Figures & data
Table 1. Self-ratings from the language background questionnaire given by German speakers of Dutch in Experiment 1.
Table 2. Characteristics of the four matched nonword conditions.
Figure 1. Mean error rates for the three nonword categories in the two groups. Error bars represent standard errors.
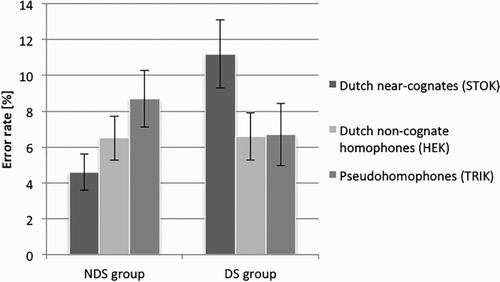
Figure 2. Mean RTs for the three nonword categories in the two groups. Error bars represent standard errors.
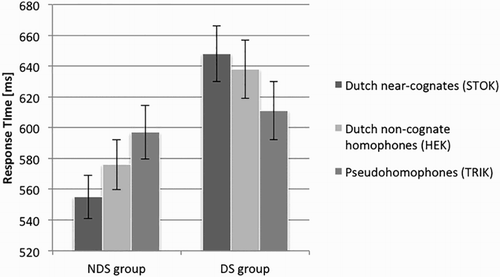
Table 3. Mean RTs and error rates (standard deviations in parentheses) for the three experimental nonword conditions, as well as the matched filler condition, in Experiment 1.
Table 4. Results of the ANOVA’s for Error Rates and Reaction Times in Experiment 1.
Figure 3. Scatter plot and regression line showing the correlation between the near-cognate effect (near-cognates minus homophones) in error rates and Dutch vocabulary size, as measured by LexTALE.
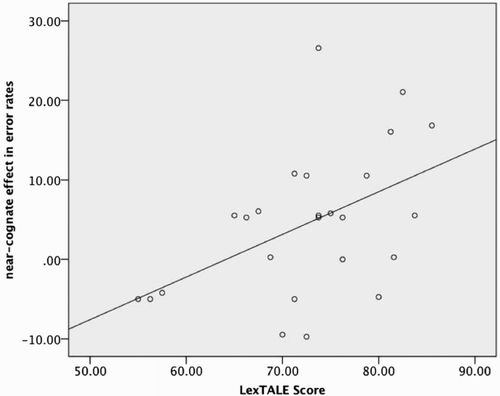
Table 5. Mean RTs and error rates (standard deviations in parentheses) for German near-cognates and non-cognates in Experiment 1.
Table 6. Self-ratings from the language background questionnaire for the German speakers of Dutch in Experiment 2.
Table 7. Mean cloze probabilities (standard deviations in parentheses) for the targets in the three experimental nonword conditions in Experiment 2.
Figure 4. Bar graph of fixation measures (first fixation duration, re-fixation duration, re-reading time) for the three critical misspelling categories in the two groups. Cog = cognates, Hom = homophones, Pseu = pseudo.
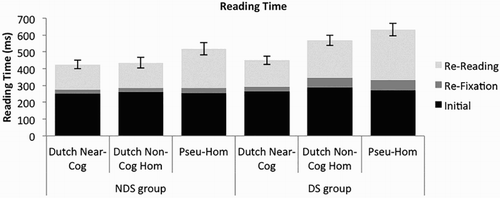
Table 8. Mean temporal reading parameters (standard deviations in parentheses) for the three experimental nonword conditions in Experiment 2.
Table 9. Results of the ANOVA’s for the three fixation duration measures in Experiment 2.
Table 10. Mean spatial fixation parameters (standard deviations in parentheses) for the three experimental nonword conditions in Experiment 2.
Table 11. Results of the ANOVA’s for the three spatial fixation parameters in Experiment 2.
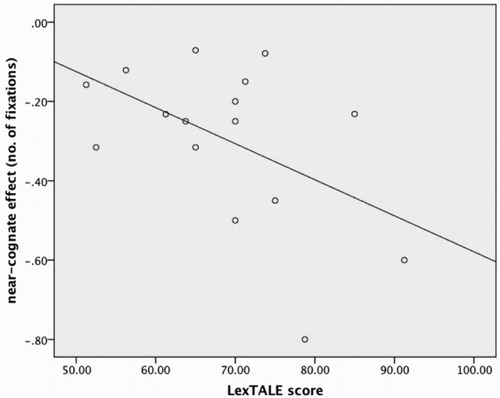
Figure 5. Scatter plot and regression line showing the correlation between the near-cognate effect (near-cognates – homophones) concerning the total number of fixations and Dutch vocabulary size, as measured by LexTALE.