Figures & data
Figure 1. Models of visual search. (a) The canonical sequence of visual search stages. When an individual sets out to look for an object (e.g., a tomato), first a template needs to be prepared and set up in VWM (preparation stage). Once the search display appears and the visual input enters the system, the template, through recurrent feedback mechanisms, interacts with the visual information and guides attention towards regions that match the target feature(s). Finally, the template may be used to confirm that the selected information is indeed what an observers was looking for. (b) Theoretical possibilities for the capacity of multiple-target search. Search for multiple targets can be subject to unlimited processing (multiple targets can be sought for at the same time with similar efficiency), limited parallel processing (multiple targets can be sought for at the same time, but the more targets are searched for, the less efficient search becomes), limited serial processing (only one item can be processed at a time, and observers need to alternate between searching for each target), or weighted parallel processing (multiple targets can be sought for at the same time, but search targets differ in relative priority).
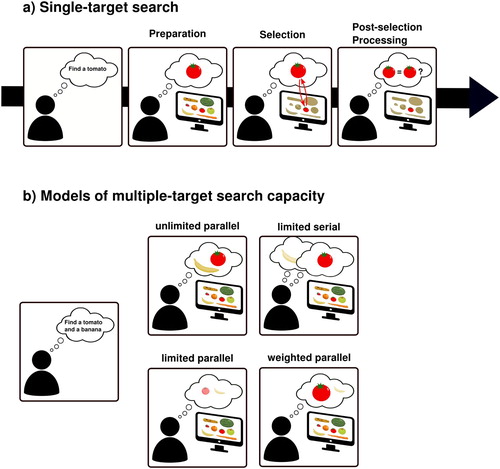
Table 1. Schematic description of possible architectures underlying MTS. Note that any of these limitations can be present at any search-related processing stage.
Figure 2. Commonly used paradigms to test the capacity of multiple-target search. (a) Multiple-target cost. Individuals have to either look for one or for multiple targets in a search display. If performance is lower for the multiple-target search compared to the single-target search, one speaks of a multiple-target cost. This cost is indicative that the capacity of multiple-target search is limited. Figure adapted from Houtkamp and Roelfsema (Citation2009). (b) Redundancy gain. If individuals have to report the presence of either of two target items in a search display, responses are usually faster when both are present in the search. This alone is to be expected under serial and parallel models. However, if responses are faster than the fastest response to a single target – a so-called race model violation – this would be evidence that both target items guided attention in an integrated way, indicative of co-active parallel visual search. Figure adapted from Bahle et al. (Citation2019). (c) Switch cost. If looking for multiple targets at the same time is not possible, individuals have to alternate between two single-target searches in order to find all targets. This alternation is considered a costly process. Therefore, when observers are being instructed to look for two targets and the relevant target either repeats or changes across trials, less efficient search (slower search times, or lower accuracy) on switch trials compared to repeat trials suggests that individuals indeed alternated, and did not look for both targets simultaneously. Figure adapted from Ort et al. (Citation2017). (d) Foraging tasks – run length. individuals are instructed to select all targets from a cluttered display with many targets presented among distractors. It is assumed that under a serial model individuals would try to avoid switch costs and stick to the same target for longer runs. Conversely, short run lengths, mimicking random selections of targets, are consistent with multiple parallel biases. During feature multiple-target search (targets: red & green), run lengths are close to what would be expected by random selection of either target (consistent with parallel MTS), whereas during conjunction MTS (targets: red squares & green circles) runs are much longer (suggesting serial MTS). Figure adapted from Kristjánsson et al. (Citation2014). (e) Memory-based attentional capture. Participants are instructed to memorize an item for a later memory task. Prior to the memory test however, an unrelated search is injected, in which participants need to find a shape singleton. On different trials, zero, one, or two of the memorized colours could appear in the search display as distractors. Capture by memory-matching distractors is evidence that those colours guided attention. Figure adapted from Hollingworth and Beck (Citation2016).
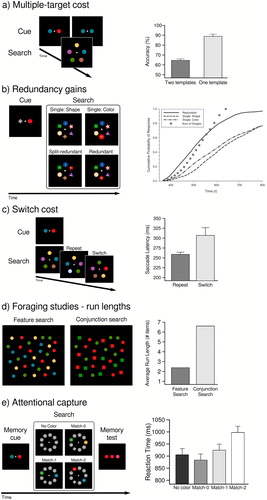
Figure 3. Dissociating template preparation versus selection using EEG. (a) Design. In all conditions, observers were required to select two target characters and determine whether they were of the same (i.e., both letters or both digits) or different category (i.e., letter and digit). Depending on the condition, either one or two colours were cued to be task-relevant in the beginning of a block (thus creating one vs. two unique templates). In addition, whenever two colours were cued, targets in the search displays would be of one or of two colours (thus one vs. two unique target features had to be selected). Consequently, in the one-template-one-target-feature condition (1TMP–1TGT) one colour was cued, and both targets carried this colour in the search display, in the two-templates-one-target-feature condition (2TMP–1TGT) two colours were cued but only one of these colours was present in the search display with both targets carrying that colour, and in the two-template-two-target-feature condition (2TMP–2TGT) two colours were cued and both colours were present in the search displays. One target always appeared on the horizontal meridian (above or below fixation), and the other target on the vertical meridian (to the left or right of fixation). (b) and (c) MVPA decoding performance for target position. (b) Decoding performance comparing the 1TMP–1TGT and 2TMP–1TGT conditions, with the difference score, thus showing the effect of the number of templates – a minor preparation cost. (c) The same, now comparing the 2TMP–1TGT and 2TMP–2TGT conditions, thus showing the effect of the number of to-be-selected features within the display – a severe selection cost. For further details see Ort, Fahrenfort, ten Cate, et al. (Citation2019).
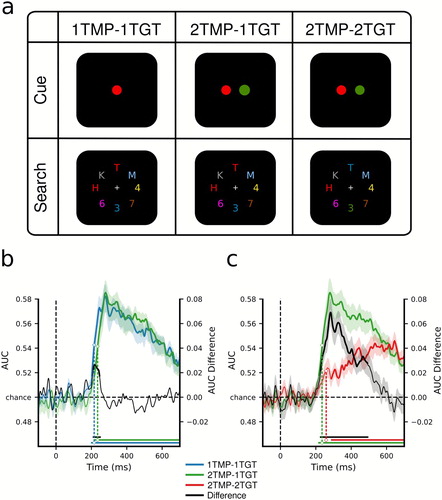
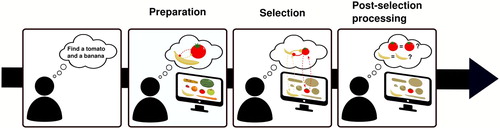
Figure 4. Current model of multiple-target search. Preparation. When set out to look for two targets, multiple target representations can be prepared and kept in a ready-to-use state. However, these representations stand in a competitive relationship to each other (represented through round arrowheads), responsible for a minor cost that arises at this stage. Selection. During search, these top-down target biases interact with matching bottom-up signals factors and trigger recurrent feedback loops that cause both target features to be concurrently enhanced, leading to selection. However, at this stage, when both targets are present in the display, the mutual inhibitory relationship between the target representations becomes detrimental and severely impairs selection, representing the major bottleneck of multiple-target search. Post-selection processing. Once potentially task-relevant information has been selected, individuals need to verify whether it is indeed the sought-for information. Its limitations are currently unknown for VWM based search tasks.