
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Piecewise affine systems constitute a popular framework for the approximation of non-linear systems and the modelling of hybrid systems. This paper addresses the recursive subsystem estimation in continuous-time piecewise affine systems. Parameter identifiers are extended from continuous-time state-space models to piecewise linear and piecewise affine systems. The convergence rate of the presented identifiers is improved further using concurrent learning, which makes concurrent use of current and recorded measurements. In concurrent learning, assumptions on persistence of excitation are replaced by the less restrictive linear independence of the recorded data. The introduction of memory, however, reduces the tracking ability of concurrent learning because errors in the recorded measurements prevent convergence to the true parameters. In order to overcome this limitation, an algorithm is proposed to detect and remove erroneous measurements at run-time and thereby restore the tracking ability. Detailed examples are included to validate the proposed methods numerically.
1. Introduction
Piecewise affine (PWA) systems constitute a powerful tool to describe complex dynamical systems. They consist of multiple linear subsystems, which define the dynamics of the continuous states. A discrete value indicates the active subsystem. For switched affine systems, this index is an exogenous input signal. For PWA systems, the index is a function of the state and input, and is obtained by partitioning the state-input space of the system. PWA systems have gained popularity due to their universal approximation capabilities for non-linear systems (Azuma, Imura, & Sugie, Citation2010) and their equivalence to certain hybrid systems (Heemels, Schutter, & Bemporad, Citation2001).
Identifying PWA systems requires estimating both the linear subsystems as well as the partitions of the state space. This is particularly challenging as available measurements of the state and control input usually do not reveal which subsystem and region they belong to. This is similar to the identification of linear parameter-varying (LPV) systems where the scheduling variable may be unknown (Bamieh & Giarré, Citation2002; Tóth, Citation2010; Verdult & Verhaegen, Citation2002). An overview of identification algorithms for PWA systems is given by Paoletti, Juloski, Ferrari-Trecate, and Vidal (Citation2007). The later survey by Garulli, Paoletti, and Vicino (Citation2012) provides an extensive summary of more recent approaches. The identified models are mostly discrete-time models in input--output form, i.e. switched autoregressive exogenous (SARX) models or piecewise ARX (PWARX) models. However, continuous-time models are more intuitive. Furthermore, as pointed out by Garnier (Citation2015), direct identification of continuous-time models based on sampled data can outperform the discrete-time models in case of rapidly or irregularly sampled data. Algorithms to identify PWA systems in state-space form are less common, due to increased complexity in case the state is not accessible. Exemplary algorithms to deal with discrete-time PWA state-space systems are proposed in Pekpe and Lecœuche (Citation2008), Blackmore, Gil, Seung, and Williams (Citation2007), Bako, Mercère, and Lecoeuche (Citation2009), Bako, Mercère, Vidal, and Lecoeuche (Citation2009), Gil and Williams (Citation2009), Chen, Bako, and Lecoeuche (Citation2011), and Bako, van Luong, Lauer, and Bloch (Citation2013). Identifying state-space systems is considerably more challenging than SARX and PWARX as the partition of the system is based on the state that might not even be measurable. Nevertheless, many control strategies rely on state-space models, which is the first motivation to identify PWA state-space systems. Furthermore, research in realisation theory shows that PWA models in state-space form can realise a greater class of systems than input--output models, i.e. there exist PWA state-space models that cannot be transformed into a corresponding input--output model. Also the conversion from PWA state-space models to PWARX models can result in a tremendous increase of modes and parameters (Garulli et al., Citation2012). Realisation theory also plays a crucial role in determining, whether a switched system is identifiable or not (Petreczky, Citation2011; Petreczky & van Schuppen, Citation2010, Citation2011). It was shown by Petreczky, Bako, and van Schuppen (Citation2010) that minimality of a realisation is necessary for identifiability. Interestingly, minimality or identifiability of a linear switched system does not imply minimality or identifiability of the linear subsystems.
Most state-of-the-art identification algorithms for PWA systems fall into one of the four major categories: optimisation-based methods, algebraic methods, clustering-based methods or recursive methods. The identification of PWA systems is generally a non-convex combinatorial optimisation problem. The optimisation-based methods seek to solve this problem through a relaxation of the problem (e.g. Bako, Citation2014; Lauer, Bloch, & Vidal, Citation2011) or by finding alternative formulations (e.g. Maruta, Sugie, & Kim, Citation2011). The algebraic methods originate from (Vidal, Soatto, Yi, & Sastry, Citation2003) and share the idea that multiple ARX models can be identified (independent of the switching sequence) as a single, lifted ARX model. The individual ARX models are retrieved from the lifted model by differentiation. In clustering-based methods, clustering techniques are applied at different stages of the identification process (e.g. Ferrari-Trecate, Muselli, Liberati, & Morari, Citation2003; Lopes, Borges, & Ishihara, Citation2013).
Recursive methods, like Bako, Boukharouba, Duviella, and Lecoeuche (Citation2011), Bako et al. (Citation2009), Chen et al. (Citation2011), Vidal (Citation2008), Feiler and Narendra (Citation2008), and Wang and Chen (Citation2011), solve the identification problem online and therefore allow tracking of parameter changes in the system. Also, recursive algorithms handle the available data sequentially and are therefore computationally more efficient. Since the aforementioned properties are desirable, the focus of this article is on recursive estimation algorithms. Some recursive algorithms are modifications of existing batch algorithms: Vidal (Citation2008) for instance extends the original algebraic method in Vidal et al. (Citation2003) to recursively identify SARX systems. Another popular approach is to reason online about the active/best performing model and update the corresponding parameters (Bako et al., Citation2011; Feiler & Narendra, Citation2006; Feiler & Narendra, Citation2008; Wang & Chen, Citation2011). Proof of convergence remains an open issue for this class of algorithms. Overall, a provably converging, recursive identification algorithm for PWA systems in state-space form is still missing.
The adaptive control literature on the other hand has provably converging algorithms for the control of uncertain PWA systems. The method presented by Di Bernardo, Montanaro, and Santini (Citation2009) allows to identify bimodal piecewise linear (PWL) state-space systems based on the gain evolution of the adaptive controller in Di Bernardo, Montanaro, and Santini (Citation2008). The main drawback of this approach is the limitation to two subsystems. The works by Di Bernardo et al. (Citation2009) and Di Bernardo et al. (Citation2008) show that recursive identification and adaptive control are closely related. In Sang and Tao (Citation2012), exponential tracking is achieved through parameter projection by imposing slow switching and persistence of excitation (PE) on the system. More recently, Di Bernardo, Montanaro, and Santini (Citation2013) proposed a new adaptive control law to asymptotically track the states of a multi-modal PWA reference model. Note that the above adaptive control algorithms for PWA systems share the assumption of known switching hyperplanes. In previous work by Kersting and Buss (Citation2014a, Citation2014c), adaptive parameter identifiers were extended from linear systems to PWL and PWA systems under the same assumption. Afterwards, they were enhanced in Kersting and Buss (Citation2014b) by the use of concurrent learning.
Chowdhary et al. introduced the concept of concurrent learning to adaptive control in order to circumvent the limitations in adaptive systems related to PE (see Chowdhary, Citation2010; Chowdhary & Johnson, Citation2010; Chowdhary, Mühlegg, & Johnson, Citation2014; Chowdhary, Yucelen, Mühlegg, & Johnson, Citation2013). While traditional update laws in adaptive control rely on current measurements, the central idea in concurrent learning is to use current measurements concurrently with past measurements. Closely related to concurrent learning is the concept of experience replay, which is applied in reinforcement learning with actor–critic structure (Modares, Lewis, & Naghibi-Sistani, Citation2014; Wawrzyński, Citation2009). By replaying recorded past experiences concurrently with current data, convergence rates are improved and assumptions on the excitation of the system are relaxed. The concept of concurrent learning has been applied successfully in various fields (Chowdhary, Mühlegg, How, & Holzapfel, Citation2013; Kamalapurkar, Walters, & Dixon, Citation2016; Klotz, Kamalapurkar, & Dixon, Citation2014). However, the most promising field for concurrent learning is switched systems, where the use of memory enables a continuous adaptation of active and inactive subsystems (De La Torre, Chowdhary, & Johnson, Citation2013; Kersting & Buss, Citation2014b). Despite the growing interest in concurrent learning, some of its properties still lack detailed analysis. Especially the effect of erroneous data in the history stacks has received little attention. It is noted by Chowdhary et al. (Citation2013) that tracking errors remain uniformly ultimately bounded and that adaptive weights converge to a compact ball around the ideal weights in the presence of erroneous history stack data. Unfortunately, the size of the compact ball is related to the errors in history stack data. Hence, errors in the history stack limit guaranteed convergence levels.
This paper provides the following contributions. First, we revise the extension of parameter identifiers from linear to PWL/PWA systems and improve the achievable convergence rate using concurrent learning. In addition to previous, preliminary works by Kersting and Buss (Citation2014a, Citation2014b, Citation2014c), we provide extended proofs and further insights. Specifically, proving PE for affine systems, which violate the assumption of sufficiently rich input signals, constitutes an enabling contribution for the presented algorithms. Second, we analyse the convergence of concurrent-learning-based parameter identifiers in more detail and propose algorithms to detect and remove erroneous history stack elements online. The extension of Kersting and Buss (Citation2015) to PWA systems is particularly useful due to erroneous stack elements introduced by switching. This not only enables better estimation of the system parameters but also restores the tracking ability of concurrent-learning-based algorithms. Simulation studies illustrate the benefit of concurrent learning and show the approximation of a non-linear hybrid systems.
The remainder of this paper is organised as follows. Section 2 defines parameter identifiers for PWA and PWL systems. The concurrent-learning-based identification of PWA systems is presented in Section 3. The management of history stack data, especially the detection and removal of erroneous data, is subject of Section 4. Section 5 validates the obtained results in numerical simulations of general PWA systems as well as a non-linear hybrid two-tank system. Section 6 concludes the paper.
2. Parameter identifiers for PWA systems
This section defines PWL and PWA systems and discusses briefly how they naturally arise from the linearisation of a non-linear system at multiple operating points. Afterwards, parameter identifiers are extended from linear systems to PWL and PWA systems.
2.1 Definition of PWA systems
PWA systems in state-space form are switched systems of the form
(1)
(1) where
,
are the state and input vectors, respectively. Let the input u be generated by a stabilising controller such that x and u remain bounded, also for open-loop unstable systems. Let the switched system (Equation1
(1)
(1) ) consist of
subsystems, where each subsystem i is characterised by a system matrix
, an input matrix
and an affine input vector
. The piecewise constant switching signal σ(t) ∈ {1,… , N} indicates the currently active subsystem.
In PWA systems, σ is a function of the system state x and its input u. The extended state-input space is partitioned into polyhedral regions Ω
i
. In order to form a complete partition
, the regions do not overlap, i.e. Ω
i
∩Ω
j
= ∅, ∀i ≠ j. The value of the switching signal σ(x(t), u(t)) is given by the index of the region that currently contains the state-input vector:
In order to obtain a well-posed identification problem, it must be possible to excite all states in x for all subsystems. This in turn poses restrictions on the allowed partitions Ω i . Hence, throughout this article, we assume that all Ω i are such that they allow sufficient excitation of the state x. For more details on the well-posedness of identification problems for switched systems, refer to Petreczky et al. (Citation2010).
The challenge in identifying PWA systems originates from the coupling between subsystem dynamics (A i , B i and f i ) and the polyhedral regions Ω i that might both be assumed unknown and thus need to be identified. In Kersting and Buss (Citation2014b) as well as in the remainder of this paper, we consider the simplified case in which the switching signal σ(t) is known. This constitutes on the one hand a restrictive assumption for the identification of PWA systems, as it generally reduces the identification of PWA systems to the identification of N individual subsystems A i , B i and f i . On the other hand, it is in line with adaptive control concepts for PWA systems (Di Bernardo et al., Citation2008; Di Bernardo et al., Citation2013; Sang & Tao, Citation2012). Also, this is acceptable for the second objective of this paper, which is to provide insights into concurrent learning and to extend its capabilities.
A PWA model (Equation1(1)
(1) ) can be obtained by linearising a non-linear system around multiple operating points. Consider therefore the non-linear system
(2)
(2) where g is a non-linear vector function of dimension n. Note that for the rest of this paper the time instance t is omitted as long as it is clear from the context. Neglecting higher-order terms in the linearisation of g around an operating point (x*
i
, ui
*), the affine model is obtained as
(3)
(3) where
,
and fi
= g(x*
i
, u*
i
) − Aix*
i
− Bix*
i
. Linearising around various operating points {(x*
i
, ui
*)}
i = 1, …, N
yields a PWA model. In this PWA model, the state space is partitioned such that the linear subsystem in each region is characterised by a minimal error compared to the original non-linear system.
Assuming that (x*
i
, ui
*) are known equilibrium points and considering only the deviations Δxi
= x − x*
i
and Δui
= u − u*
i
from these equilibrium points, the same considerations yield a PWL model without the affine vectors f
i
:
Note however that working with PWL models requires the additional knowledge about the equilibrium points in order to compute the deviations Δx
i
and Δu
i
. Therefore, PWA models are more favourable when it comes to designing adaptive algorithms as less knowledge about the system is required.
The actual partitions Ω i of a PWA model, approximating a non-linear system, are often unknown in practice. In such cases, one can define a sufficiently large number of fictitious partitions in order to obtain a satisfactory approximation of the actual switching behaviour. The assumption of a known switching signal σ is hence satisfied for such designer-chosen partitions.
With the introduced notation for PWA systems, the problem of estimating the subsystem parameters of a PWA system online is formulated as follows:
Problem 2.1:
Assume that the identification problem is well-posed. Given the partitions Ω
i
and hence also the switching signal σ(t), find update laws which are based on the measured state x and input u, and provably drive the dynamic estimates ,
and
to the true system parameters A
i
, B
i
and f
i
.
2.2 Parameter identifiers for PWA systems
The literature on adaptive systems offers identifiers to recursively identify the parameters of linear state-space models (see Ioannou & Sun, Citation1996, Chapter 4). Those identifiers extend to switched affine systems in state-space form by carefully including the switching signal σ. The update laws in parameter identifiers are based on prediction errors. Therefore, the state of the currently active subsystem (σ(t) = i) is predicted with the state observer:
(4)
(4) where the stable (Hurwitz) design matrix
ensures boundedness of
. Hence, there always exists a symmetric, positive definite
satisfying
(5)
(5) with a positive definite matrix
.
Define the prediction error , which provides information about the fit of subsystem i. It is used to update the parameter estimates of the active subsystem. For inactive subsystems e
i
is unrelated. The predicted state
is thus reset and kept equal to the true state x as long as the corresponding subsystem is inactive:
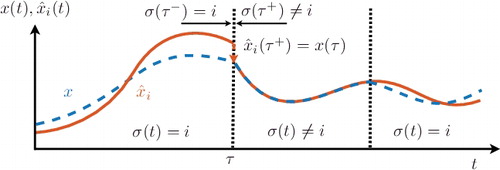
(6)
(6)
shows the state prediction for the ith subsystem with continuous prediction (Equation4(4)
(4) ) and state reset (Equation6
(6)
(6) ). This reset is the crucial step in extending parameter identifiers to switched systems because it ensures that switching between different subsystems does not destabilise the overall system.
Figure 1. Discrete reset of the state prediction for the ith subsystem upon deactivation of the ith subsystem dynamics, i.e. as σ(τ−) = i and σ(τ+) ≠ i.
Note that some preliminaries are needed for convergence analysis. Therefore, Appendix A details a definition for PE as well as two useful lemmas from the adaptive control literature (Ioannou & Sun, Citation1996). It is well known that PE conditions in adaptive systems can be derived from the spectral distribution of input or reference signals. The following definition captures such spectral properties.
Definition 2.1
(sufficiently rich): A signal is called sufficiently rich of order 2n, if it consists of at least n distinct frequencies (Ioannou & Sun, Citation1996, Def. 5.2.1).
The state of the art in parameter identifiers (see Ioannou & Sun, Citation1996, Chapter 5) requires all input signals of a controllable system to be sufficiently rich of order n + 1. In PWA systems, however, the affine vectors f i are constant and therefore violate this assumption. Hence, the following lemma is needed for the extension to PWA systems as it ensures PE of the internal signal vector [x ⊤, u ⊤, 1]⊤.
Lemma 2.1:
Consider an affine subsystem (Equation3(3)
(3) ) with controllable pair (A, B) and invertible A. If the input signals in u are sufficiently rich of order n + 1 with distinct frequencies, then the vector z = [x
⊤, u
⊤, 1]⊤ is PE.
The proof of Lemma 2.1 is given in Appendix A for improved readability. Lemma 2.1 extends the state of the art in a sense that violating the common assumption of sufficiently rich input signals can be compensated by restricting the system to invertible system matrices. This insight enables the application of parameter identifiers for PWA systems.
Lemma 2.1 relates PE of each affine subsystem to the richness of the inputs. For the considered class of PWA systems, however, PE should also reflect how frequently each subsystem is visited over time. Only if each subsystem is PE and visited in a persistent manner, it is possible to estimate all system parameters. The first formal but restrictive notion for PE in switched linear systems is given by Petreczky and Bako (Citation2011). In this paper, we require the input signals to be sufficiently rich and such that they repeatedly drive the system through all regions in order to ensure PE of the PWA system.
Theorem 2.1:
Consider the switched system (Equation1(1)
(1) ) with controllable pairs (A
i
, B
i
) and A
i
invertible. Let the state of the system be predicted by Equations (Equation4
(4)
(4) ) and (Equation6
(6)
(6) ) for all subsystems. If the input signals in u are sufficiently rich of order n + 1 with distinct frequencies, and such that they cause repeated activation of all subsystems obeying a certain dwell time T
0, then the update laws
(7)
(7) with P from Equation (Equation5
(5)
(5) ) and scaling constants
, cause the estimates
to converge to the real system matrices A
i
, B
i
, f
i
and cause the prediction errors
to converge to zero.
Proof:
The superscript C in Equation (Equation7(7)
(7) ) indicates that the update laws only depend on current measurements. This distinction is important for the later introduction of concurrent learning but is irrelevant for the following proof. The superscript C is thus neglected.
The proof is separated into two parts. In the first part, we show stability of all estimates in the switched system. Multiple Lyapunov functions guarantee stability even for arbitrary fast switching. Note that we apply the same stability notation as Liberzon (Citation2003) throughout the paper, which at the same time serves as an excellent introduction to switched systems. In the second part, we prove convergence to the true parameters with the help of PE. Convergence is achieved under a loose minimal dwell time condition needed to ensure sufficient excitation of the system.
Part I – Stability: In order to formulate a quadratic candidate Lyapunov function for each subsystem in terms of the parameter errors ,
and
, they are combined in a single column vector
(8)
(8) where the vec-operator concatenates the columns of a matrix. We make use of the Kronecker product ⊗ and introduce the matrices
(9)
(9) with identity matrices I
n
, I
nn
and I
np
of dimensions n × n, nn × nn and np × np, respectively, which allow expressing most equations in a more compact form, which in turn simplifies the later analysis. The derivative of the prediction error for the active subsystem in terms of
is given by
(10)
(10) Also, with Equations (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ), the update laws (Equation7
(7)
(7) ) take the form
(11)
(11)
Consider the quadratic candidate Lyapunov function
(12)
(12) Its time derivative along Equations (Equation10
(10)
(10) ) and (Equation11
(11)
(11) ) yields
(13)
(13) for σ = i. For the inactive subsystems, e
i
= 0 due to Equation (Equation6
(6)
(6) ). Therefore, the Lyapunov function of the inactive subsystems remains constant, i.e.
for σ ≠ i.
While Equation (Equation13(13)
(13) ) shows stability in the sense of Lyapunov for all subsystems individually, it does not imply stability of the overall switched system. In order to prove stability for the obtained hybrid system, we will see that the candidate Lyapunov functions have to be Lyapunov-like functions along all possible trajectories and switching sequences (Branicky, Citation1998; Liberzon, Citation2003). This requires the values of the Lyapunov functions at each activation of the corresponding subsystem to form a decreasing sequence.
A precise notation for the switching instances is required in order to show that the candidate Lyapunov functions are Lyapunov-like. Express the qth activation of sub-model i by (we have
and
). Similarly, the instance
refers to the qth exit from sub-model i (
and
). With this notation, the following requirement arises for stability in the sense of Lyapunov for switched systems (Branicky, Citation1998):
(14)
(14)
Due to the negative semi-definiteness in Equation (Equation13(13)
(13) ), it follows that
(15)
(15) Furthermore, the state reset associated with Equation (Equation6
(6)
(6) ) yields e
i
(τ) = 0 for the inactive periods
. With e
i
= 0, adaptation pauses and the parameter errors remain constant, i.e.
. It follows that
which shows that Equation (Equation14
(14)
(14) ) is satisfied. In other words: switching between different subsystems does not cause divergence of the parameter estimates. It remains to be shown that all errors converge to zero.
Part II – Convergence: The proof of convergence relies on Lemma 2.1 and Lemma A.2 in Appendix A. In order to show asymptotic convergence of the switched error system with multiple Lyapunov functions, the sequence in Equation (Equation14(14)
(14) ) must be shown to be strictly decreasing to zero. This will be achieved by showing that the Lyapunov function derivative of the active subsystem is actually negative definite under PE. A certain dwell time is demanded to sufficiently excite each subsystem and ensure that
while σ = i. Therefore, let the dwell time be equal to the constant T
0 in the definition of PE (see Definition A.1 in Appendix A). The shorter this dwell time, the lower is the level of excitation and the slower do errors converge.
First, the error dynamics are rewritten in the form of Lemma A.2 given in Appendix A:
(16)
(16) with Ψ = z⊗I
n
. Note that condition (EquationA2
(A2)
(A2) ) has been shown in the previous stability proof in form of Equation (Equation13
(13)
(13) ), where P
0 = diag(P, Γ−1). For convergence of e and
, Lemma A.2 additionally requires the vector
to be PE, which is ensured by Lemma 2.1 under the given assumptions. Consequently with Lemma A.2, the equilibrium e
e
= 0,
of Equation (Equation16
(16)
(16) ) is exponentially stable in the large. Hence, the difference
is bounded from above by a negative definite function
. As shown in Liberzon (Citation2003, Theorem 3.1), this implies that multiple Lyapunov functions can be used to reason asymptotic stability of the switched system. In other words, the Lyapunov function of the active subsystem is negative definite, which implies that the sequence in Equation (Equation14
(14)
(14) ) is strictly decreasing to zero. Including the assumption that each subsystem i is visited in a persistent manner, this means that all prediction errors e
i
as well as all parameter errors
converge to zero, i.e.
,
and
as t → ∞.
2.3 Parameter identifiers for PWL systems
Considering the simpler case of PWL systems (for which f = 0), one notices that Theorem 2.1 holds with one assumption less, i.e. the matrices A i are not required to be invertible.
Theorem 2.2:
Consider a PWL system with controllable pairs (A
i
, B
i
). Let the state of the system be predicted by Equation (Equation4(4)
(4) ) with
and Equation (Equation6
(6)
(6) ) for all subsystems. If the input signals in u are sufficiently rich of order n + 1 with distinct frequencies, and such that they cause repeated activation of all subsystems obeying a certain dwell time T
0, then the update laws
and
in Equation (Equation7
(7)
(7) ) cause the estimates
to converge to the real system matrices A
i
, B
i
and cause the prediction errors
to converge to zero.
Proof:
The proof of Theorem 2.2 follows the one of Theorem 2.1 and is therefore sketched briefly. First, stability is verified in the same way as before, i.e. with multiple Lyapunov functions which form the decreasing sequence (Equation14(14)
(14) ). In the second part of the proof, which is concerned with convergence, PE now only needs to be guaranteed for the vector z = [x
⊤, u
⊤]⊤. Analysing the proof of Lemma 2.1 in Appendix A shows that this can be guaranteed without restricting A
i
to invertible matrices. The remainder of the proof remains unchanged as compared to Theorem 2.1.
Note that Theorem 2.1 and Theorem 2.2 both assume a certain dwell time of the switched system. This dwell time assumption is however not restrictive. It turns out that arbitrary fast switching does not cause divergence of the estimated parameters. But, if little time is spent in a subsystem, the corresponding estimates receive only minor updates, resulting in slow convergence.
The derivation of parameter identifiers for PWA and PWL systems may seem a little technical. An intuitive interpretation of the discussed identifiers for PWA systems is to initialise a separate identifier for each subsystem and apply it during the time frames in which the corresponding subsystem is active. The update laws (Equation7(7)
(7) ) suffer three shortcomings: (1) all signals in u must be sufficiently rich of order n + 1 for all time in order to ensure PE; (2) adaptation of subsystem i only takes place while subsystem i is active; (3) convergence is rather slow. These shortcomings can be overcome by introducing memory in the form of concurrent learning as shown by Kersting and Buss (Citation2014b) and as we revise in the following section.
3. Concurrent learning adaptive identification
The update laws in concurrent-learning-based adaptive control and identification consist of two parts. The first part is based on current measurements of states and control inputs (such as the ones presented in the previous section). The second part is based on selected, past measurements that are stored in memory, the so-called history stacks. The update laws thus make concurrent use of current and recorded data. This idea is motivated by the ability to repeatedly employ the recorded data to compute updates for the system parameters, allowing for continued identification of all subsystems. In the case of switched systems, even estimates of currently inactive subsystems can then be further updated. Furthermore, concurrent learning reduces the PE requirements to a limited period of excitation in which the measurements are taken.
Denote with (,
,
) the jth triplet that is recorded while subsystem i is active. Let a total of
such triplets be recorded for each subsystem i. The elements of the triplets are stored in the three history stacks
,
and
. For now, let the number of triplets q be fixed and the stack elements
,
and
be constant. Later, this assumption will be discarded without loss of generality. Furthermore, it will be shown how to record new data for the history stacks and when to replace existing data with new data.
Note that in case the derivatives cannot be measured directly, techniques such as fixed point smoothing (Jazwinski, Citation1970; Shumway & Stoffer, Citation2006; Simon, Citation2006) can be applied to get an accurate estimate.
Two assumptions on the history stacks arise.
Assumption 3.1:
For each subsystem i, the history stacks X
i
and U
i
contain elements, such that there exist n + p + 1 linearly independent vectors .
Assumption 3.1 ensures that the recorded data contain enough information for the identification task and hence amounts to a PE-like condition to guarantee negative definiteness of the Lyapunov function in later proofs of convergence. The existence of linearly independent history stack elements for Assumption 3.1 is guaranteed under PE. Note however that PE is by no means necessary for the collection of the history stack elements. The assumption also implies the lower bound n + p + 1 ≤ q for the number of history stack elements. An upper bound is only given by practical considerations in form of limited, available memory.
Assumption 3.2:
The elements of each history stack fulfil
.
Assumption 3.2 requires the recorded derivative to match the real derivative
at state
and input
. As will be shown in Theorem 3.1, one can relax Assumption 3.2 such that estimates of
obtained with fixed point smoothing are sufficiently accurate.
For the jth triplet of subsystem i, define as the error between estimated and recorded derivative of the state:
(17)
(17) Note that the history stack elements
,
and
in Equation (Equation17
(17)
(17) ) are constant and thus only the time-varying estimates
,
and
cause changes in
.
In the ideal case, when Assumption 3.2 is satisfied and thus is correctly measured, the error
vanishes for the true system parameters:
In the suboptimal case, when Assumption 3.2 is violated, the measured derivative differs from the true derivative. To model this, let the measured derivative
equal the true derivative
minus an error term
:
Expressing in Equation (Equation17
(17)
(17) ) in terms of the true system dynamics
and the error
yields
(18)
(18)
While Equation (Equation17(17)
(17) ) specifies how to calculate
online, the expression in Equation (Equation18
(18)
(18) ) – which cannot be calculated due to the unknown parameter errors – is beneficial in the later convergence analysis. The errors
form a key element in the recorded data-based part (hence superscript R) of the update laws:
(19)
(19)
The rationale behind the update laws (Equation19(19)
(19) ) is to ensure exponential parameter convergence in the Lyapunov function (Equation12
(12)
(12) ),which will become evident shortly. As Equation (Equation19
(19)
(19) ) does not depend on current measurements of u or x, these update laws continuously update the parameter estimates, which enables convergence even for currently inactive subsystems. By combining the current data-based (superscript C) update laws in Equation (Equation7
(7)
(7) ) and the recorded data-based (superscript R) update laws in Equation (Equation19
(19)
(19) ), we obtain the following theorem which specifies concurrent learning adaptive identification of PWA systems.
Theorem 3.1:
Consider the PWA system (Equation1(1)
(1) ) with a known switching signal σ and let the subsystem states be predicted by Equations (Equation4
(4)
(4) ) and (Equation6
(6)
(6) ). Then the update laws
(20)
(20) cause the estimates
,
and
to
either converge exponentially to the true parameters A i , B i and f i if Assumptions 3.1 and 3.2 are satisfied,
or converge to a compact ball around the true parameters in case only Assumption 3.1 holds.
Proof:
The proof of Theorem 3.1 is based on multiple Lyapunov functions, one per subsystem. The derivative of all Lyapunov functions is shown to be negative definite regardless of σ. The parameter estimates of subsystem i therefore converge towards the true parameters whether the ith subsystem is active (σ = i) or inactive (σ ≠ i). It is therefore possible to analyse the stability of each subsystem individually, which is done in the following by neglecting the index i (i.e. A≜A
i
or ).
Again, the parameter error vector enables a compact representation of the concurrent learning-based updated laws. First, rewrite Equation (Equation18
(18)
(18) ) as
(21)
(21) Then, recall the definitions of Γ and Ψ in Equation (Equation9
(9)
(9) ) as well as the compact representation for
in Equation (Equation10
(10)
(10) ):
(22)
(22) Additionally, define
(23)
(23) After a few transformations involving Equations (Equation21
(21)
(21) ) and (Equation23
(23)
(23) ), the update laws in Equation (Equation20
(20)
(20) ) take the form
(24)
(24)
For stability analysis, consider the same quadratic candidate Lyapunov function (Equation12(12)
(12) ) as before. The time derivative of V along Equations (Equation22
(22)
(22) ) and (Equation24
(24)
(24) ) yields:
(25)
(25) where
and Q
θ≜Ξ⊤ + Ξ. Recall that Q
e
was chosen to be positive definite in the design of the current data-based update laws (Equation7
(7)
(7) ). Also, because of Assumption 3.1, the matrix Ξ and thus Q
θ are positive definite. Note that the useful consequence that
results from the recorded data-based update laws (Equation19
(19)
(19) ) and thus constitutes the motivation behind Equation (Equation19
(19)
(19) ). Assuming the ideal case in Equation (Equation25
(25)
(25) ), i.e.
, then the Δ-term vanishes and the derivative of the candidate Lyapunov function is indeed negative definite. Hence, all prediction errors e and parameter errors
converge exponentially to zero.
For the suboptimal case, however, in which , the derivative (Equation25
(25)
(25) ) consists of quadratic terms in e and
but is also linear in
. This observation permits a division of the error space
in two sets as exemplified in . For some small values of
the linear term dominates, which results in a first closed set for which
. The first set is surrounded by a second set in which the quadratic terms outweigh the linear term and
. The outer set with
guarantees boundedness of e and
.
Figure 2. Visualisation of the ellipsoidal set for which and approximation of the maximum parameter error
in terms of the centroid
and the maximal semi-principal axis νmax of the ellipsoid (
).
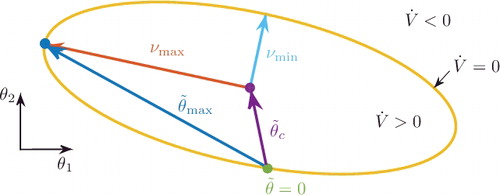
We can approximate the compact set to which the parameter errors converge by analysing the shape of the boundary between the two sets. On this boundary
, and thus,
(26)
(26)
It is easy to verify that both the origin and the state with e = 0 and reside on this boundary. Furthermore, Equation (Equation26
(26)
(26) ) resembles an ellipsoid in the error space centred at e
c
= 0 and
. An alternative formulation of this ellipsoid is
The eigenvectors of the positive definite matrix E define the principal axes of the ellipsoid. The length of the semi-axes is given by the square root of the inverse eigenvalues of E. visualises the ellipsoid for a two-dimensional parameter vector θ = [θ1, θ2]⊤.
In a last step, exploiting the triangle inequality on the centroid of the ellipsoid and its maximal semi-principal axis (characterised by the minimal eigenvalue) gives an approximation of the ball around the true parameters to which the estimates converge in the presence of errors :
where ‖ · ‖ is the Euclidean norm and λmin ( · ) denotes the minimum eigenvalue. Compare with for a visual interpretation of this approximation.
While the discussion of concurrent learning thus far involved only PWA systems, it is stressed that the results also apply for PWL systems. In PWL systems, there is no affine input vector f. Consequently, deleting the terms related to f yields the special case of PWL systems. Importantly, this removes the constant 1 in Assumption 3.1 and in the definitions of Ψ and Ξ.
From an adaptive control or identification point of view, the above proof is remarkable in a sense that convergence is guaranteed without the usual PE requirement. The linear independence of the history stack elements (required by Assumption 3.1) replaces PE. This is beneficial as linear independence is considerably easier to monitor than PE. Furthermore, excitation over a limited period of time suffices to record linear independent data.
4. History stack management in concurrent learning
In the discussion of concurrent learning, the stack elements were thus far assumed to be constant. However, looking back at Equation (Equation25(25)
(25) ), one realises that parameter convergence is maintained as long as Q
θ remains positive definite. In other words, as long as Q
θ is ensured to be positive definite, one can arbitrarily replace history stack elements. From a control theoretic perspective, this resembles switching between different stable dynamics that share the common Lyapunov function V. In the following steps, this is exploited in order to further improve the performance of concurrent learning adaptive identification.
4.1 Populating the history stacks
Since initially all history stacks are empty and Assumption 3.1 is violated, consider first the process of populating the history stacks. The history stacks need to be filled with at least n + p + 1 linearly independent elements. Also, a new data point should be sufficiently different from the previously recorded data point. Let Φ(t)≜[x(t)⊤, u(t)⊤]⊤ be the state-input vector at time instance t and let Φprev denote the last recorded state-input vector. In concurrent learning, it is common to refer to a new measurement Φ(t) as sufficiently different if the following inequality is satisfied (Chowdhary et al., Citation2013):
(27)
(27) where the threshold
is a design parameter. Until the history stack fulfils Assumption 3.1, a new measurement is added to the history stack if x and u are linearly independent of all previously recorded elements and if they fulfil Equation (Equation27
(27)
(27) ).
4.2 Maximising the rate of convergence
In order to confine computational complexity, the number of recorded data elements q is limited. Once the history stack is filled with q data points, it has to be reasoned whether replacing old data with new data is beneficial or not.
With the derivative of the Lyapunov function in Equation (Equation25(25)
(25) ), we are able to characterise the rate of convergence. Note that in the ideal case (
), the derivative of the Lyapunov function of an inactive subsystems (e = 0) is bounded by
(28)
(28)
It is thus intuitive to record stack elements and
such that the minimum eigenvalue of Q
θ is maximised, as this maximises the rate of convergence. Especially for full history stacks, this approach allows to reason whether or not it is beneficial to replace an existing stack element with a new measurement. While the same idea is also applied in concurrent learning adaptive identification by Kersting and Buss (Citation2014b), it was Chowdhary et al. (Citation2013) who originally introduced it to concurrent learning adaptive control.
Note that the maximisation of the convergence rate also affects the centroid , which characterises the remaining parameter error. Approximate the squared norm of
as follows:
(29)
(29) According to Equation (Equation29
(29)
(29) ), improving the convergence rate by maximising λmin (Q
θ) provides a second benefit. That is, with increased λmin (Q
θ), the error term Δ – caused by errors
in the estimation of
– has a weakened effect on the parameter errors.
4.3 Detecting erroneous history stack elements
Section 3 explained that wrongly recorded or estimated stack elements hinder convergence to the true parameters. This problem has received limited attention in previous works on concurrent learning, excluding De La Torre et al. (Citation2013). Therefore, concurrent learning is expected to work well in case of constant system parameters. However, if system parameters change over time (e.g. due to ageing or wear), then history stack elements become outdated and estimates converge to (or are stuck at) wrong values.
Here we describe the first algorithm to detect and remove erroneous stack elements online (Kersting & Buss, Citation2015), which is based on the result of Section 3: i.e. estimated parameters converge to an ellipsoidal set in the parameter space (depicted in ) in the presence of erroneous history stack elements.
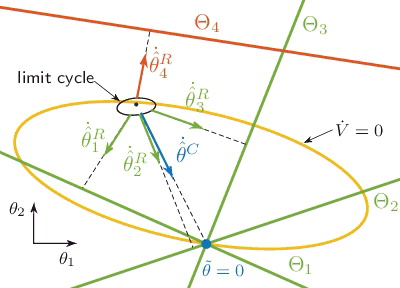
In order to understand the cause of this ellipsoid, note that each triplet () in the history stack spans a subspace Θ
j
in the parameter space. The subspace Θ
j
, associated with the jth triplet, contains all parameter configurations that cannot be falsified by the measurements
, i.e.
(30)
(30) The parameter configurations
form the solution of an under-determined system of equations, from which the dimension of Θ
j
can be found to be
.
In the error-less case (δ
j
= 0, ∀j) and under Assumption 3.1, all subspaces intersect at a single point θ = ∪
q
j = 1Θ
j
, for which . In case δ
j
≠ 0, however, the subspaces do not intersect at a single point. displays an example with four subspaces. The first three subspaces represent the subspaces of error-less history stack triplets. The fourth subspace corresponds to an erroneous history stack element, which is therefore shifted away from the intersection point. Due to the shifted subspace Θ4, the estimates do not converge to the true parameter configuration θ. Instead the estimates enter a limit cycle in the ellipsoidal set as shown in the proof of Theorem 3.1. In turn, the prediction error does not converge to zero, i.e. e ≠ 0 or greater than some threshold in the presence of noise.
Figure 3. Exemplary limit cycle in a two-dimensional parameter space. The history stack has four elements for which only δ4 ≠ 0. The update vectors are an orthogonal projection onto Θ
j
.
The strategy to detect erroneous history stack elements is to compare the individual contributions in the update laws (Equation20(20)
(20) ). Hence, let the contribution of the current measurements and of the jth history stack triplet be denoted by
(31)
(31)
(32)
(32) where
which combined in
form the original update laws (Equation20
(20)
(20) ).
Next, note that the recorded data-based update laws (Equation32(32)
(32) ) correspond to an orthogonal projection onto the subspaces Θ
j
. For correct history stack triplets, this projection points into the ellipsoid. Also the current data-based update (Equation31
(31)
(31) ) drives the estimates towards the true parameter configuration under the assumption of persistent excitation. Therefore,
serves as a reference point. Convergence is prevented if at least one erroneous stack element exists and points out of the ellipsoid. Therefore, the directional information compared to the current data-based update law is used to reason about the erroneous history stack elements.
Note that the PE requirement for the reference point should not be understood as a limitation at this point. Once the history stack is known to contain erroneous elements, one must in any case record new measurements. In order to fulfil Assumption 3.1, excitation of the system is beneficial. During the collection of new measurements, it can be reasoned which elements are erroneous and need to be replaced. While the existence of measurements, which satisfy Assumption 3.1, is guaranteed under PE, it is not a necessary condition. Future work could analyse how the following ideas perform without PE. As shown in the proof of Theorem 2.1, PE can be ensured by choosing input signals sufficiently rich of order n + 1 with distinct frequencies.
In order to analyse to which extent the recorded data-based update laws (Equation32(32)
(32) ) coincide with the reference vector
, define for each stack element j the angle ϕ
j
between
and
:
(33)
(33)
Note that statements, which are based on the angles ϕ
j
, are only meaningful if the norms of the corresponding vectors are sufficiently large. Therefore, we introduce the two thresholds ϑ
C
and ϑ
R
for and
, respectively. If
, the current data-based update vector fails to qualify as a reliable reference point. This is for instance the case if the parameter estimates are in the vicinity of the true parameters. For
, the contribution of the jth history stack element is very small. In this case, the jth history stack triplet
cannot be falsified by the current estimates
. In summary, falling below these two thresholds corresponds to good estimates. The angle ϕ
j
is therefore set to zero whenever one of the two thresholds is not exceeded:
(34)
(34)
The parameter estimates and angles ϕ
j
are time-varying for sinusoidal excitation and enter into a limit cycle. Due to the known excitation u, the frequency of this limit cycle can be approximated. Since we are interested in the update directions on average, consider the low-pass filtered angles
, where the cut-off frequency of the filter is lower than the lowest excitation frequency in u. The following algorithm to detect and remove erroneous history stack elements is based on the filtered angles
.
Algorithm 1:
Consider the concurrent learning-based update law in Theorem 3.1 with errors δ
j
. Monitor the filtered angles according to Equations (Equation33
(33)
(33) ) and (Equation34
(34)
(34) ). If the parameter estimates enter a limit cycle (i.e. e ≠ 0 and
), replace the kth history stack triplet, where
(35)
(35) by a new measurement with
in order to reduce the errors in the history stack.
Since PE constitutes a critical assumption in adaptive systems, we want to complete the theoretical part of this paper by briefly repeating the role of PE in the presented algorithms. For the parameter identifiers discussed in Theorems 2.1 and 2.2, PE is a necessary condition for parameter convergence. The concurrent learning-based parameter identifiers in Theorem 3.1 replace PE by linear independence of the history stack elements. While PE in this context guarantees the existence of linearly independent measurements, PE is by no means necessary in order to obtain them. In case of an erroneous history stack element, we propose in Algorithm 1 to resume PE over a limited period of time in order to detect and replace the erroneous element. Once the erroneous element is replaced, convergence can proceed without PE.
5. Numerical validation
In this section, we numerically validate the proposed update laws for PWA systems as well as Algorithm 1 for the detection of erroneous history stack elements in concurrent learning. First, the advantage of concurrent learning over traditional adaptation is demonstrated for a linear bimodal system. Then, we analyse the estimation and tracking of time-varying parameters with concurrent learning-based parameter identifiers. Afterwards, we compare the proposed algorithm with Recursive Least Squares and with an alternative approach to enable tracking in concurrent learning (De La Torre et al., Citation2013). Finally, we apply concurrent learning for the adaptive identification of a hybrid two-tank system.
5.1 Benefit of concurrent learning
First, consider a bimodal PWL system with n = 1 and p = 1. Let the parameters for the two subsystems be
The initial state is x = 1 and the control input is an exponentially decaying sinusoidal signal: u(t) = 5e−0.1t
sin (t). The state derivatives are estimated with fixed point smoothing.
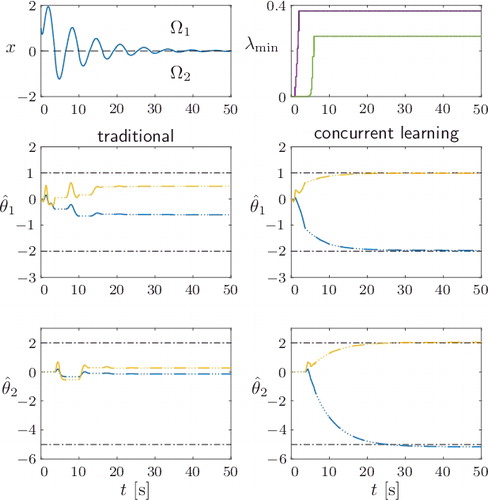
Simulation results with and without concurrent learning are shown in for the design parameters −A m = P = Γ1 = Γ2 = 1. The exponentially decaying state does not yield a persistent excitation of the system. Hence, the estimates do not converge under the traditional update laws. For concurrent learning, the initial excitation is sufficient to fill the history stacks with linear independent data, which can be seen from the increase in λmin . Based on the recorded data, exponential convergence is achieved for both active (solid lines) and inactive (dotted lines) subsystems. This comparison demonstrates the benefit of concurrent learning in terms of reduced PE requirements and increased convergence rates.
Figure 4. Comparison of parameter identifiers without (left column) and with (right column) concurrent learning. The top left shows the exponentially decaying excitation of the state in both cases. The top right shows the minimum eigenvalues associated with the two history stacks for the concurrent-learning-based estimation.
5.2 Parameter estimation and tracking
First, on a time interval t ∈ [0, 700) s, consider the following PWA system (n = 2, p = 1), which consists of three subsystems with the unknown parameter vectors
and the known state-space partitions
To test the tracking abilities, the subsystems abruptly change their parameters at time instance t = 700 s. During the second interval t ∈ [700, 1400) s, the parameters are
The system is excited with , where
is a ramp-like offset shown in , which drives the system into all regions. Therefore, the input signal u is sufficiently rich of order 6, which enables traditional updating according to Theorem 2.1 as well as recording linearly independent data according to Theorem 3.1. Gaussian white noise with zero mean and 10−3 variance is added to the state measurement x.
Figure 5. Offset in the input signal u(t).

The scaling constants are for balanced adaptation of A
i
, B
i
and f
i
. For unknown system parameters, we choose the design parameters P = I
2 and
. All parameter estimates
are initially zero and the history stacks of size q = 4 are initially empty. Selected estimates of the state derivative for the history stacks are obtained with fixed point smoothing. The design parameters for the detection of erroneous history stack elements are ϑ
C
= 0.09,
.
shows the evolution of estimates for all subsystems i = 1, 2, 3 on the entire time interval [0, 1400] s. The figure shows that once a subsystem is activated for the first time, its history stacks are quickly filled with measurements and the parameter estimates converge to the true parameters. Note that the transition between two regions is characterised by multiple switches due to the sinusoidal excitation. These switches likely cause the smoothing process to result in erroneous history stack elements. Especially the estimates
converge to wrong parameters between 400 and 450 s. The proposed detection algorithm, however, detects and removes these erroneous elements once the system remains in Ω3 for a sufficiently long time.
Figure 6. Identification and tracking of PWA subsystem parameters with concurrent-learning-based parameter identifiers and removal of erroneous history stack elements.
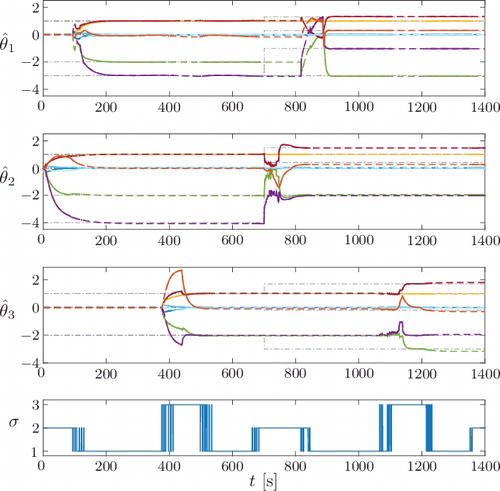
The evolution of after the parameter change at 700 s shows that the system enters into a limit cycle due to the parameter mismatch. This can be seen by oscillating estimates, which naturally triggers the proposed detection algorithm. In turn, outdated history stack elements taken before the change are successfully replaced. As can also be seen from the figure, the removal of erroneous history stack elements only takes place for the active subsystem, which is why
reacts to the parameter change with a delay of 400 s. Approximately 100 s after a subsystem is activated, the corresponding history stacks do not contain outdated measurements taken with θ′
i
anymore and the estimates converge to the true parameters θ′′
i
.
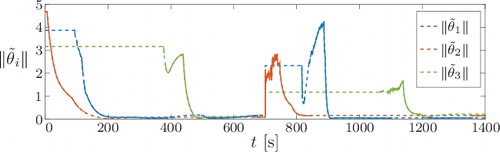
shows the normed parameter errors for all subsystems. At around 400 and 900 s, it can be seen that the sequential removal of erroneous history stack elements according to Algorithm 1 might lead to a temporary increase in the parameter errors. As shown in the proof of Theorem 3.1, however, all errors remain bounded.
Figure 7. Normed parameter errors during concurrent-learning-based parameter estimation with removal of erroneous history stack elements. The lines are dashed for inactive and solid for active subsystems.
5.3 Comparison with cyclic replacement and recursive least squares
Reducing the parameter error in the presence of errors δ
j
constitutes a major advantage of the proposed algorithm over other approaches. In this section, we demonstrate this by comparing our approach with the cyclic replacement approach proposed by De La Torre et al. (Citation2013) and recursive least squares (RLS) (see Ljung, Citation1987, Chapter 11) applied to an affine linear time-invariant (LTI) system. In De La Torre et al. (Citation2013), the ageing of data is modelled with an exponential decay (e
−0.01t
) on the current history stack. Once a new history stack outperforms the current history stack, the entire history stack is replaced. For the following comparison, the standard RLS algorithm was implemented on the history stack measurements x
j
, u
j
and
with a forgetting factor γ = 0.95.
A stable, randomly chosen state-space system of higher order (n = 5, p = 2) is considered, i.e. . The system is excited with input signals
and
, each sufficiently rich of order 6 with distinct frequencies. We initialise the history stacks with q = 10 measurements. The errors of each stack element are drawn from a normal distribution
. For 2000 s, the stack elements with the greatest errors (detected by the mechanism according to Algorithm 1) are replaced by new measurements. Note that the errors δ
j
of new elements follow the same normal distribution as the initial errors. The chosen design parameters are the same as in Section 5.2.
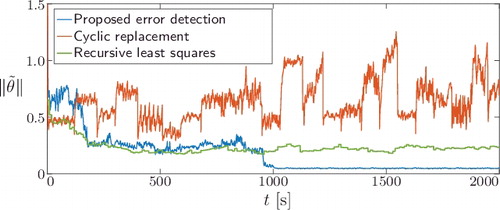
shows the estimation process in terms of the normed parameter errors for all three approaches. The normed parameter error for the cyclic replacement approach is greater than the normed error obtained with our error detection approach, because the cyclic replacement exchanges the entire history stack at once. In that case, it is likely that the history stack contains elements with similarly large errors, leading to no improvement. Even though RLS provides lower estimation errors than concurrent learning with cyclic replacement, it is still affected by the errors δ
j
. In contrast, the algorithm proposed here selectively replaces the most erroneous history stack element. After about 900 s, the algorithm has found history stack elements with sufficiently small errors which cause the update terms to fall below the thresholds ϑ
C
and ϑ
R
in Equation (Equation34(34)
(34) ). This terminates the proposed detection algorithm and the history stack is left unchanged. Consequently, the estimates converge to the smallest neighbourhood of the true parameters, as can be seen from the smallest normed parameter error.
Figure 8. Comparison between the proposed detection mechanism for erroneous stack elements and a cyclic replacement of the entire history stack and Recursive Least Squares.
5.4 Adaptive identification of a hybrid two-tank system
We apply the proposed algorithm to estimate the parameters of a PWA model for the hybrid two-tank system shown in . The system consists of two tanks, each of height 4 m. The cross-sectional areas of the tanks are C
t1 = 1.54 m2 and C
t2 = 0.79 m2. Two pipes connect the tanks: one at the bottom of the tanks and one at height h
c
= 2 m. The cross-sectional area of the upper pipe is C
p1 = 0.0314 m2, which is wider than the one of the lower pipe C
p2 = 0.0079 m2. The only outflow of the system is through the pipe with cross-sectional area at the bottom of the right tank.
Figure 9. Hybrid two-tank system with two connecting pipes.
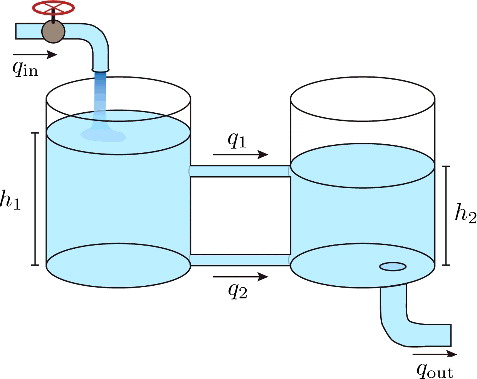
The control input is the inflow to tank 1: u = q
in. The levels in the tanks h
1 and h
2 form the states of the system and are governed by the flows q
1/2 between the tanks
and the outflow from the second tank
. The dynamics of the states are
Note that the system dynamics are on the one hand non-linear due to the Bernoulli equation and on the other hand hybrid due to the sudden change in dynamics as the level h
1 rises above the connecting pipe. Hence, this example is the first showcase of the proposed parameter identifiers to simultaneously approximate non-linear and hybrid effects by PWA systems.
The maximal inflow u
max = 0.127 m3/s, at which the tanks will overflow, limits the controlled inflow u. The system is excited by two sinusoidal signals with amplitudes 0.3u
max and with frequencies 0.4 and 1 rad/s. Furthermore, a triangle-like offset that alternates between 0.2u
max and 0.9u
max is added to u and Gaussian noise is added to the measured tank levels.
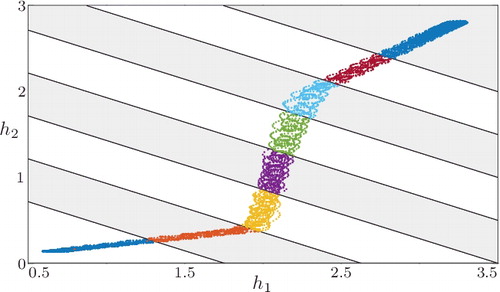
For the a-priori partitioning of the state-input space, we incorporate the previous knowledge that the system does not switch with respect to the inflow u. Hence, only the two-dimensional state-space is partitioned. The state-space partitions together with the state-space trajectory obtained with the excitation signal are shown in . The figure at the same time suggests that the system may not be approximated well by an LTI model.
Figure 10. State-space trajectory for excitation with triangle-like offset and two sinusoidal signals. The state-space partitions are given by gray and white stripes.
The concurrent learning design parameters are A m = −I n , P = I n , Γ = I n(n + p + 1), q = 18 and ν = 0.03. We excited the system for 4000 s and the parameter estimates in each subsystem converged about 500 s after the corresponding history stacks satisfied Assumption 3.1.
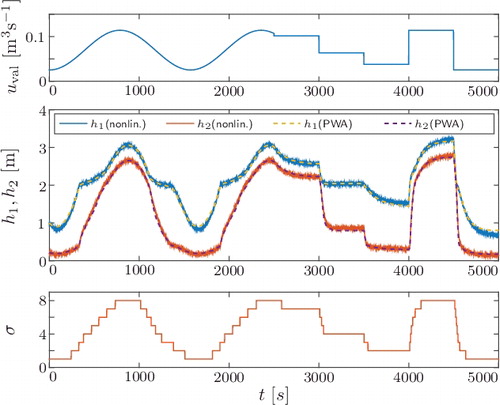
The comparison between the estimated PWA system and the hybrid two tank is shown in . The excitation for this experiment differs from the training data which was used to estimate the model parameters. As can be seen from the figure, the estimated PWA system approximates well the non-linear, switching dynamics of the hybrid two-tank system.
Figure 11. Comparison of the hybrid two-tank system with the obtained PWA model for the validation input .
6. Conclusions
This paper extends linear parameter identifiers to switched systems in the form of PWL and PWA systems. In the case of PWA systems, it is shown that the affine input violates classical assumptions on the richness of input signals. This violation is compensated by restricting the applicability to invertible system matrices. A neat state reset associated with detected switches secures stability of the estimation process, even for arbitrarily fast switching. Despite the maintained stability, fast switching does affect the rate of convergence. The proposed parameter identifiers for PWA systems are further improved by concurrent learning, where recorded data are used concurrently with instantaneous data. In the switched system setting, this allows to adapt even currently inactive parameter estimates and yields faster convergence. Furthermore, it is shown that the main drawback of concurrent learning, caused by outdated or erroneous history stack elements, can be overcome by the proposed outlier detection algorithm. Numerical simulations of both theoretical systems as well as a non-linear hybrid two-tank system validate the performance of parameter identifiers using concurrent learning. Future work focuses on deriving identifiers for systems with partial state measurement and unknown state-space partitions.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Azuma, S. , Imura, J. , & Sugie, T. (2010). Lebesgue piecewise affine approximation of nonlinear systems. Nonlinear Analysis: Hybrid Systems, 4 (1), 92–102.
- Bako, L. (2014). Subspace clustering through parametric representation and sparse optimization. IEEE Signal Processing Letters, 21 (3), 356–360.
- Bako, L. , Boukharouba, K. , Duviella, E. , & Lecoeuche, S. (2011). A recursive identification algorithm for switched linear/affine models. Nonlinear Analysis: Hybrid Systems, 5 (2), 242–253.
- Bako, L. , Mercère, G. , & Lecoeuche, S. (2009). On-line structured subspace identification with application to switched linear systems. International Journal of Control, 82 (8), 1496–1515.
- Bako, L. , Mercère, G. , Vidal, R. , & Lecoeuche, S . (2009, July). Identification of switched linear state space models without minimum dwell time. In E. Walter (Eds.), Proceedings of the 15th IFAC symposium on system identification (pp. 569–574). Saint-Malo, France: Elsevier.
- Bako, L. , van Luong, L. , Lauer, F. , & Bloch, G . (2013, June). Identification of MIMO switched state-space models. In Proceedings of the american control conference (ACC) (pp. 71–76). Washington, DC: IEEE.
- Bamieh, B. , & Giarré, L. (2002). Identification of linear parameter varying models. International Journal of Robust and Nonlinear Control, 12 (9), 841–853.
- Blackmore, L. , Gil, S. , Seung, C. , & Williams, B . (2007, December). Model learning for switching linear systems with autonomous mode transitions. In 46th IEEE conference on decision and control (pp. 4648–4655). New Orleans, LA: IEEE.
- Branicky, M. S. (1998). Multiple Lyapunov functions and other analysis tools for switched and hybrid systems. IEEE Transactions on Automatic Control, 43 (4), 475–482.
- Chen, D. , Bako, L. , & Lecoeuche, S . (2011, September). A recursive sparse learning method: Application to jump Markov linear systems. In S. Bittanti (Eds.), Proceedings of the 18th IFAC world congress (pp. 3198–3203). Milan, Italy: Elsevier.
- Chowdhary, G. (2010). Concurrent learning for convergence in adaptive control without persistency of excitation ( Unpublished doctoral dissertation). Atlanta, GA: Georgia Institute of Technology.
- Chowdhary, G. , & Johnson, E . (2010, December). Concurrent learning for convergence in adaptive control without persistency of excitation. In Proceedings of the 49th IEEE conference on decision and control (CDC) (pp. 3674–3679). Atlanta, GA: IEEE.
- Chowdhary, G. , Mühlegg, M. , How, J. P , & Holzapfel, F . (2013, December). A concurrent learning adaptive-optimal control architecture for nonlinear systems. In Proceedings of the 52nd IEEE conference on decision and control (pp. 868–873). Firenze, Italy: IEEE.
- Chowdhary, G. , Mühlegg, M. , & Johnson, E. (2014). Exponential parameter and tracking error convergence guarantees for adaptive controllers without persistency of excitation. International Journal of Control, 87 (8), 1583–1603.
- Chowdhary, G. , Yucelen, T. , Mühlegg, M. , & Johnson, E. N. (2013). Concurrent learning adaptive control of linear systems with exponentially convergent bounds. International Journal of Adaptive Control and Signal Processing, 27 , 280–301.
- De La Torre, G. , Chowdhary, G. , & Johnson, E. N . (2013, June). Concurrent learning adaptive control for linear switched systems. In Proceedings of the American control conference (ACC) (pp. 854–859). Washington, DC: IEEE.
- Di Bernardo, M. , Montanaro, U. , & Santini, S . (2008, December). Novel switched model reference adaptive control for continuous piecewise affine systems. In Proceedings of the 47th IEEE conference on decision and control (pp. 1925–1930). Cancun, Mexico: IEEE.
- Di Bernardo, M. , Montanaro, U. , & Santini, S . (2009, December). Hybrid minimal control synthesis identification of continuous piecewise linear systems. In Proceedings of the 48th IEEE conference on decision and control and 28th chinese control conference (pp. 3188–3193). Shanghai, China: IEEE.
- Di Bernardo, M. , Montanaro, U. , & Santini, S. (2013). Hybrid model reference adaptive control of piecewise affine systems. IEEE Transactions on Automatic Control, 58 (2), 304–316.
- Feiler, M. J. , & Narendra, K . (2006, December). Simultaneous identification and control of time-varying systems. In Proceedings of the 45th IEEE conference on decision and control (pp. 1093–1098). San Diego, CA: IEEE.
- Feiler, M. J. , & Narendra, K . (2008, June). Identification and control using multiple models. In Proceedings of the 14th Yale workshop on adaptive and learning systems (pp. 33–42). New Haven, CT: Yale University Center of Systems Science.
- Ferrari-Trecate, G. , Muselli, M. , Liberati, D. , & Morari, M. (2003). A clustering technique for the identification of piecewise affine systems. Automatica, 39 (2), 205–217.
- Garnier, H. (2015). Direct continuous-time approaches to system identification. Overview and benefits for practical applications. European Journal of Control, 24 , 50–62.
- Garulli, A. , Paoletti, S. , & Vicino, A . (2012, July). A survey on switched and piecewise affine system identification. In Proceedings of the 16th IFAC Symposium on system identification (pp. 344–355). Brussels, Belgium: Elsevier.
- Gil, S. , & Williams, B . (2009, December). Beyond local optimality: An improved approach to hybrid model learning. In Proceedings of the 48th IEEE conference on decision and control and 28th Chinese control conference (pp. 3938–3945). Shanghai, China: IEEE.
- Heemels, W. P. M. H. , Schutter, B. D. , & Bemporad, A. (2001). Equivalence of hybrid dynamical models. Automatica, 37 (7), 1085–1091.
- Ioannou, P. , & Sun, J . (1996). Robust adaptive control . Upper Saddle River, NJ: Prentice-Hall.
- Jazwinski, A. H . (1970). Stochastic processes and filtering theory . New York, NY: Academic Press.
- Kamalapurkar, R. , Walters, P. , & Dixon, W. E. (2016). Model-based reinforcement learning for approximate optimal regulation. Automatica, 64 , 94–104.
- Kersting, S. , & Buss, M . (2014a, June). Adaptive identification of continuous-time switched linear and piecewise linear systems. In Proceedings of the European control conference (ECC) (pp. 31–36). Strasbourg, France: IEEE.
- Kersting, S. , & Buss, M . (2014b, December). Concurrent learning adaptive identification of piecewise affine systems. In Proceedings of the 53rd IEEE conference on decision and control (CDC) (pp. 3930–3935). Los Angeles, CA: IEEE.
- Kersting, S. , & Buss, M. (2014c, July). Online identification of piecewise affine systems. In Proceedings of the UKACC 10th international conference on control (pp. 90–95). Loughborough, UK: IEEE.
- Kersting, S. , & Buss, M . (2015, December). Removing erroneous history stack elements in concurrent learning. In Proceedings of the IEEE 54th annual conference on decision and control (pp. 7604–7609). Osaka, Japan: IEEE.
- Klotz, J. , Kamalapurkar, R. , & Dixon, W. E . (2014, June). Concurrent learning-based network synchronization. In Proceedings of the American control conference (ACC) (pp. 796–801). Portland, OR: IEEE.
- Lauer, F. , Bloch, G. , & Vidal, R. (2011). A continuous optimization framework for hybrid system identification. Automatica, 47 (3), 608–613.
- Liberzon, D . (2003). Switching in systems and control . New York, NY: Springer Science+Business Media.
- Ljung, L. (1987). System identification: Theory for the user . Englewood Cliffs, NJ: Prentice-Hall.
- Lopes, L. R. , Borges, G. A. , & Ishihara, J. Y . (2013, June). New algorithm for identification of discrete-time switched linear systems. In Proceedings of the American control conference (ACC) (pp. 6219–6224). Washington, DC: IEEE.
- Maruta, I. , Sugie, T. , & Kim, T . (2011, September). Identification of multiple mode models via distributed particle swarm optimization. In S. Bittanti (Eds.) Proceedings of the 18th IFAC world congress (pp. 7743–7748). Milan, Italy: Elsevier.
- Modares, H. , Lewis, F. L. , & Naghibi-Sistani, M.-B. (2014). Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems. Automatica, 50 (1), 193–202.
- Narendra, K. , & Annaswamy, A. M . (2005). Stable adaptive systems . Mineola, NY: Dover Publications.
- Paoletti, S. , Juloski, A. L. , Ferrari-Trecate, G. , & Vidal, R . (2007). Identification of hybrid systems: A tutorial. European Journal of Control, 13 (2–3), 242–260.
- Pekpe, K. M. , & Lecœuche, S . (2008). Online clustering of switching models based on a subspace framework. Nonlinear Analysis: Hybrid Systems, 2 (3), 735–749.
- Petreczky, M. (2011). Realization theory for linear and bilinear switched systems: A formal power series approach. ESAIM: Control, Optimisation and Calculus of Variations, 17 (2), 410–445.
- Petreczky, M. , & Bako, L . (2011, December). On the notion of persistence of excitation for linear switched systems. In Proceedings of the 50th IEEE conference on decision and control and european control conference (CDC-ECC) (pp. 1840–1847). Orlando, FL: IEEE.
- Petreczky, M. , Bako, L. , & van Schuppen, J. H . (2010, April). Identifiability of discrete-time linear switched systems. In Proceedings of the 13th ACM international conference on hybrid systems: Computation and control (pp. 141–150). Stockholm, Sweden: ACM.
- Petreczky, M. , & van Schuppen, J. H. (2010). Realization theory for linear hybrid systems. IEEE Transactions on Automatic Control, 55 (10), 2282–2297.
- Petreczky, M. , & van Schuppen, J. H. (2011). Partial-realization theory for linear switched systems – a formal power series approach. Automatica, 47 (10), 2177–2184.
- Sang, Q. , & Tao, G . (2012). Adaptive control of piecewise linear systems: The state tracking case. IEEE Transactions on Automatic Control, 57 (2), 522–528.
- Shumway, R. H. , & Stoffer, D. S . (2006). Time series analysis and its applications: With R examples (2nd updated ed.). New York, NY: Springer.
- Simon, D . (2006). Optimal state estimation: Kalman, H [infinity] and nonlinear approaches . Hoboken, NJ: Wiley-Interscience.
- Tóth, R. (2010). Modeling and identification of linear parameter-varying systems (Vol. 403). Berlin: Springer.
- Verdult, V. , & Verhaegen, M. (2002). Subspace identification of multivariable linear parameter-varying systems. Automatica, 38 (5), 805–814.
- Vidal, R . (2008). Recursive identification of switched ARX systems. Automatica, 44 (9), 2274–2287.
- Vidal, R. , Soatto, S. , Yi, M. , & Sastry, S. (2003, December). An algebraic geometric approach to the identification of a class of linear hybrid systems. In Proceedings of the 42nd IEEE conference on decision and control (pp. 167–172). Maui, HI: IEEE.
- Wang, J. , & Chen, T. (2011, March). Online identification of switched linear output error models. In Proceedings of the IEEE international symposium on computer-aided control system design (CACSD) (pp. 1379–1384). Tucson, AZ: IEEE.
- Wawrzyński, P . (2009). Real-time reinforcement learning by sequential actor–critics and experience replay. Neural Networks, 22 (10), 1484–1497.
Appendix A. Definitions and lemmas
This appendix repeats definitions and lemmas from Ioannou and Sun (Citation1996) which are needed for the convergence proofs in this paper. Another excellent introduction to the field of adaptive control is Narendra and Annaswamy (Citation2005). PE plays a fundamental role in the convergence of adaptive systems.
Definition A.1
(Ioannou & Sun, Citation1996, Def. 4.3.1): A piecewise continuous signal vector is persistently excited in
with a level of excitation α0 > 0 if there exist constants α1, T
0 > 0 such that
The following lemmas are used to prove convergence in Theorem 2.1 and Lemma 2.1 in Section 2.
Lemma A.1
(Ioannou & Sun, Citation1996, Lem. 5.6.1): If the auto-covariance of a function defined as
exists and is uniform with respect to t
0, then z is persistently exciting if and only if R
z
(0) is positive definite.
Lemma A.2
(Ioannou & Sun, Citation1996, Lem. 5.6.3): Consider the system described by
(A1)
(A1) where
,
for some integer g, n
1 ≥ 1, and
are constant matrices and F(t) is of the form
where z
i
, i = 1, 2,… , g are the elements of the vector
. Suppose that z is persistently excited and there exists a matrix P
0 > 0 such that
(A2)
(A2) where
Then, the equilibrium ξ1e
= 0, ξ2e
= 0 of Equation (EquationA1
(A1)
(A1) ) is exponentially stable in the large.
For PWA systems, the PE condition on z in Lemma A.2 can be guaranteed by Lemma 2.1, which is proposed in Section 2. The corresponding proof is given here for improved readability.
Proof of Lemma 2.1:
Lemma 2.1 is shown with the help of Lemma A.1 and a frequency domain relationship between z and the inputs u. Note that the affine term f can be seen as the input matrix of an additional constant input of 1. Therefore, let z be related to the constant input via a transfer function H
f
(s). Furthermore, let the transfer function H
k
(s) relate z to the kth input u
k
. The dimensions of H
f
(s) and H
k
(s) are (n + p + 1) × 1. Overall, z is related to the inputs by
where b
k
denotes the kth column of B and
denote the kth and (p + 1)th column of the identity matrix
, i.e.:
Under the assumption of distinct input frequencies, the auto covariance of z is given by
(A3)
(A3) where S
1(ω) and
are the spectral distributions of the constant input 1 and the input u
k
, respectively. Since u
k
is sufficiently rich of order n + 1, its spectrum has n + 1 distinct peaks
at frequencies ω
kl
, l = 1, …n + 1. The affine term f results in a spectral peak at zero. The spectral distributions are
(A4)
(A4) where δ(ω = 0) = 1 and δ(ω ≠ 0) = 0. With Equation (EquationA4
(A4)
(A4) ), the integrals in Equation (EquationA3
(A3)
(A3) ) are replaced by summations:
(A5)
(A5)
According to Lemma A.1, the vector z is persistently exciting if Equation (EquationA5(A5)
(A5) ) is positive definite, i.e. the quadratic equation
(A6)
(A6) can only have a single solution at χ = 0
n + p + 1. Note that the outer products H
k
( − jω
kl
)H
k
(jω
kl
)⊤ of the column vectors H
k
(jω
kl
) are positive semi-definite. Therefore, each summand in Equation (EquationA5
(A5)
(A5) ) is positive semi-definite and Equation (EquationA6
(A6)
(A6) ) is equivalent to
(A7)
(A7) where
First, χ⊤
R
z1(0)χ = 0 is solved for χ. As all the summands of R
z1(0) are positive semi-definite, this equality only holds if
or equivalently
(A8)
(A8) The transfer function H
k
(s) can also be written as
(A9)
(A9) where
. Therefore, the equalities (EquationA8
(A8)
(A8) ) are also equivalent to
(A10)
(A10)
Each vector element of is a polynomial in ω
kl
of maximal order n (see Equation (EquationA9
(A9)
(A9) )). So after multiplying with χ,
is also a polynomial in s of maximal order n. For a given k, Equation (EquationA10
(A10)
(A10) ) states that g
k
(s) is zero at n + 1 frequencies or values of s. As g
k
(s) is only of order n, it follows that
. Combining the p equalities of Equation (EquationA10
(A10)
(A10) ) in matrix form gives
(A11)
(A11) where
is a p-dimensional zero vector. Next, the vector χ is expressed as
, with
,
and
. This leads to
(A12)
(A12)
The following expressions for adj(sI
n
− A)B and a(s) are applied to Equation (EquationA12(A12)
(A12) )
which results in a polynomial of order n. All coefficients of the resulting polynomial must be zero, so that the polynomial is zero independent of s. This leads to n equalities that can be written in a compact form:
With (A, B) controllable, it follows that the matrix [B, AB,… , A
n − 1
B] is of full rank. Therefore, the equality (EquationA12(A12)
(A12) ) holds for
,
and an arbitrary
. Consequently, R
z1(0) is only positive semi-definite. Therefore, R
z2(0) in Equation (EquationA7
(A7)
(A7) ) must restrict the choice of
further, i.e. χ⊤
R
z2(0)χ = 0 for
,
and
. The same arguments as above lead to
and with
result in
(A13)
(A13)
Since R
z1(0) and R
z2(0) are both positive semi-definite, one needs to find those χ for which χ⊤
R
z1(0)χ = 0 and χ⊤
R
z2(0)χ = 0. In order to ensure χ⊤
R
z1(0)χ = 0, it is thus necessary to assume and
in Equation (EquationA13
(A13)
(A13) ). With a(j0) = a
0, Equation (EquationA13
(A13)
(A13) ) reduces to a
0
Z = 0. Since A is assumed to be invertible, we have a
0 ≠ 0. Therefore,
in order to ensure
with
and
. This shows that χ⊤
R
z
(0)χ = 0 only holds for χ = 0
n + p + 1 and thus proves positive definiteness of R
z
(0) and according to Lemma A.1 makes z persistently exciting.