
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Insurance pricing systems should fulfill the auto-calibration property to ensure that there is no systematic cross-financing between different price cohorts. Often, regression models are not auto-calibrated. We propose to apply isotonic recalibration to a given regression model to restore auto-calibration. Our main result proves that under a low signal-to-noise ratio, this isotonic recalibration step leads to an explainable pricing system because the resulting isotonically recalibrated regression function has a low complexity.
1. Introduction
There are two seemingly unrelated problems in insurance pricing that we are going to tackle in this paper. First, an insurance pricing system should not have any systematic cross-financing between different price cohorts. Systematic cross-financing implicitly means that some parts of the portfolio are under-priced, and this is compensated by other parts of the portfolio that are over-priced. We can prevent systematic cross-financing between price cohorts by ensuring that the pricing system is auto-calibrated. We propose to apply isotonic recalibration which turns any regression function into an auto-calibrated pricing system.
The second problem that we tackle is the explainability of complex algorithmic models for insurance pricing. In a first step, one may use any complex regression model to design an insurance pricing system such as, e.g. a deep neural network. Such complex regression models typically lack explainability and rather act as black boxes. For this reason, there are several post-hoc tools deployed to explain such complex solutions, we mention, for instance, SHAP by Lundberg & Lee (Citation2017), see also Mayer et al. (Citation2023). Since algorithmic solutions do not generally fulfill the aforementioned auto-calibration property, we propose to apply isotonic recalibration to the algorithmic solution. If the signal-to-noise ratio is low in the data, then the isotonic recalibration step leads to a coarse partition of the covariate space and, as a consequence, it leads to an explainable version of the algorithmic model used in the first place. Thus, explainability is a nice side result of applying isotonic recalibration in a low signal-to-noise ratio situation, which is typically the case in insurance pricing settings.
There are other methods for obtaining auto-calibration through a recalibration step; we mention the tree binning approach of Lindholm et al. (Citation2023) and the local regression approach of Loader (Citation1999) considered in Denuit et al. (Citation2021). These other methods often require tuning of hyperparameters, e.g. using cross-validation. Isotonic recalibration does not involve any hyperparameters as it solves a constraint regression problem (ensuring monotonicity). As such, isotonic recalibration is universal because it also does not depend on the specific choice of the loss function within the family of Bregman losses, and it is scale invariant w.r.t. the first regression as it only uses the ranks of the first regression.
We formalize our proposal. Throughout, we assume that all considered random variables have finite means. Consider a response variable Y that is equipped with covariate information . The general goal is to determine the (true) regression function
that describes the conditional mean of Y, given
. Typically, this true regression function is unknown, and it needs to be determined from i.i.d. data
, that is, a sample from
. For this purpose, we try to select a regression function
from a (pre-chosen) function class on
that approximates the conditional mean
as well as possible. Often, it is not possible to capture all features of the regression function from data. In financial applications, a minimal important requirement for a well-selected regression function
is that it fulfills the auto-calibration property.
Definition 1.1
The regression function μ is auto-calibrated for if
Auto-calibration is an important property in actuarial and financial applications because it implies that, on average, the (price) cohorts are self-financing for the corresponding claims Y, i.e. there is no systematic cross-financing within the portfolio, if the structure of this portfolio is described by the covariates
and the price cohorts
, respectively. In a Bernoulli context, an early version of auto-calibration (called well-calibrated) has been introduced by Schervish (Citation1989), and recently, it has been considered in detail by Gneiting & Resin (Citation2022). In an actuarial and financial context, the importance of auto-calibration has been emphasized in Krüger & Ziegel (Citation2021), Denuit et al. (Citation2021), Lindholm et al. (Citation2023) and Wüthrich (Citation2023).
Many regression models do not satisfy the auto-calibration property. However, there is a simple and powerful method, which we call isotonic recalibration, to obtain an (in-sample) auto-calibrated regression function starting from any candidate function . We apply isotonic recalibration to the pseudo-sample
to obtain an isotonic regression function
. Then,
(1.1)
(1.1) where
is distributed according to the empirical distribution
of
; see Section 2.1 for details. Isotonic regression determines an adaptive partition of the covariate space
, and
is determined by averaging y-values over the partition elements. Clearly, other binning approaches can also be used on the pseudo-sample
to enforce (Equation1.1
(1.1)
(1.1) ), but we argue that isotonic regression is preferable since it avoids subjective choices of tuning parameters and leads to sensible regression functions under reasonable and verifiable assumptions. The only assumption for isotonic recalibration to be informative is that the function π gets the rankings of the conditional means right, that is, whenever
, we would like to have
; we will justify this in more detail in the first paragraph of Section 3.1, below.
Using isotonic regression for recalibration is not new in the literature. In the case of binary outcomes, it has already been proposed by Zadrozny & Elkan (Citation2002), Menon et al. (Citation2012) and recently by Tasche (Citation2021, Section 5.3). The monotone single index models of Balabdaoui et al. (Citation2019) follow the same strategy as described above but the focus of their work is different from ours. They specifically consider a linear regression model for the candidate function π, which is called the index. In the case of distributional regression, that is, when interest is in determining the whole conditional distribution of Y given covariate information , Henzi et al. (Citation2023) have suggested to first estimate an index function π that determines the ordering of the conditional distributions w.r.t. first order stochastic dominance and then estimate conditional distributions using isotonic distributional regression; see Henzi et al. (Citation2021).
As a new contribution, we show that the size of the partition of the isotonic recalibration may give insight concerning the information content of the recalibrated regression function . Furthermore, the partition of the isotonic recalibration allows to explain connections between covariates and outcomes, in particular, when the signal-to-noise ratio is small which typically is the case for insurance claims data.
In order to come up with a candidate function , one may consider any regression model such as, e.g. a generalized linear model, a regression tree, a tree boosting regression model or a deep neural network regression model. The aim is that
provides us with the correct rankings of the conditional means
,
. Moreover, this first candidate function
can be estimated on the original response scale or on any monotonically transformed scale, e.g. logged insurance losses, as long as we get the rankings correct. The latter may be an attractive option to limit the influence of outliers on the estimation of the candidate function. The details are discussed in Section 3.
Organization. In Section 2, we formally introduce isotonic regression which is a constraint optimization problem. This constraint optimization problem is usually solved with the pool adjacent violators (PAV) algorithm, which is described in Appendix A.1. Our main result is stated in Section 2.2. It relates the complexity of the isotonic recalibration solution to the signal-to-noise ratio in the data. Section 3 gives practical guidance on the use of isotonic recalibration, and in Section 4 we exemplify our results on a frequently used insurance dataset. In this section we also present graphic tools for interpreting the regression function. In Section 5, we conclude.
2. Isotonic regression
2.1. Definition and basic properties
For simplicity, we assume that the candidate function does not lead to any ties in the values
, and that the indices
are chosen such that they are aligned with the ranking, that is,
. Remark 2.1 explains how to handle ties. The isotonic regression of
with positive case weights
is the solution
to the restricted minimization problem
(2.1)
(2.1) This problem has a unique solution; see Barlow & Brunk (Citation1972, Theorem 2.1). We can rewrite the side constraints as
(component-wise), where
is the matrix with the elements
. We define
and the (diagonal) case weight matrix
. The above optimization problem then reads as
(2.2)
(2.2) This shows that the isotonic regression is solved by a convex minimization with linear side constraints. It remains to verify that the auto-calibration property claimed in (Equation1.1
(1.1)
(1.1) ) holds.
Remark 2.1
If there are ties in the values , for example,
for some
, we replace
and
with their weighted average
and assign them weights
. The procedure is analogous for more than two tied values. This corresponds to the second option of dealing with ties in de Leeuw et al. (Citation2009, Section 2.1).
Remark 2.2
Barlow et al. (Citation1972, Theorem 1.10) show that the square loss part in (Equation2.1
(2.1)
(2.1) ) can be replaced by any Bregman loss,
, without changing the optimal solution
. Here, ϕ is a strictly convex function with subgradient
. Bregman losses are the only strictly consistent loss functions for mean estimation; see Savage (Citation1971) and Gneiting (Citation2011, Theorem 7). For claims count modeling, a Bregman loss of relevance for this paper is the Poisson deviance loss, which arises by choosing
,
.
The solution to the minimization problem (Equation2.3(2.2)
(2.2) ) can be given explicitly as a min-max formula
While the min-max formula is theoretically appealing and useful, the related minimum lower sets (MLS) algorithm of Brunk et al. (Citation1957) is not efficient to compute the solution. The pool adjacent violators (PAV) algorithm, which is due to Ayer et al. (Citation1955), Miles (Citation1959) and Kruskal (Citation1964), allows for fast computation of the isotonic regression and provides us with the desired insights about the solution. In Appendix A.1, we describe the PAV algorithm in detail. The solution is obtained by suitably partitioning the index set
into (discrete) intervals
(2.3)
(2.3) with
-dependent slicing points
, and with
denoting the number of discrete intervals
. The number
of intervals and the slicing points
,
, for the partition of
depend on the observations
. On each discrete interval
we then obtain the isotonic regression parameter estimate, i.e. for an instance
we have
(2.4)
(2.4) see also (EquationA5
(A5)
(A5) ). Thus, on each block
we have a constant estimate
, and the isotonic property tells us that these estimates are strictly increasing over the block indices
, because these blocks have been chosen to be maximal. We call
the complexity number of the resulting isotonic regression.
Figure gives an example for n = 20 and rankings for
. The resulting (non-parametric) isotonic regression function
, which is only uniquely determined at the observations
, can be interpolated by a step function. In Figure this results in a step function having
steps, that is, we have
blocks, and the estimated regression function
takes only
different values. This motivates to call
the complexity number of the resulting step function.
Figure 1. Example of an isotonic regression with blocks, the x-axis shows the ranks
and the y-axis the resulting isotonic regression estimates
connected by a step function (in red color).
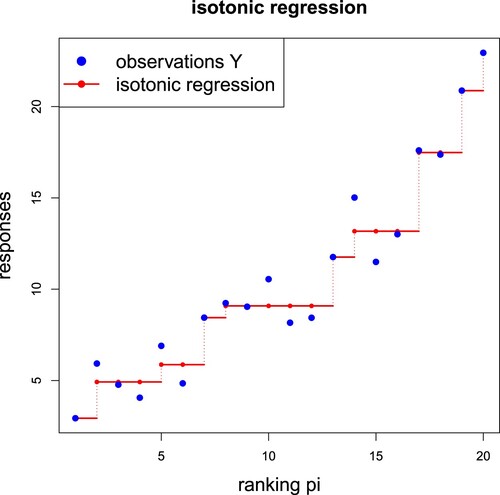
The partition of the indices into the isotonic blocks
is obtained naturally by requiring monotonicity. This is different from the regression tree approach considered in Lindholm et al. (Citation2023). In fact, this latter reference does not require monotonicity but aims at minimizing the ‘plain’ square loss using cross-validation for determining the optimal number of partitions. In our context, the complexity number
is fully determined through requiring monotonicity and, in general, the results will differ.
In insurance applications, the blocks provide us with the (empirical) price cohorts
, for
, and (Equation2.4
(2.4)
(2.4) ) leads to the (in-sample) auto-calibration property for Y
(2.5)
(2.5) where
is distributed according to the weighted empirical distribution of
with weights
, see also (Equation1.1
(1.1)
(1.1) ). Moreover, summing over the entire portfolio we have the (global) balance property
(2.6)
(2.6) that is, in average the overall (price) level is correctly specified if we price the insurance policies with covariates
by
, where the weights
now receive the interpretation of exposures.
2.2. Monotonicity of the expected complexity number
In this section, we prove that the expected complexity number is an increasing function of the signal-to-noise ratio. For this, we assume a location-scale model for the responses
, that is, we assume that
(2.7)
(2.7) with noise terms
, location parameters
with
, and scale parameter
. Here,
takes the role of
in the previous section. The parameters
are unknown but it is known that they are labeled in increasing order. The signal-to-noise ratio is then described by the scale parameter σ, i.e. we have a low signal-to-noise ratio for high σ and vice-versa. The explicit location-scale structure (Equation2.7
(2.7)
(2.7) ) allows us to analyze
(2.8)
(2.8) point-wise in the sample points
of the probability space
as a function of
; this is similar to the re-parametrization trick of Kingma & Welling (Citation2019) that is frequently used to explore variational auto-encoders.
In this section, we write , because the ranking of the outcomes
is clear from the context (labeling), and we do not go via a ranking function
.
Theorem 2.3
Assume that the responses ,
, follow the location-scale model (Equation2.7
(2.7)
(2.7) ) with (unknown) ordered location parameters
, and scale parameter
. Then, the expected complexity number
of the isotonic regression of
is a decreasing function in
. If the distribution of the noise vector
has full support on
, then
is strictly decreasing in σ.
Theorem 2.3 proves that, under a specific but highly relevant model, the complexity number of the isotonic regression is decreasing on average with a decreasing signal-to-noise ratio. Implicitly, this means that more noisy data, which has a lower information ratio, leads to a less granular regression function. Consequently, if the partition of the isotonic regression is used to obtain a partition of the covariate space
via the candidate function π, this partition will be less granular, the more noise of
cannot be explained by
. Remark that ‘explain’ has different meanings in machine learning and in statistics. In statistics, a regression function explains part of the uncertainty in the response variable, also called resolution or discrimination in Murphy's score decomposition (Murphy Citation1973); see Gneiting & Resin (Citation2022, Theorem 2.23). In our case, a regression function that poorly explains the variability of the response, leads to explainability of the regression function itself by a low complexity partitioning of the covariate space.
To the best of our knowledge, our result is a new contribution to the literature on isotonic regression. While we focus on the finite sample case, a related result studies the complexity number of the isotonic regression function as function of the sample size n, see Dimitriadis et al. (Citation2022, Lemma 3.2). The complexity number is also related to the effective dimension of the model, and has been studied under the assumption of independent Gaussian errors in (Equation2.7(2.7)
(2.7) ) in Meyer & Woodroofe (Citation2000) and Tibshirani et al. (Citation2011).
We are assuming strictly ordered location parameters in the formulation of Theorem 2.3. This assumption simplifies the proof in the case where we show that the expected complexity number
is strictly decreasing in σ. With some additional notation, the theorem could be generalized to allow for ties between some (but not all)
.
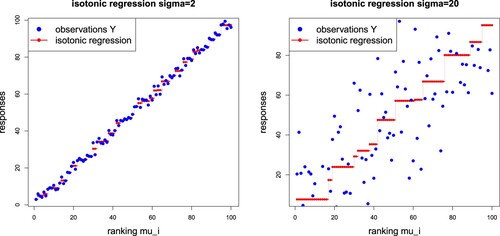
Figure gives an example of a location-scale model (Equation2.7(2.7)
(2.7) ) with i.i.d. standard Gaussian noise and scale parameters
(lhs) and
(rhs), and both figures consider the same sample point
in the noise term
, see (Equation2.8
(2.8)
(2.8) ). On the left-hand side of Figure , we have complexity number
, and on the right-hand side
; the chosen sample size is n = 100.
Figure 2. Example of an isotonic regression of location-scale type with varying signal-to-noise ratio for the identical sample point : (lhs)
with
and (rhs)
with
.
3. Isotonic recalibration for prediction and interpretation
3.1. Estimation and prediction
To determine an auto-calibrated estimate of the true regression function from i.i.d. data
, we are suggesting a two-step estimation procedure. First, we use the data
to obtain an estimate
of a candidate function π that should satisfy
(3.1)
(3.1) for all
. This first step is motivated by the fact that the true regression function
is auto-calibrated and satisfies,
-a.s.,
As a consequence, requirement (Equation3.1
(3.1)
(3.1) ) gives strict comonotonicity between
and
, that is,
-a.s.,
for a strictly increasing function T.
In a second step, we aim at finding this monotone transformation T. We therefore apply isotonic regression (rank-preserving) to the pseudo-sample to obtain the in-sample auto-calibrated regression function
defined on
. We call this second step isotonic recalibration, and this isotonically recalibrated version
of
not only satisfies auto-calibration (Equation1.1
(1.1)
(1.1) ), but it is also an approximation to the true regression function
, i.e.
; for a related statement in a binary classification context we refer to Tasche (Citation2021, Proposition 3.6). In our case study in Section 4, below, a deep neural network model is chosen for estimating the ranks π.
In order to obtain a prediction for a new covariate value , we compute
, find i such that
, and interpolate by setting
. This interpolation may be advantageous for prediction. For interpretation and analysis, however, we prefer a step function interpolation as this leads to a partition of the covariate space, see Section 3.3, below, and Figure .
Summarizing, the proposed two-step estimation procedure first aims at getting the ranks right, see (Equation3.1
(3.1)
(3.1) ). Based on a correct ranking, isotonic recalibration lifts these ranks to the right level using that the true regression function
is a monotone transformation of the correct ranks
, and, thus, the isotonically recalibrated ranks
provide an approximation to the true regression function
. A way to verify the rank property (Equation3.1
(3.1)
(3.1) ) is to maximize the Gini score; we refer to Wüthrich (Citation2023). A first regression function
may not be auto-calibrated, but since the Gini score is invariant under strictly increasing transformations, maximizing the Gini score is still a valid procedure, if one isotonically recalibrates this first regression function
. As a consequence, isotonic recalibration gives a Gini score preserving transformation that provides the auto-calibrated counterpart of the first regression function. Using the uniqueness part of Theorem 4.3 of Wüthrich (Citation2023) then says that this auto-calibrated version
is a valid approximation to the true regression function. This justifies the isotonic recalibration procedure under (Equation3.1
(3.1)
(3.1) ), and it is the general regression version of the binary case presented in Menon et al. (Citation2012).
This two-step estimation approach can also be interpreted as a generalization of the monotone single index models considered by Balabdaoui et al. (Citation2019). They assume that the true regression function is of the form , with an increasing function ψ. In contrast to our proposal, the regression model π is fixed to be a linear model
in their approach. They consider global least squares estimation jointly for
, but find it computationally intensive. As an alternative they suggest a two-step estimation procedure similar to our approach with a split of the data such that
and the isotonic regression are estimated on independent samples. They find that if the rate of convergence of the estimator for
is sufficiently fast, then the resulting estimator of the true regression function is consistent with a convergence rate of order
.
In a distributional regression framework, Henzi et al. (Citation2023) considered the described two-step estimation procedure with an isotonic distributional regression, instead of a classical least squares isotonic regression as described in Section 2.1. They show that in both cases, with and without sample splitting, the procedure leads to consistent estimation of the conditional distribution of Y, given , as long as the index π can be estimated at a parametric rate. The two options, with and without sample splitting, do not result in relevant differences in predictive performance in the applications considered by Henzi et al. (Citation2023).
Assumption (Equation3.1(3.1)
(3.1) ) can also be checked by diagnostic plots using binning similarly to the plots in Henzi et al. (Citation2023, Figure ) in the distributional regression case, such plots are also called lift plots in actuarial practice. Predictive performance should be assessed on a test set of data disjoint from
, that is, on data that has not been used in the estimation procedure at all. Isotonic recalibration ensures auto-calibration in-sample, and under an i.i.d. assumption, auto-calibration will also hold approximately out-of-sample. Out-of-sample auto-calibration can be diagnosed with CORP (consistent, optimally binned, reproducible and PAV) mean reliability diagrams as suggested by Gneiting & Resin (Citation2022), and comparison of predictive performance can be done with the usual squared error loss function or with deviance loss functions.
3.2. Over-fitting at the boundary
There is a small issue with the isotonic recalibration, namely, it may tend to over-fit at the lower and upper boundaries of the ranks . For instance, if
is the largest observation in the portfolio (which is not unlikely since the ranking
is chosen response data-driven), then we estimate
, where
. Often, this over-fits to the (smallest and largest) observations, as such extreme values/estimates cannot be verified on out-of-sample data. For this reason, we visually analyze the largest and smallest values in the estimates
, and we manually merge, say, the smallest block
with the second smallest one
(with the resulting estimate (Equation2.4
(2.4)
(2.4) ) on the merged block). More rigorously, this pooling could be cross-validated on out-of-sample data, but we refrain from doing so. In our examples in Section 4.1, below, we merge the two blocks with the smallest/biggest estimates.
3.3. Interpretation
In (Equation2.3(2.3)
(2.3) ) we have introduced the complexity number
that counts the number of different values in
, obtained by the isotonic regression (Equation2.2
(2.2)
(2.2) ) in the isotonic recalibration step. This complexity number
allows one to assess the information content of the model, or in other words, how much signal is explainable from the data. Theorem 2.3 shows that the lower the signal-to-noise ratio, the lower the complexity number of the isotonic regression that we can expect. Clearly, in Theorem 2.3 we assume that the ranking of the observations is correct which will only be approximately satisfied since π has to be estimated. In general, having large samples and flexible regression models for modeling π, it is reasonable to assume that the statement remains qualitatively valid. However, in complex (algorithmic) regression models, we need to ensure that we prevent from in-sample over-fitting; this is typically controlled by either using (independent) validation data or by performing a cross-validation analysis.
Typical claims data in non-life insurance have a low signal-to-noise ratio. Regarding claims frequencies, this low signal-to-noise ratio is caused by the fact that claims are not very frequent events, e.g. in car insurance annual claims frequencies range from 5% to 10%, that is, only one out of 10 (or 20) drivers suffers a claim within a calendar year. A low signal-to-noise ratio also applies to claim amounts, which are usually strongly driven by randomness and the explanatory part from policyholder information is comparably limited. Therefore, we typically expect a low complexity number both for claims frequency and claim amounts modeling. This low signal-to-noise ratio in actuarial modeling is also a reason for exploiting new sources of information such as telematics data, see, e.g. Peiris et al. (Citation2023), or images, see, e.g. Blier-Wong & Lamontagne (Citation2022).
In case of a small to moderate complexity number , the regression function
becomes interpretable through the isotonic recalibration step. For this, we extend the auto-calibrated regression function
from the set
to the entire covariate space
by defining a step function
for all
, where
are the slicing points of the isotonic regression as defined in (Equation2.3
(2.3)
(2.3) ). Figure illustrates this step function interpolation. We define a partition
of the original covariate space
by
(3.2)
(3.2) Figure , below, illustrates how this partition of
provides insights on the covariate-response relationships in the model. This procedure has some analogy to regression trees and boosting trees that rely on partitions of the covariate space
. In the case study in Section 4, we illustrate two further possibilities to use the partition defined at (Equation3.2
(3.2)
(3.2) ) for understanding covariate-response relationships. First, in Figure , the influence of individual covariates on the price cohorts is analyzed, and second, Figure gives a summary view of the whole covariate space for a chosen price cohort.
Figure 3. Isotonic recalibration in the French MTPL example only using DrivAge and BonusMalus as covariates resulting in the complexity number ; the x-axis shows the estimated ranks
and the y-axis the resulting isotonic regression estimates
using a step function (in red color) on
.
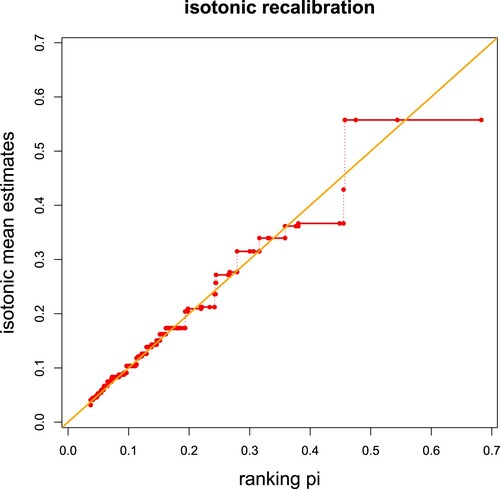
Figure 4. Estimated expected claims frequencies : (lhs) isotonically recalibrated FFNN regression and (rhs) binary regression tree, both only using DrivAge and BonusMalus as covariates; the color scale shows the expected frequencies, this color scale is the same in both plots.
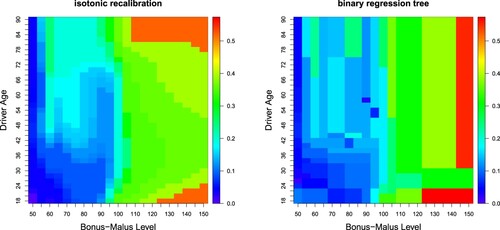
Figure 5. (top-left) Isotonic recalibration, (top-right) regression tree recalibration with 17 leaves, (bottom) local regression recalibration with nearest neighbor fractions (lhs and rhs); these graphs show how the different recalibration methods change the first FFNN predictions.
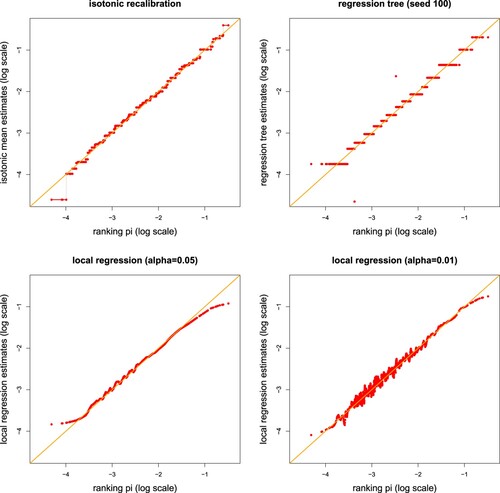
Figure 6. Marginal view of the isotonically recalibrated FFNN predictions (line (2) of Table ) of the considered covariate components (top) DrivAge, Area, VehPower, (middle) VehAge, BonusMalus, VehGas, (bottom) VehBrand, Region; the K = 77 colors show the distribution of the estimates on all levels of the considered covariates.
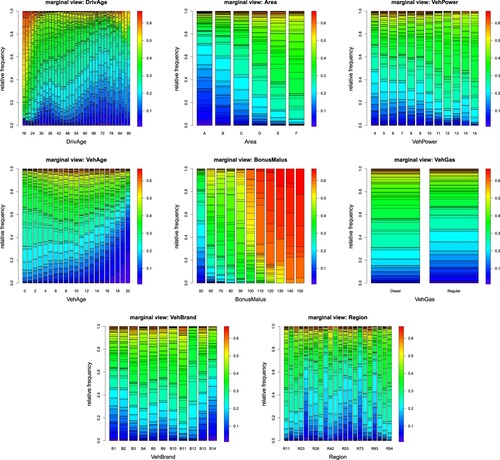
Figure 7. Partition of the covariate space
w.r.t. the isotonic recalibration; the complexity number K = 77 induces 77 different expected frequencies illustrated by the colors at the right-hand side of the plots. The lines and dots illustrate the covariate combinations that lead to these expected frequencies for three selected values of k = 2, 45, 77 (top-middle-bottom).
4. Motor third party liability claims frequency example
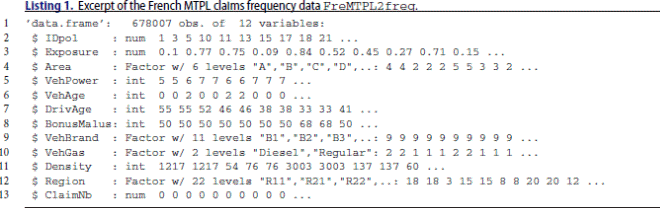
We consider the French motor third party liability (MTPL) claims frequency data FreMTPL2freq, available through the R package CASdatasets (Dutang & Charpentier Citation2018). This is a frequently studied dataset that has been considered, e.g. in Lindholm et al. (Citation2023) and Denuit et al. (Citation2021). For an exploratory analysis of this data set we refer to Wüthrich & Merz (Citation2023, Chapter 13). For our analysis we use the same data cleaning as described in Wüthrich & Merz (Citation2023, Listing 13.1), an excerpt of the cleaned data is given in Listing 1.
We have insurance policies which have been exposed within the same accounting year and for which we have claims records and covariate information, see Listing 1. Our goal is to build a neural network regression model for pricing and prediction, and we use isotonic recalibration for auto-calibration and interpretation as described in Section 3.3. To make our analysis directly comparable to the one in Wüthrich & Merz (Citation2023), we partition the available sample into a learning sample
and a test sample
precisely as described in Wüthrich & Merz (Citation2023, Listing 5.2). A summary statistics of the resulting learning and test samples is given in Wüthrich & Merz (Citation2023, Table 5.2). For model fitting and the isotonic recalibration step we only use the learning sample
. All models are then evaluated out-of-sample on the test sample
, and these out-of-sample results are directly comparable, e.g. to Wüthrich & Merz (Citation2023, Table 7.10), because we use the identical test sample
.
We remark that in the present study we consider the time exposures as known information for claims frequency modeling. Lindholm et al. (Citation2023) raise the problem of having random time exposures, e.g. caused by early terminations of insurance policies. In some sense, early terminations contaminate claims data which needs a proper statistical treatment for predictive modeling. However, to be able to focus our discussion on isotonic recalibration, we do not discuss and model uncertainties coming from random time exposures here, but we refer to Lindholm et al. (Citation2023) for an in-depth treatment.
4.1. Isotonic recalibration and binary regression trees
We start by considering the two covariate components DrivAge and BonusMalus only. Since the resulting covariate space is two-dimensional, we can illustrate graphically the differences between the isotonic recalibration approach and a binary regression tree (as a competing model for interpretation). In Section 4.2, below, we consider all available covariates for a competitive predictive model.
We fit a deep feed-forward neural network (FFNN) regression model to the learning sample . We choose a network architecture of depth 3 with
neurons in the three hidden layers, the hyperbolic tangent activation function in the hidden layers, and the log-link for the output layer. The input has dimension 2, this results in a FFNN architecture with a network parameter of dimension 546; for a detailed discussion of FFNNs we refer to Wüthrich & Merz (Citation2023, Chapter 7), in particular, to Listings 7.1–7.3 of that reference. We fit this model using the Poisson deviance loss, see Remark 2.2 and Wüthrich & Merz (Citation2023, Section 5.2.4), we use the nadam version of stochastic gradient descent. We exercise early stopping on a validation set being 10% of the learning sample
, and we ensemble over ten different network calibrations to reduce the randomness of individual stochastic gradient descent network fits, see Wüthrich & Merz (Citation2023, Section 7.4.4). Line (1) of Table , called ‘FFNN ensemble’, shows the performance of the fitted FFNN regression model ensemble. This is compared to the null model (empirical mean) on line (0) that does not consider any covariates. We observe a decrease in Poisson deviance loss which justifies the use of a regression model. The last column of Table , called ‘average frequency’, compares the average frequency estimate of the FFNN ensemble on
to its empirical mean, and we observe a negative bias in the FFNN prediction, i.e.
, thus, these network estimates under-price the portfolio.
Table 1. Loss figures in the French MTPL example only considering DrivAge and BonusMalus; Poisson deviance losses in .
Table 2. Loss figures in the French MTPL example using all covariates; Poisson deviance losses in .
In the next step, we use the FFNN estimates as ranks for ordering the claims
and the covariates
, respectively. Note that these ranks
correspond to expected frequencies which still need to be multiplied by the time exposures
to receive the expected number of claims; these time exposures
are given on line 3 of Listing 1. Therefore, we perform isotonic recalibration on the observed frequencies for
. These observed frequencies
are obtained by dividing the claim counts, line 13 of Listing 1, by the time exposures, line 3 of Listing 1. Then, the isotonic recalibration step is performed by solving the constraint weighted square loss minimization problem (Equation2.1
(2.1)
(2.1) ) and (Equation2.2
(2.2)
(2.2) ), respectively. We use the R package monotone (Busing Citation2022), which provides a fast implementation of the PAV algorithm; in fact, this optimization step takes much less than one second on an ordinary laptop. The numerical results are presented on line (2) of Table . We observe that this isotonic recalibration leads to a complexity number
, i.e. we receive a partition into 49 different expected frequencies to represent the isotonically recalibrated FFNN predictor. The out-of-sample loss on
is slightly increased by this isotonic calibration step, which may indicate that the ranks of the FFNN prediction could be improved. On the other hand, we now have the auto-calibration property (Equation1.1
(1.1)
(1.1) ) and the global balance property on
, as can be seen from the last column of Table .
Figure provides the resulting step function from the isotonic recalibration (in red color) of the ranking given by the FFNN ensemble. The isotonic recalibration has been performed on
, and Figure shows the results out-of-sample on
. From this figure it is not directly observable why the global balance property does not hold in the first place, as the isotonic recalibration is fairly concentrated around the diagonal orange line.
The isotonic recalibration on the ranks of the FFNN leads to a partition
of the covariate space as defined in (Equation3.2
(3.2)
(3.2) ). We compare this partition to the one that results from a binary split regression tree approach (with Poisson deviance loss). We use 10-fold cross-validation to determine the optimal tree size. In this example the optimal tree has 60 splits and, hence, 61 leaves. The resulting losses of this optimal tree are shown on line (3) of Table . We observe that this tree has a worse out-of-sample performance on
than the isotonically recalibrated version, line (2). The binary regression tree uses a finer partition of the covariate space for this result, 61 leaves vs. complexity number K = 49. Figure which shows the resulting partitions (the color scale illustrates the estimated expected claims frequencies). We observe that binary splitting along the covariate axis may not be sufficiently flexible (the binary tree only has vertical and horizontal splits, see Figure , rhs), whereas the isotonically recalibrated version indicates a more complex topology with diagonal splits, see Figure (lhs).
Finally, we remark that the binary tree does not (exactly) fulfill the global balance property, , see last column of Table . This comes from the fact that the Poisson binary tree implementation in the R package rpart uses a Bayesian version for frequency estimation to avoid leaves with an expected frequency estimate of zero; see Therneau & Atkinson (Citation2022). In our isotonic recalibration approach, this is avoided by merging the two blocks with the smallest estimates, see Section 3.2.
4.2. Consideration of all covariates
In this section, we consider all available covariate components, see lines 4–12 of Listing 1. We first fit an ensemble of ten FFNNs to the learning sample . This is done exactly as in the previous section with the only difference that the input dimension changes when we consider all available information. We use the same covariate pre-processing as in Wüthrich & Merz (Citation2023, Example 7.10). That is, we transform the (ordered) Area code to real values, and we use embedding layers of dimension two for the two categorical covariates VehBrand and Region. The FFNN receives a network parameter of dimension 792. The FFNNs are fitted with stochastic gradient descents that are early stopped based on a validation set of 10% of the learning sample
. The results are presented on line (1) of Table .
We compare the FFNN prediction to the null model (empirical mean), the FFNN prediction with reduced covariates given in Table , and the GLM and network predictors given in Wüthrich & Merz (Citation2023, Tables 5.5 and 7.9). The out-of-sample Poisson deviance losses are directly comparable between all these examples because we use the identical test sample . In view of these results, we conclude that the FFNN ensemble on line (1) of Table (with an out-of-sample loss of 23.784) is highly competitive because it has roughly the same out-of-sample loss as the best predictor in the aforementioned examples/tables.
Our main concern is the auto-calibration property (Equation1.1(1.1)
(1.1) ) and the global balance property (Equation2.6
(2.6)
(2.6) ). We study this on the learning sample
, and in view of the last column of Table , we conclude that the FFNN predictor on line (1) severely under-estimates the average frequency,
, and auto-calibration fails to hold here.
In the next step, we use the FFNN prediction as ranks for ordering the responses and covariates, and we label the claims
such that
; ties are aggregated as described in Remark 2.1. We then isotonically recalibrate
on the learning sample
. Figure (top-left) shows how the isotonic recalibration step changes the original FFNN predictions (x-axis, on log scale) to their isotonically recalibrated version (y-axis, on log scale). The isotonic recalibration compresses the 581,272 different values of the FFNN predictions to a complexity number of
. Thus, the entire regression problem is encoded (binned) into 77 different estimates
,
. In view of Figure (top-left), the isotonic recalibration step provides heavier lower and upper tails, and this could also be a sign of over-fitting. This isotonically recalibrated regression is empirically auto-calibrated (Equation2.5
(2.5)
(2.5) ) on
and, henceforth, it fulfills the global balance property, see last column of line (2) in Table . The resulting out-of-sample loss on
of 23.800 is slightly worse than the one on line (1) but it is the best of all recalibration methods considered.
We compare the isotonic recalibration results to other recalibration methods, namely, the regression tree binning proposal of Lindholm et al. (Citation2023), and the local regression proposal of Denuit et al. (Citation2021). Both of these methods need hyperparameter tuning which is in contrast to isotonic recalibration. We start with the regression tree recalibration proposed by Lindholm et al. (Citation2023), which aims at finding an optimal binning of the the ranks using a regression tree predictor. If one would not aim for binning the ranks optimally, but just considered binning, e.g. using empirical deciles, this would result in a
-test situation similar to Hosmer & Lemeshow (Citation1980). For an optimal regression tree binning, we use 10-fold cross-validation on
with the Poisson deviance loss to receive the optimal number of leaves (bins). A further hyperparameter involved is the minimal leaf size, i.e. the required minimal number of instances in each leaf of the regression tree. A comparably small minimal leaf size seems advantageous, and we choose
. Intuitively, this is motivated by the fact that we have ranks
that should respect monotonicity in the true expected frequencies. I.e. though we do not rely on a restricted (isotonic) regression in this tree binning approach, we expect a similar behavior as in the isotonic recalibration because the binary tree splits use this ordering for exploring the best possible splits. If we run 10-fold cross-validation on this configuration, we select an optimal tree size having 17 leaves; there are small variations in this choice because 10-fold cross-validation involves some randomness from the random choice of the folds. The results are presented on line (3) of Table and Figure (top-right).
This tree binning recalibration approach results in a comparably small model, only having 17 leaves, and, in view of Table , we have a slightly bigger out-of-sample loss. Interestingly, the regression tree predictor illustrated in Figure (top-right) is not (completely) monotone in the ranks, but there seem to be two outlier bins. There are different explanations for this observation, namely, these outlier bins might be driven by the fact that we have chosen a minimal leaf size that is too small which implies that the irreducible risk (random noise) has a bigger impact on the binary tree splitting, but it could also indicate that the initial ranking of the FFNN predictor is not fully correct in this part of the covariate space. Finally, from the last column of Table we observe that the tree recalibration approach has the global balance property, see line (3); subject to the explanation at the end of Section 4.1 on how rpart treats zeros in predictions; see also Therneau & Atkinson (Citation2022).
The recalibration proposal of Denuit et al. (Citation2021) is based on a local regression; see Loader (Citation1999). This local regression can be interpreted as a local kernel smoothing. Since we use the same data as Denuit et al. (Citation2021), we choose the same configuration for this local regression recalibration as in Denuit et al. (Citation2021, Section 6.1), i.e. based on the R package locfit Loader (Citation1999), we perform a local regression of degree 0 with a nearest neighbor fraction of . The results are presented in Figure (bottom-left) and line (4a) of Table . This local regression recalibration seems to provide biased estimates in the tails. Selecting a smaller nearest neighbor fraction of
gives a smaller bias, but a more wiggly curve in the main body of the data, see Figure (bottom-right), therefore, an adaptive smoothing window size may work better. Focusing on the last column of Table , we see that this local regression recalibration tries to accurately estimate the expected frequency locally, but this does not give us any guarantee that the global balance property holds. Alternatively, one could explore a generalized additive model (GAM) which is based on natural cubic splines, and which will have the global balance property if we work with the canonical link.
Next, we exploit Theorem 2.3. The expected claims frequency on the considered data is roughly 7.36%, i.e. we expected that on average only 7 out of 100 car drivers suffer a claim within one calendar year. This is a typical situation of a low signal-to-noise ratio. This can also be verified from Table . The total uncertainty of the null model of 25.445 (out-of-sample Poisson deviance loss) is reduced to 23.800 by the regression structure using all available information . Thus, the systematic part reduces the total uncertainty by roughly 6.5%, and the remainder can be interpreted as irreducible risk. This is a typical situation of a low signal-to-noise ratio which, in our case, provides a complexity number of
, see Figure (top-left); the first FFNN predictor has 581,272 different values. Thus, the resulting complexity of the partition
of the covariate space
is substantially reduced by the isotonic recalibration. This leads to explainability of insurance prices, illustrated in Figures and , that we are going to discuss next.
In Figure , we illustrate the resulting marginal plots if we project the estimated values of the isotonic recalibration to the corresponding covariate levels, i.e. this is the marginal distribution of the resulting covariate space partition (Equation3.2
(3.2)
(3.2) ) on each level of the considered covariates. For our complexity number of
, this results in 77 different colors, and the resulting picture can be interpreted nicely, see Figure . From this plot we conclude that BonusMalus is the most important covariate component, young DrivAge have significantly higher expected frequencies, Area code A (country side) has a lower expected frequency, etc.
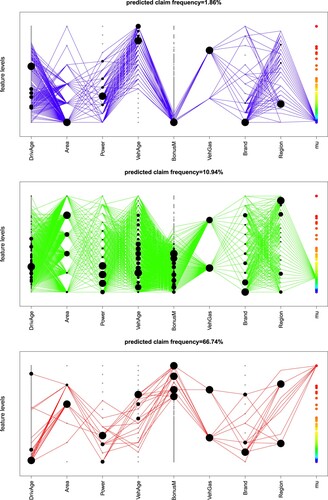
The previous figure gives a marginal view because the estimates (and colors) are projected to the corresponding covariate levels, similar to partial dependence plots (PDPs). Since it is also important to understand interactions of covariate components, we analyze a second plot in Figure ; this plot uses the same coloring for the 77 different expected frequencies as Figure . The lines connect all the covariate combinations in that are observed within the data
for a given value
, and the size of the black dots illustrates how often a certain covariate level is represented in this data. E.g. the figure on the top belongs to the second smallest expected claims frequency estimate
. These car drivers are aged above 30, they mostly live in Area A, have lower power and old cars, and they are on the lowest bonus-malus level. The bottom plot shows the drivers that belong to the biggest expected frequency of
. Not surprisingly, these are mostly young drivers (and some very old drivers) with a higher bonus-malus level. Similar conclusions can be drawn for the other parts
of the covariate space
, thus, having a low complexity number
enables to explain the regression model.
Finally, we perform a robustness check of the isotonic recalibration by perturbing the ranks . As a benchmark, we consider the local regression calibration to which we apply the same perturbations. In a first experiment, we choose a different FFNN ensemble. Since network fitting involves several elements of randomness, see Wüthrich & Merz (Citation2023, Remarks 7.9), every fitted network will be slightly different. On lines (2a)–(2c) of Table , we consider a second FFNN ensemble to which we apply precisely the same isotonic recalibration and local regression recalibration (using the same hyperparameters) as to the first one on lines (1a)-(1c). The results are rather similar which supports a certain robustness across different FFNN calibrations. The second experiment that we consider is to randomly locally perturb the ranks
of the first FFNN ensemble by multiplying the estimated FFNN frequencies by
for i.i.d. standard uniformly distributed random variables
. This increases or decreases to original frequencies by maximally
. Through this additional random noise we generally expect that the complexity number K will decrease. The results are presented on lines (3a)–(3c). We observe that this perturbation does not harm the results too much, which supports that these methods have a certain robustness towards small perturbations of the ranks.
Table 3. Robustness check in the French MTPL example using all covariates; Poisson deviance losses in .
5. Conclusions
We have tackled two problems. First, we have enforced that the regression model fulfills the auto-calibration property by applying an isotonic recalibration to the ranks of a fitted (first) regression model. This isotonic recalibration does not involve any hyperparameters, but it solely assumes that the ranks from the first regression model are (approximately) correct. Isotonic regression has the property that the complexity of the resulting (non-parametric) regression function is small in low signal-to-noise ratio problems. Benefiting from this property, we have shown that this leads to explainable regression functions because a low complexity is equivalent to a coarse partition of the covariate space. In insurance pricing problems, this is particularly useful as we typically face a low signal-to-noise ratio in insurance claims data. We can then fit a complex (algorithmic) model to that data in a first step, and in a subsequent step we propose to auto-calibrate the first regression function using isotonic recalibration, which also leads to a substantial simplification of the regression function.
Acknowledgements
We would like thank the editor and the referees for giving us very useful remarks that have helped us to improve this manuscript. The second author would like to thank Alexander Henzi for pointing out related results on the complexity number of isotonic regression.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ayer, M., Brunk, H. D., Ewing, G. M., Reid, W. T. & Silverman, E. (1955). An empirical distribution function for sampling with incomplete information. Annals of Mathematical Statistics 26, 641–647.
- Balabdaoui, F., Durot, C. & Jankowski, H. (2019). Least squares estimation in the monotone single index model. Bernoulli 25, 3276–3310.
- Barlow, R. E., Bartholomew, D. J., Brenner, J. M. & Brunk, H. D. (1972). Statistical inference under order restrictions. Wiley.
- Barlow, R. E. & Brunk, H. D. (1972). The isotonic regression problem and its dual. Journal of the American Statistical Association 67(337), 140–147.
- Blier-Wong, C., Lamontagne, L. & Marceau, E. (2022). A representation-learning approach for insurance pricing with images. Insurance Data Science Conference, 15–17 June 2022, Milan.
- Brunk, H. D., Ewing, G. M. & Utz, W. R. (1957). Minimizing integrals in certain classes of monotone functions. Pacific Journal of Mathematics 7, 833–847.
- Busing, F. M. T. A. (2022). Monotone regression: a simple and fast O(n) PAVA implementation. Journal of Statistical Software 102, 1–25.
- de Leeuw, J., Hornik, K. & Mair, P. (2009). Isotone optimization in R: pool-adjacent-violators algorithm (PAVA) and active set methods. Journal of Statistical Software 32(5), 1–24.
- Denuit, M., Charpentier, A. & Trufin, J. (2021). Autocalibration and Tweedie-dominance for insurance pricing with machine learning. Insurance: Mathematics & Economics 101, 485–497.
- Dimitriadis, T., Dümbgen, L., Henzi, A., Puke, M. & Ziegel, J. (2022). Honest calibration assessment for binary outcome predictions. arXiv:2203.04065.
- Dutang, C. & Charpentier, A. (2018). CASdatasets R Package Vignette. Reference Manual. Version 1.0-8, packaged 2018-05-20.
- Gneiting, T. (2011). Making and evaluating point forecasts. Journal of the American Statistical Association 106(494), 746–762.
- Gneiting, T. & Resin, J. (2022). Regression diagnostics meets forecast evaluation: conditional calibration, reliability diagrams and coefficient of determination. arXiv:2108.03210v3.
- Henzi, A., Kleger, G.-R. & Ziegel, J. F. (2023). Distributional (single) index models. Journal of the American Statistical Association 118(541), 489–503.
- Henzi, A., Ziegel, J. F. & Gneiting, T. (2021). Isotonic distributional regression. Journal of the Royal Statistical Society Series B: Statistical Methodology 83, 963–993.
- Hosmer, D. W. & Lemeshow, S. (1980). Goodness of fit tests for the multiple logistic regression model. Communications in Statistics - Theory and Methods 9, 1043–1069.
- Karush, W. (1939). Minima of functions of several variables with inequalities as side constraints [MSc thesis]. Department of Mathematics, University of Chicago.
- Kingma, D. P. & Welling, M. (2019). An introduction to variational autoencoders. Foundations and Trends in Machine Learning 12(4), 307–392.
- Krüger, F. & Ziegel, J. F. (2021). Generic conditions for forecast dominance. Journal of Business & Economics Statistics 39(4), 972–983.
- Kruskal, J. B. (1964). Nonmetric multidimensional scaling: a numerical method. Psychometrika 29, 115–129.
- Kuhn, H. W. & Tucker, A. W. (1951). Nonlinear programming. Proceedings of 2nd Berkeley Symposium. University of California Press. P. 481–492.
- Lindholm, M., Lindskog, F. & Palmquist, J. (2023). Local bias adjustment, duration-weighted probabilities, and automatic construction of tariff cells. Scandinavian Actuarial Journal, published online: 14 Feb 2023.
- Loader, C. (1999). Local regression and likelihood. Springer.
- Lundberg, S. M. & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30. Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.). Curran Associates. P. 4765–4774.
- Mayer, M., Meier, D. & Wüthrich, M. V. (2023). SHAP for actuaries: explain any model. SSRN Manuscript ID 4389797.
- Menon, A. K., Jiang, X., Vembu, S., Elkan, C. & Ohno-Machado, L. (2012). Predicting accurate probabilities with ranking loss. ICML'12: Proceedings of the 29th International Conference on Machine Learning. Omnipress, 2600 Anderson Street, Madison, WI, United States P. 659–666.
- Meyer, M. & Woodroofe, M. (2000). On the degrees of freedom in shape-restricted regression. Annals of Statistics 28(4), 1083–1104.
- Miles, R. E. (1959). The complete amalgamation into blocks, by weighted means, of a finite set of real numbers. Biometrika 46, 317–327.
- Murphy, A. H. (1973). A new vector partition of the probability score. Journal of Applied Meteorology 12(4), 595–600.
- Peiris, H., Jeong, H. & Kim, J.-K. (2023). Integration of traditional and telematics data for efficient insurance claims prediction. SSRN Manuscript ID 4344952.
- Savage, L. J. (1971). Elicitable of personal probabilities and expectations. Journal of the American Statistical Association 66(336), 783–801.
- Schervish, M. J. (1989). A general method of comparing probability assessors. The Annals of Statistics 17(4), 1856–1879.
- Tasche, D. (2021). Calibrating sufficiently. Statistics: A Journal of Theoretical and Applied Statistics 55(6), 1356–1386.
- Therneau, T. M. & Atkinson, E. J. (2022). An introduction to recursive partitioning using the RPART routines. R Vignettes, version of October 21, 2022. Rochester: Mayo Foundation.
- Tibshirani, R. J., Hoefling, H. & Tibshirani, R. (2011). Nearly-isotonic regression. Technometrics 53(1), 54–61.
- Wüthrich, M. V. (2023). Model selection with Gini indices under auto-calibration. European Actuarial Journal 13(1), 469–477.
- Wüthrich, M. V. & Merz, M. (2023). Statistical foundations of actuarial learning and its applications. Springer Actuarial.
- Zadrozny, B. & Elkan, C. (2002). Transforming classifier scores into accurate multiclass probability estimates. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, New York, NY, United State P. 694–699.
Appendix
A.1. Pool adjacent violators algorithm
Minimization problem (Equation2.2(2.2)
(2.2) ) is a quadratic optimization problem with linear side constraints, and it can be solved using the method of Karush–Kuhn–Tucker (KKT) (Karush Citation1939, Kuhn & Tucker Citation1951). We therefore consider the Lagrangian
with Lagrange multiplier
. The KKT conditions are given by
(A1)
(A1)
(A2)
(A2)
(A3)
(A3)
(A4)
(A4) The solution to these KKT conditions (EquationA1
(A1)
(A1) )–(EquationA4
(A4)
(A4) ) provides the isotonic estimate
. This solution can be found by the PAV algorithm. The main idea is to compare raw estimates
. If we have an adjacent pair with
, it violates the monotonicity constraint. Such pairs are recursively merged (pooled) to a block with an identical estimate, and iterating this pooling of adjacent pairs and blocks, respectively, that violate the monotonicity constraint, yields the PAV algorithm.
Pool Adjacent Violators (PAV) Algorithm
| (0) | Initialize the algorithm | ||||
| (1) | Iterate for
| ||||
| (2) | Set the isotonic regression estimate | ||||
Remark A.1
PAV algorithm interpretation
We initialize with the unconstraint optimal solution, and setting
ensures that the KKT conditions (EquationA1
We identify a pair
We set on each block the constant estimate (EquationA5
On a sample of size n, this algorithm can be iterated at most n−1 times, thus, the algorithm will terminate.
Since we have for
A.2. Proof of Theorem 2.3
Proof
Proof of Theorem 2.3
For given responses , the solution to (Equation2.2
(2.2)
(2.2) ) gives the partition (Equation2.3
(2.3)
(2.3) ) of the index set
with empirical weighted averages (Equation2.4
(2.4)
(2.4) ) on the blocks
. These empirical weighted averages satisfy
for all
, because the blocks
have been chosen maximal. We now consider how these blocks are constructed in the PAV algorithm. Suppose that we are in iteration
, and in this iteration of the PAV algorithm, we merge the two adjacent blocks
and
because
for
and
. We analyze this inequality
We use the location-scale structure (Equation2.4
(2.4)
(2.4) ) which gives us the equivalent condition
Since for any indices
and
we have
, it follows that the previous condition for merging the two adjacent blocks
and
in iteration t of the PAV algorithm reads as
(A6)
(A6) The important observation is that if this condition is fulfilled for scale parameter
, then it will also be fulfilled for any bigger scale parameter
(pointwise in
). Thus, any pooling that happens for σ also happens for
. Since this is pointwise on the underlying probability space
, it shows that
is decreasing in
.
Suppose now that the distribution of has full support on
. Then, the event
occurs with positive probability, i.e.
Consider
We focus on the first event on the right-hand side. Note that
, hence
describes an open half space in
containing the origin and with bounding hyperplane that moves further away from the origin when decreasing σ. Overall, the set
of values of
is a non-empty open polyhedron containing the origin that scales with σ, that is,
. Therefore, since the distribution of
has full support, the probability
is strictly decreasing in σ.