Figures & data
Table 1. The description of the clips used in the experiment, as provided in Schaefer et al. (Citation2010).
Figure 1. Tactile Self-Assessment Manikin (Iturregui-Gallardo & Méndez-Ulrich, Citation2020).
Figure 2. Interaction of intonation type with valence. Bars represent standard error.
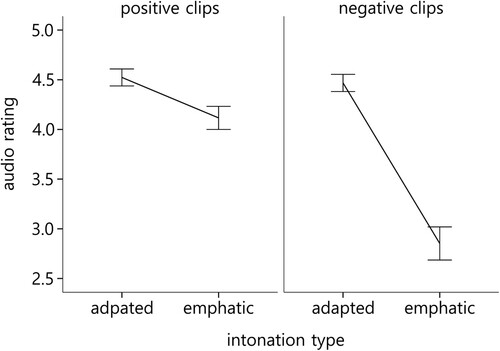
Figure 3. Relation between presence scale and audio ratings predicted by the model plotted separately for every condition with overlaid linear regression (solid lines) and 95% CIs (dashed lines).
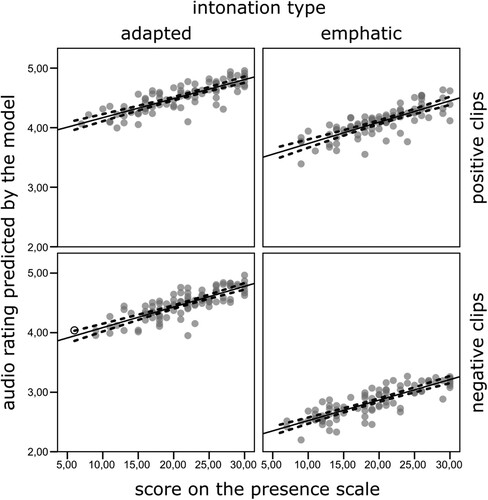
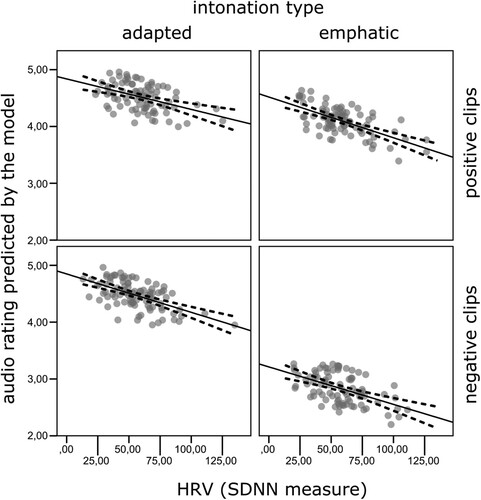
Figure 4. Relation between heart rate variability (SDNN measure) and audio ratings predicted by the model plotted separately for every condition with overlaid linear regression (solid lines) and 95% CIs (dashed lines).