
Figures & data
Figure 1. The GF-2 dataset (a to j represent data from the GF-2 dataset. We used white color to depict the annotated road areas by overlaying road labels onto image tiles).

Table 1. The parameters of GF-2 images used in this study.
Figure 2. Dilated convolutional block (the green square represents the learning region of dilated convolution, the white square represents the “hole” of dilated convolution, which refers to the gaps between the convolutional units. The blue shadows at the bottom of the figure depict the receptive field).
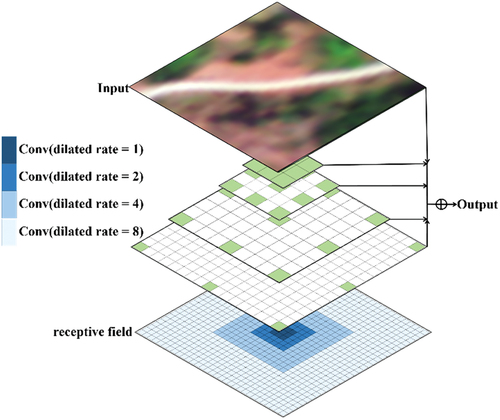
Figure 3. Structure of D-FusionNet. (The encoder-decoder in this figure is composed of different modules, represented by the rectangular blocks of various colors. The dashed lines indicate the specific operations performed by each block, while the solid lines represent the connections within the network. The rectangles of different colors correspond to the various standard operations in CNNs, and the group of gray rectangles represents the current feature map).
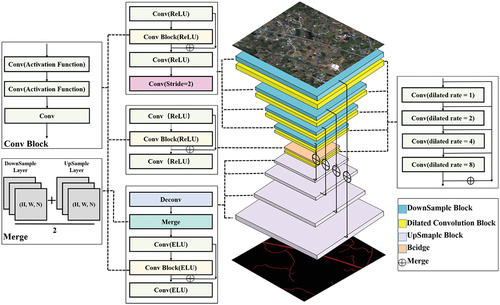
Figure 4. The flowchart of the experimental process (The sources of a-1 and b-1 are the Massachusetts dataset and the GF-2 dataset, respectively. The extraction results can be seen in a-2 and b-2. c demonstrates the Spatial transferability of D-FusionNet).

Figure 5. Grad-CAM analysis of ablation models in dilation rate experiment (ablation I, II, III, IV and V represents the ablation model by replacing the dilation rate in DCB with {2, 4, 8, 16}, {4,8,16,32}{32,16,8,4}{16,8,4,2}{8,4,2,1}, respectively).
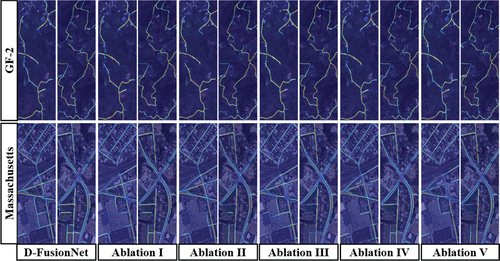
Table 2. Ablation experiments by modifying the dilation rates.
Figure 6. The Grad-CAM analysis of ablation models in embedding positions experiment. Ablation I, II, III, IV, and V represent the ablation model by removing the downsampling performed after the first, second, third, fourth, and fifth iteration.
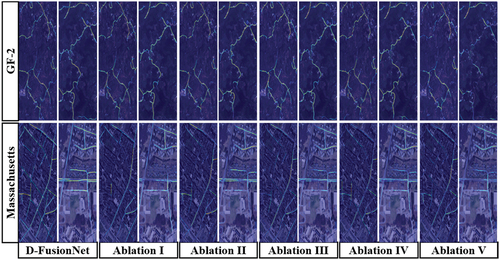
Table 3. Ablation experiments by modifying the embedding positions.
Table 4. Comparisons among FCN, UNet, LinkNet, D-LinkNet, FusionNet, and proposed D-FusionNet models.
Figure 7. The comparisons of road extraction among FCN, UNet and D-FusionNet models (for each model, the left shows the extracted road and the right shows the evaluation parameters: TP with green, FN with red, TN with black, and FP with blue. The red rectangles highlight the comparisons among FCN, UNet and D-FusionNet models).

Figure 8. The comparisons of road extraction among LinkNet, D-LinkNet and D-FusionNet models (for each model, the left shows the extracted road and the right shows the evaluation parameters: TP with green, FN with red, TN with black, and FP with blue. The red rectangles highlight the comparisons among LinkNet, D-LinkNet and D-FusionNet models).

Figure 9. The comparisons of road extraction between FusionNet and D-FusionNet models (For the each model, the left shows the extracted road and the right shows the evaluation parameters: TP with green, FN with red, TN with black, and FP with blue. The yellow rectangles highlight the comparisons among LinkNet, D-LinkNet and D-FusionNet).
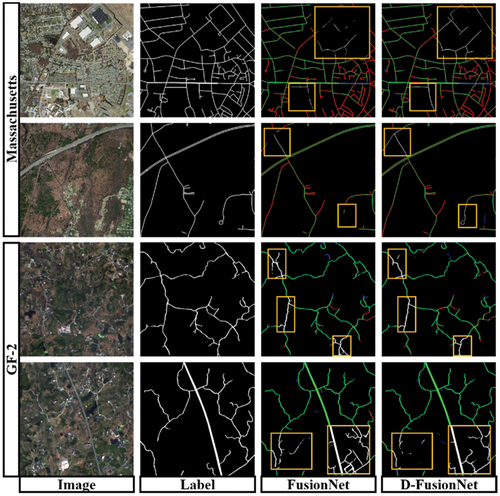
Figure 10. The roads that the D-FusionNet is difficult to extract.

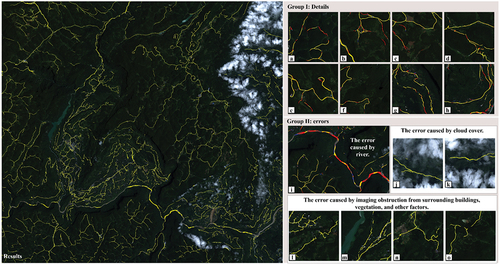
Figure 11. Spatial transferability test of D-FusionNet (The figure consists of three parts: on the left is the extraction result of D-FusionNet in the summer imagery of Enshi Tujia and Miao Autonomous Prefecture, Hubei Province. The extracted road areas are highlighted in yellow. In group I, we randomly selected eight image tiles from the imagery and compared the extraction results of D-FusionNet and FusionNet. Yellow represents the common areas extracted by both networks, red indicates the additional road areas extracted by D-FusionNet compared to FusionNet, and the meaning of blue is opposite to that of red. In group II, we demonstrate several error sources of D-FusionNet. Among them, i shows the influence of rivers on network extraction, using the same annotation method as group I. j and k demonstrate the impact of cloud and fog cover on network extraction. l~o illustrate the impact of imaging obstruction from surrounding buildings, vegetation, and other factors on network extraction. The annotation method for j~o is the same as that on the left side of the figure).
Data availability statement
The public dataset used in this study can be obtained from https://www.cs.toronto.edu/~vmnih/data/. The satellite imagery data involved in the study can be acquired from the China Center for Resources Satellite Data and Application at https://www.cresda.com/zgzywxyyzx/index.html.