Abstract
Textbook data is essential for teaching statistics and data science methods because it is clean, allowing the instructor to focus on methodology. Ideally textbook datasets are refreshed regularly, especially when they are subsets taken from an ongoing data collection. It is also important to use contemporary data for teaching, to imbue the sense that the methodology is relevant today. This article describes the trials and tribulations of refreshing a textbook dataset on wages, extracted from the National Longitudinal Survey of Youth (NLSY79) in the early 1990s. The data is useful for teaching modeling and exploratory analysis of longitudinal data. Subsets of NLSY79, including the wages data, can be found in supplementary materials from numerous textbooks and research articles. The NLSY79 database has been continually updated through to 2018, so new records are available. Here we describe our journey to refresh the wages data, and document the process so that the data can be regularly updated into the future. Our journey was difficult because the steps and decisions taken to get from the raw data to the wages textbook subset have not been clearly articulated. We have been diligent to provide a reproducible workflow for others to follow, which also hopefully inspires more attempts at refreshing data for teaching. Three new datasets and the code to produce them are provided in the open source R package called yowie. Supplementary materials for this article are available online.
1 Introduction
Statistics and data science education relies on cleaned and simplified data, suitably called textbook data, for clear examples on how to apply different techniques. An example of this is the wages data made public by Singer and Willett (Citation2003) in their book, “Applied longitudinal data analysis,” which can be used to teach generalized linear models, and additionally hierarchical, mixed effects, and multilevel models. The data records hourly wages of a sample of high school dropouts from 1979 to 1994, along with demographic variables, such as education and race, taken from the National Longitudinal Survey of Youth (NLSY79) (Bureau of Labor Statistics, U.S. Department of Labor Citation2021a).
The story from modeling the data (and as reported by Singer and Willett) is that wages increase with the length of time in the workforce, a higher level of education leads to higher wages, and that race makes a difference, on average. However, an exploratory analysis reveals that the individual experience varies a great deal from the overall average. Some individuals experience a decline in wages the longer they are in the workforce, and many experience volatility in their wages. It is for these reasons that the wages data was used to illustrate exploratory longitudinal data analysis in Ilk (Citation2004), and was further developed into a case study for use in the teaching of exploratory data analysis at Iowa State University.
This disparity between the overall trend and the individual heterogeneity is what makes this data interesting. Textbook data sets have longevity if they have unresolved elements. The iris data (Anderson Citation1935) is a prime example. Although the origin of the commonly available data today is uncertain and the original purpose was different (Unwin and Kleinman Citation2021), its use as a textbook data has grown and persisted. The three species cannot be perfectly classified, and so it continues to challenge researchers and instructors to do better in the analysis.1 We argue that the wages data is in this class of textbook data, too, because it presents a challenge for longitudinal data analysis: how can we better summarize and explain the individual experience?
For statistics, and data science by association, it is increasingly important to reach the individual. One might think of this as a divergence of purpose—statistics for public policy—or statistics for the public. The two are not the same. As the world becomes more electronically connected, combating misinformation and mitigating conspiracy theories require statistics that address the individual. For example, with the wages data, the overall trend, across demographics, is a steady increase in wages, but the patterns are among individuals is heterogeneous. Some individuals see a decline in their wages, some an increase, some have dramatic ups and downs from year to year, and the heterogeneity of the patterns are evident across demographics. Subject-specific variation explains most of the variation in wages, and even though the overall trend is statistically significant, it is weak. The message for public policy is that demographic profile is related to different wage patterns on average and some structural social change is desirable. However, discussing the overall trend with an individual is misleading—more than likely their pattern is completely different. It could even be depressing for them to compare themselves to the overall average, especially if the individual’s wages have a declining trend or high volatility. It would be more useful for an individual to know what percentage of the population have profiles like theirs. We argue that different summaries are needed to communicate with the public, and ones where they might be able to individually act on to change their own situation. We occasionally hear this voiced in the public media, also, for example, an article published in the Sydney Morning Herald argues there is no average Australian (Moncrief Citation2015). Thus, the wages data provides educators with a challenge, from a methodological and a philosophical perspective, and wage experience is a topic of interest to many.
As a textbook dataset, though, the wages data is outdated. The most recent year in the data is 1994, 9 years prior to when Singer and Willett (Citation2003) was published. Teachers of statistics need contemporary datasets to show how techniques are relevant for today’s students. Using tired old textbook datasets can imbue a misconception that the field is not current. The wages data is extracted from NSLY79, one of the best examples of open data (see details at Open Knowledge Foundation Citation2021), which is constantly being updated. It should be possible to continuously refresh the textbook data from the data repository. This article describes our (nonglamorous) journey from open wild data to textbook data.
This article demonstrates the steps of cleaning data, including subjective decisions made on dealing with anomalies, and documents the process, as recommended by Huebner, Werner, and Cessie (Citation2016). They emphasize that making the data cleaning process accountable and transparent is imperative and essential for the integrity of downstream statistical analyses and model building. Clean data often then goes through an “initial data analysis” (IDA) (Chatfield Citation1985), where one would summarize and scrutinize the data, especially to check if the data is consistent with assumptions required for modeling. This stage is related to exploratory data analysis (EDA), coined by Tukey (Citation1977) with a focus on learning from data. EDA can be considered to encompass IDA. In practice, the three stages of cleaning, summarizing, and exploring are cyclical, one often needs to do more cleaning after scrutinizing. Dasu and Theodore (2003) say that data cleaning and exploration is a difficult task and typically consumes a large percentage of the time spent in analyzing data.
Our approach to cleaning builds heavily on the tidyverse approach (Wickham et al. Citation2019). The data is first organized into “tidy data” (Wickham Citation2014) and then further wrangled using step-wise piping with a split-apply-combine strategy for mutating new variables (Wickham Citation2011). Tidy data shouldn’t be confused with “tame data,” which Kim, Ismay, and Chunn (Citation2018) coined to refer to textbook datasets suitable for teaching, particularly teaching statistics. The resulting (tame) data is provided in a new R package called yowie, which includes the code so the process is reproducible and could be used to further refresh the data as new records are made available in the NLSY79 database.
This article is structured in the following way. Section 2 describes the NLSY79 data source. Section 3 presents the steps of cleaning the data, including getting and tidying the data from the NLSY79 and IDA to find and repair anomalies. Our final subset is compared to the old textbook subset in Section 4. Finally, Section 5 summarizes the contribution and makes recommendations for the NLSY79 data curators.
2 The NLSY79
Singer and Willett (Citation2003) used the wages and other variables of high school dropouts from the NLSY79 data as an example dataset to illustrate longitudinal data modeling of wages on workforce experience, with covariates education and race. This data has been playing an important role in research in various disciplines, including but not limited to economics, sociology, education, public policy, and public health for more than a quarter of the century (Pergamit et al. Citation2001). In addition, this is considered a carefully designed longitudinal survey with high retention rates, making it suitable for life course research (Pergamit et al. Citation2001; Cooksey Citation2017). According to Cooksey (Citation2017), thousands of articles and hundreds of book chapters and monographs have used this data. Moreover, the NLSY79 is considered the most widely used and most important cohort in the survey data (Pergamit et al. Citation2001).
Our aim is to refresh the wages textbook data and append it with data from 1994 through to the latest data reported in 2018, a purpose consistent with Grimshaw (Citation2015)’s statistics education goal of embracing authentic data experiences. Here, we investigate the process of getting from the raw NLSY79 data to a textbook dataset as similar as possible to that provided by Singer and Willett (Citation2003). We should also note that race is a variable in the original dataset, and for compatibility, it is also provided with the refreshed data for the purposes of studying racism, not race (Fullilove Citation1998). There are a number of datasets provided by Singer and Willett (Citation2003), but we focus only on wages data because it has captivated our attention for a number of years in our own teaching of longitudinal data analysis.
2.1 Database
The NLSY79 is a longitudinal survey administered by the U.S Bureau of Labor Statistics that follows the lives of a sample of American youth born between 1957 and 1964 (Bureau of Labor Statistics, U.S. Department of Labor Citation2021a). The cohort originally included 12,686 respondents aged 14–22 when first interviewed in 1979. For a variety of reasons, some structural, the number of respondents dropped to 9964 after 1990. The surveys were conducted annually from 1979 to 1994 and biennially thereafter. Data are currently available from Round 1 (1979 survey year) to Round 28 (2018 survey year).
Although the main focus area of the NLSY is labor and employment, the NLSY also covers several other topics, including education, training, achievement, household, geography, dating, marriage, cohabitation, sexual activity, pregnancy, fertility, children, income, assets, health, attitudes and expectations, crime, and substance use.
There are two ways to conduct the interview of the NLSY79, which are face-to-face or telephone interviews. In recent survey years, more than 90% of respondents were interviewed by telephone (Cooksey Citation2017).
2.2 Target Data
The NLSY79 data used in Singer and Willett (Citation2003) contains the longitudinal records of male high school dropouts who first participated in the study at age 14–17 years from 1979 through to 1994. This dataset contains several variables as follows:
ID: the respondents’ ID.
EXPER: stands for experience, the temporal scale, that is, the length of time (years) in the workforce, starting on the respondents’ first day at work.
LNW: natural logarithm of wages, adjusted with 1990s inflation rate.
BLACK: binary variable, 1 indicates Black and 0 otherwise.
HISPANIC: binary variable, 1 indicates Hispanic and 0 otherwise.
HGC: the highest grade completed.
UERATE: the unemployment rate of the year of the survey. When missing, the variable is set to be 7.875 (the average rate).
We refresh this data by recreating the full data with records from survey years 1979 through to 2018 (the most recent year published). We also modify some variables. For example, we use a single categorical race variable instead of the two binary race variables, for reasons detailed below. We also include additional variables, some for the purpose of providing more options for data exploration in teaching examples: year of the survey, age of individual in 1979, whether the individual completed high school with a diploma or with a graduate equivalency degree (GED), the highest grade completed in the corresponding year of survey, the number of jobs the individual had in the corresponding year of survey, the total number of hours the individual usually works per week, the year when the individual started to work, and the number of years the individual worked. We do not attempt to refresh the unemployment rate variable.
We aim to create three datasets as follows:
The wages data of the whole NLSY79 cohort, including females,
A separate table of the demographic data of the whole NLSY79 cohort, and
The subset of wages data in (1), which is the wages of high school dropouts’ as a refreshed version of Singer and Willett (Citation2003)’s data.
3 Data Cleaning
In the context of official statistics, M. van der Loo and de Jonge (Citation2018) describe the “statistical value chain,” which includes various production stages of the data cleaning process as raw data (initial data as delivered originally), input data (data organized with correct type and identified variables), and valid data (data that has been cleaned and more accurately represents the intent of variables). What we have colorfully named wild data can be considered to be raw data, and valid data could be considered to be textbook data in the above statistical value chain. In this section, we outline the steps to download the raw data (Section 3.1) and then tidy the raw data into input data, specifically for the demographic variables (Section 3.1.1) and the employment variables (Section 3.1.2), so the resulting input data can be used downstream for validating the data as described in Sections 3.3 and 3.4.
3.1 Getting the Data
The NLSY79 data contains a large number of variables, but for our purposes, the scope required is limited to demographic profiles, wages data, and work experience. More specifically, we went to the NLSY79 database website at https://www.nlsinfo.org/content/cohorts/nlsy79/get-data, clicked on the direct link to NSLY79 data, and navigated as described in .
Fig. 1 Documented steps taken to select variables of interest and download the raw data.

The downloaded dataset comes as a zip file, containing the following set of files:
NLSY79.csv: comma separated value format of the response data,
NLSY79.dat: alternative text format of the response data,
NLSY79.NLSY79: tagset of variables that can be uploaded to the website to recreate the dataset, and
NLSY79.R: R script for reading the data into R and converting the variable names and label into something more sensible.
We alter only the file path in NLSY79.R and run the script without any other alteration. This results in the initial processing of the raw data into two datasets, categories_qnames (where the observations are stored in categorical/interval values) and new_data_qnames (the observations are stored in integer form).
To get the data into tidy form (Wickham Citation2014), it needs to comply with three rules: (i) each variable forms a column, (ii) each observation forms a row, and (iii) each type of observational unit forms a table. The raw data, new_data_qnames, violates these rules (i) and (ii) because information about an individual’s multiple jobs over different years are in multiple columns. The raw data consequently has a large number of columns (742 to be specific). The values in the cell under the variables begin with HRP correspond to the hourly wage in dollars. A glimpse of this data show the format problems:
#> Rows: 12,686 #> Columns: 11 #> $CASEID_1979 <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1 #> $HRP1_1979 <int> 328, 385, 365, NA, 310, NA, NA, NA, 214, NA, 337 #> $HRP2_1979 <int > NA, NA, NA, NA, 375, NA, NA, NA, NA, NA, 300, NA #> $HRP3_1979 <int > NA, NA, 275, NA, NA, NA, NA, NA, NA, NA, NA, NA, #> $HRP4_1979 <int > NA, NA, NA, NA, NA, 250, NA, NA, NA, NA, NA, NA, #> $HRP5_1979 <int > NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, #> $HRP1_1980 <int > NA, 457, 397, NA, 333, 275, 300, 394, 200, 318, #> $HRP2_1980 <int > NA, NA, 367, NA, NA, NA, NA, NA, NA, NA, NA, NA, #> $HRP3_1980 <int > NA, NA, 380, NA, NA, NA, 290, NA, NA, NA, NA, NA #> $HRP4_1980 <int > NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, #> $HRP5_1980 <int > NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
Thus, we rearrange and wrangle the data into tidy data form, with columns corresponding to individual ID, year, job number, wage in dollars, and the demographic variables. This is done using the tidyverse suite of packages (Wickham et al. Citation2019). We use pivot_longer in tidyr (Wickham and Hester Citation2020) to pivot the data into long-form. For example, we use it to pull the hourly wage (HRPjob_year), which is stored in a column corresponding to each job and each year of survey, into columns: job and rate per hour. After that, separate from tidyr is also used to get the job and survey year in two separate columns. Further dplyr (Wickham and Hester Citation2020) is used and stringr (Wickham et al. Citation2019) are used to create new variables from the downloaded data from the database, and code levels of factors by text wrangling. The long form of the data makes it possible to do data transformations efficiently, and it is an intermediate step toward the final target data. The code for tidying the data are demonstrated at https://numbats.github.io/yowie/articles/raw-to-input-data.html but also described in the subsequent sections.
3.1.1 Tidying Demographic Variables
Our final target data will include the demographic variables (variable names): sex (sex), race (race), age (age_1979), highest grade completed reported in each round of the survey (grade), highest grade completed ever reported (hgc), highest grade completed in terms of years (as an integers), for example, ninth grade = 9, third-year college = 15, (hgc_i), highest grade completed in 1979 (hgc_1979) and whether the graduate equivalency diploma is obtained (ged).
For sex and race, we have simplified the original names provided in the raw data, SAMPLE_SEX_1979 and SAMPLE_RACE_78SCRN, respectively. However, it is important to note that the use of “sex” is probably not correct. This information is provided by the individual, and although it only has two categories, it is more consistent with “gender” as defined in Heidari et al. (Citation2016). When using the dataset in the classroom, the educators might include discourse on the use of terms “sex” and “gender.” Particularly, measuring gender as a binary variable has the potential to fail to capture people who do not identify themselves as either male or female or create measurement error for people whose gender does not align with their sex classification. From a statistical perspective, this can make it difficult to adjust survey statistics to the population when gender is measured in different categorization in different data sources. Kennedy et al. (Citation2020) provides a helpful discussion on these topics.
Similarly, there are issues for the race variable. The current U.S. Federal guidelines (Office of Management and Budget Citation1997) state that there should be at least five categories for race, and an individual should be able to identify as more than one race category. In addition, “Hispanic” or “Latino” should be considered to be an ethnic group rather than a race. This level of detail is not available in the database. There is one variable with only three categories, and an individual can be a member of only one. Thus, the race variable is inadequate by today’s standards, and educators should point to the current Federal guidelines when using this variable, and keep in mind that the purpose of any analysis is to study racism rather than race.
Furthermore, the object new_data_qnames, contains the variables Q1-3_ÃY_1979 and Q1-3_ÃY_1981, which records two versions of the birth year of the respondent; this is also the case for the record of birth month (Q1-3_ÃM_1979 and Q1-3_ÃM_1981). The record contains two versions of birth year and birth month as the survey recorded this in 1979 and 1981. We checked for consistency between the two versions and found no discrepancy where the responses were recorded in both 1979 and 1981. The age was then calculated using the birth year.
The next step is processing the highest grade completed. There are several ways to define this, and this should be reflected in the refreshed data to give some flexibility for downstream analysis. The first one is the highest grade ever completed is reported in the database and provided in the refreshed data as hgc and hgc_i, encoded as a factor and integer variable, respectively. For each individual, there is only one value of hgc and hgc_i. This variable is obtained from new_data_qnames with the name HGC_EVER_XRND and stored in year units (e.g., 10, 11, 12, 13, and so on), so the transformation is simply giving a new column name as hgc_i and recoded as a factor to give hgc (e.g., 10th grade, 11th grade, and so on). We decide to include both the factor and integer variables to be used as examples in various classroom demonstrations to explain different data types say. Besides this, it can also serve as a demonstration of different type of data visualization ascribed by the data type and for teaching the modeling of cross sectional data.
The second definition is the highest grade completed that is reported in each round of the survey (provided in the refreshed data as grade). This value can change over time, but it is nondecreasing. This has been included in the refreshed dataset to enable richer downstream analyses, for example, if one would like to explore how the temporal changes in education level affect the wages of individuals. Hence, different from hgc, this variable could be used to demonstrate longitudinal and time series analysis in the classroom. This is recorded in new_data_qnames as columns beginning with Q3-4 and HGC with year as a suffix. In addition, it is also in the columns beginning with HGCREV reflecting revised data. We chose to use these revised values because there were fewer missing values indicating it had been more thoroughly checked. In the survey years when the revised value were not reported, that is, in 2012, 2014, 2016, and 2018, we used the unrevised version accordingly.
The third definition is the highest grade completed in 1979 (provided in the refreshed data as hgc_1979), corresponding to the value from the first round of the survey. This is calculated from the grade value in 1979. This best reflects the grade when the individual left school and is included in order to compare with the original data.
The next step is tidying to obtain ged. Along with hgc, ged is used to subset the data to the high school dropouts as in the original data. The graduate equivalency status is saved as a variable started with “Q3-8A” followed by the year of the survey. Thus, we only separate the year and the GED status. Although the GED status is asked in each round of the survey, we only retain the latest status of one’s GED.
Finally, we get all of the demographic profiles of the NLSY79 cohort. We then save this data as demog_nlsy79.
3.1.2 Tidying Employment Variables
Our target for the employment-related variables is to obtain the respondent’s mean hourly wage (wage), the number of jobs (njobs), the total hours of work per week (hours) for each survey year, the year when individual starting to work (stwork), the length of time (in years) in the workforce (yr_wforce), and work experience measured as the number of years worked (exp). As the data only reports up to five jobs for each respondent, the maximum number of jobs is capped at five.
From 1979 to 1987, new_data_qnames only contains one version of hours worked per week for each job (in the variables with names starting with QES-52A). From 1988 onward, we selected the total hours worked per week, including hours working from home (QES-52D). However, in 1993, this variable was missing for the first and last job, so we selected to use QES-52A instead. In addition, 2008 only had jobs 1–4 for the QES-52D variable, so we use only these.
The hourly wages are in the variables beginning with HRP in new_data_qnames. As a respondent may have multiple jobs, the mean_hourly_wage is computed as a weighted average of the hourly wage for each job with the number of hours worked for each job as weights (provided that the information on the number of hours is available); if the number of hours worked for any job is missing, then the mean_hourly_wage is computed as a simple average of all available hourly wages. Prior to computing the mean hourly wage, we undertook a number of steps to treat extreme observations as described below:
If the hourly rate is recorded as 0, we set wage as missing, and
If the total hours of worked per week for the corresponding job is greater than 84 hr (12 hr/day every day), we set the wage and hours worked as missing.
The number of jobs (number_of_jobs) for each respondent per year is computed from the number of non-missing values of hourly wage. In other words, even if the information of hours worked exists for a particular observation, we do not tally when the hourly wage is missing.
#> # A tibble: 10 x 6 #> id year mean_hourly_wage total_hours number_of_jobs is_wm #> <int> <dbl> <dbl> <int> <dbl> <lgl> #> 1 1 1979 3.28 38 1 FALSE #> 2 1 1981 3.61 NA 1 FALSE #> 3 2 1979 3.85 35 1 FALSE #> 4 2 1980 4.57 NA 1 FALSE #> 5 2 1981 5.14 NA 1 FALSE #> 6 2 1982 5.71 35 1 FALSE #> 7 2 1983 5.71 NA 1 FALSE #> 8 2 1984 5.14 NA 1 FALSE #> 9 2 1985 7.71 NA 1 FALSE #> 10 2 1986 7.69 NA 1 FALSE
For the year of individual started working (stwork), we only rename the column names, which is EMPLOYERS_ALL_ STARTDATE_ORIGINAL.01˜Y_XRND, from new_data_ qnames. This variable is then used to calculate the next variable, the length of time in the workforce (yr_wforce) for each survey round, which is the year of survey (year) minus stwork. Finally, experience (exp) variable is derived from the number of weeks worked since the last interview indicated as variable started with WKSWK in new_data_qnames. To obtain the work experience since 1979, we calculate the cumulative value. As the measurement unit is weeks, we convert this to fractional year.
The employment and demographic variables are then merged into one dataset as in the original data. These data are further filtered to the cohort who participated in at least three rounds in the survey, the minimum observation recommended for longitudinal data in Singer and Willett (Citation2003). We also opt to restrict the minimum number of observations so that the data can be used to demonstrate within-person variation when it is used to teach longitudinal data. However, it is worth noting that the original data does not restrict the number of observations for each individual, that is, there are individuals with only one and two observations.
Finally, we save the resultant wage data on this cohort as wages. Note that we save the grade variable in this dataset instead of the demog_nlsy79 dataset because it is a longitudinal variable, while demog_nlsy79 is a cross-sectional dataset reflecting the state of individuals corresponding to the most recent round of the survey.
3.2 Calculated Variables: Work Experience
Work experience is one of the most important variables in Singer and Willett (Citation2003) as it indicates time and makes longitudinal analysis possible. It is desirable to calculate this rather than using the survey year for time because it more accurately reflects a person’s time in the workforce. Thus, in the spirit of refreshing the data to the newest round of the survey, this variable needs to be calculated from other variables provided. It is not straightforward. We start with the definition of experience in Singer and Willett (Citation2003).
Experience is defined as years after entering the labor force. It represents the difference between the day an individual enters the labor force (stwork) relative to the date of the survey, which we call yr_wforce. However, using this calculation produced numbers that do not quite match the original data.
Reading the section titled “Topical Guide to the Data” in the guide suggests it should be calculated based on the variable “number of weeks worked since the last interview.” This would remove periods of unemployment which makes sense when measuring experience while actually working. Since it is only measured since the last interview, this needs to be cumulated for each survey year. This produced results more similar to the original data (as discussed further in Section 4.3).
3.3 Initial Data Analysis
According to Huebner, Werner, and Cessie (Citation2016), initial data analysis (IDA) is the step of inspecting and screening the data after collection to ensure the data is clean, valid, and ready to be deployed in the later analyses. This is supported by Chatfield (Citation1985), who argues that the two main objectives of IDA are data description, which is to assess the structure and the quality of the data, and model formulation without any formal statistical inference.
In this article, we conduct an IDA or a preliminary data analysis to assess the validity of the variable values in the cohort of data that the NLSY provides. The first step is validating that the numerical summaries of the raw data are the same as reported by NLSY79. This is followed by graphical summaries using methods available in ggplot2 (Wickham Citation2016) and brolgar (Tierney, Cook, and Prvan Citation2020).
The respondents’ ages ranged from 12 to 22 when first interviewed in 1979. Hence, we validate whether all respondents were in this range in the data we extracted. Additionally, the NLSY also provides the number of the survey cohort by their sex (6403 males and 6283 females) and race (7510 Non-Black/Non-Hispanic; 3174 Black; 2002 Hispanic). To validate this, we used the demog_nlsy79, that is, the data with the survey years 1979 sample. and suggest the demographic data we had is consistent with the sample information in the database.
Table 1 Frequency table of the age at the start of the survey in NSLY79 cohort in the extracted data.
Table 2 Contingency table for sex and race for the extracted NLSY79 demographic data.
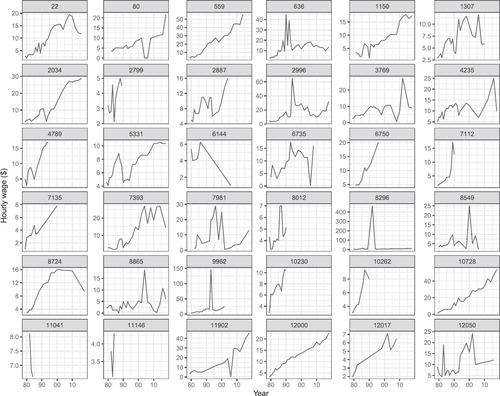
In the next step, we explore the mean hourly wage data of samples of individuals. The purpose is to examine the common patterns and check the quality. A random sample of 36 individuals is chosen (using the sample_n_keys function in brolgar). Their longitudinal profiles are plotted, faceted by id, and using free y scales so that the individual patterns can be examined (). There is a lot of variability from one individual to another and substantial fluctuation in wages at different times for most individuals. Some individuals (2799, 11,041, 11,146) are only measured for a short period. Some individuals (8296, 9962) possibly have errors in wages in some years because of the extreme fluctuation. These need to be inspected more closely. It is also important to note that some shorter profiles indicate some individuals have left the study before it has finished. Checking whether the demographics of the early departing are similar to those who remain in the study is an important part of any downstream analysis to account for the bias induced by the inadvertent censoring.
Fig. 2 Longitudinal profiles of wages for a random sample of 36 individuals in the pre-cleaned data. There is considerable variation in wages. Some individuals (2799, 11,041, 11,146) are only measured for a short period. Some individuals (8296, 9962) possibly have errors in wages in some years, because of the extreme fluctuation.
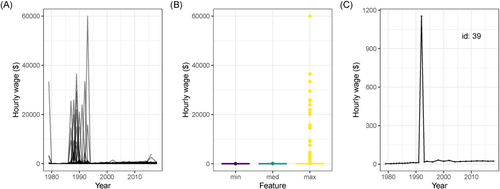
shows an alternative way to check the data quality. Plot (A) is the spaghetti plot where all profiles are shown, and it can be seen that there are unbelievably high wage values (up to $60,000/hr) for some individuals, mostly around 1990. Plot (B) shows side-by-side boxplots of the three number summaries (minimum, median, and maximum) for all individuals. This tells us there are a number of individuals with unbelievably high maximum wages. Plot (C) shows the profile for an individual with a maximum wage that is not so extreme but still indicates a problem: their wages are consistently low except for one year where they earned close to $1200/hr. This does not seem to be reasonable and leads us to use a procedure to detect and fix these temporal anomalies.
Fig. 3 Summary plots to check the data after the tidying stage: (A) longitudinal profiles of wages for all individuals 1979–2018, (B) boxplots of minimum, median, and maximum wages of each individual, (C) and one individual (id = 39) with an unusual wage relative to their years of data. It reveals that some values of hourly wages are unbelievable, and some individuals have extremely unusual wages in some years. Accordingly, more cleaning is necessary to treat these extreme values.
Extremely high values were also found in the total hours of work, where some observations reported having worked for 420 hr a week in total. According to Pergamit et al. (Citation2001), one of the flaws of the NLSY79 employment data is the NLSY79 collects the information of the working hours since the last interview. Thus, it might be challenging for the respondents to track the within-job hours’ changes between survey years, especially for the respondents with fluctuating working hours or seasonal jobs. It even has been more challenging since 1994, after which respondents were only surveyed every other year and thus, had to recall two full years’ job history. This shortcoming might also contribute to the fluctuation of one’s wages data.
3.4 Replacing Extreme Values
A robust linear regression model using the rlm function from MASS package (Venables and Ripley Citation2002) is used to treat the extreme values in the data. The robustness weight (calculated with the Huber method) is used to determine if a value should be replaced with the fitted value from the model. This is constructed for each ID using the nest and map function from tidyr (Wickham and Hester Citation2020) and purrr (Henry and Hadley Citation2020), respectively. An alternative approach would be a robust linear mixed model using robustlmm (Koller Citation2016).
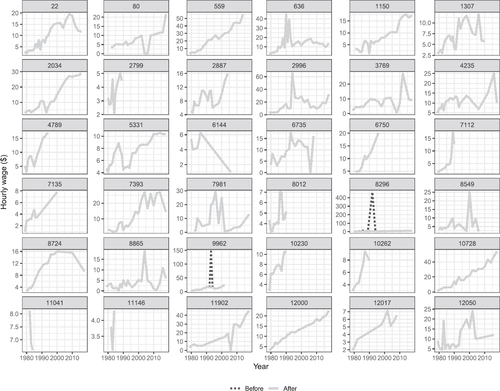
shows the profiles for a sample of 30 individuals the mean hourly wage before and after extreme values are replaced. The plot shows fluctuations in wages remain, but the large spikes (in this sample, individuals 8296, 9962), which are considered implausible, are replaced.
Fig. 4 Comparison between the original (black dots) and the corrected (solid gray) mean hourly wage for same sample of individuals as shown in . A robust linear model prediction was used to identify and correct mean hourly wages value. The extreme spikes, corresponding to implausible wages, have been replaced with values more similar to wages in neighboring years for individuals 8296 and 9962, but otherwise the profiles have not changed.
The challenging part of detecting an anomaly using the robustness weight is determining the weight threshold beyond which the observations are considered outliers. It is also important not to be too aggressive in outlier removal, because this would overly smooth the data, and ignore actual workforce experiences important wage volatility such as, abnormally high wages for a fleeting amount of time. To explore the risk of being overly vigorous in labeling observations as outliers, a range of threshold value were assessed. Numerous samples of individuals were drawn for each threshold, and the smoothness of the profiles was examined. Overly smooth profiles would indicate the replacement of values was too severe, resulting in removing the very interesting volatility of wages seen in many individuals. This was achieved using a purpose written shiny (Chang et al. Citation2020) app (provided with the code of this article). Observations where a change was made are tracked with a new variable called is_pred, so that this effect in the downstream analyses can be monitored.
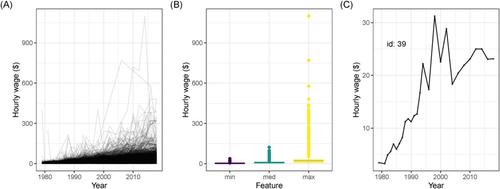
shows the summary statistics after removing extremes. The highest wage overall is now around $1000. Plot (A) shows a more reasonable spaghetti plot, where there are some profiles with high wages, but most profiles have wages under $300, and there has been a steady increase in wages over the years. Plot (B) shows there are still a small number of individuals with high maximum wages. Plot (C) shows the profile for ID = 39 after imputing the extreme value. The wages for this individual increase over the years, and do fluctuate some between 1900 and 2005.
Fig. 5 Remake of the summary plots of the fully processed data suggest it is now in a reasonable state: (A) longitudinal profiles of wages for all individuals 1979–2018, (B) boxplots of minimum, median, (C) and maximum wages of each individual, and one individual with an unusual wage relative to their years of data.
3.5 Recap
There are many steps and decisions made to go from raw to input to valid data. summarizes these in order to create a refreshed wages dataset.
Fig. 6 The stages of data cleaning from the raw data to get three datasets contained in yowie. “# of individuals” means the number of respondents included in each stage, while “# of observations” means the number of rows in the data. The color represents the stage of data cleaning in the statistical value chain (M. P. J. van der Loo and de Jonge Citation2021). Pink, blue, and green represent the raw, input, and valid data, respectively.
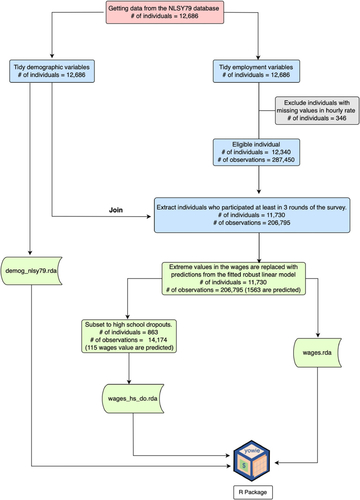
The list of variables provided in the three new datasets are as follows:
demog_nlsy79:
id: A unique individual’s ID number.
age_1979: The age of the individual in 1979.
sex: Sex of the individual, f = Female and m = Male.
race: Race the individual belongs to, NBH = Non-Black, Non-Hispanic; H = Hispanic; B = Black.
hgc: The highest grade completed ever.
hgc_i: Integer value of the highest grade completed ever.
hgc_1979: The highest grade completed in 1979 (integer value).
ged: Whether the individual had a high school diploma or Graduate Equivalency Degree (GED). 1: High school diploma; 2: GED; 3: Both.
wages and its subset for high school dropouts cohort wages_hs_do:
id: A unique individual’s ID number. This is the key of the data as we saved the data as a tsibble object.
year: The year the observation was taken. This is the index of the data.
wage: The mean of the hourly wages the individual gets at each of their different jobs. The value could be a weighted or an arithmetic mean. The weighted mean is used when the information of hours of work as the weight is available. The mean hourly wage could also be a predicted value if the original value is considered influential by the robust linear regression as part of data cleaning.
age_1979: The age of the individual in 1979.
sex: Sex of the individual, f = Female and m = Male.
race: Race of the individual belong to, NBH = Non-Black, Non-Hispanic; H = Hispanic; B = Black.
grade: Integer value of the highest grade completed corresponding to the survey year.
hgc: The highest grade completed ever.
hgc_i: Integer value of the highest grade completed ever.
hgc_1979: The highest grade completed in 1979 (integer value).
ged: Whether the individual had a high school diploma or Graduate Equivalency Degree (GED). 1: High school diploma; 2: GED; 3: Both.
njobs: Number of jobs that an individual has.
hours: The total number of hours the individual usually works per week.
stwork: The year when the individual started to work.
yr_wforce: The length of time in the workforce in years (year - stwork).
exp: Work experience, that is, the number of years of working.
is_wm: Whether the mean hourly wage is weighted mean, using the hour work as the weight, or regular/arithmetic mean. TRUE = is weighted mean. FALSE = is regular mean.
is_pred: Whether the mean hourly wage is a predicted value of RLM or not.
4 Comparison of Refreshed with the Original Data
The original set, containing wages of high school dropouts (Singer and Willett Citation2003) from 1979 through to 1994, is available in the R package brolgar (Tierney, Cook, and Prvan Citation2020). To compare the refreshed data with the original, a subset needs to be matched. There are numerous ways to do this, with the simplest being to extract the individuals based on their id being part of the original data and restricting the longitudinal measurements to the same years. However, we decided to try to replicate the process, as suggested by the description of the original data. This requires first identifying individuals who dropped out of high school.
4.1 Filtering: Determining who is a Dropout
There is no explicit explanation of how the dropouts cohort is determined in the original data. Hence, we use the high school dropouts criteria from Wolpin (Citation2005), which are:
An individual whose highest grade completed (hgc) is reported to be less than 12th grade, or
An individual whose highest grade completed (hgc) is reported to be at least 12th grade and has received a GED (i.e. ged code is 2).
An additional criterion from Singer and Willett (Citation2003) is to only include males aged between 14 and 17 years old in 1979. With this filtering, we obtained 670 individuals in the refreshed data compared to 888 individuals in the original data. To investigate the reason for the difference, individuals from the original and refreshed dataset were matched by id. This revealed several reasons for the disparity:
173 individuals were more than 17 years old in 1979. Thus, it looks like the description of the original data, that there are people older than 17 in the subset, is not quite accurate. Our decision is to also include them in the refreshed data as the new data contains an age variable, so analysts could filter them later.
79 individuals were less than or equal to 17 years old in 1979. However, they were not captured in the refreshed data because:
35 of them completed at least 12th grade with a diploma instead of GED (ged variable is coded as 1). This suggests they are not dropouts, and so we excluded them from the refreshed data.
The information about ged is missing in 38 individuals. We decided to include them in the refreshed data.
Three individuals have both diploma and GED (ged is coded as 3). These were kept in the refreshed data.
12 individuals do not exist in wages data because they have participated in less than three rounds of the survey.
The filtering was reapplied using these decisions, resulting in a refreshed dropout subset containing 863 individuals.
4.2 Summaries of Original with Refreshed Dropouts Data
Because the original data does not have the year of collection, it is not possible to merge the two subsets directly. Merging longitudinal data requires both the key (id) and the index (ideally survey year). In the original data, the experience variable is the time index, and it was not possible to exactly match this for the refreshed data. Thus, comparisons of the two sets have to be conducted in a two-sample fashion rather than a matched sample.
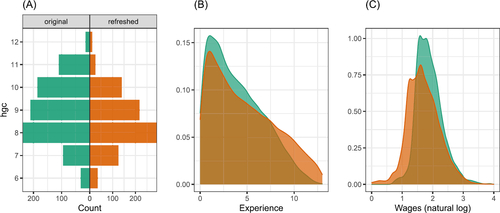
contains summaries of corresponding variables in the two subsets. Plot (A) shows a back-to-back bar chart of the highest grade completed. The two sets are almost the same, but small differences remain. Plots (B) and (C) show stacked density plots of experience and log wages, respectively. The distributions are relatively close, with more differences in wages as would be expected because the refreshed data is not inflation-adjusted.
Fig. 7 Comparison of original and refreshed data: (A) highest grade completed, (B) experience, and (C) log wages. Some difference in wages would be expected because the refreshed data is not inflation-adjusted, but the two sets are reasonably similar.
4.3 The Takeaways
There are several aspects of the original data that were difficult to replicate. The calculation of the work experience is not clearly articulated. Singer and Willett (Citation2003) describe the temporal variable as the years of experience since the first day of work. This variable is not explicitly available in the database. From the NLSY79 topical guide (Bureau of Labor Statistics, U.S. Department of Labor Citation2021b), we find several variables are tagged as work experience-related variables. One of them is the weeks worked since the last interview. This is used to calculate the variable. It produces reasonably similar but not exactly the same values. Because the original dataset did not include the year of the survey, it cannot be precisely compared.
The variables from “highest grade completed” have some confusion. There are several ways this is reported, including the highest grade ever completed and also the hgc at each survey year. To match the original data, it is appropriate to use the hgc while in high school. The documentation suggests this variable is available, but it is actually not. Hence, to match the original data, we have calculated the hgc to match the hgc achieved in the years between 1979 and 1994 based on the yearly survey value. The result does not exactly match the original for a few individuals.
In the original dataset, wages were inflation-adjusted to 1990 prices. This is not done for the refreshed data because we plan to keep refreshing it as the data is added to and released from the survey. Instead, we have provided a function called adj_inflation in the R package, yowie, for users to conduct the inflation adjustment when they are ready to analyze the data.
It is important to note that the treatment of unlikely wages differs in the refreshed data. In the original data by Singer and Willett (Citation2003), wages greater than $75 are set to be missing. However, this value is too low to be set as the maximum threshold, and it doesn’t take into account temporal neighbors for an individual. We opted to use the weights from a robust linear regression to determine what should be regarded as extreme and imputed them with their predicted values as described in Section 3.4.
Finally, the matching of individuals in the dropouts subset of the refreshed data with the original data was done using their ids. (Only males were in the original data.) It was comforting to see that all of the individuals in both sets do match on sex (all are male!), and race.
5 Summary and Discussion
Any longitudinal dataset used for education should have a sufficiently reproducible process to be refreshed with new data. The NLSY79 dataset is a great teaching tool that has become outdated, both because the dataset stops in 1994, and because the demographic data could be handled more delicately. This article has illustrated the necessary steps and decisions made to take a particular open dataset and make it a textbook dataset, ready for the classroom or research. In the first stage, we showed the steps performed to get the data from the NLSY79 database. The data format was converted to a tidy format for more flexibility in cleaning and exploring. Initial data analysis was conducted to investigate and screen the quality of the data. We found and provided a fix for many anomalous observations in wages using a robust linear regression model. The refreshed data is compared with the original set using a variety of numerical summaries and graphics. The current subset is made available in a new R package, called yowie.
The data cleaning process is documented, and the code has been made available. These provide the opportunity to again refresh the textbook data as new data is published into the NLSY79 database. Determining an appropriate robustness weight from which to threshold unusual observations was conducted using a shiny (Chang et al. Citation2020) app, which is provided with the code, and the choices used in the refreshed data are documented.
Various difficulties were encountered in trying to refresh the data, which include:
Determining which records should be downloaded from the database.
Calculating experience in the workforce requires comparing the date of the first job with the first year the individual was recorded, both of which are available in the database.
Treating the extreme values since there are many unusually high hourly wages, for example, greater than $60,000 per hour.
Determining the dropouts subset as there is no explicit variable in the database recording high school dropout, which means we needed to compare the date of 12th grade with their GED status.
Matching IDs from the original data with those in the refreshed data do refer to the same person based on the demographic information available.
Ultimately, the refreshed data is reasonably similar to the original. The last step required would be to inflation-adjust wages. This is better to do with each wave of new data added so that it is relative to the last date in the data. Our decision was to provide the raw wages and include code to make the adjustment as part of the package.
Some readers may disagree with our decisions made to produce the refreshed textbook data and may have better insight than us in producing more appropriate textbook data. We do not assert that we have produced the best textbook data, but rather we describe our journey to provide a reasonable textbook dataset. All code and documentation are provided for transparency. Readers could use this to make different decisions or provide suggestions through the package for better choices. Future updates of the yowie package may contain additional variables, or filters of the full set if it is deemed important.
For the data providers, we recommend a better validation system with clear rules applied at data entry and alternative output formats, such as a tidy format, which would help users better use their resources. The problem with many wages records is that there are implausible values or confusion on how to record wages for multiple jobs. These values can be validated with simple checks at data entry. Providing an open data resource is also accompanied by the responsibility that the data, especially as valuable as this, is reliable. Users need to be able to trust the data.
Why is the work presented here useful for teachers and students? There are several reasons:
It primarily illustrates the steps in cleaning and processing a well-known longitudinal data so that it can be further refreshed as a textbook dataset as new data emerges. Choices made during the cleaning and processing can affect findings made with the data, are transparent, and can be a basis for classroom discussions.
Some of the methods shown, and lessons learned about the data, can also be considered to be useful for working with other datasets, and also apply generally for data cleaning, initial data analysis and exploratory data analysis.
The refreshed data can be used for teaching advanced linear modeling, using almost identical code from Singer and Willett (Citation2003), and thus, make those lessons more current for today’s students.
It provides the data to develop a case study for teaching exploratory data analysis of longitudinal data, focusing on the individual experience. The vignettes of the brolgar (Tierney, Cook, and Prvan Citation2020) package provide useful guides for the case study content.
The wages data provides a good opportunity to discuss the difference between statistics for public policy and statistics that relate to the individual. Public policy is based on models, yielding averages that might vary across strata. Modeling the wages relative to workforce experience with demographic covariates, we learn that there are significantly different patterns. More education leads to increasingly higher wages, which is a satisfying result for educators. It means education makes a difference in the wage experience, so public policy encouraging education is a data-supported action. We would also learn, although not presented here, that wages on average differ by race category. This is a disturbing finding because there is no rationale for such a difference in a fair society. This would provide support for action in public policy to remove this overall average effect. It also provides an example for educators to explain the use of data to support public policy action.
On an individual level, people might want to see how their characteristics relate to those in the dataset. To do this, the individual profiles need to be explored. Predominantly, we would learn the variation from one individual to another is far more than the variation between demographic strata. For example, many individuals with lower educational attainment earn very high wages. From a statistics and data science educator perspective, more focus and more methodology for this type of statistics need to be included in the curriculum.
The above interpretations of results from analyzing the wages data rely on trusting that the data provided is accurate and valid. The wages data is collected by a reputable organization, but we found the data has obvious errors that should be corrected. This article has illustrated procedures and guidelines to achieve valid data and provides the code and details for it to be reproduced and modified if deemed appropriate.
Having trustworthy data is imperative for statistics and data science education. Whenever one uses a textbook dataset that is perceived as relating to the students’ lives, there will be interpretations made. The wages data is an example of this. Students can take away multiple interpretations from the data (e.g., wages increase with experience, education, and race) based on the teaching focus to learn about the world. If one uses data examples that are synthetic, instilled with our own inherent prejudices (e.g., sex and race), or data that has been poorly processed containing errors, we, as educators, are being irresponsible because the societal message taught to students may be flawed. This article demonstrates the process of producing a trustworthy dataset for teaching.
Supplementary Materials
Code: R script to reproduce data tidying and cleaning is available at https://numbats.github.io/yowie/articles/process-data.html. The code for the extreme value handling with robust linear fits is in https://numbats.github.io/yowie/articles/input-to-valid-data.html.
R Package: yowie is an R data package that contains three datasets, namely the high school mean hourly wage data, high school dropouts mean hourly wage data, and demographic data of the NLSY79 cohort. This package can be accessed from https://github.com/numbats/yowie.
shiny app: An interactive shiny web app to visualize the effect of selecting different weight threshold for substituting the wages data to its predicted value from a fit of the robust linear regression model. This app can be accessed at https://ebsmonash.shinyapps.io/yowie_app/ with the source code provided https://github.com/numbats/yowie/tree/master/inst/app.
supplementary_materials.zip
Download Zip (4.3 MB)Acknowledgments
The authors would like to thank Aarathy Babu for the insight and discussion during the writing of this article. The entire analysis is conducted using R (R Core Team Citation2020) in RStudio IDE using these packages: tidyverse (Wickham et al. Citation2019), ggplot2 (Wickham Citation2016), dplyr (Wickham and Hester Citation2020), readr (Wickham and Hester Citation2020), tidyr (Wickham and Hester Citation2020), stringr (Wickham et al. Citation2019), purrr (Henry and Hadley Citation2020), brolgar (Tierney, Cook, and Prvan Citation2020), patchwork (Pedersen Citation2020), kableExtra (Zhu Citation2019), MASS (Venables and Ripley Citation2002), janitor (Firke Citation2020), and tsibble (Wang, Cook, and Hyndman Citation2020). The article was generated using knitr (Xie Citation2014) and rmarkdown (Xie, Dervieux, and Riederer Citation2020). The authors also wish to thank the reviewers of this article for greatly helping to improve it.
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within the supplementary materials.
Disclosure Statement
There are no competing interests to declare.
Funding
The research was not specifically funded by any organisation
References
- Anderson, E. (1935), “The Irises of the Gaspe Peninsula,” Bulletin of the American Iris Society 59, 2–5.
- Bureau of Labor Statistics, U.S. Department of Labor. (2021a), “National Longitudinal Survey of Youth 1979 Cohort, 1979-2016 (Rounds 1-28),” Produced and distributed by the Center for Human Resource Research (CHRR), The Ohio State University. Columbus, OH. Available at https://www.nlsinfo.org/bibliography-citing-nls-data.
- Bureau of Labor Statistics, U.S. Department of Labor. (2021b), “National Longitudinal Survey of Youth 1979 Cohort, Topical Guide to the Data,” available at https://www.nlsinfo.org/content/cohorts/nlsy79/topical-guide/employment/work-experience.
- Chang, W., Cheng, J., Allaire, J. J., Xie, Y., and McPherson, J. (2020), shiny: Web Application Framework for R. Available at https://CRAN.R-project.org/package=shiny.
- Chatfield, C. 1985. “The Initial Examination of Data,” Journal of the Royal Statistical Society, Series A, 148, 214–253.
- Cooksey, E. C. (2017), “Using the National Longitudinal Surveys of Youth (NLSY) to Conduct Life Course Analyses,” in Handbook of Life Course Health Development, eds. R. M. Lerner, N. Halfon, and C. B. Forrest, pp. 561–577, Cham: Springer. DOI: 10.1007/978-3-319-47143-3_23..
- Dasu, T., and Johnson, T. (2003), Exploratory Data Mining and Data Cleaning. Wiley Series in Probability and Statistics, Hoboken: Wiley.
- Firke, S. (2020), janitor: Simple Tools for Examining and Cleaning Dirty Data. Available at https://CRAN.R-project.org/package=janitor.
- Fullilove, M. T. (1998), “Comment: Abandoning “Race” as a Variable in Public Health Research–an Idea Whose Time Has Come,” American Journal of Public Health, 88, 1297–1298.
- Grimshaw, S. D. (2015), “A Framework for Infusing Authentic Data Experiences Within Statistics Courses,” The American Statistician 69, 307–314. DOI: 10.1080/00031305.2015.1081106..
- Heidari, S., Babor, T. F., De Castro, P., Tort, S., and Curno, M. (2016), “Sex and Gender Equity in Research: Rationale for the SAGER Guidelines and Recommended Use,” Research Integrity and Peer Review 1, 1–9. 10.1186/s41073-016-0007-6.
- Henry, L., and Hadley, W. (2020), purrr: Functional Programming Tools. Available at https://CRAN.R-project.org/package=purrr.
- Horst, A., Marie, A., Hill, P., and Gorman, K. B. (2020), Palmerpenguins: Palmer Archipelago (Antarctica) Penguin Data. Available at DOI: 10.5281/zenodo.3960218..
- Huebner, M., Werner, V., and Cessie, S. L. (2016), “A Systematic Approach to Initial Data Analysis Is Good Research Practice,” The Journal of Thoracic and Cardiovascular Surgery 151, 25–27. DOI: 10.1016/j.jtcvs.2015.09.085.
- Ilk, O. (2004), “Exploratory Multivariate Longitudinal Data Analysis and Models for Multivariate Longitudinal Binary Data,” PhD thesis, Iowa State University. DOI: 10.31274/rtd-180813-11012.
- Kennedy, L., Khanna, K., Simpson, D., and Gelman, A. (2020), “Using Sex and Gender in Survey Adjustment,” available at https://arxiv.org/abs/2009.14401.
- Kim, A. Y., Ismay, C., and Chunn, J. (2018), “The Fivethirtyeight R Package: “Tame Data” Principles for Introductory Statistics and Data Science Courses,” Technology Innovations in Statistics Education, 11, 1–22. DOI: 10.5070/T511103589..
- Koller, M. (2016), “robustlmm: An R Package for Robust Estimation of Linear Mixed-Effects Models,” Journal of Statistical Software 75, 1–24. DOI: 10.18637/jss.v075.i06.
- Moncrief, M. (2015), “By the Numbers – the Average Australian Doesn’t Exist… Not a Single One of Us Is ‘Normal’,” available at https://bit.ly/smh-not-normal.
- Office of Management and Budget. (1997), “Revisions to the Standards for the Classification of Federal Data on Race and Ethnicity,” available at https://www.govinfo.gov/content/pkg/FR-1997-10-30/pdf/97-28653.pdf.
- Open Knowledge Foundation. (2021), “Open Definition. Defining Open in Open Data, Open Content, and Open Knowledge,” available at http://opendefinition.org/od/2.1/en/.
- Pedersen, T. L. (2020), patchwork: The Composer of Plots. https://CRAN.R-project.org/package=patchwork.
- Pergamit, M. R., Pierret, C. R., Rothstein, D. S., and Veum, J. R. (2001), “Data Watch: The National Longitudinal Surveys,” The Journal of Economic Perspectives, 15, 239–53. DOI: 10.1257/jep.15.2.239.
- R Core Team. (2020), R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available at https://www.R-project.org/.
- Singer, J. D., and Willett, J. B. (2003), Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence, Oxford: Oxford University Press.
- Stodel, M. (2020), “Stop Using Iris,” available at https://www.meganstodel.com/posts/no-to-iris/.
- Tierney, N., Cook, D., and Prvan, T. (2020), brolgar: BRowse Over Longitudinal Data Graphically and Analytically in R, available at https://github.com/njtierney/brolgar.
- Tukey, J. W. (1977), Exploratory Data Analysis. Addison-Wesley Series in Behavioral Science. Reading, MA: Addison-Wesley Pub. Co.
- Unwin, A., and Kleinman, K. (2021), “The Iris Data Set: In Search of the Source of Virginica,” Significance 18, 26–29. DOI: 10.1111/1740-9713.01589..
- van der Loo, M. P. J., and de Jonge, E. (2021), “Data Validation Infrastructure for R,” Journal of Statistical Software, 97, 1–31. DOI: 10.18637/jss.v097.i10..
- van der Loo, M., and de Jonge, E. (2018), Statistical Data Cleaning with Applications in R, Hoboken: Wiley.
- Venables, W. N., and Ripley, B. D. (2002), Modern Applied Statistics with S (4th ed.), New York: Springer. Available at http://www.stats.ox.ac.uk/pub/MASS4.
- Wang, E., Cook, D., and Hyndman, R. J. (2020), “A New Tidy Data Structure to Support Exploration and Modeling of Temporal Data,” Journal of Computational and Graphical Statistics 29, 466–478. DOI: 10.1080/10618600.2019.1695624..
- Wickham, H. (2011), “The Split-Apply-Combine Strategy for Data Analysis,” Journal of Statistical Software, 40, 1–29. DOI: 10.18637/jss.v040.i01..
- Wickham, H. (2014), “Tidy Data,” Journal of Statistical Software 59, 1–23.
- Wickham, H. (2016), ggplot2: Elegant Graphics for Data Analysis, New York: Springer-Verlag. Available at https://ggplot2.tidyverse.org.
- Wickham, H. (2019), stringr: Simple, Consistent Wrappers for Common String Operations. Available at https://CRAN.R-project.org/package=stringr.
- Wickham, H. (2020), tidyr: Tidy Messy Data. Available at https://CRAN.R-project.org/package=tidyr.
- Wickham, H., Averick, M., Bryan, J., Chang, W., D’Agostino McGowan, L., François, R., Grolemund, G., Hayes, A., Henry, L., Hester, J., Kuhn, M., Pedersen, T. L., Miller, E., Bache, S. M., Müller, K., Ooms, J., Robinson, D., Seidel, D. P., Spinu, V., Takahashi, K., Vaughan, D., Wilke, C., Woo, K., and Yutani, H. (2019), “Welcome to the Tidyverse,” Journal of Open Source Software, 4, 1686. DOI: 10.21105/joss.01686..
- Wickham, H., François, R., Henry, L., and Müller, K. (2020), dplyr: A Grammar of Data Manipulation. Available at https://CRAN.R-project.org/package=dplyr.
- Wickham, H., and Hester, J. (2020), readr: Read Rectangular Text Data. Available at https://CRAN.R-project.org/package=readr.
- Wolpin, K. I. (2005), “National Longitudinal Survey of Youth 1979 Cohort, 1979-2016 (Rounds 1-28),” Published by Bureau of Labor Statistics, U.S. Department of Labor. Available at https://www.bls.gov/opub/mlr/2005/02/art3full.pdf.
- Xie, Y. (2014), “Knitr: A Comprehensive Tool for Reproducible Research in R,” in Implementing Reproducible Computational Research, eds. V. Stodden, F. Leisch, and R. D. Peng, pp. 3–31, Boca Raton, FL: Chapman and Hall/CRC. Available at http://www.crcpress.com/product/isbn/9781466561595.
- Xie, Y., Dervieux, C., and Riederer, E. (2020), R Markdown Cookbook. Boca Raton, Florida: Chapman; Hall/CRC. Available at https://bookdown.org/yihui/rmarkdown-cookbook.
- Zhu, H. (2019), kableExtra: Construct Complex Table with ’kable’ and Pipe Syntax. Available at https://CRAN.R-project.org/package=kableExtra.