
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Background
Conventional growth charts offer limited guidance to track individual growth.
Aim
To explore new approaches to improve the evaluation and prediction of individual growth trajectories.
Subjects and methods
We generalise the conditional SDS gain to multiple historical measurements, using the Cole correlation model to find correlations at exact ages, the sweep operator to find regression weights and a specified longitudinal reference. We explain the various steps of the methodology and validate and demonstrate the method using empirical data from the SMOCC study with 1985 children measured during ten visits at ages 0–2 years.
Results
The method performs according to statistical theory. We apply the method to estimate the referral rates for a given screening policy. We visualise the child’s trajectory as an adaptive growth chart featuring two new graphical elements: amplitude (for evaluation) and flag (for prediction). The relevant calculations take about 1 millisecond per child.
Conclusion
Longitudinal references capture the dynamic nature of child growth. The adaptive growth chart for individual monitoring works with exact ages, corrects for regression to the mean, has a known distribution at any pair of ages and is fast. We recommend the method for evaluating and predicting individual child growth.
Introduction
Evaluation and prediction of child growth are central activities in child health care. Conventional growth charts display the variation in growth in the population by age. Such charts offer limited guidance to address questions of parents and health professionals. Typical questions that parents have are: Is my child’s growth normal? Why is my child not following the centile line? What are the options to counter my child’s inhibited growth? Where will the next measurement be? Health professionals have questions like: Given what I know of the child, how will it develop in the future? Did the child grow normally since the last visit? What can I tell the parent about the child’s realised and future growth? While this article does not address all these questions directly, it offers tools that aim to advance the evaluation and prediction of individual growth curves.
Most published growth charts are distance references that portray the effects of age and sex on growth. Distance references have two primary uses. First, we can use them to evaluate the attained child’s growth at a particular age by comparing the child’s measurement to the population centiles in the chart. Second, we can apply distance references to remove the effects of age and sex on growth by transforming each measurement to a standard deviation score (SDS) or -score. As a result, effects on growth unrelated to age or sex will be easier to detect. Distance-based charts provide limited guidance on individual growth. Differences in tempo between children may produce distance references that are both biased and inefficient for studying growth during puberty (Tanner Citation1990, p. 187). At the individual level, it is better to look for unexpected changes in growth (e.g. failure-to-thrive, slow persistent deceleration, developmental delay) to identify potential pathology. This paper, therefore, concentrates on measures of change.
A simple measure of change is velocity, defined as , where
and
are the attained size at ages
and
. Low velocity appears on the distance chart as a downwards centile crossing. The level and variance of
depend on age and sex, so proper interpretation of
requires age- and sex-conditional references. Replacing
by
standardises the velocity scale to SDS per year, but its distribution depends on
and
. Whereas a decelerating curve with a slope of −1 SDS/year indicates a dramatic height loss during childhood, the same value in infancy could fall within the normal range. Cole (Citation1995) discussed a standardised version of velocity
, where
and
is the correlation between
and
.
has a standard normal distribution for all pairs of
However, the problem with
is that it fails to account for regression to the mean. Generally, a child with a
value below zero has a higher expected growth rate than a child with a
value above zero. The strength of the effect depends on
.
Healy (Citation1974) proposed a regression approach that conditions the reference on one or more known child factors. Prior measurements made at an earlier age are predictive in longitudinal settings. Early examples of references that condition previous data include Cameron (Citation1980) and Berkey et al. (Citation1983). Cole (Citation1995) developed the conditional gain score with
, which predicts
from a prior measurement
. Conditioning may also involve multiple factors. For example, Thompson and Fatti (Citation1997) proposed weight charts that adjusted the references to individual characteristics like height, age, and parity. The idea of conditioning can improve screening and monitoring tools with elevated sensitivity and specificity for detecting growth-related diseases.
lists velocity and conditional indices for two measurements. The conditional SDS gain is the preferred measure in . It is the only measure that standardises for age and sex and that corrects for regression to the mean, a fundamental statistical phenomenon. Regression to the mean stems from the natural variation in weight gain from child to child. This variation is a combination of measurement error and actual biological differences in weight gain, so both components contribute to regression to the mean (Wright et al. Citation1994; Cole Citation1995). Moreover, especially for small values of , its variance
is low, so it is less sensitive to measurement error in
and
than alternatives. For these reasons, this paper concentrates on conditional SDS gain
as the measure of change.
Table 1. Overview of distance, velocity and conditional gain measures for longitudinal data.
Despite its technological superiority, the conditional SDS gain has yet to be widely adopted. One reason for the slow update is that calculating by hand is difficult. In addition, there are no accepted standards or references for the time-to-time correlation matrix, i.e. the correlation matrix of the measurement taken at different ages. Another complication is that is defined for two ages. In practice, we need to assess growth curves that consist of more than two measurements. In that case, there are multiple ways to select two ages. Calculating
for many age pairs leads to issues related to multiple testing. This paper, therefore, concentrates on extending
to work with more than two ages.
Wright et al. (Citation1994) introduced the term thrive line. Until now, thrive lines have enjoyed limited popularity. For example, the overview by Scherdel et al. (Citation2016) shows that many routine monitoring systems rely on decision rules with arbitrary cut points and unconditional SDS gain scores. Visual thrive line overlays exist that help interpret the growth chart, but these apply only to fixed age intervals. Technically, the thrive line is equivalent to a centile of the distribution of . This paper adopts the concept of the thrive line as a natural and elegant criterion for finding children experiencing failure to thrive.
This paper aims to develop, validate and demonstrate tools to evaluate and predict individual growth. The tools should work on growth curves with measurements taken at arbitrary ages, allow for a flexible choice of growth reference, take the dynamic nature of growth into account, be fast, intuitive, and easy to communicate, and have known statistical properties. Evaluation should inform us whether the observed growth is normal and assist in decision-making in cases where the child’s growth is unusual. Prediction should inform us about the likely growth path in the future and portray the inherent uncertainty associated with this prediction.
Section 2 (Materials) introduces the data used. Section 3 (Methodology) presents a definition of a longitudinal reference, extends to include additional measurements, describes a fast algorithm to fit the relevant regression models, and explains how the method can work with arbitrary ages. Section 4 (Statistical Analysis) describes the quantitative techniques used to estimate the model parameters and validation statistics. Section 5 (Results) reports the results of the quantitative analysis. Section 6 (Applications) describes two applications: estimation of the overall referral rate and visualisation by the adaptive growth chart. Section 7 (Discussion) highlights the pros and cons and identifies areas for further research.
Subjects and methods
Materials
Data
The SMOCC study (Herngreen et al. Citation1994) collected weight measurements of a representative sample of 2151 Dutch children aged 0–2 between 1989 and 1990. Trained observers monitored and measured children at ten visits: birth and at months 1, 2, 3, 6, 9, 12, 15, 18, and 24. We selected the subset of 1895 children with a gestational age 37 weeks and a minimum of four visits. Raw weights and heights were transformed into age- and sex-conditional
-scores using references from the Fourth Dutch Growth Study (Fredriks et al. Citation2000).
Descriptive statistics
contains the time-to-time correlations 1000 calculated from the
-scores in the SMOCC study subsample of term births. The number of measurements used to calculate was 16,266 (height) and 17,618 (weight). We grouped the measurement ages into ten age bins and calculated the pairwise Pearson correlation matrix from the wide data.
Table 2. Time-to-time correlations times 1000 for Dutch children measured at birth, 1, 2, 3, 6, 9, 12, 15, 18 and 24 months. The upper triangle contains height correlations and the lower triangle represents weight correlations at different ages. Source data: Herngreen et al. (Citation1994).
Methodology
Longitudinal reference
A longitudinal reference describes the variation in growth between and within children. It is convenient to compose a longitudinal reference from two independent parts, a distance reference, and a time reference.
The distance reference describes how growth depends on sex and age (or on height, in the case of weight-for-height). Distance references derive from cross-sectional or longitudinal data or mixes of these. A significant application of
is transforming measurements
into
-scores, which removes the effects of age and sex. Assuming that
is appropriate for the sample of interest, then
follows a normal distribution with a zero mean and a unit variance at every age.
The time reference describes how
-scores are related over time by the time-to-time correlation matrix
of
-scores. Time references can be calculated only from longitudinal studies. The idea of modelling distance and time references in successive stages is not novel. Pan and Goldstein (Citation1997) emphasise that modelling on the scale of
is statistically convenient since it allows us to characterise the multivariate data structure fully.
We use the notation to refer to a longitudinal reference
. Note that we do not require that
and
stem from the same study. In this paper, we take
as the height and weight references from the Fourth Dutch Growth Study (Fredriks et al. Citation2000) and define
as the values in . The combination of
and
completely defines this study’s longitudinal reference
.
Conditional SDS gain for multiple time points
Let stand for a measurement made at child age
(in months). Once we have reference
in place, the objective is to model
, i.e. the distribution of outcome
at time points
given any measurements observed at earlier time points
. Subscript
represents a vector of time points, possibly in the past, present or future.
describes the predictive distribution of
if
lies in the future. For present and past
, the observed value
can be checked against the predicted distribution. We first consider this situation.
Two-time points
Suppose that we have height measurements and
taken at ages of
(past) and
(present) months, respectively. In a screening context, we wish to evaluate whether the realised height gain of the child during the interval
is deficient. We check whether the probability of observing a value
given
,
, exceeds a pre-set cut point. Let the “hat notation”
indicate the predicted child height at month 6 given the child’s observed height at month 2 and reference
. We are interested in answering two questions: What is the expected score
given a previous
and
? How far is realised
from the expected
? The recipe for calculating the conditional SDS gain
is:
Transform measurements
into
Interpolate
Calculate conditional SDS gain
Back transform
Back transform
Assess the location of realised
For example, suppose that ,
and
, where
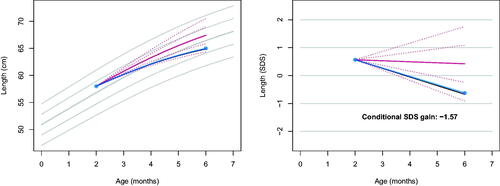
’s unit is CM. plots the observed curve (solid, blue) and the predicted centiles at −2 SD, −1 SD, 0 SD, +1 SD, +2 SD of the prediction interval (in red) at
. The left-hand plot depicts the observed and predicted curves in the measurement scale, whereas the right-hand side figure plots the same data in the SDS scale. The conditional SDS gain is
, just above the thrive line at the fifth centile (solid, black), at
.
Figure 1. Observed length curve (blue) plotted on top of the personalised reference (solid red: predicted growth; dotted red: centiles -2, -1, +1, +2 SD of the prediction interval), in the measurement scale (left) and the SDS scale (right). The conditional SDS gain at month 6 is equal to -1.57, just above thrive line at -1.64 (solid black). The grey lines in the background correspond to the height references for girls from the Fourth Dutch Growth Study.
Three time points
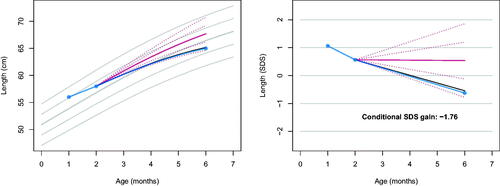
Growth faltering between months 2 and 6 is substantial in the example, but the value of −1.57 is slightly above the cut-off. Could our evaluation change if we use more than one historic measurement? To gain further insight, let us model and address the following questions: What is the expected score
given
,
and
? How far is realised
from the expected
? Suppose we have an additional measurement at month 1. The recipe for calculating the conditional SDS gain from time points
is:
Transform measurements
Define time model
Calculate regression weights
Calculate multiple correlation
Calculate conditional SDS gain
Then follow the previous recipe
Using ,
and
from , we obtain
,
and
. Suppose
CM, then
so
.
communicates that the curve shows a prolonged growth failure starting at month 1. The conditional SDS gain of −1.76 indicates a more severe growth deceleration than before. As a result of adding the additional measurement, the realised gain is below the fifth centile thrive line.
Figure 2. Observed length (blue) on the personalised reference (solid red: predicted growth; dotted red: centiles -2, -1, +1, +2 SD of the prediction interval) with three time points. The conditional SDS gain of -1.76 indicates a more severe drop-off (4 out of 100) than in , thus providing an early warning of possible growth failure.
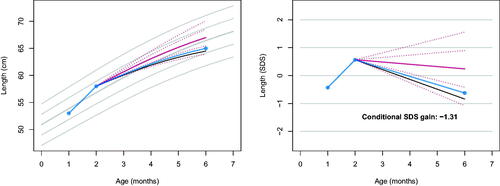
shows the same analysis, with one difference: instead of
. Now
, which changes
, so for these data 10 out of 100 have a lower
value. Compared to , deceleration between months 2 and 6 now appears less alarming. The jagged nature of the trajectory in suggests that
may be too high, perhaps due to measurement error. The difference between and illustrates that adding one extra observation affects the interpretation of the growth curve in an intuitive way.
Figure 3. Same as , but now with an altered starting observation. Observed length (blue) on the personalised reference (solid red: predicted growth; dotted red: centiles -2, -1, +1, +2 SD of the prediction interval) with three time points. The conditional SDS gain of -1.31 indicates that drop-off is less severe than in . The pattern suggests that the drop-off between months 2 and 6 may partly result from measurement error at month 2.
Estimation with more than three time points
The calculation of and
in recipe 2 becomes cumbersome for more than three-time points. The sweep operator (Beaton Citation1964; Goodnight Citation1979) is a fast and easy way to obtain these quantities for arbitrary time points. The operator calculates
and
for any linear regression by applying simple pivots to the correlation matrix. Suppose we have the correlation matrix for time points 1, 2, and 6 months, and we wish to obtain
and
for predicting the outcome at month 6. The procedure below uses the sweep.operator() function from the R package fastmatrix (Osorio and Ogueda Citation2022). We start with the relevant
correlation matrix:

All variables are outcomes, but we may sweep out (“turn into in predictor variable”) columns 1 and 2 as follows:
We find the values of the and
parameters in the third column of the calculated result matrix s. The two regression weights
and
are
, and
equals
.
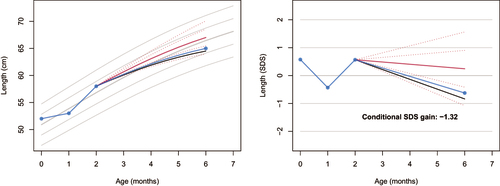
Application of the sweep operator to the time-to-time correlation table generalises the conditional SDS gain to any number of time points. For example, adds a birth length of cm to the curve. Note that the conditional SDS gain of −1.32 is similar to the previous model, which included two historical points. Adding birth length here had only a minimal impact on the evaluation.
Figure 4. Same as , but now with an additional observation at birth. The conditional SDS gain of -1.32 is similar in size as in , suggesting that including birth length does not add new information.
Arbitrary observation ages
Until now, the text presented examples where the measurement ages coincide with tabulated time points in . In reality, the measurement ages and tabulated time points will differ. To make it useable, our model needs to work with arbitrary ages.
Correlation models express the correlation between two Z-scores
and
at successive ages
and
as a function of those ages. The Cole correlation model (Cole Citation1995) describes the Fisher-transform
of the correlation
as a function of the sum
, the difference
, the reciproke
and includes two multiplicative terms. If
,
and
the model
has six unknown parameters that need to be estimated from
. Once the model is fitted and applied to new
and
, the outcomes can be back-transformed into the correlation scale as
.
Statistical analysis
The aims of the statistical analyses were 1) to estimate the parameters of the correlation model and 2) to validate the statistical properties of the proposed methodology.
The first task was to estimate the parameters of the correlation model from the data in . The shortest interval in the table is one month, so the fitted model will need to extrapolate outside the data when is shorter than one month. To stabilise the estimates for such intervals, we arbitrarily specified the correlation of any 3-day difference to be equal to 0.95.
The second task was to obtain insight into the statistical properties of the method in practice. We calculated the mean and the standard deviation of the empirical distribution of the conditional SDS gain for two models, called LAST and ALL. Model LAST conditions on the most recent measurement, while model ALL conditions on all historic measurements since birth. We estimated the proportion of explained variance and percentage of observations below the thrive line at each visit.
Results
Correlation model estimates
contains the parameter estimates of the Cole model fitted to the Fisher-transformed weight and height correlations in . The fit for weight is near perfect with a percentage of explained variance of 99.7 per cent. Height correlations (97.1 per cent) are more challenging to model, especially for correlations below 0.5. After back-transformation into the correlation scale, the standard deviation of the observed minus predicted correlations was equal to 0.012 and 0.043, respectively, for weight and height.
Table 3. Linear regression of Fisher transformed correlations between Z-scores as predicted by mean age and time gap (in months), fitted on the data in .
Validation
summarises the mean and standard deviations of the -scores for weight and height relative to the Dutch references for the SMOCC data. As expected, most aggregates are close to 0 (mean) and 1 (sd). The empirical distribution of the conditional SDS weight and height gains
is close to the standard normal distribution. The SMOCC children are slightly heavier and taller than the references between months 2 and 6. Note that the weight gain at month 2 has a positive bias (0.416 and 0.453), which indicates that children grow faster than expected between months 1 and 2. Weight gain is slower between months 3 and 6. The empirical standard deviation of
tends to be smaller than 1.0 around month 12. The proportion of explained variance for child weight from visit-to-visit is around 80 per cent. An exception is month 3 due to the relatively large time gap between month 3 and month 6. For height, predictive accuracy hovers around 73 per cent. Finally, the observed percentage of children below the P5 thrive line is 4.1 (weight) and 4.5 per cent (height), close to the nominal percentage of 5 per cent. Differences are generally slight between models LAST and ALL.
Table 4. Mean (MEAN) and standard deviations (SD) of Z-scores and conditional SDS gains
, the proportion of variance explained
and the percentage of children below the P5 for models LAST (only last measurement) and ALL (all historic measurements), aggregated by visits (in months).
Applications
We demonstrate two applications of the method. The first application studies the effect of multiple testing on the overall referral rate. The second application uses the conditional SDS gain to create an adaptive growth chart that adds two new graphical elements.
Overall referral rate
Suppose we refer a child if its conditional gain SDS at some age is below a pre-specified centile. We wish to study the statistical properties of a growth monitoring scheme with visits. What is the probability that we refer a child in any of those
visits? Under successive independent assessments, we can calculate the theoretical answer as 1 - pbinom(0, k − 1, 0.05). For example, if
, we obtain a probability of 0.185. How accurate is the theoretical answer in practice for different
?
We calculated the percentage of children with a conditional SDS gain below the 5 per cent thrive line in one or more of 10 visits and compared the result to the cumulative binomial distribution. specifies three base referral probabilities and compares the theoretical answer to the actual proportions in the SMOCC data. The theoretical proportion rapidly grows as the number of evaluations increases. For example, if we refer if the conditional SDS gain is below −1.645 (
, then the binomial predicts that a sequence of ten evaluations will refer 37.0 per cent of all children at least once. Although the realised percentages are lower (28.2 and 30.5 per cent), these referrals are unreasonably large parts of the population. Using a stricter cut-off of −2.326 (
) reduces the rate to a more reasonable 8.6 per cent.
Table 5. Percentage of children with at least one referral based on the evaluation of the conditional SDS gain for a growth monitoring scheme with 10 visits in the first two years. For three base probabilities (0.05, 0.025, 0.01) the table gives the probability according to the binomial distribution, the realised proportion for weight, and the realised proportion for height.
The binomial provides a reasonably accurate representation of the realised proportions, especially for small base probabilities. The distribution appears as a workable approximation for calibrating referral proportions in a growth monitoring scheme. suggests that we may change the base referral probability, but there are also other alternatives. For example, we can tailor cut-off values to different actions (e.g. planning an additional visit), reduce the evaluation moments to a subset of time points, or - more generally - specify different referral proportions at different ages. The sequential testing literature on alpha spending functions (Demets and Lan Citation1994) treats the problem in detail.
Adaptive growth chart
A frequently asked question among parents is how tall their child will be. We know that tall parents have tall offspring, but for a given child, an accurate answer depends primarily on the realised growth of that child. Prediction of future growth can help to set expectations and motivate healthy behaviour. This section explores the techniques proposed in this paper to draw personalised growth charts.
The conditional SDS gains conditions on realised child growth and predicts current growth from previous growth. The same technique also applies to future growth. We can augment the correlation table of measurements at past ages with a set of future ages and calculate a personalised growth chart from the augmented table.
presents an adaptive growth chart that combines four graphic elements, each with a specific function:
Figure 5. Adaptive growth chart for the same child at nine successive visits (top-left to bottom-right). A computer-generated dispay would show one panel at a time, so the elements change dynamically at every new measurement. Each panel contains four graphic elements: the child’s growth curve (blue line), the population reference band (light green), amplitude showing the conditional SDS gain (darker bars, left of last measurement) and the flag, personalised reference band of future growth one-year ahead for the child.
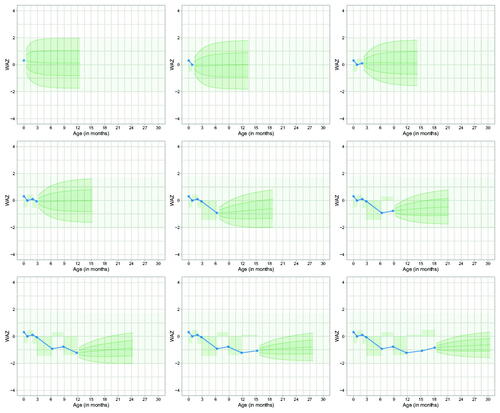
Blue points and lines: the child’s growth curve;
Reference band: area for evaluating the child’s data relative to a reference population;
Amplitude: area to evaluate how common the variation in the data over time is;
Flag: a mini-growth chart delimiting the area where we expect the child’s subsequent measurement one-year ahead.
We discuss each in turn.
The blue points represent the realised weight measurements adjusted for age (WAZ) for nine successive visits. Each visit adds one measurement. We see the top-left chart at birth, the top-middle chart at month 1, and the bottom-right chart at 18 months.
The reference band between the −2.0 SD and +2.0 SD delimits the normal range of the reference population. We expect that 95.4 per cent of the measurements of children of a given age will fall within this range. We can quickly evaluate whether some of the blue points are located outside the normal range and take appropriate action accordingly.
The amplitude element visualises a series of conditional SDS gains calculated for successive age intervals. The amplitude element is empty at birth and expands as a new measurement arrives. The element indicates how common the observed variability in the growth curve is. A zero amplitude means that the child grows precisely according to expectation. This could occur occasionally, but actual child growth typically deviates from the expectation. The level expresses the deviation’s direction and intensity during the age interval. A positive direction indicates that the child grew faster than expected, while the intensity level measures how much. The amplitude element provides a quick assessment of the commonness of variations in the data. We expect 95.4 per cent of the intensity levels to lie between the −2.0 SD and −2.0 SD centiles. Levels beyond this range could indicate that something is wrong, for example, that the child has rapidly lost weight due to an illness. However, an extreme value could also signal a measurement error in the data. If that is the case, we often see that the intensity level for a subsequent fidel measurement is extreme in the other direction. Measurement error will manifest itself by rapidly changing directions. Finding a run of four visits in the same direction is exceptional and could indicate slow growth failure, especially when combined with sizeable intensities. For this child, all levels fall nicely in the horizontal band, so the variation in the curve is normal.
The last element looks like a flag with the wind coming from the East. The flag element is a mini-growth chart that visualises the prediction interval for the next 12 months as centile lines −2 SD, −1 SD, 0 SD (median), +1 SD and +2 SD. More precisely, we expect with a confidence of 95 per cent that the subsequent measurement for the child will be located within the range of −2 SD to +2 SD. Centile lines grow apart with age because predicting further in time is more error-prone. The prediction interval is initially wide because infant growth at these ages is highly variable. As time goes by, predictions will become more accurate.
All elements work together. For example, consider the middle-left chart when the child is three months old. The 95 per cent prediction interval of the (yet unobserved) WAZ at month 6 varies roughly between −1.3 SD and +1.1 SD (read off the flag at month 6). Three months later, the realised value is slightly above −1.0 SD. This value locates approximately halfway between the −1.0 and −2.0 flag centile lines. The central chart for month 6 adds the −1.4 SD level to the amplitude element (read-off amplitude between months 3 and 6). We can quickly gauge whether the value falls outside the −2.0 SD to +2.0 SD range. Note that we use the same reference band for evaluating distance and gain, but one may set these levels independently when required. The prediction interval is updated with the new data point, and the cycle repeats.
The graph contains more information than might be needed for some purposes. Depending on the intended user, we could alter various aspects of the design. For example, a bouncing amplitude element could feel uncomfortable for parents. We could replace it with a smiley for periods when the conditional SDS gain falls within preset bounds or show a question mark or a frown when outside. Also, we could tweak the flag centiles as more straightforward interquartile ranges or even show only the predicted value without indicating uncertainty. To enhance compliance, we could tightly shrink the flag’s width to an age interval around the next scheduled visit. Another possibility to communicate the inherent predictive uncertainty is to plot the realised curves of children with a similar predicted value, a technique known as curve matching (van Buuren Citation2014; Toet et al. Citation2019). Another idea is to apply a one-sample runs test (Siegel and Castellan Citation1988) to separate measurement error from biological variation in a more formal way.
Discussion
The generalisation of the conditional SDS gain to the complete historical data requires us to specify three model components: a longitudinal reference, a correlation model to deal with arbitrary time points, and a prediction model for individual child data. The text below discusses these choices and their interdependencies.
The longitudinal reference consists of a distance and a time component. Both can be estimated from the same data but may derive from different samples. Although any distance reference defines a transformation from raw measurements into -scores, an improper reference choice can bias predictions. Suppose that the references are too low, then regression to the mean is more forceful for taller or heavier children, which results in a prediction that is too low and an SDS gain that is too high. As a rule of thumb, we suggest that the
-score mean in the target sample should lie between −0.1 SD and +0.1 SD to prevent this bias.
The time component is a time-to-time correlation table. was estimated by assigning each -score to the closest scheduled age. This procedure is sub-optimal because it assumes that the correlation is constant within bins, which may not hold. Binning may reduce correlations, but we do not yet know by what amount and what the impact would be in practice. The use of specialised estimation methods, as proposed by Xiao et al. (Citation2018), Anderson et al. (Citation2019), and van Buuren (Citation2023) may improve upon simple binning. The Pearson correlation measures the strength between two normally distributed variables. Realise that applying a correlation for pairs of
-scores that systematically deviate from bivariate normality may fail to capture subtle effects in growth.
The primary function of the correlation model is to produce a correlation table per child between ages of measurement. We used the parametrisation of the Cole correlation model and estimated the parameters from our data. Other correlation models with applications in child growth can be found in Lesaffre et al. (Citation2000), Argyle et al. (Citation2008) and Feng et al. (Citation2020), and could potentially be used to improve the Cole model.
One striking result in is that including more historical data points hardly raises the proportion of explained variance . This finding is at variance with Ivanescu et al. (Citation2017), who concluded, “Prediction performance increases substantially when using the entire growth history relative to using only the last and first observation” and “Subtle changes in the subject-specific history contain substantial additional information.” In contrast, in our approach, the inclusion of additional time points had negligible effects on
. Regression weights vanished after conditioning on the last two observations. Adding more than two measurements had little effect on the predicted value and the conditional SDS gain. It is an open question whether these results hold more generally. One reason why prediction may not get more precise could be that the correlation model smoothes out meaningful relationships beyond lag 2. It would be interesting to investigate this hypothesis in more detail. Finding a correlation model directly from the source data (instead of compressing the dynamic information into the correlation matrix) could shed light on the issue.
There is not yet much experience with formal growth prediction in preventive settings. My vision is that prediction intervals can help practitioners set expectations, motivate healthy behaviours, and communicate the variability in human growth. The predictive model produces a personalised mini-chart for the child’s subsequent measurement. The current model returns the area that contains a single future observation. Depending on the setting, one may also construct intervals in which all future observations will lie or contain
out of
(Hahn and Meeker Citation1991).
The predictive model is fast. For a given person, the algorithm calculates the personalised correlation matrix, the regression weights, the prediction and the SDS gain for each measurement. On an M1 Max processor, the calculations for all children in the data () took 1.8 s, irrespective of the number of historical data points added. Thus, for a child with a growth curve of 10 measurements, we need about 1 millisecond to calculate the nine SDS gains.
A limitation of the current model is that it conditions only on previous outcomes. Including other time-varying outcomes or covariates (e.g. parental weights and heights, socio-economic factors) as predictors lead to sharper predictions. Technically, such extensions can be done in multiple ways. One straightforward possibility is to augment the time-to-time correlation matrix with the relevant factors.
The validation study revealed that the generalised conditional SDS gain has the expected statistical properties. show that the inclusion of the second last visit affects the value and interpretation of the conditional SDS gain. Cole (Citation1995) said: “Strictly speaking, weight is better predicted if more than one previous weight is used.” Our study found only a slight increase in the proportion of explained variance. Still, using all historical information produces more informative gain scores less impacted by measurement error. In order to benefit, we suggest including at least the last two historical measurements in the conditional SDS gain.
The paper used the distance references from the Fourth Dutch Growth Study and calculated the time-to-time correlation matrices
from the SMOCC data. Users from non-Dutch countries may want to use their national reference or adopt the WHO Child Growth Standards. For
, there are many options. However, only a few published estimates exist for
, so choices are minimal. We have yet to learn how
differs across child populations. The SMOCC study involved a large longitudinal sample from 0–2 years from the general population. For the time being, we suggest using
from as a replacement.
Tracking individual child growth sounds easier than it is. This paper provides the theory, algorithms and tools for assembling an extensible modular monitoring system from simple principles. Setting a distance reference, a time-to-time correlation matrix, and a correlation model is enough to capture the dynamic nature of child growth. The adaptive growth chart for individual tracking works with exact ages, corrects for regression to the mean, and has a known distribution at any pair of ages. These properties turn the methodology presented here into an ideal vehicle for evaluating and predicting child growth.
The adaptive growth chart proposed in the Applications section incorporates two novel graphical elements: amplitude and flag. Incorporating these elements into one display will contribute to well-informed decision-making for parents, health professionals, and researchers.
Acknowledgements
The author wishes to thank the collaborators from the Child Health Clinics of the SMOCC cohort study for their contributions to the data collection.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data used in this study are not public. The point of contact for the data is dr. Paul Verkerk (email: [email protected]).
Additional information
Funding
References
- Anderson C, Xiao L, Checkley W. 2019. Using data from multiple studies to develop a child growth correlation matrix. Stat Med. 38(19):3540–3554.
- Argyle J, Seheult A, Wooff D. 2008. Correlation models for monitoring child growth. Stat Med. 27(6):888–904.
- Beaton A. 1964. The use of special matrix operations in statistical calculus. Princeton, NJ: Educational Testing Service. Research Bulletin RB-64-51.
- Berkey C, Reed R, Valadian I. 1983. Longitudinal growth standards for preschool children. Ann Hum Biol. 10(1):57–67.
- Cameron N. 1980. Conditional standards for growth in height of British children from 5.0 to 15.99 years of age. Ann Hum Biol. 7(4):331–337.
- Cole T. 1995. Conditional reference charts to assess weight gain in British infants. Arch Dis Child. 73(1):8–16.
- Demets D, Lan K. 1994. Interim analysis: the alpha spending function approach. Stat Med. 13(13–14):1341–1352.
- Feng Y, Xiao L, Li C, Chen S, Ohuma E. 2020. Correlation models for monitoring fetal growth. Stat Methods Med Res. 29(10):2795–2813.
- Fredriks A, van Buuren S, Burgmeijer R, Meulmeester J, Beuker R, Brugman E, Roede M, Verloove-Vanhorick S, Wit J. 2000. Continuing positive secular growth change in The Netherlands 1955–1997. Pediatr Res. 47(3):316–323.
- Goodnight J. 1979. A tutorial on the sweep operator. Am Stat. 33(3):149–158.
- Hahn G, Meeker W. 1991. Statistical intervals: a guide for practitioners. New York: John Wiley & Sons.
- Healy M. 1974. Notes on the statistics of growth standards. Ann Hum Biol. 1(1):41–46.
- Herngreen W, van Buuren S, van Wieringen J, Reerink J, Verloove-Vanhorick S, Ruys J. 1994. Growth in length and weight from birth to 2 years of a representative sample of Netherlands children (born in 1988–89) related to socio-economic status and other background characteristics. Ann Hum Biol. 21(5):449–463.
- Ivanescu A, Crainiceanu C, Checkley W. 2017. Dynamic child growth prediction: a comparative methods approach. Stat Mod. 17(6):468–493.
- Lesaffre E, Todem D, Verbeke G, Kenward M. 2000. Flexible modelling of the covariance matrix in a linear random effects model. Biom J. 42(7):807–822.
- Osorio F, Ogueda A. 2022. fastmatrix: Fast computation of some matrices useful in statistics. R Package Version 0.4-124. https://CRAN.R-project.org/package=fastmatrix
- Pan H, Goldstein H. 1997. Multi-level models for longitudinal growth norms. Stat Med. 16(23):2665–2678.
- Scherdel P, Dunkel L, van Dommelen P, Goulet O, Salaün JF, Brauner R, Heude B, Chalumeau M. 2016. Growth monitoring as an early detection tool: a systematic review. Lancet Diabetes Endocrinol. 4(5):447–456.
- Siegel S, Castellan N.Jr 1988. Nonparametric statistics for the behavioral sciences. 2nd ed. New York, USA: McGraw-Hill Book Company.
- Tanner J. 1990. Foetus into man: physical growth from conception to maturity. 2nd ed. Cambridge, MA: Harvard University Press.
- Thompson M, Fatti L. 1997. Construction of multivariate centile charts for longitudinal measurements. Stat Med. 16(4):333–345.
- Toet A, van Erp J, Boertjes E, van Buuren S. 2019. Graphical uncertainty representa- tions for ensemble predictions. Inf Vis. 18(4):373–383.
- van Buuren S. 2014. Curve matching: a data-driven technique to improve individual prediction of childhood growth. Ann Nutr Metab. 65(3):227–233.
- van Buuren S. 2023. Broken stick model for irregular longitudinal data. J Stat Softw. 106(7):1–51.
- Wright C, Matthews J, Waterston A, Aynsley-Green A. 1994. What is a normal rate of weight gain in infancy. Acta Paediatr. 83(4):351–356.
- Xiao L, Li C, Checkley W, Crainiceanu C. 2018. Fast covariance estimation for sparse functional data. Stat Comput. 28(3):511–522.