
Figures & data
Table 1. Measures of inter-participant agreement (internal reliability) for those participants whose ratings met the criteria of test–retest reliability and criterion validity. For the KMO, a value of at least .5 is usually required and values of .8 are considered ‘meritorious’ (Kaiser, Citation1974). A significant p-value on the Bartlett test indicates that correlations exist in the population and for Cronbach’s alpha values of
.7 are generally considered ‘good’.
Table 2. Regression coefficients for a linear model predicting mean similarity ratings by types and numbers of errors.
Table 3. Pearson correlation coefficients between (asymmetric, unnormalised) and listeners’ mean similarity ratings in Experiments 1–3. The top section shows results for viewpoints predicting pitch, the middle section results for viewpoints predicting Onset and the bottom section shows the best performing viewpoint systems for predicting both pitch and onset. The three rows in the bottom section indicate the viewpoint systems yielding the highest correlation for Experiments 1, 2 and 3, respectively.
Table 4. Pearson correlation coefficients between (asymmetric, normalised) and listeners’ mean similarity ratings in Experiments 1–3. The top section shows results for viewpoints predicting Pitch, the middle section results for viewpoints predicting Onset and the bottom section shows the best performing viewpoint systems for predicting both pitch and onset. The three rows in the bottom section indicate the viewpoint systems yielding the highest correlation for Experiments 1, 2 and 3, respectively.
Table 5. Pearson correlation coefficients between (symmetric, normalised) and listeners’ mean similarity ratings in Experiments 1–3. The top section shows results for viewpoints predicting pitch, the middle section results for viewpoints predicting Onset and the bottom section shows the best performing viewpoint systems for predicting both pitch and onset. The three rows in the bottom section indicate the viewpoint systems yielding the highest correlation for Experiments 1, 2 and 3, respectively.
Table 6. Pearson correlation coefficients between (Li et al., Citation2004) and listeners’ mean similarity ratings in Experiments 1–3. The top section shows results for viewpoints predicting pitch, the middle section results for viewpoints predicting Onset and the bottom section shows the best performing viewpoint systems for predicting both pitch and onset. The three rows in the bottom section indicate the viewpoint systems yielding the highest correlation for Experiments 1, 2 and 3, respectively.
Figure 1. Correlation between mean similarity ratings and compression distance from the best-fitting IDyOM model on each experiment for each similarity measure (see models marked with an asterisk in Tables – for ,
,
and
, respectively) using order bounds ranging from 0 to 8. The variable-order model with unbounded order is indicated by ‘nil’.
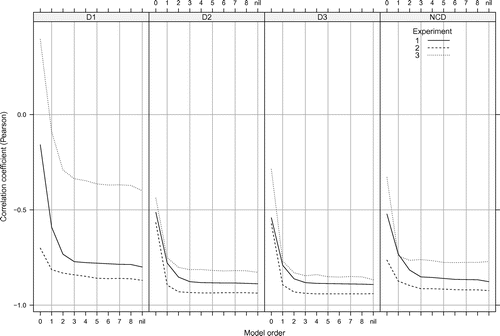
Table 7. Coefficients for the Pearson correlation between the edit distance and opti3 similarity measures reported by Müllensiefen & Frieler (Citation2004) and listeners’ mean similarity ratings in Experiments 1–3. Figures in brackets indicate 95 confidence intervals. See main text for details of the algorithms. In the lower panel, results for the best-fitting models for each experiment are reproduced from Table for comparison.
Table 8. Results for the MIREX 2005 melodic similarity task taken from Typke et al. (Citation2005). Algorithms are ordered by performance in terms of ADR. Results for the compression-based model are in italics and superscript numbers indicate the rank for the four best-performing algorithms in terms of NRGB, AP and PND. ADR is ADR, NRGB is Normalised Recall at Group Boundaries, AP is Average Precision and PND is Precision at N Documents. See text for further details.
Table A1. Coefficients for the Pearson correlation between three similarity algorithms (edit distance, opti3 and ) and mean similarity ratings for all participants in Experiments 1-3. Figures in brackets indicate 95% confidence intervals. See main text for details of the algorithms. The parameters of the
models correspond exactly to those shown in Table .