Quarterly Journal of Experimental Psychology, 61(5), 665–673. https://doi.org/10.1080/17470210701774168
- Schlittmeier, S. J., Weißgerber, T., Kerber, S., Fastl, H., & Hellbrück, J. (2012). Algorithmic modeling of the irrelevant sound effect (ISE) by the hearing sensation fluctuation strength. Attention, Perception, and Psychophysics, 74(1), 194–203. https://doi.org/10.3758/s13414-011-0230-7
- Slawson, A. W. (1968). Vowel quality and musical timbre as functions of spectrum envelope and fundamental frequency. The Journal of the Acoustical Society of America, 43(1), 87–101. https://doi.org/10.1121/1.1910769
- Sörqvist, P. (2010a). High working memory capacity attenuates the deviation effect but not the changing-state effect: Further support for the duplex-mechanism account of auditory distraction. Memory & Cognition, 38(5), 651–658. https://doi.org/10.3758/MC.38.5.651
- Sörqvist, P. (2010b). The role of working memory capacity in auditory distraction: A review. Noise & Health, 12(49), 217–224. https://doi.org/10.4103/1463-1741.70500
- Sörqvist, P., Marsh, J. E., & Nöstl, A. (2013). High working memory capacity does not always attenuate distraction: Bayesian evidence in support of the null hypothesis. Psychonomic Bulletin & Review, 20(5), 897–904. https://doi.org/10.3758/s13423-013-0419-y
- Sörqvist, P., Nöstl, A., & Halin, N. (2012). Disruption of writing processes by the semanticity of background speech. Scandinavian Journal of Psychology, 53(2), 97–102. https://doi.org/10.1111/j.1467-9450.2011.00936.x
- Sternberg, S. (1969). Memory-scanning: Mental processes revealed by reaction-time experiments. American Scientist, 57(4), 421–457. https://www.jstor.org/stable/27828738
- Tremblay, S., Nicholls, A. P., Alford, D., & Jones, D. M. (2000). The irrelevant sound effect: Does speech play a special role? Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(6), 1750–1754. https://doi.org/10.1037//0278-7393.26.6.1750
- Turner, M. L., & Engle, R. W. (1989). Is working memory capacity task dependent? Journal of Memory & Language, 28(2), 127–154. https://doi.org/10.1016/0749-596X(89)90040-5
- Ueda, K., Nakajima, Y., Kattner, F., & Ellermeier, W. (2019). Irrelevant speech effects with locally time-reversed speech: Native vs non-native language. The Journal of the Acoustical Society of America, 145(6), 3686–3694. https://doi.org/10.1121/1.5112774
- Unsworth, N., Heitz, R. P., Schrock, J. C., & Engle, R. W. (2005). An automated version of the operation span task. Behavior Research Methods, 37(3), 498–505. https://doi.org/10.3758/BF03192720
- Viswanathan, N., Dorsi, J., & George, S. (2014). The role of speech-specific properties of the background in the irrelevant sound effect. The Quarterly Journal of Experimental Psychology, 67(3), 581–589. https://doi.org/10.1080/17470218.2013.821708