
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Digitalizing cement production plants to improve operation parameters’ control might reduce energy consumption and increase process sustainabilities. Cement production plants are one of the extremest CO2 emissions, and the rotary kiln is a cement plant’s most energy-consuming and energy-wasting unit. Thus, enhancing its operation assessments adsorb attention. Since many factors would affect the clinker production quality and rotary kiln efficiency, controlling those variables is beyond operator capabilities. Constructing a conscious-lab “CL” (developing an explainable artificial intelligence “EAI” model based on the industrial operating dataset) can potentially tackle those critical issues, reduce laboratory costs, save time, improve process maintenance and help for better training operators. As a novel approach, this investigation examined extreme gradient boosting (XGBoost) coupled with SHAP (SHapley Additive exPlanations) “SHAP-XGBoost” for the modeling and prediction of the rotary kiln factors (feed rate and induced draft fan current) based on over 3,000 records collected from the Ilam cement plant. SHAP illustrated the relationships between each record and variables with the rotary kiln factors, demonstrated their correlation magnitude, and ranked them based on their importance. XGBoost accurately (R-square 0.96) could predict the rotary kiln factors where results showed higher exactness than typical EAI models.
1. Introduction
Although the cement industry globally is one of the most important parts of the economic sector, cement production is an extremely CO2 emission process. Several investigations have been conducted to reduce cement production issues (Chipakwe et al. Citation2020). They were focused mainly on cement chemistry, and few studies have been conducted on process control and equipment assessments (Söğüt Citation2012; Sui et al. Citation2014; Gaurav and Khanam Citation2016; Coskun Citation2019). Therefore, many rooms are left open for exploring and understanding relationships between various cement product factors, where cement plants are also one of the most energy-intensive industries. In modern cement manufacture as a dry method process, a rotary kiln is one of the primary units (S. Wang, Dong, and Yuan Citation2007). As a central unit, the rotary kiln is the most energy-consuming and energy-wasting unit throughout cement production. Thus, the rotary kiln is the most expensive part of a cement plant, which significantly consumes fuel and directly affects the final product price (Bui, Tarasiewicz, and Charette Citation1982; Radwan Citation2012). All these aspects have highlighted the importance of understanding interactions among rotary kiln variables essentially on the industrial scale.
In cement production, the rotary kiln is a rotating furnace tube for baking and turning the raw material into cement clinker (Sharabiany, Fatehi, and Araabi Citation2011). This long cylinder (based on the plant capacity, the length could be 70 m with around 5 m diameter) can produce over 2,000 tons of clinker per day. It uses a powerful electrical motor, and its temperature can be up to 1,400 °C (Makaremi et al. Citation2009). The cylinder, based on specific slop, turns around its axis, and the raw materials stick adhesively to its walls, gradually mixed, burned, and baked to produce clinker. Controlling the feed rate would have an essential role in smooth kiln performance. If the flow of feed into the kiln is suddenly interrupted, the heat normally absorbed by the slurry concentrates in the chains, causing serious damage if not quickly corrected. Small, controlled increases or decreases in the feed rate may cause a significant variation in the kiln temperature profile (Delong and Aitken Citation1981). These variations can be managed by understanding correlations among kiln variables. A powerful fan, called induced draft or “ID fan,” is installed at the end of the pre-heater in a kiln rotary. It develops necessary suction through the kiln and controls the gas flow in the kiln (Sharabiany, Fatehi, and Araabi Citation2011). The ID fan sucks the kiln air out of it, and consequently, new air is blown into the kiln. Rotational kiln speed can be adjusted by feed rate (Fallahpour et al. Citation2007). ID fans (typically assessed with its current (A)) induce the total flow inside the kiln. Thus, they may also be called dirty fans since they handle the gases generated by combustion, dust that cannot be taken into the bag filter, excess air, and any infiltration air that arises to the fan inlet (Boateng Citation2015). In other words, numerous factors could affect the ID fan performance and kiln feed rate, exhibiting complex nonlinear interactions among them (Akalp, Dominguez, and Longchamp Citation1994; Fallahpour et al. Citation2007; Boateng Citation2008). However, it was reported that controlling these two critical variables is beyond the operator’s capabilities (Delong and Aitken Citation1981).
For cement plants, modeling such complicated inter-correlations among rotary kiln operating variables could significantly improve the level of process understanding and control. However, few published investigations examined relationships among cement equipment variables (none around rotary kiln operational parameters) (Delong and Aitken Citation1981; L.-X. Wang Citation1994). Using the conscious lab (CL) concept as a novel methodology would potentially tackle this challenge. CL as a new concept means using industrial monitoring datasets for developing explainable artificial intelligence (EAI) models to understand and predict interactions among full-scale operating variables (Chelgani, Nasiri, and Alidokht Citation2021; Chelgani, Nasiri, and Tohry Citation2021; Alidokht et al. Citation2021; Tohry et al. Citation2021). EAI methods are not black-box systems (Jorjani, Mesroghli, and Chelgani Citation2008) and can highlight the interaction among each record of variables with their representative responses within the dataset, evaluate their individual record and variable importance, rank them based on their effectiveness, and illustrate their relationship magnitudes. In other words, EAI models would translate the dataset to a human-basis understanding level, exponentially improving the unit’s reasoning and planning. This strategic methodology can generate a systematic approach toward digitalizing the whole plant. It would be markedly decreased laboratory costs, prohibiting the scale-up complexes, saving time, and converting decisions based on the process’s real operational properties (not according to some ideal solid aspects).
This study, for the first time, as a novel perception, is going to use extreme gradient boosting (XGBoost), which is coupled with SHAP (SHapley Additive exPlanations) “SHAP-XGBoost” as an EAI system for modeling of “ID fan current” and rotary kiln “feed rate” by using an industrial dataset (monitored operating variables). This investigation will launch a CL for accessing critical variables of a rotary kiln in a short sentence. XGBoost, as a newly constructed machine learning model, would be able to handle missing data, regularize the prediction by parallel processing, prune a non-greedy tree, and set an objective function (Gómez-Ríos, Luengo, and Herrera Citation2017; X. Zhang et al. Citation2020; K. Zhou, Li, et al. Citation2021). SHAP would translate the relationships by simultaneously assessing multivariable inter-correlations linearly and non-linearly and increasing the XGBoost process transparency (Chelgani Citation2021; Mangalathu et al. Citation2021; Bussmann et al. Citation2021). For comparison and verification purposes, Pearson correlation, random forest, and support vector regression, as common machine learning tools, were also considered for the modeling and accuracy assessments. These EAI modeling approaches could be key for better controlling the cement plants, improving their process efficiencies, and reducing environmental issues.
2. Materials and methods
2.1. Dataset
For exploring the relationships between kiln feed rate, and ID fan speed, and other operating variables, a dataset was collected from one of the pre-heater and rotary kiln (Clinker Baking unit) circuits (line 1) in the Ilam cement plant (). The Ilam plant has two lines for cement production (5,300 t/d). The clinker baking circuit includes a pre-heater unit, five air cyclones, and one calcinator) up to 900 °C for calcination (and rotary kiln (62 m length,4.2 m diameter) with 2,000 t/d capacity (made by O&K Company from Germany). The maximum kiln’s rotation speed is 3 rpm. The plant has approximately a fixed one-year period for the overhaul. The pre-heater and rotary kiln key operating parameters are summarized in . Variables were monitored hourly and were taken into account. In general, over 3,000 records from 2020 to 2021 were prepared and used for the modeling. In the plant, before the introduction in the rotary kiln, the raw meal is pre-heated through a suspension pre-heater. The pre-heated material is up in the air with the combustion exhaust gas from the kiln. In the suspension pre-heater, composed of five cyclones stages, the heat transfer rate increases, which enhances the heat exchange efficiency combustion from the kiln, which flows through the cyclones from the bottom upwards. Raw meal, finely milled, is mixed with the exhaust gas upstream. A rotary kiln is a steel cylinder that rotates around its axis. The kiln is horizontally sloped at about 2.5–4.5%, letting the processed mixture move along with it. The kiln fuel is introduced through a burner placed at the end of the kiln. After its entry into the furnace, Raw meal is subjected to calcination, solid-phase reactions, and clinkering.
Figure 1. Clinker Baking circuits (line 1) of the Ilam cement plant.
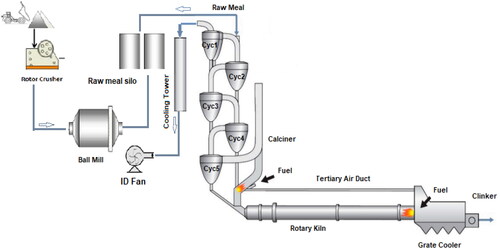
Table 1. The statistical description of operating variables for the pre-heater and rotary kiln of Ilam cement plant.
2.2. Shapley Additive exPlanations (SHAP)
The Shapley Additive exPlanations (SHAP) developed by Lundberg and Lee (Lundberg and Lee Citation2017) in 2017 originates from the game theory (Feng et al. Citation2021). SHAP employs Shapley values to explain the model’s output. Shapley value was first introduced by Lloyd Shapley, who received the Nobel Prize in Economics for that in 2012 (Ungari and Benhamou Citation2021). Shapley value is the average marginal feature contribution, i.e., it measures how much each feature’s importance is in the model (Chelgani, Nasiri, and Alidokht Citation2021; Chelgani, Nasiri, and Tohry Citation2021; Mangalathu et al. Citation2021). More formally, Shapley value for the prediction model
is calculated as follows:
(1)
(1)
where
denotes the set of all variables,
is a subset of
is the trained model, and
determines the
th input variable’s contribution to the model (Chelgani Citation2021; Mangalathu et al. Citation2021; Bussmann et al. Citation2021).
2.3. Extreme Gradient Boosting (XGBoost)
XGBoost stands for “Extreme Gradient Boosting,” a distributed, decision tree-based ensemble approach developed in 2016 (Chen and Guestrin Citation2016). XGBoost uses a gradient boosting framework designed to be extremely efficient, adaptable, scalable, and portable (Ogunleye and Wang Citation2020; Ezzoddin, Nasiri, and Dorrigiv Citation2022; Hasani and Nasiri Citation2022; Leng et al. Citation2022; Nasiri and Hasani Citation2022). It employs various regularization methods, including L1 regularization (i.e., Lasso) and L2 regularization (i.e., Ridge), to smooth the learned weights and avoid overfitting (Gómez-Ríos, Luengo, and Herrera Citation2017; Chelgani Citation2021; K. Zhou, Li, et al. Citation2021). Moreover, it uses first and second-order derivatives (Abbasniya et al. Citation2022). XGBoost’s objective function includes a convex loss function and a penalty term (X. Zhang et al. Citation2020), as can be seen in EquationEquation (2)(2)
(2) :
(2)
(2)
where
denotes the
th training iteration,
computes the difference between the ground truth and predicted value, and
is the penalty term for the
th tree, controlling its complexity of it (Chelgani, Nasiri, and Tohry Citation2021; X. Zhang et al. Citation2020; Nasiri and Alavi Citation2022). In the penalty term,
is the number of leaf nodes, and
represents the score on each leaf.
and
are parameters controlling the penalty associated with
and
(Ma et al. Citation2019; W. Zhang et al. Citation2021; Zhifen Zhang et al. Citation2021; J. Zhou, Qiu, et al. Citation2021; Fatahi et al. Citation2022).
2.4. Random Forest
Random Forest (RF) is a supervised learning algorithm, which is a decision tree (DT) basis model (Zojaji, Ebadzadeh, and Nasiri Citation2022). RF, first proposed by Breiman (Breiman Citation2001) in 2001, can be considered as an improved Bootstrap aggregating (Bagging) algorithm (Hou, Liu, and Yang Citation2022). The bagging approach combines several learning models to improve the final output. RF employs a random sampling technique when creating trees (Chelgani Citation2019). The training samples are drawn with replacement; thus, some samples may be used many times in a tree. Training on different samples helps the RF to reduce variance (Matin et al. Citation2016; Sun et al. Citation2021). Moreover, RF considers a random subset of input variables when splitting nodes. Modeling by RF has the following advantages: 1) reducing overfitting 2) having a few tunable parameters 3) being robust to outliers 4) having low bias 5) reducing variance compared to DTs (Gong et al. Citation2018; Ouallouche, Lazri, and Ameur Citation2018; Chelgani, Nasiri, and Tohry Citation2021; Nasiri, Homafar, and Chelgani Citation2021). Formally, RF creates an ensemble of DT estimators, and its final prediction can be computed as follows:
(3)
(3)
where
represents the input feature vector, and
denotes the
th decision tree’s prediction (Wager and Athey Citation2018; J. Zhou et al. Citation2019).
2.5. Support vector regression
Support vector regression (SVR) is a supervised machine learning method, similar to support vector machines but for the regression problem. The main idea behind SVR is to minimize the generalization error bound instead of minimizing the training error (Premalatha and Lakshmi Citation2013). The advantages of using RF for regression tasks include having high generalization capability with high prediction accuracy, being robust to outliers, low computational complexity in high dimensional space (i.e., computational complexity does not depend on the dimension of the input space), and being capable of obtaining a global solution (Y. Wang, Zhao, and Wang Citation2013; Awad and Khanna Citation2015; Parveen, Zaidi, and Danish Citation2016; Wolff Citation2017; Lawal and Kwon Citation2021).
Given a dataset …,
},
consider the problem of approximating output variable
with a linear function:
(4)
(4)
The parameters of the linear function (i.e., and
) can be determined by minimizing the following objective function:
(5)
(5)
where
denotes the regularization parameter,
and
are slack variables, indicating upper and lower bounds on the output variable (Li, Fang, and Liu Citation2018; Panahi et al. Citation2020; Premalatha and Vijaya Lakshmi Citation2013; Zichen Zhang and Hong Citation2019).
3. Results and discussions
3.1. Inter-correlations
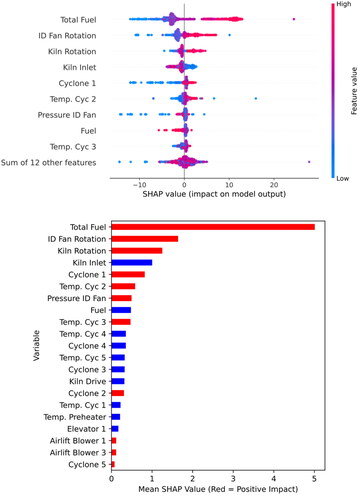
SHAP, and Pearson’s correlation have been used for exploring the potential relationships among operating variables and outcomes (ID fan and kiln feed rate), highlighting the importance of monitoring variable importance and ranking them based on their effectiveness in the modeling prediction. These assessments would formulate and lead to constructing a robust and informative CL for the unit. SHAP results ( and ) illustrated that ID fan rotation and pressure ID fan have the highest positive correlations with the ID fan current. SHAP outcomes also showed a high positive relationship between the ID fan rotation, total fuel consumption, and kiln feed rate. Generally, kiln speed and kiln feed rate can control with a fixed linear relationship and unilateral variation; however, it was documented that the speed should be kept constant in the upper range of feed rates (Alsop and Post Citation1995; Arad, Arad, and Bobora Citation2008; Stadler, Poland, and Gallestey Citation2011).
Figure 2. SHAP values of various variables for the prediction of ID fan current.
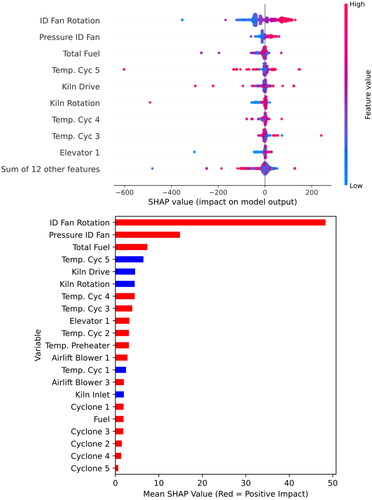
Figure 3. SHAP values of various variables for the prediction of Kiln feed rat.
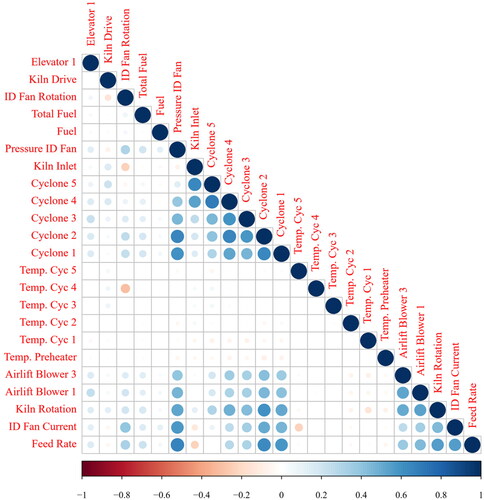
Exploring linear inter-correlations among variables by SHAP and Pearson correlation () highlights several interactions between various parameters. A strong positive correlation between ID fan current and kiln feed rate can be observed. In other words, increasing the ID fan current could positively affect its performance when the feed rate increases. A comparison between Pearson correlation and SHAP results indicated that a highly nonlinear model such as SHAP would be required for modeling the rotary kiln parameters since Pearson correlation as a linear method could not accurately illustrate some intercorrelations (Chelgani and Makaremi Citation2013).
Figure 4. Pearson correlation between operational parameters and their representative rotary kiln indexes.
3.2. Predictions
From the entire dataset, 70% of recorded variables were used to train the different AI models (i.e., XGBoost, RF, and SVR), 15% of the samples were used for validation, and the remaining 15% were considered for the model’s testing phase. For finding XGBoost’s optimal hyperparameters through the validation phase, many different values for its hyperparameters were examined in the tuning process (a try and error procedure) to find its optimal hyperparameters using the validation set. (). The XGBoost outcomes () in the testing phase demonstrated a higher accuracy than two other examined typical machine learning methods (RF and SVR). These differences have been highlighted for both the ID fan current and kiln feed rate predictions in .
Figure 5. Differences between actual and predicted values by various AI models in the testing phase.
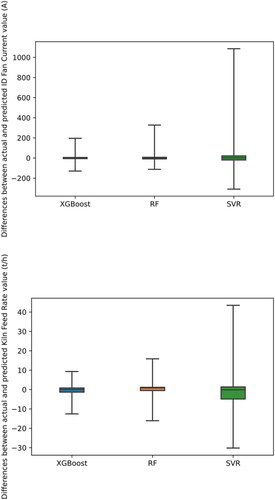
Table 2. The XGBoost parameter settings for various outputs.
Table 3. Model assessments based on accuracy indexes.
By comparing different ML algorithms, it could be mentioned that both RF and XGBoost are ensemble methods but not SVR. RF is based on bagging, while XGBoost is a boosting method. SVR has low bias and high variance, whereas XGBoost and RF have low bias and low variance. However, XGBoost is more flexible than the other two methods. It allows the user to customize the objective function. When using SVR, it might be challenging to choose the appropriate kernel function. In terms of computational complexity, XGBoost implements parallel processing, so it is very fast and has low computational complexity. SVR performs well in high dimensional space, but RF requires more computational resources; therefore, it has a high computational cost. All the mentioned algorithms can handle outliers and are not easily affected by them (Fan et al. Citation2018; Lee et al. Citation2019; Huang et al. Citation2020). These significant results indicated that the constructed CL based on the SHAP-XGBoost model could be considered as a robust EAI system for controlling and maintaining different cement units in various plants.
4. Conclusions
Since many cement production plants are monitored by the direct knowledge of their operators, developing an accurate knowledge-based system close to human basis understanding could markedly change the process efficiency. Digitalization and using explainable artificial intelligence (EAI) could be key steps of this transformation. As one of the most recent digitalization approaches, construing conscious lab “CL” by using SHAP-XGBoost (a most recent EAI development) for a rotary kiln has been investigated for the first time based on a cement plant dataset. The developed CL highlighted the correlations among various monitoring variables in the plant and indicated their effectiveness on the rotary kiln representative factors (induced draft (ID) fan current and kiln feed rate). SHAP as an explainable artificial intelligence method indicated that ID fan rotation has the highest positive relationship with the ID fan current. In general, increasing the ID fan rotation could increase the ID fan current and kiln feed rate. SHAP analyses demonstrated a significant correlation between the total fuel consumption and kiln feed rate. The XGBoost model has predicted the key rotary kiln representative factors. This model quite accurately could predict these two variables with R2 = 0.96. The estimation accuracy of XGBoost had been challenged with random forest and support vector regression models. The outcomes demonstrated that XGBoost could provide accurate results (root mean square error for kiln feed was XGBoost 2.47, random forest 4.2, and SVR 7.68, and ID fan current 26.49, 42.17, and 112.78, respectively). In general, these outcomes proposed that the developed model could effectively be used as a CL for digitalizing and controlling various units within cement plants.
Disclosure statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Abbasniya, M. R., S. A. Sheikholeslamzadeh, H. Nasiri, and S. Emami. 2022. Classification of breast tumors based on histopathology images using deep features and ensemble of gradient boosting methods. Computers and Electrical Engineering 103: 108382. doi:10.1016/j.compeleceng.2022.108382.
- Akalp, M., A. L. Dominguez, and R. Longchamp. 1994. Supervisory fuzzy control of a rotary cement kiln. Proceedings of MELECON’94. Mediterranean Electrotechnical Conference, 754–7.
- Alidokht, M., S. Yazdani, E. Hadavandi, and S. C. Chelgani. 2021. Modeling metallurgical responses of coal tri-flo separators by a novel BNN: A ‘conscious-lab’ development. International Journal of Coal Science & Technology 8 (6):1436–46. doi:10.1007/s40789-021-00423-7.
- Alsop, P. A, and J. W. Post. 1995. Cement plant: Operations handbook. Dorking, Surrey: Tradeship.
- Arad, S., V. Arad, and B. Bobora. 2008. Advanced control schemes for cement fabrication processes. London: Intech.
- Awad, M, and R. Khanna. 2015. Support vector regression. In Efficient learning machines, 67–80. Berkeley, CA: Apress.
- Boateng, A. A. 2008. Rotary kilns: Transport phenomena and transport process, Jordan Hill, Oxford: Linacre House.
- Boateng, A. A. 2015. Rotary kilns: Transport phenomena and transport processes. Oxford: Butterworth-Heinemann.
- Breiman, L. 2001. Random forests. Machine Learning 45 (1):5–32. doi:10.1023/A:1010933404324.
- Bui, R. T., S. Tarasiewicz, and A. Charette. 1982. A computer model for the cement kiln. IEEE Transactions on Industry Applications, IA-18 (4):424–30.
- Bussmann, N., P. Giudici, D. Marinelli, and J. Papenbrock. 2021. Explainable machine learning in credit risk management. Computational Economics 57 (1):203–16. doi:10.1007/s10614-020-10042-0.
- Chelgani, S. C. 2019. Prediction of specific gravity of afghan coal based on conventional coal properties by stepwise regression and random forest. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects. 41:1–12.
- Chelgani, S. C., H. Nasiri, and A. Tohry. 2021. Modeling of particle sizes for industrial HPGR products by a unique explainable AI tool – A ‘conscious lab’ development. Advanced Powder Technology 32 (11):4141–8. doi:10.1016/j.apt.2021.09.020.
- Chelgani, S. C. 2021. Estimation of gross calorific value based on coal analysis using an explainable artificial intelligence. Machine Learning with Applications 6:100116. doi:10.1016/j.mlwa.2021.100116.
- Chelgani, S. C., H. Nasiri, and M. Alidokht. 2021. Interpretable modeling of metallurgical responses for an industrial coal column flotation circuit by XGBoost and SHAP – A ‘conscious-lab’ development. International Journal of Mining Science and Technology 31 (6):1135–44. doi:10.1016/j.ijmst.2021.10.006.
- Chelgani, S. C., and S. Makaremi. 2013. Explaining the relationship between common coal analyses and afghan coal parameters using statistical modeling methods. Fuel Processing Technology 110:79–85. doi:10.1016/j.fuproc.2012.11.005.
- Chen, T, and C. Guestrin. 2016. Xgboost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–94.
- Chipakwe, V., P. Semsari, T. Karlkvist, J. Rosenkranz, and S. C. Chelgani. 2020. A critical review on the mechanisms of chemical additives used in grinding and their effects on the downstream processes. Journal of Materials Research and Technology 9 (4):8148–62. doi:10.1016/j.jmrt.2020.05.080.
- Coskun, C. 2019. A time-varying carbon intensity approach for demand-side management strategies with respect to CO2 emission reduction in the electricity grid. International Journal of Global Warming 19 (1/2):3–23. doi:10.1504/IJGW.2019.101768.
- Delong, J. H, and R. C. Aitken. 1981. Factorial analysis of a cement kiln. Applied Mathematical Modelling 5 (5):341–7. doi:10.1016/S0307-904X(81)80056-X.
- Ezzoddin, M., H. Nasiri, and M. Dorrigiv. 2022. Diagnosis of COVID-19 cases from chest X-ray images using deep neural network and LightGBM. 2022 International Conference on Machine Vision and Image Processing (MVIP), 1–7. doi:10.1109/MVIP53647.2022.9738760.
- Fallahpour, M., A. Fatehi, B. N. Araabi, and M. Azizi. 2007. A supervisory fuzzy control of back-end temperature of rotary cement kilns. 2007 International Conference on Control, Automation and Systems, 429–34.
- Fan, J., X. Wang, L. Wu, H. Zhou, F. Zhang, X. Yu, X. Lu, and Y. Xiang. 2018. Comparison of support vector machine and extreme gradient boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Conversion and Management 164:102–11. doi:10.1016/j.enconman.2018.02.087.
- Fatahi, R., H. Nasiri, E. Dadfar, and S. C. Chelgani. 2022. Modeling of energy consumption factors for an industrial cement vertical roller mill by SHAP-XGBoost: A ‘conscious lab’ approach. Scientific Reports 12 (1):7543. doi:10.1038/s41598-022-11429-9.
- Feng, D.-C., W.-J. Wang, S. Mangalathu, and E. Taciroglu. 2021. Interpretable XGBoost-SHAP machine-learning model for shear strength prediction of squat RC walls. Journal of Structural Engineering 147 (11): 4021173. doi:10.1061/(ASCE)ST.1943-541X.0003115.
- Gaurav, G. K., and S. Khanam. 2016. Analysis of temperature profile and % metallization in rotary kiln of sponge iron process through CFD. Journal of the Taiwan Institute of Chemical Engineers 63:473–81. doi:10.1016/j.jtice.2016.02.035.
- Gómez-Ríos, A., J. Luengo, and F. Herrera. 2017. A study on the noise label influence in boosting algorithms: AdaBoost, GBM and XGBoost. International Conference on Hybrid Artificial Intelligence Systems, 268–80.
- Gong, H., Y. Sun, X. Shu, and B. Huang. 2018. Use of random forests regression for predicting IRI of asphalt pavements. Construction and Building Materials 189:890–7. doi:10.1016/j.conbuildmat.2018.09.017.
- Hasani, S, and H. Nasiri. 2022. COV-ADSX: An automated detection system using X-ray images, deep learning, and XGBoost for COVID-19. Software Impacts 11:100210. doi:10.1016/j.simpa.2021.100210.
- Hou, S., Y. Liu, and Q. Yang. 2022. Real-time prediction of rock mass classification based on TBM operation big data and stacking technique of ensemble learning. Journal of Rock Mechanics and Geotechnical Engineering 14 (1):123–43. doi:10.1016/j.jrmge.2021.05.004.
- Huang, J.-C., Y.-C. Tsai, P.-Y. Wu, Y.-H. Lien, C.-Y. Chien, C.-F. Kuo, J.-F. Hung, S.-C. Chen, and C.-H. Kuo. 2020. Predictive modeling of blood pressure during hemodialysis: A comparison of linear model, random forest, support vector regression, XGBoost, LASSO regression and ensemble method. Computer Methods and Programs in Biomedicine 195:105536.
- Jorjani, E., S. Mesroghli, and S. C. Chelgani. 2008. Prediction of operational parameters effect on coal flotation using artificial neural network. Journal of University of Science and Technology Beijing, Mineral, Metallurgy, Material 15 (5):528–33. doi:10.1016/S1005-8850(08)60099-7.
- Lawal, A. I., and S. Kwon. 2021. Application of artificial intelligence to rock mechanics: An overview. Journal of Rock Mechanics and Geotechnical Engineering 13 (1):248–66. doi:10.1016/j.jrmge.2020.05.010.
- Lee, Y., D. Han, M.-H. Ahn, J. Im, and S. J. Lee. 2019. Retrieval of total precipitable water from Himawari-8 AHI data: A comparison of random forest, extreme gradient boosting, and deep neural network. Remote Sensing 11 (15):1741. doi:10.3390/rs11151741.
- Leng, J., D. Wang, X. Ma, P. Yu, L. Wei, and W. Chen. 2022. Bi-level artificial intelligence model for risk classification of acute respiratory diseases based on Chinese clinical data. Applied Intelligence 52:13114–13131.
- Li, S., H. Fang, and X. Liu. 2018. Parameter optimization of support vector regression based on sine cosine algorithm. Expert Systems with Applications 91:63–77. doi:10.1016/j.eswa.2017.08.038.
- Lundberg, S. M., and S.-I. Lee. 2017. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30:4765–74.
- Ma, J., Y. Ding, J. C. P. Cheng, Y. Tan, V. J. L. Gan, and J. Zhang. 2019. Analyzing the leading causes of traffic fatalities using XGBoost and grid-based analysis: A city management perspective. IEEE Access 7:148059–72. IEEEdoi:10.1109/ACCESS.2019.2946401.
- Makaremi, I., A. Fatehi, B. N. Araabi, M. Azizi, and A. Cheloeian. 2009. Abnormal condition detection in a cement rotary kiln with system identification methods. Journal of Process Control 19 (9):1538–45. doi:10.1016/j.jprocont.2009.07.013.
- Mangalathu, S., H. Shin, E. Choi, and J.-S. Jeon. 2021. Explainable machine learning models for punching shear strength estimation of flat slabs without transverse reinforcement. Journal of Building Engineering 39:102300. doi:10.1016/j.jobe.2021.102300.
- Matin, S. S., J. C. Hower, L. Farahzadi, and S. C. Chelgani. 2016. Explaining relationships among various coal analyses with coal grindability index by random forest. International Journal of Mineral Processing 155:140–6. doi:10.1016/j.minpro.2016.08.015.
- Nasiri, H, and S. A. Alavi. 2022. A novel framework based on deep learning and ANOVA feature selection method for diagnosis of COVID-19 cases from chest X-ray images. Computational Intelligence and Neuroscience 2022:4694567. doi:10.1155/2022/4694567.
- Nasiri, H, and S. Hasani. 2022. Automated detection of COVID-19 cases from chest x-ray images using deep neural network and XGBoost. Radiography 28 (3):732–8. doi:10.1016/j.radi.2022.03.011.
- Nasiri, H., A. Homafar, and S. C. Chelgani. 2021. Prediction of uniaxial compressive strength and modulus of elasticity for travertine samples using an explainable artificial intelligence. Results in Geophysical Sciences 8:100034. doi:10.1016/j.ringps.2021.100034.
- Ogunleye, A, and Q. G. Wang. 2020. XGBoost model for chronic kidney disease diagnosis. IEEE/ACM Transactions on Computational Biology and Bioinformatics 17 (6):2131–40. doi:10.1109/TCBB.2019.2911071.
- Ouallouche, F., M. Lazri, and S. Ameur. 2018. Improvement of rainfall estimation from MSG data using random forests classification and regression. Atmospheric Research 211:62–72. doi:10.1016/j.atmosres.2018.05.001.
- Panahi, M., N. Sadhasivam, H. R. Pourghasemi, F. Rezaie, and S. Lee. 2020. Spatial prediction of groundwater potential mapping based on convolutional neural network (CNN) and support vector regression (SVR). Journal of Hydrology 588:125033. doi:10.1016/j.jhydrol.2020.125033.
- Parveen, N., S. Zaidi, and M. Danish. 2016. Support vector regression model for predicting the sorption capacity of lead (II). Perspectives in Science 8:629–31. doi:10.1016/j.pisc.2016.06.040.
- Premalatha, M, and C. Vijaya Lakshmi. 2013. SVM trade-off between maximize the margin and minimize the variables used for regression. International Journal of Pure and Applied Mathematics 87 (6):741–50.
- Radwan, A. M. 2012. Different possible ways for saving energy in the cement production. Advances in Applied Science Research 3 (2):1162–74.
- Sharabiany, M. G., A. Fatehi, and B. N. Araabi. 2011. An adaptive neuro fuzzy controller for cement kiln. 2011 2nd International Conference on Instrumentation Control and Automation, 65–70.
- Söğüt, M. Z. 2012. A research on exergy consumption and potential of total CO2 emission in the Turkish cement sector. Energy Conversion and Management 56:37–45.
- Stadler, K. S., J. Poland, and E. Gallestey. 2011. Model predictive control of a rotary cement kiln. Control Engineering Practice 19 (1):1–9. doi:10.1016/j.conengprac.2010.08.004.
- Sui, X., Y. Zhang, S. Shao, and S. Zhang. 2014. Exergetic life cycle assessment of cement production process with waste heat power generation. Energy Conversion and Management 88:684–92. doi:10.1016/j.enconman.2014.08.035.
- Sun, Y., G. Li, N. Zhang, Q. Chang, J. Xu, and J. Zhang. 2021. Development of ensemble learning models to evaluate the strength of coal-grout materials. International Journal of Mining Science and Technology 31 (2):153–62. doi:10.1016/j.ijmst.2020.09.002.
- Tohry, A., S. Yazdani, E. Hadavandi, E. Mahmudzadeh, and S. C. Chelgani. 2021. Advanced modeling of HPGR power consumption based on operational parameters by BNN: A ‘conscious-lab’ development. Powder Technology 381:280–4. doi:10.1016/j.powtec.2020.12.018.
- Ungari, S, and E. Benhamou. 2021. Deep reinforcement learning for portfolio allocation. Risk Magazine Global Quant Network.
- Wager, S, and S. Athey. 2018. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association 113 (523):1228–42. doi:10.1080/01621459.2017.1319839.
- Wang, L.-X. 1994. Adaptive fuzzy systems and control: Design and stability analysis. Upper Saddle River, NJ: Prentice-Hall, Inc.
- Wang, S., F. Dong, and D. Yuan. 2007. The design and implementation of a cement kiln expert system. 2007 IEEE International Conference on Automation and Logistics, 2716–9.
- Wang, Y., X. Zhao, and B. Wang. 2013. LS-SVM and Monte Carlo methods based reliability analysis for settlement of soft clayey foundation. Journal of Rock Mechanics and Geotechnical Engineering 5 (4):312–7. doi:10.1016/j.jrmge.2012.06.003.
- Wolff, B. 2017. Support Vector Regression for Solar Power Prediction. Oldenburg: Universität Oldenburg.
- Zhang, Z, and W.-C. Hong. 2019. Electric load forecasting by complete ensemble empirical mode decomposition adaptive noise and support vector regression with quantum-based dragonfly algorithm. Nonlinear Dynamics 98 (2):1107–36. Springer doi:10.1007/s11071-019-05252-7.
- Zhang, Z., Y. Huang, R. Qin, W. Ren, and G. Wen. 2021. XGBoost-based on-line prediction of seam tensile strength for Al-Li alloy in laser welding: Experiment study and modelling. Journal of Manufacturing Processes 64:30–44. doi:10.1016/j.jmapro.2020.12.004.
- Zhang, W., C. Wu, H. Zhong, Y. Li, and L. Wang. 2021. Prediction of Undrained shear strength using extreme gradient boosting and random forest based on Bayesian optimization. Geoscience Frontiers 12 (1):469–77. doi:10.1016/j.gsf.2020.03.007.
- Zhang, X., C. Yan, C. Gao, B. A. Malin, and Y. Chen. 2020. Predicting missing values in medical data via XGBoost regression. Journal of Healthcare Informatics Research 4 (4):383–94. doi:10.1007/s41666-020-00077-1.
- Zhou, J., Y. Qiu, S. Zhu, D. Jahed Armaghani, M. Khandelwal, and E. Tonnizam Mohamad. 2021. Estimation of the TBM advance rate under hard rock conditions using XGBoost and Bayesian optimization. Underground Space. 6 (5):506–15. doi:10.1016/j.undsp.2020.05.008.
- Zhou, J., E. Li, H. Wei, C. Li, Q. Qiao, and D. J. Armaghani. 2019. Random forests and cubist algorithms for predicting shear strengths of rockfill materials. Applied Sciences 9 (8):1621. doi:10.3390/app9081621.
- Zhou, K., S. Li, X. Zhou, Y. Hu, C. Zhang, and J. Liu. 2021. Data-driven prediction and analysis method for nanoparticle transport behavior in porous media. Measurement 172:108869. doi:10.1016/j.measurement.2020.108869.
- Zojaji, Z., M. M. Ebadzadeh, and H. Nasiri. 2022. Semantic schema based genetic programming for symbolic regression. Applied Soft Computing 122:108825. doi:10.1016/j.asoc.2022.108825.