
Figures & data
Figure 1. In high-resolution satellite videos, ground targets show attributes such SS, PO, PoV, PTBD, SD, and PGFI. These attributes are the challenges in current satellite video SOT task and also make natural scene-based trackers inapplicable to satellite videos.

Figure 2. The overall tracking workflow of ThickSiam. It formally includes TRBS-Net for extracting robust semantic features to obtain the initial tracking results and a RKF module for simultaneously correcting the trajectory and size of the targets. The results of TRBS-Net and RKF modules are combined by an N-frame-convergence mechanism to achieve final tracking results.
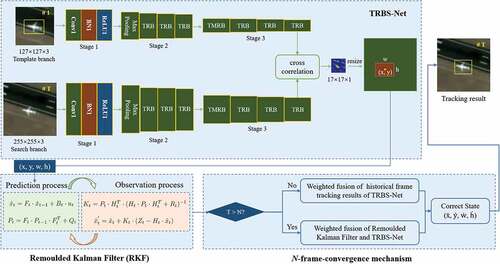
Figure 3. The structure comparisons of original residual block and the proposed TRB. Based on the original residual block, the modifications of TRM include doubling the number of channels in bottleneck and cropping out the limbic elements attached to the feature map.
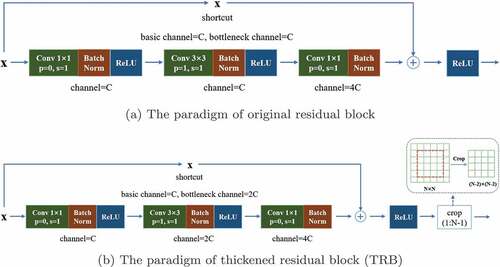
Figure 4. The structure comparisons of original down-sampling residual block and the proposed TMRB. Based on the original down-sampling residual block, the modifications of the TMRB include doubling the number of channels in bottleneck, cropping out the outermost features, modifying the stride in the above two convolutional modules to 1, and adding a maxpooling layer to achieve down-sampling of the feature map.
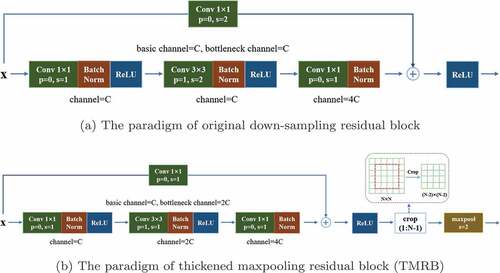
Table 1. The detailed information of feature map in each stage of TRBS-Net. is the abbreviation of
.
and
, respectively, represent the convolutional layer and batch normalization in
.
Figure 5. The constructed exemplar-search training pairs. The annotation selected from DIOR (Li et al. Citation2020) object detection dataset is expanded outward by 1/2 of the sum of width and height, and scaled according to the sizes of the exemplar image and search image of the TRBS-Net.

Figure 6. The constructed testing dataset used in the experiments. There are twelve objects in eight satellite scenarios, and the targets consist of airplanes, ships, trains, and vehicle.

Table 2. The detailed descriptions of the constructed testing dataset. is the abbreviation of
. Attributes refer to the difficulties in tracking this object.
Table 3. The experimental results of the ThickSiam framework with different training mechanisms. The baseline method was stacked by original residual block and down-sampling residual block according to the structure of the TRBS-Net.
Table 4. Comparative experiment results of different values in the
-frame convergence mechanism.
selected the number divisible by 10 from 10 to 100.
Table 5. Comparisons with the state-of-the-art trackers on our constructed testing dataset.
Figure 7. The visualized tracking results of ThickSiam, SiamFC++ (AlexNet) and SiamFC (AlexNet) trackers with corresponding GT. The yellow at the top right of the image represented the video frame number. The yellow, red, blue, and green bounding boxes represented the results of GT, ThickSiam (ours, TRBS-Net+RKF), SiamFC++ (AlexNet), and SiamFC (AlexNet), respectively.

Figure 8. The tracking results of the ThickSiam tracker in six typical scenarios containing all attributes including SS, PO, PoV, PTBD, SD, and PGFI.

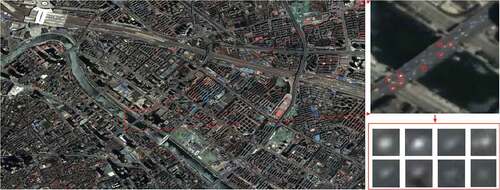
Figure 9. The field of view of “Jilin-1” satellite video. The specified area in the red box on the left was enlarged and displayed in the upper right corner. Cars on the bridge were further magnified for visual display. These targets usually had only a few or dozens of pixels, and the ultra-small size made their apparent features weak, and the boundary with the background was not clearly visible.
Data availability statement
The testing data in this study are available at https://github.com/CVEO/ThickSiam.