
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Online peer-to-peer (P2P) lending is a new form of loans. Different from traditional banks, lenders provide loans to borrowers directly through P2P platforms. Since many P2P loans are unsecured personal loans, credit rating of loans is vital to control default risk and improve profit for lenders and platforms. Standard binary classifiers are inappropriate in P2P lending because there are multiple credit classes and misclassification costs vary largely across classes in P2P lending. Though there are a few works that studied cost-sensitive classifiers in P2P lending, none of them have analyzed this issue from the perspective of multi-class classifications and measured misclassification costs of different credit grades using real losses and opportunity costs. The objective of this paper is to model credit rating in P2P lending as a cost-sensitive multi-class classification problem. We proposed a misclassification cost matrix for P2P credit grading with a set of equations and models to calculate the costs. An experiment using publicly available data from Lending Club was conducted to validate the usefulness of the proposed misclassification cost matrix. The results showed that the cost-sensitive classifiers can significantly reduce the total cost, which is essential for the survival and profitability of P2P platforms.
1. Introduction
In the past decade, online peer-to-peer (P2P) lending, as a popular form of personal loan, has emerged in credit market. It transfers traditional way of face-to-face personal loans through online services (Bachmann et al., Citation2011). P2P lending is an electronic marketplace where individual lenders provide loans to individual borrowers. It is pervasive, convenient, efficient, and low-cost without the involvement of traditional financial institutions (Guo, Zhou, Luo, Liu, & Xiong, Citation2016).
Since the first lending platform Zopa was established in UK in February 2005, an increasing number of P2P lending platforms, such as Prosper, Smava, and Lending Club, have been developed all around the world (Ge, Feng, Gu, & Zhang, Citation2017) and accumulated data and management experiences. Comparing with traditional banking systems, P2P lending has some characteristics. First, P2P platforms facilitate transactions by connecting borrowers and lenders directly. Borrowers fill in electronic loan application forms, including amounts, terms, purposes, and personal information (such as age, job, address, and credit card). Platforms provide available financial situations and credit histories of borrowers to lenders, who will decide whether to grant a loan and an interest rate. Platforms use various approaches to help lenders set interest rates. Some platforms carry out an auction at which a borrower set her/his maximum interest rate and lenders give their bids (Galloway, Citation2009). Another approach is to assign interest rates automatically using borrowers’ credit grades, which are calculated based on borrowers’ characteristics (Collier & Hampshire, Citation2010). Generally, better credit grades are associated with lower interest rates. Second, P2P lending platforms charge service fees for transactions (Klafft, Citation2008), instead of charging borrowers higher interest rates than the cost of the money as traditional financial institutions. P2P lending process benefits both borrowers and lenders. While borrowers can borrow money at lower costs than traditional financial institutions, lenders can make more money than putting their money in banks. This benefit comes with the risk of borrowers’ defaulting on the loans because many P2P loans are unsecured personal loans and most lenders have little knowledge about credit risk management (Xia, Liu, & Liu, Citation2017).
To control default rates and risks, P2P lending platforms built classification models to evaluate credit risks of loans and borrowers and suggest appropriate interest rates for loan applications. The quality of credit classification models is vital to the credit risk management and sustainability of P2P lending platforms. Using experiences from financial institutions, P2P lending platforms adopt and develop classification algorithms to categorize borrowers into different credit grades based on their characteristics and credit history, and recognize potential borrowers who are likely to default (Lessmann, Baesens, Seow, & Thomas, Citation2015; Florez-Lopez & Ramon-Jeronimo, Citation2014; Marqués, García, & Sánchez, Citation2013).
Though it is a common practice in traditional credit rating to use standard cost-insensitive binary classification algorithms (Li, Kou, Peng, & Shi, Citation2017; Morente-Molinera, Mezei, Carlsson, & Herrera-Viedma, Citation2017), such as logistic regression, neural networks, and decision trees (Butaru et al., Citation2016; Luo, Wu, & Wu, Citation2017), they are not appropriate in P2P lending for the following reasons. First, there are more than two classes of credit grades in P2P lending and each credit grade implies a certain level of risk. Thus multi-class classification should be considered in P2P credit grading. Second, P2P loan data are imbalanced. The number of samples in different credit grades varies dramatically. For instance, the number of ideal borrowers in the best grade or high-risk borrowers in the worst grade is much smaller than the other grade groups. Third, misclassification costs are not uniform across classes in P2P lending. In general, the cost of classifying a loan with bad credit as a good one is usually greater than classifying a good one as bad (Chen, Ribeiro, & Chen, Citation2016). In a multi-class credit-grading scenario, classifying a sample of grade C into grade A is more costly than classifying B into A. Therefore, standard cost-insensitive multi-class classification, in which all errors have the same cost, is not suitable for credit rating in P2P lending.
Cost-sensitive multi-class classifiers fit well for credit rating in P2P lending. Cost-sensitive classifiers were developed for imbalanced data classification (Elkan, Citation2001; Hu et al., Citation2015; Sun, Shang, & Li, Citation2014). Various cost-sensitive classifiers have been proposed for credit rating (Bahnsen, Aouada, & Ottersten, Citation2015; Chao & Peng, Citation2018; Marqués et al., Citation2013; Sahin, Bulkan, & Duman, Citation2013). The goal of cost-sensitive classifier is to minimize total costs measured by a misclassification cost matrix (Guan, Yuan, Ma, Khattak, & Chow, Citation2017), which is not only necessary but also important for cost-sensitive classification problems.
Though there are a few works in P2P lending (Xia et al., Citation2017; Xu, Chen, & Chau, Citation2016) that studied cost-sensitive classifiers, none of them have analyzed this issue from the perspective of multi-class classifications and measured misclassification costs of different credit grades using real losses and opportunity costs associated with P2P lending. How to measure the misclassification costs of different credit grades is a useful but understudied problem. Serrano-Cinca and Gutiérrez-Nieto (Citation2016) showed that loan profitability outperformed loan default probability in P2P lending, which proved the importance of considering both interest rates and the probability of default in P2P credit scoring.
Misclassification costs are losses of lenders’ earnings due to misclassifying credit grades of loans. It equals to the difference between the return of a loan when it is correctly classified and the return of a loan when it is misclassified as other credit grade. The difference can be one of the following situations: Equation(1)(1)
(1) If a loan is classified to a better credit grade with a lower interest rate, the risk to default of the loan is underestimated and the interest rate of the loan is set lower than it should be, which means that the interest maybe insufficient to cover the risk that the lender bears. The lender will lose potential returns that they could have gotten, including an unpaid risk that the borrower should pay for the higher-risk loan. Equation(2)
(2)
(2) If a loan is classified to a worse credit grade with a higher interest rate, borrowers might be scared away or it may increase their chance to default, which causes opportunity costs and financial losses to lenders.
The objective of this paper is to propose a multi-class cost matrix that measures misclassification costs of P2P credit grading by considering real losses and opportunity costs associated with P2P lending. We developed a set of equations and models to calculate misclassification costs. The parameters in the proposed equations and models are designed to calculate the cost matrix and support P2P lending platforms’ operations. A case study using data from Lending Club is conducted to demonstrate the performances of the proposed cost matrix using several well-known cost-sensitive classifiers. The results show that the proposed cost matrix can not only reveal the sources of losses caused by misclassifications, but also reduce the total costs for real-world P2P platforms, which is better than cost-insensitive classification algorithms.
The rest of this paper is organized as follows. Section 2 reviews related works. Section 3 proposes an abstract structure of credit grades, and misclassification costs which measure real financial losses in P2P lending. Section 4 analyzes the range of parameters in the misclassification cost matrix and explains their managerial implications. Section 5 conducts an experiment using data from Lending Club. Section 6 concludes the paper with limitations and future research directions.
2. Related works
The goal of most classifiers is to maximize accuracy and minimize misclassifications. Various classification methods have been proposed for credit rating and risk management (Santana, Lanzarini, & Bariviera, Citation2018; Huang & Kou, Citation2014; Kou, Peng, & Wang, Citation2014; Lanzarini, Villa Monte, Bariviera, & Jimbo Santana, Citation2017; Peng, Wang, Kou, & Shi, Citation2011; Wu & Kou, Citation2016;). Standard classifiers treat the costs of misclassifications the same, which is not true in real credit risk management (Fiore, De Santis, Perla, Zanetti, & Palmieri, Citation2017; Tapkan, Özbakır, Kulluk, & Baykasoğlu, Citation2016). Many researches support the use of cost-sensitive classifiers in credit rating. Sahin et al. (Citation2013) proposed a cost-sensitive decision tree approach with varying misclassification costs. It is successfully used in credit card fraud detection to decrease financial losses. Alejo, García, Marqués, Sánchez, and Antonio-Velázquez (Citation2013) improved the Multilayer Perceptron neural network using three misclassification cost functions and can be used to improve the prediction effectively in credit rating. Bahnsen, Aouada, and Ottersten (Citation2014, Bahnsen et al., Citation2015) suggested example-dependent cost-sensitive methods and proposed logistic regression and decision trees for credit scoring.
Misclassification cost can be described by a cost matrix C = (cij)n×n, where cij indicates the cost due to misclassifying an instance of class i as class j, and n is the number of classes (Domingos, Citation1999). In credit rating, the measurement of misclassification costs in C is not only a basic component of cost-sensitive classification, but also vital for high quality credit rating. Real financial indicators, like profit-based or financial loss-related measures, are well aligned with the objectives in credit rating (Maldonado, Bravo, Lopez, & Perez, Citation2017; Serrano-Cinca & Gutiérrez-Nieto, Citation2016; Verbraken, Bravo, Weber, & Baesens, Citation2014). Beling, Covaliu, and Oliver (Citation2005) set the cost of a false negative to a loan’s interest rate charged to the customer intr, the cost of a false positive to the loss given default Lgd, and both the costs of true positive and true negative are set to zero. Following this notation, this paper regards default loans as negative instances and good loans as positive instances. shows the cost matrix (Beling et al., Citation2005).
Table 1. Cost matrix proposed by Beling et al. (Citation2005).
Hand, Whitrow, Adams, Juszczak, and Weston (Citation2008) proposed a cost matrix () for credit card fraud detection. It represents the costs of misclassification by the administrative cost Ca, which is related to analyzing the transactions and contacting card holders. In the cases of false negative and true negative, the associated costs both equal to Ca because the card holder will have to be contacted. However, in the case of false positive, due to the fact that frauds are not detected, the cost is defined as a hundred times Ca.
Table 2. Cost matrix proposed by Hand et al. (Citation2008).
Bahnsen, Stojanovic, Aouada, and Ottersten (Citation2013) pointed out a limitation of the above cost matrices. Since losses of different frauds range from a few to a large amount, it is unrealistic to assume constant cost in false positive. In Bahnsen et al. (Citation2013), a new cost matrix () is proposed as a better representation of the actual costs, where the cost of false positive is replaced by the amount Amti of the transaction i.
Table 3. Cost matrix proposed by Bahnsen et al. (Citation2013).
Bahnsen et al. (Citation2014) proposed a cost matrix () with example-dependent varying misclassification costs. For every borrower i, the costs of correct classifications are zero, and the cost of false positive is the losses if borrower i defaults which is proportional to his credit line Cli. The cost of false negative is ri plus Ca, where ri is the profit that can be earned from a good borrower, and Ca is related to uncertainty of next alternative borrower.
Table 4. Example-dependent cost matrix proposed by Bahnsen et al. (Citation2014).
Xia et al. (Citation2017) proposed a cost-sensitive boosted tree loan evaluation model to discriminate potential default borrowers in P2P lending. The model considers the imbalanced misclassification cost (shown in ), based on the assumption that the cost of misclassifying a default borrower is larger than that of misclassifying a good one, i.e. C(0, 1) > C(1, 0). It adopts a cost matrix with two classes (Good and Default).
Table 5. Cost matrix in Xia et al. (Citation2017).
Existing studies in cost-sensitive classification and cost matrices in credit rating focused on binary classification problems and traditional credit risk applications. Few, if there’s any, analyzed this issue from the perspective of multi-class classifications and in the context of P2P lending.
In cost-sensitive multi-class classification, the corresponding cost matrix C = (cij) is n-dimensional (Kou, Ergu, Lin, & Chen, Citation2016) where n is number of classes. For any the element cij indicates the misclassification cost that is caused by misclassifying an instance of class i as class j. The objective of this study is to determine the values of misclassification costs by incorporating profit losses and other indirect costs in P2P lending. A high-quality n-dimensional cost matrix can help to improve the performances of classifiers and reduce default losses in P2P lending.
3. Misclassification cost measures
This section analyzes the risks and profits in P2P lending, and proposes a multi-class misclassification cost matrix for P2P lending.
3.1. Modeling risks and profits in P2P lending
P2P lending platform provides services to lenders and borrowers to facilitate their transactions, and charges a proportion of profits earned by successful repaid loans as an essential part of services fee. One of the main services is to provide credit information of borrowers and suggestions (including credit rating and appropriate interest rates) to lenders. In fact, platforms and lenders share profits and risks.
For lenders, borrowers’ default would cause loses. In this paper, loss given default (Lgd) (Schuermann, Citation2004) is used to measure the proportion of a lender’s loss when a borrower defaults on a loan. Although Lgd is different for different loans, it is usually treated as a constant number for all loans to simplify models (Bahnsen et al., Citation2014; Beling et al., Citation2005). Lenders’ profits come from the interests of investments if borrowers fully repaid.
For platforms, default loans impact their profits directly by causing the loss of service fees and indirectly by damaging their reputations in quality of services on credit rating and setting interest rates. Thus, accurate credit rating is the foundation of healthy and profitable operations of P2P platforms. Consequently, an important requirement of credit rating in P2P lending is to measure the profitability of a loan (Xia et al., Citation2017), and the amount of loss in profit for lenders should be considered in misclassification cost matrix.
P2P platforms usually classify borrowers into multiple credit grades and determine hierarchical interest rates for them. We construct a structure of credit grades to measure the profits and losses in P2P lending (), based on the assumption that different credit grade i is associated with a certain probability of default (PD) PDi. Therefore it is assigned an interest rate Ii to reflect the corresponding credit risk. Credit rating classifies loans into these grades, where ‘1(A)’ refers to the best credit, and ‘n’ refers to the worst credit risk. Generally, the worse the credit grade, the higher probability of default and the higher interest rate. That is, for any
so that
and
Table 6. Structure of credit grades in P2P lending.
When a lender lends a loan of credit grade i (i = 1, 2, …, n) with PDi probability of default and Ii interest rate, the lenders’ expected return is:
(1)
(1)
where Lgd is the loss given default which indicates the average loss rate of money when a borrower defaulting on the loan.
3.2. Misclassification cost matrix
Based on , we propose a misclassification cost matrix C for credit rating in P2P lending (), where the cost of correct classification is zero, i.e. cii = 0, i = 1, 2, …, n.
Table 7. Misclassification cost matrix C for credit rating in P2P lending.
Misclassification cost matrix C can be decomposed into two blocks C1 and C2, that is C1is the lower triangular submatrix corresponding to the loans whose predicted credit grades (j) are better than their actual credit grades (i), i.e. i > j, and C2 is the upper triangular submatrix corresponding to the loans whose actual credit grades (i) are better than their predicted credit grades (j), i.e. i < j.
3.2.1. Lower triangular submatrix C1: Prediction (j) better than actual (i)
In the lower triangular matrix
is the cost of misclassifying a loan in grade i as grade j. As a result of misclassification,
and
which means a borrower pays a lower interest rate than he/she should. Lower interest rate may affect borrowers’ potential defaults to a certain extent, which has been supported by theoretical and empirical evidences (Edelberg, Citation2006; Serrano-Cinca, Gutierrez-Nieto, & López-Palacios, Citation2015). Specifically, the relationship between interest rate and risk of default is positive in P2P lending. To describe this kind of changes, we revise the PD in a linear function related with the difference of interest rates:
(2)
(2)
where β is a revised coefficient of PD, indicating how the PD of a borrower changes with different interest rates. Obviously,
is the actual probability of default, after misclassifying a loan in grade i to grade j. The misclassification leads to a change of expected return for the lender:
(3)
(3)
The misclassification also leads to a loss in return and the cost is formulated as:
(4)
(4)
3.2.2. Upper triangular submatrix C2: Actual (i) better than prediction (j)
In the upper triangular matrix
and
which means a borrower pays a higher interest rate than he/she should. This misclassification may lead to a withdrawal of loan application with a certain probability because the borrower can’t tolerate the high interest rate. This probability of application withdrawal is related to the difference of interest rates
To simplify the model, a linear function is used to calculate the probability that a borrower of credit grade i will give up application when misclassified as credit grade j (worse than grade i).
(5)
(5)
where α is borrowers’ churn rate (Zhu, Baesens, Backiel, & Vanden Broucke, Citation2018). It indicates how the probability
varies with the difference of interest rates
On the other hand, the probability of a borrower accepting interest rate Ij caused by misclassification is In this case, the PD of the borrower increases with the higher interest rate. EquationEquation (6)
(6)
(6) is used to calculate the actual PD
when i < j.
(6)
(6)
For a lender who accepts the misclassified loans when i < j, the expected return is:
(7)
(7)
Thus, the misclassification cost can be measured as:
(8)
(8)
It is rewritten as:
(9)
(9)
On the right hand side of EquationEquation (9)(9)
(9) , the first term indicates the loss in profit from transactions, and the second term
indicates the opportunity cost caused by application withdrawals due to misclassifications.
This model does not consider the idle investment due to borrowers’ termination and the uncertainty of next alternative borrower, which were discussed in Bahnsen et al. (Citation2014). If a borrower terminates the application, the transaction will not happen, and the money of a lender invested will be lent to an alternative borrower. Credit rating for the alternative borrower is also a classification problem using the proposed misclassification cost matrix.
In summary, based on a structure of credit grades in P2P lending, we designed a misclassification cost matrix to measure real business losses, which are calculated using EquationEquations (4)(4)
(4) and Equation(9)
(9)
(9) . In addition, we analyzed the parameters (Lgd, β, and α) from the perspective of both cost-sensitive classification and operations in P2P lending.
4. Parameters analysis
4.1. Loss given default: Lgd
We adopt a quadratic programming to deduce loss given default (Lgd) backward from observed PDs, interest rates, and actual return rates:
(10)
(10)
where ERi indicates the expected returns of lenders who lend to borrowers in credit grade i.
is the actual return rate of investing loans to borrowers in credit grades i, which considers potential losses due to defaults and is calculated by P2P platforms. The Lgd value is calculated by minimizing the sum of squared differences between expected returns ERi and actual returns
on different grades. This fits the realistic environment and reflects the average percentage of losses due to defaults.
4.2. PD’s revised coefficient: β
β is PD’s revised coefficient in EquationEquation (2)(2)
(2) . It indicates how the PD of a borrower changes with different interest rates she/he bears. There are two reasonable assumptions about the revised PD in practice. First, the higher the interest rate is, the higher the probability that a borrower defaults. Second, a lower interest rate will not completely convert PDs of lower-credit-grades borrowers into those with better-credit-grades. In other words, when i > j, even if a borrower of credit grade i lowers her/his PD from PDi to
is still larger than PDj due to the lower interest rate Ij. That is,
According to EquationEquation (2)
(2)
(2) , it is equivalent to:
because
(11)
(11)
In the view of cost matrix, for any i, j = 1, 2, …, n, if i > j, then According to EquationEquation (4)
(4)
(4) , we get:
(12)
(12)
Moreover, for any i, j, k = 1, 2, …, n, if i > j > k, the cost due to misclassifying a loan of credit grade i into k should be larger than misclassifying it as j. That is, so
If
that is,
is less than a positive number, which have been covered by
in formula Equation(12)
(12)
(12) .
If
(13)
(13)
Similarly, because
(14)
(14)
4.3. Borrowers’ churn rate: α
When a loan of credit grade i is misclassified into grade j (), a borrower will give up his loan application with a probability
α is borrowers’ churn rate which indicates how the probability
varies with the difference of interest rates
Naturally,
so that:
(15)
(15)
We analyze the parameter α in the view of cost matrix. Then α holds:
(16)
(16)
(17)
(17)
(18)
(18)
Specifically, the cost of misclassifying a bad loan into a better one is larger than the other way around. That is,
(19)
(19)
where
indicates the misclassification costs of misclassifying a loan (of grade j) to a better credit grade i, and
indicates the misclassification costs of misclassifying a loan (of grade i) to a worse credit grade j.
5. Experiment: A case study on lending club
5.1. Data collection
To validate the proposed measure of misclassification costs in a real P2P platform, the empirical study utilizes data collected from Lending Club (Lending Club, Citation2017), which is the largest P2P lending platform in U.S and the data is publicly available.
We collected the data of loans on Lending Club from the first quarter of 2016 to the third quarter of 2017. The total number of loans in this data set is 759348 (as shown in ). There are 128 features for each loan in the original data, including loan characteristics (such as loan amount, term, and purpose), borrowers’ financial situation (such as annual income and home ownership), and credit history (such as FICO score, the number of inquiries, the number of open credit lines, and incidences of delinquency). In particular, a variable named LC grade, which is the credit grade for loans assigned by Lending Club, is used as the class label for training and testing classification algorithms in the experiment.
Table 8. Number of instances in lending club data.
The Lending Club data has been used in existing P2P lending researches (Serrano-Cinca & Gutiérrez-Nieto, Citation2016; Xia et al., Citation2017). Serrano-Cinca and Gutiérrez-Nieto (Citation2016) provided some statistics of the data, such as the proportions of loans in different credit grades, the proportions of default, and the mean of interest rates for each grade. summarizes the structure of credit grades of the Lending Club data, where the probability of default is estimated using the proportion of default loans to all loans in the grade.
Table 9. Structure of credit grades on lending club data.
supports our assumptions of the proposed models. First, there are seven credit grades (A–G) implemented on Lending Club, where A is best and G is worst. It confirms the use of multi-class classification in P2P lending. Second, the proportions of loans vary from 33.60% to 0.15%, which means that the data are highly imbalanced. Third, worse credit grades are associated with higher PDs and interest rates, which is a basic assumption of our model to measure misclassification costs using real losses in P2P lending.
5.2. Setting parameters and managerial implications
The interest rates in P2P lending are set based on the business environment, which can be measured using parameters, such as Lgd, β, and α. In the experiment, we set the values of parameters using the observed PDs and interest rates in . The parameters not only reflect the operating environment of Lending Club, but also provide guidelines for interest rates adjustments.
Furthermore, Lending Club provides actual average annualized returns for lenders, shown in . According to formula Equation(10)(10)
(10) , the parameter Lgd is approximately 0.5 (0.50543), which means that about 50% of principal in investment will be lost if default happens.
Table 10. Actual annualized returns provided by lending clubTable Footnote*.
To satisfy inequalities in Equation(11)–(14), the range of parameter β is solved as −0.1116 < β < 0. To calculate the proposed model, we set β as the median of the range, that is β = −0.0558. Thus, the revised PD on Lending Club, shown in , can be estimated using EquationEquation (2)(2)
(2) . Bold numbers in indicate the inherent PDs for loans of credit grades. In fact, fluctuations of interest rates caused by misclassification can affect borrowers' default. The experiment proved that inherent credit ratings have more effects on the probability of default than the fluctuations of interest rates. This makes sense in P2P lending, where loans are normally small in size and repayment of unsecured microloans is more dependent on the willingness to pay than the ability to pay.
Table 11. Revised PD on lending club.
To satisfy inequalities in Equation(15)–(19), the range of parameter α is −1.2916 < α < −0.8412. We set α as the median of the range, this is α = −1.0664. It indicates that a borrower's probability of terminating a loan application increases about 1.1% if the interest rate rises by 1%.
In the experiment, we calculate the parameters by analysis of models based on observed structure including probability of default and interest rates. In fact, the parameters are determined by behaviors of borrowers, which can be measured through investigation. It provides a guidance to check and adjust interest rates. If there’s a big difference between the values of parameters calculated and the results obtained from the real practice, the interest rates on P2P lending platforms should be adjusted, because PDs are given and generally stable.
5.3. Cost matrix
According to EquationEquations (4)(4)
(4) and Equation(9)
(9)
(9) , we calculate the misclassification cost matrix C (), which is the main contribution of this paper. Elements in the cost matrix measure the loss of lenders’ expected return if a loan is misclassified. For example, in the cost matrix C, c21 = 0.0333 means that a lender who provides a loan with a certain amount amt will loss 0.0333*amt in her/his expected return when a loan of credit grade B is misclassified as grade A. Meanwhile, the revenue of the platform reduces because of the misclassification of credit grades, where the costs should be minimized in cost-sensitive credit rating.
Table 12. Misclassification cost matrix on lending club.
The largest cost in is 0.0856, which happens when class G was misclassified as class A. It is align with the reality because this misclassification assigns the lowest interest rate to the highest credit risk group. And the smallest cost is 0.0055, which appears when class E is misclassified into F.
5.4. Sensitivity analysis
The parameters α and β were set as the median value of the corresponding ranges in the experiments. In reality, there is uncertainty on the parameters due to borrowers’ behaviors. This section uses sensitivity analysis to study how the uncertainty of input parameters affects the cost matrix in the output.
To facilitate observations of the cost matrixes under different parameters, cosine similarity is adopted to compare them with the cost matrix C = (cij) shown in , where parameters are taken as median (α0, β0). Given any −1.2916 < α1 < −0.8412 and −0.1116 < β1 < 0, the corresponding cost matrix D = (dij) can be obtained. Then the cosine similarity between C and D is calculated as follows:
(20)
(20)
In other words, the cost matrix C in is considered as benchmark in calculation of cosine similarity. shows the similarity result when the parameters vary in their ranges. Obviously, the similarity is equal to 1 when α and β are median, because it is benchmark. To observe more details of the result, we take the parameters α and β respectively at 9 equidistant points within their ranges. lists the cosine similarities on these discrete values of parameters. The element at the center of indicates the situation of benchmark (). The lowest similarity appears at the corner of the range. When both α and β are taken as the maximum in their ranges, the fact that similarity equals 0.9451 still guaranteed a small difference between the corresponding cost matrix and benchmark.
Figure 1. Sensitivity analysis for cosine similarity of cost matrixes in terms of parameters uncertainty.
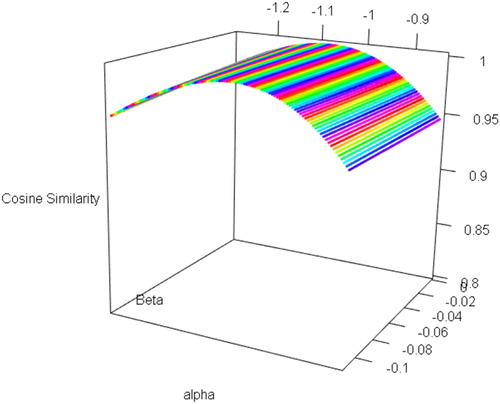
Table 13. Cosine similarities of cost matrixes when the parameters are discrete values.
The sensitivity analysis for the parameters shows that the proposed method used to calculate cost matrix is robust in the presence of uncertainty of parameters. Thus, it is reasonable to set the parameters as the median value of the ranges.
5.5. Cost-sensitive credit rating
After calculated the misclassification cost matrix, we can use cost-sensitive credit rating to classify the loans into credit grades (A, B, C, D, E, F, or G), using the collected Lending Club data.
Data preprocessing was performed first. We deleted some null features and irrelevant features (such as title and other date-type features). The number of features reduced from 128 to 74. We randomly sample 10% instances from 759348 loans to train and test classifiers.
In this experiment, we selected four well-known classifiers (Lessmann et al., Citation2015) and the corresponding Meta-cost-sensitive classifiers to compare their performances. The four classifiers are C4.5, Random Forest, Logistic Regression, and SVM. Then we adopted a Meta approach proposed by Domingos (Citation1999) to make the four classifiers cost-sensitive by wrapping a cost-minimizing procedure around it. The proposed cost matrix is used to guide credit rating in cost-sensitive classification.
For experimental setup, the cost-insensitive and cost-sensitive classifiers were evaluated by 10-folds cross validation using Weka software (Frank, Hall, & Witten, Citation2016). The performances of classifiers were evaluated using accuracy, total cost, average cost, and cost saving rate. They were computed using the confusion matrix N () in classification result and the cost matrix proposed in Section 3.
Table 14. Confusion matrix NTable Footnote*.
Accuracy is the percentage of correctly classified loans (Kou, Lu, Peng, & Shi, Citation2012) and computed as Total cost is the sum of the costs of misclassified instances, and
Average cost is cost per instance, that is,
Cost saving rate is the rate of decreased cost after using cost-sensitive classifiers.
The classification results were summarized in . Since traditional standard classifiers focus on optimizing the accuracy and ignoring the relationship between classes and different misclassifications, they have higher accuracies than their cost-sensitive counterparts, and the cost-sensitive classifiers reduced the total costs dramatically, which is a major concern of P2P lending platforms and lenders.
Table 15. Classification results using proposed cost matrix.
It is really difficult, if not impossible, to achieve the highest accuracy and the lowest total cost simultaneously. Cost-sensitive classification normally sacrifices accuracy for lower total cost (Wang, Kou, & Peng, Citation2018). The objective of cost-insensitive classifiers is to maximize the total accuracy. But none of them can reach 100% accuracy in multi-class classification. Although misclassified instances may cause different costs according to the cost matrix, cost-insensitive classifiers treat them the same. This is the reason that cost-insensitive classifiers have higher accuracy and higher total misclassification cost. Cost-sensitive classifiers, on the other hand, try to minimize total costs caused by misclassification, and some misclassification errors with low costs are compromised to achieve this goal when training the classifiers. Thus, cost-sensitive classifiers reduce total cost of classification, but have lower accuracy than cost-insensitive classifiers. As shown in , the classifiers which achieved the highest accuracy and the lowest total cost are C4.5 and cost-sensitive C4.5, respectively. While the accuracy of cost-sensitive C4.5 is 1.33% lower than C4.5, cost-sensitive C4.5 reduced 13.12% total cost, compared to C4.5.
Since the proposed cost matrix measured the real losses of lenders, the total cost is more practical than the accuracy. Compared with the corresponding standard classifiers, the four cost-sensitive classifiers reduced 13%, 25%, 21%, and 12% total costs, respectively (shown as the column “Cost saving rate” in ). In order to connect the classification results and business reality in P2P lending, the average cost indicates how much money is lost in a loan, on average, due to potential misclassification of credit grades when a classification algorithm is used. For example, if standard C4.5 is used to grade a loan, potential misclassification cost will cause 0.43% less returns for lenders, comparing to 100% accurate classification. And this cost dropped to 0.38% if cost-sensitive C4.5 is used.
In summary, using cost-sensitive classifiers for credit rating is able to reduce losses effectively in P2P lending, which is measured by the cost matrix proposed in this paper. It also shows the need to evaluate and develop more credit rating approaches with respect to minimizing financial losses for P2P lending platforms.
6. Conclusion and discussion
Online peer-to-peer (P2P) lending platforms provide convenient and low costs lending option to individuals and small businesses. Since many P2P loans are unsecured personal loans, the quality of credit risk classification is vital to P2P lending platforms. Traditional cost-insensitive binary classification is not appropriate in P2P lending because there are more than two credit classes in real-life P2P lending and misclassification costs are not uniform across classes. Cost-sensitive classifiers try to minimize total costs measured by misclassification cost matrixes. How to measure misclassification costs of different credit grades in P2P lending is a useful but understudied issue.
The objective of this paper is to model credit rating in P2P lending as a cost-sensitive multi-class classification problem. We first proposed a misclassification cost matrix for P2P credit grading that takes into account real losses and opportunity costs associated with P2P lending. A set of equations and models were developed to calculate the costs in the misclassification cost matrix. Then we analyzed the parameters in the proposed equations and models from the perspective of both cost-sensitive classification and business operations.
To validate the proposed misclassification cost matrix, an experiment using publicly available data from Lending Club was conducted. The results showed that standard classifiers have higher accuracy than cost-sensitive counterparts, but the cost-sensitive classifiers significantly reduced the total costs, which is essential for the survival and profitability of P2P lending platforms.
One of the limitations of this work is that it did not take administrative cost into consideration. The administrative cost is an important part of the total cost in traditional bank loans. We did not include the administrative costs in the total cost calculation because Lending Club does not provide such information. Since the administrative cost in P2P lending, comparing with traditional bank loans, is insignificant, the reduced total cost calculated in the experiment can still be used as a useful reference for P2P lending platforms.
This paper defined two variables, revised PD and a borrower’s probability of give-up, as linear function related with different interest rates. The actual situations may be more complex than these assumptions. One of the future research directions is to investigate how changes in interest rates affect human behaviors on default and giving up a loan. Though this paper focuses on misclassification costs in credit rating, the basic idea of the proposal is not necessarily restricted to the financial domain and can be applied to a wide selection of areas. For instance, misclassification costs of type I and type II errors are quite different in medical diagnosis. The difficulty lies in the definition of misclassification cost matrix for medical diagnosis. Another future research direction is to generalize the misclassification cost matrix for other multi-class cost-sensitive classification problems.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Alejo, R., García, V., Marqués, A. I., Sánchez, J. S., & Antonio-Velázquez, J. A. (2013). Making accurate credit risk predictions with cost-sensitive mlp neural networks. In Management intelligent systems (pp. 1–8). Heidelberg: Springer.
- Bachmann, A., Becker, A., Buerckner, D., Hilker, M. K. M., Lehmann, M., & Tiburtius, P. (2011). Online peer-to-peer lending-a literature review. Journal of Internet Banking and Commerce, 16(2), 1–18.
- Bahnsen, A. C., Aouada, D., & Ottersten, B. (2014). Example-dependent cost-sensitive logistic regression for credit scoring. In 2014 13th International Conference on Machine Learning and Applications (ICMLA) (pp. 263–269). IEEE.
- Bahnsen, A. C., Aouada, D., & Ottersten, B. (2015). Example-dependent cost-sensitive decision trees. Expert Systems with Applications, 42(19), 6609–6619. doi:10.1016/j.eswa.2015.04.042
- Bahnsen, A. C., Stojanovic, A., Aouada, D., & Ottersten, B. (2013). Cost sensitive credit card fraud detection using Bayes minimum risk. In 2013 12th International Conference on Machine Learning and Applications (ICMLA) (Vol. 1, pp. 333–338). IEEE.
- Beling, P., Covaliu, Z., & Oliver, R. M. (2005). Optimal scoring cutoff policies and efficient frontiers. Journal of the Operational Research Society, 56(9), 1016–1029. doi:10.1057/palgrave.jors.2602021
- Butaru, F., Chen, Q., Clark, B., Das, S., Lo, A. W., & Siddique, A. (2016). Risk and risk management in the credit card industry. Journal of Banking & Finance, 72, 218–239. doi:10.1016/j.jbankfin.2016.07.015
- Chao, X., & Peng, Y. (2018). A cost-sensitive multi-criteria quadratic programming model for imbalanced data. Journal of the Operational Research Society, 69(4), 500–516. doi:10.1057/s41274-017-0233-4
- Chen, N., Ribeiro, B., & Chen, A. (2016). Financial credit risk assessment: A recent review. Artificial Intelligence Review, 45(1), 1–23. doi:10.1007/s10462-015-9434-x
- Collier, B., & Hampshire, R. (2010). Sending mixed signals: Multilevel reputation effects in peer-to-peer lending markets. In Proceedings of the 2010 ACM Conference on Computer Supported Cooperative Work (pp. 197–206). ACM. doi:10.1145/1718918.1718955
- Domingos, P. (1999). Metacost: A general method for making classifiers cost-sensitiv. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 155–164). ACM. doi:10.1145/312129.312220
- Edelberg, W. (2006). Risk-based pricing of interest rates for consumer loans. Journal of Monetary Economics, 53(8), 2283–2298. doi:10.1016/j.jmoneco.2005.09.001
- Frank, E., Hall, M. A., & Witten, I. H. (2016). The WEKA workbench. Online appendix for “Data mining: Practical machine learning tools and techniques” (4th ed.). Burlington, MA: Morgan Kaufmann.
- Elkan, C. (2001). The foundations of cost-sensitive learning. In International joint conference on artificial intelligence. (Vol. 17, No. 1, pp. 973–978). Hillsdale, NJ: Lawrence Erlbaum Associates Ltd.
- Fiore, U., De Santis, A., Perla, F., Zanetti, P., & Palmieri, F. (2017). Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Information Sciences, 479, 448–455. doi:10.1016/j.ins.2017.12.030
- Florez-Lopez, R., & Ramon-Jeronimo, J. M. (2014). Modelling credit risk with scarce default data: On the suitability of cooperative bootstrapped strategies for small low-default portfolios. Journal of the Operational Research Society, 65(3), 416–434. doi:10.1057/jors.2013.119
- Galloway, I. (2009). Peer-to-peer lending and community development finance. Community Investments, 21(3), 19–23.
- Ge, R., Feng, J., Gu, B., & Zhang, P. (2017). Predicting and deterring default with social media information in peer-to-peer lending. Journal of Management Information Systems, 34(2), 401–424. doi:10.1080/07421222.2017.1334472
- Guan, D., Yuan, W., Ma, T., Khattak, A. M., & Chow, F. (2017). Cost-sensitive elimination of mislabeled training data. Information Sciences, 402, 170–181. doi:10.1016/j.ins.2017.03.034
- Guo, Y., Zhou, W., Luo, C., Liu, C., & Xiong, H. (2016). Instance-based credit risk assessment for investment decisions in P2P lending. European Journal of Operational Research, 249(2), 417–426. doi:10.1016/j.ejor.2015.05.050
- Hand, D. J., Whitrow, C., Adams, N. M., Juszczak, P., & Weston, D. (2008). Performance criteria for plastic card fraud detection tools. Journal of the Operational Research Society, 59(7), 956–962. doi:10.1057/palgrave.jors.2602418
- Hu, Y., Feng, B., Mo, X., Zhang, X., Ngai, E. W. T., Fan, M., & Liu, M. (2015). Cost-sensitive and ensemble-based prediction model for outsourced software project risk prediction. Decision Support Systems, 72, 11–23. doi:10.1016/j.dss.2015.02.003
- Huang, Y., & Kou, G. (2014). A kernel entropy manifold learning approach for financial data analysis. Decision Support Systems, 64, 31–42. doi:10.1016/j.dss.2014.04.004
- Klafft, M. (2008). Peer to peer lending: Auctioning microcredits over the internet. In Proceedings of the International Conference on Information Systems, Technology and Management. Dubai: IMT.
- Kou, G., Ergu, D., Lin, C., & Chen, Y. (2016). Pairwise comparison matrix in multiple criteria decision making. Technological and Economic Development of Economy, 22(5), 738–765. doi:10.3846/20294913.2016.1210694
- Kou, G., Lu, Y., Peng, Y., & Shi, Y. (2012). Evaluation of classification algorithms using MCDM and rank correlation. International Journal of Information Technology & Decision Making, 11(01), 197–225. doi:10.1142/S0219622012500095
- Kou, G., Peng, Y., & Wang, G. (2014). Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Information Sciences, 275, 1–12. doi:10.1016/j.ins.2014.02.137
- Lanzarini, L. C., Villa Monte, A., Bariviera, A. F., & Jimbo Santana, P. (2017). Simplifying credit scoring rules using LVQ + PSO. Kybernetes, 46(1), 8–16. doi:10.1108/K-06-2016-0158
- Lending Club. (2017). Data from: Lending club statistics [Dataset]. Retrieved from https://www.lendingclub.com/info/download-data.action.
- Lessmann, S., Baesens, B., Seow, H. V., & Thomas, L. C. (2015). Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research, 247(1), 124–136. doi:10.1016/j.ejor.2015.05.030
- Li, T., Kou, G., Peng, Y., & Shi, Y. (2017). Classifying with adaptive hyper-spheres: An incremental classifier based on competitive learning. In IEEE Transactions on Systems, Man, and Cybernetics: Systems (pp. 1–12). IEEE.
- Luo, C., Wu, D., & Wu, D. (2017). A deep learning approach for credit scoring using credit default swaps. Engineering Applications of Artificial Intelligence, 65, 465–470. doi:10.1016/j.engappai.2016.12.002
- Maldonado, S., Bravo, C., Lopez, J., & Perez, J. (2017). Integrated framework for profit-based feature selection and SVM classification in credit scoring. Decision Support Systems, 104, 113–121. doi:10.1016/j.dss.2017.10.007
- Marqués, A. I., García, V., & Sánchez, J. S. (2013). On the suitability of resampling techniques for the class imbalance problem in credit scoring. Journal of the Operational Research Society, 64(7), 1060–1070. doi:10.1057/jors.2012.120
- Morente-Molinera, J. A., Mezei, J., Carlsson, C., & Herrera-Viedma, E. (2017). Improving supervised learning classification methods using multi-granular linguistic modelling and fuzzy entropy. IEEE Transactions on Fuzzy Systems, 25(5), 1078–1089.
- Peng, Y., Wang, G., Kou, G., & Shi, Y. (2011). An empirical study of classification algorithm evaluation for financial risk prediction. Applied Soft Computing, 11(2), 2906–2915. doi:10.1016/j.asoc.2010.11.028
- Sahin, Y., Bulkan, S., & Duman, E. (2013). A cost-sensitive decision tree approach for fraud detection. Expert Systems with Applications, 40(15), 5916–5923. doi:10.1016/j.eswa.2013.05.021
- Santana, P. J., Lanzarini, L., & Bariviera, A. F. (2018). Fuzzy Credit Risk Scoring Rules using FRvarPSO. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 26(Suppl. 1), 39–57. doi:10.1142/S0218488518400032
- Schuermann, T. (2004). What do we know about loss given default?
- Serrano-Cinca, C., & Gutiérrez-Nieto, B. (2016). The use of profit scoring as an alternative to credit scoring systems in peer-to-peer (P2P) lending. Decision Support Systems, 89, 113–122. doi:10.1016/j.dss.2016.06.014
- Serrano-Cinca, C., Gutierrez-Nieto, B., & López-Palacios, L. (2015). Determinants of default in P2P lending. PloS One, 10(10), e0139427doi:10.1371/journal.pone.0139427
- Sun, J., Shang, Z., & Li, H. (2014). Imbalance-oriented SVM methods for financial distress prediction: A comparative study among the new SB-SVM-ensemble method and traditional methods. Journal of the Operational Research Society, 65(12), 1905–1919. doi:10.1057/jors.2013.117
- Tapkan, P., Özbakır, L., Kulluk, S., & Baykasoğlu, A. (2016). A cost-sensitive classification algorithm: BEE-Miner. Knowledge-Based Systems, 95, 99–113. doi:10.1016/j.knosys.2015.12.010
- Verbraken, T., Bravo, C., Weber, R., & Baesens, B. (2014). Development and application of consumer credit scoring models using profit-based classification measures. European Journal of Operational Research, 238(2), 505–513. doi:10.1016/j.ejor.2014.04.001
- Wang, H., Kou, G., & Peng, Y. (2018). Cost-sensitive classifiers in credit rating: A comparative study on P2P lending. In 2018 7th International Conference on Computers Communications and Control (ICCCC) (pp. 210–213). IEEE. doi:10.1109/ICCCC.2018.8390460
- Wu, W., & Kou, G. (2016). A group consensus model for evaluating real estate investment alternatives. Financial Innovation, 2(1), 8. doi:10.1186/s40854-016-0027-8
- Xia, Y., Liu, C., & Liu, N. (2017). Cost-sensitive boosted tree for loan evaluation in peer-to-peer lending. Electronic Commerce Research and Applications, 24, 30–49. doi:10.1016/j.elerap.2017.06.004
- Xu, J., Chen, D., & Chau, M. (2016). Identifying features for detecting fraudulent loan requests on P2P platforms. In 2016 IEEE Conference on Intelligence and Security Informatics (ISI) (pp. 79–84). IEEE.
- Zhu, B., Baesens, B., Backiel, A., & Vanden Broucke, S. K. (2018). Benchmarking sampling techniques for imbalance learning in churn prediction. Journal of the Operational Research Society, 69(1), 49–65. doi:10.1057/s41274-016-0176-1